
Hadoop架构
Hadoop由三大部分组成:HDFS、MapReduce、yarn
HDFS:负责数据的存储
其中包括:
**namenode:**主节点,用来分配任务给从节点 **secondarynamenode:**副节点,辅助主节点 **datanode:**从节点,负责实际的存储MapReduce:负责计算
其中Map负责分解,reduce负责合并
yarn:负责资源调度
其中包括:
**resourcemanager:**负责接收用户的请求,并负责集群的管理和资源调度 **nodemanager:**负责执行resourcemanager分配的任务
Hive相关知识点
元数据:用来描述数据的数据。
元数据包含:用Hive创建的database、table、表的字段等元信息。
元数据存储:存在关系型数据库中,如:hive内置的Derby数据库或者第三方MySQL数据库等,一般使用Mysql数据库。
Metastore:即元数据存储服务
作用是: 客户端连接metastore服务,metastore再去连接MySQL等数据库来存取元数据。
特点: 有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL等数据库的用户名和密码,只需要连接metastore 服务即可。
Hive执行流程

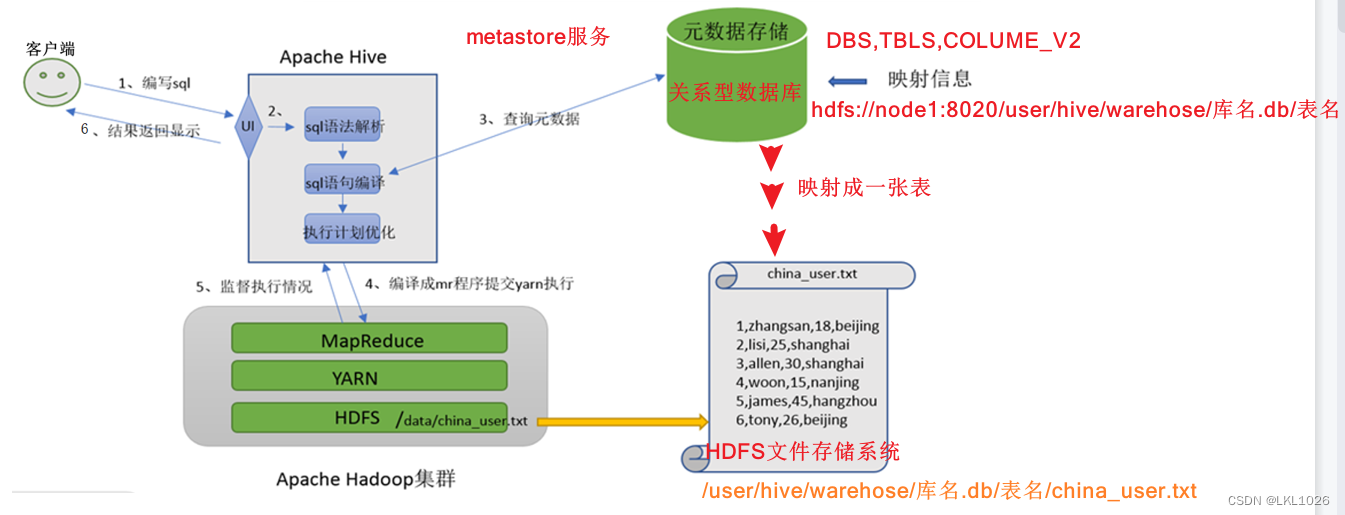
1.用户在用户端编写sql语句,通过hive thrift server传到hive
hive中:
2.解析器:解析sql语法
3.编译器:将sql语句编译成MapReduce程序,通过metastore在数据库中获取元数据并映射成一张表
优化器:优化MapReduce程序
4.执行器:将优化后的执MapReduce程序传给Hadoop
Hadoop来执行MapReduce程序,yarn复制资源调度,MapReduce负责计算
5.hive来监督执行情况,Hadoop会将结果存在hdfs中
6.结果返回显示
本文转载自: https://blog.csdn.net/qq_52442855/article/details/134337091
版权归原作者 LKL1026 所有, 如有侵权,请联系我们删除。
版权归原作者 LKL1026 所有, 如有侵权,请联系我们删除。