
每晚睡前复习一个题,云计算必高分过系列
为了提高学习效率,这里搬个友链
这里写目录标题
以下所有内容可能有误,请自行甄别
一. HBase && Spark
1. HBase
启动集群后:
① Shell
- 建表
create用来建表create "apple","base_info"其中,apple为表名,base_info为列族,列族至少有一个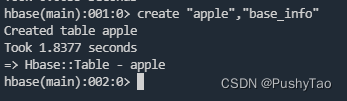 查看所创建的表:
查看所创建的表: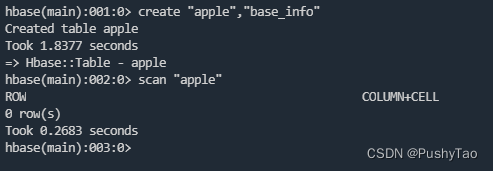
- 插入数据
put命令用来插入put "apple","0001","base_info:weight","89"
其中apple为表名,0001为行键,base_info为列族(必须是已经创建了的),weight为列名,89为具体的值
其余可参考: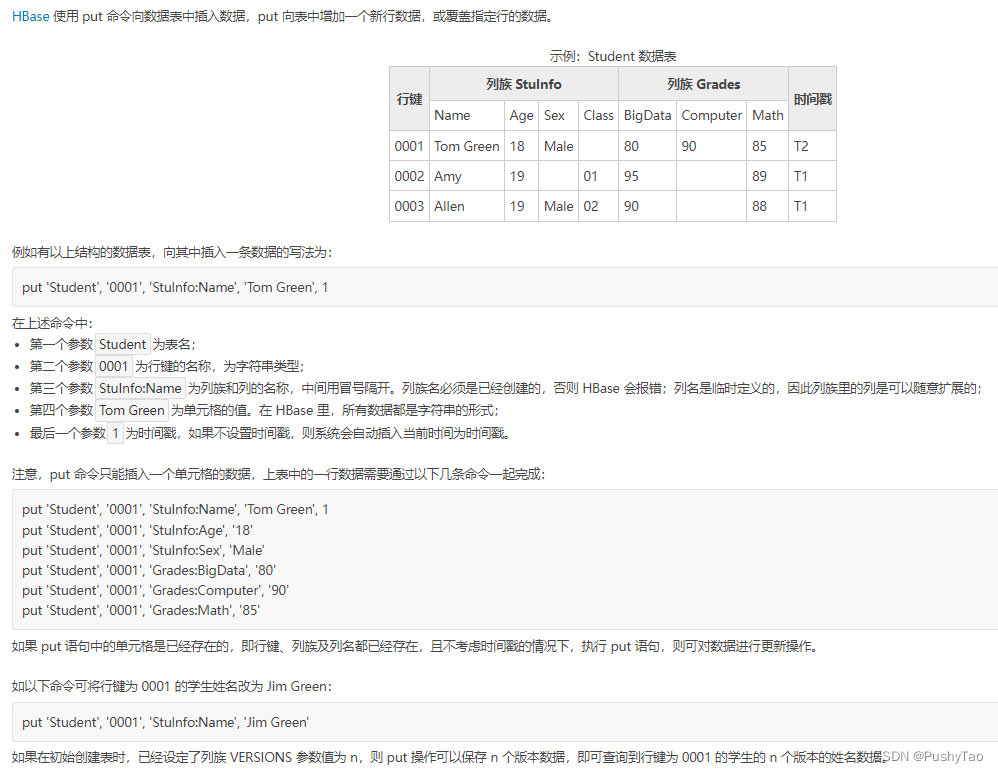
在上图中,在创建表的时候,可以用命令:
create "Student","Stuinfo","Grades"
列族是可以后续添加的,比如:
alter "apple","extra_info"
再插入数据:
put "apple","0001","extra_info:grade","good"
然后继续插入信息可以查看到更新后的表信息: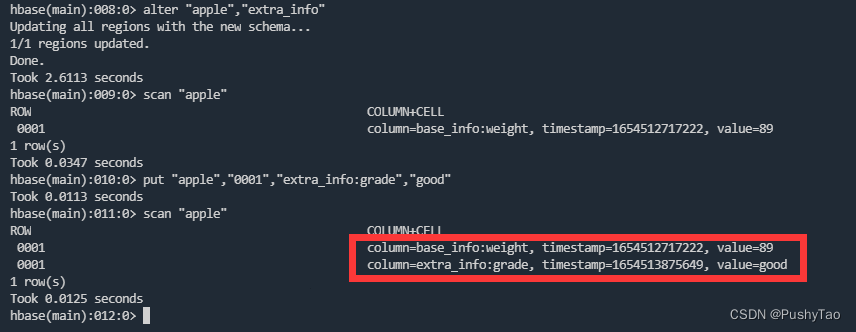
- 浏览数据
get命令可以用来获取表中的数据get "apple","0001"其中,apple为表名,0001为行键 可以看见:

scan "apple"
用来获取所有的信息
apple为表名
在结果中我们可以看到两部分
第一部分是:ROW为0001
第二部分是:COLUMN(包含列的名字
列族:列名
的形式)+CELL(时间戳和值)
指定获取某个值:
get "apple","0001","base_info:weight"
其中,apple为表名,0001为行键,base_info为列族,weight为列名
- 分析 HBase的插入和删除操作与关系型数据库(e.g. MySQL)的区别 ** 感觉必考**
插入的区别(个人总结,可能不对):
HBase一次只能插入一个表一个列族某单元格的数据,插入时自动加时间戳。而MySQL再插入的过程中,不会自动加时间戳,而且必须要严格按照表的结构来进行插入,也就说在MySQL中是没有办法通过列来进行插入的,但是HBase是可以的(HBase插入要提供表名、行键的名称、列族和列的名称,列名是临时定义的,列族里的列可以随意扩展,极大程度上扩大了数据的存储结构,这也决定了HBase适合大数据的存储、具有高效性的特点)。
在执行的插入命令方面,HBase通过命令put来进行插入,而MySQL通过insert命令来进行插入。
底层方面:在MySQL(不仅仅是MySQL,是包括MySQL所有的关系型数据库)的底层方面,是通过关系代数的运算来实现的,而HBase操作则不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等。
删除的区别(来自网络 && 个人总结):
- 删除的方式不同 HBase不会定位到需要删除或更新的记录进行操作。由于HBase底层依赖HDFS,对于HBase删除操作来说,HBase无法在查询到之前的数据并进行修改,只能顺序读写,追加记录。为了更新或删除数据,HBase会插入一条一模一样的新的数据,但是key type会标记成Delete状态,以标记该记录被删除了。在读取的时候如果取到了是Delete,而且时间是最新的,那么这条记录肯定是被删掉了,从而达到删除的目的。 对于关系型数据库来说,进行删除会直接将二维表中的某一行删除掉
- 删除的粒度不同 在HBase中进行删除的时候,如果使用命令delete ,可以从表中删除一个单元格或一个行集,语法与 put 类似,必须指明表名和列族名称,而列名和时间戳是可选的。删除的粒度可以是单元格或者是一个行集,要想删除一整个数据,要使用deleteall(原因是:delete 命令不能跨列族操作,如需删除表中所有列族在某一行上的数据,即删除上表中一个逻辑行,则需要使用 deleteall 命令,不需要指定列族和列的名称,只需要指定表明和行键即可);但是在关系型数据库中,不能够删除一个单元格,在关系型数据库中删除的最小粒度是行,即二维表中的一整条数据。 3.使用的命令不同 在关系型数据库中(以MySQL为例),可以使用delete或者是truncate 进行删除,前者可以根据一定的条件进行删除,而后者是删除整个表。在HBase中,删除的命令是delete 和 deleteall,前者用于删除单元格或者是行集(在某一个列组内删除),后者是删除整个逻辑行(跨越列族的限制)
② IDE 下 CRUD
给定JSON or XML数据
比如:
或者是: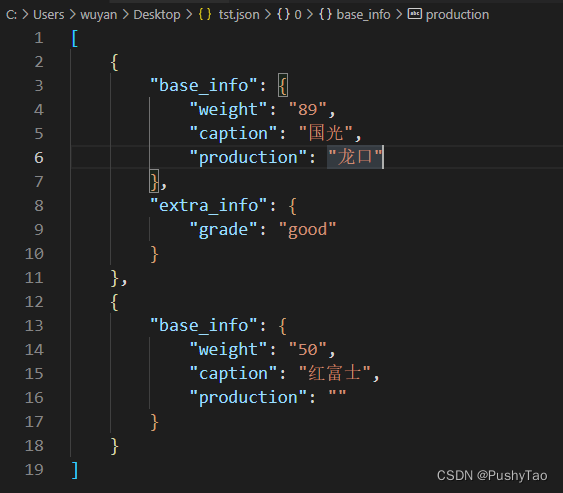
或者是xml格式: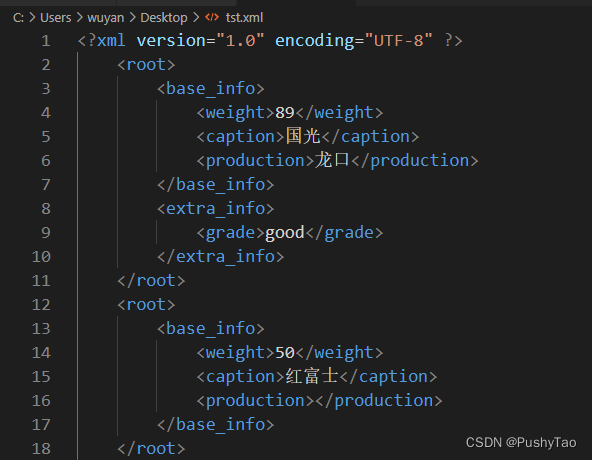
转换为二维表就是: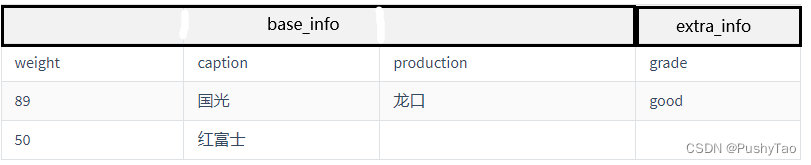
- 连接数据库
publicstaticvoidgetConnect()throwsIOException{
conf.set("hbase.zookeeper.quorum","master315");
conf.set("hbase.zookeeper.property.clientPort","2181");//conf.set("zookeeper.znode.parent", "/hbase");try{ connection=ConnectionFactory.createConnection(conf);}catch(IOException e){}}
其中master315为主机名
2. 创建表
//创建一张表,通过HBaseAdmin HTableDescriptor来创建 publicstaticvoidcreateTable(String tablename)throwsException{TableName tableName =TableName.valueOf(tablename);Admin admin = connection.getAdmin();if(admin.tableExists(tableName)){
admin.disableTable(tableName);
admin.deleteTable(tableName);System.out.println(tablename +" table Exists, delete ......");}@SuppressWarnings("deprecation")HTableDescriptor desc =newHTableDescriptor(tableName);@SuppressWarnings("deprecation")HColumnDescriptor colDesc =newHColumnDescriptor("base_info");
colDesc.setBloomFilterType(BloomType.ROWCOL);
desc.addFamily(colDesc);
desc.addFamily(newHColumnDescriptor("extra_info"));
admin.createTable(desc);
admin.close();System.out.println("create table success!");}
- 插入数据
publicstaticvoidaddData(String tablename)throwsException{HTable table =(HTable) connection.getTable(TableName.valueOf(tablename));Put p1 =newPut(Bytes.toBytes("0001"));
p1.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("weight"),Bytes.toBytes(String.valueOf(89)));
p1.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("caption"),Bytes.toBytes("GuoGuang"));
p1.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("production"),Bytes.toBytes("LongKou"));
p1.addColumn(Bytes.toBytes("extra_info"),Bytes.toBytes("grade"),Bytes.toBytes("good"));
table.put(p1);Put p2 =newPut(Bytes.toBytes("0002"));
p2.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("weight"),Bytes.toBytes(String.valueOf(50)));
p2.addColumn(Bytes.toBytes("base_info"),Bytes.toBytes("caption"),Bytes.toBytes("HongFuShi"));
table.put(p2);
table.close();System.out.print("insert successed");}
shell可查: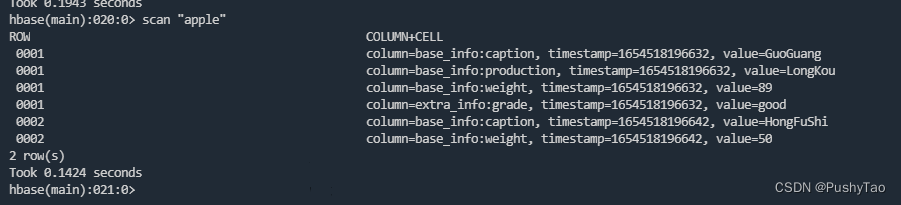
- 浏览全部信息 因为已知插入了两行,所以代码直接for i到2:此代码普适性不够高,但是适合浏览以某一个字符串开头比如"000"开头的row key或者是某一个单独的行
publicstaticvoidgetData(String tablename)throwsIOException{HTable table =(HTable) connection.getTable(TableName.valueOf(tablename));for(int i =1; i <=2; i++){Get get =newGet(Bytes.toBytes("000"+String.valueOf(i)));Result result = table.get(get);if(result !=null&&!result.isEmpty()){for(Cell cell : result.listCells()){String family =Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength());String key =Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());String value =Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());System.out.println(family +" "+ key +": "+ value);}}System.out.println("");}}
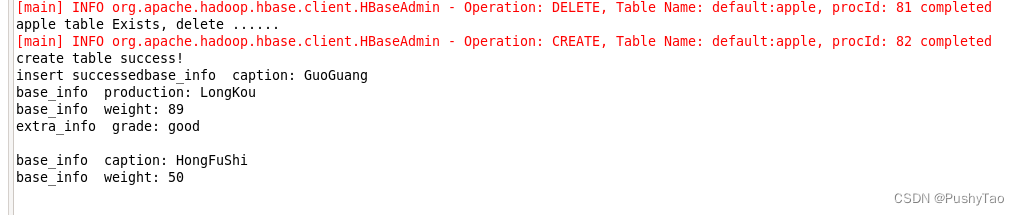
如果说在事先不知道有多少行的情况下,建议采用下面的方法:
publicstaticvoidgetAllRows(String tableName)throwsIOException{HTable table =(HTable) connection.getTable(TableName.valueOf(tableName));Scan scan =newScan();ResultScanner resultScanner = table.getScanner(scan);for(Result result : resultScanner){Cell[] cells = result.rawCells();for(Cell cell : cells){System.out.println("Row Key: "+Bytes.toString(CellUtil.cloneRow(cell)));System.out.println("Column Family: "+Bytes.toString(CellUtil.cloneFamily(cell)));System.out.println("Column: "+Bytes.toString(CellUtil.cloneQualifier(cell)));System.out.println("Calue :"+Bytes.toString(CellUtil.cloneValue(cell))+"\n\n");}}}
结果如下图: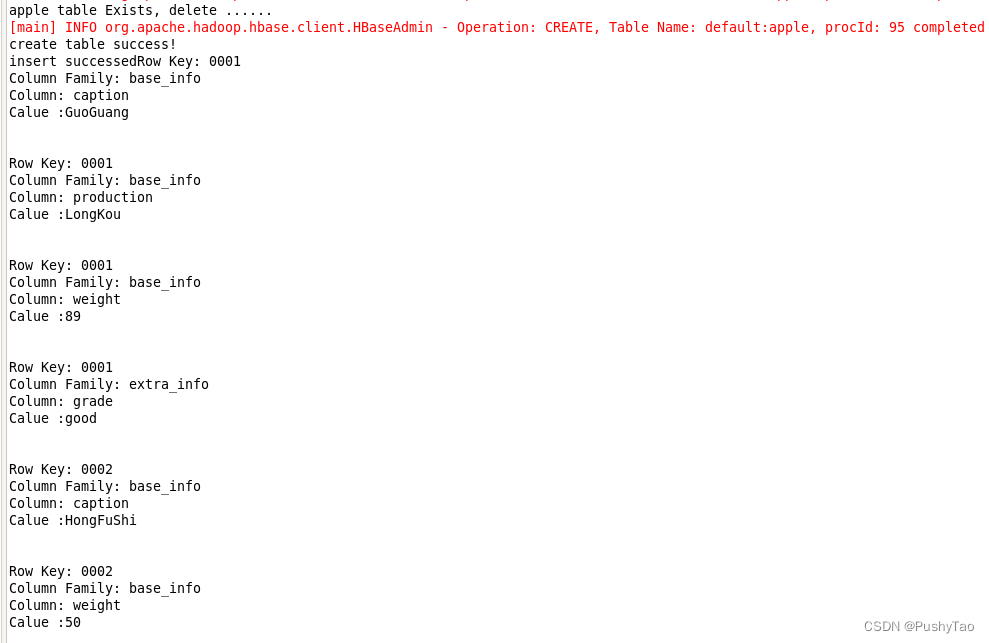
2. Spark(Shell下)
①从外部数据源创建DataFrame
②根据JSON数据转化为二维表
③Spark SQL
④DataFrame基本操作
二
三
版权归原作者 PushyTao 所有, 如有侵权,请联系我们删除。