
今天试着用一个工具 ui vision rpa 一个edge插件,今天试着用一个流程图创作的免费站Flowchart Maker & Online Diagram Software
0.蓝图
胡乱画的。
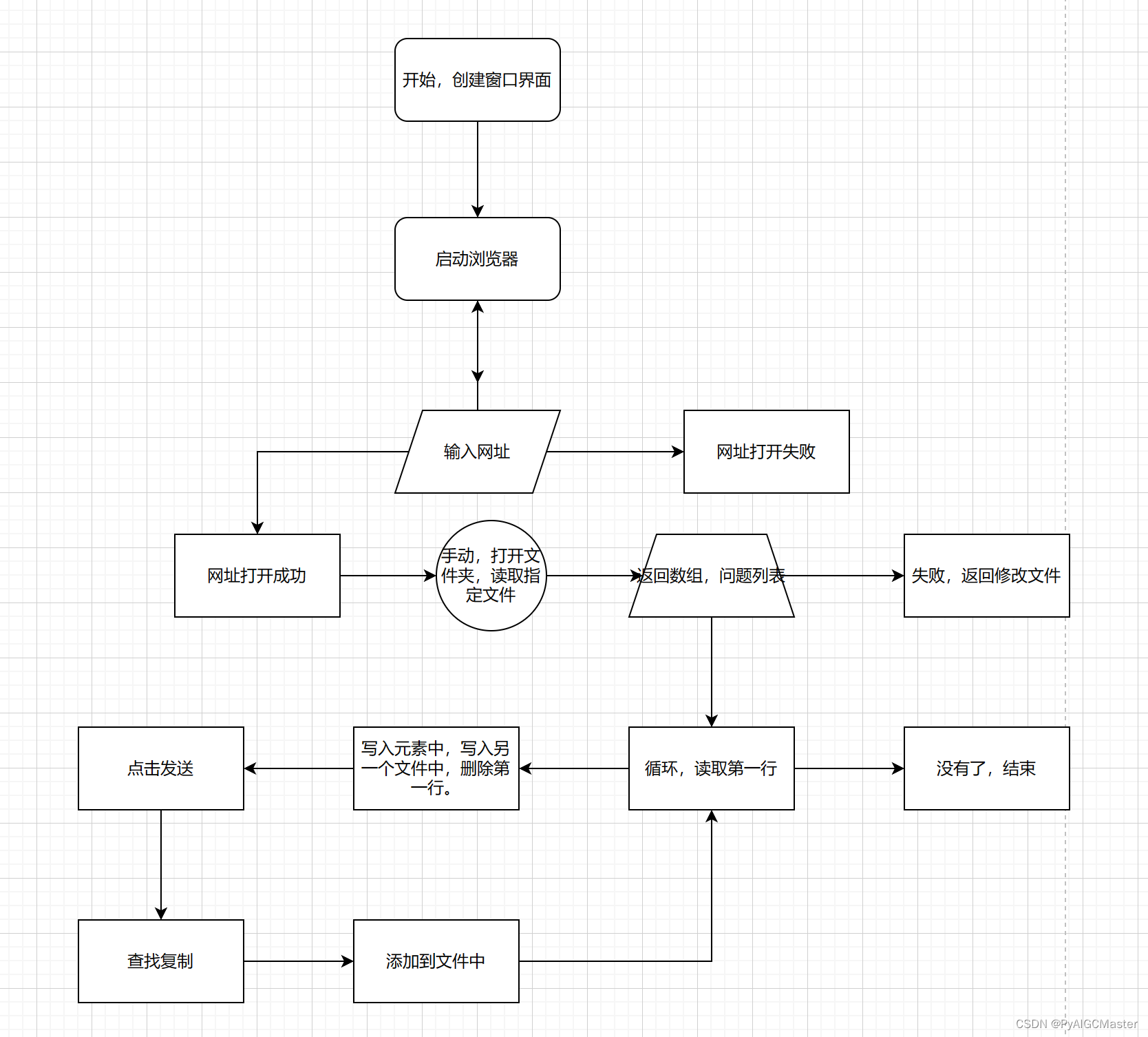
1.判断一个网站是否加载成功。
要判断网页已经打开并且加载完成,可以使用Selenium的显式等待(Explicit Waits)功能,配合expected_conditions模块中的条件来实现。以下是一个常用的示例,展示如何等待整个页面加载完成:(测试可用)
def js_condition(driver):
"""自定义等待条件函数,检查JavaScript返回值"""
return driver.execute_script("return document.readyState") == "complete"
def open_edge_browser(url):
global driver
# 设置Edge选项
edge_options = Options()
edge_options.use_chromium = True
# 向Edge浏览器传递启动参数
edge_options.add_argument('--disable-extensions') # 禁用浏览器扩展
edge_options.add_argument('--disable-gpu') # 禁用GPU硬件加速
# 初始化Edge浏览器驱动(假设msedgedriver.exe已添加到PATH)
driver = webdriver.Edge(options=edge_options)
driver.maximize_window()
try:
# 打开网页
driver.get(url)
# 设置显式等待,等待页面加载完成
# 这里使用了多个条件来确保页面加载完成:
# 1. `EC.presence_of_element_located((By.TAG_NAME, 'body'))` 确保body标签存在,基本的HTML结构已加载。
# 2. `EC.visibility_of_element_located((By.ID, 'someId'))` 可以替换为页面上某个关键元素的ID,确保该元素不仅加载而且可见。
# 3. `EC.javascript_returned_value(True)` 可以用来执行JavaScript检查`document.readyState`是否为"complete"。
# 通常选择其中一个或几个条件根据实际情况而定,这里以`document.readyState`为例。
WebDriverWait(driver, 10).until(js_condition)
print("网页已加载完成。")
return driver
except Exception as e:
print(f"页面加载超时或发生错误: {e}")
2.通过头像判断是否已经登录(测试通过)
def login_in_kimi(driver):
# XPath 位置
# xpath_button = 'xpath=//*[@id="root"]/div/div[2]/div/div/div/div[7]/div/div/div/div/div/img'
# 类名位置
class_name = 'image___tZVx_'
try:
# 设置等待时间,如果元素在60秒内出现则继续
wait = WebDriverWait(driver, 60)
# element = wait.until(EC.element_to_be_clickable((By.XPATH, xpath_button)))
element = wait.until(EC.element_to_be_clickable((By.CLASS_NAME, class_name)))
if element:
# 元素出现并可点击,执行点击操作
# element.click()
print("头像发现,人物已经登录")
except TimeoutException:
print("按钮在60秒内未出现。")
3.编辑框的sendkeys问题,我在这个地方纠结了好长时间。总之,就是根据提示语向上找第一个div即可。
编辑框要先输入除提示语外的内容,然后再检查。可以使用唯一的class或 css等。选择最上层。
写成'//div[@data-slate-node="element"]' 还是'div[data-slate-node="element"]'在Selenium中,定位元素时,你可以使用XPath或CSS选择器。你提供的两个表达式分别对应XPath和CSS选择器的语法。
'//div[@data-slate-node="element"]' 是XPath表达式,它从文档的任意位置开始搜索,查找所有属性data-slate-node等于"element"的元素。
'div[data-slate-node="element"]' 是CSS选择器的语法,它同样用于定位属性data-slate-node值为"element"的元素。
选择哪个?
XPath ('//div[@data-slate-node="element"]'):
更加灵活,可以进行更复杂的路径匹配和属性筛选。
在需要遍历整个DOM树或进行更精确控制时很有用。
性能上可能不如CSS选择器,特别是在大型DOM结构中。
CSS选择器 ('div[data-slate-node="element"]'):
通常更简洁,易于阅读和编写。
在现代Web开发中更为常见,与CSS标准一致。
性能通常优于XPath,尤其是在浏览器中执行时。
结论:
如果你的应用场景简单,且主要关注性能和代码可读性,推荐使用CSS选择器:'div[data-slate-node="element"]'。如果需要进行更复杂的层级匹配或属性逻辑判断,可以选择XPath。在HTML中,元素通常不用于接收用户输入,而是用于显示占位符文本。因此,我们需要找到与这个元素相关联的真正用于输入的元素,如<input>或<textarea>。然而,由于元素不能直接接收send_keys,我们需要找到那个关联的输入元素来输入文本。
当编辑框(如<input>或<textarea>)初始显示有提示语,而在开始输入时提示语消失,定位该编辑框元素通常不受提示语的影响,因为我们要定位的是编辑框本身,而不是其内部的提示文本。以下是一些步骤和代码示例来帮助你定位并输入文字到这样的编辑框中:
步骤:
确定元素标识:首先,你需要通过开发者工具找到编辑框的唯一标识,比如id、name、class或CSS选择器。
使用显式等待:为了避免由于页面加载速度导致的元素定位失败,使用WebDriverWait和适当的预期条件来等待元素变为可交互状态。
清空与输入:定位到编辑框后,先清空其内容(以防有默认值或提示语),然后输入你想要的文字。以下代码测试可用。
def set_edit_string(driver, param): # # CSS 选择器 xpath_name = '//div[@data-slate-node="element"]' # HTML元素定位 # element_xpath = _xpath = 'div[data-slate-node="el
本文转载自: https://blog.csdn.net/weixin_42771529/article/details/138367442
版权归原作者 PyAIGCMaster 所有, 如有侵权,请联系我们删除。