
一:配置虚拟机IP地址
**以三台虚拟机为例,分别作为Master、Server 1、Server 2**

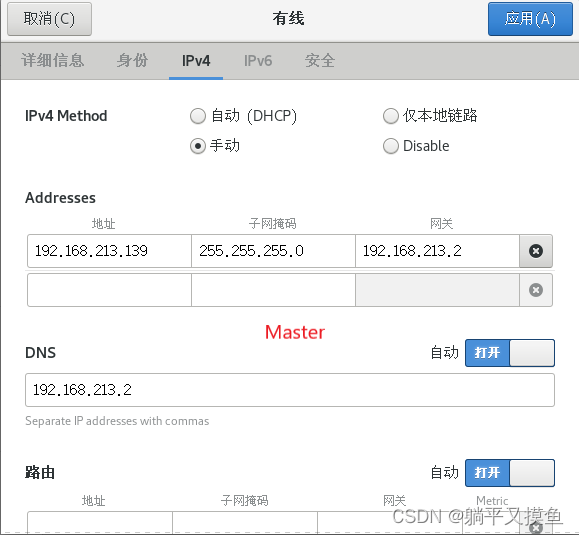
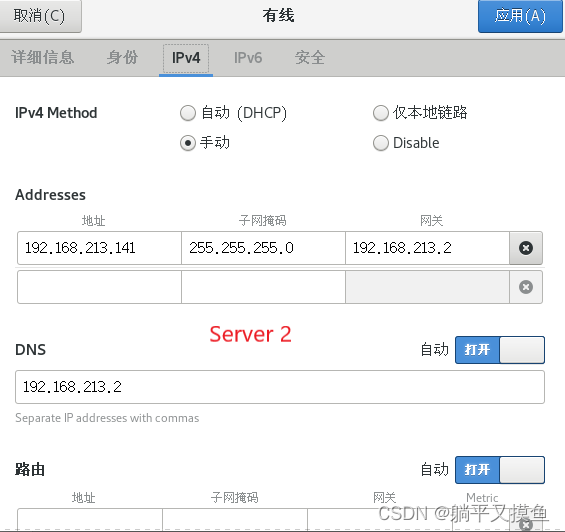
** 手动给三台虚拟机分别配以相应IP地址**

二:集群机器
**这里使用三台主机搭建分布式集群环境,更多台机器同样可以使用如下配置。IP在不同局域网环境下有可能不同,可以用ifconfig****命令查看当前主机的IP。**

** 即可获得当前主机的IP在局域网地址,如下图:**

** 三台机器的名称和IP如下:**
主机名称
IP****地址
Master
192.168.213.139
Server1
192.168.213.140
Server2
192.168.213.141
** 三台电脑主机的用户名均为:W,三台机器可以**ping双方的ip来测试三台电脑的连通性。以Master主机为例,在Master节点主机上的Shell中运行如下命令,测试能否连接到Server 1节点主机。

**如果出现如下图,说明连接成功**

**为了更好的在Shell中区分三台主机,修改其显示的主机名,执行如下命令**
sudo vim /etc/hostname

** 在Master的/etc/hostname添加如下配置:Master**
** 同样Server 1的/etc/hostname添加如下配置:Server1**
** 同样Server 2的/etc/hostname添加如下配置:Server2**
** 重启三台电脑,重启后在终端Shell中才会看到机器名的变化,如下图:**

**修改三台机器的/etc/hosts****文件,添加同样的配置:**
sudo vim /etc/hosts

** 配置如下:**
127.0.0.1 localhost
192.168.213.139 Master
192.168.213.140 Server1
192.168.213.141 Server2

三:配置ssh无密码登录本机和访问集群机器
**三台主机电脑分别运行如下命令:**
sudo yum -y install openssh
systemctl enable sshd.service
systemctl start sshd.service

** 删除秘钥配置文件,在配置之前要将之前配置过得删除,配置文件在当前用户的家目录下.ssh目录(三个节点操作)**
rm -rf ~/.ssh

** 生成秘钥(三个节点生成)**
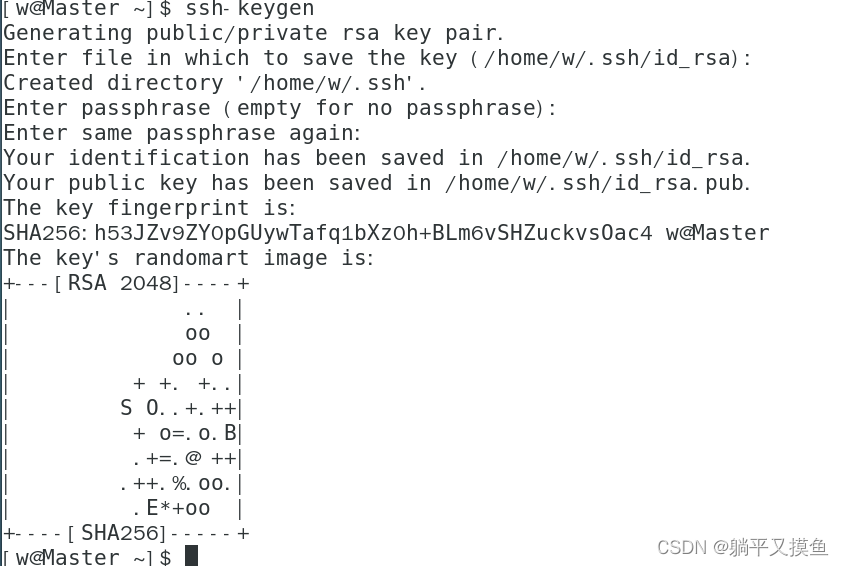
ssh-keygen
** 输入完成后按四次回车,显示以下结果:**
**秘钥拷贝(将三个节点的秘钥都拷贝到Master中)(三个节点执行)**
ssh-copy-id Master

**拷贝完成后,在Master中检查是否拷贝成功(Master执行)**
cat ~/.ssh/authorized_keys

**秘钥分发(Master执行) **
scp -r ~/.ssh/authorized_keys Server1:~/.ssh/
scp -r ~/.ssh/authorized_keys Server2:~/.ssh/

**免密登录验证(三个节点操作)
**
ssh Master
ssh Server1
ssh Server2
**
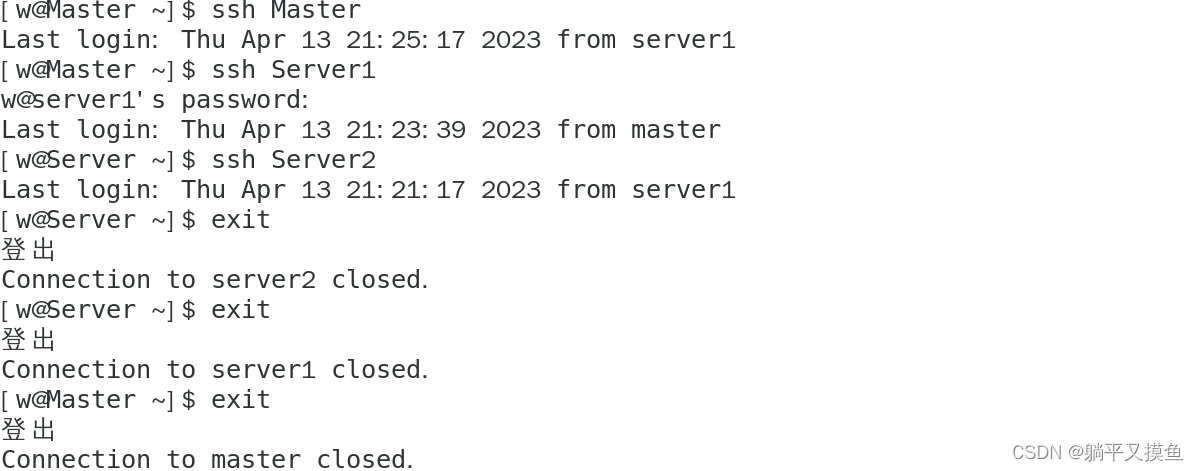
**
四:JDK和Hadoop****安装配置
** <1>:**JDK安装配置
(1):查询已有JAVA环境版本信息
java -version

(2): 卸载已有的openJDK
rpm -qa |grep java

** 如上,将下面几个删除即可**

** .noarch文件属于通用文件,不影响,不用删除,删了也没事~**

**删除命令,(注:删除命令需要用root权限)**
sudo rpm -e --nodeps xxx

**检查是否已经删除成功,(如下说明已经删除成功了)**
java -version

** (3):**查看云端目前支持安装的jdk版本
yum search java|grep jdk

** 选择版本后,安装(执行以下命令会自动安装jdk相关依赖)**
sudo yum install -y java-11-openjdk

(4):安装完成,验证是否安装成功
java -version

** (5):配置JDK**的环境变量
sudo vim ~/.bashrc
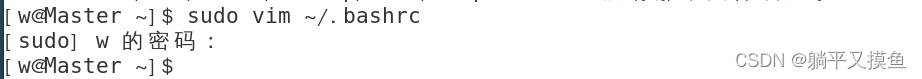
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.19.0.7-1.el7_9.x86_64
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:/usr/local/hadoop-3.3.5/bin:/usr/local/hadoop-3.3.5/sbin
Master hadoop-3.3.5]$ bin/hdfs namenode -format
unset HADOOP_HOME

** 命令使修改的配置文件生效**
source ~/.bashrc

** 通过搜索java文件,查找jdk默认安装目录**
sudo find / -name 'java'

提示:通过yum命令在线安装jdk简单、快捷、无需配置环境变量即可使用java相关服务。
<2>hadoop安装配置
** (1):下载hadoop(以hadoop-3.3.5为例):点击跳转下载**


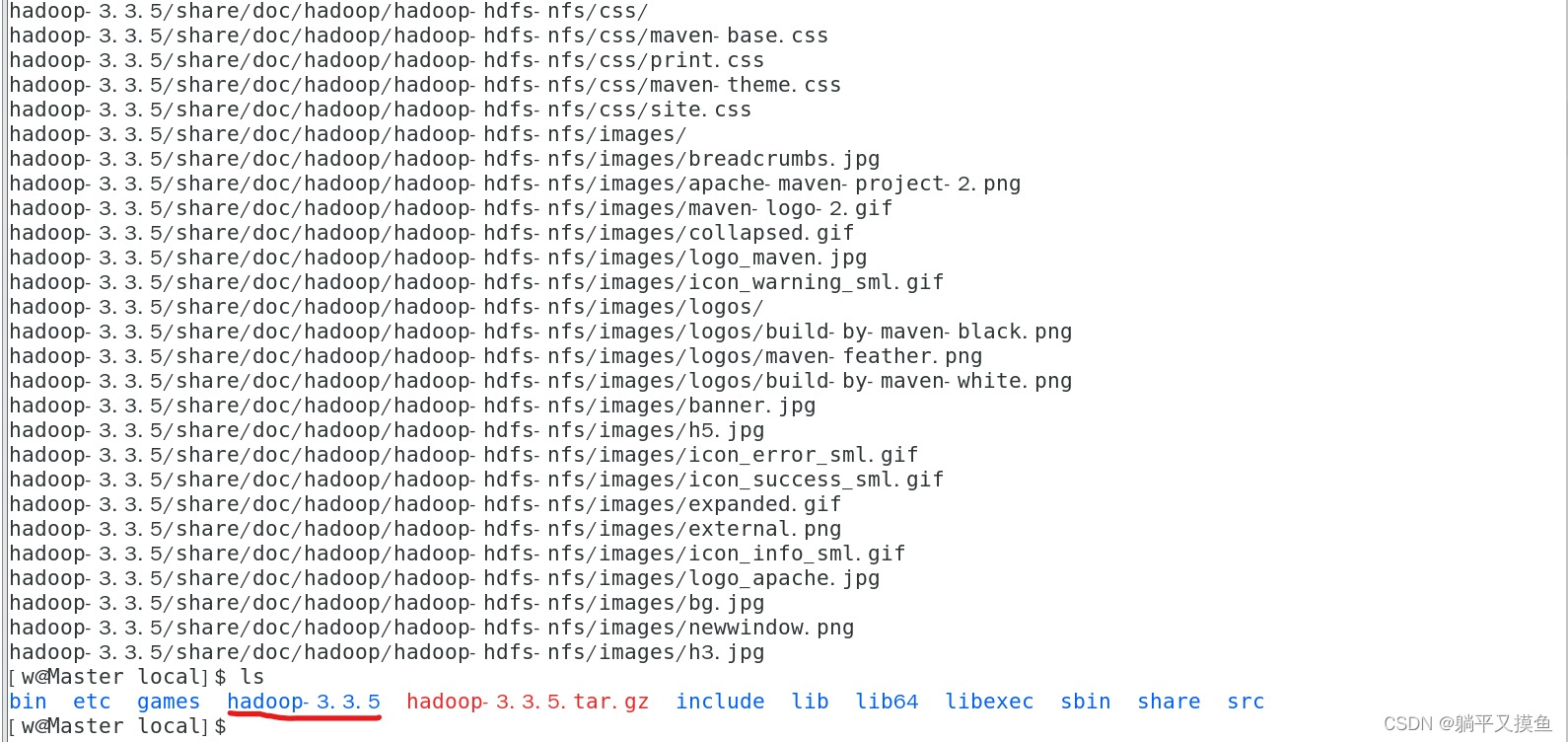
下载好的安装包放在 /usr/local目录,然后进入该目录下****解压安装:
sudo tar -xvf hadoop-3.3.5.tar.gz

 (2): 配置Hadoop环境变量:
(2): 配置Hadoop环境变量:
sudo vim /etc/profile

**添加hadoop环境变量:**
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.19.0.7-1.el7_9.x86_64
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin:/usr/local/hadoop-3.3.5/bin:/usr/local/hadoop-3.3.5/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native

注意:这里的$PATH:$JAVA_HOME/bin:/usr/local/hadoop-3.3.5/bin::/usr/local/hadoop-3.3.5/sbin表示在保留原来的$PATH环境变量的基础上,再增加$JAVA_HOME/bin和:/usr/local/hadoop-3.3.5/bin和:/usr/local/hadoop-3.3.5/sbin这些路径作为新的$PATH环境变量。
** 执行使修改的配置文件生效。**
source /etc/profile

五:Hadoop配置文件修改
** **** 修改etc/hadoop-3.3.5中的一系列配置文件**
(1): 修改core-site.xml文件(Master:在主节点的ip或者映射名(改成自己的))
sudo vim /usr/local/hadoop-3.3.5/etc/hadoop/core-site.xml

** 在节点内加入配置:**
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-3.3.5/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>

(2):修改hadoop-env.sh文件
sudo vim /usr/local/hadoop-3.3.5/etc/hadoop/hadoop-env.sh

export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.19.0.7-1.el7_9.x86_64

将 export JAVA_HOME=${JAVA_HOME}修改为:export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.19.0.7-1.el7_9.x86_64 说明:修改为自己的JDK路径
(3):修改hdfs-site.xml文件(注意改成自己的路径)
sudo vim /usr/local/hadoop-3.3.5/etc/hadoop/hdfs-site.xml

** 在节点内加入配置:**
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-3.3.5/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-3.3.5/tmp/dfs/data</value>
</property>
</configuration>

(4):修改mapred-site.xml文件
** Hadoop没有mapred-site.xml这个文件,现将文件复制到这然后进入mapred-site.xml**
cd /usr/local/hadoop-3.3.5/etc/hadoop
sudo cp mapred-queues.xml.template mapred-site.xml
sudo vim mapred-site.xml
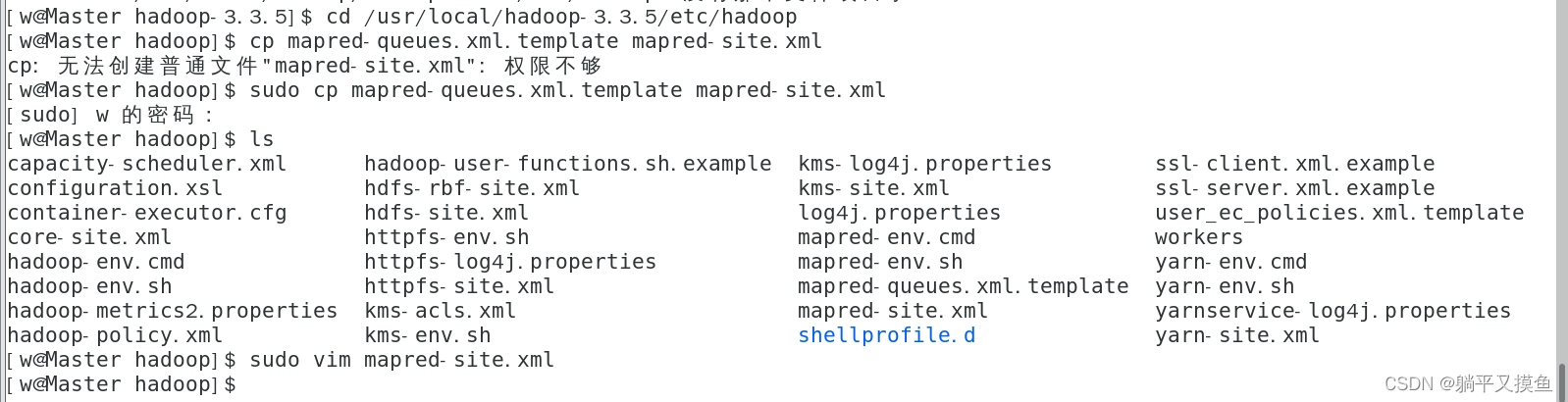
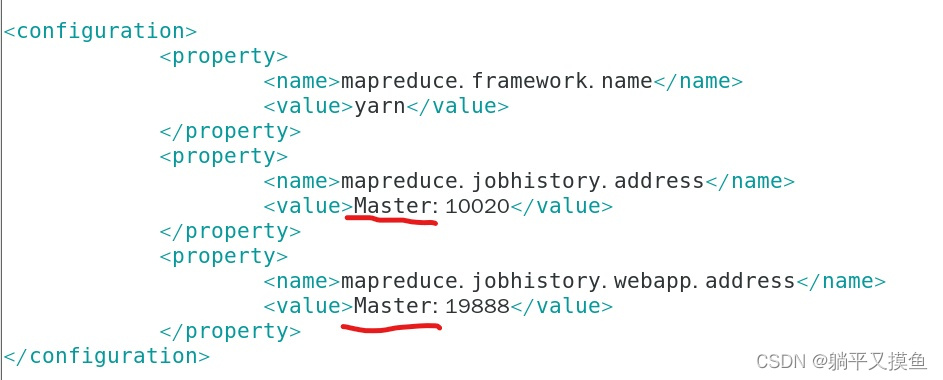
** (Master:在主节点的ip或者映射名(改成自己的))**
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
(5):修改workers文件
** 添加自己的主节点和从节点(Server1、Server2)**
sudo vim /usr/local/hadoop-3.3.5/etc/hadoop/workers

** 将里面的localhost删除,添加以下内容(Master和Server1、Server2节点都要修改):**
Server1
Server2

** 注意:这里面不能有多余空格,文件中不允许有空行。**
(6):修改yarn-site.xml文件
sudo vim /usr/local/hadoop-3.3.5/etc/hadoop/yarn-site.xml

<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

(7):配置hadoop-3.3.5/sbin/目录下文件
**(start-dfs.sh、start-yarn.sh、stop-dfs.sh、stop-yarn.sh文件)**
** 服务启动权限配置
配置start-dfs.sh与stop-dfs.sh文件**
sudo vim sbin/start-dfs.sh

** 和**
sudo vim sbin/stop-dfs.sh

HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root

** 配置start-yarn.sh与stop-yarn.sh文件**
sudo vim sbin/start-yarn.sh

**和**
sudo vim sbin/stop-yarn.sh

YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root

(8):将各个文件复制到其他节点上
配置好后,将 Master 上的 /usr/local/Hadoop-3.3.5 文件夹复制到各个节点上。因为之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。在 Master 节点上执行:
cd /usr/local
sudo rm -r ./hadoop-3.3.5/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop-3.3.5/logs/* # 删除日志文件
sudo tar -zcf ~/hadoop-3.3.5.master.tar.gz ./hadoop-3.3.5 # 先压缩再复制
cd ~
sudo scp ~/hadoop-3.3.5.master.tar.gz Server1:/home/w
sudo scp ~/hadoop-3.3.5.master.tar.gz Server2:/home/w
sudo scp -r /etc/profile w@Server1:/etc/profile #将环境变量profile文件分发到Server1节点
sudo scp -r /etc/profile w@Server2:/etc/profile #将环境变量profile文件分发到Server2节点
sudo scp -r /usr/local/hadoop-3.3.5 w@Master:/usr/local
sudo scp -r /usr/local/hadoop-3.3.5 w@Server1:/usr/local #将hadoop文件分发到Server1节点
sudo scp -r /usr/local/hadoop-3.3.5 w@Server2:/usr/local #将hadoop文件分发到Server2节点

(9):在 Server1、Server2 节点上执行:
sudo rm -r /usr/local/hadoop-3.3.5 # 删掉旧的(如果存在)
sudo tar -zxf ~/hadoop-3.3.5.master.tar.gz -C /usr/local
sudo chown -R w /usr/local/hadoop-3.3.5
 (10):生效Server1、Server2的环境变量
(10):生效Server1、Server2的环境变量
source /etc/profile

六、启动Hadoop
CentOS系统需要关闭防火墙: CentOS系统默认开启了防火墙,在开启 Hadoop 集群之前,需要关闭集群中每个节点的防火墙。有防火墙会导致 ping 得通但 telnet 端口不通,从而导致 DataNode 启动了,但 Live datanodes 为 0 的情况。
(1):CentOS 7关闭防火墙
**需通过如下命令关闭(防火墙服务改成了 firewall,在Master执行):**
systemctl stop firewalld.service # 关闭firewall
systemctl disable firewalld.service # 禁止firewall开机启动

** 使用以下命令查看防火墙状态:**
systemctl status firewalld

(2):启动
**首次启动需要先在 Master 节点执行 NameNode 的格式化:**
cd /usr/local/hadoop-3.3.5
hdfs namenode -format # 首次运行需要执行初始化,之后不需要

**接着可以启动 hadoop 了,启动需要在 Master 节点上进行:**
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
#或者
start-all.sh
 **输入命令
**输入命令
jps
可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode 进程,如下图所示:**

** 在 Server1、Server2节点可以看到 DataNode 和 NodeManager 进程,如下图所示:**


**缺少任一进程都表示出错。另外还需要在 Master 节点上通过命令
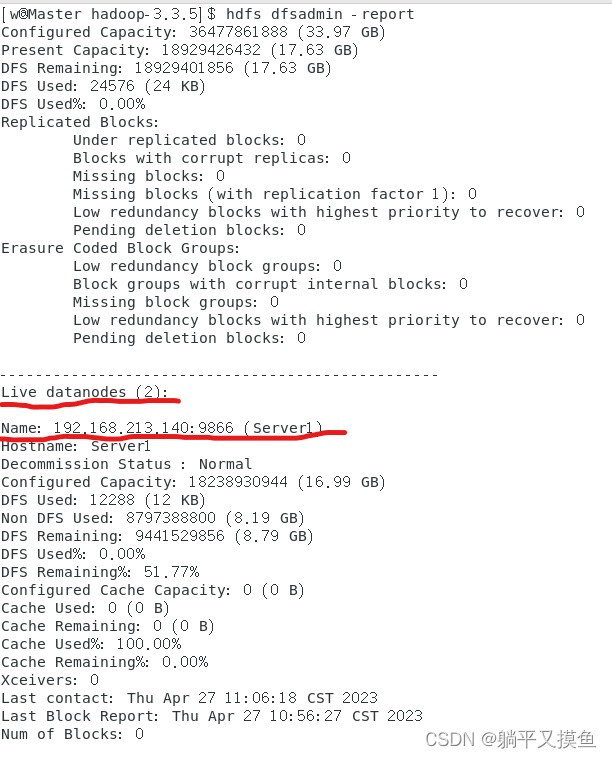
hdfs dfsadmin -report
查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。例如我这边一共有 2 个 Datanodes**:

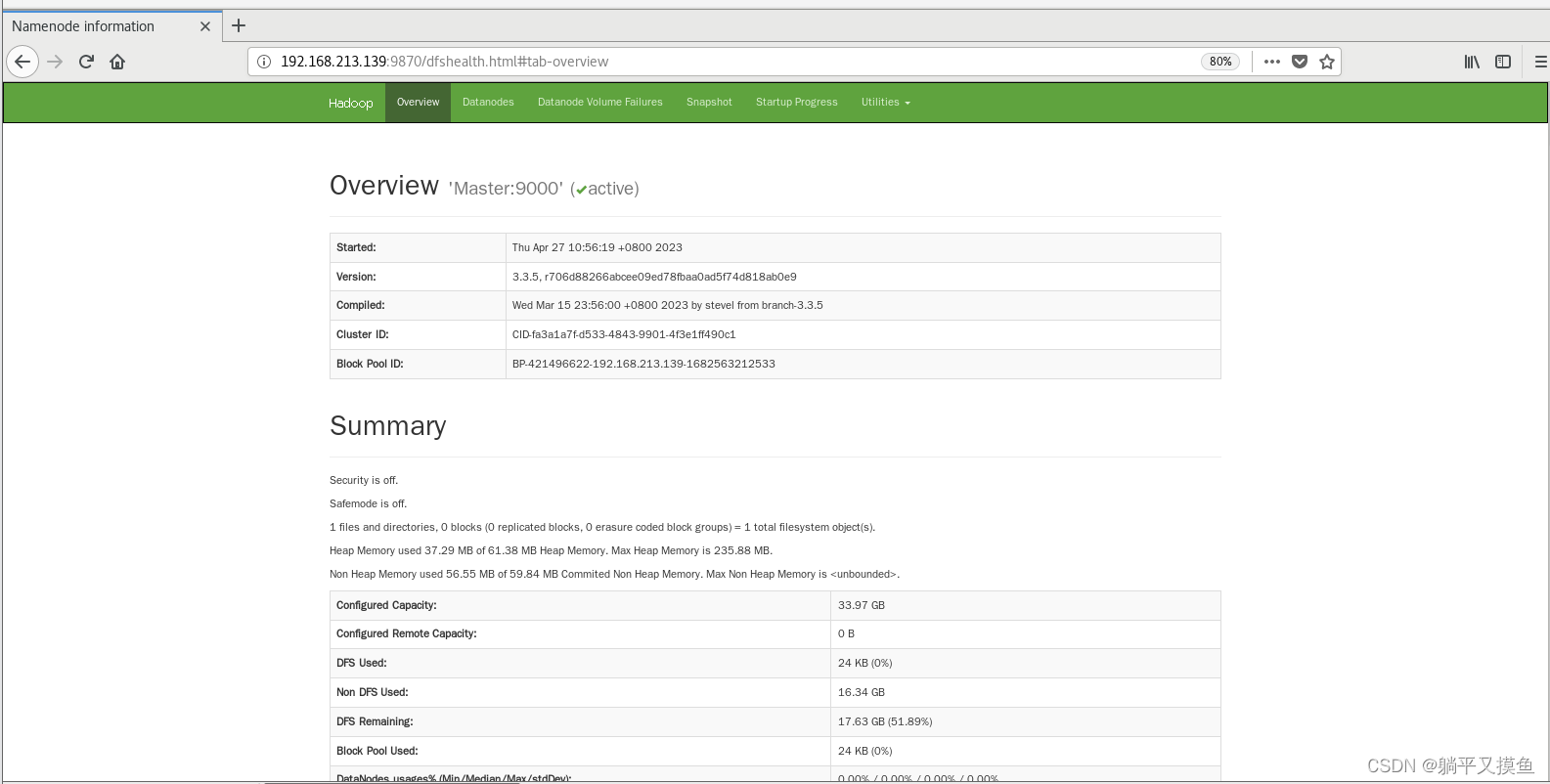
**也可以通过 Web 页面看到查看 DataNode 和 NameNode 的状态:http://主节点IP地址:9870 **如果不成功,可以通过启动日志排查原因。
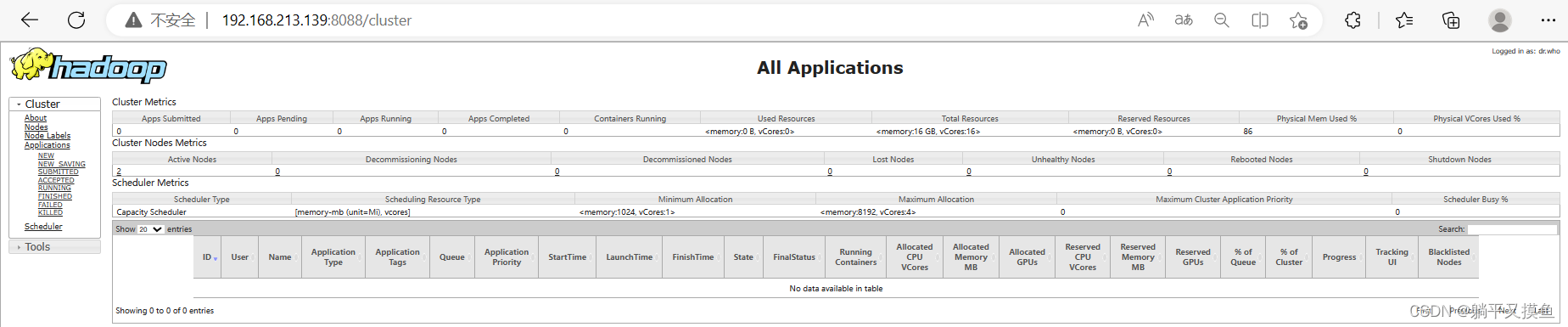
** 在本地浏览器里访问如下地址:可以通过 ****http://主节点IP地址:808//cluster **自动跳转到cluster页面
** 如果要关闭hadoop,执行以下命令:(三节点执行)**
stop-dfs.sh
stop-yarn.sh
#或
stop-all.sh
版权归原作者 躺平又摸鱼 所有, 如有侵权,请联系我们删除。