
操作环境:Ubuntu 20.04.2 LTS x64 in VMware虚拟机
来源
spleeter-github
spleeter-github-wiki
Ubuntu环境变量配置
步骤
安装spleeter
- 打开终端,安装ffmpeg:
sudo apt-get install ffmpeg - 通过pip3安装spleeter:
pip3 install spleeter, (如果未安装pip3的话需要先安装pip3:sudo apt install python3-pip) - 脚本文件会被下载到 /home/[当前用户名]/.local/bin ,提前将此目录加入环境变量以便于直接输入命令执行脚本:
另:如何添加全局环境变量
- 输入
sudo gedit /etc/profile,输入密码后在profile文件的最后一行添加:export PATH="$PATH:/home/[当前用户名]/.local/bin",保存后注销用户,重新登录。 - 通过
echo $PATH检查目录是否已经加入环境变量
开始提取
使用默认的二枝干(2stems)预训练模型,提取得到伴奏(accompaniment)和人声(vocals):
- 打开终端,输入命令:
spleeter separate -o [输出目录] [输入文件], 例如:spleeter separate -o /home/code/Music /home/code/Music/test.mp3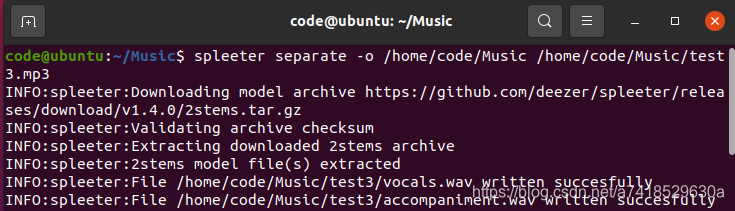
- 在输出目录下会产生以“输入文件名”为名的文件夹,其中有 accompaniment.wav 和 vocals.wav 两个文件,对应前述的伴奏和人声。
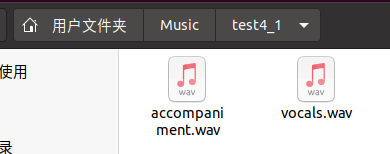
- 成功得到伴奏。效果尚可,明显优于单纯的中置声道提取。
问题反馈
- 对于总时长超过10分钟的单个音频,处理结束后也只会返回10分钟的结果。建议在处理过长的音频时将其在“声音很小”的地方进行分割。 因为处理后的文件在开头和结尾处会有一定时长的静音部分,不做任何处理将分割后的部分处理完拼接起来会导致分割点前后有明显的音量不匹配。
- 对虚拟机/实体机内存空间要求较高,处理较长时间的音频时建议调整内存大小至4G以上。 实测4G大约能处理4分钟多的音频,超过此长度运行脚本时终端会返回“已杀死”。我这里实际调整为8G内存。
- spleeter还有其他的匹配模型和操作方式,具体可参考开头的wiki。
本文转载自: https://blog.csdn.net/a7418529630a/article/details/115449414
版权归原作者 NGuanghua 所有, 如有侵权,请联系我们删除。
版权归原作者 NGuanghua 所有, 如有侵权,请联系我们删除。