
** Spark系列文章:**
大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客
大数据 - Spark系列《二》- 关于Spark在Idea中的一些常用配置-CSDN博客
大数据 - Spark系列《三》- 加载各种数据源创建RDD-CSDN博客
大数据 - Spark系列《四》- Spark分布式运行原理-CSDN博客
大数据 - Spark系列《五》- Spark常用算子-CSDN博客
大数据 - Spark系列《六》- RDD详解-CSDN博客
大数据 - Spark系列《七》- 分区器详解-CSDN博客
大数据 - Spark系列《八》- 闭包引用-CSDN博客
9.1 🥙简介
广播变量(Broadcast Variables)是 Spark 中用于在集群中共享数据的一种机制。*它允许在整个集群中缓存一个只读*的变量,从而在每个节点(****executor)**上只复制一份数据,而不是每个任务都复制一份。这样可以大大减少网络传输的数据量,提高了任务的执行效率。
广播变量被保存在本地,并会把广播变量的值切分成多个数据块进行保存。广播变量数据块的默认大小是4M,数据块太大或太小都不利于数据的传输。
就是说,
当Job的某个阶段的Task使用到一个闭包变量, 且一个Executor中可能会运行相同类型的任务时
如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量非常适合。
9.2 特点
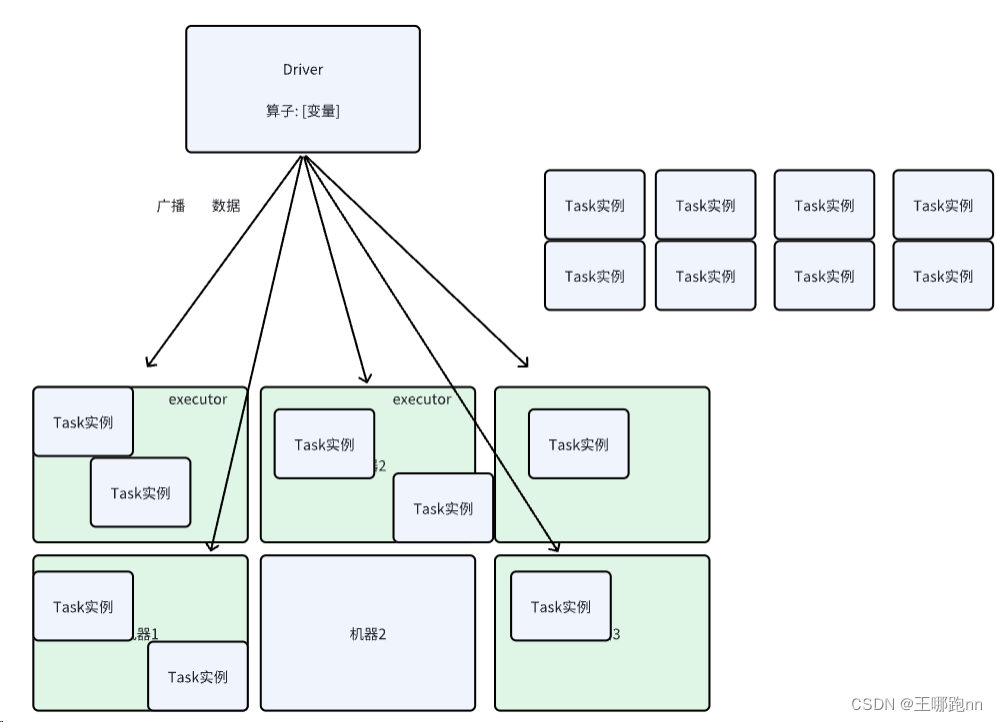
1)广播变量会在每个executor中保留一份副本,而不是为每个Task保留一份副本。
2)Spark使用了BitTorrent协议进行广播变量的分发,这样可以减少通信成本,该分发算法在后面章节有介绍。
9.3 🥙使用场景
- 共享较大的只读数据: 广播变量通常用于在任务之间共享较大的只读数据,例如机器学习模型参数、配置信息等。
- 减少数据传输量: 通过在集群中广播变量的方式,可以避免在每个任务中复制大量的数据,减少了网络传输的数据量,提高了任务的执行效率。
注意事项
1)能不能将一个RDD使用 广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的计算结果广播出去。
2)广播变量只能在Driver端定义,不能在Executor端定义。
3)在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
9.4 使用方法
1. 🥙****创建广播变量
使用 SparkContext 的 broadcast 方法将要广播的数据包装成广播变量。
val broadcastVar = sc.broadcast(data)
2. 🥙****访问广播变量
在任务中通过 value 属性来访问广播变量的值。
broadcastVar.value
3. 不适用广播变量的问题
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSc
val rdd1: RDD[(String, Int)] = sc.parallelize(List(("a", 1), ("b", 2), ("c", 3)))
val rdd2: RDD[(String, Int)] = sc.parallelize(List(("a", 11), ("b", 22), ("c", 33)))
// 数据在进行join的时候会出现shuffle , 我们在编程的时候尽量避免shuffle的产生
val resRDD1: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
// 使用这样的方式来实现join逻辑, 这里调用的是map函数是没有shuffle产生的
// 1 将数据收集到driver端
val mp: Map[String, Int] = rdd2.collect().toMap
// map函数的逻辑分布式执行在不同的Task中 , 那么我们的mp数据在每个Task中都存在
val resRDD2: RDD[(String, (Int, Int))] = rdd1.map {
case (k, v) => {
val i: Int = mp.getOrElse(k, -1)
(k, (v, i))
}
}
resRDD2.foreach(println)
sc.stop()
4. 🥙使用广播变量
package com.doit.day0217
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.io.Source
/**
* @日期: 2024/2/19
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test09 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
// 加载用户数据,将其转换为Map
val user = Source.fromFile("data/join/user.txt")
val userMap: Map[String, String] = user.getLines().map(line => {
val arr = line.split(",")
(arr(0), arr(1))
}).toMap // 将用户数据转换为Map,存储在内存中 一般数据集控制大小为1G以内
//1)-------------------- 将map集合变成广播变量
val bc = sc.broadcast(userMap)
// 加载订单数据
val orders = sc.textFile("data/join/orders.txt")
// 使用闭包变量userMap避免shuffle,将用户名直接关联到订单数据中
val rdd2 = orders.map(iter => {
val arr2 = iter.split(",")
//val name = userMap.getOrElse(arr2(4), "unknown") // 使用闭包变量userMap关联订单数据中的用户ID
// 2)-------------------- 从广播变量中取出数据
val name = bc.value.getOrElse(arr2(4), "unknown")
(arr2(0), arr2(1), arr2(2), arr2(3), arr2(4), name)
})
// 打印处理后的订单数据
rdd2.foreach(println)
// 关闭SparkContext对象
sc.stop()
}
}
5. 销毁广播变量
从driver端发送一个RemoveBroadcast消息。在Executor上的BlockManager服务接收该消息,就会把广播变量从BlockManager中删除。若removeFromDriver设置成True,还会从Driver删除该变量的数据。
// 销毁广播变量
bc.unpersist()
9.5 广播变量分发读取机制
1. 创建原理

广播变量的创建发生在Driver端,如图所示,当调用SparkContext#broadcast来创建广播变量时,会把该变量的数据切分成多个数据块,保存到driver端的BlockManger中,使用的存储级别是:MEMORY_AND_DISK_SER。
所以,广播变量的读取也是懒加载的,只有在Executor端需要获取广播变量时才会去获取。此时广播变量的数据只在Driver端存在。
2. 读取原理
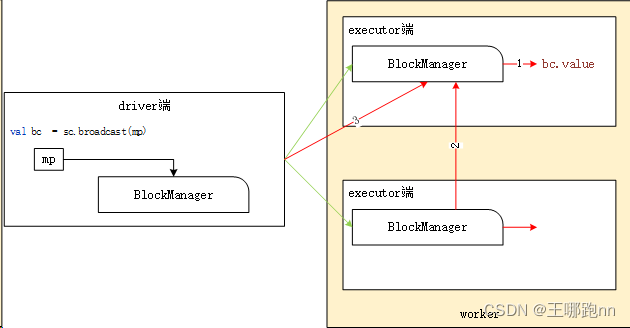
1)第1步(红色线1):首先从本Executor的BlockManager中(或本机的其他executor)读取广播变量的数据,若存在就直接获取,并返回。若不存在,则执行2或3。
2)第2步(红色线2):从远端获取数据。先从同一个机架(rack)的主机的Executor端获取。若不能从其他Executor中获取广播变量,则会直接从Driver端获取。
3)第3步(红色线3):从Driver端获取广播变量的状态和位置信息(由于所有的BlockManager slave端都会向Master端汇报数据块状态)。
从以上获取流程可以看出,在执行spark应用时,只要有一个worker节点的Executor从Driver端获取到了广播变量的数据,则其他的Executor就不需要从Driver端获取了。
BT协议
当某个Executor上的某个数据块被删除,可以从其他Executor直接获取该数据块,然后把数据块保存到自己的Executor的BlockManager中。

Executor4中的任务需要使用广播变量,但它只有该变量的b4数据块。此时,它首先从同主机(worker2节点)的中获取数据,获取到数据块;然后分别从不同主机的Executor1和Executor2中读取数据块。此时,Executor4就获取到变量b的全部数据块了,然后把这些数据块在自己的BlockManager中保存一份。此时,其他Executor就可以从Executor4中读取数据了。
当完成这些操作后,各个Executor端的BlockManager(slave端)会向Driver端的BlockManager(master端)汇报数据块的状态。
版权归原作者 王哪跑nn 所有, 如有侵权,请联系我们删除。