
前言:quartz是一个定时调度的框架,就目前市场上来说,其实有比quartz更优秀的一些定时调度框架,不但性能比quartz好,学习成本更低,而且还提供可视化操作定时任务。例如xxl-Job,elastic-Job这两个算是目前工作中使用比较多的定时调度框架了,适配于分布式的项目,性能也是很优秀。这是很多人就很疑惑,既然这样我们为什么还要了解学习quartz呢?我个人觉得学习quartz有两方面,首先xxl-Job,elastic-Job这些框架都是基于quartz的基础上二次开发的,学习quartz更有利于我们加强理解定时调度。第二方面就是工作需求,有一些传统互联网公司还是有很多项目是使用quartz来完成定时任务的开发的,不懂quartz的话,老板叫你写个定时任务都搞不定。
1. quartz的基础概念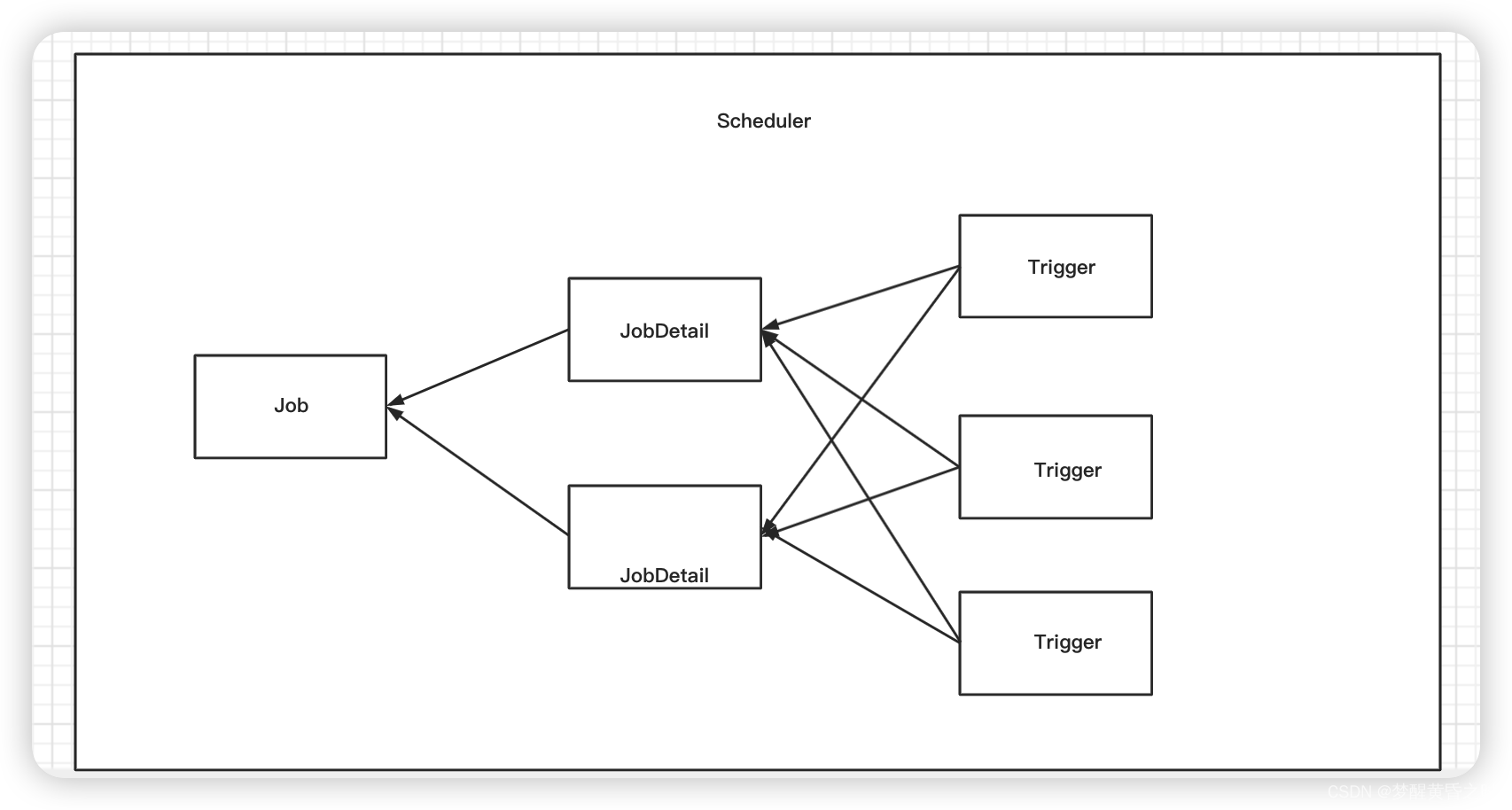
有上图可以看到,一个job可以给多个jobDetail封装,一个jobDetail可以给trigger来配置规则,但是一个trigger只能装配一个jobDetail。
scheduler:可以理解为定时任务的工作容器或者说是工作场所,所有定时任务都是放在里面工作,可以开启和停止。
trigger:可以理解为是定时任务任务的工作规则配置,例如说,没个几分钟调用一次,或者说指定每天那个时间点执行。
jobDetail:定时任务的信息,例如配置定时任务的名字,群组之类的。
job:定时任务的真正的业务处理逻辑的地方。
2. quartz的简单使用
这是quartz的api使用,在官网直接提供使用例子,但是在工作中用不到这种方式的
地址:https://www.quartz-scheduler.org/documentation/quartz-2.3.0/quick-start.html
publicclassQuartzTest{publicstaticvoidmain(String[] args)throwsException{try{Scheduler scheduler =StdSchedulerFactory.getDefaultScheduler();
scheduler.start();JobDetail job =newJob(HelloJob.class).withIdentity("job1","group1").build();Trigger trigger =newTrigger().withIdentity("trigger1","group1").startNow().withSchedule(simpleSchedule().withIntervalInSeconds(2).repeatForever()).build();
scheduler.scheduleJob(job, trigger);TimeUnit.SECONDS.sleep(20);
scheduler.shutdown();}catch(SchedulerException se){
se.printStackTrace();}}}
3. quartz与springboot的整合使用
在官网中介绍了,只要你引用了quartz的依赖后,springboot会自适配调度器。当然我们也可以新建bean,修改SchedulerFactoryBean的一些默认属性值。
使用javaBean方式按实际业务需求初始化SchedulerFactoryBean(可以不要,就用默认SchedulerFactoryBean
@ConfigurationpublicclassQuartzConfiguration{// Quartz配置文件路径privatestaticfinalStringQUARTZ_CONFIG="config/quartz.properties";@Value("${task.enabled:true}")privateboolean enabled;@AutowiredprivateDataSource dataSource;@BeanpublicSchedulerFactoryBeanschedulerFactoryBean(){SchedulerFactoryBean schedulerFactoryBean =newSchedulerFactoryBean();
schedulerFactoryBean.setDataSource(dataSource);// 设置加载的配置文件
schedulerFactoryBean.setConfigLocation(newClassPathResource(QUARTZ_CONFIG));// 用于quartz集群,QuartzScheduler 启动时更新己存在的Job
schedulerFactoryBean.setOverwriteExistingJobs(true);
schedulerFactoryBean.setStartupDelay(5);// 系统启动后,延迟5s后启动定时任务,默认为0// 启动时更新己存在的Job,这样就不用每次修改targetObject后删除qrtz_job_details表对应记录了
schedulerFactoryBean.setOverwriteExistingJobs(true);// SchedulerFactoryBean在初始化后是否马上启动Scheduler,默认为true。如果设置为false,需要手工启动Scheduler
schedulerFactoryBean.setAutoStartup(enabled);return schedulerFactoryBean;}}
要使用quartz实现定时任务,首先要新建一个Job,在springboot中,新建的Job类要继承QuartzJobBean
publicclassHelloJobextendsQuartzJobBean{@OverrideprotectedvoidexecuteInternal(JobExecutionContext context){StringJoiner joiner =newStringJoiner(" | ").add("---HelloJob---").add(context.getTrigger().getKey().getName()).add(DateUtil.formatDate(newDate()));System.out.println(joiner);}}
创建jobDetail和Trigger来启动定时任务,有两种方式可以实现,本质上就是创建jobDetail和Trigger
方式一:为对应的Job创建JobDetail和Trigger,这种方式有两个注意的地方,jobDetail一定要设置为可持久化.storeDurably(),Trigger创建要用.forJob(“helloJob”),要与JobDetail定义的相同。
@ComponentpublicclassHelloJobDetailConfig{@BeanpublicJobDetailhelloJobDetail(){JobDetail jobDetail =JobBuilder.newJob(HelloJob.class).withIdentity("helloJob").storeDurably().usingJobData("data","保密信息").build();return jobDetail;}@BeanpublicTriggerhelloJobTrigger(){Trigger trigger =TriggerBuilder.newTrigger().forJob("helloJob").withSchedule(simpleSchedule().withIntervalInSeconds(3).repeatForever()).build();return trigger;}}
方式二:在注入Bean之前初始化创建JobDetail和Trigger,然后使用Scheduler来调用,跟原生API调用差不多。
@ComponentpublicclassHelloJobDetailConfig2{@AutowiredprivateScheduler scheduler;@PostConstructprotectedvoidInitHelloJob()throwsException{JobDetail jobDetail =JobBuilder.newJob(HelloJob.class).withIdentity("helloJob")// .storeDurably().usingJobData("data","保密信息").build();Trigger trigger =TriggerBuilder.newTrigger().withIdentity("helloTrigger").withSchedule(simpleSchedule().withIntervalInSeconds(3).repeatForever()).build();
scheduler.scheduleJob(jobDetail,trigger);}}
4. quartz的持久化
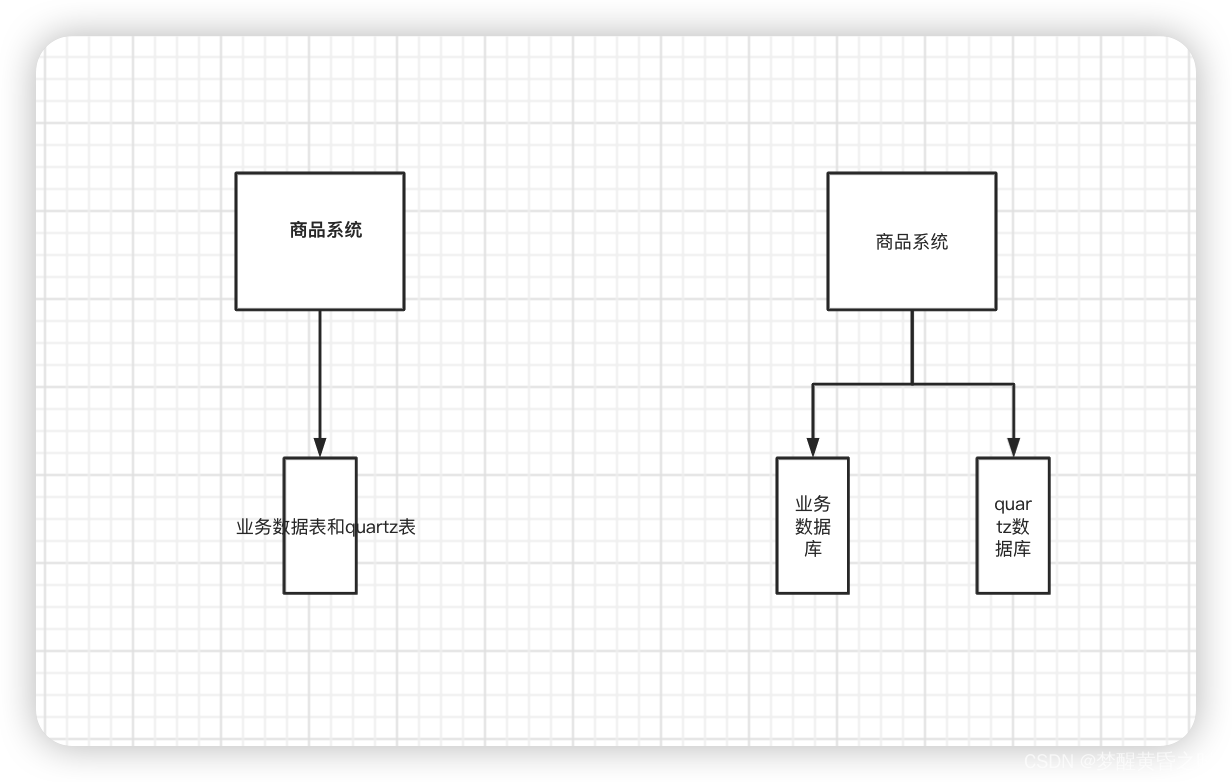
quartz持久化有两种存储,一般情况下quartz相关的表和业务表是放在同一个数据库里的。但是如果考虑性能问题的话,就要配多数据源,业务表单独一个库,quartz相关的表放在一个库。
spring官网说明,默认情况下,使用内存中的JobStore。但是,如果应用程序中有DataSourcebean,并且spring.quartz是可用的,则可以配置基于JDBC的存储。将相应地配置作业存储类型属性。第二个配置,每次启动先删除表数据再重新创建(在实际生产中,个人更倾向于拿dml来手动创建表,这个值设置为never)。在quartz的jar包里这个路径下有不同数据库的dml:org.quartz.impl.jdbcjobstore
spring.quartz.job-store-type=jdbc
spring.quartz.jdbc.initialize-schema=never
另外一种方式:
要让Quartz使用DataSource而不是应用程序的主DataSource,请声明DataSourcebean,并用@QuartzDataSource注释其@bean方法。这样做可以确保SchedulerFactoryBean和模式初始化都使用Quartz特定的DataSource
@ConfigurationpublicclassQuartzDataSourceConfig{@Bean@QuartzDataSourcepublicDataSourcequartzDataSource(){DriverManagerDataSource dataSource =newDriverManagerDataSource();
dataSource.setUsername("root");
dataSource.setPassword("123456");
dataSource.setUrl("jdbc:mysql://127.0.0.1:3306/quartz?useUnicode=true&characterEncoding=utf-8&useSSL=false");return dataSource;}}
还有一点需要注意:当jobbean已经注入spring容器后,下次不用需要再注入,把@Component注释掉。
5. quartz的misfire策略
misfire:到了任务触发时间点,但是任务没有被触发
原因:- 使用@DisallowConcurrentExecution注解,而且任务的执行时间>任务间隔
-线程池满了,没有资源执行任务
-机器宕机或者认为停止,果断时间恢复运行。
@DisallowConcurrentExecution:这个是比较常用的注解,证上一个任务执行完后,再去执行下一个任务,不会允许任务并行执行。
@PersistJobDataAfterExecution:任务执行完后,会持久化保留数据到下次 执行
针对不同的ScheduleBuilder,可以设置不同的失火策略,SimpleScheduleBuilder和非SimpleScheduleBuilder,
SimpleScheduleBuilder有六种,而非SimpleScheduleBuilder有三种,在实际工作中我们使用的比较的是CronScheduleBuilder.
.withMisfireHandlingInstructionIgnoreMisfires()
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY = -1
所有未触发的执行都会立即执行,然后触发器再按计划运行。
.withMisfireHandlingInstructionFireAndProceed()
MISFIRE_INSTRUCTION_FIRE_ONCE_NOW = 1
立即执行第一个错误的执行并丢弃其他(即所有错误的执行合并在一起),也就是说无论错过了多少次触发器的执行,都只会立即执行一次,然后触发器再按计划运行。(默认的失火策略)
.withMisfireHandlingInstructionDoNothing()
MISFIRE_INSTRUCTION_DO_NOTHING = 2
所有未触发的执行都将被丢弃,然后再触发器的下一个调度周期按计划运行。
6、总结
关于quartz还有一个很重要的点就是corn表达式,这个个人认为没必要死记硬背,实在不会写的,上网找corn表达式在线转换就可以了。
一个简单demo的代码地址:https://gitee.com/gorylee/quartz-demo
生产项目中quartz的配置使用代码地址:https://gitee.com/gorylee/learnDemo/tree/master/quartzDemo
版权归原作者 小lee学编程 所有, 如有侵权,请联系我们删除。