
文章目录
1. master 中安装 Hadoop
将Hadoop安装包解压,并复制到指定文件夹
/usr/local/src/
下
tar -zxvf hadoop-2.7.7.tar.gz
mv ./hadoop-2.7.7/ /usr/local/src/
和 配置Java环境变量 一样地,配置Hadoop环境变量
vi /root/.bash_profile # 根据要求修改这个文件,也可以修改/etc/profile
然后在末尾写上
export HADOOP_HOME=/usr/local/src/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

让配置生效
source /root/.bash_profile
然后终端输入 hadoop 看看是不是安装成功了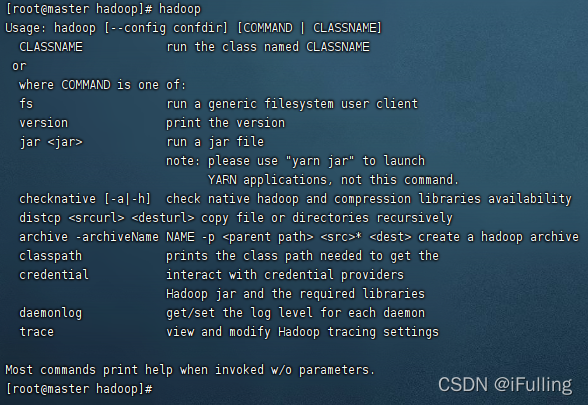
2. master 中配置 Hadoop
Hadoop配置文件在
/hadoop-2.7.7/etc/hadoop
目录下,
ls -l
可以看到有很多配置文件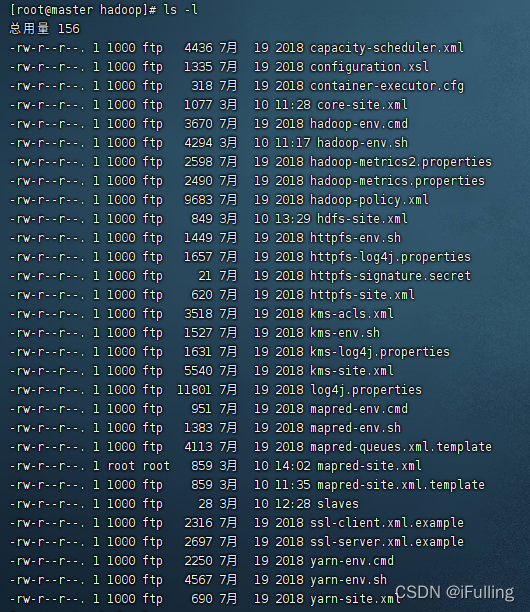
(1) 配置 core-site.xml 文件
现在 Hadoop 安装路径新建 tmp文件夹。
cd /usr/local/src/hadoop-2.7.7
mkdir tmp
修改Hadoop核心配置文件core-site.xml,这里配置的是HDFS的地址和端口号。
cd /usr/local/src/hadoop-2.7.7/etc/hadoop
vi core-site.xml
<configuration><property><name>hadoop.tmp.dir</name><value>/usr/local/src/hadoop-2.7.7/tmp</value><description>A base for other temporary directories.</description></property><!--file system properties--><property><name>fs.default.name</name><!--这是 master 的 ip--><value>hdfs://192.168.1.101:9000</value></property></configuration>

备注: 如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被干掉,必须重新执行format才行,否则会出错。
(2) 配置 hdfs-site.xml文件
vi hdfs-site.xml
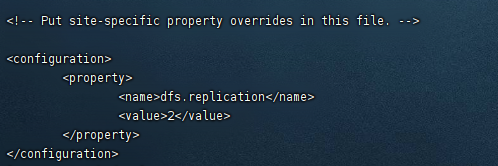
- 修改Hadoop中HDFS的配置,配置的备份方式默认为3。
- replication 是数据副本数量,默认为3,slave少于3台就会报错。
<configuration><property><name>dfs.replication</name><value>2</value></property></configuration>
(3) 配置 mapred-site.xml 文件
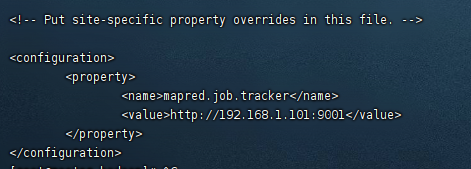
只有 mapred-site.xml.template 文件, 则先在 mapred-site.xml.template 中写配置,然后再复制一份,并命名为mapred.xml,该文件是MapReduce的配置文件,用于指定MapReduce使用的框架,配置的是JobTracker的地址和端口。
vi mapred-site.xml.template
<configuration><property><name>mapred.job.tracker</name><!--这里是 master 的 ip--><value>http://192.168.1.101:9001</value></property></configuration>
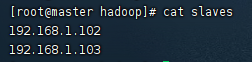
(4) 配置 slaves文件(Master主机特有)
vi slaves
在里面删掉"localhost",加入集群中所有Slave机器的IP,也是每行一个。
192.168.1.102
192.168.1.103
(5) 关闭防火墙
systemctl stop firewalld
(6) 把 Hadoop 安装包传到 slave
把安装包和环境变量文件传到 slave
scp -r /usr/local/src/hadoop-2.7.7/ [email protected]:/usr/local/src/
scp -r /usr/local/src/hadoop-2.7.7/ [email protected]:/usr/local/src/
scp /root/.bash_profile [email protected]:/root
scp /root/.bash_profile [email protected]:/root
现在在Master机器上的Hadoop配置就结束了,剩下的就是配置Slave机器上的Hadoop。
3. slave 中配置 Hadoop
用户切换到 slave1 和 slave2,所有子结点都需要执行以下操作。
(1) 关闭防火墙
如果不关闭防火墙,会出现报错
systemctl stop firewalld
(2) 生效配置
因为安装包和环境变量都已经传输过来了,只需要生效配置就行。
source /root/.bash_profile
然后终端输入 hadoop 看看是不是安装成功了。
4. 启动及验证
(1) 格式化HDFS文件系统
切换到 master。
hadoop namenode -format

输出比较多,大致是这样的。
(2) 启动 Hadoop
如果觉得总是输密码很麻烦,可以 配置 SSH 免密登录 ,master 也可以给自己免密登录。
start-all.sh
输出的结果:
可以看出,首先启动 namenode 接着启动datanode1,datanode2,…,然后启动secondarynamenode。再启动 yarn,然后启动 nodemanager1,nodemanager2,…。
(3) 验证hadoop
在Master上用 java自带的小工具
jps
查看进程。
在Slave上用
jps
查看进程。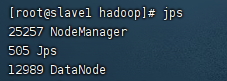
4. 网页查看集群
- 查看hdfs集群状态,也就是namenode的访问地址,默认访问地址:http://namenode的ip:50070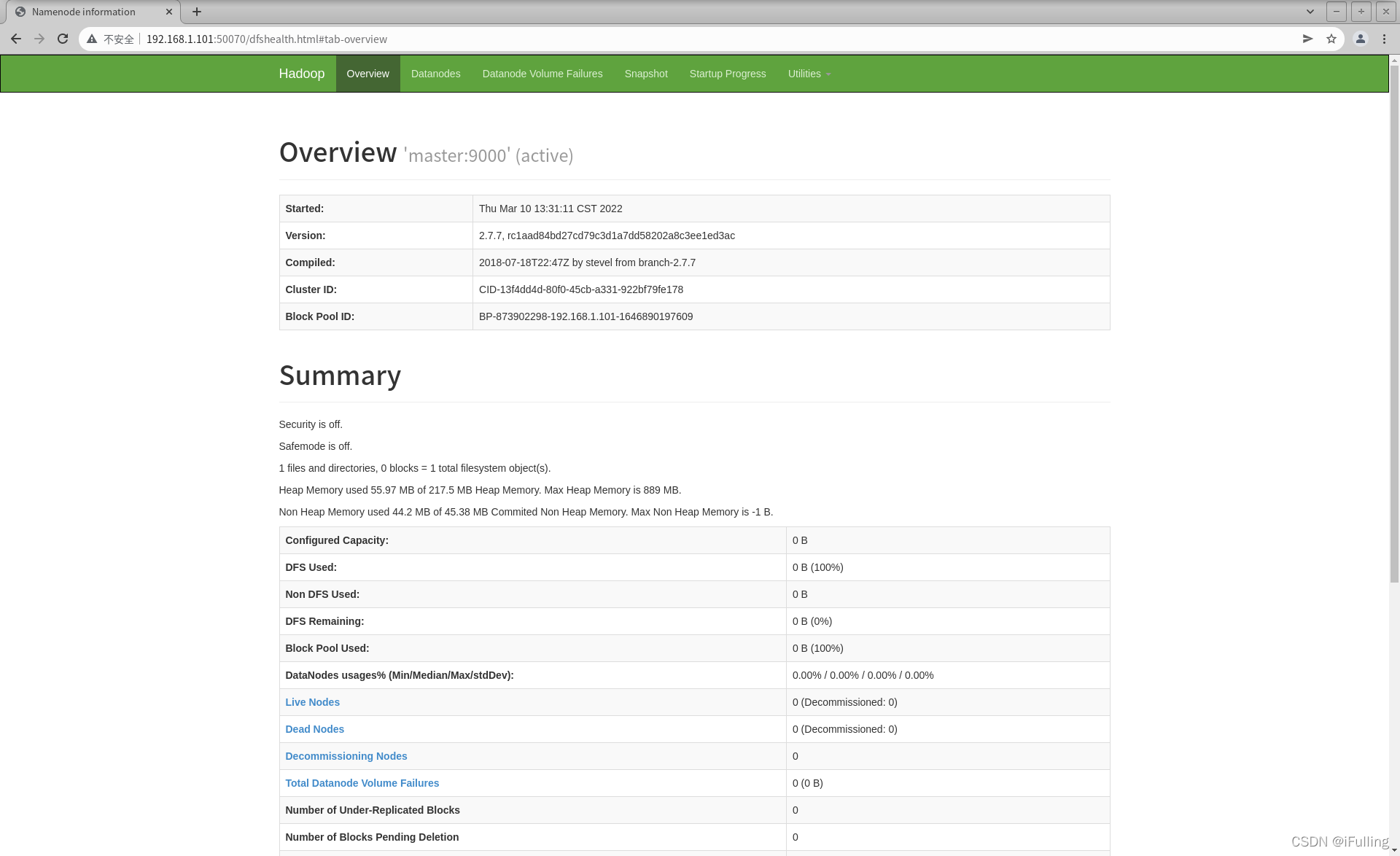
- 查看secondary namenode的集群状态,默认访问地址:http://namenode的ip:50090

版权归原作者 iFulling 所有, 如有侵权,请联系我们删除。