
1.什么是数据仓库
数据仓库是一个面向主题的,集成性的,非易失性的,时变性的数据集合,用于管理决策。
数据仓库解决的问题:
- 为业务部门提供准确清晰的报表
- 为管理人员提供更强的分析能力
- 为数据挖掘和知识发现奠定基础
面向主题
数据仓库内的数据是针对特定的业务主题。数据仓库将与特定主题相关的数据整合到一起,方便企业进行全面的数据分析。
例如“销售分析”就是一个分析领域,因此这个数据仓库应用的
主题就是“销售分析”。
集成性
数据仓库内的数据来自多个数据源,并通过转换,整合成为统一的数据模型
这是因为源数据一般都是有不完整的和数
据形式不统一的。这些“脏数据”的直接导入将对在数据仓库基础上进行的数据挖掘造成混乱。
“脏数据”在进入数据仓库之前必须经过抽取、清洗、转换才能生成从面向事务转而面向主题的
数据集合。
非易失性
数据仓库的非易失性是指数据仓库内的数据是持久存储的,不会因为计算机系统故障或其他原因而丢失。
时变性
数据仓库的时变性指的是数据仓库中存储的数据具有时间上的变化性质。也就是说,数据仓库中的数据不仅仅反映当前状态,还包含了过去和可能的未来状态。
2.数仓建模基本理论
2.1 维度模型
维度建模是从分析决策的需求出发构建模型,以满足用户对快速完成需求分析和执行大规模复杂查询的需求。典型的代表是星形模型,同时在一些特殊场景下也会使用雪花模型。
分析决策的需求就是企业或组织在做出决策之前所需要的信息和洞察,通过对数据的分析来支持决策制定。
举例来说,一个公司可能需要分析销售数据来确定最畅销的产品,以便制定更好的市场推广策略;
在设计维度模型期间存在5个关键决策
- 确定业务过程 业务过程通常用行为动词表示,表示业务执行的活动。
1.比如淘宝订单流转的业务过程有四个:创建订单、买家付款、卖家发货、买家确认收货。
在选择了业务过程以后,相应的事实表类型也随之确定了。
2.比如选择买家付款单个业务过程,那么事实表应为只包含买家付款这一个业务过程的单事务型事实表
3.如果选择的是所有这四个业务过程,并且需要分析各个业务过程之间的时间间隔,那么所建的事实表应为包含了所有四个业务过程的累积快照型事实表
- 声明业务过程的粒度
应该尽量选择最细级别的原子粒度,以确保事实表的应用具有最大的灵活性。同时对于订单过程而言,粒度可以被定义为最细的订单级别。
比如在淘宝订单中有父子订单的概念,即一个子订单对应一种商品,如果拍下了多种商品,则每种商品对应一个子订单:这些子订单一同结算的话,则会生成一个父订单。那么在这个例子中,事实表的粒度应该选择为子订单级别
- 确定维度
维度是维度建模的基础和灵魂。在维度建模中,将度量称为“事实”,将环境描述为“维度”,维度是用于分析事实所需要的多样环境。
例如:
在分析交易过程时,可以通过买家、卖家、商品和时间等维度描述交易发生的环境。
- 确定事实
事实可以通过回答“过程的度量是什么”来确定。应该选择与业务 过程有关的所有事实,且事实的粒度要与所声明的事实表的粒度一致。
事实有可加性、半可加性、非可加性三种类型 , 需要将不可加性事实分 解为可加的组件。
比如在淘宝订单付款事务事实表中,同粒度的事实有子订单分摊的 支付金额、邮费、优惠金额等。
- 冗余维度
冗余方便下游用户使用的常用维度,提高下游用户的使用效率,降低数据获取的复杂性,减少关联的表数量
2.1.1 数据粒度
数据粒度:数据仓库中数据单元的细节程度或者是综合程度的级别,数据到底细到什么程度
- 细节程度越高,粒度级别就越低。
- 细节程度越低,粒度级别就越高。
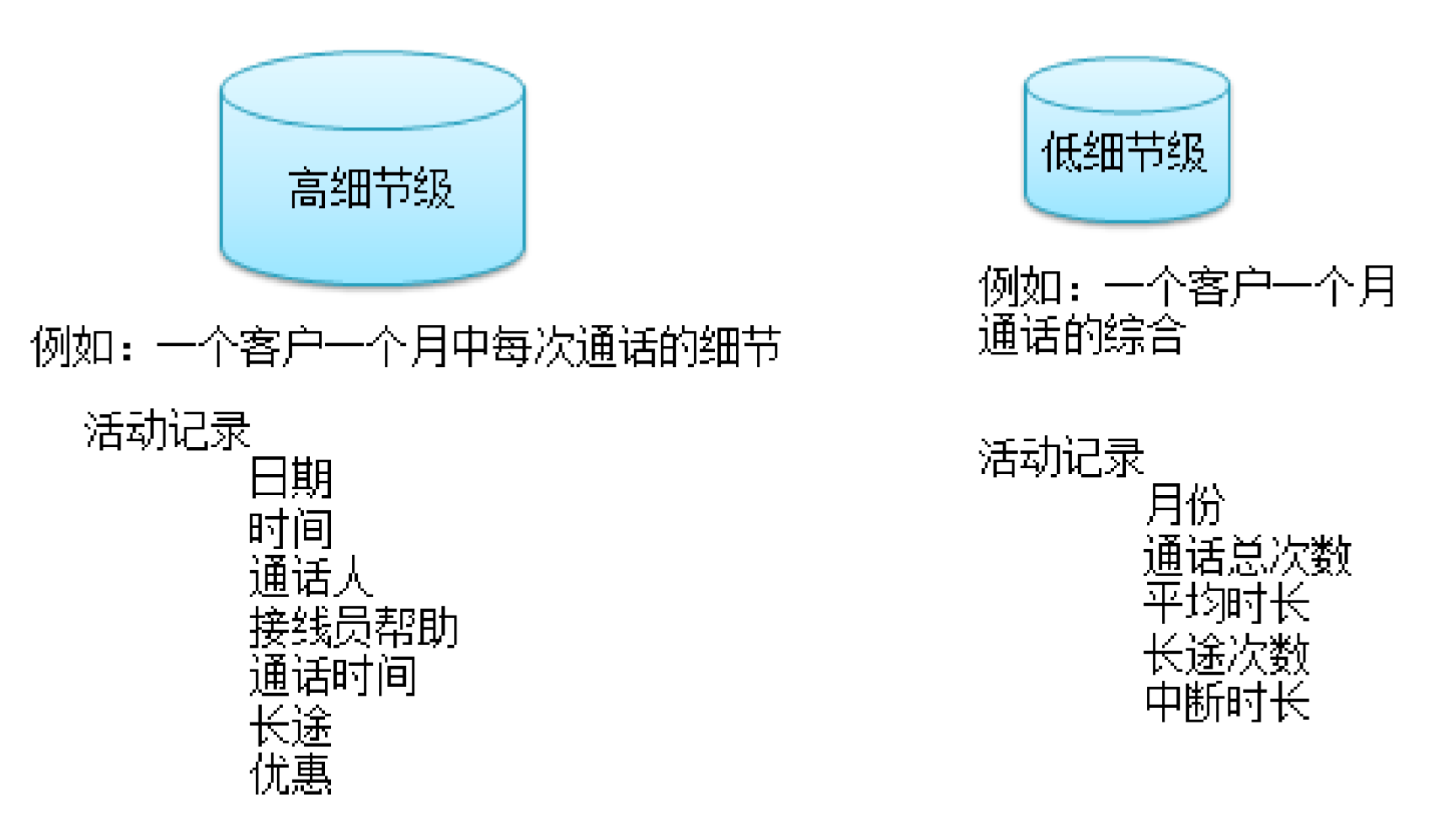
粒度级别越低(细节越高)查询范围更广,粒度级别越高(细节越低)查询所能回答的问题就越少。
2.1.2 事实表
事实表是数据仓库中的一种表,用于存储业务事实或可度量的数据。事实表通常包含了与业务过程相关的数字性数据,如销售金额、数量、成本等。它记录了业务事件的事实或度。
场景:一次购买事件,涉及主体包括客户、商品、商家。产生的可度量值,包括商品数量、金额、
件数等,所以订单明细表,就是一张事实表。
订单表是事实表,那么就会有商品维度,时间维度,品牌维度等等
作为度量业务过程的事实,一般为整型或浮点型的十进制数值,有可加性、半可加性和不可加性三种类型。
事实表的可加性、半可加性和不可加性指的是对事实数据在不同维度组合下的加法规则的分类。
可加性:可加性指的是事实数据在所有维度组合下都可以简单相加,而不会产生歧义或错误的结果。例如,销售额是一个可加性事实,无论按照产品、地区、时间等任何维度进行分析,各个维度上的销售额总和都等于总销售额。
就像你手里有两个篮子,一个装满了苹果,一个装满了橙子。无论你怎么处理这两个篮子,无论是将它们合并成一个篮子还是保持它们分开,你最终都可以简单地把所有水果的数量加起来,得到所有水果的总数
半可加性:半可加性指的是事实数据在某些特定维度组合下可以相加,而在其他维度组合下不能简单相加。
比如库存可以按照地点和商品进行汇总,而按时间维度把一年中每个月的库存累加起来则毫无意义。
不可加性:不可加性指的是事实数据在任何维度组合下都不能简单相加,因为这样做会导致结果失去意义或产生错误。(比如比例事实)
举例来说,假设你有一个事实表记录了一个网站上的广告点击次数和对应的转化次数(比如点击后用户购买产品的次数)。现在你想要计算广告的转化率,即每点击一次广告所对应的购买比率。
假设有两个广告A和B,它们分别获得了100次点击和50次点击,对应的转化次数分别是10次和5次。虽然你可以计算出每个广告的转化率(转化次数除以点击次数),但你不能简单地将两个广告的转化率相加来得到总体的转化率。因为这两个转化率反映了不同广告的效果,它们的加和并不代表整体的转化率
事实表设计原则:摘自《大数据之路:阿里巴巴大数据实践》
- 包含所有业务过程相关的事实有助于多角度度量业务,但要确保不过度冗余。
- 仅选择与业务过程相关的事实,避免不必要的数据存储 例如不应该存在支付金额这个表示支付业务过程的事实。
- 将不可加性事实分解为可加的组件,以提高数据的分析和计算效率。比如订单 的优惠率,应该分解为订单原价金额与订单优惠金额两个事实存储在事实表中。
- 在确定维度和事实之前,明确定义粒度,保持一致性以确保数据一致性和可扩展性。
- 事实表中应保持一致的粒度,避免多种不同粒度的混合。
- 事实的计量单位应保持一致,便于数据处理和分析。
- 处理事实表中的空值,建议使用零值填充以确保查询和分析的准确性。
- 使用退化维度提高事实表的易用性,减少表间关联,提高数据操作效率,但要注意空间和性能的平衡。
2.1.3 事实表的分类
事务事实表: 用于记录业务过程中的原子级别事实或事件。这种事实表通常记录每个单独的事务,例如每笔销售订单或每次交易。
例子:销售订单事实表
每个记录对应一个销售订单的详细信息,包括订单号、订单日期、顾客信息、产品信息、销售数量、销售金额等。
每一行代表一个独立的销售交易,通常情况下会有大量的行记录,每一行代表一个独立的销售订单。
周期快照事实表: 用于捕获在特定时间间隔内发生的事实。它们记录某一时间段内的状态或度量值,例如每月的销售总额或每周的库存量。
例子:每日销售快照事实表
每天记录一次销售情况的总结,包括当天的销售总额、销售数量、最畅销的产品等信息。
每行记录代表一个时间段内的汇总数据,例如每天、每周或每月。
累积快照事实表: 用于捕获业务过程中的状态变化。它们记录业务过程中的关键阶段,例如订单的生命周期,每个阶段的状态及相关度量。
例子:订单处理状态快照事实表
记录订单生命周期中的关键状态,例如订单创建、付款完成、发货、签收等状态,以及每个状态对应的时间和其他相关信息。
每行记录代表一个订单的状态变化,可以追踪订单在整个生命周期中的变化。
混合事实表(Hybrid Fact Table): 结合了以上不同类型的特征,用于满足多种不同的业务需求。混合事实表可能同时包含事务级别和周期快照级别的数据。
例子:零售综合事实表
综合了销售订单的详细信息(事务级别)、每日销售快照(周期快照级别)以及订单处理状态快照(累积快照级别)等不同粒度的数据。
可以包含不同层次和粒度的数据,以满足不同的分析需求。
2.2 模型分类
在构建数据仓库的维度建模中,一般有三种模式。星型模型/雪花模型/星座模型
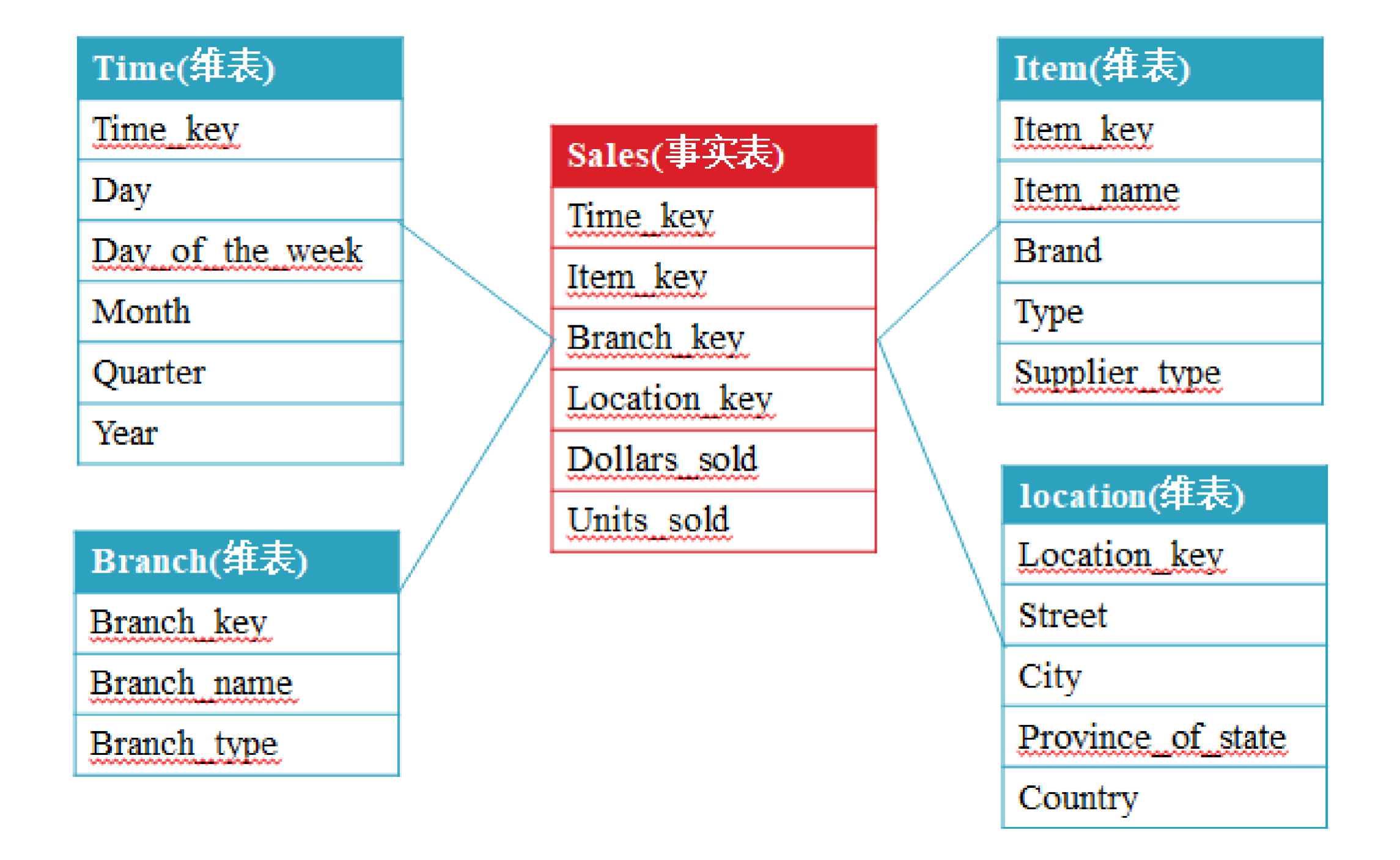
2.2.1 星形模型
星形模型的维度建模由一个事实表和一组维度表组成,有以下特点:
- 维度表只和事实表关联,维度表之间没有关联;
- 每个维表的主码为单列,且该主码放置在事实表中,作为两边连接的外码;
- 以事实表为核心,维表围绕核心呈星形分布;
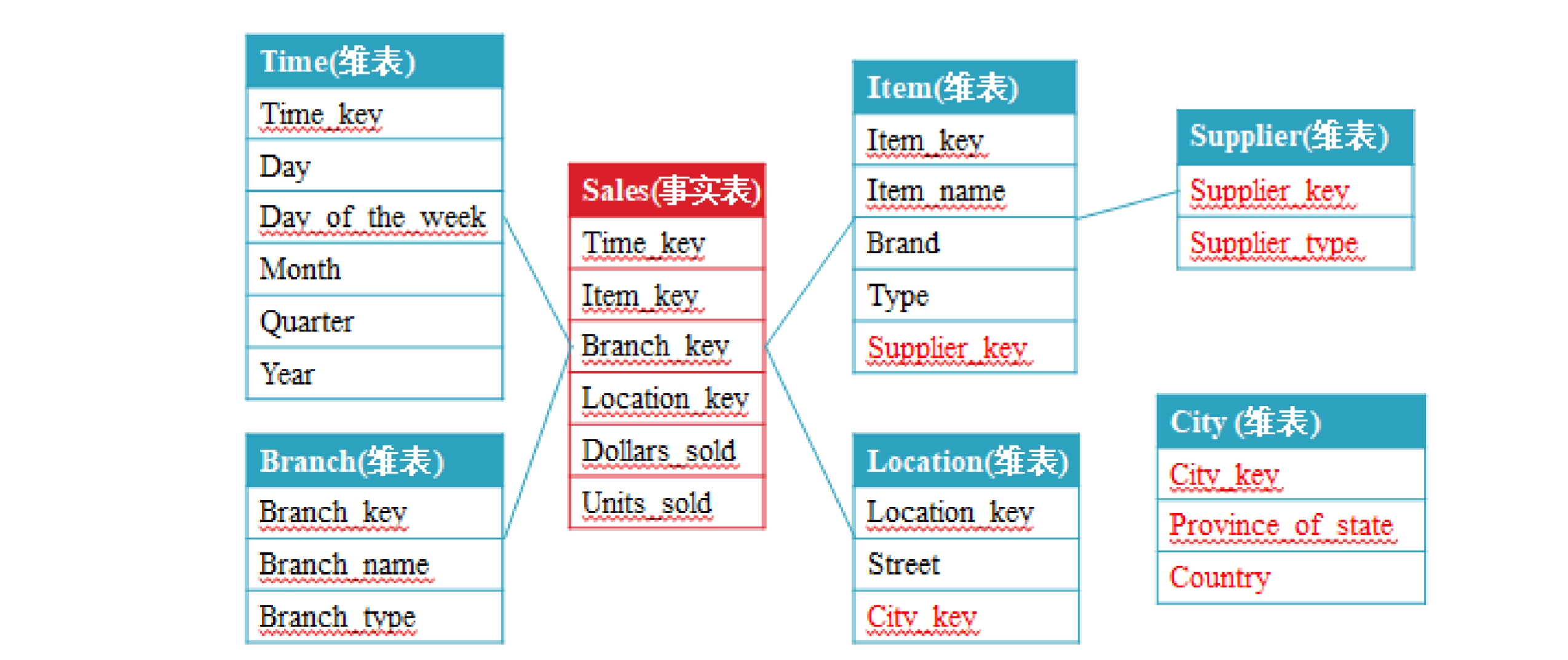
2.2.2 雪花模型
雪花模型的特点:
- 将星形模式的大维度表拆分为小维度表,满足规范化设计,但不利于开发。
- 星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
- 在雪花模型中,数据模型的业务层级是由一个不同维度表主键-外键的关系来代表的。而在星形模型中,所有必要的维度表在事实表中都只拥有外键。
2.3.3星座模型
星型模型和雪花模型都是基于多个维表对应事实表,有的时候一个维度表可能被多个事实表用到
,这个时候就需要采用星座模式
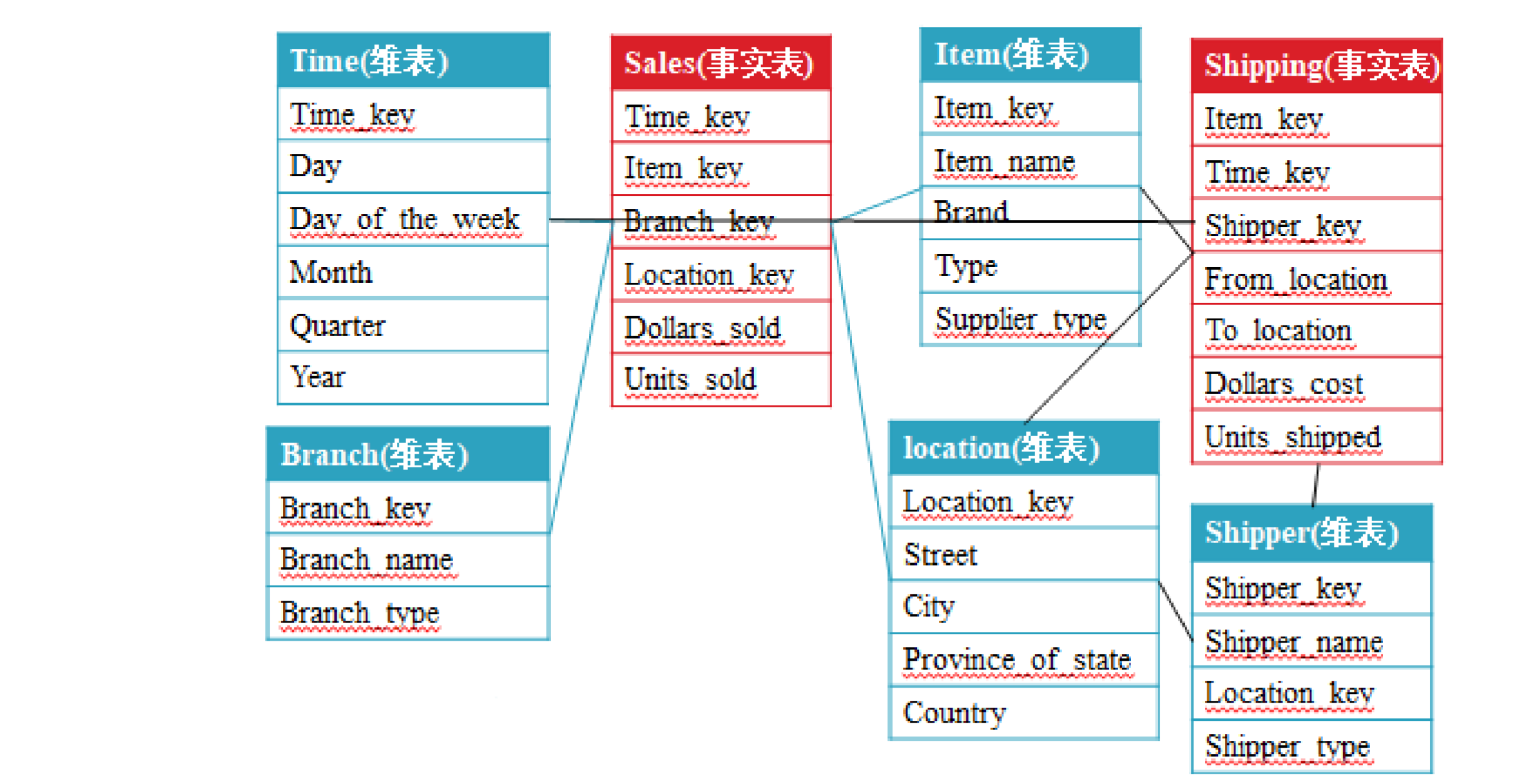
对比
雪花模型是将星型模型的维度表进一步划分,使得各维度表满足规范化设计。而星座模型允许星型
模型中出现多个事实表,更符合实际业务需求。雪花模型使得维度分析更加容易。
特征雪花模型星型模型冗余符合3NF设计,降低数据冗余,但需连接更多的维度表维度表设计不符合3NF,维度表之间不直接相关,牺牲部分存储空间性能由于需要连接更多的维度表,性能偏低采用降维的操作将维度整合,减少维度表连接数,性能较高ETL处理在ETL过程中相对简单,但ETL任务并行化较低在设计维度表时反范式设计,整合业务数据到维度表有一定难度,但ETL任务并行化较高
2.3 建模案例
-电商平台(比如JD),经常需要对订单进行分析,以购物订单为例,以维度建模的方式设计该模
型。
涉及到事实表为订单表、订单明细表,维度包括商品维度、用户维度、商家维度、区域维度、时间
(日期)维度
事实表:订单表****描述性属性订单ID、下单时间、支付时间、订单状态度量商品件数、总金额、总减免事实表:订单明细表****描述性属性订单明细ID、加入购物车时间、状态度量商品ID、件数、单价、减免金额维度表:商品维度****属性商品ID、商品名称、商品种类、单价、来源地维度表:用户维度****属性用户ID、姓名、性别、年龄、常住地、职业、学历维度表:商家维度****属性商家ID、商家名称、商家地点维度表:区域维度****属性区域ID、区域名称、省份、城市、区县维度表:时间(日期)维度****属性日期ID、日期、周几、上/中/下旬、是否周末、是否假期、特殊日期维度表:优惠券维度----------属性日期ID、日期、周几、上/中/下旬、是否周末、是否假期、特殊日期维度表:优惠券维度****属性券ID、券类别/优惠方式、优惠金额
版权归原作者 xQil 所有, 如有侵权,请联系我们删除。