
**本文的所有配置文件,除注释部分都可直接复制粘贴。因为本文的配置文件的语言语法采用的是HTML或JAVA,注释部分可能和linux系统上的不同,因此如果直接复制粘贴记得将注释删除或调整语法。 **
一、单机安装
1、安装虚拟机、操作系统(前期初步准备工作已完成)先关闭firewalld防火墙:
systemctl stop firewalld //停止防火墙
systemctl disable firewalld //关闭防火墙开机自启动
systemctl status firewalld //查看防火墙状态
2、设置主机名:
hostnamectl set-hostname master //设置主机名为master
hostname //查看主机名
3、映射主机名和IP地址:
ip add //查看IP地址
vi /etc/hosts //在文件最后一行加上IP地址和主机名
例:192... master
4、安装rz命令:
yum install -y lrzsz
5、利用rz将JDK上传至服务器:
mkdir -p /export/server //新建一个专用目录
cd /export/server //切换目录
rz
tar -zxvf /root/jdk.tar.gz //解压
mv jdk1.8.0_131/ jdk1.8 //重命名
6、配置JAVA环境
vi /etc/profile
//在文件最后加上
JAVA_HOME=/export/server/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
//保存并退出后,刷新文件
source /etc/profile
//查看jdk是否安装成功,出现版本号即可
java -version
7、上传hadoop压缩包至服务器并解压:
cd /export/server
rz
tar -zxvf /root/hadoop-2.7.2.tar.gz
//配置hadoop环境变量
cd hadoop-2.7.2
pwd //显示hadoop安装路径,方便后续配置
vi /etc/profile
//在文件最后加上
HADOOP_HOME=/export/server/hadoop-2.7.2
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME HADOOP_HOME PATH
//保存并退出后,刷新文件
source /etc/profile
//查看hadoop是否安装成功
hadoop version
二、伪分布式环境搭建
搭建伪分布式前提条件:文章上面的基础hadoop、jdk环境搭建完成
which java //查看java所在位置
vi hadoop-env.sh
//将export JAVA_HOME的值修改为我们安装的JDK路径
export JAVA_HOME=/export/server/jdk1.8
进入hadoop/etc/hadoop目录:
cd /export/server/hadoop/etc/hadoop
修改core-site.xml:
vi core-site.xml
如果配置了存放临时文件则需要创建一个目录:
mkdir -p /export/server/hadoop-2.7.2/data/tmp
<configuration>
<property>
<name>fs.defaultFS</name> <!--设定namenode的主机名及端口-->
<value>hdfs://master:9000</value>
</property>
<!--下面的不想要,可以不写-->
<property>
<name>hadoop.tmp.dir</name> <!--存放临时文件的目录,不想要可以不写-->
<value>/export/server/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
修改hdfs-site.xml:
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> <!--设定HDFS存储文件的副本个数,默认为3-->
</property>
<property>
<name>dfs.secondary.http.address</name> <!--SecondaryNameNode地址和端口-->
<value>master:50070</value>
</property>
</configuration>
修改mapred-site.xml:
这个文件是不存在的,但是有一个模板文件mapred-site.xml.template,我们将这个文件改名为mapred-site.xml,然后进行修改:
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value> <!--告诉hadoop mapreduce运行在yarn-->
</property>
</configuration>
修改yarn-site.xml:
vi yarn-site.xml
该文件为Yarn框架配置文件,配置ResourceManager,nodeManager的通信端口,web监视端口等
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value><!--指定ResourceManger的地址-->
</property>
<property>
<name>yarn.nodemanager.aux-services</name> <!--指定NodeManager获取数据的方式的shuffle-->
<value>mapreduce_shuffle</value>
</property>
</configuration>
格式化DFS:
hdfs namenode -format
如果在格式化的日志中出现succefully format就证明格式化成功
启动所有服务:start-all.sh
关闭所有服务:stop-all.sh
配置SSH免密登录
输入:
ssh-keygen -t rsa
按四次回车
建立密钥对:
cd /root/.ssh
查看:ll
私钥:id_rsa
公钥:id_rsa.pub
ssh-copy-id将本机的公钥复制到远程机器的authorized_keys文件中,这里是伪分布式,只有一台机器,所以仍然是master然后需要输入master的root用户密码:
ssh-copy-id master
可以查看:记录多台机器的公钥,让机器之间使用ssh不需要用户名和密码:
#more authorized_keys
可以看到authorized_keys中的内容就是id_rsa.pub的内容,再次使用start-dfs.sh和start-yarn.sh,发现不需要输入密码了,实现免密登录。
三、完全分布式环境搭建
1、先将可以联网的单机,克隆三台:master、slave1、slave2
没有创建单机,直接搭建完全分布式的。可以创建三台虚拟机,然后配置好基础的hadoop、jdk环境,效果等于克隆三台单机。单机配置可看上文
2、把每台的文件都修改一下:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
按规划设置各节点IP,网段取决于自己的电脑。为方便记忆,建议master节点IP尾数用200,slave用201,slave用202
//将UUID删除
//修改IPADDR=网段
例:
master的IPADDR=192...200
slave1的IPADDR=192...201
3、重启网络服务:systemctl restart network
4、为了方便,三台都重命名:hostnamectl set-hostname 名字
例:master主节点重命名:hostnamectl set-hostname master
如果是用远程连接工具修改,需要重新连接才会显示修改后的名字
5、修改hosts文件,在主节点映射IP地址和主机名(每个节点都要)
vi /etc/hosts
//在文件最后加上:
//主节点IP地址+ master 例:192...200 master
//从一节点IP+ slave1
//从二节点IP+ slave2
6、将配置好的hosts文件发送给两个从节点:
scp /etc/hosts slave1:/etc/hosts
scp /etc/hosts slave2:/etc/hosts
7、查看三台时间是否相同:date
如果时间不同,手动时间同步:
安装NTP服务:yum install ntp
时间同步(三台都要):ntpdate -u ntp1.aliyun.com
查看防火墙是否开启:systemctl status firewalld.service
如果开启,则关闭:systemctl stop firewalld.service
设置免密
1、删除三台机上的.ssh目录:rm -rf /root/.ssh
2、生成新密钥对(三台都要):ssh-keygen -t rsa
连按三次回车
3、切换目录,将三个节点的.ssh目录下的公钥复制到主节点(master)上(前提是你已经在主节点把/etc/hosts文件配置好并分发给了两台从节点,不然会报不知道master的错误):
cd /root/.ssh
ssh-copy-id master (三个都要)
4、查看是否复制成功(要在/root/.ssh下):
cat authorized_keys
5、在主节点上远程拷贝到两个从节点:
scp authorized_keys slave1:/root/.ssh/authorized_keys
scp authorized_keys slave2:/root/.ssh/authorized_keys
在执行过程中输入yes并输入密码
验证:ssh slave1 可以切换
第五点也可以直接将master的/root/.ssh拷贝到另外两台主机上
scp -r /root/.ssh slave1:/root
scp -r /root/.ssh slave2:/root
修改配置文件
先在主节点创建三个文件夹:
mkdir -p /export/server/tmp(不配置文件可以不创)
mkdir -p /export/server/hdfs/name(不配置文件可以不创)
mkdir -p /export/server/hdfs/data(不配置文件可以不创)
切换目录:cd /export/server/hadoop-2.7.2/etc/hadoop
修改:vi core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<!--HDFS的URI,设定namenode的主机名及端口-->
</property>
<!--下面可以不配-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/server/tmp</value>
<!--节点上本地的hadoop临时文件夹,之前一定要先建立好-->
</property>
先查看自己的java所在,方便后续配置:which java
修改文件:vi hadoop-env.sh
//大概25行
//export JAVA_HOME=/export/server/jdk1.8 (写自己jdk的存放目录)
修改:vi mapred-env.sh
将java路径写上:
//export JAVA_HOME=/export/server/jdk1.8
修改:vi yarn-env.sh
//将java路径写上
//export JAVA_HOME=/export/server/jdk.18
将文件改名:mv mapred-site.xml.template mapred-site.xml
修改:vi mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<!--指定mapreduce使用yarn框架-->
</property>
修改:vi yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<!--指定resourcemanager所在的hostname,即指定yarn的老大即ResourceManger的地址-->
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<!--NodeManager上运行的附属服务。指定NodeManager获取数据的方式是shuffle需配置成mapreduce_shuffle,才可运行MapReduce程序-->
</property>
修改:vi hdfs-site.xml(默认配好,可以不配)
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/export/server/hdfs/name</value>
<!--namenode上存储hdfs名字空间元数据-->
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/export/server/hdfs/data</value>
<!--datanode上数据块的物理存储位置-->
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<!--副本个数,默认是3,应小于datanode机器数量-->
</property>
vi slaves
将两个从节点的名字写到最后:
slave1
slave2
将文件发送给两个从节点:
scp -r /export/server/hadoop-2.7.2/etc/hadoop slave1:/export/server/hadoop-2.7.2/etc
scp -r /export/server/hadoop-2.7.2/etc/hadoop slave2:/export/server/hadoop-2.7.2/etc
格式化文件:
hdfs namenode -format
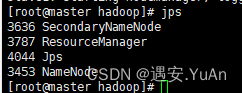
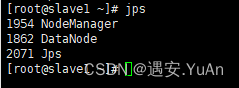
启动集群,主节点有4个,从节点有3个:
start-all.sh

版权归原作者 遇安.YuAn 所有, 如有侵权,请联系我们删除。