
1. 讲⼀下Flink的运⾏架构
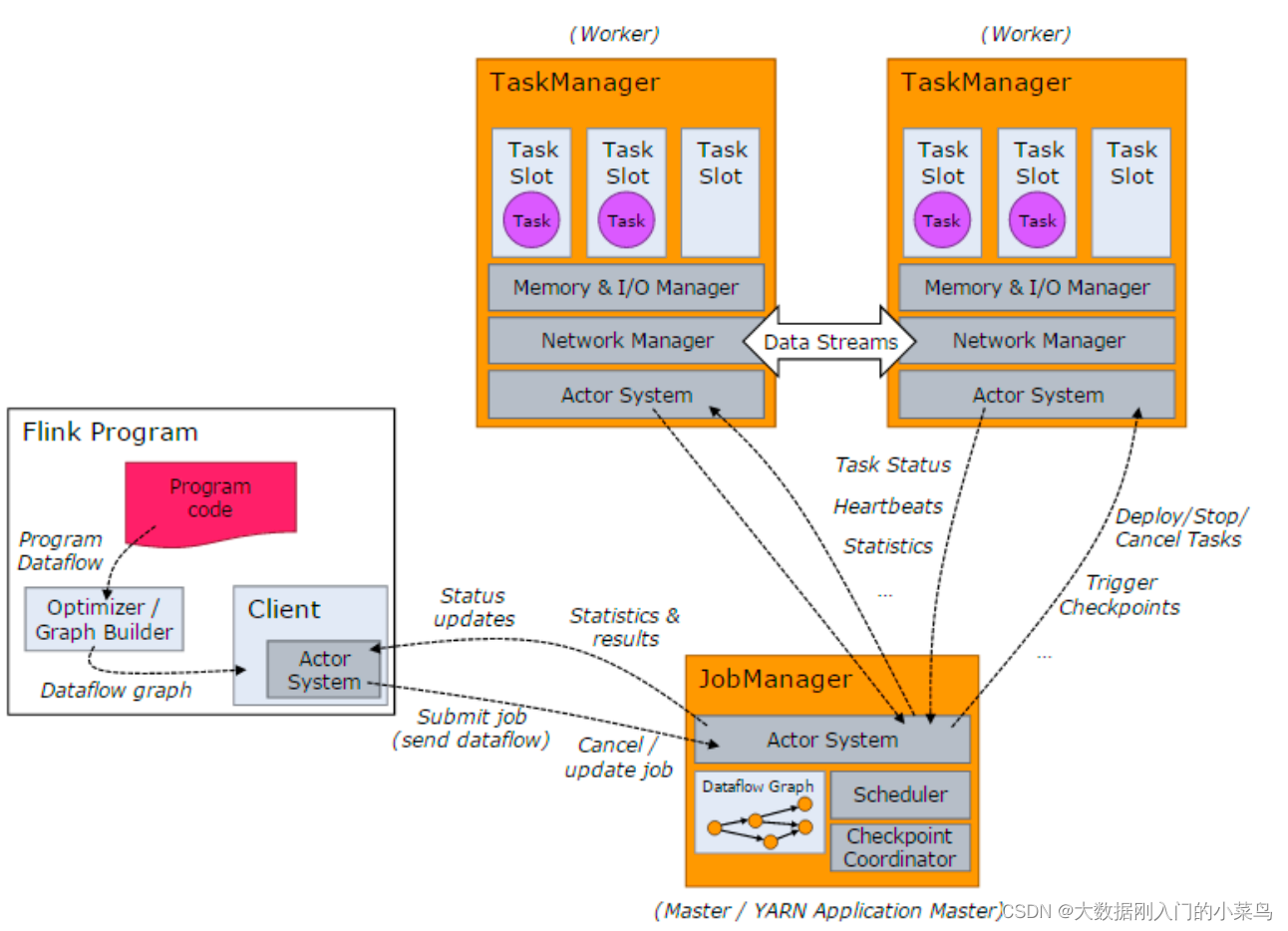
当 Flink 集群启动后,⾸先会启动⼀个 JobManger 和⼀个或多个的 TaskManager。由 Client 提交任务给
1、JobManager,JobManager 再调度任务到各个 TaskManager 去执⾏,然后 TaskManager 将⼼跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进⾏数据的传输。上述三者均为独⽴的 JVM 进程。
1.1、Client 为提交 Job 的客户端,可以是运⾏在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming的任务),也可以不结束并等待结果返回。
1.2 、JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,职责上很像 Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包等资源后,会⽣成优化后的执⾏计划,并以 Task 的单元调度到各个 TaskManager 去执⾏。
1.3、TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动⼀个 Task,Task 为线程。从JobManager 处接收需要部署的 Task,部署启动后,与⾃⼰的上游建⽴ Netty 连接,接收数据并处理。
2. 讲⼀下Flink的作业执⾏流程
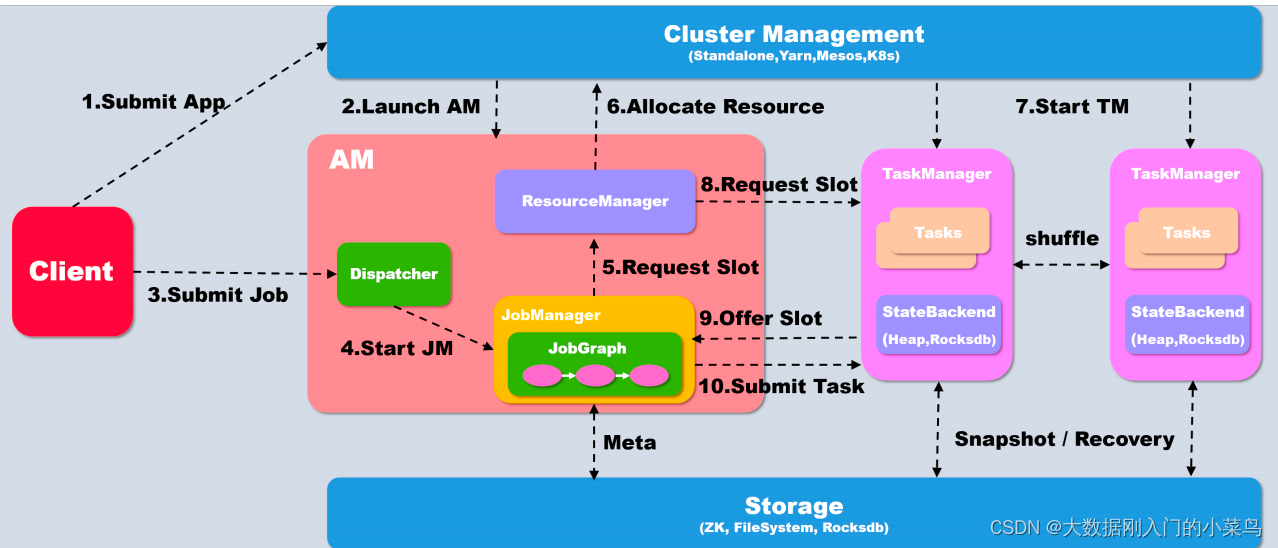
以yarn模式Per-job⽅式为例概述作业提交执⾏流程
- 当执⾏executor() 之后,会⾸先在本地client 中将代码转化为可以提交的 JobGraph 如果提交为Per-Job模式,则⾸先需要启动AM, client会⾸先向资源系统申请资源, 在yarn下即为申请container 开启AM, 如果是Session模式的话则不需要这个步骤
- Yarn分配资源, 开启AM
- Client将Job提交给Dispatcher
- Dispatcher 会开启⼀个新的 JobManager线程
- JM 向Flink ⾃⼰的 Resourcemanager申请slot资源来执⾏任务
- RM 向 Yarn申请资源来启动 TaskManger (Session模式跳过此步)
- Yarn 分配 Container 来启动 taskManger (Session模式跳过此步)
- Flink 的 RM 向 TM 申请 slot资源来启动 task
- TM 将待分配的 slot 提供给 JM
- JM 提交 task, TM 会启动新的线程来执⾏任务,开始启动后就可以通过 shuffle模块进⾏ task之间的数据交换
3. Flink的部署模式都有哪些
flink可以以多种⽅式部署,包括standlone模式/yarn/Mesos/Kubernetes/Docker/AWS/Google Compute
Engine/MAPR等
⼀般公司中主要采⽤ on yarn模式
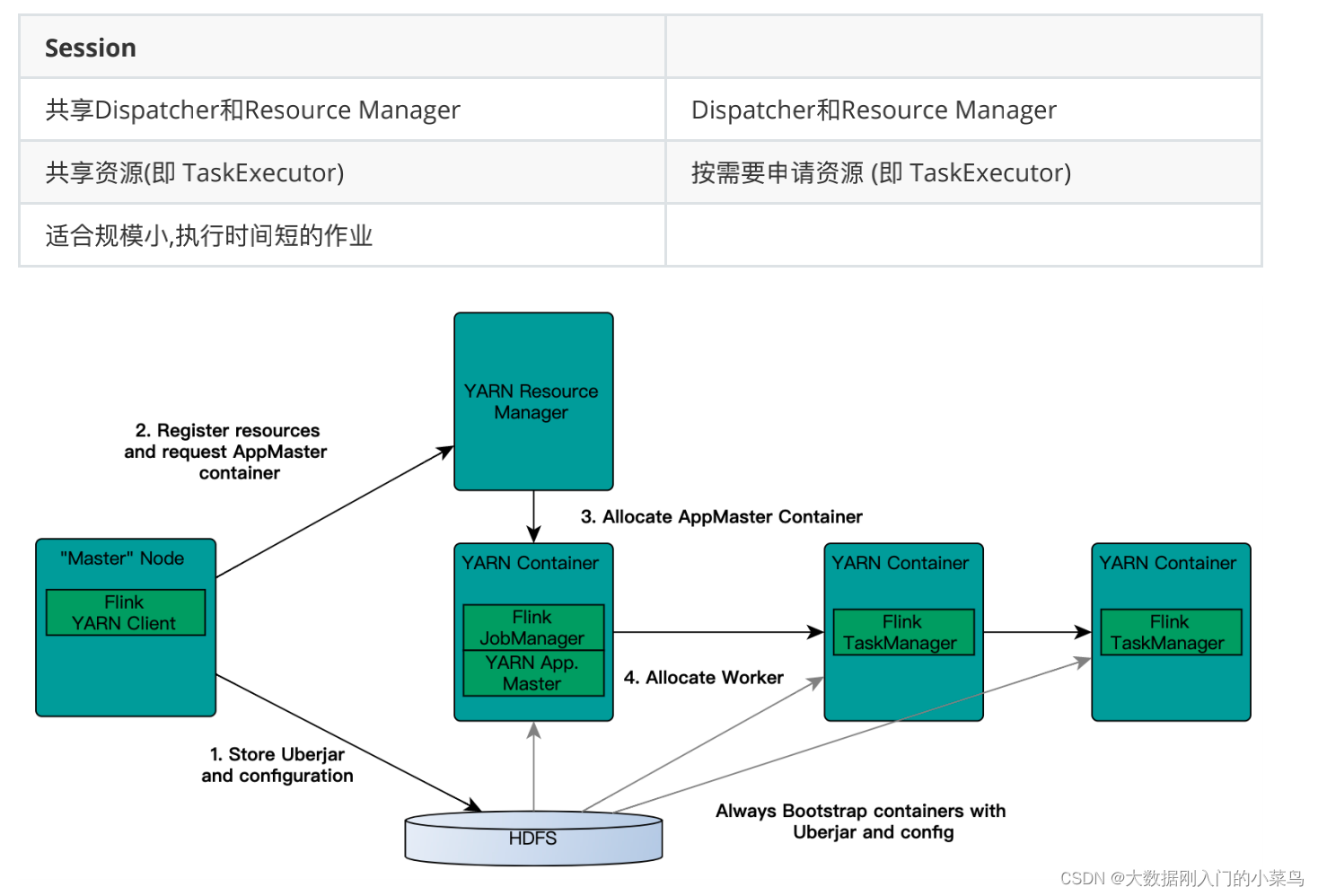
4. 讲⼀下Flink on yarn的部署
Flink作业提交有两种类型:
5. Flink 的 state 是存储在哪⾥的

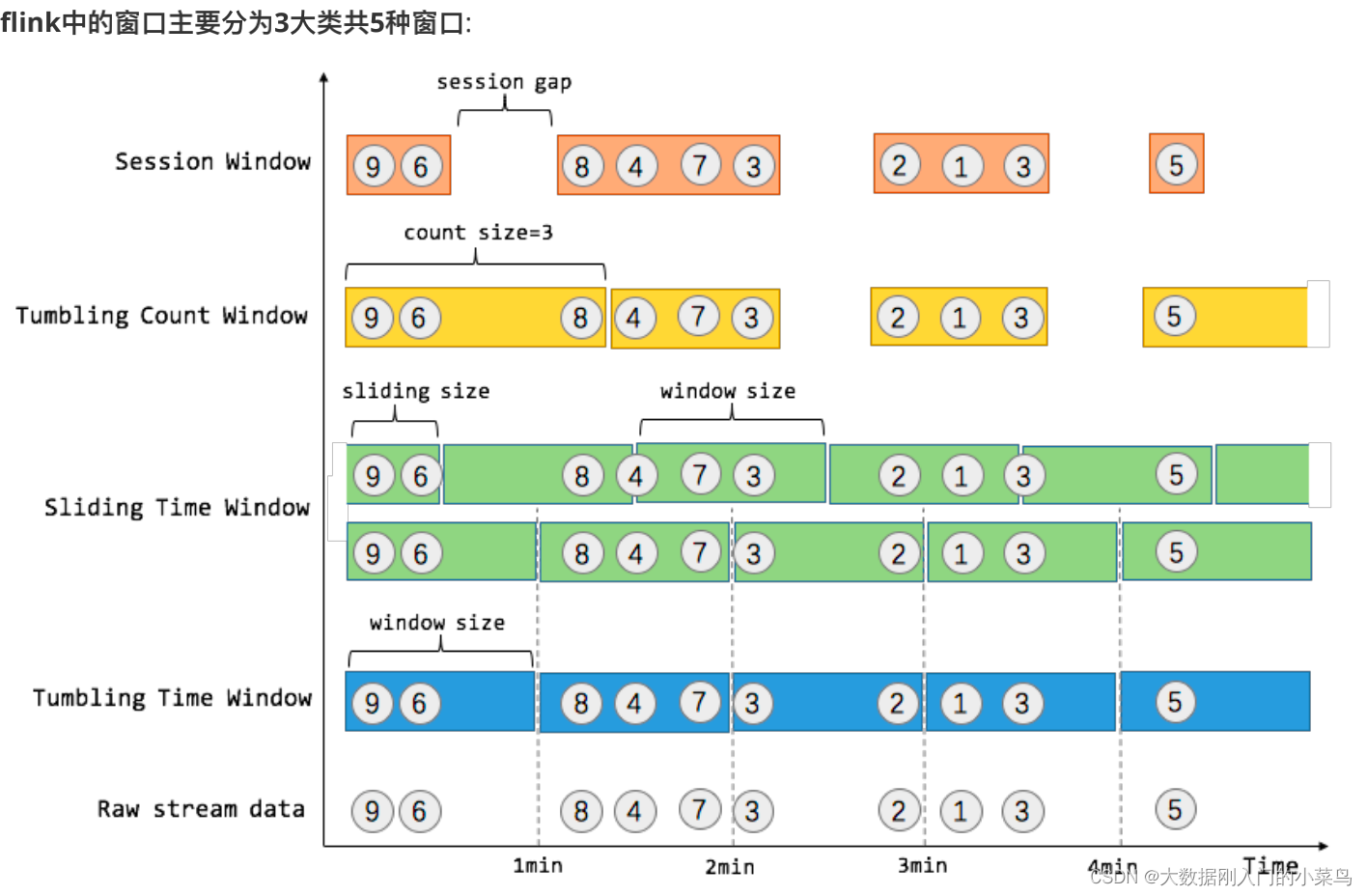
6. Flink 的 window 分类


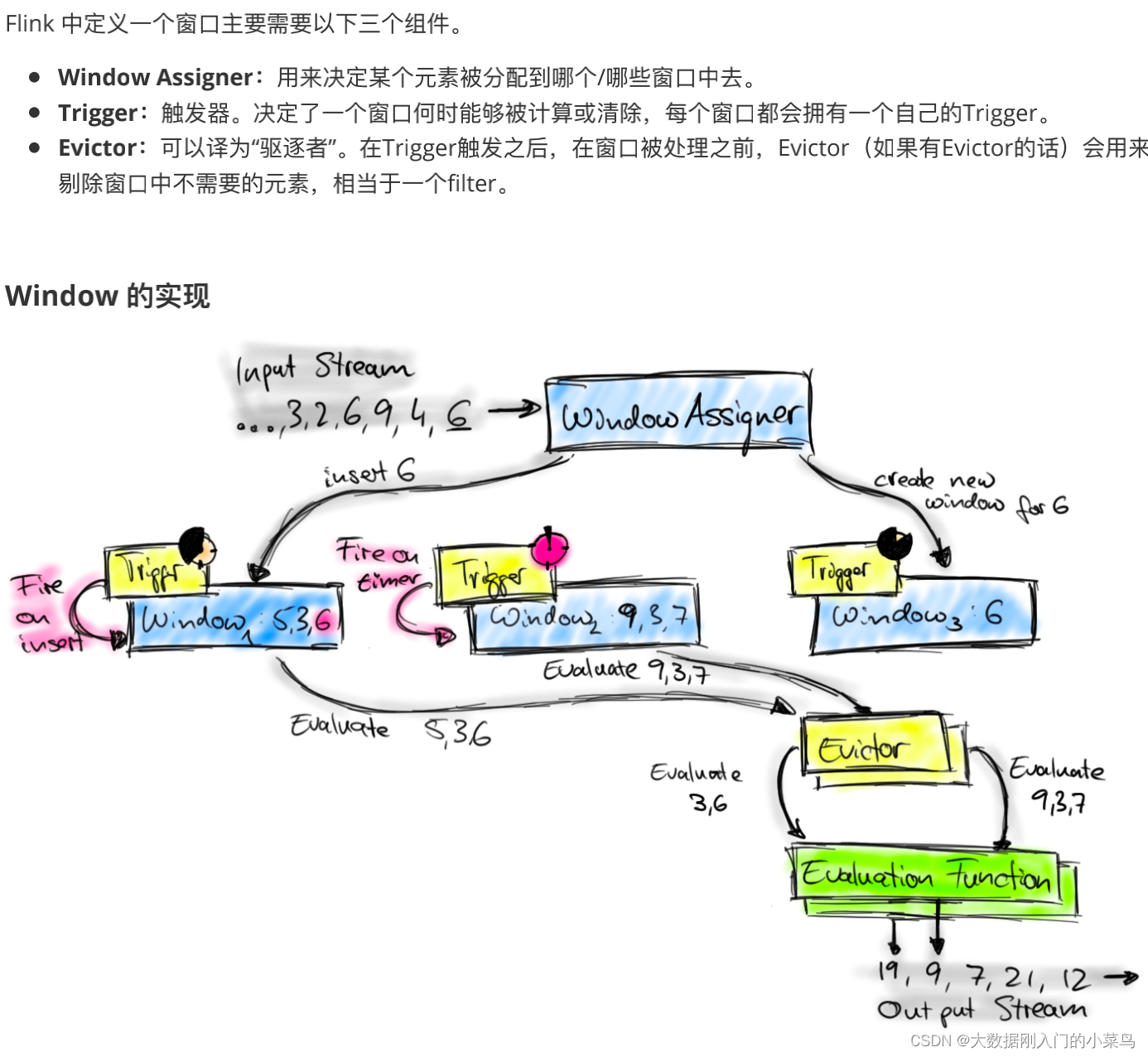
7. Flink 的 window 实现机制


8. Flink具体是如何实现exactly once 语义



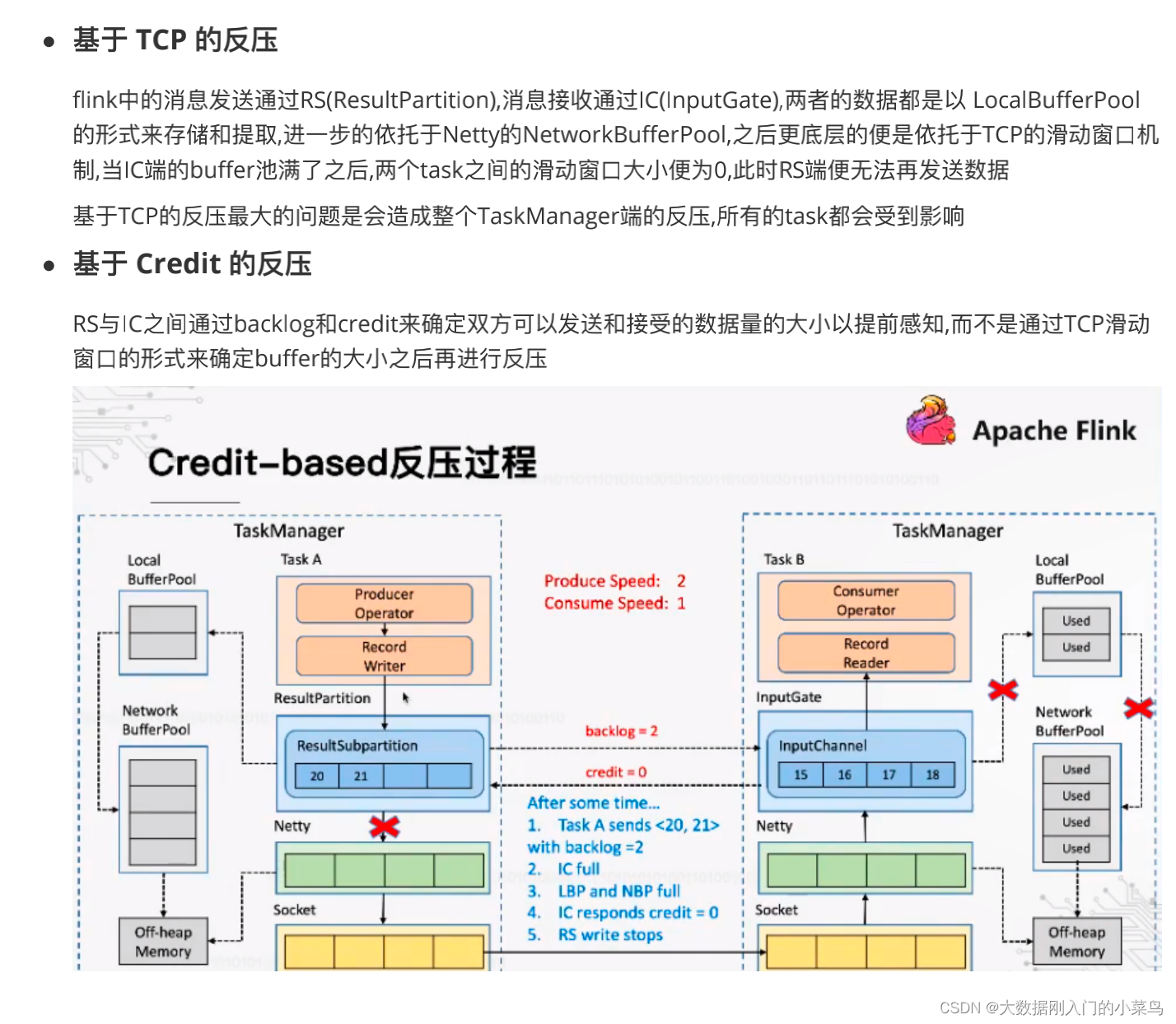
9. flink是如何实现反压的

10. flink中的时间概念 , eventTime 和 processTime的区别


本文转载自: https://blog.csdn.net/weixin_46580067/article/details/125276037
版权归原作者 大数据刚入门的小菜鸟 所有, 如有侵权,请联系我们删除。
版权归原作者 大数据刚入门的小菜鸟 所有, 如有侵权,请联系我们删除。