
目录
欢迎关注 『Python』 系列,持续更新中
欢迎关注 『Python』 系列,持续更新中
省流助手:本文使用windows的Anaconda安装环境,不建议大家用pycharm等其他途径下载环境,你会发现装好环境非常困难,第三方库之间版本的冲突兼容性报错一个接一个,不要浪费时间在无意义的事情上,大佬随意。
官方项目地址
项目地址
https://gitee.com/paddlepaddle/PaddleOCR
Python环境搭建(也就是使用Anaconda的python)
推荐环境:
- PaddlePaddle >= 2.1.2
- Python 3.7
- CUDA10.1 / CUDA10.2
- CUDNN 7.6
如果您已经安装Python环境,可以直接参考2.安装PaddlePaddle(非常不建议,如果你很自信非要不用Anaconda的话)
1. 安装Anaconda
- 说明:使用paddlepaddle需要先安装python环境,这里我们选择python集成环境Anaconda工具包- Anaconda是1个常用的python包管理程序- 安装完Anaconda后,可以安装python环境,以及numpy等所需的工具包环境。
- Anaconda下载:
地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D
- 大部分win10电脑均为64位操作系统,选择x86_64版本;若电脑为32位操作系统,则选择x86.exe
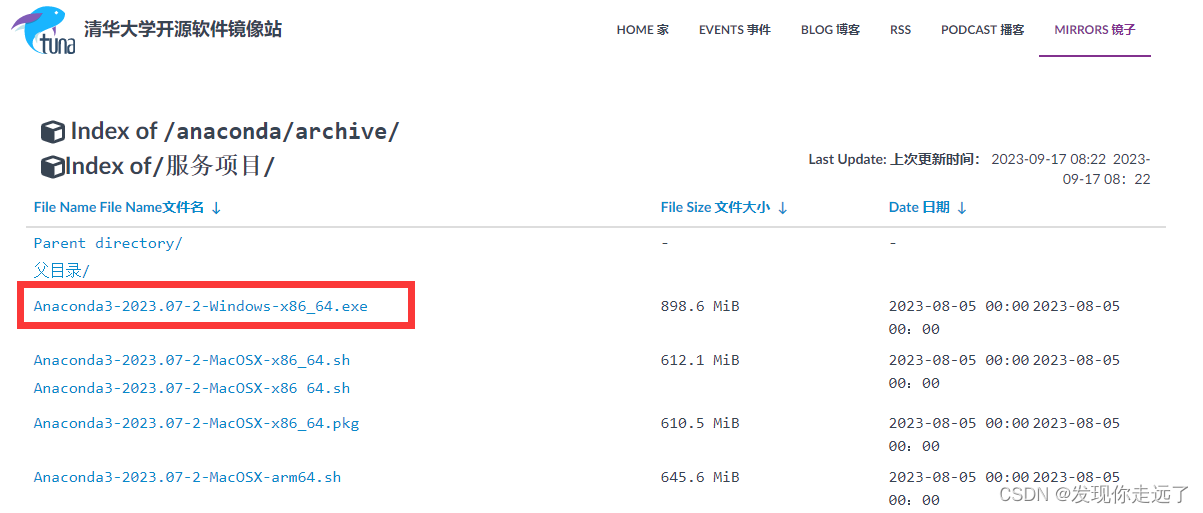
- 下载完成后,双击安装程序进入图形界面
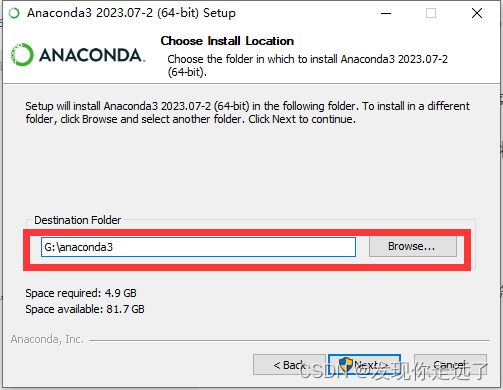
- 默认安装位置为C盘,建议将安装位置更改到自己的盘,特别注意!路径不能有空格和中文,这会影响到部分库的安装!:
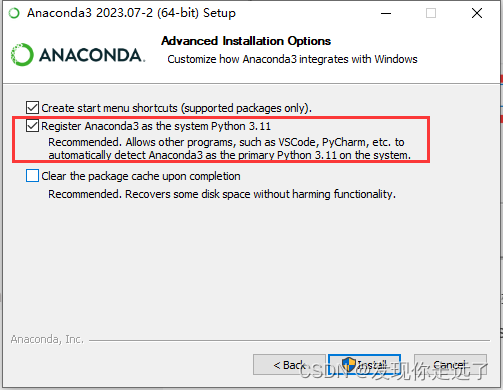
- 勾选conda加入环境变量,忽略警告: 注意勾选后会影响到其他比如vscode pycharm 中对于python的环境变量设定,这个无伤大雅。
1. 打开终端并创建conda环境
- 打开Anaconda Prompt终端:左下角Windows Start Menu -> Anaconda3 -> Anaconda Prompt启动控制台
- 右键以管理员身份打开(部分同学没有开管理员权限的情况)

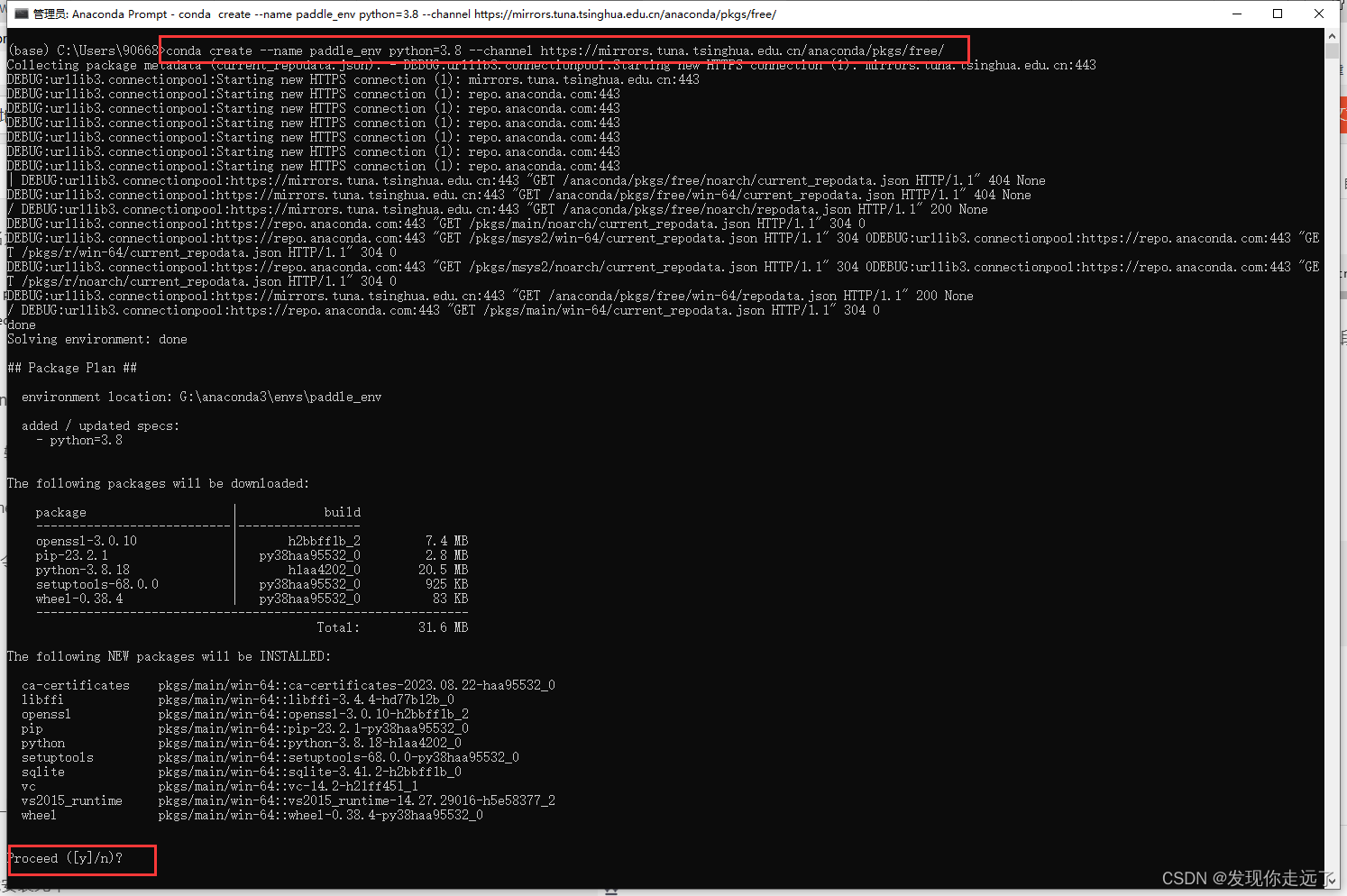
- 创建新的conda环境 在命令行输入以下命令,创建名为paddle_env的环境,此处为加速下载,使用清华源
conda create --name paddle_env python=3.8--channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
该命令会创建1个名为paddle_env、python版本为3.8的可执行环境,根据网络状态,需要花费一段时间
之后命令行中会输出提示信息,输入y并回车继续安装
- 安装完毕
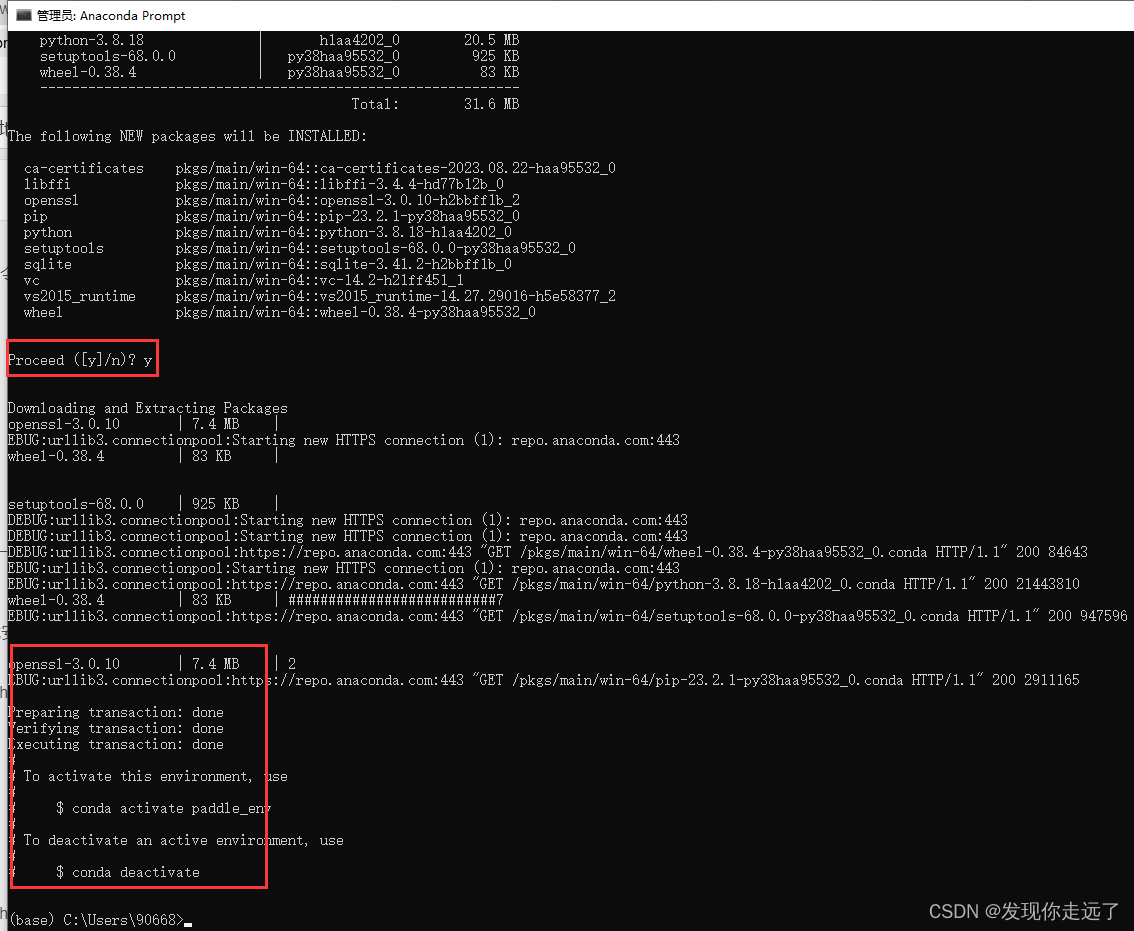
- 激活刚创建的conda环境,在命令行中输入以下命令,这个
conda activate paddle_env激活环境命令是后面的基础,我们的很多操作都要先激活了环境才能继续安装:# 激活paddle_env环境conda activate paddle_env# 查看当前python的位置where python
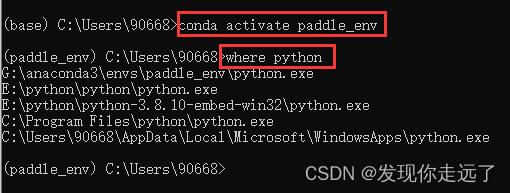
以上anaconda环境和python环境安装完毕
安装PaddlePaddle(CPU演示)
请注意,cmd窗口已经激活了虚拟环境的情况下再执行下面的命令!!
如果您没有基础的Python运行环境,请看前面的一节python环境配置
- 您的机器安装的是CUDA9或CUDA10,请运行以下命令安装
python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple - 您的机器是CPU,请运行以下命令安装(本文演示)
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
更多的版本需求,请参照飞桨官网安装文档中的说明进行操作。
- 一开始安装看到飘红有点慌
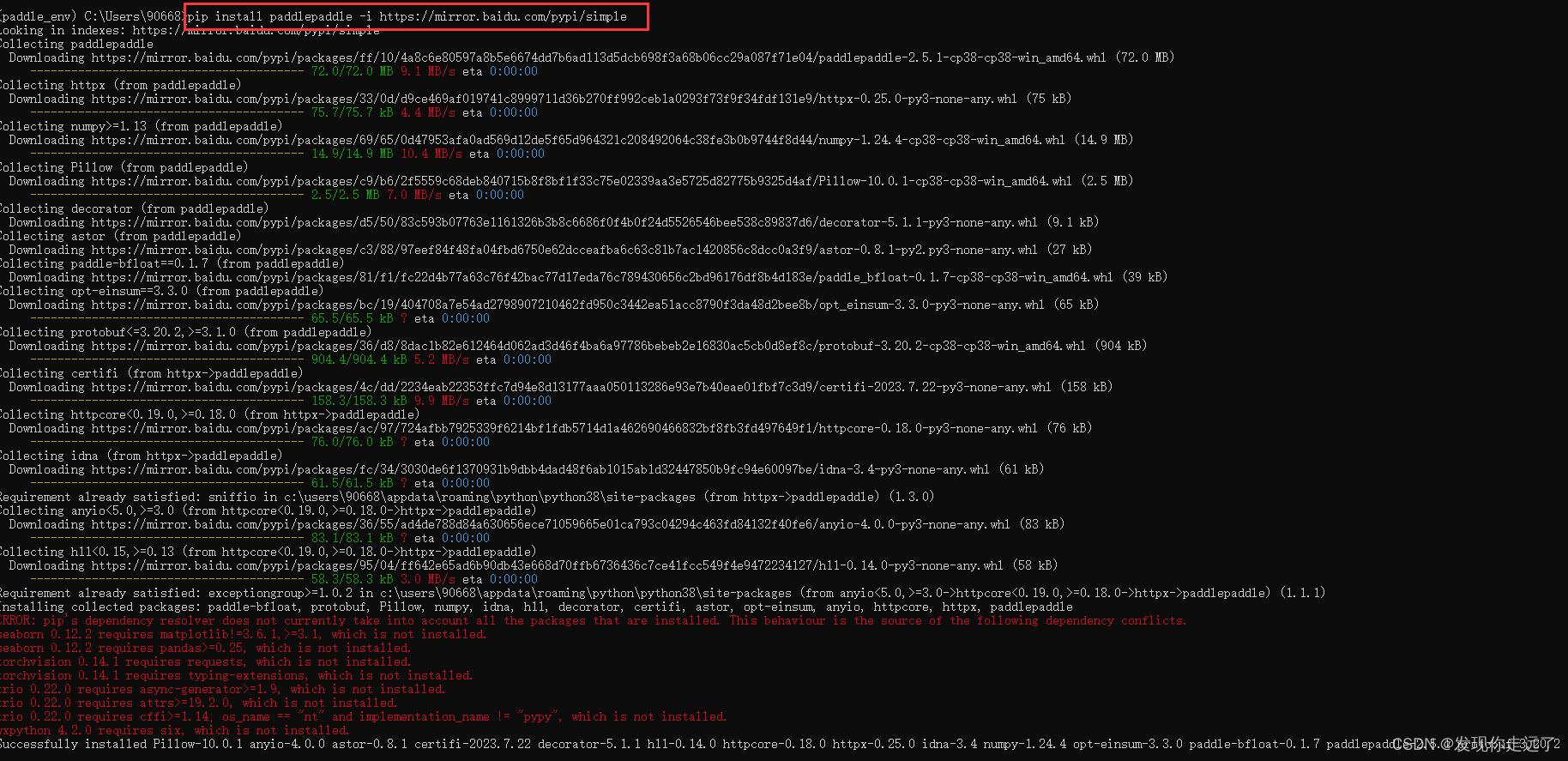
- 但是我发现重新执行一遍命令没有飘红
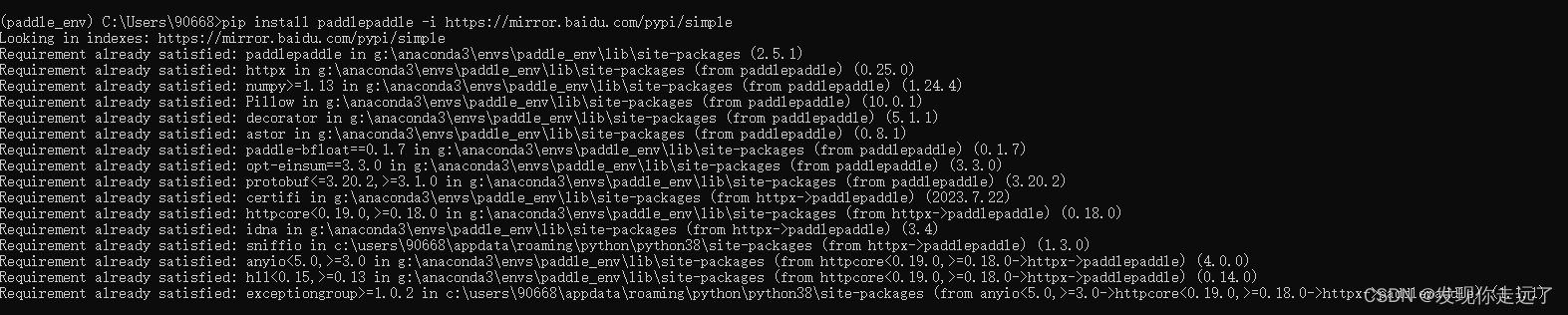
安装PaddleOCR whl包
建议用国内源加速下载!
官网的命令(不建议,下载速度慢)
pip install"paddleocr>=2.0.1"# 推荐使用2.0.1+版本
百度源下载加速(请用我!)
pip install paddleocr -i https://mirror.baidu.com/pypi/simple
- 已经在paddle_env中

- 安装成功结果

如果安装shapely库报错(我没有报错,其他类似库安装失败同理)
- 对于Windows环境用户:直接通过pip安装的shapely库可能出现
[winRrror 126] 找不到指定模块的问题。建议从这里下载shapely安装包完成安装。
shapely下载网址(仅在你命令安装失败时启用),注意这里下载的是cp38(你的python版本3.8) amd64 (64位python,请注意python版本也得是64位)
https://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely
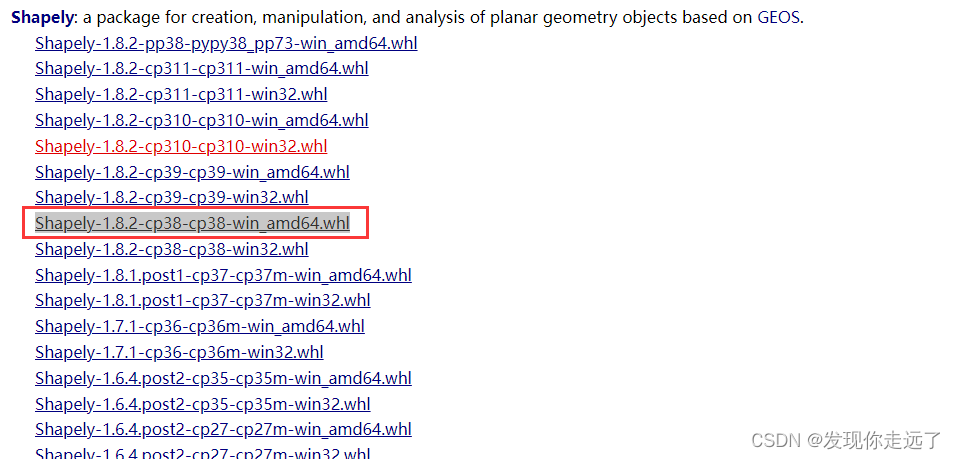
- 把下载得到的whl文件放在
G:\anaconda3\envs\paddle_env\Lib路径下 然后到文件的目录下运行“pip install XXXXX你缺少的库文件.whl”就可以很快完成安装,注意要提前先进入虚拟环境中再安装。
Pycharm中配置编译环境与报错解决
Pycharm中设置使用conda的虚拟环境。
不理解如何配置的看此文
【Python】Pycharm中设置使用conda的虚拟环境(保姆级图文)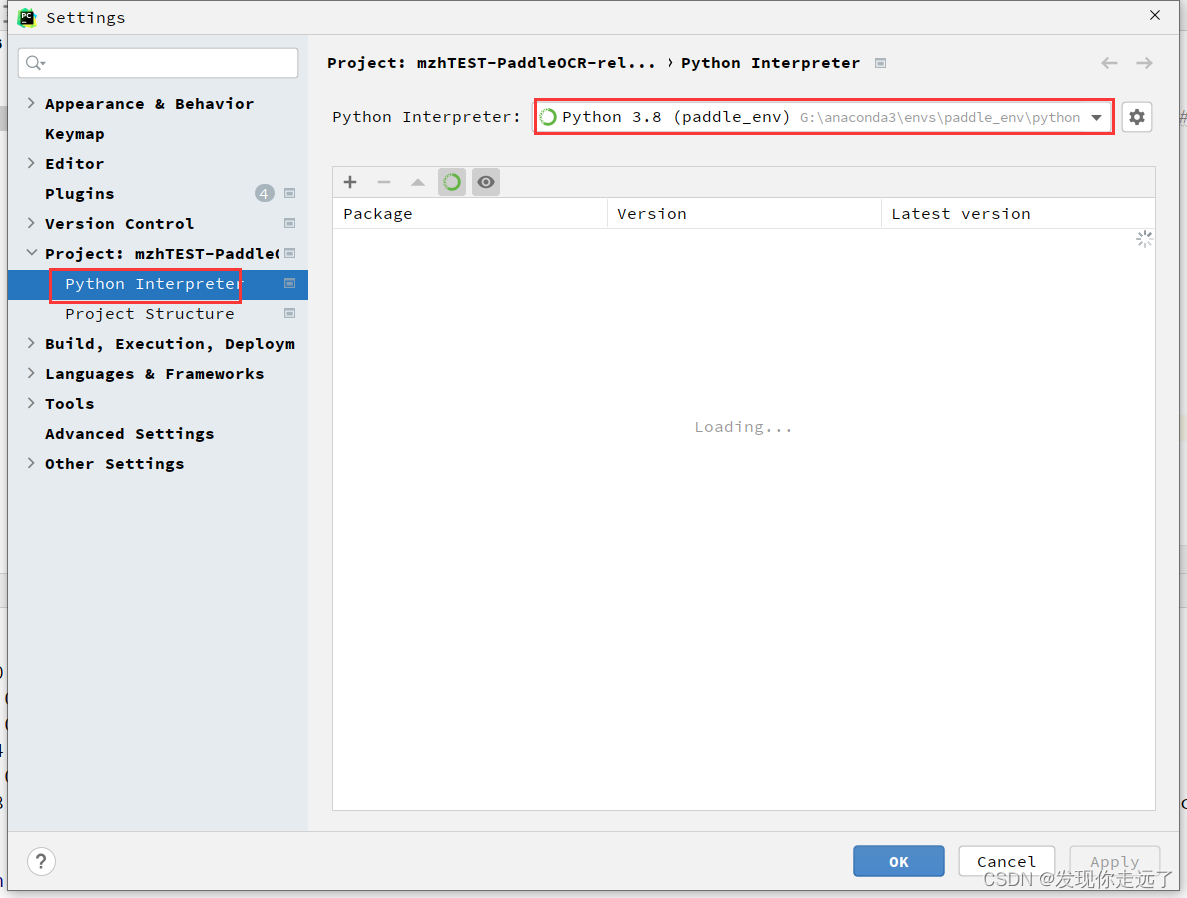
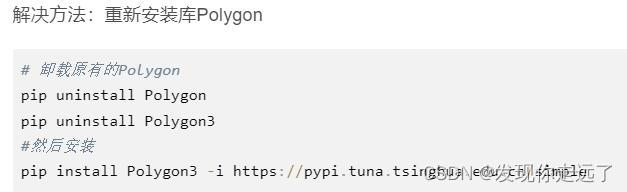
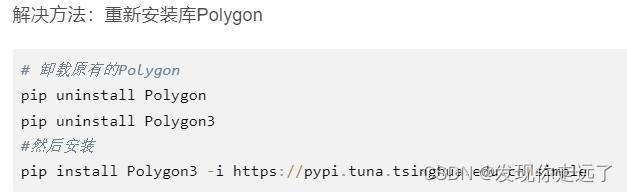
报错1:ModuleNotFoundError: No module named ‘Polygon’

File "E:\allworkspace\python work space\PaddleOCR-release-2.6\ppocr\data\imaug\ct_process.py", line 22,in<module>import Polygon as plg
ModuleNotFoundError: No module named 'Polygon'
解决方法:重新安装库Polygon
# 卸载原有的Polygon
pip uninstall Polygon
pip uninstall Polygon3
#然后安装
pip install Polygon3 -i https://pypi.tuna.tsinghua.edu.cn/simple
报错2:ModuleNotFoundError: No module named ‘lanms’
解决方法:
conda install -f pip
pip install lanms-nova
Python代码测试
- 项目结构

- 被识别的图片
- 识别结果

- 通过Python脚本使用PaddleOCR whl包,whl包会自动下载ppocr轻量级模型作为默认模型,第一次运行代码你会看到下载,是正常的,后面就不会了。
- 下面是测试所用的图片(水印除外,大家用自己的图片)
- 测试代码
######################1.文字识别#########################from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True,# 设置使用方向分类器识别180度旋转文字,处理一些不是正放的文字
use_gpu=True,#使用gpu
lang="ch"#中文识别)
img_path ='testOCR.jpg'
result = ocr.ocr(img_path, cls=True)#进行识别for idx inrange(len(result)):
res = result[idx]for line in res:print(line)#######################2.生成目标检测的图片,用检测框框选文字########################## 显示结果# 如果本地没有simfang.ttf,可以在doc/fonts目录下下载from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes =[line[0]for line in result]
txts =[line[1][0]for line in result]
scores =[line[1][1]for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
总结
大家喜欢的话,给个👍,点个关注!继续跟大家分享敲代码过程中遇到的问题!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2022 mzh
Crated:2022-1-10
欢迎关注 『Python』 系列,持续更新中
欢迎关注 『Python』 系列,持续更新中
【Python安装第三方库一行命令永久提高速度】
【使用PyInstaller打包Python文件】
【更多内容敬请期待】
版权归原作者 发现你走远了 所有, 如有侵权,请联系我们删除。