
driver.find_element_by_id(‘xxx’).send_keys(Keys.ENTER)
使用 Backspace 来删除一个字符
driver.find_element_by_id(‘xxx’).send_keys(Keys.BACK_SPACE)
Ctrl + A 全选输入框中内容
driver.find_element_by_id(‘xxx’).send_keys(Keys.CONTROL, ‘a’)
Ctrl + C 复制输入框中内容
driver.find_element_by_id(‘xxx’).send_keys(Keys.CONTROL, ‘c’)
Ctrl + V 粘贴输入框中内容
driver.find_element_by_id(‘xxx’).send_keys(Keys.CONTROL, ‘v’)
其他常见键盘操作:
| 操作 | 描述 |
| --- | --- |
| `Keys.F1` | F1键 |
| `Keys.SPACE` | 空格 |
| `Keys.TAB` | Tab键 |
| `Keys.ESCAPE` | ESC键 |
| `Keys.ALT` | Alt键 |
| `Keys.SHIFT` | Shift键 |
| `Keys.ARROW_DOWN` | 向下箭头 |
| `Keys.ARROW_LEFT` | 向左箭头 |
| `Keys.ARROW_RIGHT` | 向右箭头 |
| `Keys.ARROW_UP` | 向上箭头 |
---
### 设置元素等待
很多页面都使用 `ajax` 技术,页面的元素不是同时被加载出来的,为了防止定位这些尚在加载的元素报错,可以设置元素等来增加脚本的稳定性。`webdriver` 中的等待分为 显式等待 和 隐式等待。
#### 显式等待
显式等待:设置一个超时时间,每个一段时间就去检测一次该元素是否存在,如果存在则执行后续内容,如果超过最大时间(超时时间)则抛出超时异常(`TimeoutException`)。显示等待需要使用 `WebDriverWait`,同时配合 `until` 或 `not until` 。下面详细讲解一下。
>
> WebDriverWait(driver, timeout, poll\_frequency=0.5, ignored\_exceptions=None)
>
>
>
* `driver`:浏览器驱动
* `timeout`:超时时间,单位秒
* `poll_frequency`:每次检测的间隔时间,默认为0.5秒
* `ignored_exceptions`:指定忽略的异常,如果在调用 `until` 或 `until_not` 的过程中抛出指定忽略的异常,则不中断代码,默认忽略的只有 `NoSuchElementException` 。
>
> until(method, message=’ ‘)
> until\_not(method, message=’ ')
>
>
>
* `method`:指定预期条件的判断方法,在等待期间,每隔一段时间调用该方法,判断元素是否存在,直到元素出现。`until_not` 正好相反,当元素消失或指定条件不成立,则继续执行后续代码
* `message`: 如果超时,抛出 `TimeoutException` ,并显示 `message` 中的内容
`method` 中的预期条件判断方法是由 `expected_conditions` 提供,下面列举常用方法。
先定义一个定位器
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome()
locator = (By.ID, ‘kw’)
element = driver.find_element_by_id(‘kw’)
| 方法 | 描述 |
| --- | --- |
| title\_is(‘百度一下’) | 判断当前页面的 title 是否等于预期 |
| title\_contains(‘百度’) | 判断当前页面的 title 是否包含预期字符串 |
| presence\_of\_element\_located(locator) | 判断元素是否被加到了 dom 树里,并不代表该元素一定可见 |
| visibility\_of\_element\_located(locator) | 判断元素是否可见,可见代表元素非隐藏,并且元素的宽和高都不等于0 |
| visibility\_of(element) | 跟上一个方法作用相同,但传入参数为 element |
| text\_to\_be\_present\_in\_element(locator , ‘百度’) | 判断元素中的 text 是否包含了预期的字符串 |
| text\_to\_be\_present\_in\_element\_value(locator , ‘某值’) | 判断元素中的 value 属性是否包含了预期的字符串 |
| frame\_to\_be\_available\_and\_switch\_to\_it(locator) | 判断该 frame 是否可以 switch 进去,True 则 switch 进去,反之 False |
| invisibility\_of\_element\_located(locator) | 判断元素中是否不存在于 dom 树或不可见 |
| element\_to\_be\_clickable(locator) | 判断元素中是否可见并且是可点击的 |
| staleness\_of(element) | 等待元素从 dom 树中移除 |
| element\_to\_be\_selected(element) | 判断元素是否被选中,一般用在下拉列表 |
| element\_selection\_state\_to\_be(element, True) | 判断元素的选中状态是否符合预期,参数 element,第二个参数为 True/False |
| element\_located\_selection\_state\_to\_be(locator, True) | 跟上一个方法作用相同,但传入参数为 locator |
| alert\_is\_present() | 判断页面上是否存在 alert |
下面写一个简单的例子,这里定位一个页面不存在的元素,抛出的异常信息正是我们指定的内容。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
element = WebDriverWait(driver, 5, 0.5).until(
EC.presence_of_element_located((By.ID, ‘kw’)),
message=‘超时啦!’)

#### 隐式等待
隐式等待也是指定一个超时时间,如果超出这个时间指定元素还没有被加载出来,就会抛出 `NoSuchElementException` 异常。
除了抛出的异常不同外,还有一点,隐式等待是全局性的,即运行过程中,如果元素可以定位到,它不会影响代码运行,但如果定位不到,则它会以轮询的方式不断地访问元素直到元素被找到,若超过指定时间,则抛出异常。
使用 `implicitly_wait()` 来实现隐式等待,使用难度相对于显式等待要简单很多。
示例:打开个人主页,设置一个隐式等待时间 5s,通过 `id` 定位一个不存在的元素,最后打印 抛出的异常 与 运行时间。
from selenium import webdriver
from time import time
driver = webdriver.Chrome()
driver.get(‘https://blog.csdn.net/qq_43965708’)
start = time()
driver.implicitly_wait(5)
try:
driver.find_element_by_id(‘kw’)
except Exception as e:
print(e)
print(f’耗时:{time()-start}')

代码运行到 `driver.find_element_by_id('kw')` 这句之后触发隐式等待,在轮询检查 5s 后仍然没有定位到元素,抛出异常。
#### 强制等待
使用 `time.sleep()` 强制等待,设置固定的休眠时间,对于代码的运行效率会有影响。以上面的例子作为参照,将 隐式等待 改为 强制等待。
from selenium import webdriver
from time import time, sleep
driver = webdriver.Chrome()
driver.get(‘https://blog.csdn.net/qq_43965708’)
start = time()
sleep(5)
try:
driver.find_element_by_id(‘kw’)
except Exception as e:
print(e)
print(f’耗时:{time()-start}')

值得一提的是,对于定位不到元素的时候,从耗时方面隐式等待和强制等待没什么区别。但如果元素经过 2s 后被加载出来,这时隐式等待就会继续执行下面的代码,但 sleep还要继续等待 3s。
---
### 定位一组元素
上篇讲述了定位一个元素的 8 种方法,定位一组元素使用的方法只需要将 `element` 改为 `elements` 即可,它的使用场景一般是为了批量操作元素。
* `find_elements_by_id()`
* `find_elements_by_name()`
* `find_elements_by_class_name()`
* `find_elements_by_tag_name()`
* `find_elements_by_xpath()`
* `find_elements_by_css_selector()`
* `find_elements_by_link_text()`
* `find_elements_by_partial_link_text()`
这里以 CSDN 首页的一个 博客专家栏 为例。
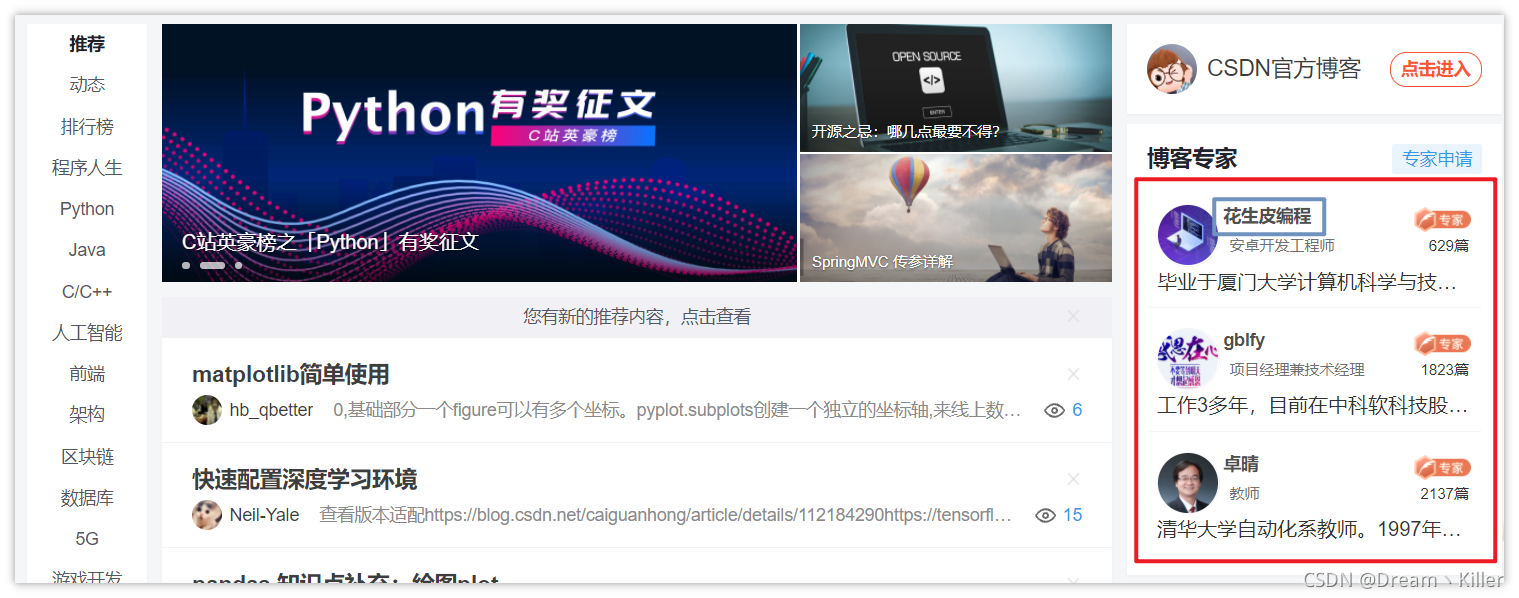
下面使用 `find_elements_by_xpath` 来定位三位专家的名称。

这是专家名称部分的页面代码,不知各位有没有想到如何通过 `xpath` 定位这一组专家的名称呢?
from selenium import webdriver
设置无头浏览器
option = webdriver.ChromeOptions()
option.add_argument(‘–headless’)
driver = w
版权归原作者 Java有多久学会 所有, 如有侵权,请联系我们删除。