
Flink API
总共分为
4
层这里主要整理
Table API
的使用
Table API
是流处理和批处理通用的关系型
API
,
Table API
可以基于流输入或者批输入来运行而不需要进行任何修改。
Table API
是
SQL
语言的超集并专门为
Apache Flink
设计的,
Table API
是
Scala
和
Java
语言集成式的
API
。与常规
SQL
语言中将查询指定为字符串不同,
Table API
查询是以
Java
或
Scala
中的语言嵌入样式来定义的,具有
IDE
支持如:自动完成和语法检测。需要引入的
pom
依赖如下:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table_2.12</artifactId><version>1.7.2</version></dependency>
Table API & SQL
TableAPI:
WordCount
案例
tab.groupBy("word").select("word,count(1) as count")
SQL:
WordCount
案例
SELECT word,COUNT(*)AS cnt FROM MyTable GROUPBY word
【1】声明式: 用户只关系做什么,不用关心怎么做;
【2】高性能: 支持查询优化,可以获取更好的执行性能,因为它的底层有一个优化器,跟
SQL
底层有优化器是一样的。
【3】流批统一: 相同的统计逻辑,即可以流模型运行,也可以批模式运行;
【4】标准稳定: 语义遵循
SQL
标准,不易改动。当升级等底层修改,不用考虑
API
兼容问题;
【5】易理解: 语义明确,所见即所得;
Table API 特点
Table API
使得多声明的数据处理写起来比较容易。
1#例如,我们将a<10的数据过滤插入到xxx表中2 table.filter(a<10).insertInto("xxx")3#我们将a>10的数据过滤插入到yyy表中4 table.filter(a>10).insertInto("yyy")
Talbe
是
Flink
自身的一种
API
使得更容易扩展标准的
SQL
(当且仅当需要的时候),两者的关系如下: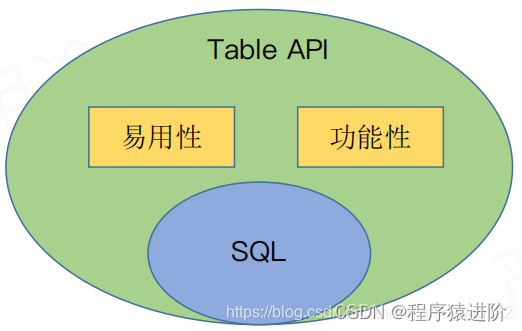
Table API 编程
WordCount
编程示例
packageorg.apache.flink.table.api.example.stream;importorg.apache.flink.api.common.typeinfo.Types;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.table.api.Table;importorg.apache.flink.table.api.TableEnvironment;importorg.apache.flink.table.api.java.StreamTableEnvironment;importorg.apache.flink.table.descriptors.FileSystem;importorg.apache.flink.table.descriptors.OldCsv;importorg.apache.flink.table.descriptors.Schema;importorg.apache.flink.types.Row;publicclassJavaStreamWordCount{publicstaticvoidmain(String[] args)throwsException{//获取执行环境:CTRL + ALT + VStreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tEnv =TableEnvironment.getTableEnvironment(env);//指定一个路径String path =JavaStreamWordCount.class.getClassLoader().getResource("words.txt").getPath();//指定文件格式和分隔符,对应的Schema(架构)这里只有一列,类型是String
tEnv.connect(newFileSystem().path(path)).withFormat(newOldCsv().field("word",Types.STRING).lineDelimiter("\n")).withSchema(newSchema().field("word",Types.STRING)).inAppendMode().registerTableSource("fileSource");//将source注册到env中//通过 scan 拿到table,然后执行table的操作。Table result = tEnv.scan("fileSource").groupBy("word").select("word, count(1) as count");//将table输出
tEnv.toRetractStream(result,Row.class).print();//执行
env.execute();}}
怎么定义一个 Table
Table myTable = tableEnvironment.scan("myTable")
都是从
Environment
中
scan
出来的。而这个
myTable
又是我们注册进去的。问题就是有哪些方式可以注册
Table
。
【1】Table descriptor: 类似于上述的
WordCount
,指定一个文件系统
fs
,也可以是
kafka
等,还需要一些格式和
Schema
等。
tEnv.connect(new FileSystem().path(path)).withFormat(new OldCsv().field("word",Types.STRING).lineDelimiter("\n")).withSchema(new Schema().field("word",Types.STRING)).inAppendMode().registerTableSource("fileSource");//将source注册到env中
【2】自定义一个 Table source: 然后把自己的
Table source
注册进去。
TableSource csvSource =newCsvTableSource(path,newString[]{"word"},newTypeInformation[]{Types.STRING});
tEnv.registerTableSource("sourceTable2", csvSource);
【3】注册一个 DataStream: 例如下面一个
String
类型的
DataStream
,命名为
myTable3
对应的
schema
只有一列叫
word
。
DataStream<String> stream =...// register the DataStream as table " myTable3" with // fields "word"
tableEnv.registerDataStream("myTable3", stream,"word");
动态表
如果流中的数据类型是
case class
可以直接根据
case class
的结构生成
table
tableEnv.fromDataStream(ecommerceLogDstream)
或者根据字段顺序单独命名:用单引放到字段前面来标识字段名。
tableEnv.fromDataStream(ecommerceLogDstream,'mid,'uid ......)
最后的动态表可以转换为流进行输出,如果不是简单的插入就使用
toRetractStream
table.toAppendStream[(String,String)]
如何输出一个table
当我们获取到一个结构表的时候(
table
类型)执行
insertInto
目标表中:
resultTable.insertInto("TargetTable");
【1】Table descriptor: 类似于注入,最终使用Sink进行输出,例如如下输出到
targetTable
中,主要是最后一段的区别。
tEnv
.connect(new FileSystem().path(path)).withFormat(new OldCsv().field("word",Types.STRING).lineDelimiter("\n")).withSchema(new Schema().field("word",Types.STRING)).registerTableSink("targetTable");
【2】自定义一个 Table sink: 输出到自己的 sinkTable2注册进去。
TableSink csvSink =newCsvTableSink(path,newString[]{"word"},newTypeInformation[]{Types.STRING});
tEnv.registerTableSink("sinkTable2", csvSink);
【3】输出一个 DataStream: 例如下面产生一个
RetractStream
,对应要给
Tuple2
的联系。
Boolean
这行记录时
add
还是
delete
。如果使用了
groupby
,
table
转化为流的时候只能使用
toRetractStream
。得到的第一个
boolean
型字段标识
true
就是最新的数据(
Insert
),
false
表示过期老数据(
Delete
)。如果使用的
api
包括时间窗口,那么窗口的字段必须出现在
groupBy
中。
// emit the result table to a DataStreamDataStream<Tuple2<Boolean,Row>> stream = tableEnv.toRetractStream(resultTable,Row.class)
stream.filter(_._1).print()
案例代码:
packagecom.zzx.flinkimportjava.util.Propertiesimportcom.alibaba.fastjson.JSONimportorg.apache.flink.api.common.serialization.SimpleStringSchemaimportorg.apache.flink.streaming.api.TimeCharacteristicimportorg.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractorimportorg.apache.flink.streaming.api.scala._
importorg.apache.flink.streaming.api.windowing.time.Timeimportorg.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011importorg.apache.flink.table.api.java.Tumbleimportorg.apache.flink.table.api.{StreamTableEnvironment,Table,TableEnvironment}
object FlinkTableAndSql{
def main(args:Array[String]):Unit={//执行环境
val env:StreamExecutionEnvironment=StreamExecutionEnvironment.getExecutionEnvironment
//设置 时间特定为 EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)//读取数据 MyKafkaConsumer 为自定义的 kafka 工具类,并传入 topic
val dstream:DataStream[String]= env.addSource(MyKafkaConsumer.getConsumer("FLINKTABLE&SQL"))//将字符串转换为对象
val ecommerceLogDstream:DataStream[SensorReding]= dstream.map{/* 引入如下依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.36</version>
</dependency>*///将 String 转换为 SensorReding
jsonString =>JSON.parseObject(jsonString,classOf[SensorReding])}//告知 watermark 和 evetTime如何提取
val ecommerceLogWithEventTimeDStream:DataStream[SensorReding]=ecommerceLogDstream.assignTimestampsAndWatermarks(newBoundedOutOfOrdernessTimestampExtractor[SensorReding](Time.seconds(0)){
override def extractTimestamp(t:SensorReding):Long={
t.timestamp
}})//设置并行度
ecommerceLogDstream.setParallelism(1)//创建 Table 执行环境
val tableEnv:StreamTableEnvironment=TableEnvironment.getTableEnvironment(env)var ecommerceTable:Table= tableEnv.fromTableSource(ecommerceLogWithEventTimeDStream ,'mid,'uid,'ch,'ts.rowtime)//通过 table api进行操作//每10秒统计一次各个渠道的个数 table api解决//groupby window=滚动式窗口 用 eventtime 来确定开窗时间
val resultTalbe:Table= ecommerceTable.window(Tumble over 10000.millis on 'ts as 'tt).groupBy('ch,'tt).select('ch,'ch.count)var ecommerceTalbe:String="xxx"//通过 SQL 执行
val resultSQLTable:Table= tableEnv.sqlQuery("select ch,count(ch) from "+ ecommerceTalbe +"group by ch,Tumble(ts,interval '10' SECOND")//把 Table 转化成流输出//val appstoreDStream: DataStream[(String,String,Long)] = appstoreTable.toAppendStream[(String,String,Long)]
val resultDStream:DataStream[(Boolean,(String,Long))]= resultSQLTable.toRetractStream[(String,Long)]//过滤
resultDStream.filter(_._1)
env.execute()}}
object MyKafkaConsumer{
def getConsumer(sourceTopic:String):FlinkKafkaConsumer011[String]={
val bootstrapServers ="hadoop1:9092"// kafkaConsumer 需要的配置参数
val props =newProperties// 定义kakfa 服务的地址,不需要将所有broker指定上
props.put("bootstrap.servers", bootstrapServers)// 制定consumer group
props.put("group.id","test")// 是否自动确认offset
props.put("enable.auto.commit","true")// 自动确认offset的时间间隔
props.put("auto.commit.interval.ms","1000")// key的序列化类
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer")// value的序列化类
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer")//从kafka读取数据,需要实现 SourceFunction 他给我们提供了一个
val consumer =newFlinkKafkaConsumer011[String](sourceTopic,newSimpleStringSchema, props)
consumer
}}
关于时间窗口
【1】用到时间窗口,必须提前声明时间字段,如果是
processTime
直接在创建动态表时进行追加就可以。如下的
ps.proctime
。
val ecommerceLogTable:Table= tableEnv
.fromDataStream( ecommerceLogWithEtDstream,
`mid,`uid,`appid,`area,`os,`ps.proctime )
【2】如果是
EventTime
要在创建动态表时声明。如下的
ts.rowtime
。
val ecommerceLogTable:Table= tableEnv
.fromDataStream( ecommerceLogWithEtDstream,'mid,'uid,'appid,'area,'os,'ts.rowtime)
【3】滚动窗口可以使用
Tumble over 10000.millis on
来表示
val table:Table= ecommerceLogTable.filter("ch = 'appstore'").window(Tumble over 10000.millis on 'ts as 'tt).groupBy('ch,'tt).select("ch,ch.count")
如何查询一个 table
为了会有
GroupedTable
等,为了增加限制,写出正确的
API
。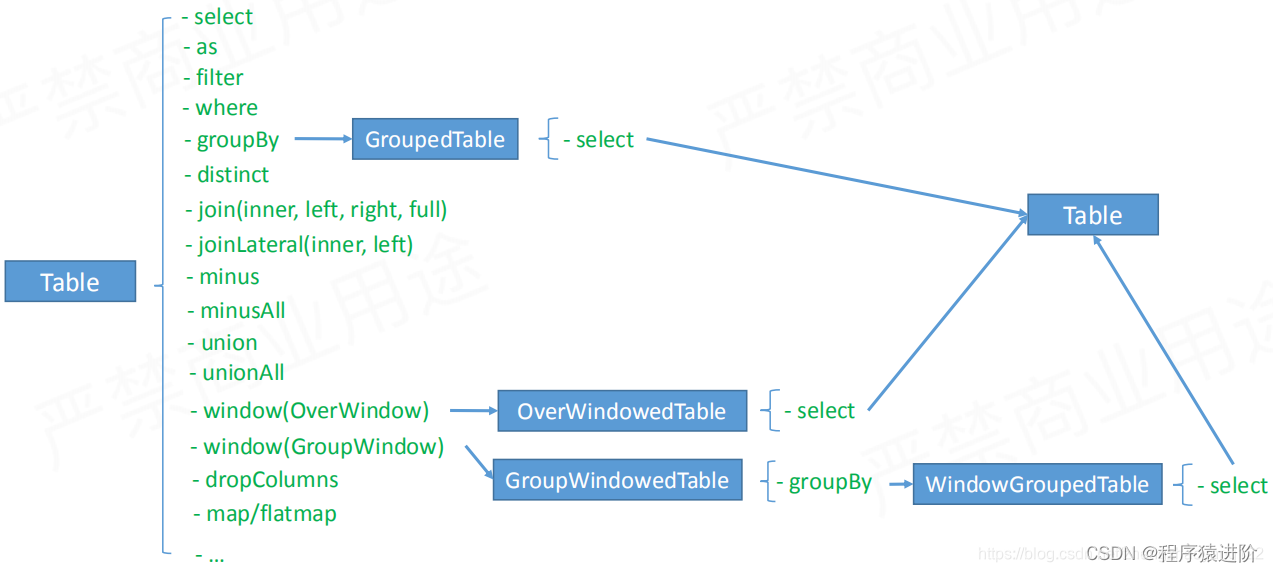
Table API 操作分类
1、与
sql
对齐的操作,
select
、
as
、
filter
等;
2、提升
Table API
易用性的操作;
——**
Columns Operation
易用性:** 假设有一张
100
列的表,我们需要去掉一列,需要怎么操作?第三个
API
可以帮你完成。我们先获取表中的所有
Column
,然后通过
dropColumn
去掉不需要的列即可。主要是一个
Table
上的算子。
OperatorsExamplesAddColumnsTable orders = tableEnv.scan(“Orders”); Table result = orders.addColumns(“concat(c,‘sunny’)as desc”); 添加新的列,要求是列名不能重复。addOrReplaceColumnsTable orders = tableEnv.scan(“Orders”); Table result = order.addOrReplaceColumns(“concat(c,‘sunny’) as desc”);添加列,如果存在则覆盖DropColumnsTable orders = tableEnv.scan(“Orders”); Table result = orders.dropColumns(“b c”);RenameColumnsTable orders = tableEnv.scan(“Orders”); Table result = orders.RenameColumns("b as b2,c as c2);列重命名
——**
Columns Function
易用性:** 假设有一张表,我么需要获取第
20-80
列,该如何获取。类似一个函数,可以用在列选择的任何地方,例如:
Table.select(withColumns(a,1 to 10))
、
GroupBy
等等。
语法描述withColumns(…)选择你指定的列withoutColumns(…)反选你指定的列
列的操作语法(建议): 如下,它们都是上层包含下层的关系。
columnOperation:
withColumns(columnExprs) / withoutColumns(columnExprs)#可以接收多个参数 columnExpr
columnExprs:
columnExpr [, columnExpr]* #可以分为如下三种情况
columnExpr:
columnRef | columnIndex to columnIndex | columnName to columnName #1 cloumn引用 2下标范围操作 3名字的范围操作
columnRef:
columnName(The field name that exists in the table)| columnIndex(a positive integer starting at 1)
Example: withColumns(a, b, 2 to 10, w to z)
Row based operation
/
Map operation
易用性:
//方法签名: 接收一个 scalarFunction 参数,返回一个 Table
def map(scalarFunction:Expression):TableclassMyMapextendsScalarFunction{var param :String=""//eval 方法接收一些输入
def eval([user defined inputs]):Row={
val result =newRow(3)// Business processing based on data and parameters// 根据数据和参数进行业务处理,返回最终结果
result
}//指定结果对应的类型,例如这里 Row的类型,Row有三列
override def getResultType(signature:Array[Class[_]]):TypeInformation[_]={Types.ROW(Types.STRING,Types.INT,Types.LONG)}}//使用 fun('e) 得到一个 Row 并定义名称 abc 然后获取 ac列
val res = tab
.map(fun('e)).as('a, 'b, 'c).select('a, 'c)//好处:当你的列很多的时候,并且每一类都需要返回一个结果的时候
table.select(udf1(),udf2(),udf3()….)VS
table.map(udf())
Map
是输入一条输出一条
**
FlatMap operation
易用性:**
//方法签名:出入一个tableFunction
def flatMap(tableFunction:Expression):Table
#tableFunction 实现的列子,返回一个 User类型,是一个 POJOs类型,Flink能够自动识别类型。
caseclassUser(name:String, age:Int)classMyFlatMapextendsTableFunction[User]{
def eval([user defined inputs]):Unit={for(..){collect(User(name, age))}}}//使用
val res = tab
.flatMap(fun('e,'f)).as('name, 'age).select('name, 'age)Benefit//好处
table.joinLateral(udtf)VS table.flatMap(udtf())
FlatMap
是输入一行输出多行
**
FlatAggregate operation
功能性:**
#方法签名:输入 tableAggregateFunction 与 AggregateFunction 很相似
def flatAggregate(tableAggregateFunction: Expression): FlatAggregateTable
class FlatAggregateTable(table: Table, groupKey: Seq[Expression], tableAggFun: Expression)
class TopNAcc {
var data: MapView[JInt, JLong]= _ // (rank -> value)...
}
class TopN(n: Int) extends TableAggregateFunction[(Int, Long), TopNAccum]{
def accumulate(acc: TopNAcc, [user defined inputs]){...
}#可以那多 column,进行多个输出
def emitValue(acc: TopNAcc, out: Collector[(Int, Long)]): Unit ={...
}...retract/merge
}#用法
val res = tab
.groupBy(‘a)
.flatAggregate(
flatAggFunc(‘e,’f) as (‘a, ‘b, ‘c))
.select(‘a, ‘c)#好处
新增了一种agg,输出多行
FlatAggregate operation
输入多行输出多行
**
Aggregate
与
FlatAggregate
的区别:** 使用
Max
和
Top2
的场景比较
Aggregate
和
FlatAggregate
之间的差别。如下有一张输入表,表有三列(
ID
、
NAME
、
PRICE
),然后对
Price
求最大指和
Top2
。
Max
操作是蓝线,首先创建累加器,然后在累加器上
accumulate
操作,例如6过去是6,3过去没有6大还是6等等。得到最终得到8的结果。
TOP2
操作时红线,首先创建累加器,然后在累加器上
accumulate
操作,例如6过去是6,3过去因为是两个元素所以3也保存,当5过来时,和最小的比较,3就被淘汰了等等。得到最终得到8和6的结果。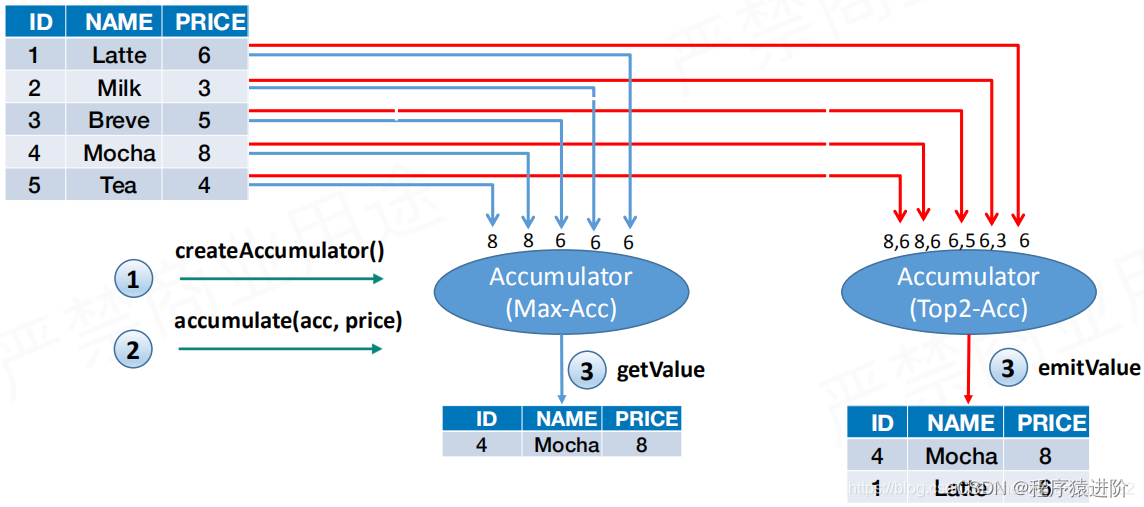
总结: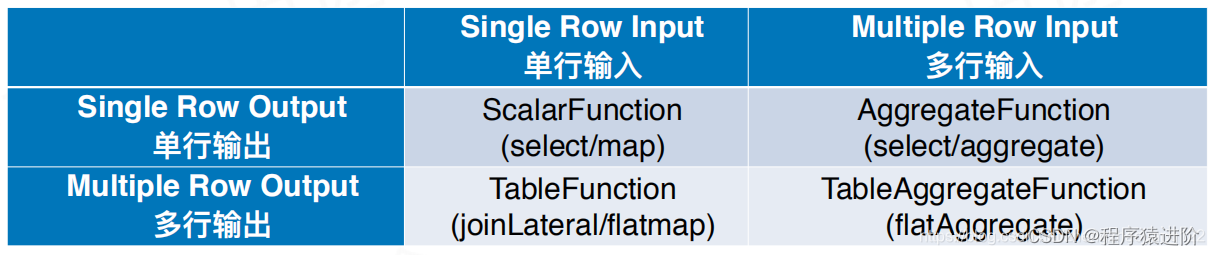
版权归原作者 程序猿进阶 所有, 如有侵权,请联系我们删除。