
前言
最近报名参加了腾讯大型开源项目Finops Crane的集训营,深入了解并实践运用了关于Crane的一系列功能。云计算以及云平台是未来服务部署的主流趋势,可以在成本条件限制下极大节省运行部署成本。因此关于云计算平台的一系列计算我都十分感兴趣,而Crane能够在云原生发展火热的状态下作为大型开源项目,提供学习渠道以及实践,是一件十分有意义的事情。本篇文章将带大家了解Crane以及了解Crane能够帮助我们在哪些业务场景下解决困难,以及我们该如何使用Crane和部署服务。
一、Crane目的是什么?
Finops Crane的发布并不算早,很多开发者对于Finops Crane的了解少之甚少,但是对于现今比较火热的云原生了解颇多,比如Kubernetes、Prometheus等。我们知道, Kubernetes是Google公司在2014年6月开源的一个容器集群管理系统,Kubernetes的目标是让部署容器化的应用简单并且高效。既然能够实现高效快捷的功能,无疑Kubernetes是一个复杂的平台,它需要多个部分组合才能工作。但是与其他复杂平台相比,Kubernetes在将其各个部分集成到一个易于管理的整体方面这点是有缺陷的。而且绝大多数的用户Kubernetes集群资源利用率并不高,浪费严重。作为开发人员,使用云原生的计算就是想要利用其强大的调度和弹性解决资源浪费问题,但是当我们接触到云原生业务资源分配的时候,发现还是使用传统的压测手工来制定策略。
通俗的来讲,我们现在就要解决一个优化问题:如何提升平台资源利用率的 KPI?
当然提出该问题的开发人员也并不是只有我,其他大牛肯定也有想到这个问题。解决方案已经有了以下几条:
- Kubernetes自动扩容能力
- Serverless 技术
- Autopilot
但是经过技术调研发现真正使用了HPA,从负载上升触发阈值,到弹性控制器开始扩容,到应用启动完成,可能有数分钟甚至数十分钟的滞后,在弹性起作用之前,应用已经被压垮。
Serverless 技术仅仅为概念,缺少服务器基础限制,底层自主可控和性能优化能力完全丧失。
谷歌 Autopilot 集群为首的资源托管类集群是需要付费的。
技术调研到这块我们似乎已经无从下手,只能从源码开始解析重构一个监管分析平台吗?这显然将耗费大量的时间和人力。那么其实讲到这里,Crane项目的诞生就已经呼之欲出了。没错,Crane 就是一个基于 FinOps 的云资源分析与成本优化平台。它的愿景是在保证客户应用运行质量的前提下实现极致的降本。既然有相应的开发目的,那么我们就已经了解Crane将来需要干什么事。
二、Crane有哪些功能?
我们现在知道了Crane要解决的业务场景难题,那么Crane又有哪些功能呢?首先我们要了解FinOps 标准。

对于 FinOps 的重要性,谷歌将其总结为以下5个方面:
- 减速商业价值的实现及业务翻新
- 推动财务问责制和可见性
- 优化云的应用和老本效率
- 为跨组织的信赖及合作赋能
- 避免云计算收入的失控
那么根据FinOps的标准,Crane提供了对应以下功能:
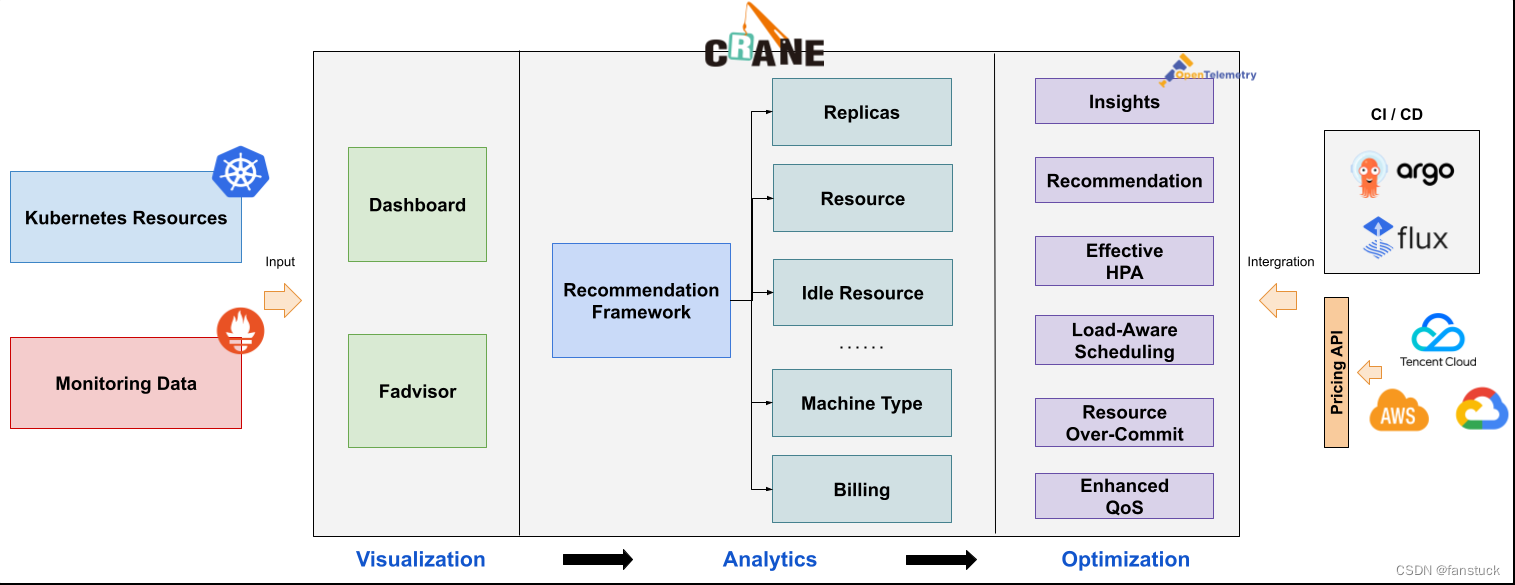
1.成本可视化和优化评估
- 提供一组 Exporter 计算集群云资源的计费和账单数据并存储到你的监控系统,比如 Prometheus。
- 多维度的成本洞察,优化评估。通过
Cloud Provider支持多云计费。

- 当月总成本:过去一个月集群总成本。从安装Crane时间开始,按小时累加集群成本
- 预估每月成本:以最近一小时成本估算未来一个月的成本。每小时成本 * 24 * 30
- 预估CPU总成本:以最近一小时CPU成本估算未来一个月的CPU成本。每小时CPU成本 * 24 * 30
- 预估Memory总成本:以最近一小时Memory成本估算未来一个月的Memory成本。每小时Memory成本 * 24 * 30
2.推荐框架
Crane提供了一个可扩展的推荐框架以支持多种云资源的分析,内置了多种推荐器:资源推荐,副本推荐,HPA 推荐,闲置资源推荐。

3.基于预测的水平弹性器
EffectiveHorizontalPodAutoscaler 支持了预测驱动的弹性。它基于社区 HPA 做底层的弹性控制,支持更丰富的弹性触发策略(预测,观测,周期),让弹性更加高效,并保障了服务的质量。
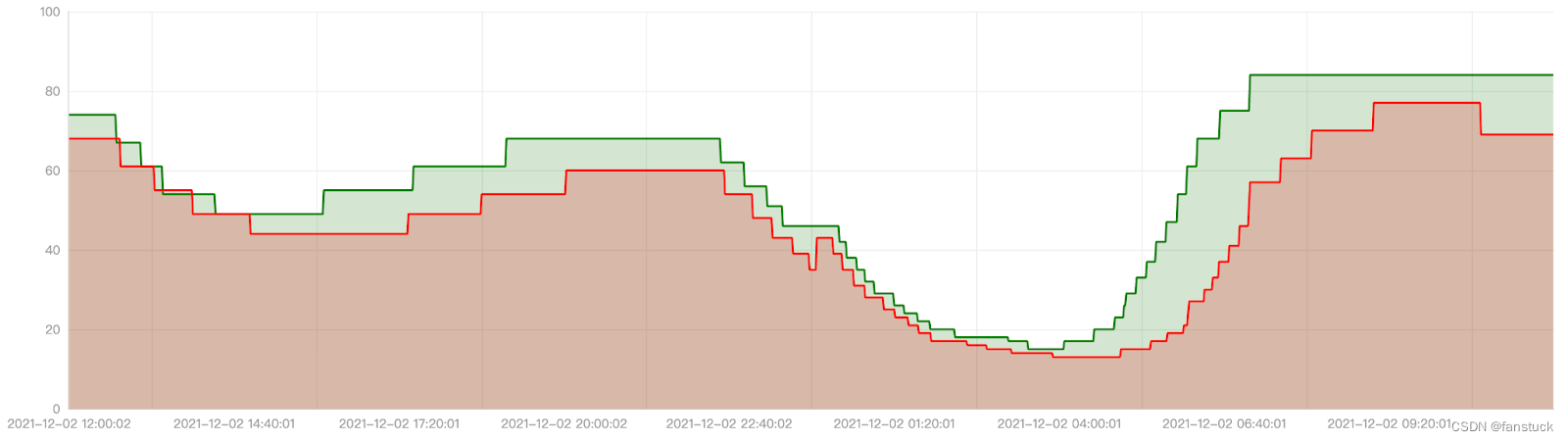
4.负载感知的调度器
Crane的动态调度器根据实际的节点利用率构建了一个简单但高效的模型,并过滤掉那些负载高的节点来平衡集群。
5.拓扑感知的调度器
Crane Scheduler与Crane Agent配合工作,支持更为精细化的资源拓扑感知调度和多种绑核策略,可解决复杂场景下“吵闹的邻居问题",使得资源得到更合理高效的利用。
6.基于 QOS 的混部
QOS相关能力保证了运行在 Kubernetes 上的 Pod 的稳定性。具有多维指标条件下的干扰检测和主动回避能力,支持精确操作和自定义指标接入;具有预测算法增强的弹性资源超卖能力,复用和限制集群内的空闲资源;具备增强的旁路cpuset管理能力,在绑核的同时提升资源利用效率。
三.Crane的整体架构及特性
在我们了解了Crane能够做哪些事情之后,深入理解Crane的功能实现还需要了解Crane项目的整体架构,了解Crane运作的机制,对于以后我们想要修改或者是提取部分功能有很大的作用。
1.Crane架构
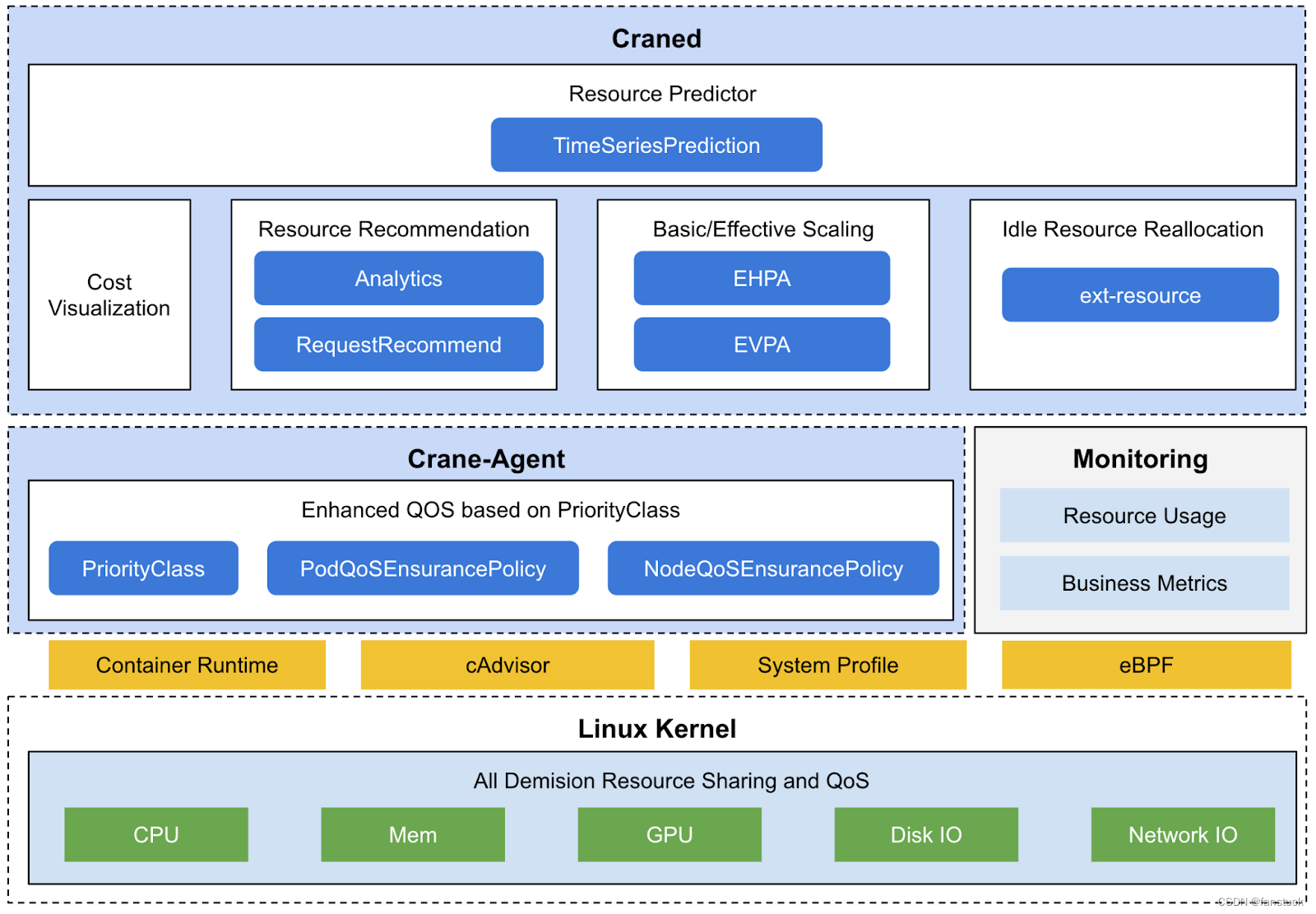
Craned
Craned 是 Crane 的最核心组件,它管理了 CRDs 的生命周期以及API。Craned 通过
Deployment
方式部署且由两个容器组成。
Fadvisor
Fadvisor 提供一组 Exporter 计算集群云资源的计费和账单数据并存储到你的监控系统,比如 Prometheus。
Metric Adapter
Metric Adapter 实现了一个
Custom Metric Apiserver
. Metric Adapter 读取 CRDs 信息并提供基于
Custom/External Metric API
的 HPA Metric 的数据。
Crane Agent
Crane Agent 通过
DaemonSet
部署在集群的节点上。
2.Crane特性
Crane 致力于推荐资源和智能弹性配置,业务人员无需再为业务需要多少资源,自动扩缩容应该如何配置等问题而烦恼,Crane 会基于业务的时序变动数据给出最优解。
一键部署
Crane 保持平台独立,通过一个 Helm 包将 Crane 安装至任意 Kubernetes 集群,无论云上还是云下,即可享受一站式资源优化能力。Crane 侵入性小,核心组件包括集中控制器 craned 和节点代理 crane agent,你可以自由组合安装,通过 featureGate 选择开启哪些能力。
简单易用可视化控制台
为降低使用门槛,Crane 提供内置控制台,用户可基于控制台查看成本分配,成本走势,并通过鼠标点击实现成本优化。所有能力均提供灰度控制和预览模式,以及回滚的能力,以消除业务侧对资源变动的顾虑。
开箱即用的巡检能力
Crane 可以全局扫描整体浪费情况,将隐藏浪费可视化的呈现出来,使运维人员免除拉取监控数据,编写查询脚本等重复性工作。
优化方案包含对成本变化的展示,对利用率变化的展示,可能的风险点,甚至是优化建议的排序。因为我们相信,每个业务都是独一无二的,都有其最适合的优化方案,不能一概而论。
稳定性与资源优化的双重兼
Crane 对资源利用率的提升,绝不是以牺牲稳定性作为代价。Crane 允许用户对业务进行定级,节点代理负责周期性检查节点资源水位和系统指标,识别应用干扰,并通过调度禁止,调整 cgroup,驱逐等多种手段确保敏感业务服务等级不受损。
四、Crane部署
了解到了Crane的各种功能以及特性,那么部署Crane是否会很麻烦呢,这点我动手尝试过,是比较简单部署的。首先我们需要安装Crane一系列的依赖:
- kubectl:安装工具 | Kubernetes
- Helm:Helm | 安装Helm
- kind:kind – Quick Start
- Docker:Get Docker | Docker Documentation
有curl工具的可通过指令下载:
curl -sf https://raw.githubusercontent.com/gocrane/crane/main/hack/local-env-setup.sh | sh -
或者直接前往github上面clone下来:GitHub - gocrane/crane: Crane is a FinOps Platform for Cloud Resource Analytics and Economics in Kubernetes clusters. The goal is not only to help users to manage cloud cost easier but also ensure the quality of applications.
之后运行检测pod是否启动:
export KUBECONFIG=${HOME}/.kube/config_crane
kubectl get deploy -n crane-system
NAME READY STATUS RESTARTS AGE
crane-agent-5r9l2 1/1 Running 0 4m40s
craned-6dcc5c569f-vnfsf 2/2 Running 0 4m41s
fadvisor-5b685f4cd6-xpxzq 1/1 Running 0 4m37s
grafana-64656f6d54-6l24j 1/1 Running 0 4m46s
metric-adapter-967c6d57f-swhfv 1/1 Running 0 4m41s
prometheus-kube-state-metrics-7f9d78cffc-p8l7c 1/1 Running 0 4m46s
prometheus-node-exporter-4wk8b 1/1 Running 0 4m40s
prometheus-server-fb944f4b7-4qqlv 2/2 Running 0 4m46s
Pod
的启动需要一定的时间等几分钟后输入命令查看后集群状态是否都
Running
kubectl get pod -n crane-system
访问 Crane Dashboard
kubectl -n crane-system port-forward service/craned 9090:9090
添加本地集群:
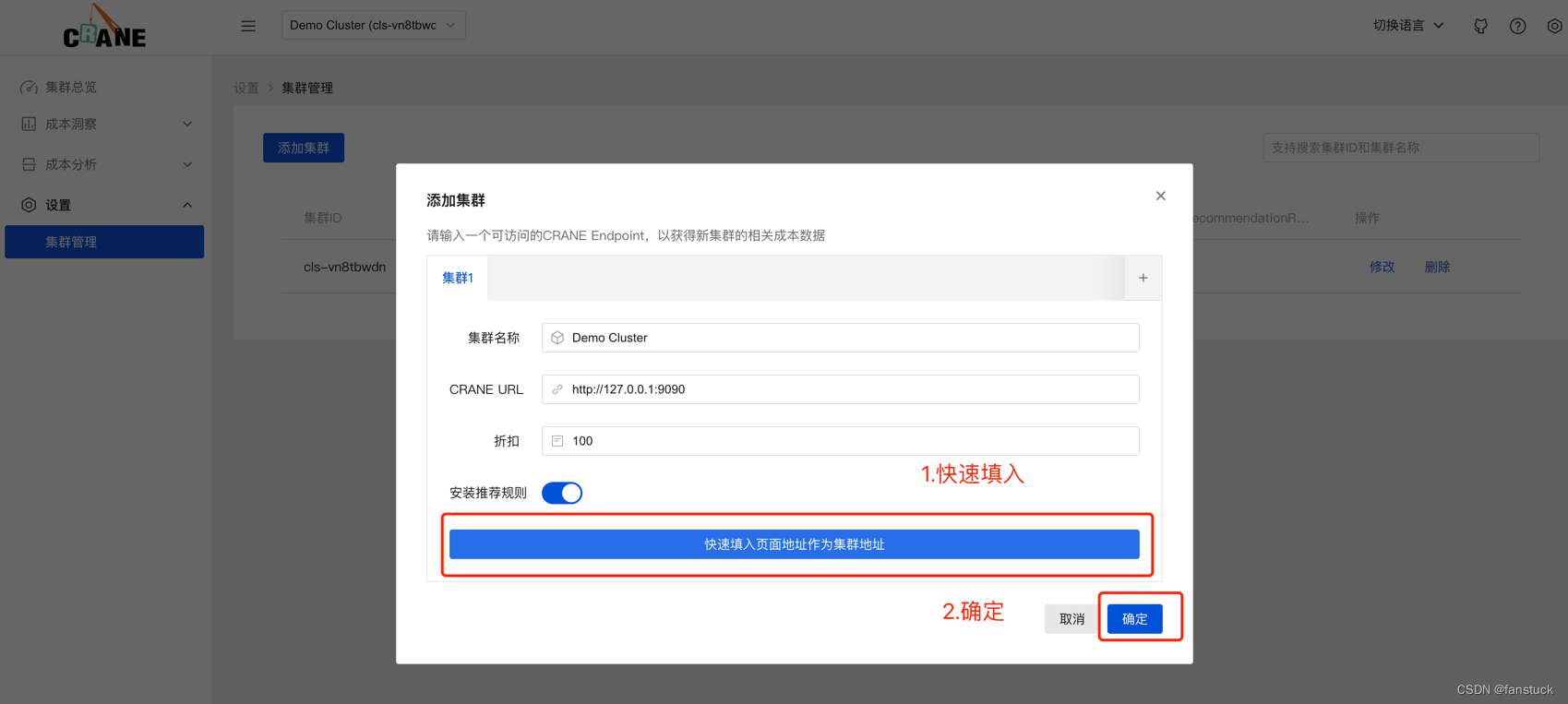
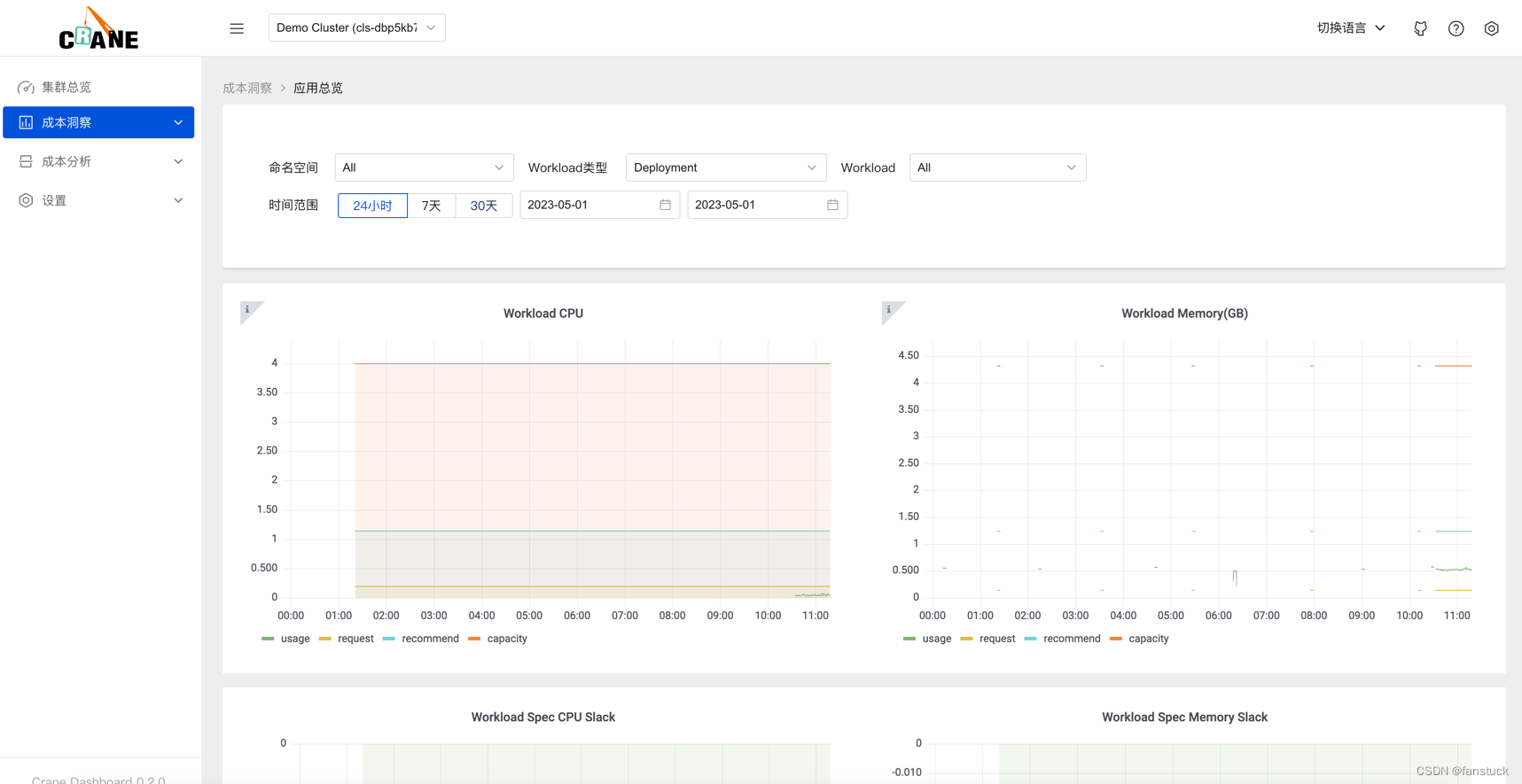
成本展示
Crane Dashboard 提供了各式各样的图表展示了集群的成本和资源用量,
集群总览
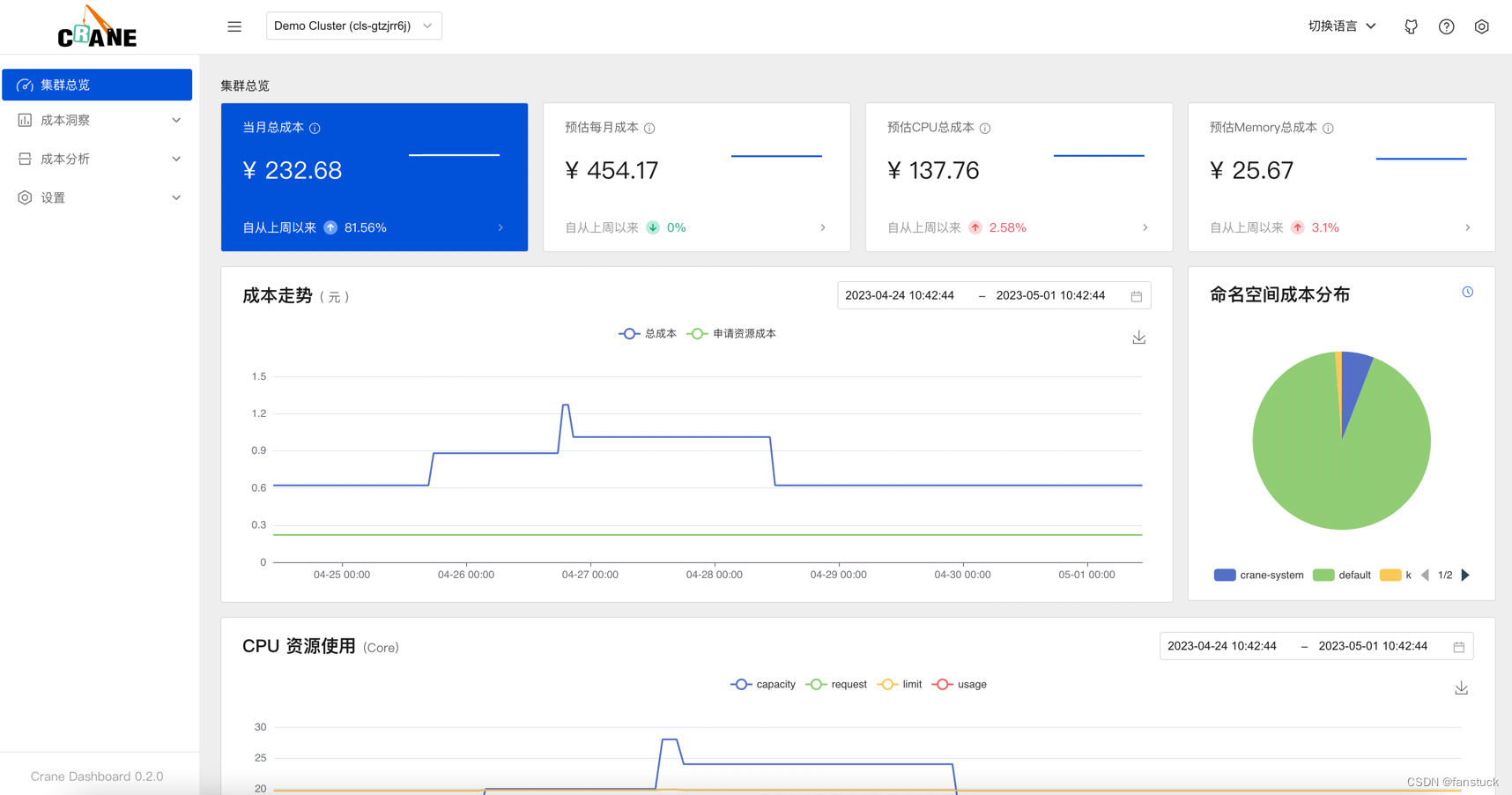
成本洞察->集群总览
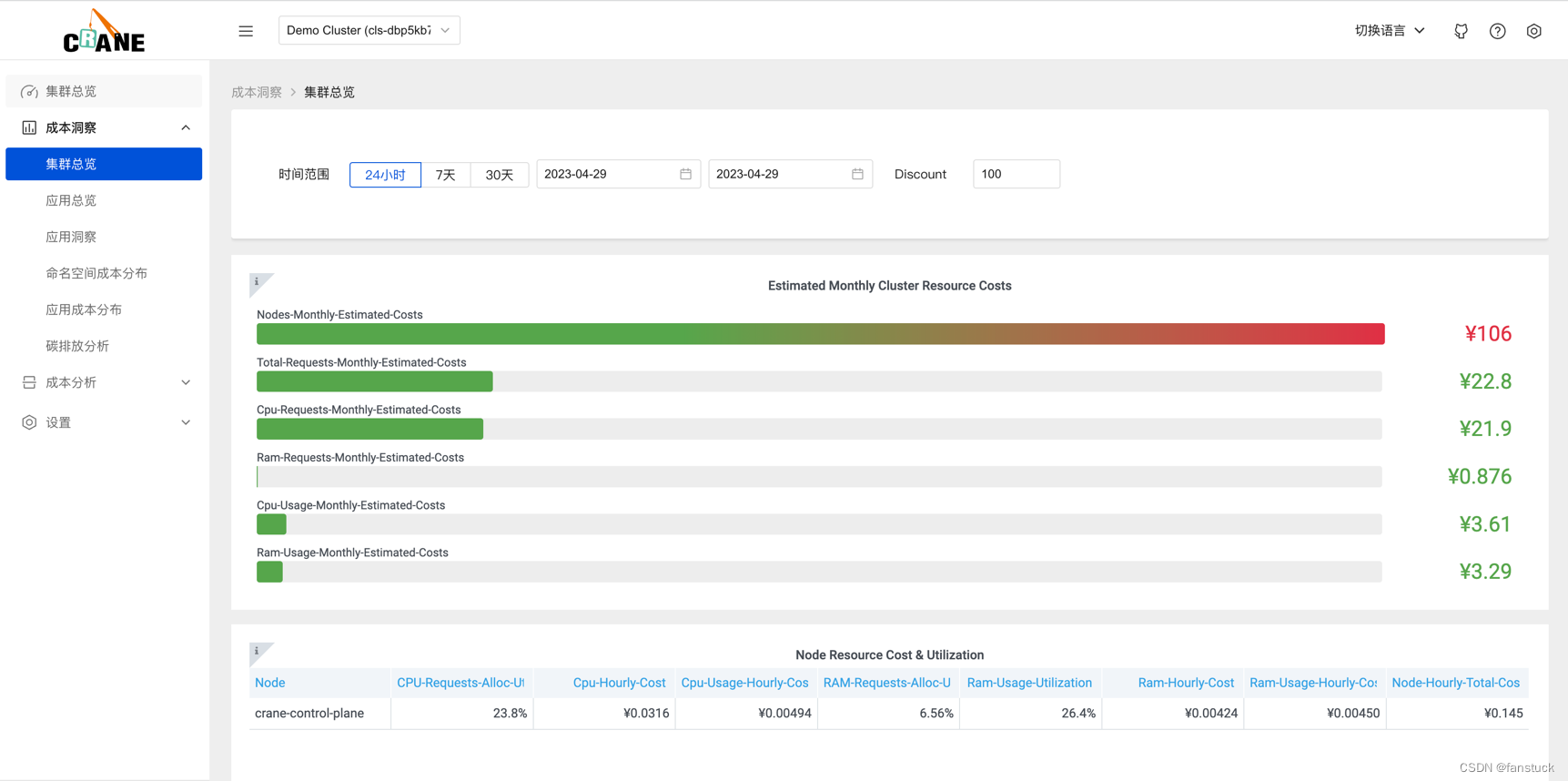
成本洞察->集群总览
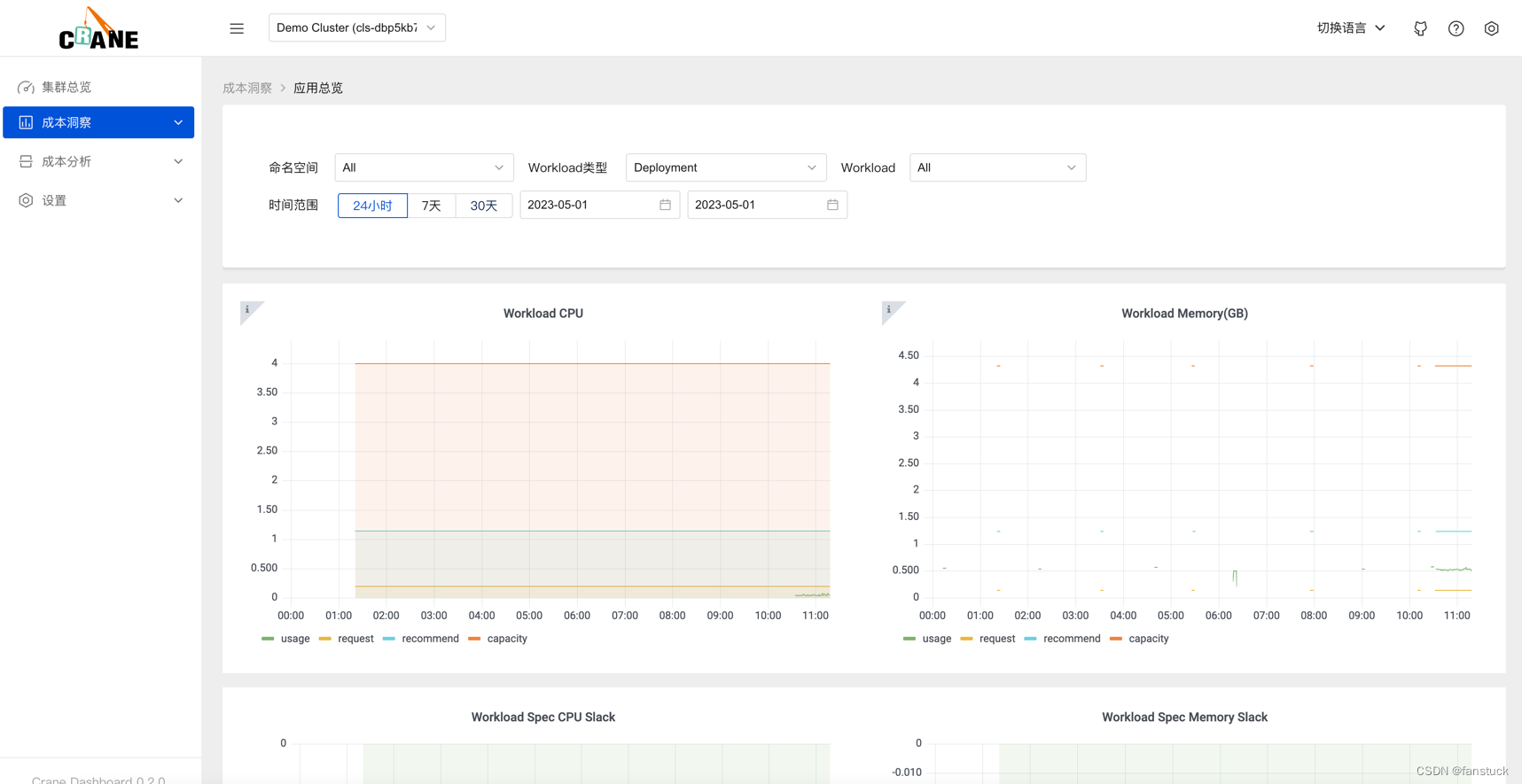
更多的成本分析图表可以通过登陆 Grafana 的页面或者分析源码研究。
优化你的应用配置
在 dashboard 中开箱后就可以看到相关的成本数据,是因为在添加集群的时候我们安装了推荐的规则。
推荐框架会自动分析集群的各种资源的运行情况并给出优化建议。Crane 的推荐模块会定期检测发现集群资源配置的问题,并给出优化建议。智能推荐提供了多种 Recommender 来实现面向不同资源的优化推荐。
在
成本分析>推荐规则
页面可以看到我们安装的两个推荐规则。

在 dashboard 的
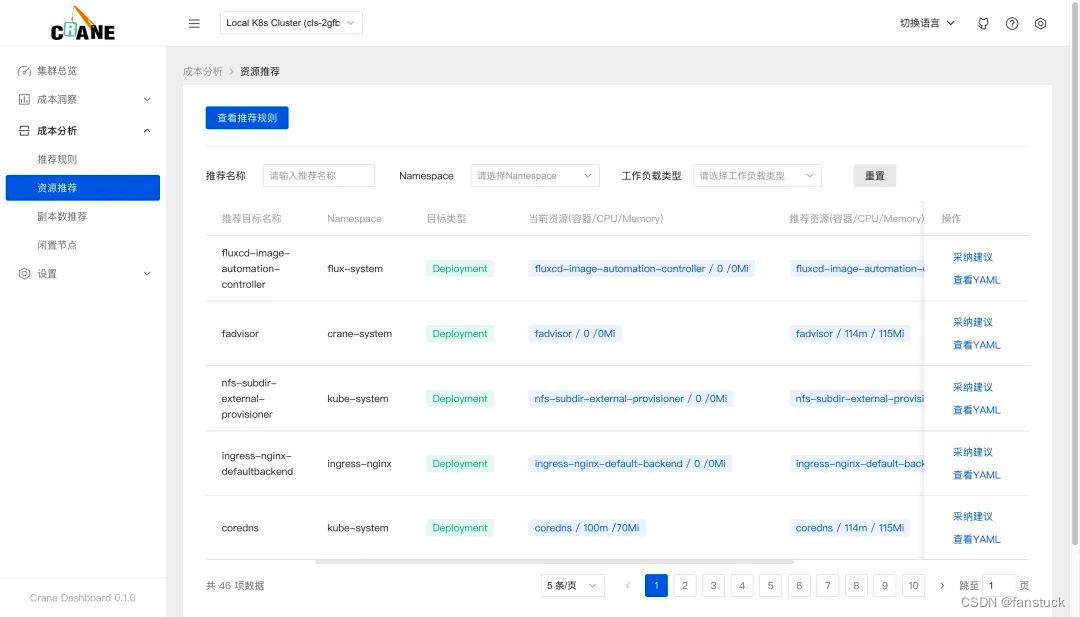
资源推荐
页面也能查看到优化建议列表。
通过
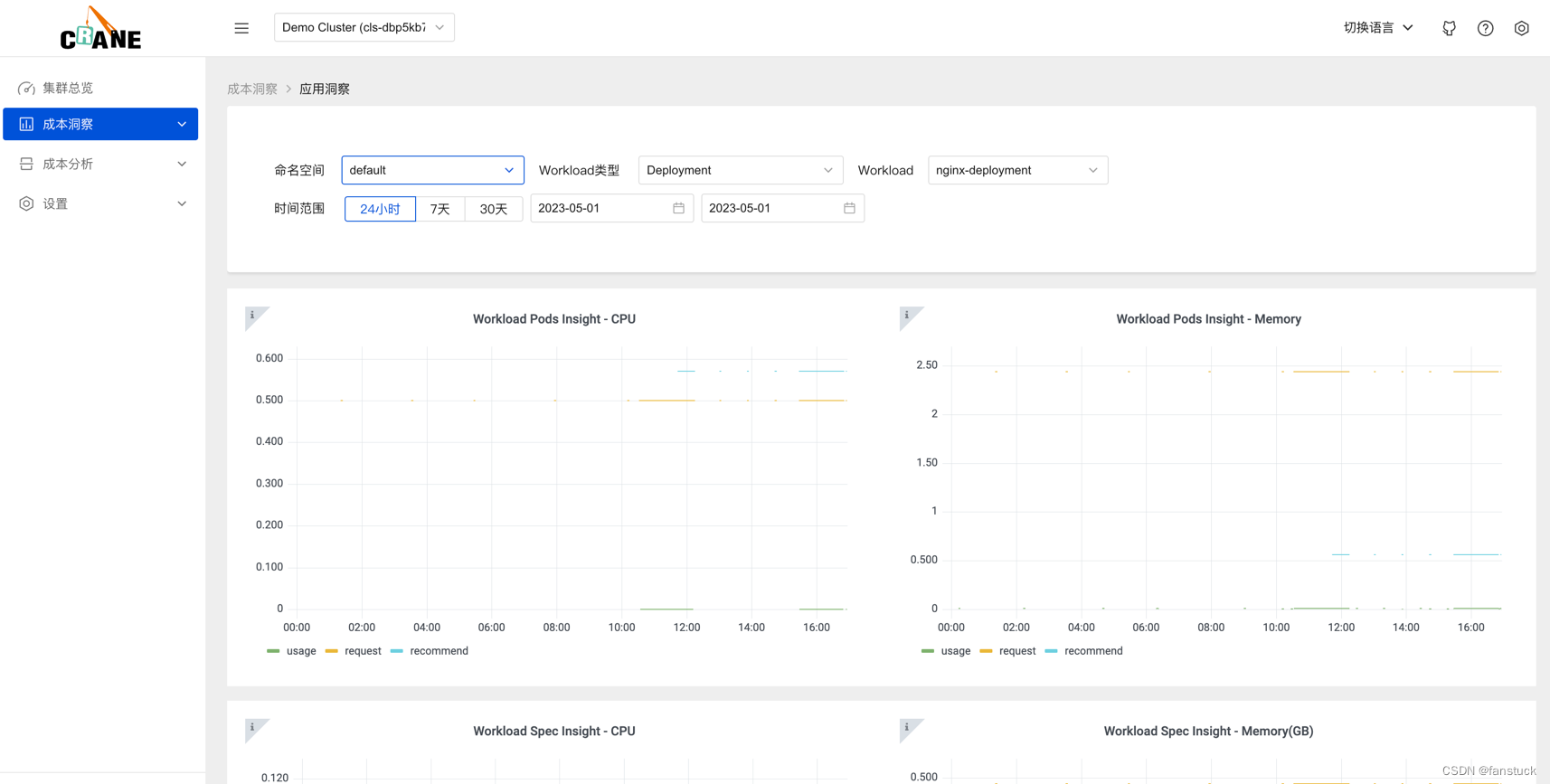
查看监控
查看详细的监控数据。
在页面中可以看到当前资源(容器/CPU/Memory)与推荐的资源数据,点击采纳建议即可获取优化的执行命令。
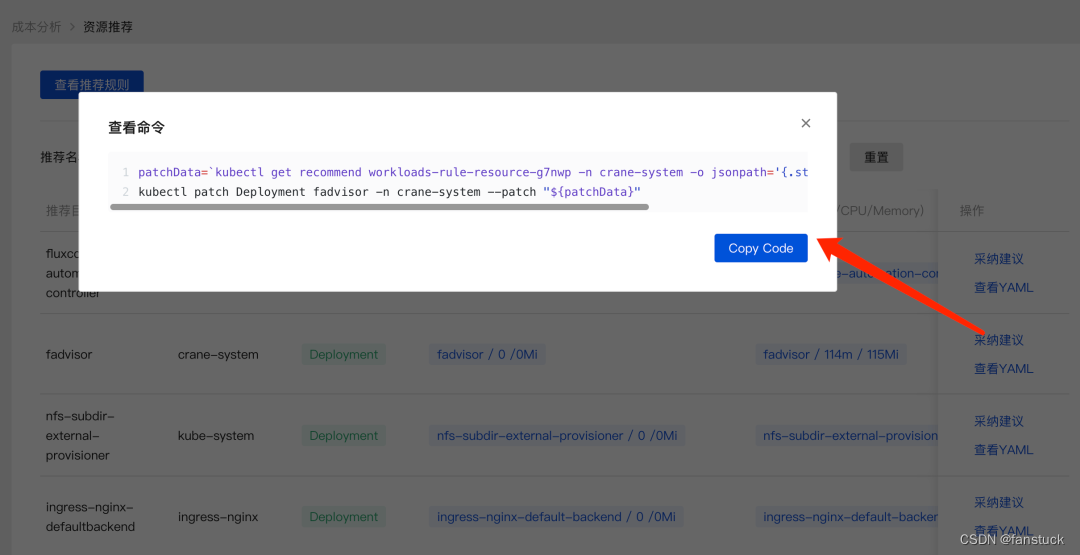
总而言之,Crane是一个超强大云资源分析与成本优化平台。
五、总结
总体体验下来,Crane无愧之为开源的超强大云资源分析与成本优化平台,无疑是解决集群资源利用率问题的高效解决方案。而且Crane部署简便,无需很繁琐的部署过程,且有着强大的云资源监控能力,能够自动化资源调度和分配,且能够智能帮助用户优化资源使用和降低成本。
尤其是配备许多可视化显示大屏,很够作为二次开发嵌套到其他大屏展示网页上。能够很直观的帮助开发运维人员找到闲置资源。
以下是个人的一些优化建议:
- 更加自由的可拓展性,一些可自定义的API集成到Dashboard中,可加入大数据监控以及数据流监控等。
- 完善开源Crane社区用户交流平台,使得更多开发者能够接触到Crane项目并且提出更多建设性的建议。
版权归原作者 fanstuck 所有, 如有侵权,请联系我们删除。