
目录
前言
随着大数据技术的不断发展,Hadoop作为开源的大数据处理框架,已经广泛应用于各种场景中。然而,在大型生产环境中,Hadoop集群的稳定性和可用性显得尤为重要。为了保障Hadoop集群的高可用性(HA),我们需要采用一系列的技术和策略。本文将重点介绍Hadoop集群的HA高可用方案。
一、Hadoop集群HA高可用概述
Hadoop集群的HA高可用主要指的是在集群中的关键组件出现故障时,能够自动切换到其他节点继续提供服务,从而确保整个集群的稳定运行。
二、集群规模
Hadoop HA高可用集群规划 - 三节点(master, slave1, slave2)
组件masterslave1slave2描述HadoopNameNode主节点备节点无主备部署,共享存储同步元数据SecondaryNameNode主节点无无辅助NameNode,定期合并fsimage和edits logResourceManager主节点备节点无主备部署,实现资源管理和任务调度DataNode有有有存储实际数据,参与数据块的读写操作NodeManager有有有负责管理容器生命周期,与ResourceManager通信
三、配置zookeeper集群
1.解压zookeeper安装包
tar -zxvf zookeeper-3.4.6.tar.gz -C/usr/local/src
2.设置环境变量
位置:vi /.bash_profile
添加环境变量
export ZK_HOME=/usr/local/src/zookeeper
export PATH=$PATH:$ZK_HOME/bin
3.配置zoo.cfg配置文件
先创建存放ZK的数据文件和配置文件的zkdata目录
mkdir zkdata
配置zoo.cfg文件,在文件中添加下面内容
dataDir=/usr/local/src/zookeeper/zkdata
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
4.分发到其他节点
scp -r zookeeper/ root@slave2:/usr/local/src
5.修改myid 配置文件
在zkdata目录中创建myid并修改
echo 1>myid (master)
echo 2>myid (slave1)
echo 3>myid (slave2)
—master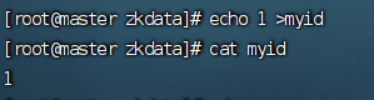
—slave1
—slave2
6.启动并查看zookeeper状态
位置:
cd /usr/local/src/zookeeper/bin
启动:
./zkServer.sh start
状态:
./zkServer.sh status
----master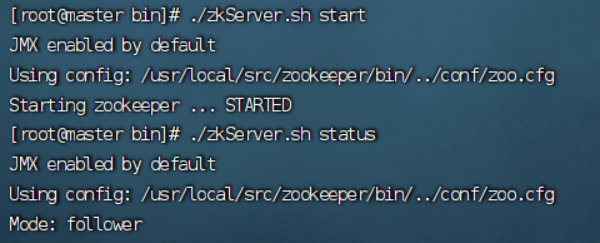
----Slave1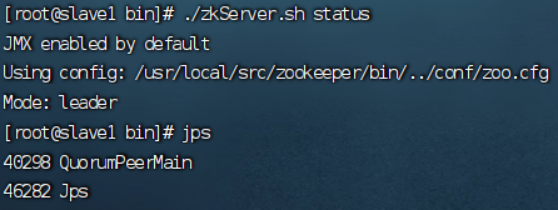
----Slave2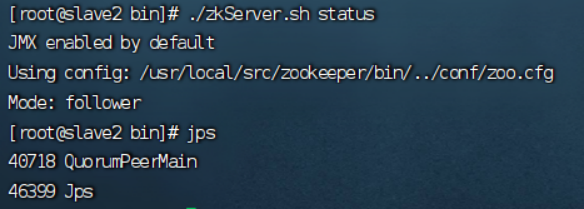
zookeeper配置完成!
四、配置HA高可用
1.解压hadoop安装包
tar -zxvf hadoop-3.2.2.tar.gz -C/usr/local/src
2.添加环境变量
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
3.修改配置文件
位置:
/usr/local/src/hadoop/etc/hadoop
(1)core-site.xml
<configuration><!-- hdfs分布式文件系统名字/地址 --><property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><!--存放namenode、datanode数据的根路径 --><property><name>hadoop.tmp.dir</name><value>/usr/loal/src/hadoop/data</value></property><!-- 存放journalnode数据的地址 --><property><name>dfs.journalnode.edits.dir</name><value>/usr/loal/src/hadoop/data/jn</value></property><!-- 列出运行 ZooKeeper 服务的主机端口对 --><property><name>ha.zookeeper.quorum</name><value>master:2181,slave1:2181,slave2:2181</value></property></configuration>
(2)hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>3</value></property><!-- 服务的逻辑名称,使用mycluster替换master:9000作为逻辑名称 --><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- 两个namenode的名称 --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2,nn3</value></property><!-- 两个namenode的rpc通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>master:8020</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>slave1:8020</value></property><property><name>dfs.namenode.rpc-address.mycluster.nn3</name><value>slave2:8020</value></property><!-- web访问端口 --><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>master:9870</value></property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>slave1:9870</value></property><property><name>dfs.namenode.http-address.mycluster.nn3</name><value>slave2:9870</value></property><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value></property><!-- 切换namenode代理类 --><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 关闭权限检查 --><property><name>dfs.permissions.enable</name><value>false</value></property><!-- 通过SSH连接到ActiveNameNode并终止进程 --><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><!-- 隔离机制 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- 启动自动故障转移机制 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property></configuration>
(3) hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
(4) workers
master
slave1
salve2
(5)start-dfs.sh 和 stop-dfs.sh
位置:
/usr/local/src/hadoop/sbin
HDFS_NAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_SECONDARYNAMENODE_USER=root
4.分发配置文件
scp -r hdfs-site.xml root@slave2:/usr/local/src/hadoop/etc/hadoop
5.1启动JournalNode
hdfs --daemon start journalnode
5.2安装自动转移机制包
yum -y install psmisc
如果不安装这个程序包,自动转移故障机制无法进行 fence。
其他的 Standby 状态的NameNode 不能自动切换为 Active状态。
6.1初始化namenode
在初始化前要先启动三台节点的zookeeper,并关闭防火墙
systemctl stop firewalld
hdfs namenode -format
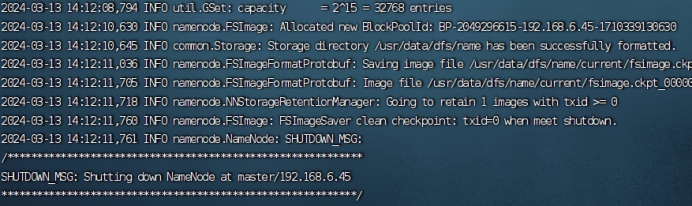
6.2格式化zookeeper
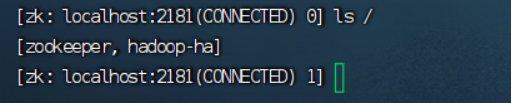
hdfs zkfc -formatZK
判断初始化是否成功:
zkCli.sh
7.1启动集群
mater上执行:(只需执行一次)
hdfs --daemon start namenode
slave1上执行:(只需执行一次)
hdfs namenode -bootstrapStandby
在mater上启动集群:
./start-dfs.sh
7.2查看进程
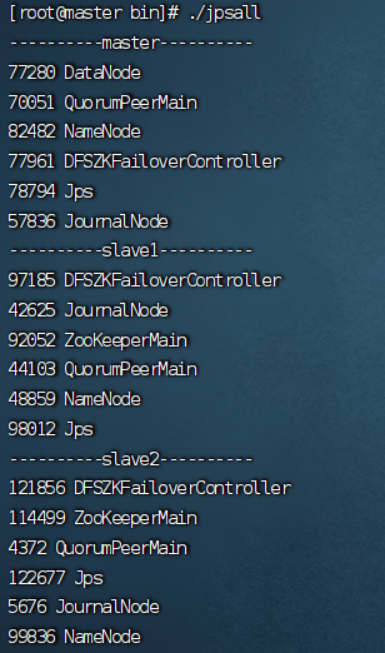
最终实现效果
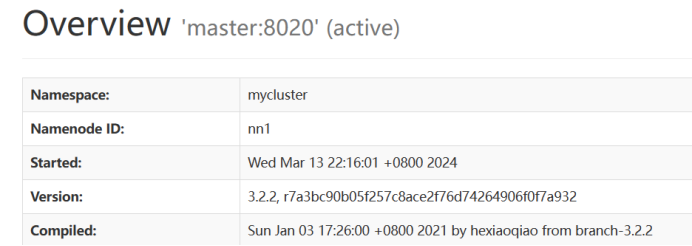
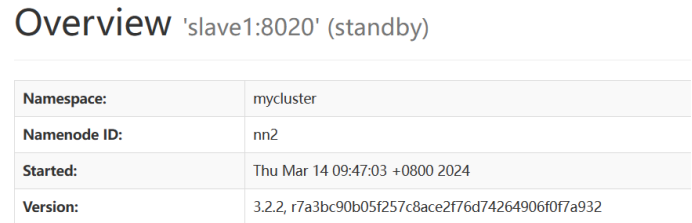
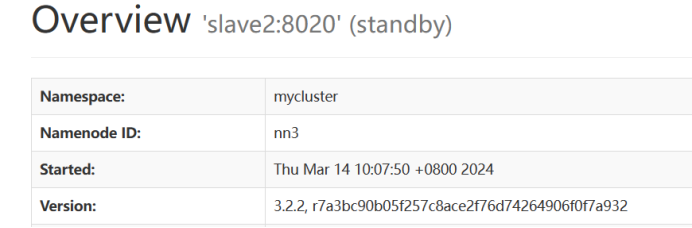
五、常见问题
**
经常有小伙伴在启动完集群后发现zkfc(DFSZKFailoverController)进程没有或是启动失败的情况
**
解决办法:
步骤一:先去关闭hadoop集群
步骤二:重新格式化zookeeper(注意:在格式化时要先启动zookeeper)
步骤三:重新启动hadoop集群
六、故障转移检测
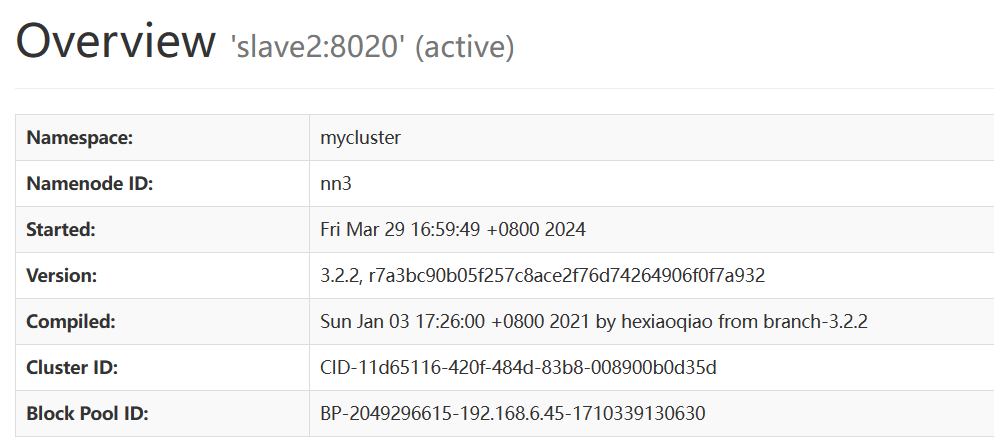
实现当杀掉第一台节点master后active状态会自动转移到第二台节点slave1或slave2上,且被杀掉的节点页面便不可访问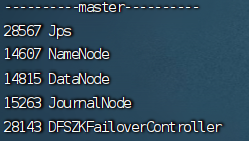
kill -9 进程号 (这里的进程号就是namenode的进程号,如 kill -914607)
七、HA启动脚本
#!/bin/bash
if[ $# -lt 1]; then
echo "No Args Input..."
exit 1;
fi
case $1in"start")
echo "----------启动zookeeper----------"for i in master slave1 slave2;do
echo "---------- zookeeper $i 启动 ------------"
ssh $i "/usr/local/src/zookeeper/bin/zkServer.sh start"&& echo "Zookeeper $i 启动成功"
done
echo "---------- 启动hdfs------------"
ssh master "/usr/local/src/hadoop/sbin/start-dfs.sh"&& echo "HDFS 启动成功"
echo "---------- hadoop HA启动成功------------";;"stop")
echo "----------关闭hdfs----------"
ssh master "/usr/local/src/hadoop/sbin/stop-dfs.sh"&& echo "HDFS 关闭成功"
echo "----------关闭zookeeper----------"for i in master slave1 slave2;do
echo "---------- zookeeper $i 停止 ------------"
ssh $i "/usr/local/src/zookeeper/bin/zkServer.sh stop"&& echo "Zookeeper $i 停止成功"
done
echo "---------- hadoop HA停止成功------------";;"status")
echo "----------检查zookeeper状态----------"for i in master slave1 slave2;do
echo "---------- zookeeper $i 状态 ------------"
ssh $i "/usr/local/src/zookeeper/bin/zkServer.sh status"
done
;;*)
echo "Input Args Error";;
esac
七、总结
Hadoop集群的HA高可用方案是保障集群稳定性和可用性的重要手段。通过合理配置NameNode、ResourceManager等关键组件的高可用策略,并结合共享存储、ZooKeeper等技术手段,我们可以有效地提高Hadoop集群的容错能力和服务水平。在实际应用中,我们需要根据集群的规模和业务需求来选择合适的HA高可用方案,并进行持续的监控和优化,以确保集群的稳定运行和高效处理大数据任务。
版权归原作者 提醒一下哟 所有, 如有侵权,请联系我们删除。