
一、Flink的安装模式
1、local(本地)
本地单机模式,一般用于测试环境是否搭建成功,很少使用
2、standload(独立集群模式)
flink自带集群,开发测试使用
StandAloneHA:独立集群的高可用模式,也是flink自带,用于开发测试环境
3、on yarn(flink on yarn)
计算资源统一由hadoop yarn管理,生产环境使用
二、Local模式下的安装
1、下载
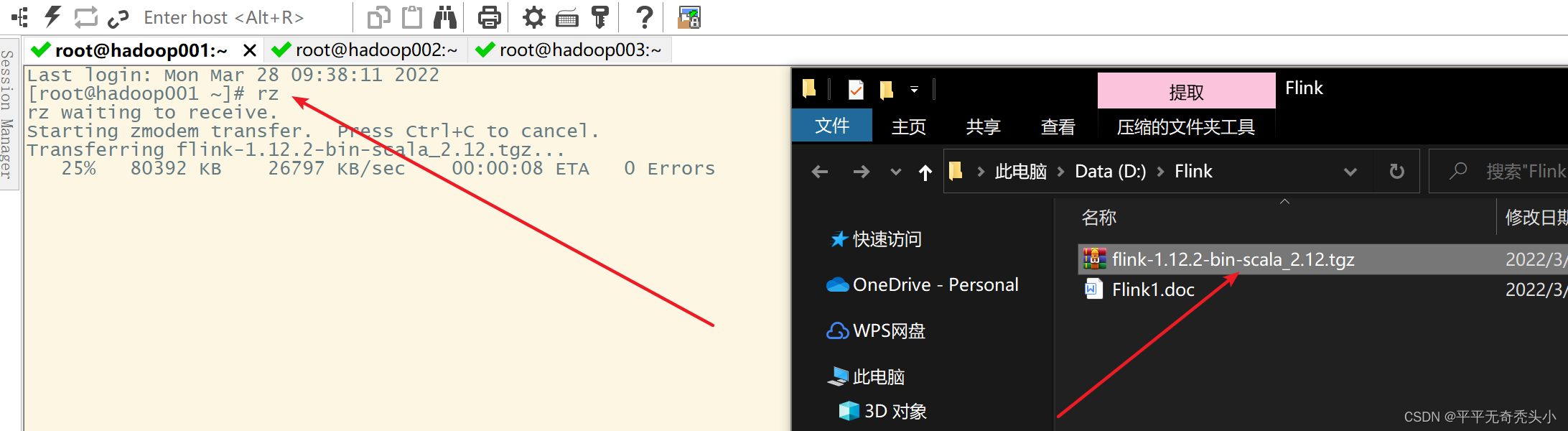
2、上传文件
上传到hadoop001
3、解压
[root@hadoop001 software]# tar -xzvf flink-1.12.2-bin-scala_2.11.tgz -C /export/servers/

4、查看文件目录
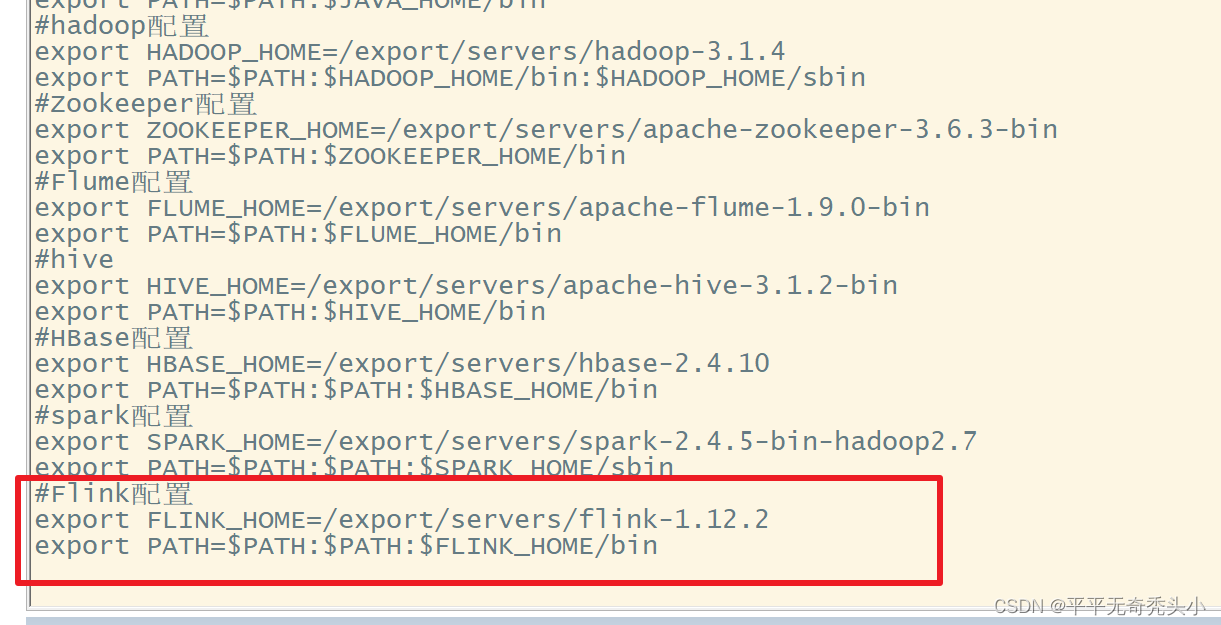
5、修改环境变量
[root@hadoop001 software]# vi /etc/profile
6、使环境变量起作用
[root@hadoop001 software]# source /etc/profile

7、查看安装成功的flink
三、启动scala sell 交互界面
[root@hadoop001 flink-1.12.2]# start-scala-shell.sh local
1、scala命令行示例——单词计数
准备好数据文件
单词计数
benv.readTextFile("/root/a.txt").flatMap(.split(" ")).map((,1)).groupBy(0).sum(1).print()

Ctrl+d退出
四、启动flink本地集群
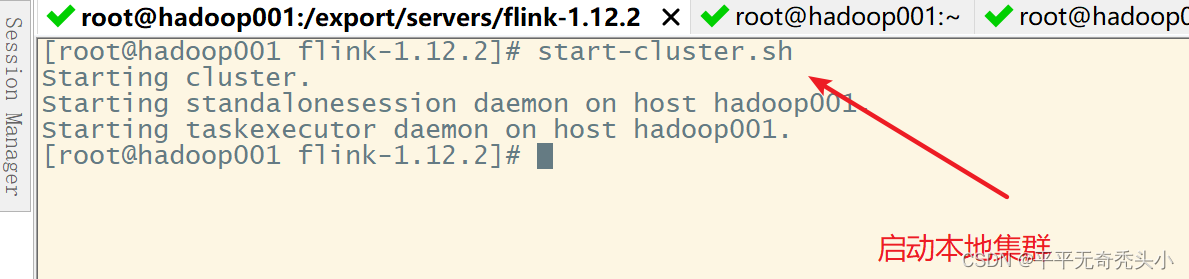
1、启动local本地模式
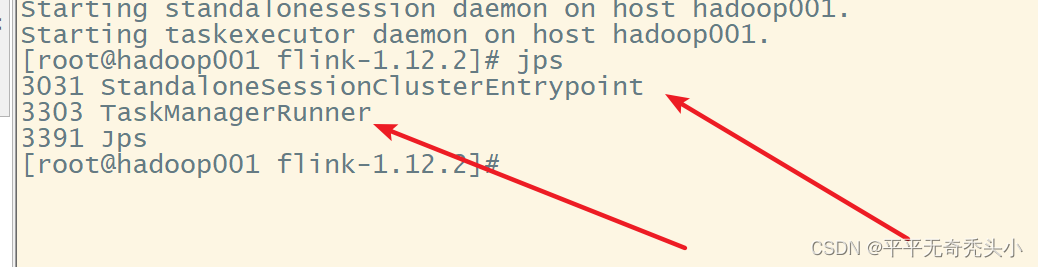
只有hadoop001上有节点
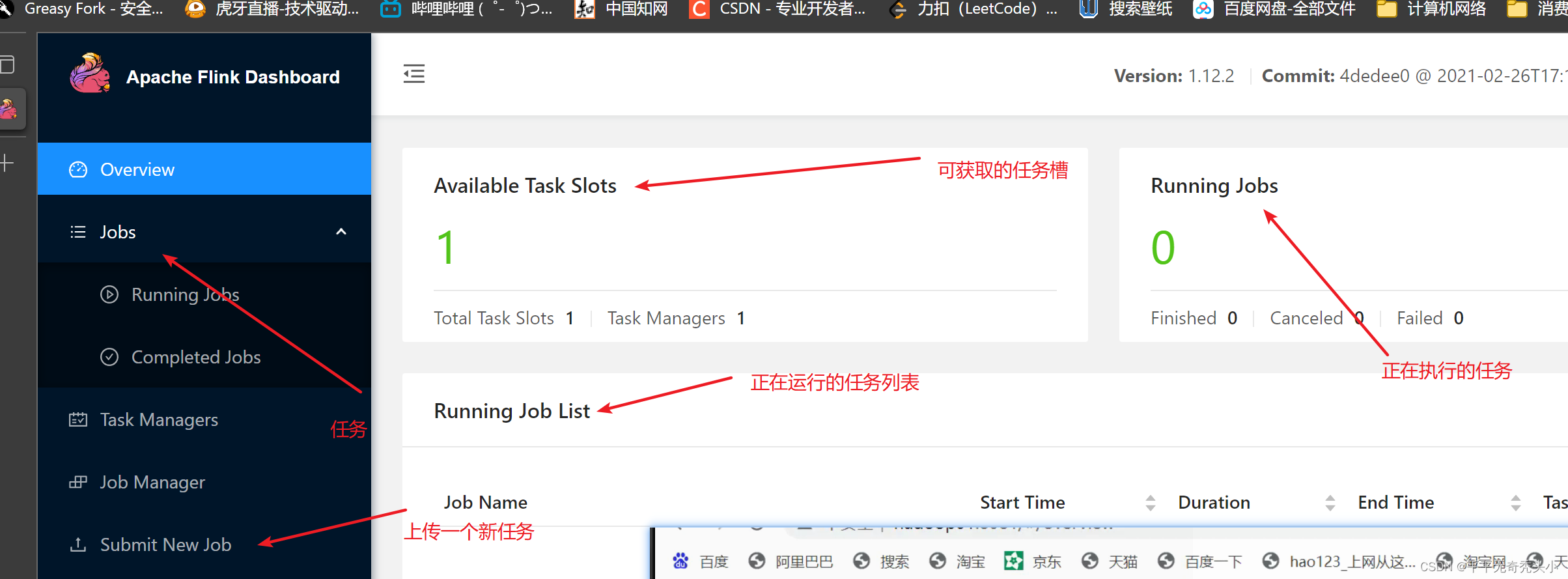
2、使用webui查看
hadoop001:8081
3、Local集群上测试运行任务——单词计数
1)准备jar包
2)提交任务

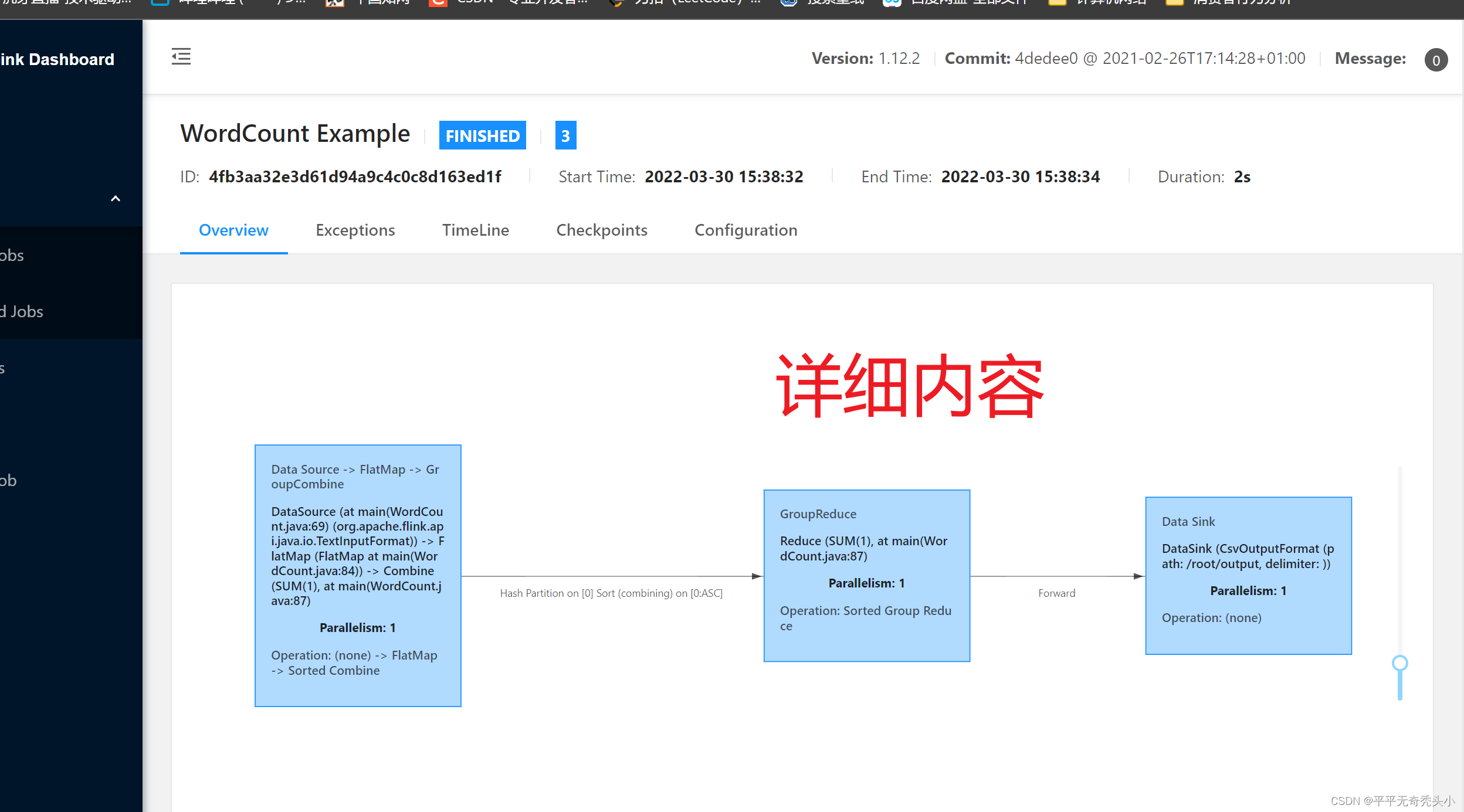
3)在webui查看完整任务过程
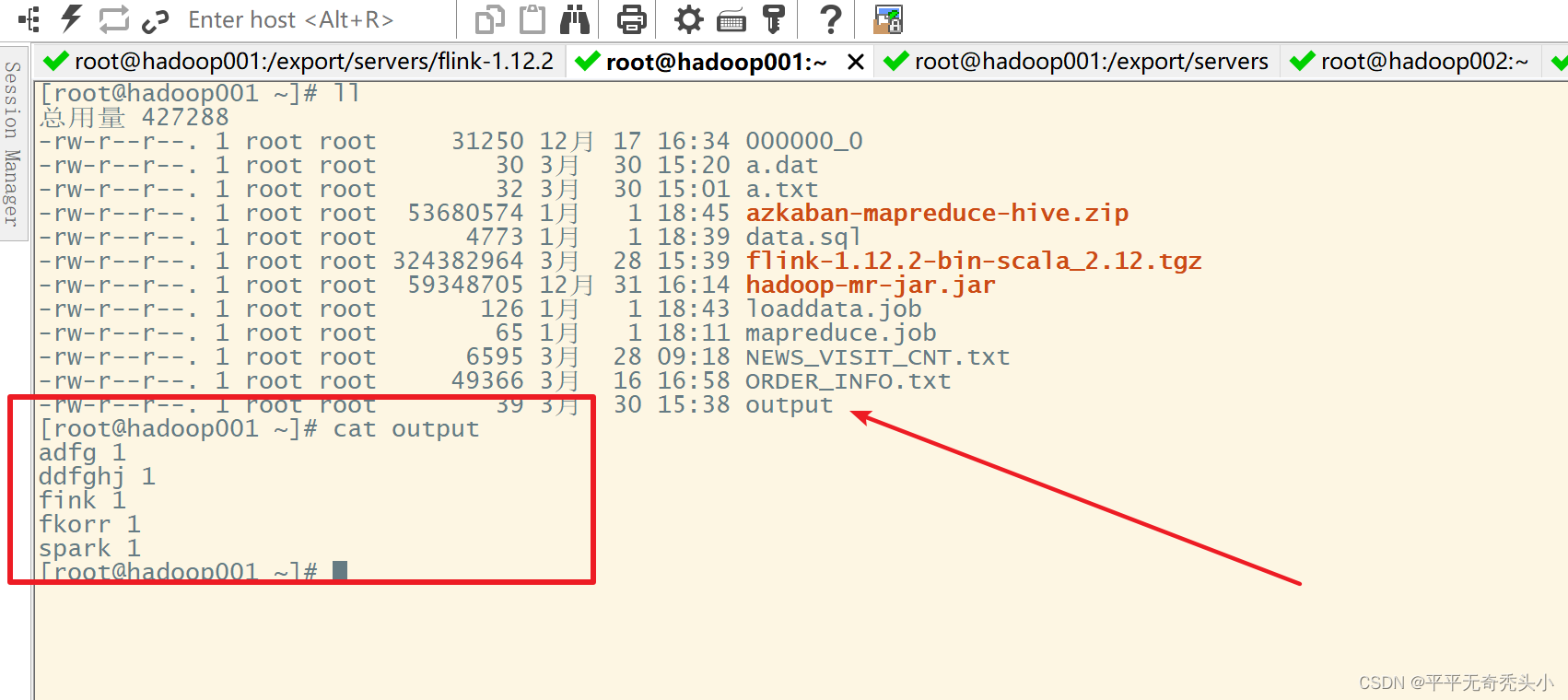
4)查看结果
五、Standalone模式安装
1、集群规划
JobManager
TaskManager
hadoop01
y
y
hadoop02
n
y
hadoop03
n
y
2、修改Flink配置文件
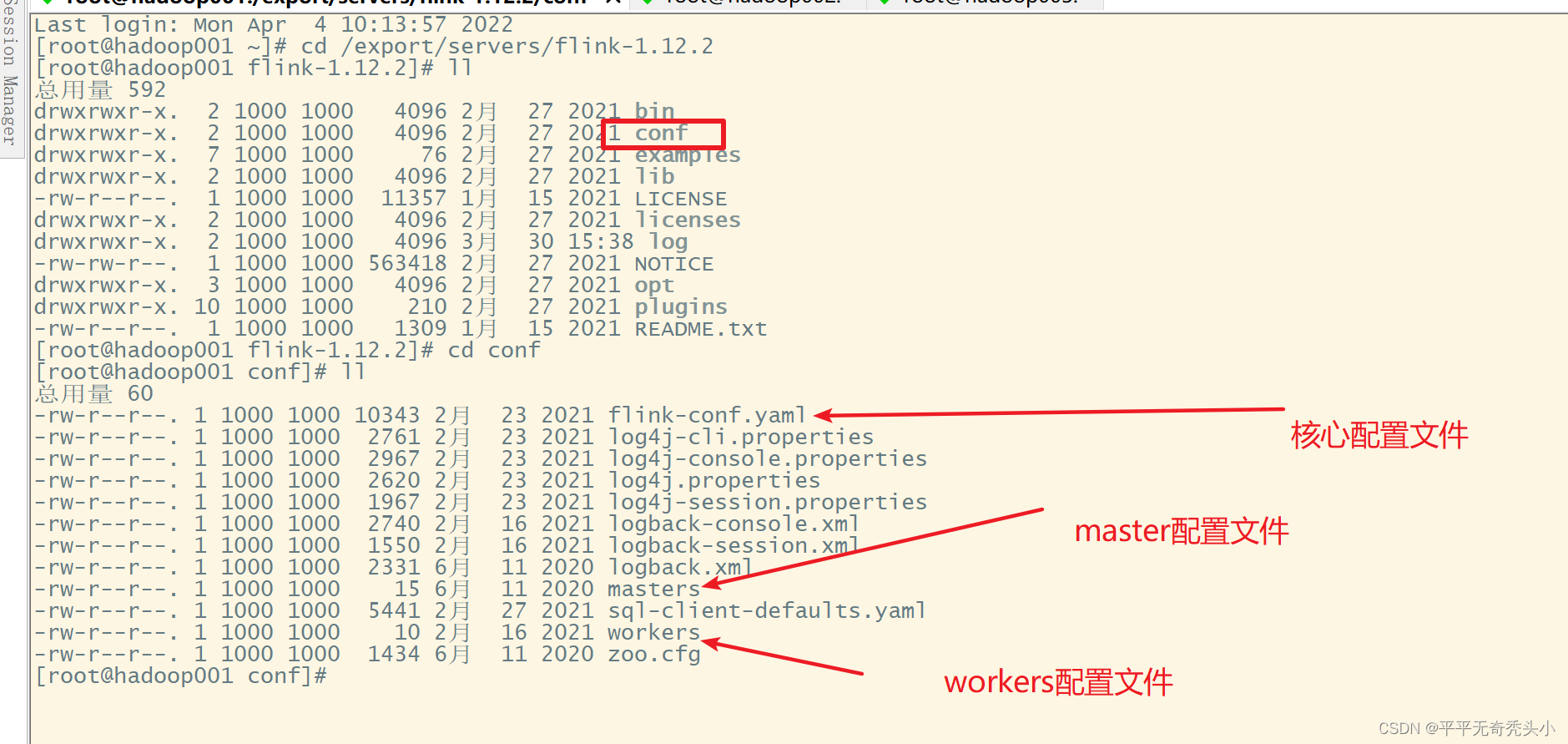
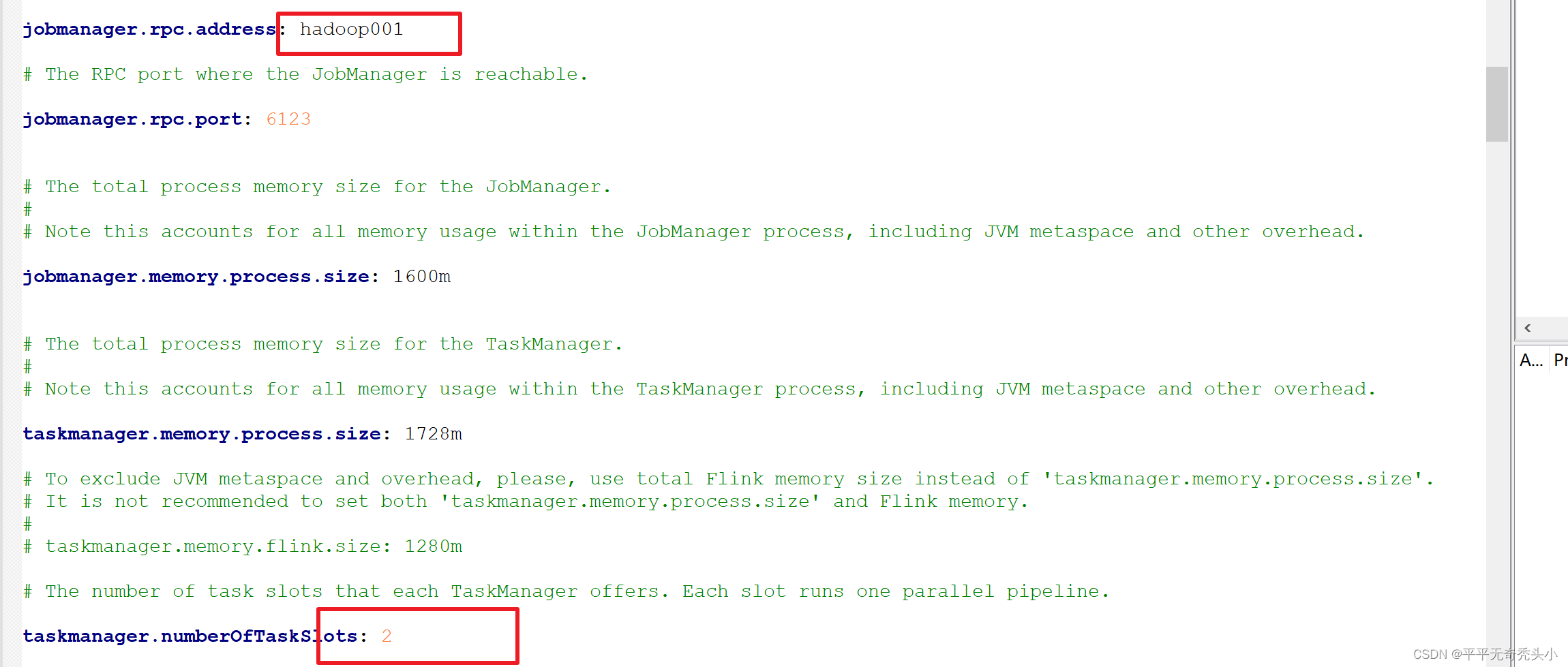
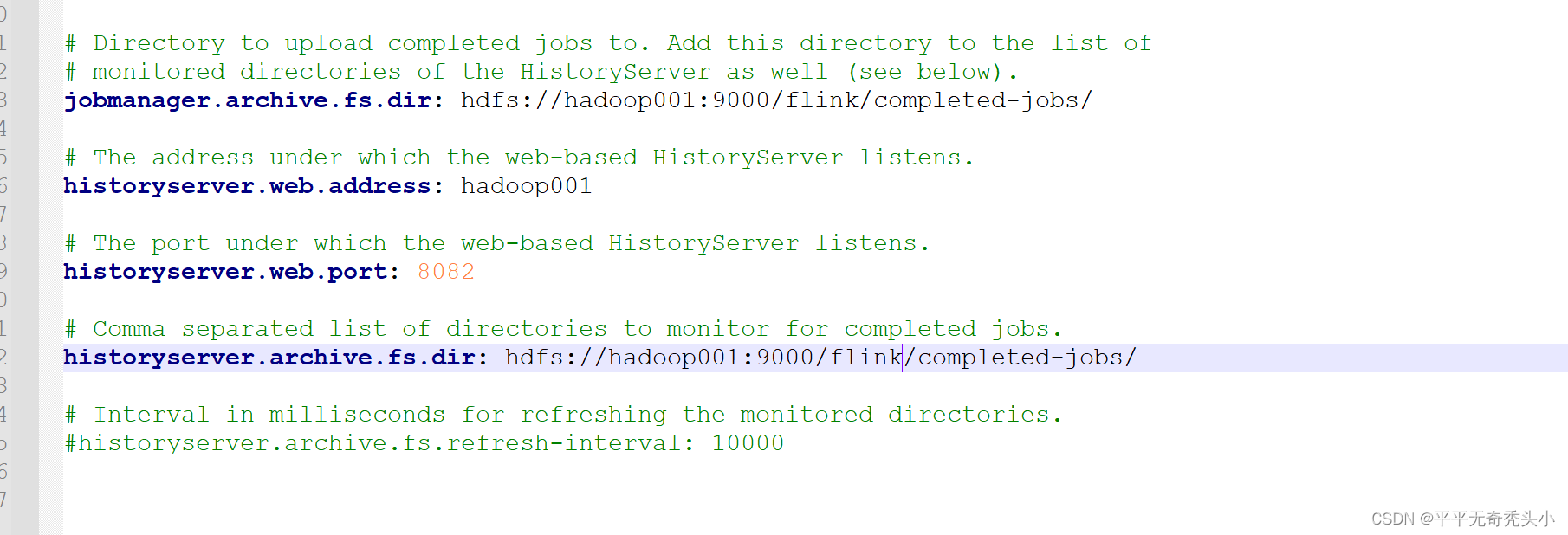
1)修改flink-conf.ymal配置文件

2)Master

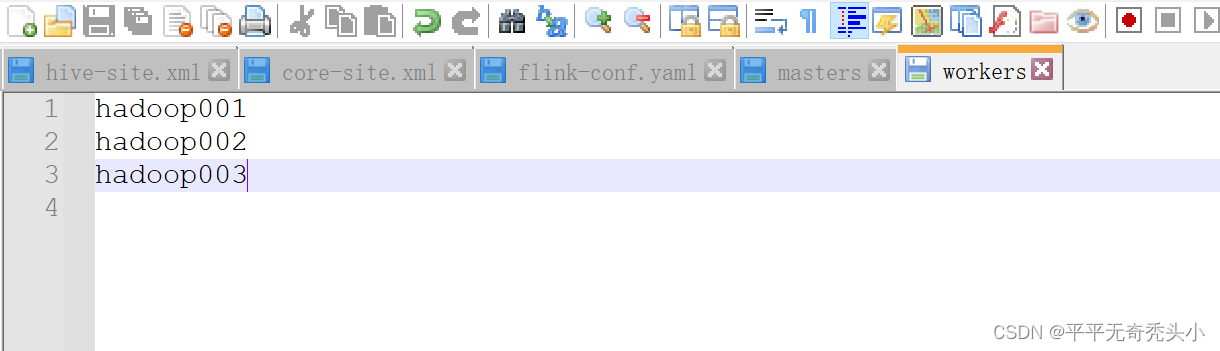
3)workers
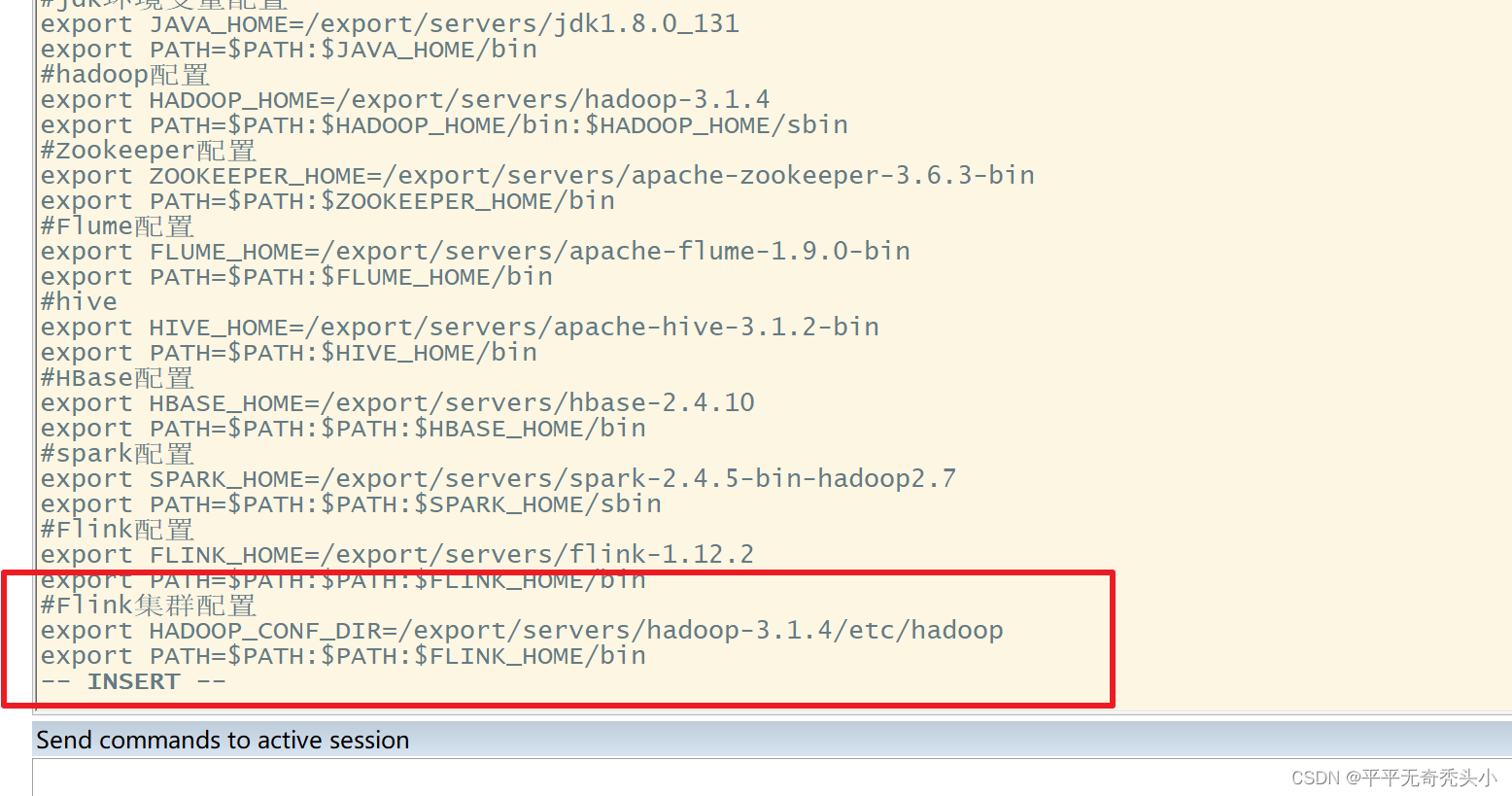
4)环境变量
3、分发文件
1)分发flink
[root@hadoop001 servers]# scp -r flink-1.12.2/ hadoop002:$PWD
[root@hadoop001 servers]# scp -r flink-1.12.2/ hadoop003:$PWD

2)分发环境变量

4、使环境变量起作用
[root@hadoop001 servers]# source /etc/profile
5、启动flink集群
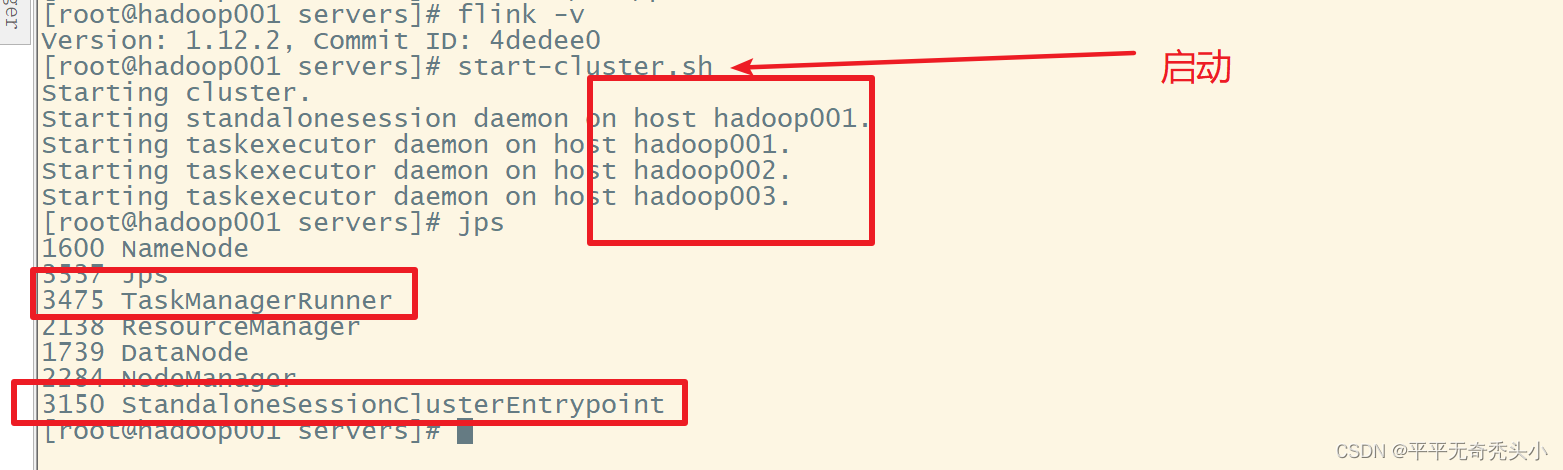
6、webui查看
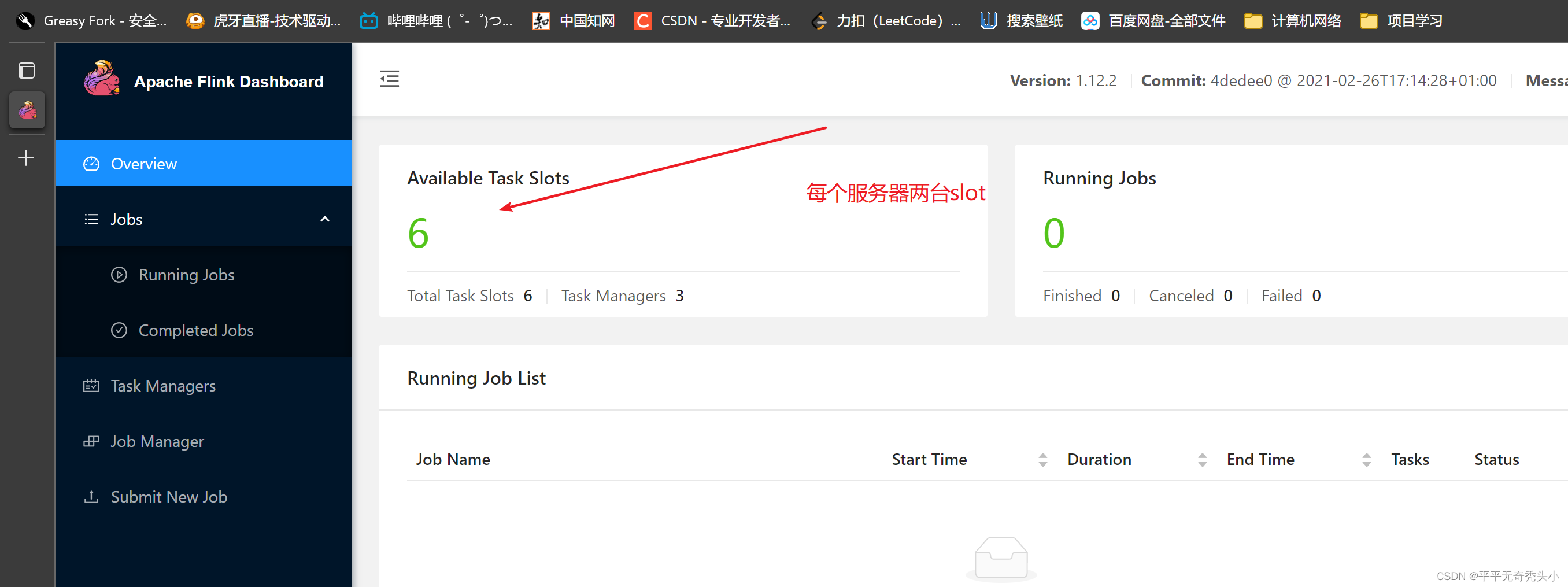
7、启动历史服务器
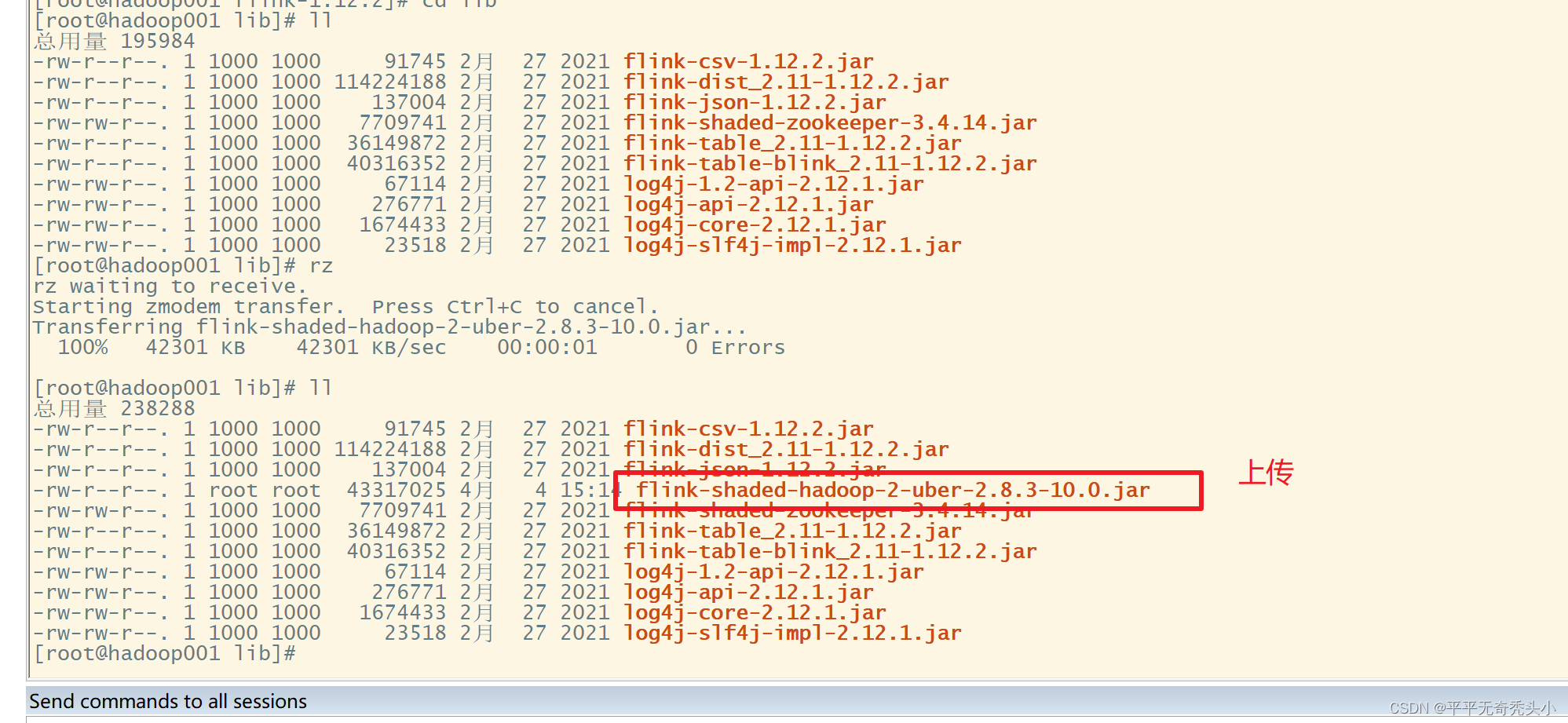
1)上传连接器
2)启动historyserver服务
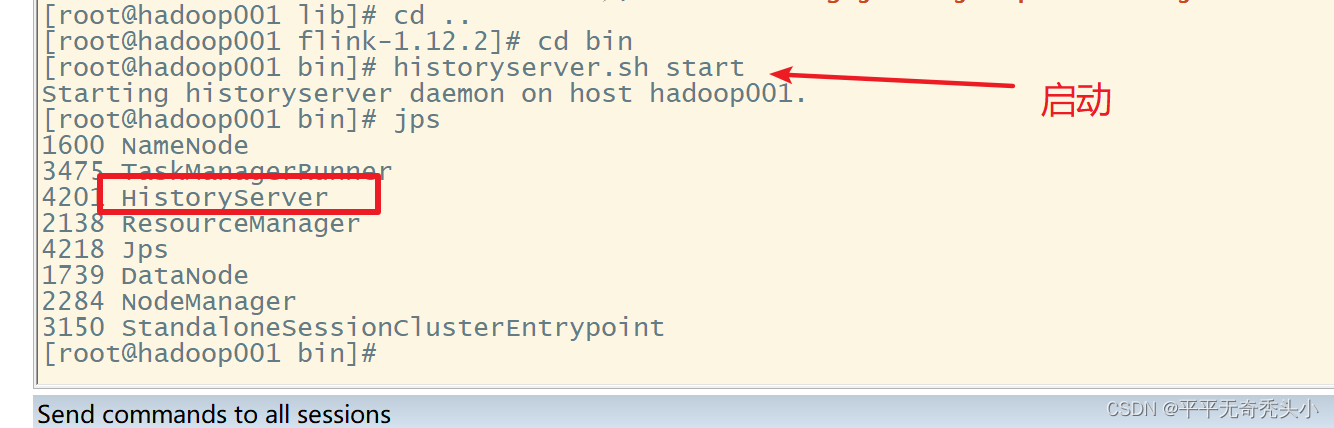
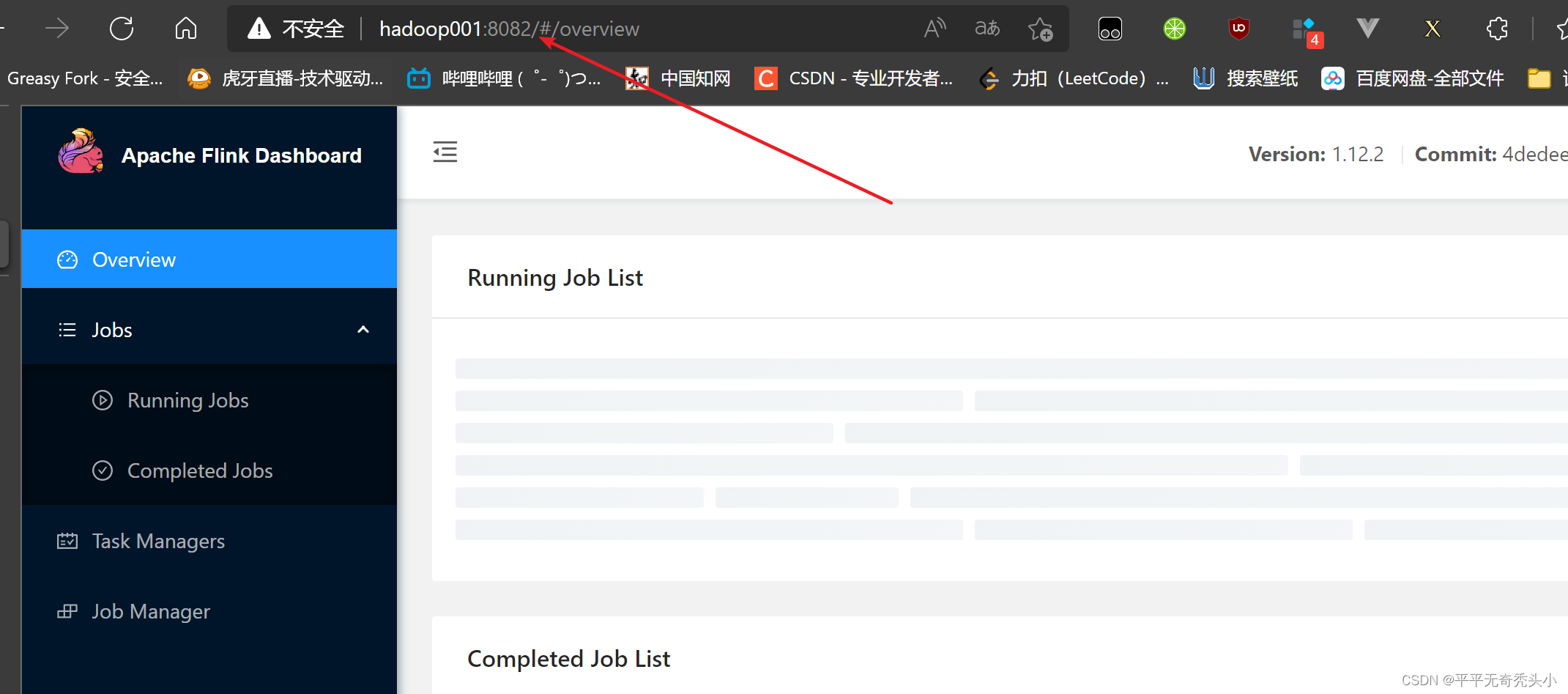
8、历史服务器webui查看
9、Standalone测试任务-单词计数
1)带参数提交任务
flink run examples/batch/WordCount.jar --input hdfs://hadoop001:9000/input/ --output hdfs://hadoop001:9000/output/result.txt
2)出错
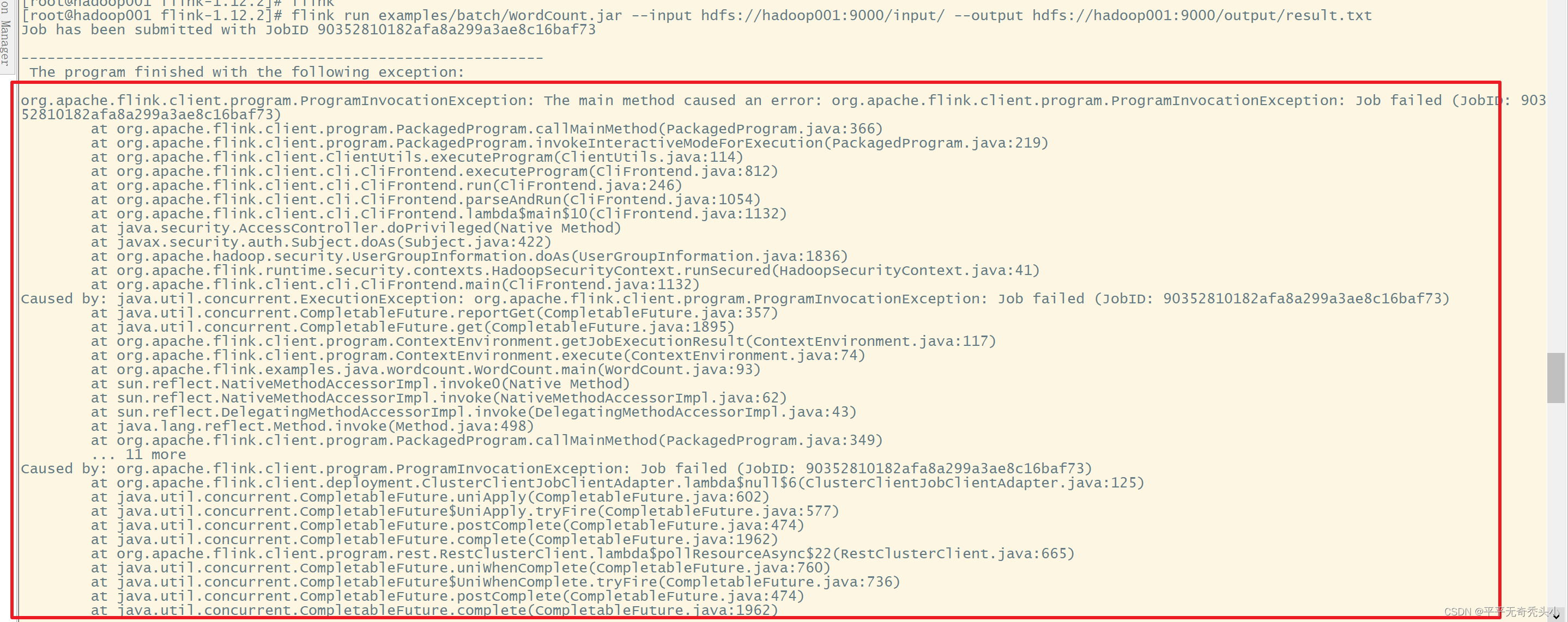
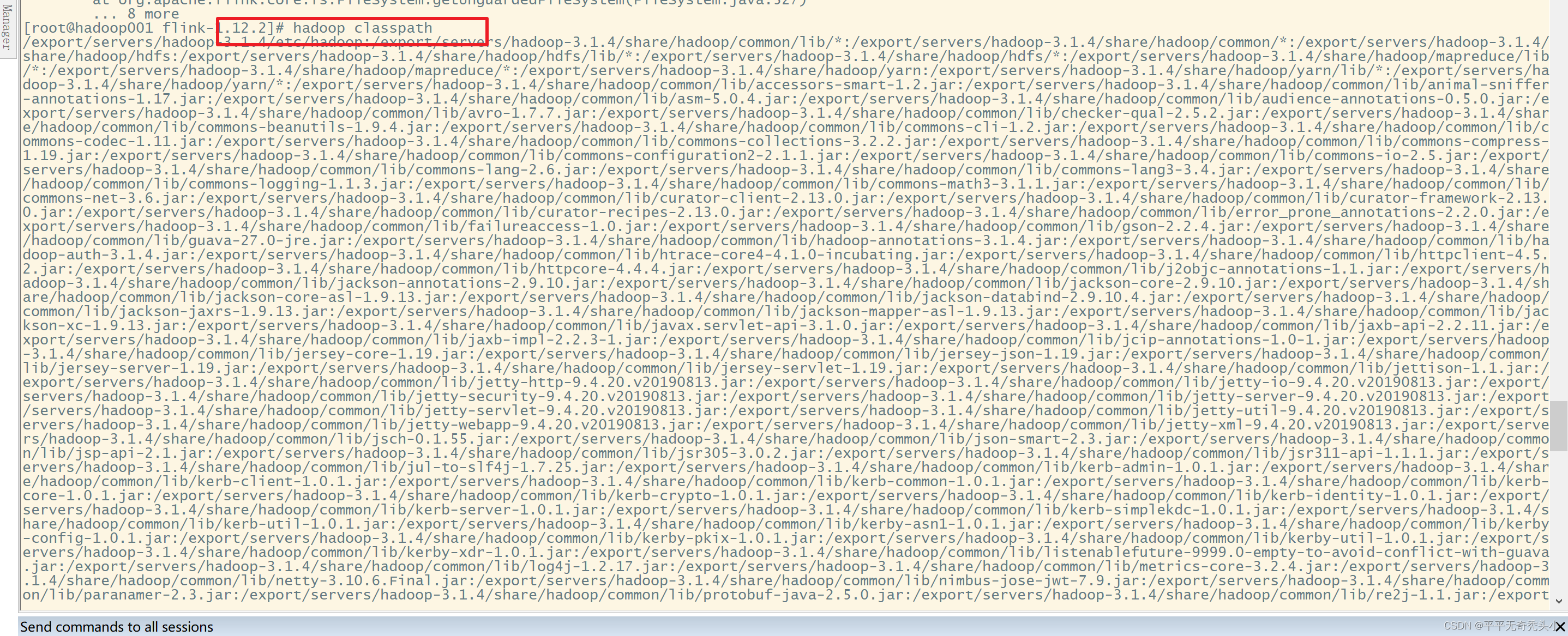
3)添加hadoop classpath配置
[root@hadoop001 flink-1.12.2]# hadoop classpath

4)重新运行
flink run examples/batch/WordCount.jar --input hdfs://hadoop001:9000/input/ --output hdfs://hadoop001:9000/output/result.txt

六、Standalone-HA模式安装
1、集群规划
JobManager TaskManager
hadoop01 y y
hadoop02 Y y
hadoop03 n y
2、停止flink集群
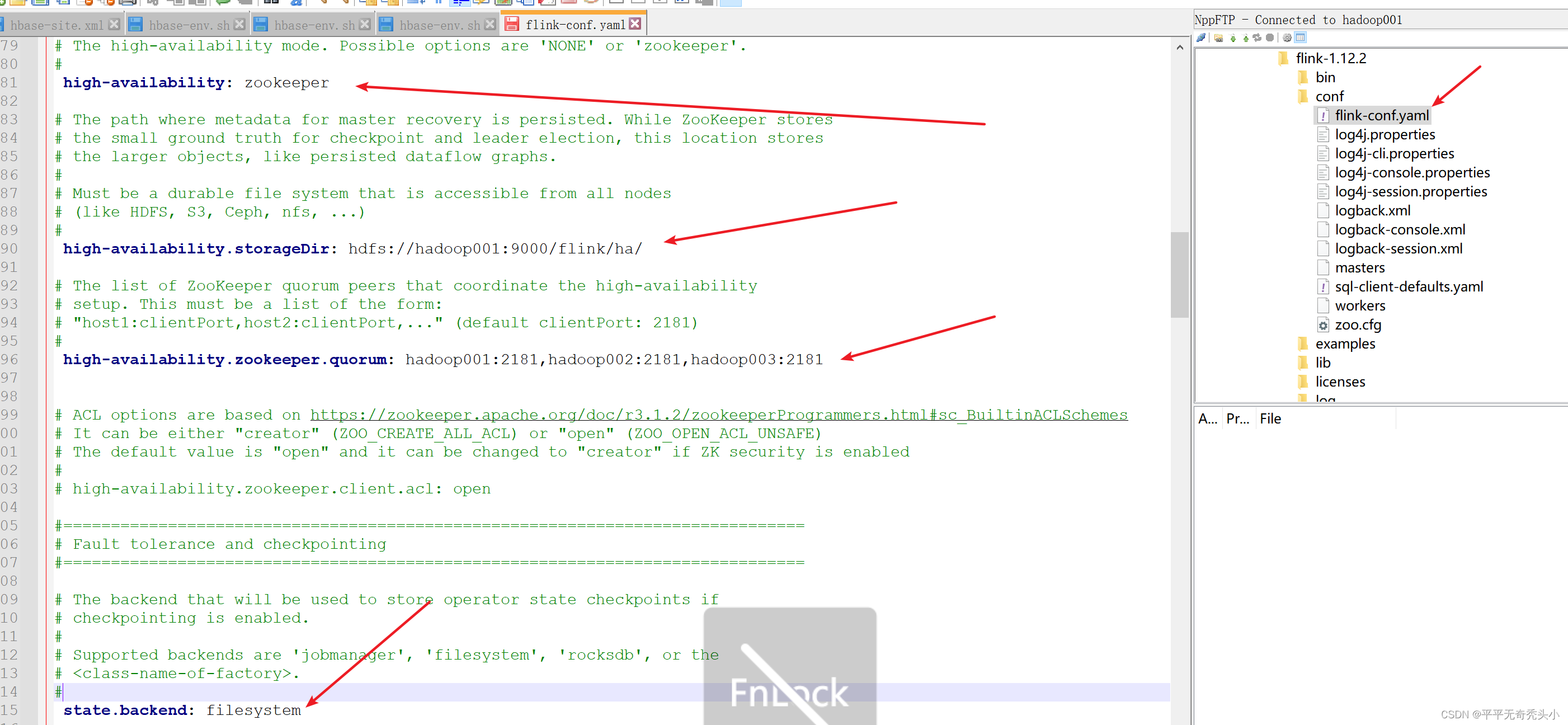
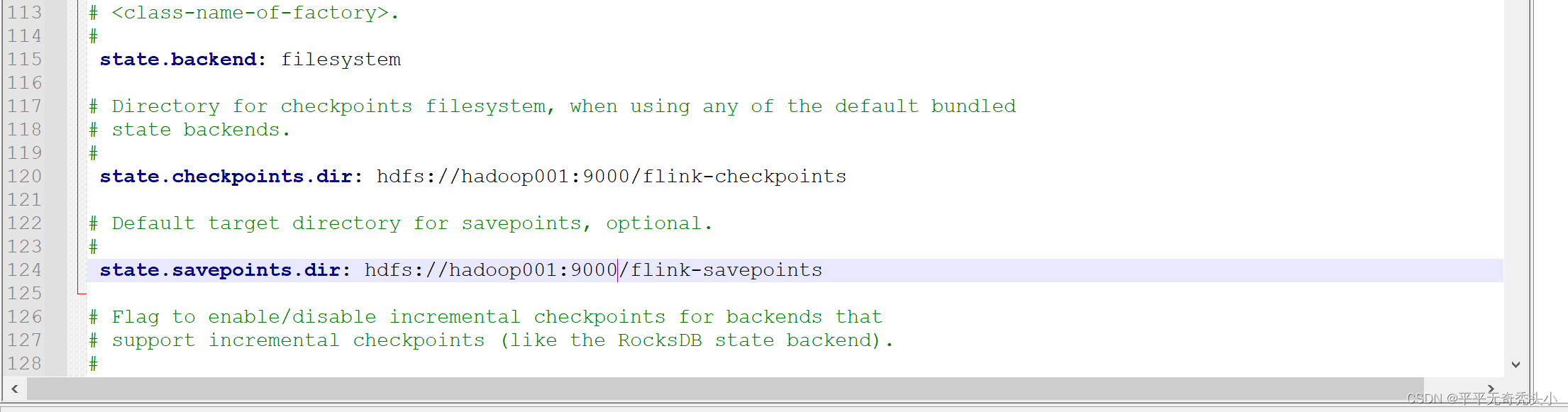
3、修改flink配置文件
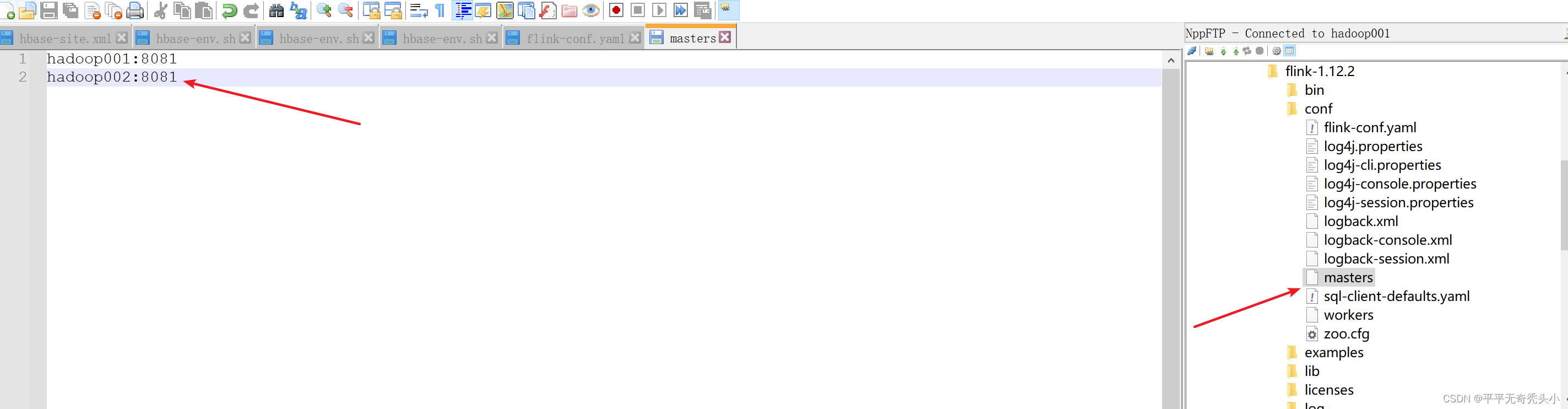
4、修改master文件
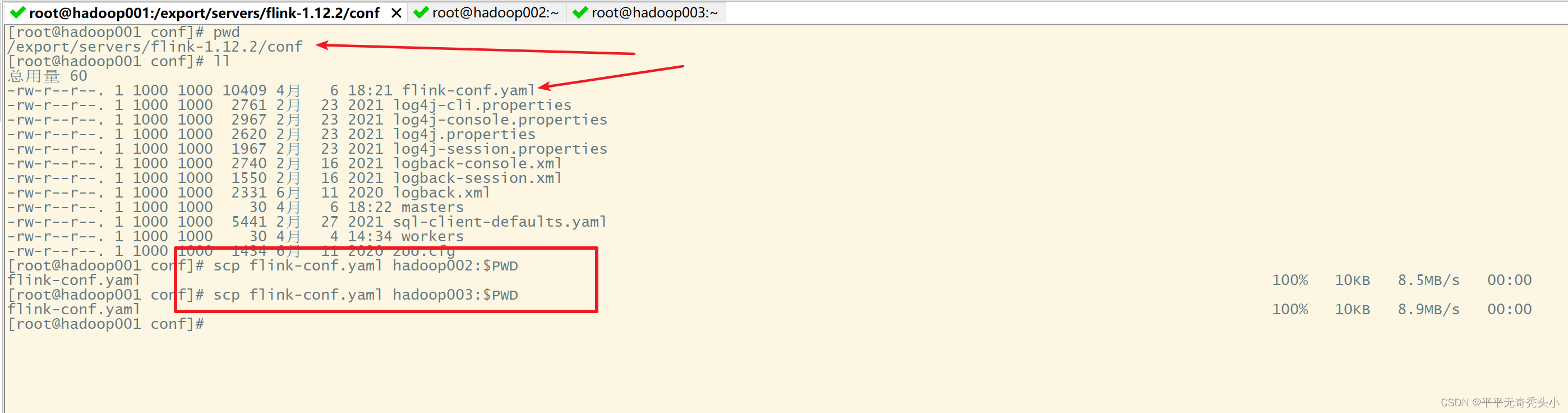
5、同步配置文件
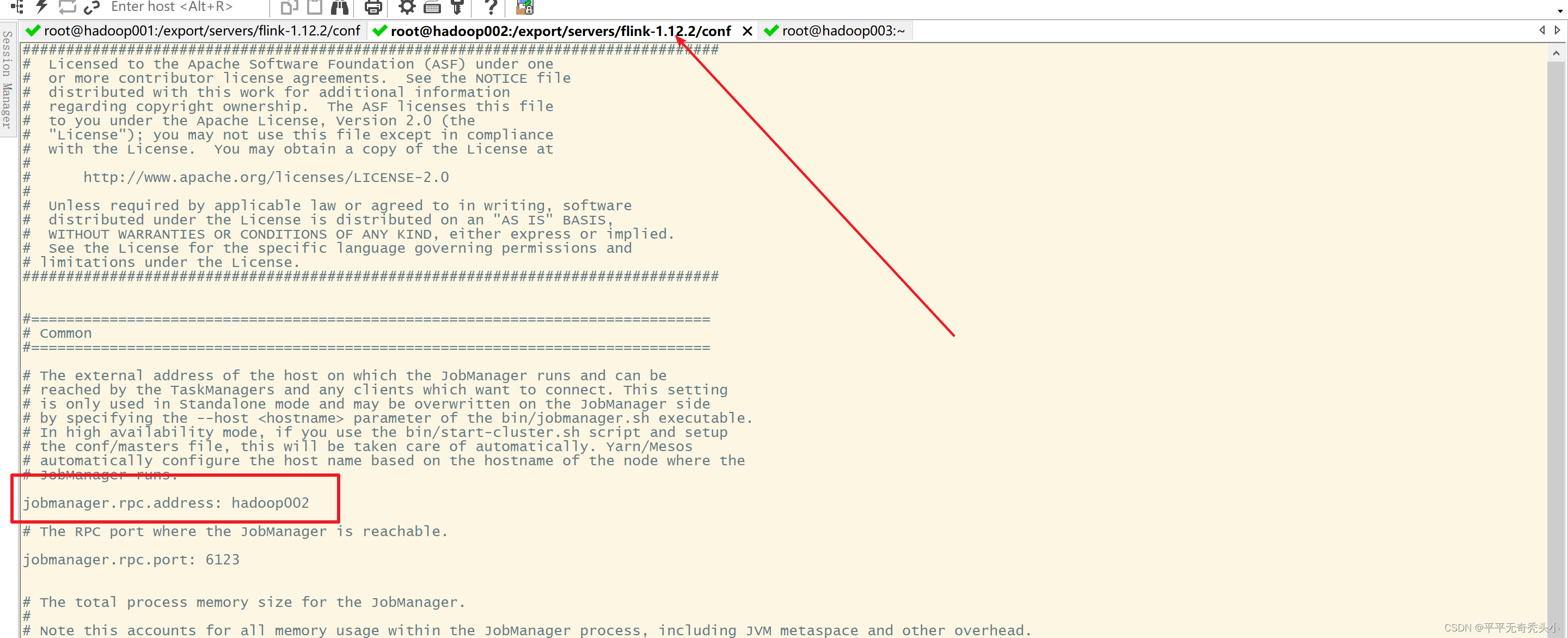
6、修改hadoop002上的flink-core.yaml
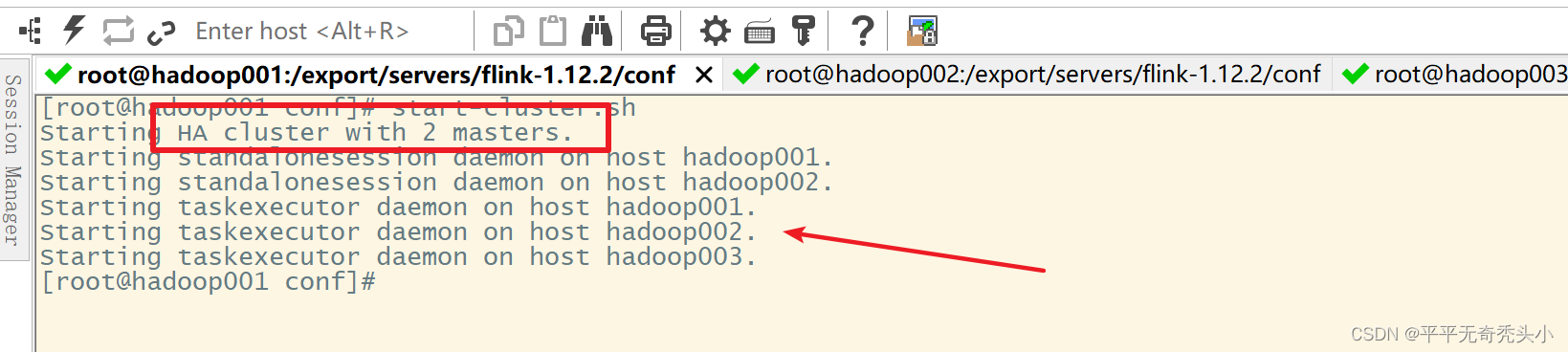
7、重新启动flink集群
8、相关进程未启动

因为缺少flink整合hadoop的jar包,需要从flink官网下载,放入flink的lib目录,并分发至其他节点Apache Flink: Downloads

重新启动

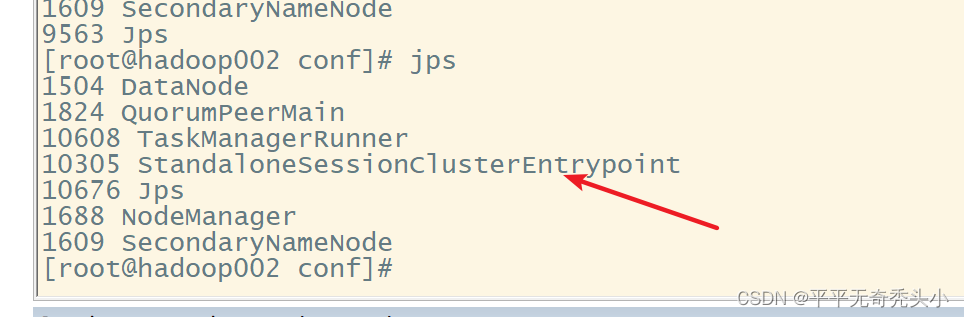
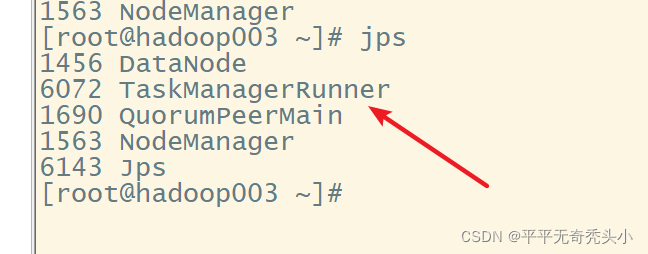
9、Flink的webui查看
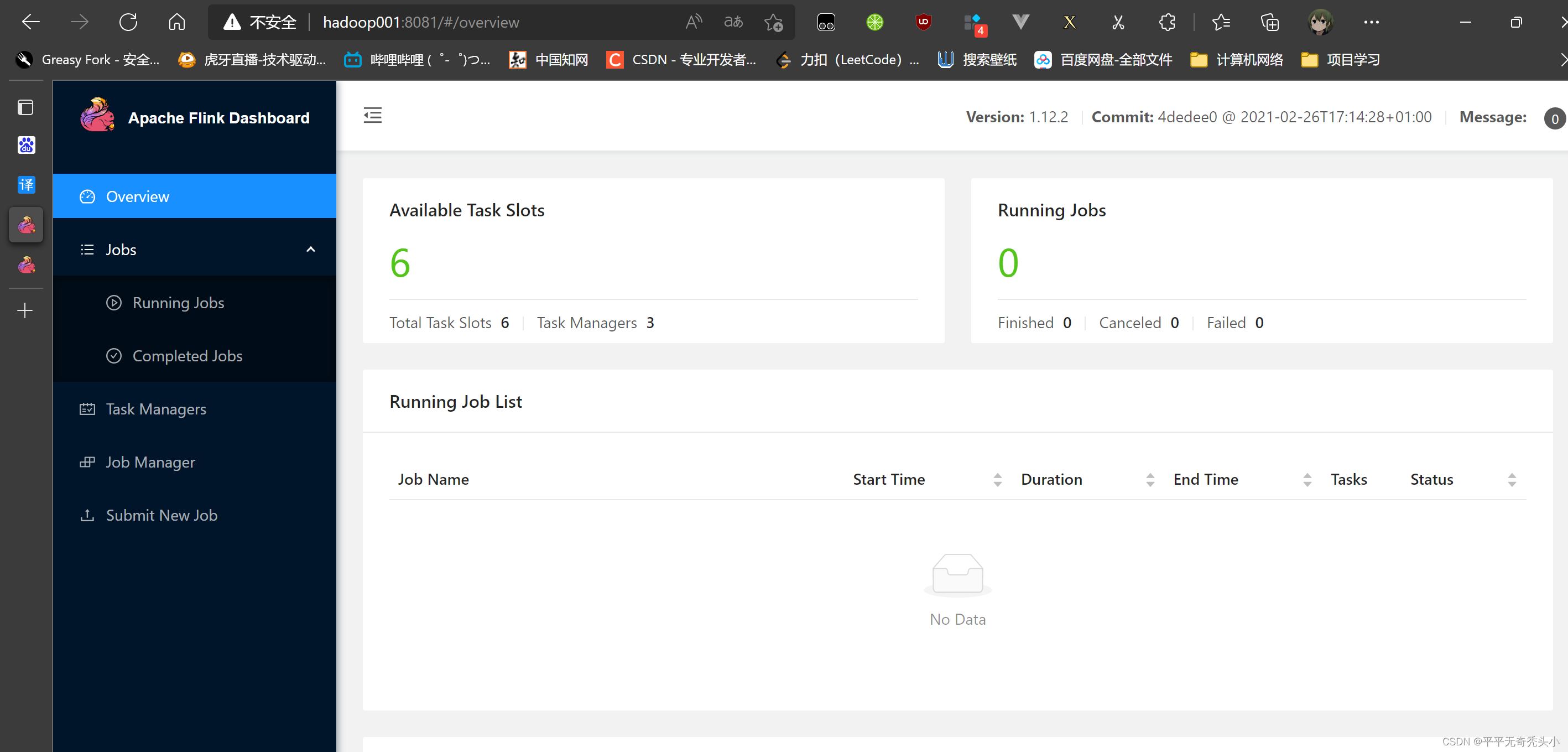
七、Flink on yarn的安装
1、修改yarn-site.xml配置文件
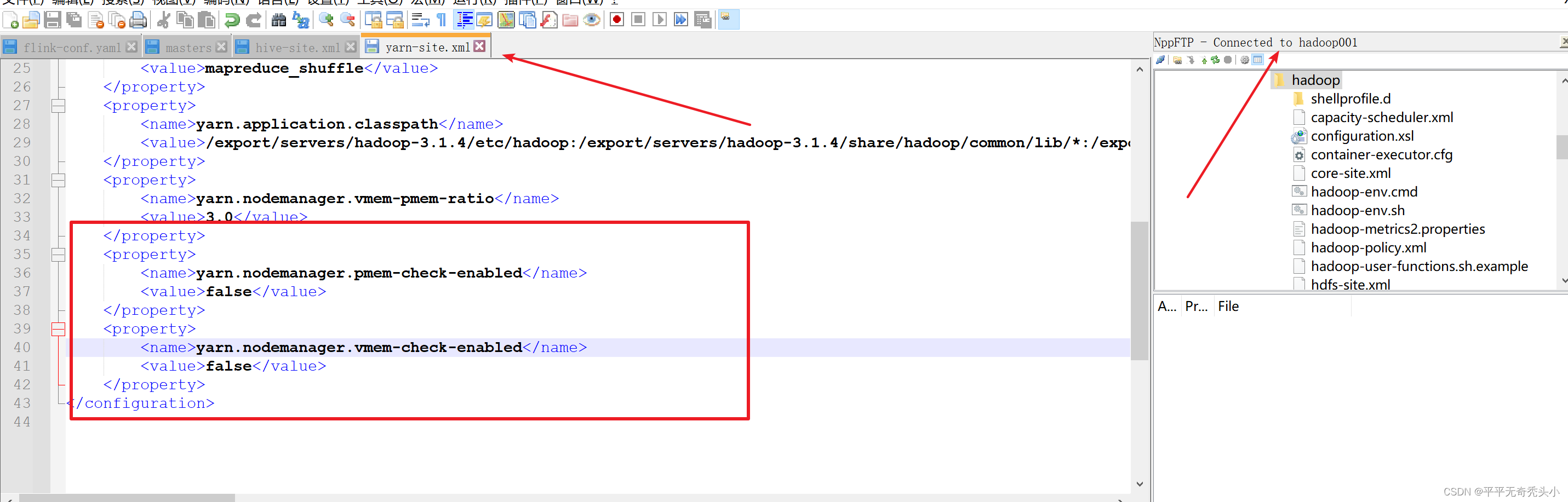
2、分发配置文件

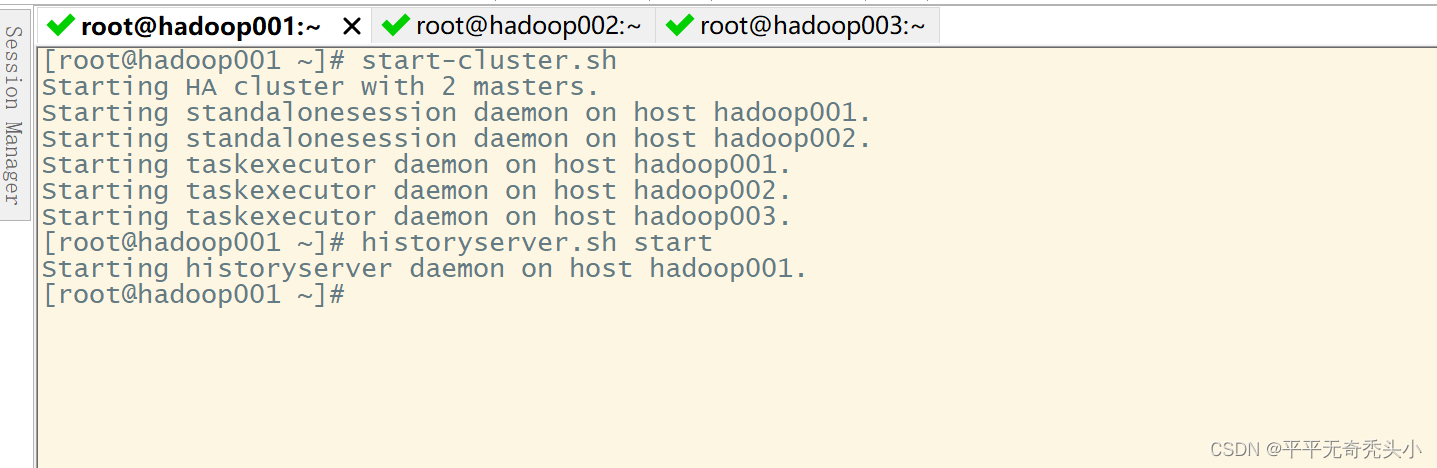
3、启动相关服务
Zookeeper
dfs
yarn
flink
historyserver
4、Session模式提交任务
1)开启会话
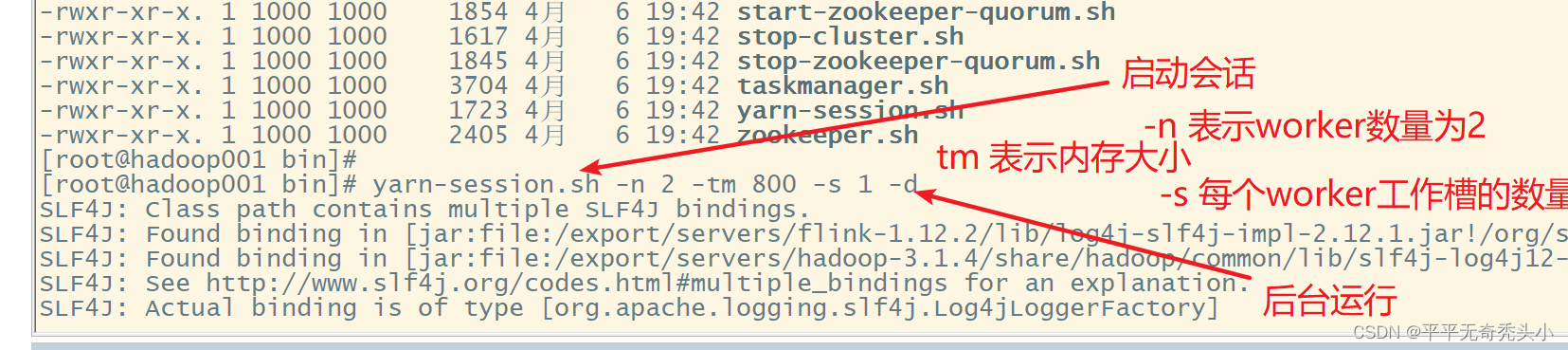
[root@hadoop001 bin]# yarn-session.sh -n 2 -tm 800 -s 1 -d
-n:表示申请的容器,也就是worker的数量,也即cpu的核心数
-tm:表示每个worker(taskManager)的内存大小
-s:表示每个worker的slot数量
-d:表示在后台运行
2)jps

3)查看yarn的webui
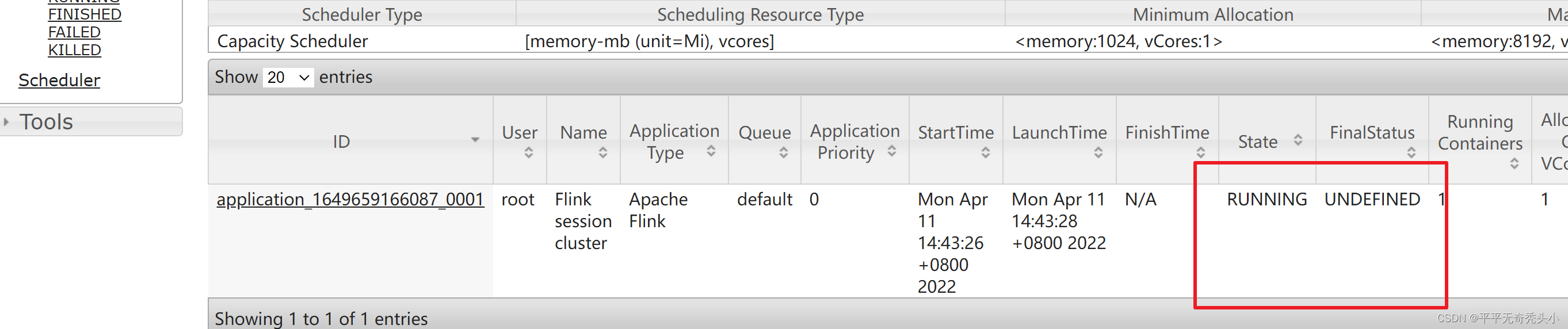
4)提交任务-单词计数

5)查看任务完成
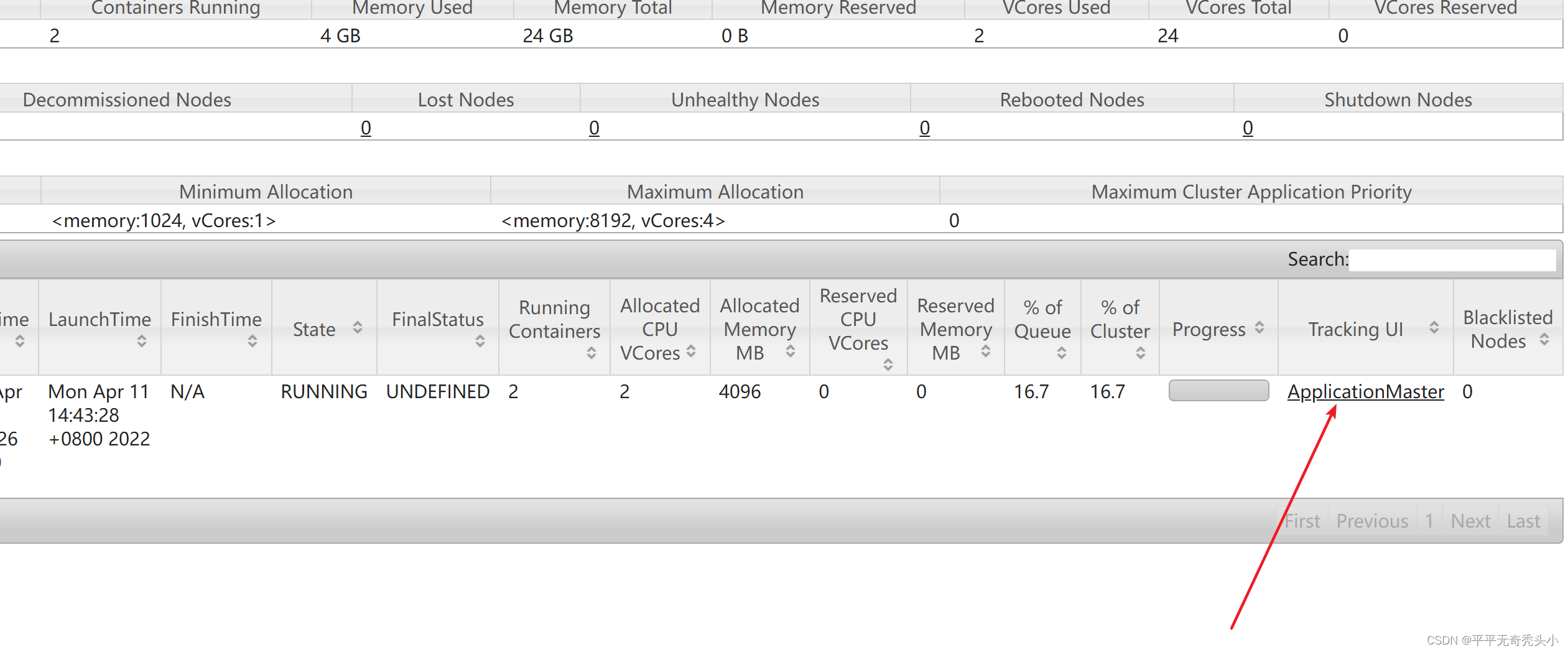
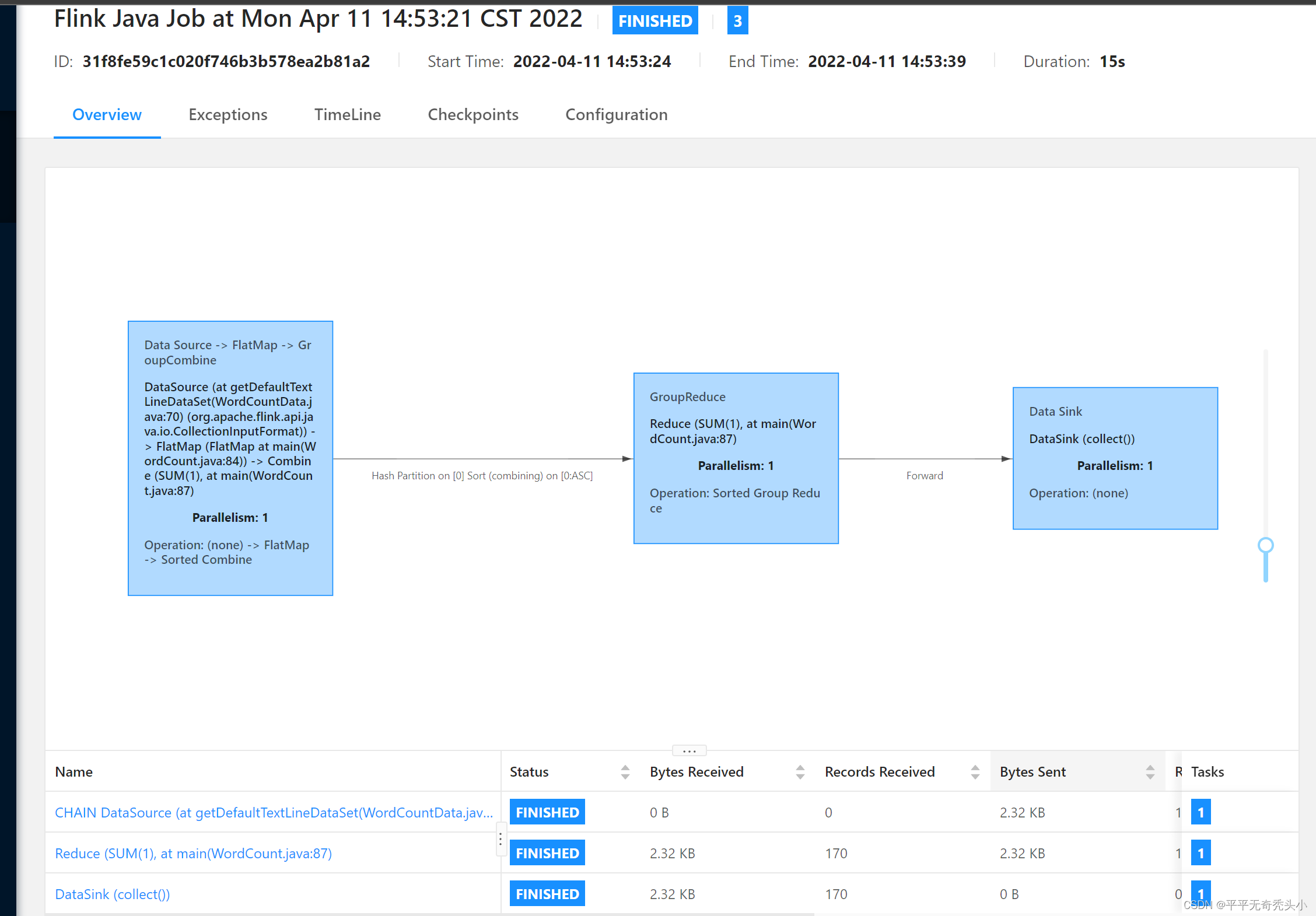
6)再提交一个任务
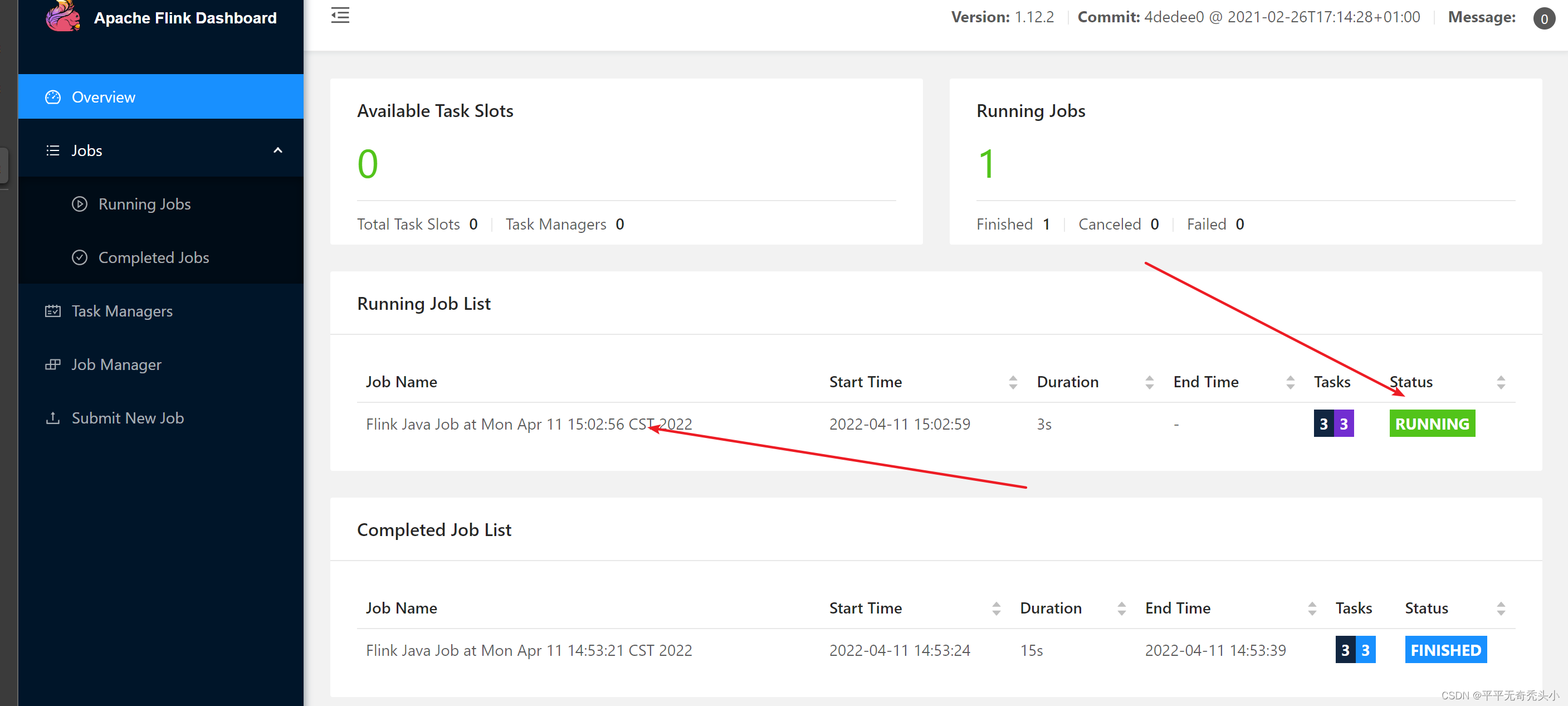
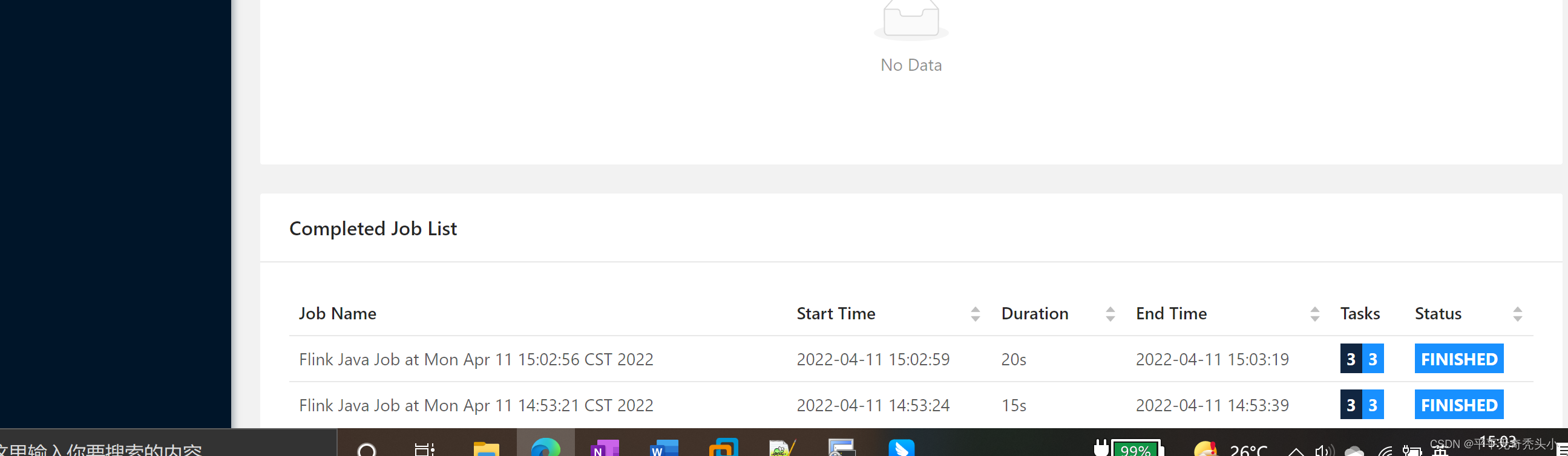
7)再次查看yarn的webui
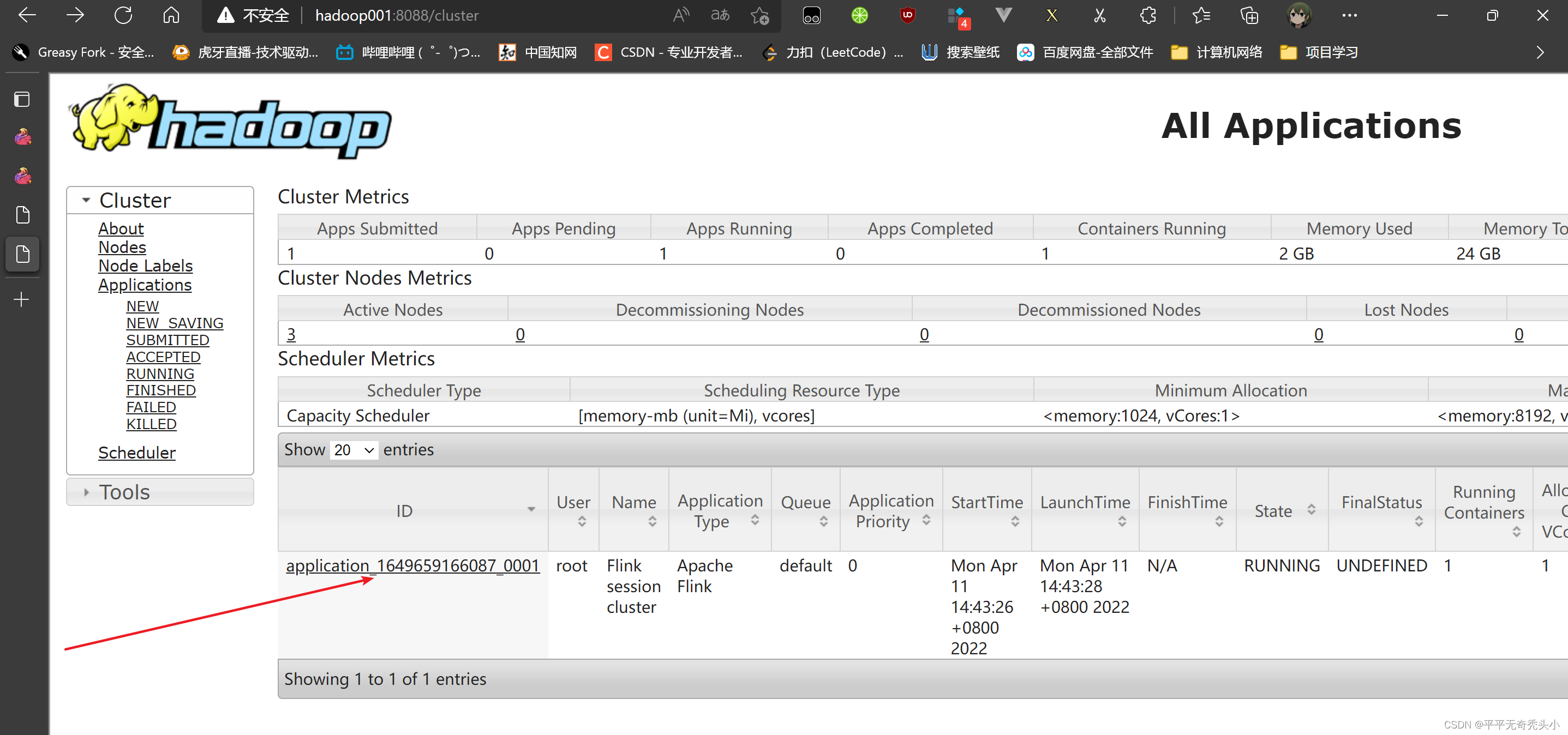
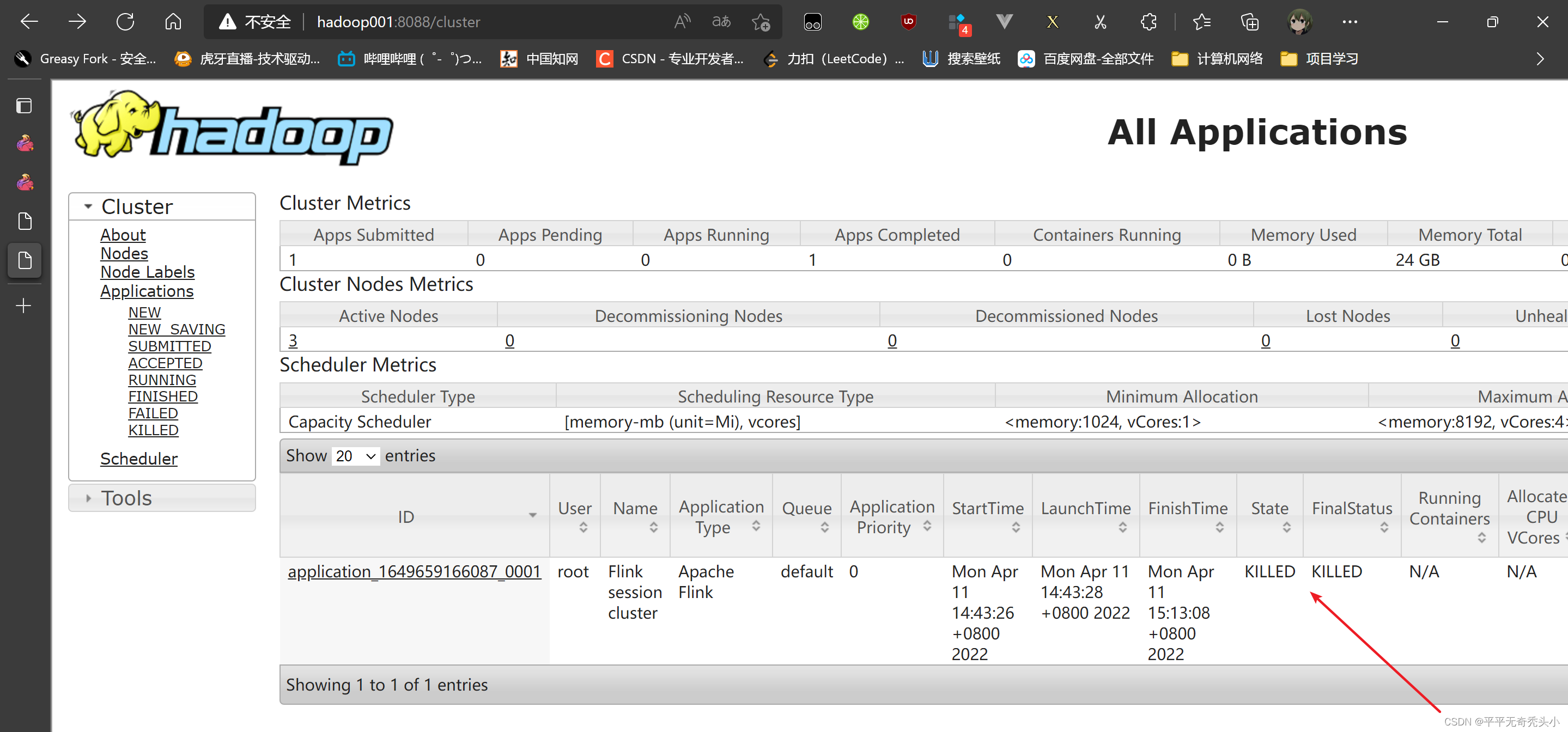
8)关闭yarn-sesion
[root@hadoop001 batch]# yarn application -kill application_1649659166087_0001

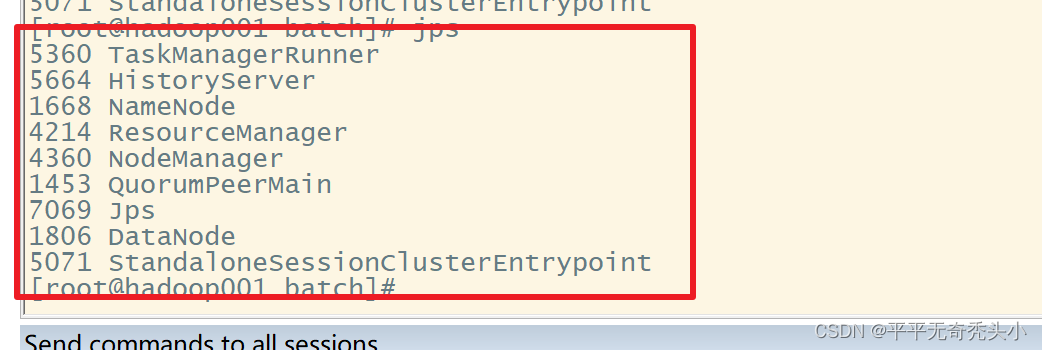
5、Per-job模式提交任务
1)提交任务
[root@hadoop001 batch]# flink run -m yarn-cluster -yjm 1024 -ytm 1024 WordCount.jar
-m:jobmanager的地址
-yjm:jobmanager的内存大小
-ytm:taskmanager的内存大小


2)查看yarn的webui
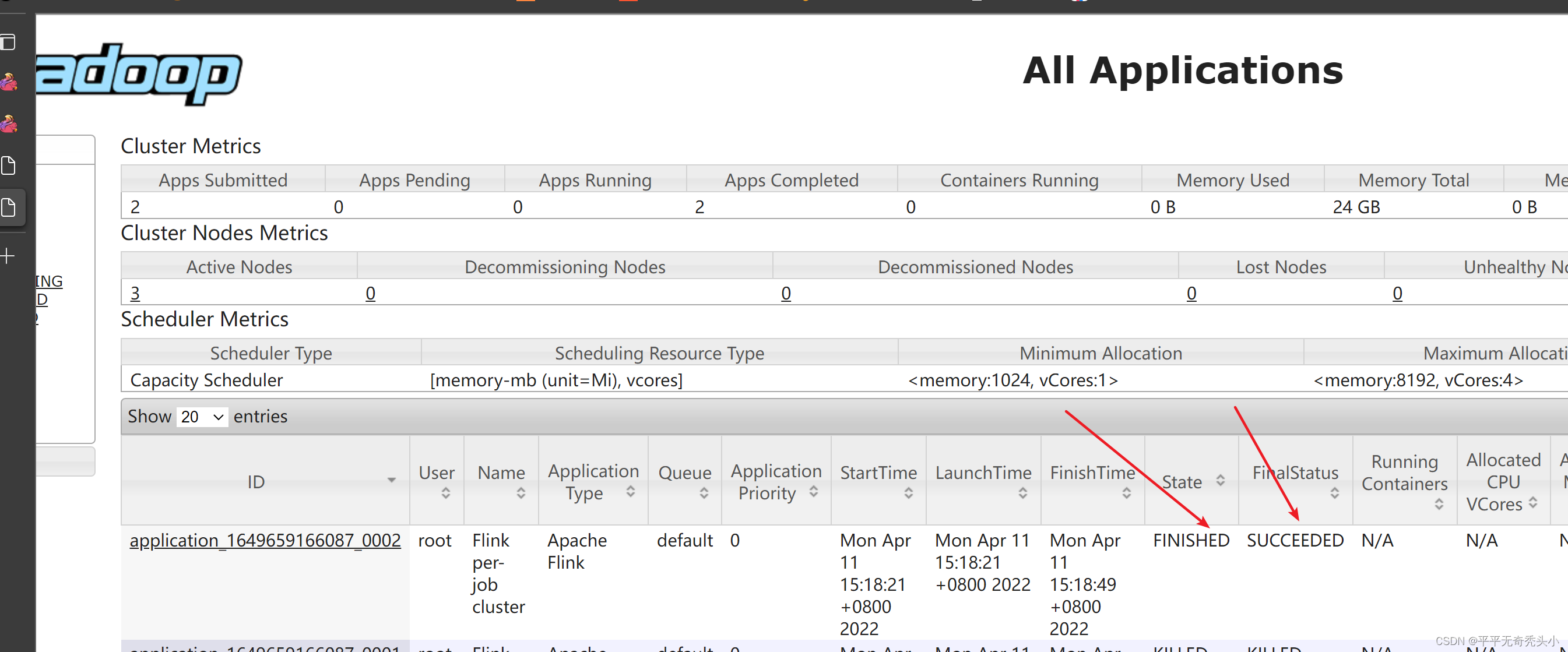
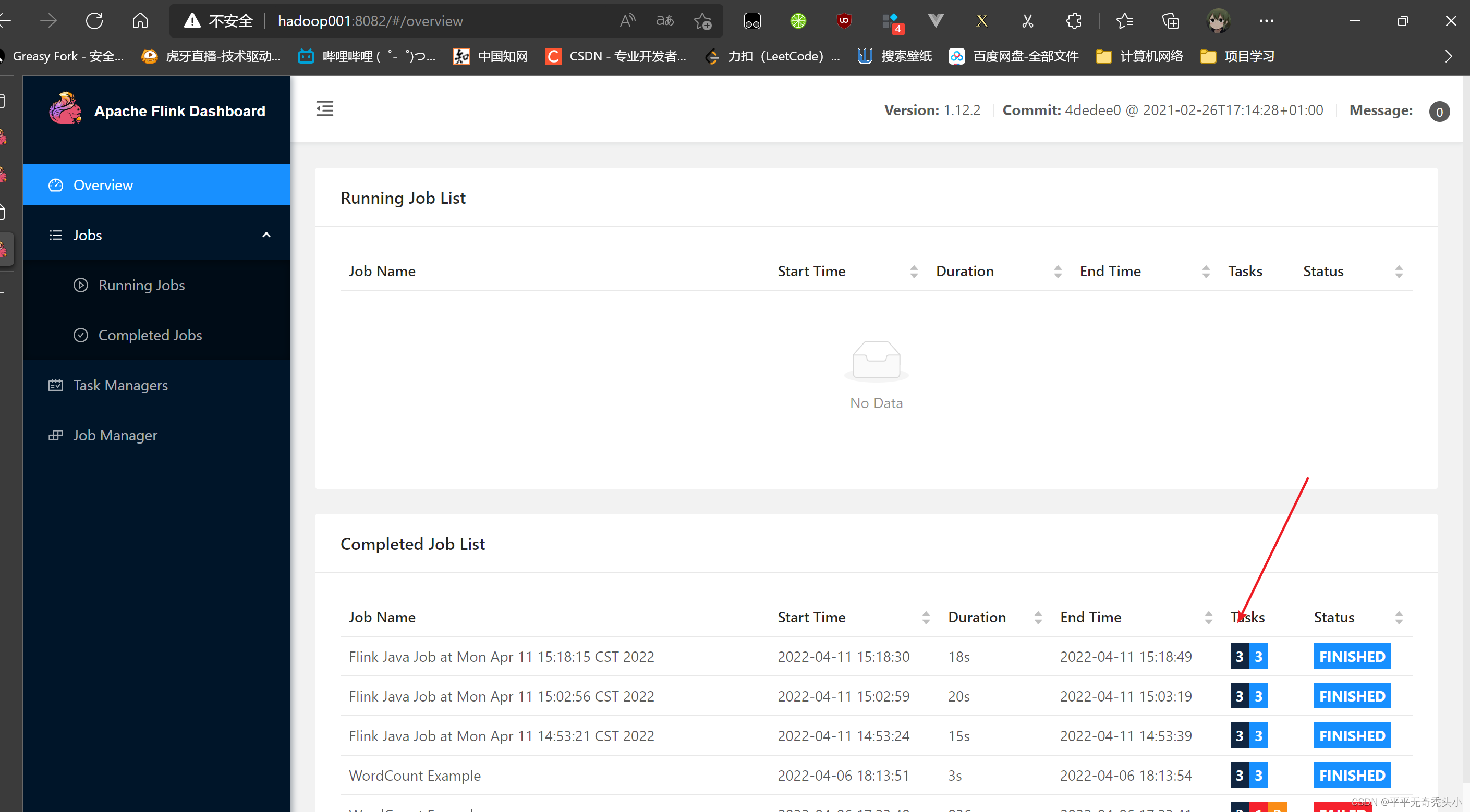
3)再次提交


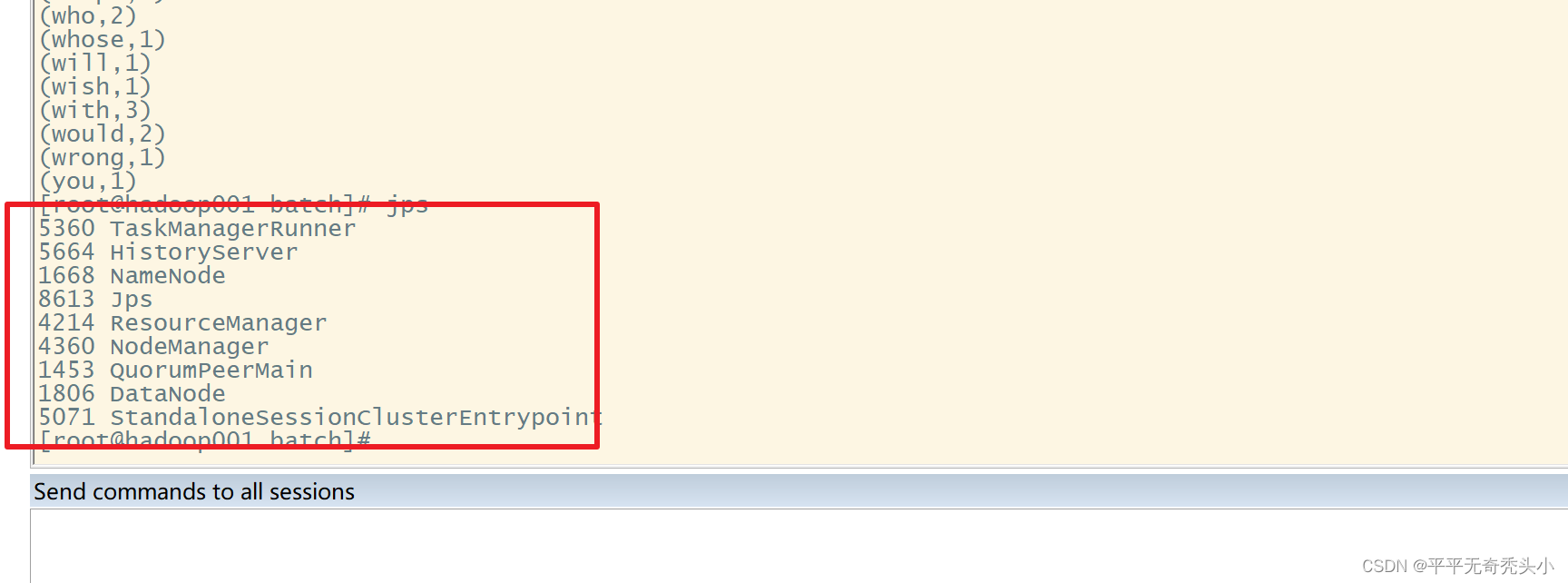
4)查看jps情况
查看到没有相关进程,进程完成后会自动关闭
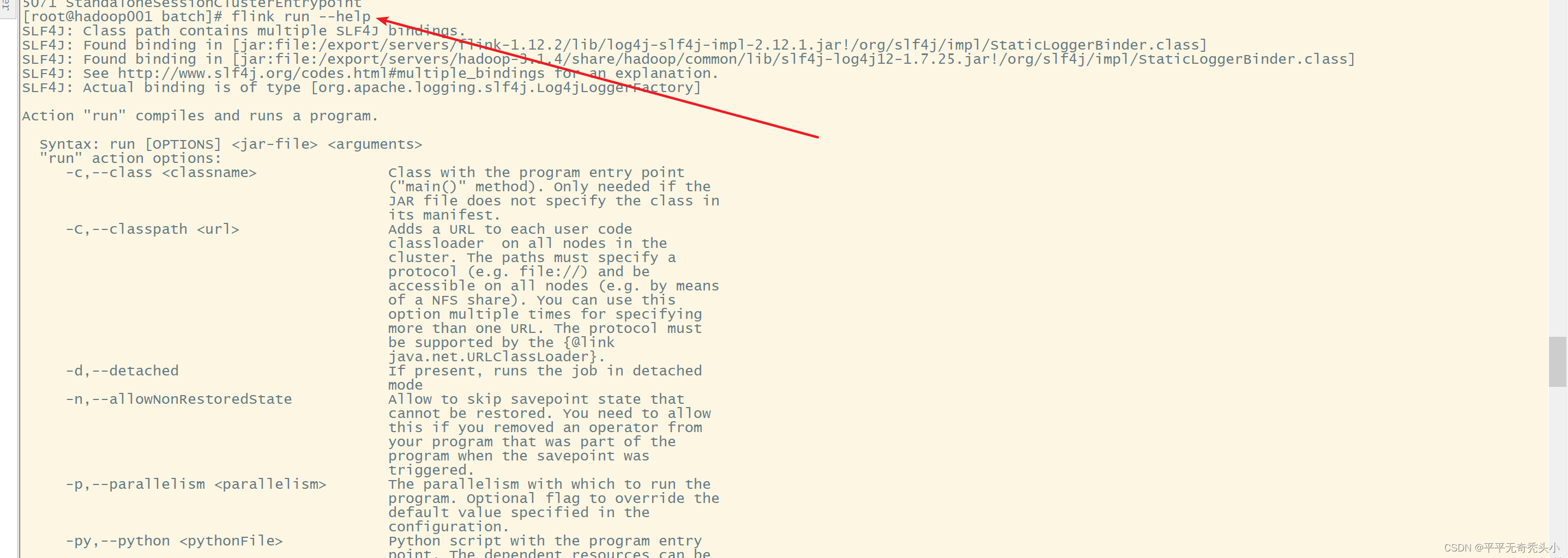
6、Flink提交参数任务总结
版权归原作者 平平无奇秃头小天才 所有, 如有侵权,请联系我们删除。