
文章很长,而且持续更新,建议收藏起来,慢慢读! Java 高并发 发烧友社群:疯狂创客圈(总入口) 奉上以下珍贵的学习资源:
- 免费赠送 经典图书 : 极致经典 + 社群大片好评 《 Java 高并发 三部曲 》 面试必备 + 大厂必备 + 涨薪必备
- 免费赠送 经典图书 : 《Netty Zookeeper Redis 高并发实战》 面试必备 + 大厂必备 +涨薪必备 (加尼恩领取)
- 免费赠送 经典图书 : 《SpringCloud、Nginx高并发核心编程》 面试必备 + 大厂必备 + 涨薪必备 (加尼恩领取)
- 免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 (加尼恩领取)
推荐:入大厂 、做架构、大力提升Java 内功 的 精彩博文
入大厂 、做架构、大力提升Java 内功 必备的精彩博文2021 秋招涨薪1W + 必备的精彩博文1:Redis 分布式锁 (图解-秒懂-史上最全)2:Zookeeper 分布式锁 (图解-秒懂-史上最全)3: Redis与MySQL双写一致性如何保证? (面试必备)4: 面试必备:秒杀超卖 解决方案 (史上最全)5:面试必备之:Reactor模式6: 10分钟看懂, Java NIO 底层原理7:TCP/IP(图解+秒懂+史上最全)8:Feign原理 (图解)9:DNS图解(秒懂 + 史上最全 + 高薪必备)10:CDN图解(秒懂 + 史上最全 + 高薪必备)10: 分布式事务( 图解 + 史上最全 + 吐血推荐 )
Java 面试题 30个专题 , 史上最全 , 面试必刷阿里、京东、美团… 随意挑、横着走!!!1: JVM面试题(史上最强、持续更新、吐血推荐)2:Java基础面试题(史上最全、持续更新、吐血推荐3:架构设计面试题 (史上最全、持续更新、吐血推荐)4:设计模式面试题 (史上最全、持续更新、吐血推荐)17、分布式事务面试题 (史上最全、持续更新、吐血推荐)一致性协议 (史上最全)29、多线程面试题(史上最全)30、HR面经,过五关斩六将后,小心阴沟翻船!9.网络协议面试题(史上最全、持续更新、吐血推荐)更多专题, 请参见【 疯狂创客圈 高并发 总目录 】
SpringCloud 精彩博文 nacos 实战(史上最全) sentinel (史上最全+入门教程) SpringCloud gateway (史上最全)更多专题, 请参见【 疯狂创客圈 高并发 总目录 】
DNS 是什么?
DNS是 Domain Name System 的缩写,也就是 域名解析系统,它的作用非常简单,就是根据域名查出对应的 IP地址。
你可以把它想象成一本巨大的电话本,比如当你要访问域名
www.163.com
,首先要通过DNS查出它的IP地址是
112.48.162.8
。
为啥需要DNS
NS服务器: 说白了, 就是一台翻译 名字到IP 的 软件。
IP: IP就是IP, 不解释。
下面, 我们来看一下逻辑关系: 假设某设备(充当DNS客户端)需要解析域名a.b.c.d, 于是就可以向DNS服务器发起请求, 然后然后DNS服务器将解析的IP结果w.x.y.z返回给客户端。

由于比较常见, 所以还是复习了一下, 至于为什么需要DNS, 你只要想想你经常使用的www.baidu.com就可以了, 这个可比其ip(http://36.152.44.95/)方便记忆多了。
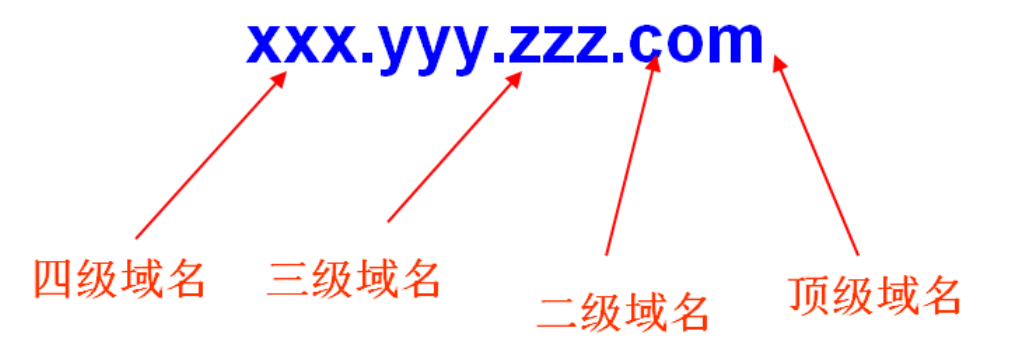
域名的形式
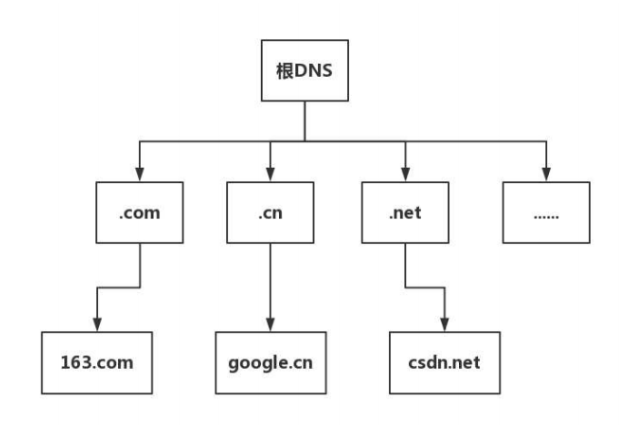
域名可以划分为各个子域,子域还可以继续划分为子域的子域,这样就形成了顶级域、二级域、三级域等。
如下图所示:
其中顶级域名分为:国家顶级域名、通用顶级域名、反向域名。
国家顶级域名中国:cn, 美国:us,英国uk…通用顶级域名com公司企业,edu教育机构,gov政府部门,int国际组织,mil军事部门 ,net网络,org非盈利组织…反向域名arpa,用于PTR查询(IP地址转换为域名)
域名的层级
由于后面我会讲到 DNS 的解析过程,因此需要你对域名的层级有一些了解
- 根域名 :
.root或者.,根域名通常是省略的 - 顶级域名,如
.com,.cn等 - 次级域名,如
baidu.com里的baidu,这个是用户可以进行注册购买的 - 主机域名,比如
baike.baidu.com里的baike,这个是用户可分配的
主机名.次级域名.顶级域名.根域名
baike.baidu.com.root

换一种形式展示,如下图所示:
eg :我们熟悉的,www.baidu.com
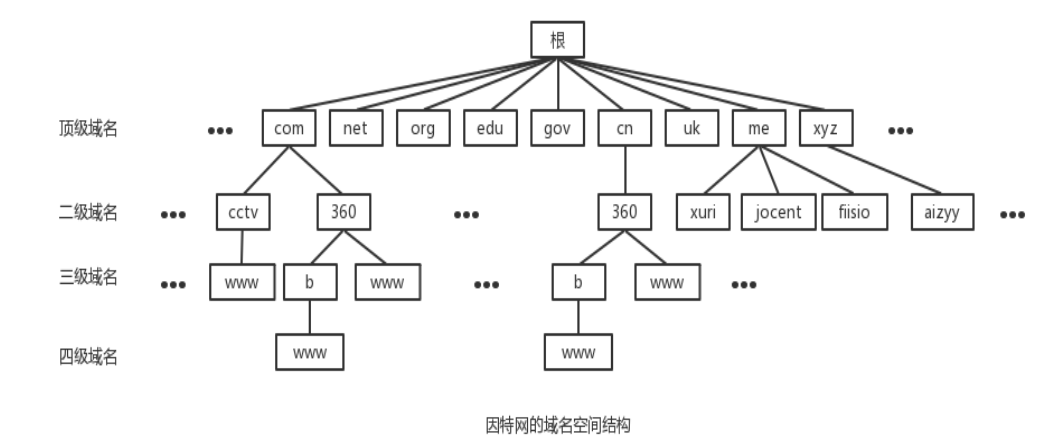
- com: 一级域名. 表示这是一个企业域名。同级的还有 “net”(网络提供商), “org”(⾮非盈利组织) 等。
- baidu: 二级域名,指公司名。
- www: 表示主机域名为 www。
域名是分层结构,域名服务器也是对应的层级结构。
有了域名结构,还需要有一个东西去解析域名,域名需要由遍及全世界的域名服务器去解析,域名服务器实际上就是装有域名系统的主机。
由高向低进行层次划分,可分为以下几大类:
分类作用根域名服务器最高层次的域名服务器,本地域名服务器解析不了的域名就会向其求助顶级域名服务器负责管理在该顶级域名服务器下注册的二级域名权限域名服务器负责一个区的域名解析工作本地域名服务器当一个主机发出DNS查询请求时,这个查询请求首先发给本地域名服务器
注:一个域名服务器所负责的范围,或者说有管理权限的范围,就称为 区域 (Zone)
关于分层, 需要注意的是:
- 每个层的域名上都有自己的域名服务器,最顶层的是根域名服务器
- 每一级域名服务器都知道下级域名服务器的IP地址
- 为了容灾, 每一级至少设置两个或以上的域名服务器
域名的层级有关要点,说明如下:
(1)“www.baidu.com” 的一个最完整的形式应该是 “www.baidu.com.”。
即在每个域名后面会有一个 “.” ,“.” 来表示根,我们统称这种域名叫绝对域名“ Fully Qualified Domain Name ”(FQDN),相当于Linux 系统中的文件绝对路径。可以通过在计算机中输入 “www.baidu.com.” 或 “www.dianrong.com.” 来确认是否可以打开网站。
不需要输入,不代表不存在。
“.” 来表示根,通常我们不需要输入这个根 ,因为计算机和浏览器默认已帮我们输入了这个“.” 根。
(2)域名体系,使用 逆向树 所示,树中的每一个分支,都称为域,一个域名可以属于多个域,如域名 www.baidu.com 属于baidu.com域的一部分,同时也是 com 域的一部分。
(3)“.” 是最树状结构中最顶层的域名,统称为“根”,即每个域名都是由根开始索引的,所有域名都属于根。
(4)域名体系是通过倒着来叙述一个域名,如 www.baidu.com 是先写最下面的 www,在写中间的 baidu ,接着写上面的 com ,最后写 “.” ,只是根可以省略
(5)顶级域名下面的分支是二级域名,即我们平时通过阿里云、腾讯云购买的域名,如 baidu.com 、fastcp.cn 、dianrong.com 等。
(6)二级域名下面的分支为三级域名,有时也可称为服务器名称,如 baidu下面的 www 代表了百度的网站服务名称,music 代表了百度的音乐网站服务器名称。
(7)由根分支出的域名叫 顶域域名(一般简称为 TLD ),一般分为国家地区顶级域名和通用顶级域名。
- 国家顶级域名如我们了解的 cn、jp等。
- 通用顶级域名如我们了解的 com、org、net、edu等,其中表示工商企业的是 .com;表示网络提供商的 .net,表示非盈利组织的 .org ;表示教育的 .edu 。
- 通常我们只能注册二级域名,如果需要注册顶级域名,比如注册类似 .com 这样的域名,在国内需要联系 CNNIC ,由他们进行代理注册,通常价格不菲。大多数情况下,二级域名已经可以完全满足当下的业务需求。
当然三级域名下还可以在分支四级域名出来,DNS 类似于 Unix 文件系统的结构,由根节点在上的反转树表示。最多分分支 127 层,每一层可以由最多 63 个字符组成,每层中间都以 “.” 进行分隔,类似 Unix 文件中以 “/” 分隔每一个目录。域名的总长度不可超过255个字符,仅可使用字符、数字和连字符,不区分大小写。
DNS 资源记录
在 DNS 服务器上,一个域名及其下级域名组成一个区域 (Zone)。一个 Zone的 相关的 DNS 信息构成一个数据库文件。
下面是一条A类型的资源记录(简称为A记录):域名 www.zdns.cn 的数据为 202.173.11.10

记录一条域名信息映射关系,称之为资源记录(RR)。当我们查询域名www.zdns.cn的时候,查询结果得到的资源记录结构体中有如下数据:
- TTL,就是生存周期,是递归服务器会在缓存中保存该资源记录的时长。
- 网络/协议类型,它的代表的标识是IN,IN就是internet,目前DNS系统主要支持的协议是IN。
- type,就是资源记录类型,一般的网站都是都是A记录(IPv4的主机地址)。
- rdata是资源记录数据,就是域名关联的信息数据。
每个区域(Zone)数据库文件都是由资源记录(RR)构成的,一个资源记录就是一行文本,提供了一组有用的 DNS 配置信息。在DNS系统中,最常见的资源记录是Internet类记录,该记录由包含4个字段的数据构成:Name、Value、Type、TTL。其中Name和Value可以理解为一对键值对,但是其具体含义取决于Type的类型,TTL记录了该条记录应当从缓存中删除的时间。
常见的资源记录类型如表所示。
类型编码内容A1将 DNS 域名映射到 IPv4 地址,基本作用是说明一个域名对应了哪些 IPv4 地址NS2权威名称服务器记录,用于说明这个区域有哪些 DNS 服务器负责解析CNAME5别名记录,主机别名对应的规范名称SOA6起始授权机构记录,NS 记录说明了有多台服务器在进行解析,但哪一个才是主服务器,NS 并没有说明,SOA 记录了说明在众多 NS 记录里哪一台才是主要的服务器PTR12IP 地址反向解析,是 A 记录的逆向记录,作用是把 IP 地址解析为域名MX15邮件交换记录,指定负责接收和发送到域中的电子邮件的主机TXT16文本资源记录,用来为某个主机名或域名设置的说明AAAA28将 DNS 域名映射到 IPv6 地址,基本作用是说明一个域名对应了哪些 IPv6 地址
域名解析中,A记录、CNAME、MX记录、NS记录的区别和联系?
联系:
都是区域(Zone)数据库文件都是由资源记录。
A记录: 又称IP指向
用户可以在此设置子域名并指向到自己的目标主机地址上,从而实现通过域名找到服务器。
说明:指向的目标主机地址类型只能使用IP地址;
附加说明:
- 泛域名解析即将该域名所有未指定的子域名都指向一个空间。在“主机名”中填入*,“类型”为A,“IP地址/主机名”中填入web服务器的IP地址,点击“新增”按钮即可。
- 负载均衡的实现:负载均衡(Server Load Balancing,SLB)是指在一系列资源上面动态地分布网络负载。负载均衡可以减少网络拥塞,提高整体网络性能,提高自愈性, 并确保企业关键性应用的可用性。
当相同子域名有多个目标地址时,表示轮循,可以达到负载均衡的目的,但需要虚拟主机服务商支持。
CNAME : 通常称别名指向。
您可以为一个主机设置别名。
比如设置 test.mydomain.com,用来指向一个主机www.rddns.com ,那么以后就可以用test.mydomain.com来代替访问www.rddns.com了。
说明:·
- CNAME的目标主机地址只能使用主机名,不能使用IP地址;
- 主机名前不能有任何其他前缀,如:http://等是不被允许的;
- A记录优先于CNAME记录。即如果一个主机地址同时存在A记录和CNAME记录,则CNAME记录不生效。
MX记录 : 邮件交换记录。
用于将以该域名为结尾的电子邮件指向对应的邮件服务器以进行处理。如:用户所用的邮件是以域名mydomain.com为结尾的,则需要在管理界面中添加该域名的MX记录来处理所有以@mydomain.com结尾的邮件。
说明:
- MX记录可以使用主机名或IP地址;
- MX记录可以通过设置优先级实现主辅服务器设置,“优先级”中的数字越小表示级别越高。
- 也可以使用相同优先级达到负载均衡的目的;
- 如果在“主机名”中填入子域名则此MX记录只对该子域名生效。
附加说明:
- 负载均衡服务器负载均衡(Server Load Balancing,SLB)是指在一系列资源上面智能地分布网络负载。负载均衡可以减少网络拥塞,提高整体网络性能,提高自愈性,并确保企业关键性应用的可用性。当域名的MX记录有多个目标地址且优先级相同时,表示轮循,可以达到负载均衡的目的,但需要邮箱服务商支持。
NS记录:指向DNS子域名
服务器解析记录, 用来表明由哪台服务器对该域名进行解析。这里的NS记录只对子域名生效。
例如用户希望由12.34.56.78 这台服务器解析 news.mydomain.com,则需要设置 news.mydomain.com 的NS记录。
说明:
- “优先级”中的数字越小表示级别越高;
- “IP地址/主机名”中既可以填写IP地址,也可以填写像 ns.mydomain.com 这样的主机地址,但必须保证该主机地址有效。
如,将news.mydomain.com的NS记录指向到 ns.mydomain.com,在设置NS记录的同时还需要设置ns.mydomain.com的指向,否则NS记录将无法正常解析;
- NS记录优先于A记录。
即,如果一个主机地址同时存在NS记录和A记录,则A记录不生效。这里的NS记录只对子域名生效。
实战:nslookup 进行IP查看
Nslookup一般是用来确认DNS服务器动作的.
nslookup有多个选择功能用命令行键入nslookup<主机名>执行,即可显示出目标服务器的主机名和对应的IP地址,称之为正向解析.
如果不能使用dig、nslookup,如下:
[root@cdh1 ~]# nslookup www.baidu.com
-bash: nslookup: command not found
报错,命令找不到,是因为新安装的centos7,没有安装bind-utils,安装后就可以运行nslookup了
安装相应软件包
yum install -y bind-utils

命令的基本格式
nslookup domain [dns-server]
1 使用命令 nslookup 域名 查询IP
[root@cdh1 ~]# nslookup www.baidu.com
Server: 10.0.2.3
Address: 10.0.2.3#53
Non-authoritative answer:
www.baidu.com canonical name = www.a.shifen.com.
Name: www.a.shifen.com
Address: 36.152.44.95
Name: www.a.shifen.com
Address: 36.152.44.96
Name: www.a.shifen.com
Address: ::1
结果说明如下:
Server: 10.0.2.3 --->指定的dns服务器
Address: 10.0.2.3#53 ------>指定的dns服务器的IP和端口
Non-authoritative answer: ----->未验证的回答
baidu.com canonical name = www.a.shifen.com. ------->目标域名的规范名称(正名/别名)记录
Name: www.a.shifen.com ------->目标域名
Address: 36.152.44.95 ------->目标返回的Ip
Name: www.a.shifen.com ------->目标域名
Address: 36.152.44.96 ------->目标返回的Ip
Name: www.a.shifen.com
Address: ::1
没有指定DNS服务器,使用默认的本地DNS服务器,保存在 /etc/resolv.conf 配置文件中。
[root@cdh1 ~]# cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 10.0.2.3
2 使用命令 nslookup 域名 dns-server 查询IP
[root@cdh1 ~]# nslookup www.baidu.com 114.114.114.114
Server: 114.114.114.114
Address: 114.114.114.114#53
Non-authoritative answer:
www.baidu.com canonical name = www.a.shifen.com.
Name: www.a.shifen.com
Address: 36.152.44.95
Name: www.a.shifen.com
Address: 36.152.44.96
以上的命令,通过电信DNS 114.114.114.114 查询 www.baidu.com 的IP地址。
3 Non-authoritative answer 的说明
Non-authoritative answer表示解析结果来自非权威服务器,也就是说这个结果来自缓存,并没有完全经历全部的解析过程,从某个缓存中读取的结果,这个结果存在一定的隐患,比如域名对应的IP地址已经更变。
查询其他记录
直接查询返回的是A记录,我们可以指定参数,查询其他记录,比如AAAA、MX等。
nslookup -qt=type domain [dns-server]
其中,type可以是以下这些类型:
- A 地址记录
- AAAA 地址记录
- AFSDB Andrew文件系统数据库服务器记录
- ATMA ATM地址记录
- CNAME 别名记录
- HINFO 硬件配置记录,包括CPU、操作系统信息
- ISDN 域名对应的ISDN号码
- MB 存放指定邮箱的服务器
- MG 邮件组记录
- MINFO 邮件组和邮箱的信息记录
- MR 改名的邮箱记录
- MX 邮件服务器记录
- NS 名字服务器记录
- PTR 反向记录
- RP 负责人记录
- RT 路由穿透记录
- SRV TCP服务器信息记录
- TXT 域名对应的文本信息
- X25 域名对应的X.25地址记录
例如:
[root@localhost ~]# nslookup -qt=mx baidu.com 8.8.8.8
*** Invalid option: qt=mx
Server: 8.8.8.8
Address: 8.8.8.8#53
Non-authoritative answer:
Name: baidu.com
Address: 111.13.101.208
Name: baidu.com
Address: 123.125.114.144
Name: baidu.com
Address: 180.149.132.47
Name: baidu.com
Address: 220.181.57.217
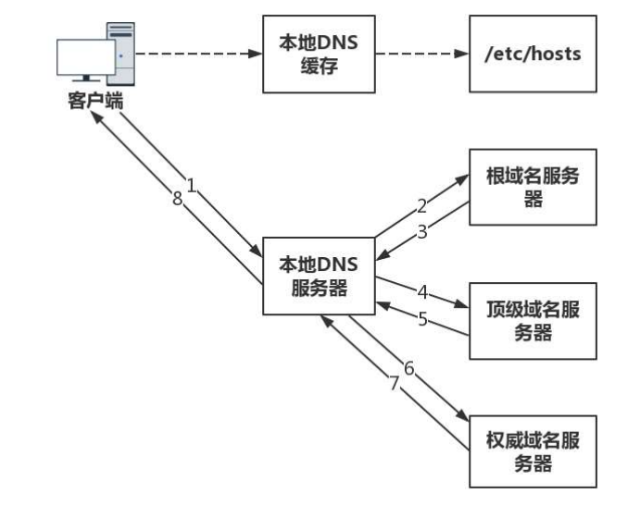
DNS 解析过程
总体的三大步骤:
1、缓存查找IP
2、本机的hosts文件查找IP
3、DNS服务器查找IP
step1:缓存查找IP
第一步:检查浏览器缓存中是否缓存过该域名对应的IP地址
用户通过浏览器浏览过某网站之后,浏览器就会自动缓存该网站域名对应的
IP
地址,当用户再次访问的时候,浏览器就会从缓存中查找该域名对应的IP地址.
但是,浏览器的本地缓存,不仅是有大小限制,而且还有时间限制(域名被缓存的时间通过
TTL
属性来设置),所以存在域名对应的
IP
找不到的情况。
当浏览器从缓存中找到了该网站域名对应的
IP
地址,将进行下一步骤。
对于
IP的缓存时间问题,不宜设置太长的缓存时间,时间太长,如果域名对应的
IP发生变化,那么用户将在一段时间内无法正常访问到网站,如果太短,那么又造成频繁解析域名。
step2:本机的hosts文件查找IP
第二步:如果在浏览器缓存中没有找到IP,那么找本机的hosts文件中是否存在IP配置
如果第一个步骤没有完成对域名的解析过程,那么浏览器会去系统hosts文件中,查找系统是否配置过这个域名对应的
IP
地址,可以理解为系统也具备域名配置的基本能力。
- 在
Windows系统中,hosts文件位置在C:\Windows\System32\drivers\etc\hosts。 - 在
Linux或者Mac系统中,hosts文件在/etc/hosts文件中。
对于开发者来说,通过hosts绑定域名和
IP
,可以轻松切换环境,可以从测试环境切换到开发环境,方便开发和测试。

step3:DNS服务器查找IP
第三步:向本地域名解析服务系统发起域名解析的请求
如果在本地无法完成域名的解析,那么系统只能请求域名解析服务系统进行解析,本地域名系统
LDNS
一般都是本地区的域名服务器。local dns (local name server)是客户端网络设置的一部分,要么是手工配置,要么从DHCP得到。一般local dns 在从网络上靠近客户端。
- 比如你连接的校园网,那么域名解析系统就在你的校园机房里;
- 如果你连接的是电信、移动或者联通的网络,那么本地域名解析服务器就在本地区,由各自的运营商来提供服务。
对于本地
DNS
服务器地址,
Windows
系统使用命令
ipconfig
就可以查看,在
Linux
和
Mac
系统下,直接使用命令
cat /etc/resolv.conf
来查看
LDNS
服务地址。
LDNS
一般都缓存了大部分的域名解析的结果,当然缓存时间也受域名失效时间控制,大部分的解析工作到这里就差不多已经结束了,
LDNS
负责了大部分的解析工作。
LDNS
解析的总体过程

LDNS
总体过程总结起来就是三句话
- 从"根域名服务器"查到"一级域名服务器"的NS记录和A记录(IP地址)
- 从"一级域名服务器"查到"二级域名服务器"的NS记录和A记录(IP地址)
- 从"二级域名服务器"查出"主机名"的IP地址
DNS 查询类型
从客户端出发,完整的DNS 查找过程中,会出现三种类型的查询。
通过组合使用这些查询,优化的 DNS 解析过程可缩短传输距离。
递归查询
本机向本地域名服务器发出一次查询请求,就静待最终的结果。如果本地域名服务器无法解析,自己会以DNS客户机的身份向其它域名服务器查询,直到得到最终的IP地址告诉本机。

在理想情况下,可以使用缓存的记录数据,从而使 DNS 域名服务器能够直接使用非递归查询。

迭代查询
本地域名服务器向根域名服务器查询,根域名服务器告诉它下一步到哪里去查询,然后它再去查,每次它都是以客户机的身份去各个服务器查询。

迭代查询一般发生在 DNS Server 之间,当 Client 发出域名解析的请求后,DNS Server 需要给予最佳答案,这个最佳答案可能是"距离最近"的顶级域名服务器,也能是权威域名服务器。无论如何,Client 需要对返回结果再次发起请求,知道获得最终结果
非递归查询
可以理解为缓存查找或者一次搞定的查找。
非递归查询发生在 Client 和 DNS Server 之间,指的是,请求的 DNS Server 已经知道答案,直接返回。这里可能有两种情况,一种是 DNS Server 本机缓存了对应的 IP,或者是缓存了对应的域名的权威服务器。第二种情况只需要再发一次请求,即可拿到结果返回
当 DNS 解析器客户端查询 DNS 服务器以获取其有权访问的记录时通常会进行此查询,因为其对该记录具有权威性,或者该记录存在于其缓存内。
DNS 服务器通常会缓存 DNS 记录,查询到来后能够直接返回缓存结果,以防止更多带宽消耗和上游服务器上的负载。
递归查询与迭代查询相结合


从递归和迭代查询可以看出:
客户端-本地dns服务端:
这部分属于递归查询。递归查询时,返回的结果只有两种:查询成功或查询失败.
本地dns服务端—外网:
这部分属于迭代查询。迭代查询,又称作重指引,返回的是最佳的查询点或者主机地址.
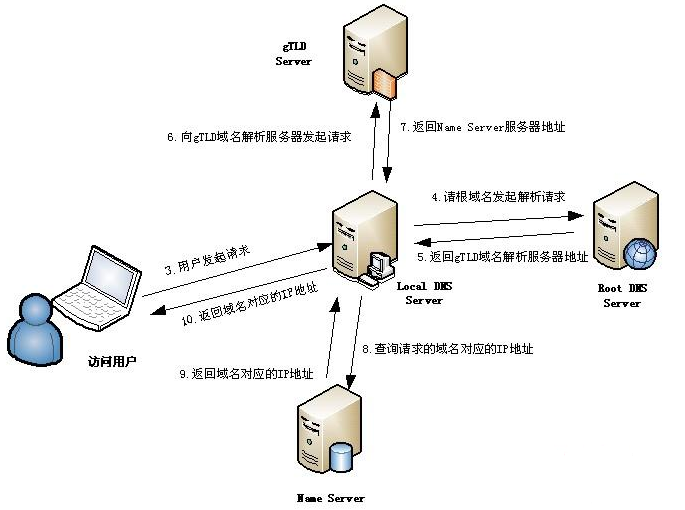
详解:DNS 解析过程10个小步骤
- 浏览器先检查自身缓存中有没有被解析过的这个域名对应的ip地址,如果有,解析结束。同时域名被缓存的时间也可通过TTL属性来设置。
- 如果浏览器缓存中没有(专业点叫还没命中),浏览器会检查操作系统缓存中有没有对应的已解析过的结果。而操作系统也有一个域名解析的过程。在windows中可通过c盘里一个叫hosts的文件来设置,如果你在这里指定了一个域名对应的ip地址,那浏览器会首先使用这个ip地址。
但是这种操作系统级别的域名解析规程也被很多黑客利用,通过修改你的hosts文件里的内容把特定的域名解析到他指定的ip地址上,造成所谓的域名劫持。所以在windows7中将hosts文件设置成了readonly,防止被恶意篡改。
- 如果至此还没有命中域名,才会真正的请求本地域名服务器(LDNS)来解析这个域名,这台服务器一般在你的城市的某个角落,距离你不会很远,并且这台服务器的性能都很好,一般都会缓存域名解析结果,大约80%的域名解析到这里就完成了。
- 如果LDNS仍然没有命中,就直接跳到Root Server 域名服务器请求解析
- 根域名服务器返回给LDNS一个所查询域的主域名服务器(gTLD Server,国际顶尖域名服务器,如.com .cn .org等)地址
- 此时LDNS再发送请求给上一步返回的gTLD
- 接受请求的gTLD查找并返回这个域名对应的Name Server的地址,这个Name Server就是网站注册的域名服务器
- Name Server根据映射关系表找到目标ip,返回给LDNS
- LDNS缓存这个域名和对应的ip
- LDNS把解析的结果返回给用户,用户根据TTL值缓存到本地系统缓存中,域名解析过程至此结束
实战:dig 命令查看域名解析过程
什么是dig
dig(域信息搜索器)命令是一个用于询问 DNS 域名服务器的灵活的工具。它执行 DNS 搜索,显示从受请求的域名服务器返回的答复。多数 DNS 管理员利用 dig 作为 DNS 问题的故障诊断,因为它灵活性好、易用、输出清晰。虽然通常情况下 dig 使用命令行参数,但它也可以按批处理模式从文件读取搜索请求。不同于早期版本,dig 的 BIND9 实现允许从命令行发出多个查询。除非被告知请求特定域名服务器,dig 将尝试 /etc/resolv.conf 中列举的所有服务器。当未指定任何命令行参数或选项时,dig 将对“.”(根)执行 NS 查询。
语法
dig [@server] [-b address] [-c class] [-f filename] [-k filename] [ -n ][-p port#] [-t type] [-x addr] [-y name:key] [name] [type] [class] [queryopt…]
-b address 设置所要询问地址的源 IP 地址。这必须是主机网络接口上的某一合法的地址。
-c class 缺省查询类(IN for internet)由选项 -c 重设。class 可以是任何合法类,比如查询 Hesiod 记录的 HS 类或查询 CHAOSNET 记录的 CH 类。
-f filename 使 dig 在批处理模式下运行,通过从文件 filename 读取一系列搜索请求加以处理。文件包含许多查询;每行一个。文件中的每一项都应该以和使用命令行接口对 dig 的查询相同的方法来组织。
-h 当使用选项 -h 时,显示一个简短的命令行参数和选项摘要。
-k filename 要签署由 dig 发送的 DNS 查询以及对它们使用事务签名(TSIG)的响应,用选项 -k 指定 TSIG 密钥文件。
-n 缺省情况下,使用 IP6.ARPA 域和 RFC2874 定义的二进制标号搜索 IPv6 地址。为了使用更早的、使用 IP6.INT 域和 nibble 标签的 RFC1886 方法,指定选项 -n(nibble)。
-p port# 如果需要查询一个非标准的端口号,则使用选项 -p。port# 是 dig 将发送其查询的端口号,而不是标准的 DNS 端口号 53。该选项可用于测试已在非标准端口号上配置成侦听查询的域名服务器。
-t type 设置查询类型为 type。可以是 BIND9 支持的任意有效查询类型。缺省查询类型是 A,除非提供 -x 选项来指示一个逆向查询。通过指定 AXFR 的 type 可以请求一个区域传输。当需要增量区域传输(IXFR)时,type 设置为 ixfr=N。增量区域传输将包含自从区域的 SOA 记录中的序列号改为 N 之后对区域所做的更改。
-x addr 逆向查询(将地址映射到名称)可以通过 -x 选项加以简化。 addr 是一个以小数点为界的 IPv4 地址或冒号为界的 IPv6 地址。当使用这个选项时,无需提供 name、class 和 type 参 数。dig 自动运行类似 11.12.13.10.in-addr.arpa 的域名查询,并分别设置查询类型和类为 PTR 和 IN。
-y name: key 您可以通过命令行上的 -y 选项指定 TSIG 密钥;name 是 TSIG 密码的名称,key 是实际的密码。密码是 64 位加密字符 串,通常由 dnssec-keygen(8)生成。当在多用户系统上使用选项 -y 时应该谨慎,因为密码在 ps(1)的输出或 shell 的历史 文件中可能是可见的。当同时使用 dig 和 TSCG 认证时,被查询的名称服务器需要知道密码和解码规则。在 BIND 中,通过提供正确的密码和 named.conf 中的服务器声明实现。
查询选项
dig 提供查询选项号,它影响搜索方式和结果显示。一些在查询请求报头设置或复位标志位,一部分决定显示哪些回复信息,其他的确定超时和重试战略。每个查询选项 被带前缀(+)的关键字标识。一些关键字设置或复位一个选项。通常前缀是求反关键字含义的字符串 no。其他关键字分配各选项的值,比如超时时间间隔。它 们的格式形如 +keyword=value。查询选项是:
+[no]tcp
查询域名服务器时使用 [不使用] TCP。缺省行为是使用 UDP,除非是 AXFR 或 IXFR 请求,才使用 TCP 连接。
+[no]vc
查询名称服务器时使用 [不使用] TCP。+[no]tcp 的备用语法提供了向下兼容。vc 代表虚电路。
+[no]ignore
忽略 UDP 响应的中断,而不是用 TCP 重试。缺省情况运行 TCP 重试。
+domain=somename
设定包含单个域 somename 的搜索列表,好像被 /etc/resolv.conf 中的域伪指令指定,并且启用搜索列表处理,好像给定了 +search 选项。
+[no]search
使用 [不使用] 搜索列表或 resolv.conf 中的域伪指令(如果有的话)定义的搜索列表。缺省情况不使用搜索列表。
+[no]defname
不建议看作 +[no]search 的同义词。
+[no]aaonly
该选项不做任何事。它用来提供对设置成未实现解析器标志的 dig 的旧版本的兼容性。
+[no]adflag
在查询中设置 [不设置] AD(真实数据)位。目前 AD 位只在响应中有标准含义,而查询中没有,但是出于完整性考虑在查询中这种性能可以设置。
+[no]cdflag
在查询中设置 [不设置] CD(检查禁用)位。它请求服务器不运行响应信息的 DNSSEC 合法性。
+[no]recursive
切换查询中的 RD(要求递归)位设置。在缺省情况下设置该位,也就是说 dig 正常情形下发送递归查询。当使用查询选项 +nssearch 或 +trace 时,递归自动禁用。
+[no]nssearch
这个选项被设置时,dig 试图寻找包含待搜名称的网段的权威域名服务器,并显示网段中每台域名服务器的 SOA 记录。
+[no]trace
切换为待查询名称从根名称服务器开始的代理路径跟踪。缺省情况不使用跟踪。一旦启用跟踪,dig 使用迭代查询解析待查询名称。它将按照从根服务器的参照,显示来自每台使用解析查询的服务器的应答。
+[no]cmd
设定在输出中显示指出 dig 版本及其所用的查询选项的初始注释。缺省情况下显示注释。
+[no]short
提供简要答复。缺省值是以冗长格式显示答复信息。
+[no]identify
当启用 +short 选项时,显示 [或不显示] 提供应答的 IP 地址和端口号。如果请求简短格式应答,缺省情况不显示提供应答的服务器的源地址和端口号。
+[no]comments
切换输出中的注释行显示。缺省值是显示注释。
+[no]stats
该查询选项设定显示统计信息:查询进行时,应答的大小等等。缺省显示查询统计信息。
+[no]qr
显示 [不显示] 发送的查询请求。缺省不显示。
+[no]question
当返回应答时,显示 [不显示] 查询请求的问题部分。缺省作为注释显示问题部分。
+[no]answer
显示 [不显示] 应答的回答部分。缺省显示。
+[no]authority
显示 [不显示] 应答的权限部分。缺省显示。
+[no]additional
显示 [不显示] 应答的附加部分。缺省显示。
+[no]all
设置或清除所有显示标志。
+time=T
为查询设置超时时间为 T 秒。缺省是 5 秒。如果将 T 设置为小于 1 的数,则以 1 秒作为查询超时时间。
+tries=A
设置向服务器发送 UDP 查询请求的重试次数为 A,代替缺省的 3 次。如果把 A 小于或等于 0,则采用 1 为重试次数。
+ndots=D
出 于完全考虑,设置必须出现在名称 D 的点数。缺省值是使用在 /etc/resolv.conf 中的 ndots 语句定义的,或者是 1,如果没有 ndots 语句的话。带更少点数的名称被解释为相对名称,并通过搜索列表中的域或文件 /etc/resolv.conf 中的域伪指令进行搜索。
+bufsize=B
设置使用 EDNS0 的 UDP 消息缓冲区大小为 B 字节。缓冲区的最大值和最小值分别为 65535 和 0。超出这个范围的值自动舍入到最近的有效值。
+[no]multiline
以详细的多行格式显示类似 SOA 的记录,并附带可读注释。缺省值是每单个行上显示一条记录,以便于计算机解析 dig 的输出。
dig最基本的使用方式就是
dig
即查询域名的A记录,查询的dns服务器将采用系统配置的服务器,即/etc/resovle.conf 中的。
如果要查询其他类型的记录,比如MX,CNAME,NS,PTR等,只需将类型加在命令后面即可
dig mx
dig ns
另外一个重要的功能是+trace参数,使用这个参数之后将显示从根域逐级查询的过程
dig a +trace
实战: dig查看 www.baidu.com 解析过程
如果需要浏览全部的解析过程,那么可以使用
dig
命令来查看解析过程。以 www.baidu.com 为例。
总的过程记录
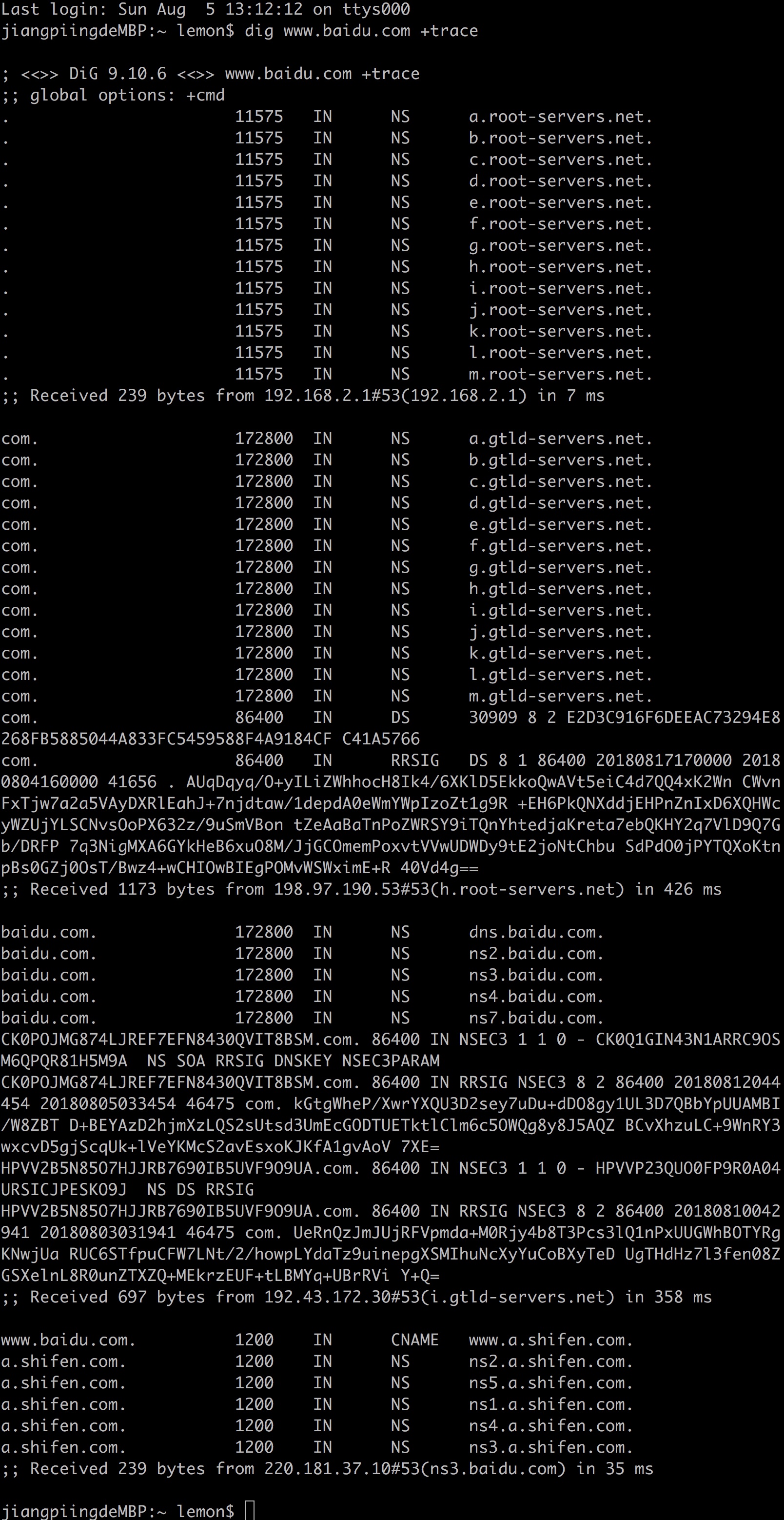
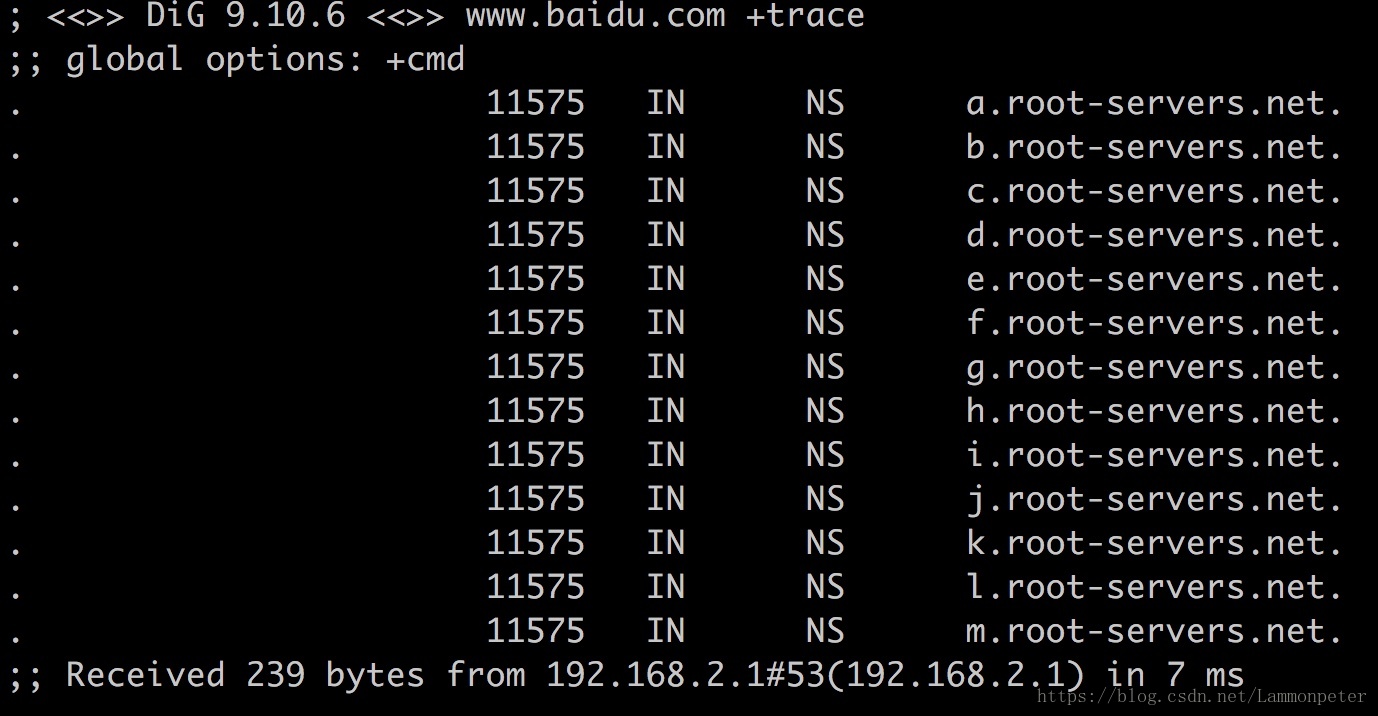
第一步:根DNS 服务器获取
从本地
DNS
域名解析服务器获取到
13
个根
DNS
域名服务器
(.)
对应的主机名。
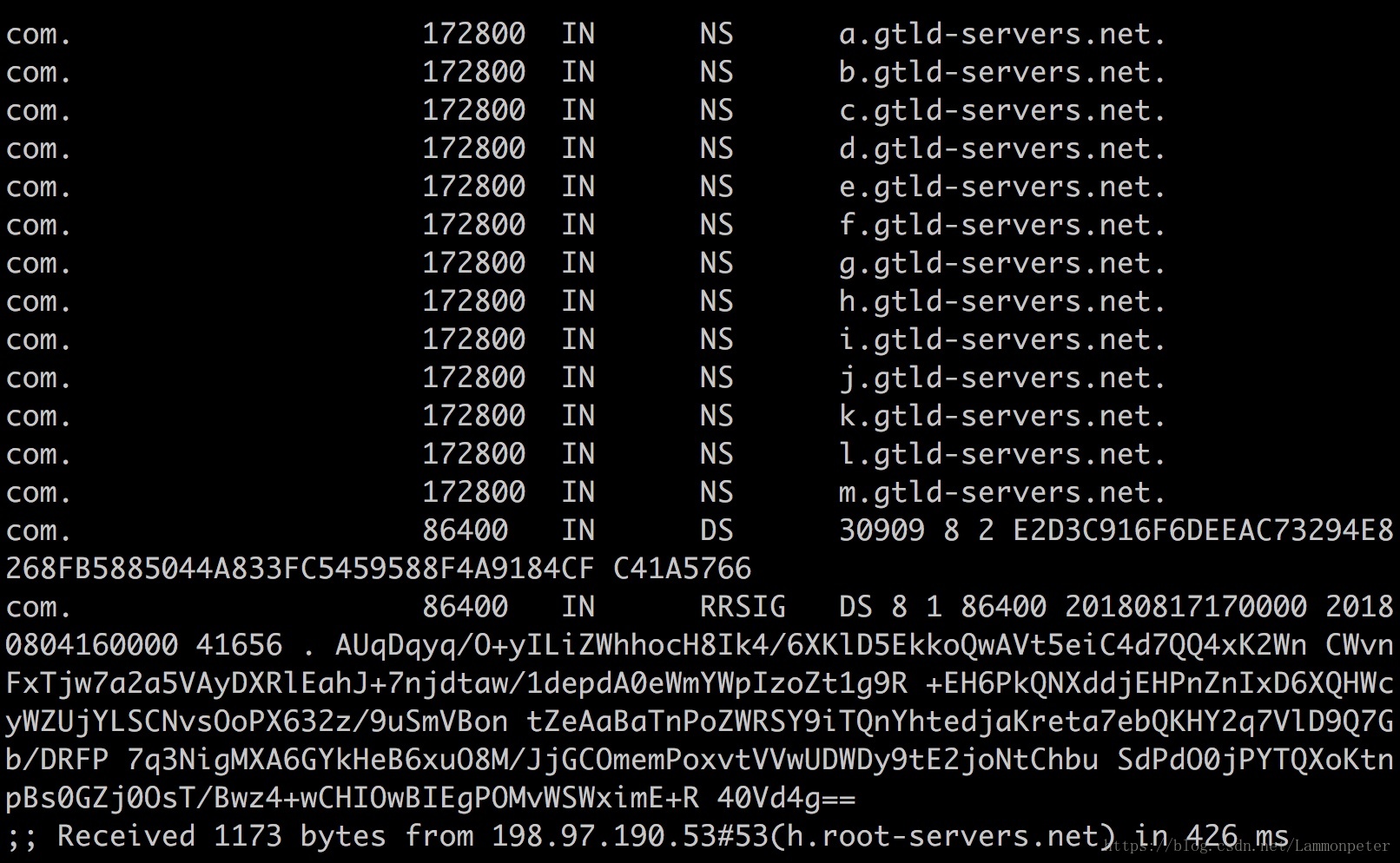
第二步:一级(或者顶级)DNS 服务器获取
从
13
个根域名服务器中的其中一个(这里是
h.root-servers.net
)获取到顶级
com.
的服务器
IP
(未显示)和名称。
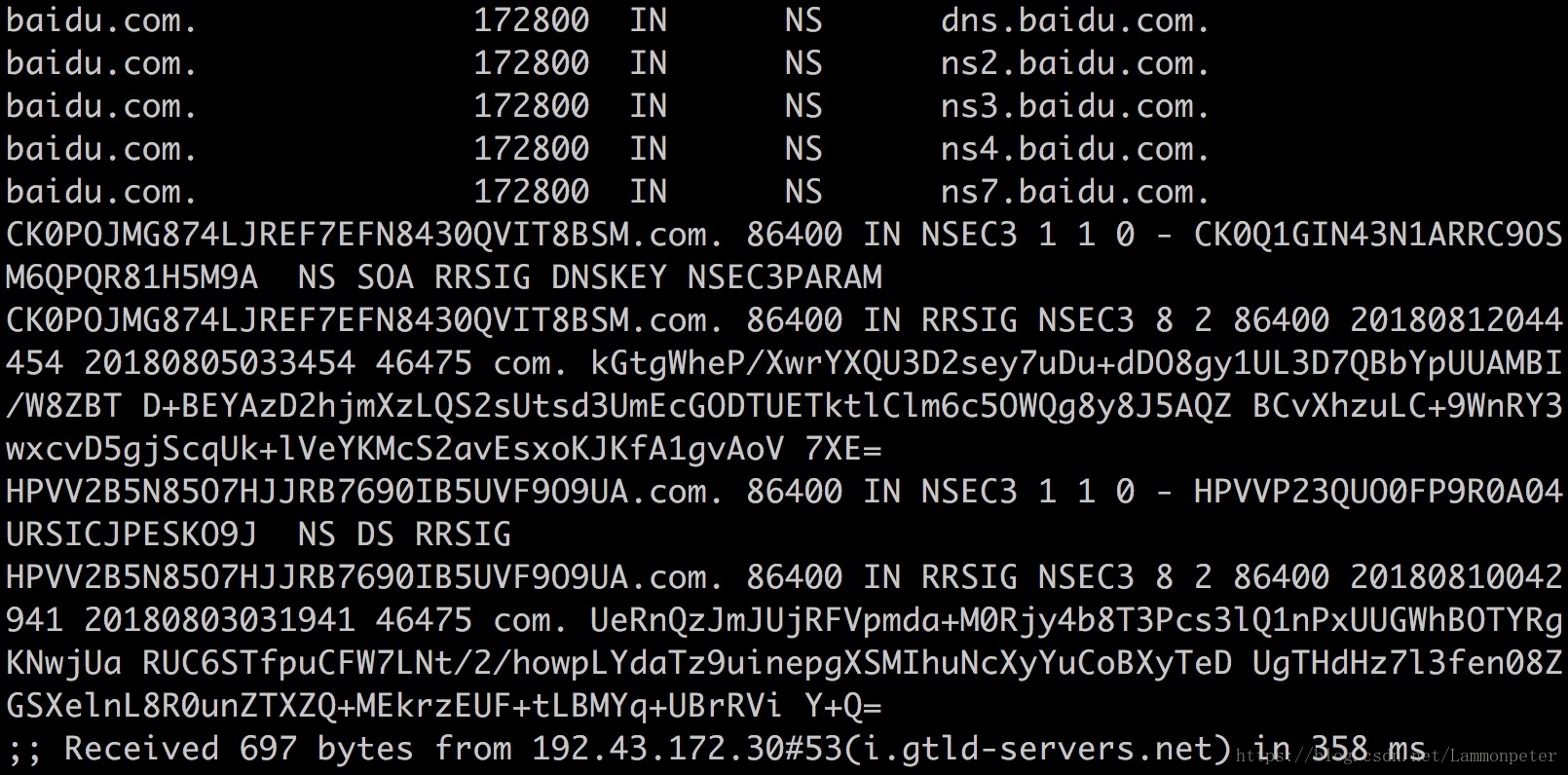
第三步:二级(或者顶级)DNS 服务器获取
向
com.
域的一台服务器
192.43.172.30(i.gtld-servers.net)
请求解析,它返回了
baidu.com
域的服务器
IP
(未显示)和名称,百度有四台顶级域的服务器。
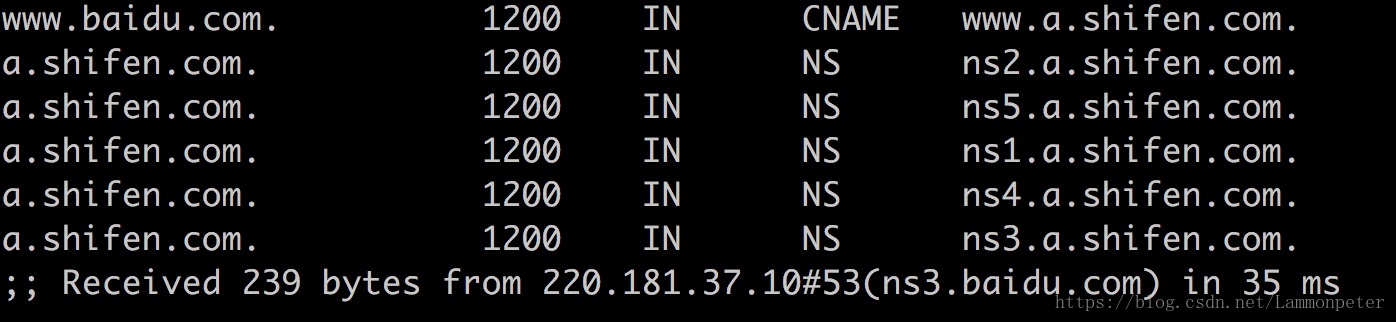
第四步:三级(或者顶级)DNS 服务器获取
向百度的顶级域服务器
220.181.37.10(ns3.baidu.com)
请求
www.baidu.com
,它发现这个
www
有个别名,而不是一台主机,别名是
www.a.shifen.com
。
一般情况下,
DNS
解析到别名就停止了,返回了具体的
IP
地址
如果想看到具体的
IP
地址,可以进一步对别名进行解析,解析结果如下:
这时候看到最后的解析结果是
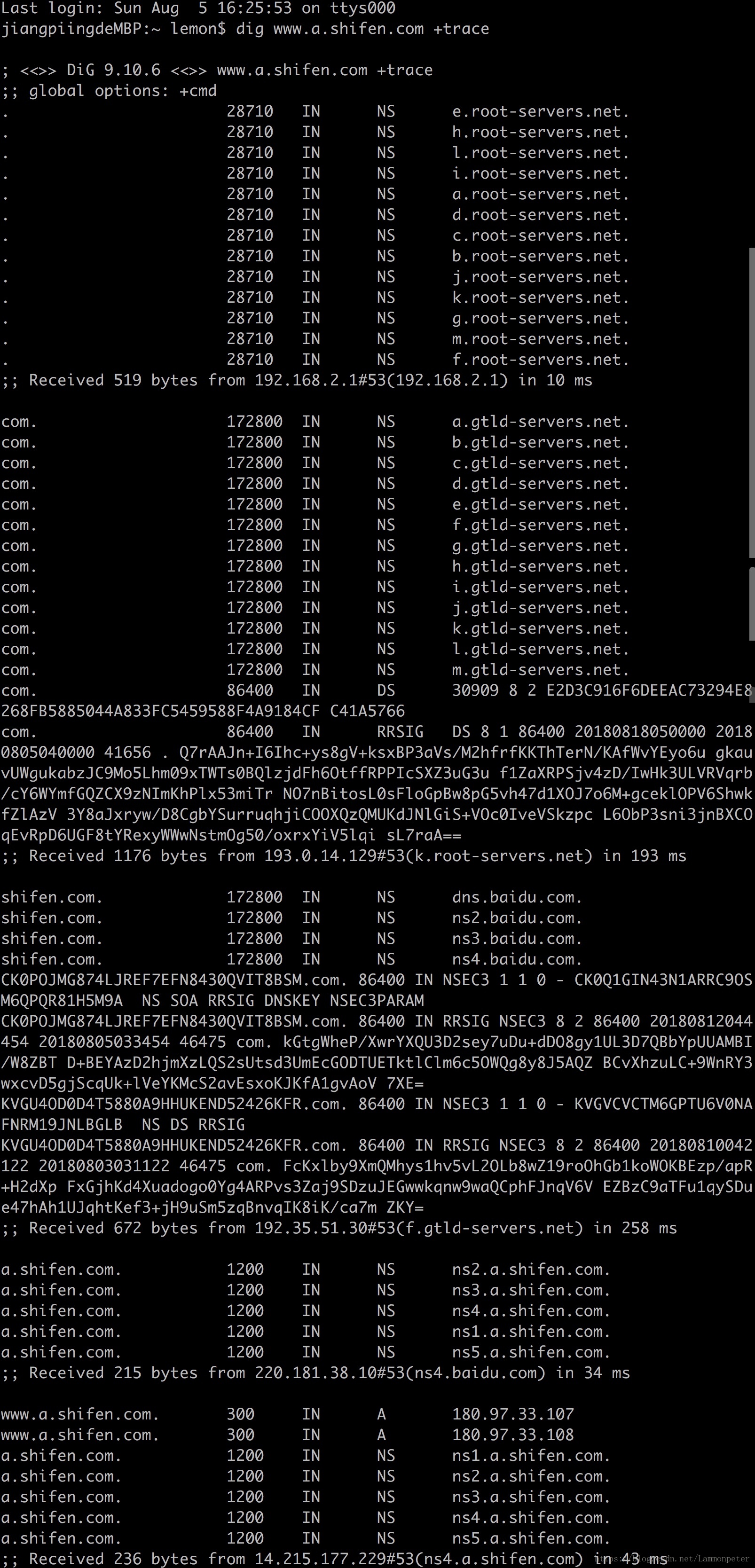
180.97.33.107
和
180.97.33.108
。在解析别名的过程中,可以发现
shifen.com
和
baidu.com
都是指定了相同的域名解析服务器。以上是一个域名的解析过程,最后的解析结果和一开始的使用
nslookup
的结果一致。
DNS协议原理与实战
后面我将使用 wireshark 抓取 DNS 的数据包,但是在开始之前 ,得先了解一下 DNS 的报文结构
DNS 的报文结构
整个 DNS 格式主要分为 3 部分内容,即基础结构部分、问题部分、资源记录部分。
事务 ID、标志、问题计数、回答资源记录数、权威名称服务器计数、附加资源记录数这 6 个字段是DNS的报文首部,共 12 个字节。
Transaction ID
请求和应答的事务ID应当是一个:0xd0d7
Flags
标志字段里的内容比较多,每个字段的含义如下
- QR(Response):查询请求/响应的标志信息。查询请求时,值为 0;响应时,值为 1。
- Opcode:操作码。其中,0 表示标准查询;1 表示反向查询;2 表示服务器状态请求。
- AA(Authoritative):授权应答,该字段在响应报文中有效。值为 1 时,表示名称服务器是权威服务器;值为 0 时,表示不是权威服务器。
- TC(Truncated):表示是否被截断。值为 1 时,表示响应已超过 512 字节并已被截断,只返回前 512 个字节。
- RD(Recursion Desired):期望递归。该字段能在一个查询中设置,并在响应中返回。该标志告诉名称服务器必须处理这个查询,这种方式被称为一个递归查询。如果该位为 0,且被请求的名称服务器没有一个授权回答,它将返回一个能解答该查询的其他名称服务器列表。这种方式被称为迭代查询。
- RA(Recursion Available):可用递归。该字段只出现在响应报文中。当值为 1 时,表示服务器支持递归查询。
- Z:保留字段,在所有的请求和应答报文中,它的值必须为 0。
- rcode(Reply code):返回码字段,表示响应的差错状态。当值为 0 时,表示没有错误;当值为 1 时,表示报文格式错误(Format error),服务器不能理解请求的报文;当值为 2 时,表示域名服务器失败(Server failure),因为服务器的原因导致没办法处理这个请求;当值为 3 时,表示名字错误(Name Error),只有对授权域名解析服务器有意义,指出解析的域名不存在;当值为 4 时,表示查询类型不支持(Not Implemented),即域名服务器不支持查询类型;当值为 5 时,表示拒绝(Refused),一般是服务器由于设置的策略拒绝给出应答,如服务器不希望对某些请求者给出应答。
Answer RRs
回答资源记录数,在应答包里为 2,说明返回了两条查询结果,你可以在 Answer 字段里看到。
Authority RRs
权威名称服务器计数
Additionnal RRs
附加资源记录数
Answers
应答的主要内容,这里返回两条结果,每条结果里的字段有

基础结构部分
DNS 报文的基础结构部分指的是报文首部,如图所示。

该部分中每个字段含义如下。
- 事务 ID:DNS 报文的 ID 标识。对于请求报文和其对应的应答报文,该字段的值是相同的。通过它可以区分 DNS 应答报文是对哪个请求进行响应的。
- 标志:DNS 报文中的标志字段。
- 问题计数:DNS 查询请求的数目。
- 回答资源记录数:DNS 响应的数目。
- 权威名称服务器计数:权威名称服务器的数目。
- 附加资源记录数:额外的记录数目(权威名称服务器对应 IP 地址的数目)。
基础结构部分中的标志字段又分为若干个字段,如图所示。

标志字段中每个字段的含义如下:
- QR(Response):查询请求/响应的标志信息。查询请求时,值为 0;响应时,值为 1。
- Opcode:操作码。其中,0 表示标准查询;1 表示反向查询;2 表示服务器状态请求。
- AA(Authoritative):授权应答,该字段在响应报文中有效。值为 1 时,表示名称服务器是权威服务器;值为 0 时,表示不是权威服务器。
- TC(Truncated):表示是否被截断。值为 1 时,表示响应已超过 512 字节并已被截断,只返回前 512 个字节。
- RD(Recursion Desired):期望递归。该字段能在一个查询中设置,并在响应中返回。该标志告诉名称服务器必须处理这个查询,这种方式被称为一个递归查询。如果该位为 0,且被请求的名称服务器没有一个授权回答,它将返回一个能解答该查询的其他名称服务器列表。这种方式被称为迭代查询。
- RA(Recursion Available):可用递归。该字段只出现在响应报文中。当值为 1 时,表示服务器支持递归查询。
- Z:保留字段,在所有的请求和应答报文中,它的值必须为 0。
- rcode(Reply code):返回码字段,表示响应的差错状态。当值为 0 时,表示没有错误;当值为 1 时,表示报文格式错误(Format error),服务器不能理解请求的报文;当值为 2 时,表示域名服务器失败(Server failure),因为服务器的原因导致没办法处理这个请求;当值为 3 时,表示名字错误(Name Error),只有对授权域名解析服务器有意义,指出解析的域名不存在;当值为 4 时,表示查询类型不支持(Not Implemented),即域名服务器不支持查询类型;当值为 5 时,表示拒绝(Refused),一般是服务器由于设置的策略拒绝给出应答,如服务器不希望对某些请求者给出应答。
为了能够更好地了解 DNS 数据包的基础结构部分,下面通过捕获的 DNS 数据包查看基础结构部分。

图中的数据包为 DNS 请求包,Domain Name System(query) 部分方框标注中的信息为 DNS 报文中的基础结构部分。
Domain Name System (query)
Transaction ID: 0x9ad0 #事务ID
Flags: 0x0000 Standard query #报文中的标志字段
0... .... .... .... = Response: Message is a query
#QR字段, 值为0, 因为是一个请求包
.000 0... .... .... = Opcode: Standard query (0)
#Opcode字段, 值为0, 因为是标准查询
.... ..0. .... .... = Truncated: Message is not truncated
#TC字段
.... ...0 .... .... = Recursion desired: Don't do query recursively
#RD字段
.... .... .0.. .... = Z: reserved (0) #保留字段, 值为0
.... .... ...0 .... = Non-authenticated data: Unacceptable
#保留字段, 值为0
Questions: 1 #问题计数, 这里有1个问题
Answer RRs: 0 #回答资源记录数
Authority RRs: 0 #权威名称服务器计数
Additional RRs: 0 #附加资源记录数
以上输出信息显示了 DNS 请求报文中基础结构部分中包含的字段以及对应的值。这里需要注意的是,在请求中 Questions 的值不可能为 0;Answer RRs,Authority RRs,Additional RRs 的值都为 0,因为在请求中还没有响应的查询结果信息。这些信息在响应包中会有相应的值。

图中方框标注部分为响应包中基础结构部分,每个字段如下:
Domain Name System (response)
Transaction ID: 0x9ad0 #事务ID
Flags: 0x8180 Standard query response, No error #报文中的标志字段
1... .... .... .... = Response: Message is a response
#QR字段, 值为1, 因为是一个响应包
.000 0... .... .... = Opcode: Standard query (0) # Opcode字段
.... .0.. .... .... = Authoritative: Server is not an authority for
domain #AA字段
.... ..0. .... .... = Truncated: Message is not truncated
#TC字段
.... ...1 .... .... = Recursion desired: Do query recursively
#RD字段
.... .... 1... .... = Recursion available: Server can do recursive
queries #RA字段
.... .... .0.. .... = Z: reserved (0)
.... .... ..0. .... = Answer authenticated: Answer/authority portion
was not authenticated by the server
.... .... ...0 .... = Non-authenticated data: Unacceptable
.... .... .... 0000 = Reply code: No error (0) #返回码字段
Questions: 1
Answer RRs: 2
Authority RRs: 5
Additional RRs: 5
以上输出信息中加粗部分为 DNS 响应包比请求包中多出来的字段信息,这些字段信息只能出现在响应包中。在输出信息最后可以看到 Answer RRs,Authority RRs,Additional RRs 都有了相应的值(不一定全为 0)。
问题部分
问题部分指的是报文格式中查询问题区域(Queries)部分。
该部分是用来显示 DNS 查询请求的问题,通常只有一个问题。该部分包含正在进行的查询信息,包含查询名(被查询主机名字)、查询类型、查询类。

该部分中每个字段含义如下:
- 查询名:一般为要查询的域名,有时也会是 IP 地址,用于反向查询。
- 查询类型:DNS 查询请求的资源类型。通常查询类型为 A 类型,表示由域名获取对应的 IP 地址。
- 查询类:地址类型,通常为互联网地址,值为 1。
- DNS 请求包的问题部分字段信息,如图所示。

在下图中,Queries 部分的信息为问题部分信息,每个字段说明如下: 其中,可以看到 DNS 请求类型为 A,那么得到的响应信息也应该为 A 类型。

从图中 Queries 部分中可以看到,响应包中的查询类型也是 A,与请求包的查询类型是一致的。
资源记录部分
资源记录部分是指 DNS 报文格式中的最后三个字段,包括:
- 回答问题区域字段、
- 权威名称服务器区域字段、
- 附加信息区域字段。
这三个字段均采用一种称为资源记录的格式,格式如图所示。

资源记录格式中每个字段含义如下:
- 域名:DNS 请求的域名。
- 类型:资源记录的类型,与问题部分中的查询类型值是一样的。
- 类:地址类型,与问题部分中的查询类值是一样的。
- 生存时间:以秒为单位,表示资源记录的生命周期,一般用于当地址解析程序取出资源记录后决定保存及使用缓存数据的时间。它同时也可以表明该资源记录的稳定程度,稳定的信息会被分配一个很大的值。
- 资源数据长度:资源数据的长度。
- 资源数据:表示按查询段要求返回的相关资源记录的数据。
资源记录部分只有在 DNS 响应包中才会出现。下面通过 DNS 响应包来进一步了解资源记录部分的字段信息。
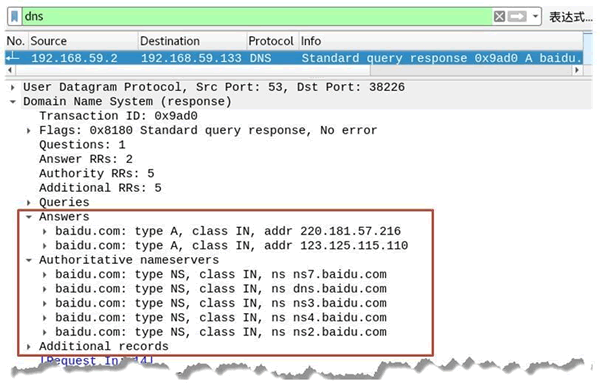
其中,方框中标注的信息为 DNS 响应报文的资源记录部分信息。
该部分信息主要分为三部分信息,即回答问题区域、权威名称服务器区域、附加信息区域,下面依次分析这三部分信息。
回答问题区域
Answers #“回答问题区域”字段
baidu.com: type A, class IN, addr 220.181.57.216 #资源记录部分
Name: baidu.com #域名字段, 这里请求的域名为baidu.com
Type: A (Host Address) (1) #类型字段, 这里为A类型
Class: IN (0x0001) #类字段
Time to live: 5 #生存时间
Data length: 4 #数据长度
Address: 220.181.57.216 #资源数据, 这里为IP地址
baidu.com: type A, class IN, addr 123.125.115.110 #资源记录部分
Name: baidu.com
Type: A (Host Address) (1)
Class: IN (0x0001)
Time to live: 5
Data length: 4
Address: 123.125.115.110
其中,Name 的值为 baidu.com,表示 DNS 请求的域名为 baidu.com;类型为 A,表示要获取该域名对应的 IP 地址。Address 的值显示了该域名对应的 IP 地址。
这里获取到了 2 个 IP 地址,分别为 220.181.57.216 和 123.125.115.110。
权威名称服务器区域
Authoritative nameservers #“权威名称服务器区域”字段
baidu.com: type NS, class IN, ns ns7.baidu.com #资源记录部分
Name: baidu.com
Type: NS (authoritative Name Server) (2) #类型字段, 这里为NS类型
Class: IN (0x0001)
Time to live: 5
Data length: 6
Name Server: ns7.baidu.com #权威名称服务器
baidu.com: type NS, class IN, ns dns.baidu.com #资源记录部分
Name: baidu.com
Type: NS (authoritative Name Server) (2) #类型字段, 这里为NS类型
Class: IN (0x0001)
Time to live: 5
Data length: 6
Name Server: dns.baidu.com #权威名称服务器
baidu.com: type NS, class IN, ns ns3.baidu.com #资源记录部分
Name: baidu.com
Type: NS (authoritative Name Server) (2)
Class: IN (0x0001)
Time to live: 5
Data length: 6
Name Server: ns3.baidu.com #权威名称服务器
baidu.com: type NS, class IN, ns ns4.baidu.com #资源记录部分
Name: baidu.com
Type: NS (authoritative Name Server) (2)
Class: IN (0x0001)
Time to live: 5
Data length: 6
Name Server: ns4.baidu.com #权威名称服务器
baidu.com: type NS, class IN, ns ns2.baidu.com #资源记录部分
Name: baidu.com
Type: NS (authoritative Name Server) (2)
Class: IN (0x0001)
Time to live: 5
Data length: 6
Name Server: ns2.baidu.com #权威名称服务器
其中,Name 的值为 baidu.com,表示 DNS 请求的域名为 baidu.com;类型为 NS,表示要获取该域名的权威名称服务器名称。Name Server 的值显示了该域名对应的权威名称服务器名称。
这里总共获取到 5 个,如 ns7.baidu.com。
附加信息区域
Additional records #“附加信息区域”字段
dns.baidu.com: type A, class IN, addr 202.108.22.220 #资源记录部分
Name: dns.baidu.com #“权威名称服务器”名称
Type: A (Host Address) (1) #类型字段, 这里为A类型
Class: IN (0x0001)
Time to live: 5
Data length: 4
Address: 202.108.22.220 #“权威名称服务器”的IP地址
ns2.baidu.com: type A, class IN, addr 61.135.165.235 #资源记录部分
Name: ns2.baidu.com #“权威名称服务器”名称
Type: A (Host Address) (1) #类型字段, 这里为A类型
Class: IN (0x0001)
Time to live: 5
Data length: 4
Address: 61.135.165.235 #“权威名称服务器”的IP地址
ns3.baidu.com: type A, class IN, addr 220.181.37.10 #资源记录部分
Name: ns3.baidu.com #“权威名称服务器”名称
Type: A (Host Address) (1) #类型字段, 这里为A类型
Class: IN (0x0001)
Time to live: 5
Data length: 4
Address: 220.181.37.10 #“权威名称服务器”的IP地址
ns4.baidu.com: type A, class IN, addr 220.181.38.10 #资源记录部分
Name: ns4.baidu.com #“权威名称服务器”名称
Type: A (Host Address) (1) #类型字段, 这里为A类型
Class: IN (0x0001)
Time to live: 5
Data length: 4
Address: 220.181.38.10 #“权威名称服务器”的IP地址
ns7.baidu.com: type A, class IN, addr 180.76.76.92 #资源记录部分
Name: ns7.baidu.com #“权威名称服务器”名称
Type: A (Host Address) (1) #类型字段, 这里为A类型
Class: IN (0x0001)
Time to live: 5
Data length: 4
Address: 180.76.76.92 #“权威名称服务器”的IP地址
其中,Name 的值为“权威名称服务器”名称,Type 的值为 A,表示获取域名对应的 IP 地址;Address 的值显示了所有获取到的权威名称服务器对应的 IP 地址。
面试题:根域名服务器为什么只有13个?
主要的原因:
与一个不分片的UDP报文的大小有关系。
最初的DNS域名查询默认使用UDP协议,而使用UDP传输的DNS查询响应(Query Response)报文,不希望任何形式的分片,包括DNS应用层的分片、以及IP层的分片。。换句话说,要求使用唯一的UDP报文传输DNS响应。
绝大多数的网络接口类型支持IP报文≥576 字节无需分片自由通行,考虑到以上诸因素,IETF决定将DNS报文体限制在512字节。每一个根域名服务器占用32字节,其中包括根域名的名称、IP地址、TTL(Time To Live)等参数。
所以:早期的DNS 查询结果是一个512字节的UDP 数据包。
一个512字节的UDP 数据包,一个根域名服务器占用32个字节(因为,IP地址由32位二进制数组成), 13根域名服务器一共占用416字节。
剩余的96字节用于包装DNS报文头以及其它协议参数。
所以,从空间上来说,一个512字节的dns数据包,最多可以容纳13个服务器的地址,没有多余的空间容纳第14个根域名服务器的32字节。
因此就规定全世界有13个根域名服务器,编号从a.root-servers.net一直到m.root-servers.net。
这13台根域名服务器由12个组织独立运营。其中,Verisign 公司管理两台根域名服务器:A 和 J。每家公司为了保证根域名服务器的可用性,会部署多个节点,比如单单Verisign 一家公司就部署了104台根域名服务器(2016年1月数据)。所以,根域名服务器其实不止13台。
这13个根域名服务器并不等于13台物理服务器
容易被大众误解的是,这13个根域名服务器并不等于13台物理服务器,而是代表着13个全球IP地址,由12个机构来管理,其中美国最大电信运营商Verizon管理两个根域名全球IP地址。
截至到今天为止,全球一共有996台服务器实例(Instances),遍布5大洲4大洋。

既然根域名服务器只有13个全球IP,而物理服务器却有996台,到底怎么分配的?
答案是: 使用BGP泛播技术(Anycast)
以Verizon管理的“198.41.0.4”为例,在全球一共分布在28个站点,每个站点的服务器,都使用同一个IP—— “198.41.0.4”, 反过来说, “198.41.0.4” 是一个全球IP, 在全球被 28 服务器使用。
问题是:IP地址在互联网上重复使用,会不会有什么问题?
咱们学习网络知识的时候,特别在局域网配置的时候,着重强调IP地址要唯一,不允许有重复使用IP地址的情况发生。但是,在互联网上不同站点可以使用相同的IP地址,只要使用方是IP地址的合法使用者。
“198.41.0.4”就会在28个站点,通过BGP路由协议,28次扩散到Internet路由表。
全球IP的路由策略
全球的主机究竟挑选哪个“198.41.0.4”来使用呢?当然是距离自己最近的,用BGP的专业术语表达就是最优路径。
泛播技术有哪些优点?
根域名服务器特别重要,曾经有黑客集中攻击它,差一点就成功了,因为13个服务器中某些依然没有被打趴下,源于服务器的全球式分布。
一朝被蛇咬,十年怕草绳。 互联网管理机构发现对付DDoS 攻击最有效的方法,就是分布式部署根域名服务器。于是,使用了泛播技术,全球有了996台实例。
如果有一天996台不够用,可以添加任意多台服务器,因为全球IP可以重复使用。
DNS劫持
先回顾一下DNS劫持的概念?
DNS劫持即通过某种技术手段,篡改正确域名和IP地址的映射关系,使得域名映射到了错误的IP地址,因此可以认为DNS劫持是一种DNS重定向攻击。DNS劫持通常可被用作域名欺诈,如在用户访问网页时显示额外的信息来赚取收入等;也可被用作网络钓鱼,如显示用户访问的虚假网站版本并非法窃取用户的个人信息。
那么 DNS劫持 是如何产生的呢?
下面大概说几种DNS劫持方法:
1.本机DNS劫持
攻击者通过某些手段使用户的计算机感染上木马病毒,或者恶意软件之后,恶意修改本地DNS配置,比如修改本地hosts文件,缓存等
2. 路由DNS劫持
很多用户默认路由器的默认密码,攻击者可以侵入到路由管理员账号中,修改路由器的默认配置
3.攻击DNS服务器
直接攻击DNS服务器,例如对DNS服务器进行DDOS攻击,可以是DNS服务器宕机,出现异常请求,还可以利用某些手段感染dns服务器的缓存,使给用户返回来的是恶意的ip地址
DNS劫持大事记
事件1:《AWS route53 BGP路由泄漏事件》
事件危害:据不完全统计,DNS劫持导致两个小时内有多个用户的以太坊钱包被转账清空,共计至少13000美元的资产被黑客盗取。
事件还原: 事件发生在2018年4月24日。黑客针对四段分配给AWS,本应作为AWS route53 DNS服务器服务地址的IP空间(205.251.192.0/23, 205.251.194.0/23, 205.251.196.0/23, 205.251.198.0/23)发布了虚假的BGP路由,导致在BGP泄漏的两个小时期间,本应该AWS route53 DNS服务器的DNS查询都被重定向到了黑客的恶意DNS服务器。且黑客DNS劫持的目标十分明确,恶意DNS服务器只响应对myetherwallet.com的查询,其他域名的查询均返回SERVFAIL。一旦用户没有注意“网站不安全”的提示而访问myetherwallet.com登录自己的以太坊钱包,黑客就可以轻易获取用户的私钥进而窃取用户的数字货币资产。正常情况的DNS,和劫持后的DNS的情况,请参考如下攻击示意图(来自cloudflare博客):
正常情况:
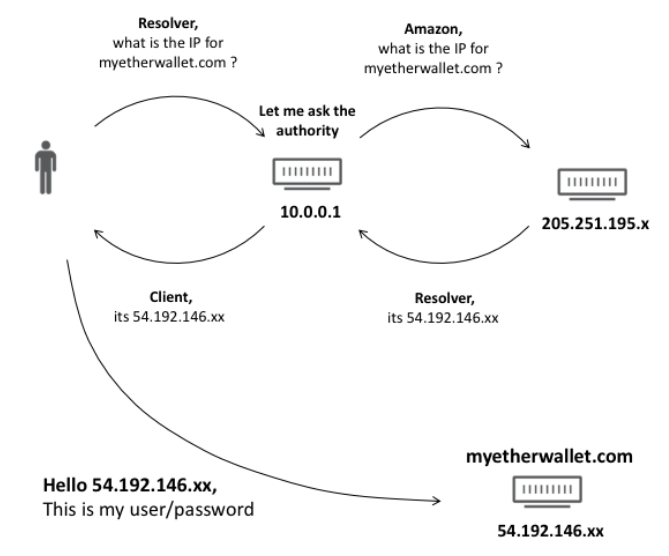
BGP泄漏后:

事件2:《巴西银行钓鱼事件》
事件危害:黑客诱导原本想访问正常银行网站的受害者访问到钓鱼网站,并恶意窃取受害者的银行账目密码信息。
事件还原:事件发生在2018年。黑客利用D-Link路由器的漏洞,入侵了至少500个家用路由器。黑客入侵后更改受害者路由器上的DNS配置,将受害者的DNS请求重定向到黑客自己搭建的恶意DNS服务器上。黑客入侵后更改受害者路由器上的DNS配置,将受害者的DNS请求重定向到黑客自己搭建的恶意DNS服务器上,最终诱导原本想访问正常银行网站的受害者访问到钓鱼网站,并恶意窃取受害者的银行账目密码信息。

上面两个案例都是触目惊心啊。接下来我们来介绍一下黑客们是怎么做到DNS劫持的?
DNS劫持分类
我们按照客户端侧–递归DNS服务器–权威DNS服务器的路径,将DNS劫持做如下分类:
本地DNS劫持
客户端侧发生的DNS劫持统称为本地DNS劫持。本地DNS劫持可能是:
- 黑客通过木马病毒或者恶意程序入侵PC,篡改DNS配置(hosts文件,DNS服务器地址,DNS缓存等)。
- 黑客利用路由器漏洞或者破击路由器管理账号入侵路由器并且篡改DNS配置。
- 一些企业代理设备(如Cisco Umbrella intelligent proxy)针对企业内部场景对一些特定的域名做DNS劫持解析为指定的结果。
DNS解析路径劫持
DNS解析过程中发生在客户端和DNS服务器网络通信时的DNS劫持统一归类为DNS解析路径劫持。通过对DNS解析报文在查询阶段的劫持路径进行划分,又可以将DNS解析路径劫持划分为如下三类:
DNS请求转发
通过技术手段(中间盒子,软件等)将DNS流量重定向到其他DNS服务器。
案例:
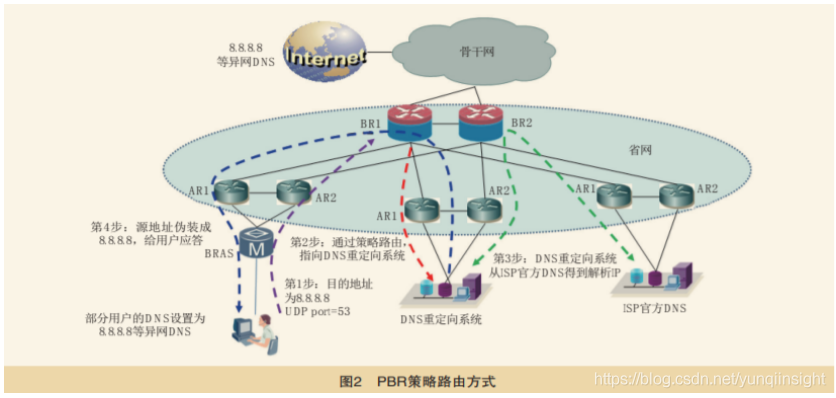
图片来自《巫俊峰, 沈瀚. 基于旁路抢答机制的异网DNS管控实践. 电信技术[J]》
DNS请求复制
利用分光等设备将DNS查询复制到网络设备,并先于正常应答返回DNS劫持的结果。
案例:一个DNS查询抓包返回两个不同的应答。

DNS请求代答
网络设备或者软件直接代替DNS服务器对DNS查询进行应答。
案例:一些DNS服务器实现了SERVFAIL重写和NXDOMAIN重写的功能。
篡改DNS权威记录
篡改DNS权威记录 我们这里指的黑客非法入侵DNS权威记录管理账号,直接修改DNS记录的行为。
案例:
黑客黑入域名的管理账户,篡改DNS权威记录指向自己的恶意服务器以实现DNS劫持。

黑客黑入域名的上级注册局管理账户,篡改域名的NS授权记录,将域名授权给黑客自己搭建的恶意DNS服务器以实现DNS劫持。
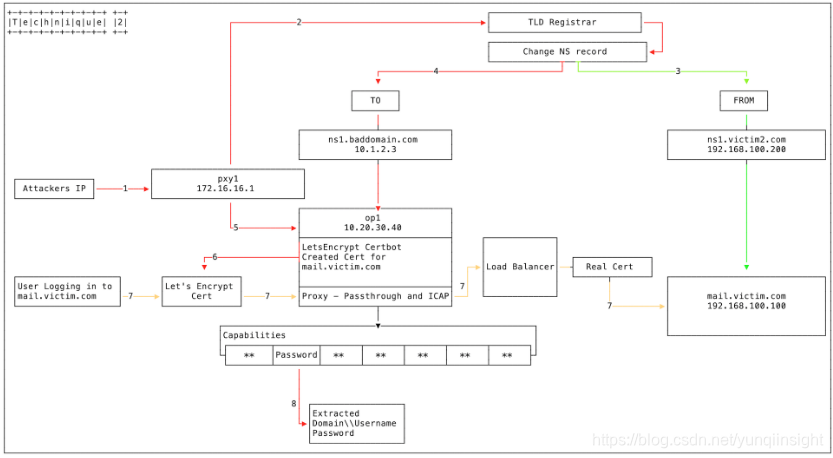
黑客黑入域名的上级注册局管理账户,篡改域名的NS授权记录,将域名授权给黑客自己搭建的恶意DNS服务器以实现DNS劫持。(以上参考fireeye博客)
DNS劫持应对策略
DNS劫持在互联网中似乎已经变成了家常便饭,那么该如何应对各种层出不穷的DNS劫持呢?如果怀疑自己遇到了DNS劫持,首先要做的事情就是要确认问题。
如何确认DNS劫持
查看路由器DNS配置是否被篡改。
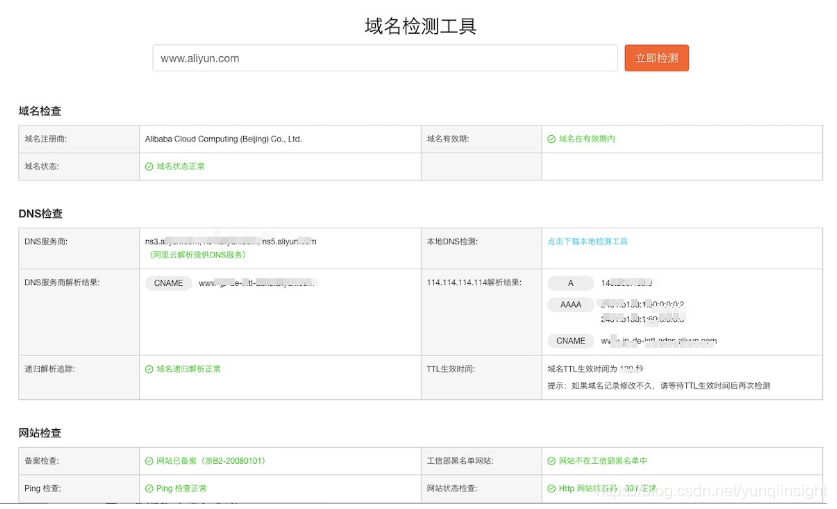
可以使用一些全网拨测的工具确认DNS劫持和其影响范围。在此隆重介绍一下,阿里的DNS域名检测工具于国庆后已经正式上线,地址是:https://zijian.aliyun.com/#/domainDetect
.
通过工具查看回复DNS应答的DNS服务器,确认DNS解析是否被重定向。
• whatismydnsresolver http://whatismydnsresolver.com/
移动端可以安装一些DNS相关的测试工具进行排查:
• 安卓 ping & dns
• IOS IOS iNetTools
DNS劫持防范
• 安装杀毒软件,防御木马病毒和恶意软件;定期修改路由器管理账号密码和更新固件。
• 选择安全技术实力过硬的域名注册商,并且给自己的域名权威数据上锁,防止域名权威数据被篡改。
• 选择支持DNSSEC的域名解析服务商,并且给自己的域名实施DNSSEC。DNSSEC能够保证递归DNS服务器和权威DNS服务器之间的通信不被篡改。阿里云DNS作为一家专业的DNS解析服务厂商,一直在不断完善打磨产品功能,DNSSEC功能已经在开发中,不日就会上线发布。
• 在客户端和递归DNS服务器通信的最后一英里使用DNS加密技术,如DNS-over-TLS,DNS-over-HTTPS等。
在此《DNS攻击防范科普系列》已经完结,欢迎大家给我们留意反馈自己对DNS攻击防范对看法。
DNS 劫持 与 HTTP 劫持
通过上面的讲解,我们都知道了,DNS 完成了一次域名到 IP 的映射查询,当你在访问 www.baidu.com 时,能正确返回给你 百度首页的 ip。
但如果此时 DNS 解析出现了一些问题,当你想要访问 www.baidu.com 时,却返回给你 www.google.com 的ip,这就是我们常说的 DNS 劫持。
与之容易混淆的有 HTTP 劫持。
那什么是 HTTP 劫持呢?
你一定见过当你在访问 某个网站时,右下角也突然弹出了一个扎眼的广告弹窗。这就是 HTTP 劫持。
借助别人文章里的例子,它们俩的区别就好比是
- DNS劫持是你想去机场的时候,把你给丢到火车站。
- HTTP劫持是你去机场途中,有人给你塞小广告。
HttpDNS
传统DNS存在哪些问题?
1)域名缓存问题:导游记忆记错了
2)域名转发问题:A运营商偷懒转给B运营商
3)出口NAT问题:NAT转换后DNS误判运营商
4)域名更新问题:DNS的域名TTL有效期跟不上场景切换
5)解析延迟问题:递归查询时间长
例子: 用户侧DNS被劫持,hosts被篡改
如下是我们的域名在用户机器上被篡改的实例,通过修改hosts文件,可以看到下面的域名被篡改成了127.0.0.1。

例子2. 缓存DNS服务器污染,返回客户端错误IP
2014年1月21日下午3点,国内顶级域的根服务器出现异常,许多知名网站的域名均被劫持到一个错误的IP地址上,至少有2/3的国内网站受到影响,用户无法正常访问。
根服务器恢复后,由于DNS缓存问题,部分地区用户“断网”现象仍持续了几个小时。
例子3. DNS缓存时间较长,短则10分钟,长则几小时
DNS的解析机制为了提升效率,在很多地方会有缓存,例如本机的缓存,DNS服务器上的缓存。缓存带来了效率上的提升,但同时却给故障处理带来了不小的麻烦,即:当我们将故障的机器下线或者将DNS指向的主机地址修改以后,用户并不能立刻感知新的主机地址,在缓存有效期内还是会继续访问旧的主机。
HTTPDNS工作模式
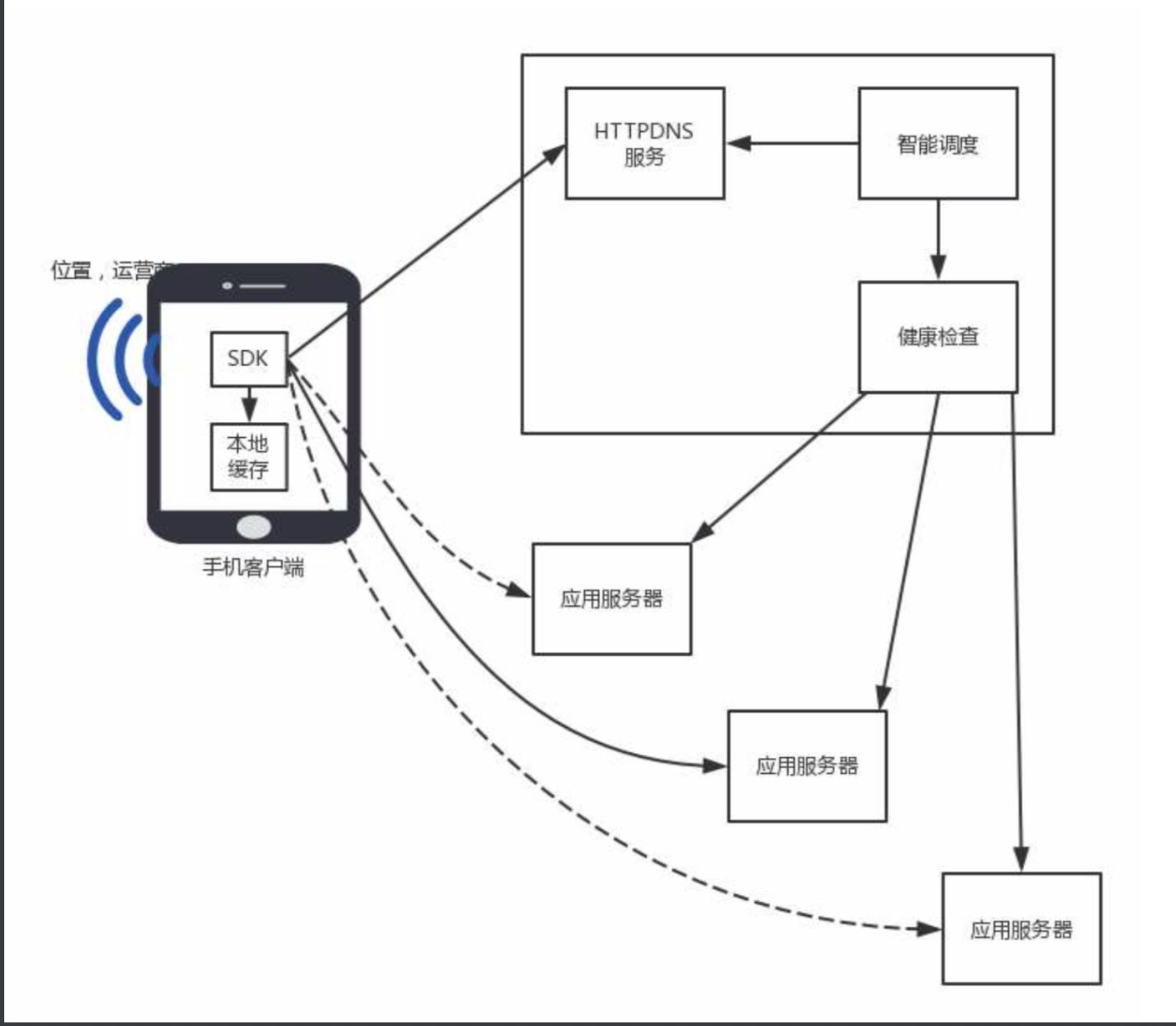
定义:不走传统的DNS解析,而是自己搭建基于HTTP协议的DNS服务器集群,分布在多个地点和多个运营商,当客户端需要DNS解析的时候,直接通过HTTP协议进行请求这个服务器集群,获得就近的地址。
- 在客户端的SDK里动态请求服务端,获取HTTPDNS服务器的ip列表,缓存到本地。SDK也会在本地缓存DNS域名解析的结果。这个缓存和本地DNS的缓存不一样,不是整个运营商统一做的,而是手机应用来做的,如何更新,何时更新。
- 如果本地无,就需要请求HTTPDNS的服务器,在本地的ip列表中,选择一个发出HTTP请求,返回一个要访问的网站的ip列表。手机客户端知道手机坐在的运营商,可以精确做到全局负载均衡。
- HTTPDNS的缓存设计解析的过程不需要本地DNS服务递归调用一大圈,一个HTTP请求直接搞定,本地也有缓存,过期时间,更新时间都可以自己控制。缓存设计模式三层:客户端,缓存,数据源- 对于应用架构,就是应用,缓存,数据库。tomcat,redis,mysql- 对于HTTPDNS来说,就是手机客户端,dns缓存,httpdns服务器例如dns缓存在内存中,也可以持久化到存储上,app重启后,就可以尽快的从存储中加载上次积累的解析结果。sdk中的缓存会严格按照缓存过期时间,如果没有命中,或已经过期,则不允许使用过期记录,会发起一次解析,保障记录是新的。解析可以是同步或异步的。同步更新的优点是实时性好,缺点是如果有多个请求都发现过期的时候,会同时请求HTTPDNS,浪费资源。对应到应用架构中缓存的Cache-Aside机制,先读缓存,不命中读数据库,同时写入到缓存。异步的优点是多个请求都过期的情况可以合并为一个,同时可以在即将过期的时候,创建一个任务进行预加载,防止过期之后再刷新成为预加载。缺点是当请求拿到过期数据,如果可以请求就没问题,如果不能请求,则失败,等下次缓存更新后,再请求方能成功。对应于应用架构中缓存的Refresh-Ahead机制,即业务仅仅访问缓存,当过期就定期刷新。
- HTTPDNS调度设计客户端嵌入了SDK,在客户端HTTPDNS服务端可以根据手机的国家,省市地点,运营商,选择最佳的服务节点。
小结:
- 传统的DNS有解析慢,更新不及时,转发跨运营商,nat跨运营商等问题,影响了流量的调度。
- HTTPDNS通过客户端sdk和服务端,直接解析dns,绕过了传统dns缺点,实现智能调度。
功能说明
HTTPDNS使用HTTP协议进行域名解析,代替现有基于UDP的DNS协议,域名解析请求直接发送到阿里云的HTTPDNS服务器,从而绕过运营商的Local DNS,能够避免Local DNS造成的域名劫持问题和调度不精准问题。
功能说明防劫持绕过运营商Local DNS,避免域名劫持,让每一次访问都畅通无阻。精准调度基于访问的来源IP,获得最精准的解析结果,让客户端就近接入业务节点。0ms解析延迟通过热点域名预解析、缓存DNS解析结果、解析结果懒更新策略等方式实现0解析延迟快速生效避免Local DNS不遵循权威TTL,解析结果长时间无法更新的问题降低解析失败率有效降低无线场景下解析失败的比率
防劫持
HTTPDNS代替了传统的LocalDNS完成递归解析的功能,基于HTTP协议的设计可以适用于几乎所有的网络环境,同时保留了鉴权、HTTPS等更高安全性的扩展能力,避免恶意攻击劫持行为。
精准调度
传统域名解析的调度精准性问题,本质根源在于Local DNS的部署和分配机制上。由于碎片化的管理方式,这些环节的服务质量同样很难得到保障。HTTPDNS在递归解析实现上优化了与权威DNS的交互,通过edns-client-subnet协议将终端用户的IP信息直接交付给权威DNS,这样权威DNS就可以忽略Local DNS IP信息,根据终端用户的IP信息进行精准调度,避免Local DNS的坐标干扰
DNS解析0延迟:
- 构建客户端DNS缓存;
通过合理的DNS缓存,我们确保每次网络交互的DNS解析都是从内存中获取IP信息,从而大幅降低DNS解析开销。根据业务的不同,我们可以 制订更丰富的缓存策略,如根据运营商缓存,可以在网络切换的场景下复用已缓存的不同运营商线路的域名IP信息,避免网络切换后进行链 路重选择引入的DNS网络解析开销。另外,我们还可以引入IP本地化离线存储,在客户端重启时快速从本地读取域名IP信息,大幅提升首页 载入效率。 - 热点域名预解析;
在客户端启动过程中,我们可以通过热点域名的预解析完成热点域名的缓存载入。当真正的业务请求发生时,直接由内存中读取目标域名的IP 信息,避免传统DNS的网络开销。 - 懒更新策略;
绝大多数场景下业务域名的IP信息变更并不频繁,特别是在单次APP的使用周期内,域名解析获取的IP往往是相同的(特殊业务场景除外)。 因此我们可以利用DNS懒更新策略来实现TTL过期后的DNS快速解析。所谓DNS懒更新策略即客户端不主动探测域名对应IP的TTL时间,当业务 请求需要访问某个业务域名时,查询内存缓存并返回该业务域名对应的IP解析结果。如果IP解析结果的TTL已过期,则在后台进行异步DNS网 络解析与缓存结果更新。通过上述策略,用户的所有DNS解析都在与内存交互,避免了网络交互引入的延迟。
实现方案
服务端:
服务端提供API接口,app端直接通过ip地址访问,ip地址可以有多个
请求方式:HTTP GET
URL参数说明:
名称是否必须描述host必须要解析的域名ip可选用户的来源IP,如果没指定这个参数,默认使用请求连接的源IP
请求示例:
- 示例1(默认来源IP):http://x.x.x.x/d?host=www.suning.com
- 示例2(指定来源IP):http://x.x.x.x/d?host=www.suning.com&ip=185.53.179.6
考虑到服务IP防攻击之类的安全风险,为保障服务可用性,HTTPDNS同时提供多个服务IP,当某个服务IP在异常情况下不可用时,可以使用其它服务IP进行重试。
请求成功时,HTTP响应的状态码为200,响应结果用JSON格式表示,示例如下:
{
"host": "www.suning.com",
"ips": [
"112.84.104.48"
],
"ttl": 57,
"origin_ttl": 120
}
请求失败的响应示例:
{
"code": "MissingArgument"
}
错误码列表如下:
错误码HTTP状态码描述MissingArgument400缺少必要参数InvalidHost400域名格式不合法MethodNotAllowed405不支持的HTTP方法InternalError500服务端内部错误
错误处理
异常下的出错兼容逻辑,主要包括异步请求,重试,降级
异步请求
访问HTTPDNS服务时,应该使用异步请求的策略,避免解析延迟太大而对业务造成影响,特别是在网络环境异常或HTTPDNS服务IP异常不可
用时,如果用同步访问,需要等待网络超时后才会返回解析失败,这个超时时间较大,可能对业务的使用体验造成很大影响。
异步请求策略:解析域名时,如果当前缓存中有TTL未过期的IP,可直接使用;如果没有,则立刻让此次请求降级走原生LocalDNS解析,同
时另起线程异步地发起HTTPDNS请求进行解析,更新缓存,这样后续解析域名时就能命中缓存。
重试
访问HTTPDNS服务解析域名时,如果请求HTTPDNS服务端失败,即HTTP请求没有返回,可以进行重试。
大部分情况下,这种访问失败是由于网络原因引起的,重试可以解决。
降级
不管是因为什么原因,当通过HTTPDNS服务无法获得域名对应的IP时,都必须降级:使用标准的DNS解析,通过Local DNS去解析域名。
Android端:
OkHttp默认使用系统DNS服务InetAddress进行域名解析,但同时也暴露了自定义DNS服务的接口,通过该接口我们可以优雅地使用HttpDns。
- 自定义DNS接口
OkHttp暴露了一个Dns接口,通过实现该接口,我们可以自定义Dns服务:
public class OkHttpDns implements Dns {
private static final Dns SYSTEM = Dns.SYSTEM;
HttpDnsService httpdns;//httpdns 解析服务
private static OkHttpDns instance = null;
private OkHttpDns(Context context) {
this.httpdns = HttpDns.getService(context, "account id");
}
public static OkHttpDns getInstance(Context context) {
if(instance == null) {
instance = new OkHttpDns(context);
}
return instance;
}
@Override
public List<InetAddress> lookup(String hostname) throws UnknownHostException {
//通过异步解析接口获取ip
String ip = httpdns.getIpByHostAsync(hostname);
if(ip != null) {
//如果ip不为null,直接使用该ip进行网络请求
List<InetAddress> inetAddresses = Arrays.asList(InetAddress.getAllByName(ip));
Log.e("OkHttpDns", "inetAddresses:" + inetAddresses);
return inetAddresses;
}
//如果返回null,走系统DNS服务解析域名
return Dns.SYSTEM.lookup(hostname);
}
}
- 创建OkHttpClient
创建OkHttpClient对象,传入OkHttpDns对象代替默认Dns服务:
private void okhttpDnsRequest() {
OkHttpClient client = new OkHttpClient.Builder()
.dns(OkHttpDns.getInstance(getApplicationContext()))
.build();
Request request = new Request.Builder()
.url("http://www.aliyun.com")
.build();
Response response = null;
client.newCall(request).enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
e.printStackTrace();
}
@Override
public void onResponse(Call call, Response response) throws IOException {
if (!response.isSuccessful()) throw new IOException("Unexpected code " + response);
DataInputStream dis = new DataInputStream(response.body().byteStream());
int len;
byte[] buff = new byte[4096];
StringBuilder result = new StringBuilder();
while ((len = dis.read(buff)) != -1) {
result.append(new String(buff, 0, len));
}
Log.d("OkHttpDns", "Response: " + result.toString());
}
});
}
- 总结
相比于通用方案,OkHttp+HttpDns有以下两个主要优势:
实现简单,只需通过实现Dns接口即可接入HttpDns服务
通用性强,该方案在HTTPS,SNI以及设置Cookie等场景均适用。规避了证书校验,域名检查等环节
IOS端:
基于NSURLProtocol可拦截iOS系统上基于上层网络库NSURLConnection/NSURLSession发出的网络请求;
通过以下接口注册自定义NSURLProtocol,用于拦截上层网络请求,并创建新的网络请求接管数据发送、接收、重定向等处理逻辑,将结果反馈给原始请求。
[NSURLProtocol registerClass:[CustomProtocol class]];
自定义NSURLProtocol处理过程概述:
- 在canInitWithRequest中过滤要需要做HTTPDNS域名解析的请求;
- 请求拦截后,做HTTPDNS域名解析;
- 解析完成后,同普通请求一样,替换URL.host字段,替换HTTP Header Host域,并接管该请求的数据发送、接收、重定向等处理;
接入流程
服务开通
HTTPDNS是移动研发平台提供的服务,请参考EMAS 快速入门开通服务。
- 开通服务后,进入控制台,点击添加产品,如图所示

- 完成添加产品后,点击添加应用,如图所示

- 添加应用完成后,点击刚才添加的应用

- 查看Account ID,这个id后面配置dns会用到
- 在域名列表中添加域名
Android SDK 接入
- 在项目根目录下的build.gradle文件中添加Maven仓库地址
allprojects {
repositories {
maven {
url 'http://maven.aliyun.com/nexus/content/repositories/releases/'
}
}
}
- 在需要引入HTTPDNS服务的模块下的build.gradle中添加依赖
dependencies {
compile ('com.aliyun.ams:alicloud-android-httpdns:1.3.3@aar') {
transitive true
}
}
按照以上官方文档配置,在同步工程后,会报错
Could not find com.aliyun.ams:alicloud-android-utdid:1.1.5.4.
Searched in the following locations:
- http://maven.aliyun.com/nexus/content/repositories/releases/com/aliyun/ams/alicloud-android-utdid/1.1.5.4/alicloud-android-utdid-1.1.5.4.pom
- https://dl.google.com/dl/android/maven2/com/aliyun/ams/alicloud-android-utdid/1.1.5.4/alicloud-android-utdid-1.1.5.4.pom
- https://jcenter.bintray.com/com/aliyun/ams/alicloud-android-utdid/1.1.5.4/alicloud-android-utdid-1.1.5.4.pom
Required by:
project :app > com.aliyun.ams:alicloud-android-httpdns:1.3.3 > com.aliyun.ams:alicloud-android-beacon:1.0.4.3
修改如下
implementation('com.aliyun.ams:alicloud-android-httpdns:1.3.3@aar') {
transitive true
exclude group: 'com.aliyun.ams', module: 'alicloud-android-utdid'
}
implementation 'com.aliyun.ams:alicloud-android-utdid:1.1.5.3'
- 引入Retrofit及gson增加依赖
implementation 'com.squareup.retrofit2:retrofit:2.3.0'implementation 'com.squareup.retrofit2:converter-gson:2.3.0'implementation 'com.google.code.gson:gson:2.8.6' - 配置DNS新建一个类,继承Dns
publicclassAliDnsimplementsDns{privateHttpDnsService httpDns;publicAliDns(Context context){//传入account_id,account_id为HTTPDNS控制台添加应用时生成的 httpDns =HttpDns.getService(context,"account_id");}@OverridepublicList<InetAddress>lookup(String hostname)throwsUnknownHostException{//通过异步解析接口获取ipString ip = httpDns.getIpByHostAsync(hostname);//Android9.0系统及以后版本,https请求无法直接访问,方便起见,直接在AndroidManifest.xml中配置android:usesCleartextTraffic="true"if(ip !=null){//如果ip不为null,直接使用该ip进行网络请求Log.e("AliDns","ip:"+ ip);List<InetAddress> inetAddresses =Arrays.asList(InetAddress.getAllByName(ip));return inetAddresses;}//如果返回null,走系统DNS服务解析域名returnDns.SYSTEM.lookup(hostname);}}设置OkHttpClient的dnsOkHttpClient client =newOkHttpClient.Builder().dns(newAliDns(getApplicationContext())).build(); - 调用请求
Retrofit retrofit =newRetrofit.Builder().client(client).baseUrl("域名").addConverterFactory(GsonConverterFactory.create()).build();Api api = retrofit.create(Api.class);Call<Bean> call = api.getBanner();call.enqueue(newCallback<Bean>(){@OverridepublicvoidonResponse(Call<Bean> call,Response<Bean> response){if(!response.isSuccessful()){ tv.setText("请求失败,错误码:"+ response.code());return;}Bean bean = response.body(); tv.setText(bean.toString());}@OverridepublicvoidonFailure(Call<Bean> call,Throwable t){ tv.setText(t.getMessage());}});
源码
https://github.com/milovetingting/Samples
SLB(DNS域名解析负载均衡)
Server Load Balancing,中文:服务端负载均衡
回顾:DNS的解析过程
- 根DNS服务器:返回顶级域DNS服务器的IP地址
- 顶级域DNS服务器:返回权威DNS服务器的IP地址
- 权威DNS服务器:返回相应主机的IP地址流程图:
SLB负载均衡的要点
- 内部负载均衡:可以配置域名,每次返回不同的ip
- 全局负载均衡:高可用,如果某个服务器挂了,在DNS里直接删除对应ip,不影响客户端的访问。
案例:DNS的SLB示例
DNS(Domain Name System)是因特网的一项服务,它作为域名和IP地址相互映射的一个分布式数据库,能够使人更方便的访问互联网。人们在通过浏览器访问网站时只需要记住网站的域名即可,而不需要记住那些不太容易理解的IP地址。
在DNS系统中有一个比较重要的的资源类型叫做主机记录也称为A记录,A记录是用于名称解析的重要记录,它将特定的主机名映射到对应主机的IP地址上。如果你有一个自己的域名,那么要想别人能访问到你的网站,你需要到特定的DNS解析服务商的服务器上填写A记录,过一段时间后,别人就能通过你的域名访问你的网站了。
DNS除了能解析域名之外还具有负载均衡的功能,下面是利用DNS工作原理处理负载均衡的工作原理图:

由上图可以看出,在DNS服务器中应该配置了多个A记录,如:
www.apusapp.com IN A 114.100.20.201;
www.apusapp.com IN A 114.100.20.202;
www.apusapp.com IN A 114.100.20.203;
因此,每次域名解析请求都会根据对应的负载均衡算法计算出一个不同的IP地址并返回,这样A记录中配置多个服务器就可以构成一个集群,并可以实现负载均衡。上图中,用户请求www.apusapp.com,DNS根据A记录和负载均衡算法计算得到一个IP地址114.100.20.203,并返回给浏览器,浏览器根据该IP地址,访问真实的物理服务器114.100.20.203。所有这些操作对用户来说都是透明的,用户可能只知道www.apusapp.com这个域名。
DNS域名解析负载均衡的优点和缺点:
DNS域名解析负载均衡有如下优点:
- 将负载均衡的工作交给DNS,省去了网站管理维护负载均衡服务器的麻烦。
- 技术实现比较灵活、方便,简单易行,成本低,使用于大多数TCP/IP应用。
- 对于部署在服务器上的应用来说不需要进行任何的代码修改即可实现不同机器上的应用访问。服务器可以位于互联网的任意位置。
- 同时许多DNS还支持基于地理位置的域名解析,即会将域名解析成距离用户地理最近的一个服务器地址,这样就可以加速用户访问,改善性能。
同时,DNS域名解析也存在如下缺点:
- 目前的DNS是多级解析的,每一级DNS都可能缓存A记录,当某台服务器下线之后,即使修改了A记录,要使其生效也需要较长的时间,这段时间,DNS任然会将域名解析到已下线的服务器上,最终导致用户访问失败。
- 不能够按服务器的处理能力来分配负载。DNS负载均衡采用的是简单的轮询算法,不能区分服务器之间的差异,不能反映服务器当前运行状态,所以其的负载均衡效果并不是太好。
- 可能会造成额外的网络问题。为了使本DNS服务器和其他DNS服务器及时交互,保证DNS数据及时更新,使地址能随机分配,一般都要将DNS的刷新时间设置的较小,但太小将会使DNS流量大增造成额外的网络问题。
事实上,大型网站总是部分使用DNS域名解析,利用域名解析作为第一级负载均衡手段,即域名解析得到的一组服务器并不是实际提供服务的物理服务器,而是同样提供负载均衡服务器的内部服务器,这组内部负载均衡服务器再进行负载均衡,请请求发到真实的服务器上,最终完成请求。
另外,DNS - SLB还存在的以下问题
- 域名缓存问题本地做一个缓存,直接返回缓存数据。可能会导致全局负载均衡失败,因为上次进行的缓存,不一定是这次离客户最近的地方,可能会绕远路。
- 域名转发问题如果是A运营商将解析的请求转发给B运营商,B去权威DNS服务器查询的话,权威服务器会认为你是B运营商的,就返回了B运营商的网站地址,结果每次都会夸运营商。
- 出口NAT问题做了网络地址转化后,权威的DNS服务器,没法通过地址来判断客户到底是哪个运营商,极有可能误判运营商,导致跨运营商访问。
- 域名更新问题本地DNS服务器是由不同地区,不同运营商独立部署的,对域名解析缓存的处理上,有区别,有的会偷懒忽略解析结果TTL的时间限制,导致服务器没有更新新的ip而是指向旧的ip。
- 解析延迟DNS的查询过程需要递归遍历多个DNS服务器,才能获得最终结果。可能会带来一定的延时。
GSLB
What is GSLB
GSLB, Global Server Load Balancing,中文:全局负载均衡
由于现实中存在各种不稳定因素,比如某个服务器集群所在的数据中心断电,洪水或者地震造成数据中心瘫痪等等。在一个数据中心内,无论采用怎样的技术,总可能存在一些不可抗因素,导致其瘫痪。所以通常会把服务器分散部署到多个数据中心,以最大程度减小灾害对服务质量产生影响的概率和程度。
采用全局负载均衡(GSLB)的前提是在不同地区设立了多个数据中心,并不是所有的互联网服务都能做GSLB,前提是业务已经做了分布式部署的规划,无论用户从哪个IDC访问都能得到相同的结果; 或者, 用户基本不会出现跨区域流动访问的情况,只会访问就近IDC,或者有一套入口调度机制,能将用户调度到所属的节点。
SLB 与GSLB 的区别
SLB(Server load balancing)是对集群内物理主机的负载均衡,而GSLB是对物理集群的负载均衡。
这里的负载均衡可能不只是简单的流量均匀分配,而是会根据策略的不同实现不同场景的应用交付。
GSLB是依赖于用户和实际部署环境的互联网资源分发技术,不同的目的对应着一系列不同的技术实现。
GSLB的优势
总结为:
- 高可用性
- 更快的响应时间
- 多版本分发
具体来说:
- Disater recovery, 发生故障时提供一个备用的位置来获取资源或者能提供可简易调整流量的装置,或两者都能提供。
- Load sharing,基于多个地理位置的流量分发,可以做到:a.尽量节省带宽 b.限制给定位置的能力 c.限制暴露断电,地理灾害等问题
- Performance,将资源置于离用户更近的地方,增强用户体验。
- 多版本,根据本地政策提供不同版本的资源,或者根据自定义的规则提供为特殊用户提供特殊版本,如灰度交付等。
GSLB实现方式
常见的GSLB实现方式有三种:
- DNS轮询
- HTTP重定向
- IP欺骗(又称三角传输)。
这三种实现方式都是在用户通过域名来访问目标服务器时,由GSLB设备进行智能决策,将用户引导到一个最佳的服务IP。
基于DNS轮询的GSLB
用户访问某个网站时,需要首先通过域名解析服务(DNS)获得网站的IP。域名解析通常不是一次性完成的,常常需要查询若干不同的域名服务器才能找到对应的IP。
普通DNS解析流程与全局负载均衡流程GSLB解析流程的对比,大致如下:
(a) 普通访问流程
用户首先在本地配置一个本地DNS服务器地址,本地DNS服务器收到DNS请求后若不能解析,会进行递归查询,将请求转发给更高一级的DNS服务器直到找到域名对应的IP或确定域名不存在。

(b) 加入GSLB的情况

基于DNS的GSLB域名解析过程
基于DNS的GSLB域名解析过程, 大致如下:
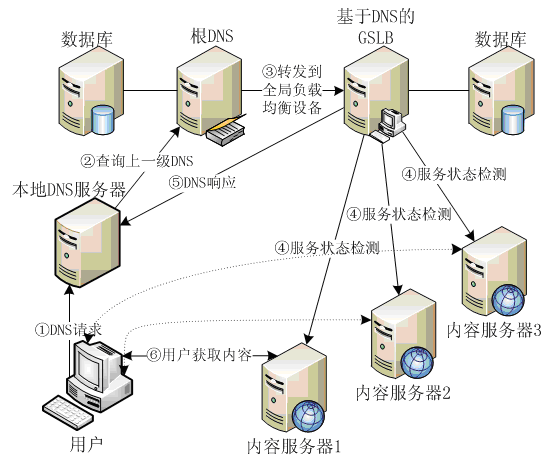
对于加入了GSLB的情况,一个GSLB设备(可能是一个4层交换机)会最终代替DNS服务器完成域名解析。
全局负载均衡GSLB案例1
目前很多DNS服务商都提供了智能DNS服务,智能DNS可以通过多种负载均衡策略来将客户端需要访问的域名解析到不同的数据中心不同的线路上,比如通过各运营商分省IP地理信息数据来判断用户的就近性,并结合健康检查策略(通常是发一个固定的http请求)来分配访问量。
下例的是一个全局负载均衡解决方案。
本示例基于DNS轮询的GSLB方案:
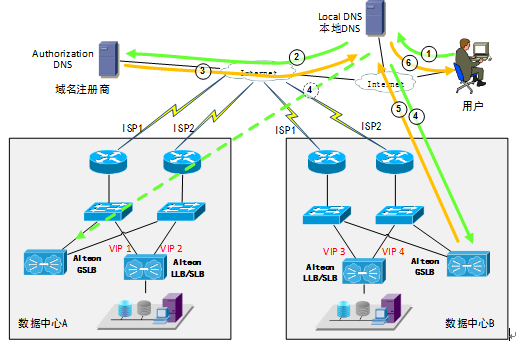
- 域名服务商处将域名的NS记录,指向有智能DNS解析功能的GSLB设备,然后由GSLB设备来进行A记录解析。
- 如果在多地部署了GSLB设备,它们都应该添加到NS记录中以保证高可用性,域名服务商处轮询地返回GSLB地址或者一次性返回全部地址。
- GSLB设备会对自己所在的IDC后端服务器以及其他IDC公网IP进行健康检查,健康检查结果会通过自有协议在不同IDC的GSLB设备之间同步,最终根据全局负载均衡策略来选择最优的地址解析给用户。
全局负载均衡解决方案中, DNS解析的步骤如下:
- 用户向本级配置的本地DNS服务器发出查询请求,如果本地DNS服务器有该域名的缓存记录,则返回给用户,否则进行第2步;
- 本地DNS服务器进行递归查询,最终会查询到域名注册商处的授权DNS服务器,这里可能有多个步骤,图中只反映最后一步;
- 授权DNS服务器返回一条NS记录给本地DNS服务器。根据授权DNS服务器上的不同设置,这条NS记录可能是指向随机一个GSLB设备的接口地址或者是所有GSLB设备的接口地址;
- 本地DNS服务器向其中一个GSLB地址发出域名查询请求,如果请求超时会向其它地址发出查询;
- GSLB设备选出最优解析结果,返回一条A记录给本地DNS服务器。根据全局负载均衡策略设定的不同可能返回一个或多个VIP地址;
- 本地服务器将查询结果通过一条A记录返回给用户,并将缓存这条记录。
通过DNS解析报文中的TTL(Time To Live)字段可以控制客户端缓存这条记录的时间,在缓存时间内客户端会使用旧的查询结果,当缓存时间超时后才可能重新发出查询,TTL值过大会导致故障发生时切换时间过长,TTL值太小会造成查询频繁,对设备和网络的压力增大。
全局负载均衡GSLB案例2
示例:DNS访问数据中心中对象存储上的静态资源。
假设全国有多个数据中心,托管在多个运营商,每个数据中心三个可用区。对象存储通过跨可用区部署,实现高可用性。在每个数据中心中,都至少部署两个内部负载均衡器,内部负载均衡器后面对接多个对象存储的前置服务器。
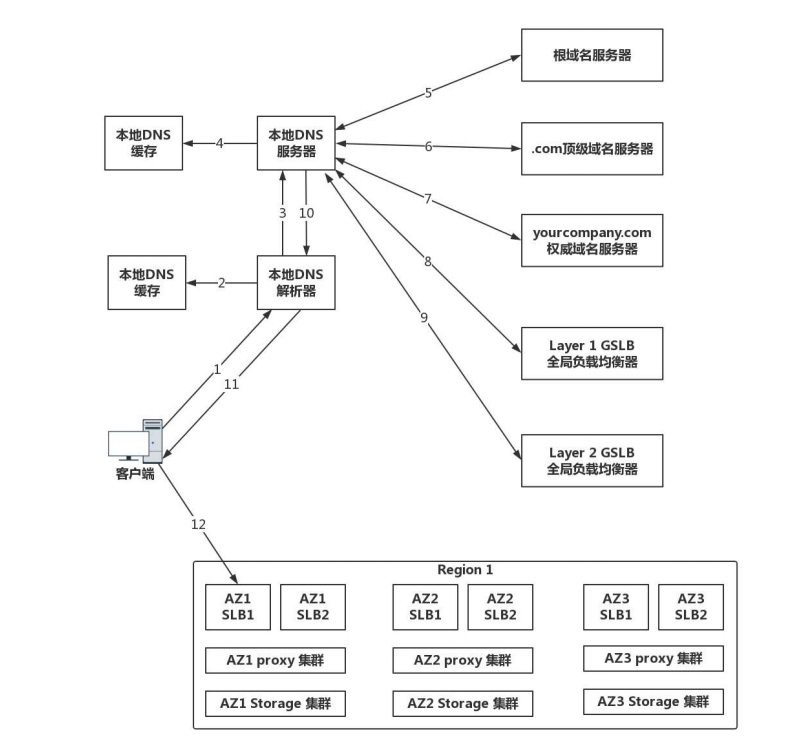
- 当一个客户端要访问object.yourcompany.com时,需要将域名转为ip,所以请求本地DNS解析器。
- 本地DNS解析器查看是否有本地缓存这个记录,如果有则直接使用
- 如果没有,请求本地的DNS服务器。
- 本地的DNS服务器一般部署在你的数据中心或所在运营商的网络中,本地DNS服务器需要查看本地是否有缓存,如果有则返回。
- 若无,本地DNS需要递归的从根DNS服务器,查到顶级域名服务器,最终查到权威DNS服务器,返回给本地DNS服务器。
对于不需要做全局负载均衡的简单应用来讲,权威DNS服务器可以直接将object.yourcompany.com域名解析为一个或多个ip地址,服务端可以通过多个ip地址,进行简单的轮询,实现简单的负载均衡。
- 全局负载均衡器(GSLB, Global Server Load Balance),在DNS服务器中,一般通过配置cname的方式,给object.yourcompany.com起一个别名,然后告诉本地DNS服务器,让他请求GSLB解析这个域名,在解析这个过程中,通过自己的策略实现负载均衡。
- GSLB可以分运营商和地域,第一层GSLB,通过查看请求他的本地DNS服务器所在的运营商,就知道用户的运营商,通过起别名,告诉本地DNS服务器去请求第二层的GSLB。第二层GSLB查看请求他的本地DNS服务器的地址,知道了用户的地理位置,将距离用户位置比较近的region里,六个内部负载均衡的地址,返回给DNS服务器。本地DNS服务器将结果返回给本地DNS解析器,然后解析器返回给客户端客户端得到了6个ip地址,可以通过负载均衡的方式,随机或者轮询选择一个可用区进行访问。
基于DNS轮询的GSLB的优点和缺点
这种方案的优点是:实现简单、实施容易、成本低。
其缺点是:当GSLB设备采用“用户就近访问”的原则作为选择最优服务器的策略时,会存在判断不准的现象。原因是在这种策略下,GSLB设备是根据用户IP地址和内容服务器IP地址比较来判断其就近性的,请注意GSLB设备收到的DNS请求的源地址,不是用户的地址, 而是用户所配置的本地DNS服务器地址,而GSLB的就近性探测是根据这个地址来判断的,若用户指定的DNS服务器IP不能正确代表用户的实际位置,就会出现判断不准的现象。

在我国大多数ADSL拨号上网用户, 都能就近分配正确的数据中心

但是当用户用户通过4G移动网络上网的情况下,客户会一直使用归属地的DNS服务器,

或者,存在手动设定本地DNS而设置的DNS距离用户较远的情况,GSLB不能分配最佳的地址。

这种手动设定本地DNS的情况,在国内很常见,国内有很多人使用google的公有dns或者opendns。
基于HTTP重定向的GSLB
为了解决基于DNS实现方式判断不准的问题,又出现了基于HTTP重定向的GSLB。这种方案中GSLB使用HTTP重定向技术,将用户访问重定向到最合适的服务器上。
DNS的这几个问题虽然我们都很清楚,但是也无能为力,因为我们不能控制DNS的设备,也不能修改DNS的实现机制。要想解决这个问题,只能另想办法,我们的解决方案就是HTTP-DNS。
WEB端基于HTTP重定向的GSLB工作流程
基于HTTP重定向的GSLB工作流程,大致如下图:
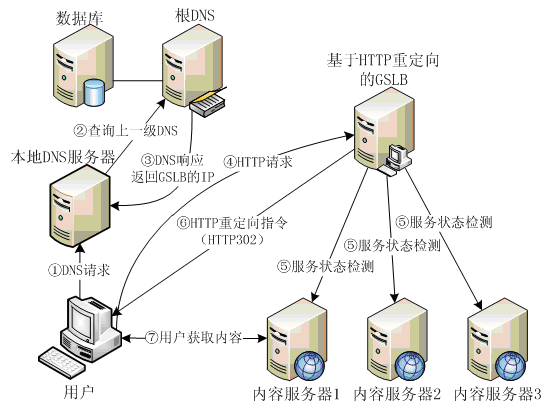
使用基于HTTP重定向方案,首先在DNS中将GSLB设备的IP地址登记为域名的A记录(既域名对应的IP)。如上图所示,用户首先通过DNS得到GSLB设备的IP地址,此时用户以为这就是站点服务器的IP,并向其发送HTTP请求。
GSLB设备收到HTTP请求后使用一定策略选择一个最合适的服务器,然后GSLB设备向用户发送一个HTTP重定向指令(HTTP302),并附上选出的服务器的IP地址。最后,用户根据重定向IP访问站点的服务器。
这一方案的优点是:由于直接向用户发送HTTP重定向指令,可以得到用户的真实IP,从而解决了判断不准确的问题。
其缺点是只能为HTTP访问重定向。
移动端基于HTTP重定向的GSLB工作流程
故名思议,HTTP-DNS就是通过HTTP的方式来自己实现一套DNS的功能,简单来说就是客户端通过HTTP接口来获取指定域名对应的主机地址,而不再通过传统的DNS设备来获取主机地址。其基本架构示意图如下:

相比传统DNS,HTTP-DNS具备如下优势:
1. 自己实现,控制力度强,可以根据业务特点灵活实现
可以根据业务进行细粒度的调度,例如发现A业务某个集群请求量较多,可以动态的将请求分配到其它集群。
2. 更新快,故障处理及时
当更新域名对应的主机信息后,客户端能够立刻拿到最新的信息。例如下线一台机器后,客户端再来获取主机地址就不会获取已经下线的机器地址,能够实现秒级的故障处理速度。
当然,HTTP-DNS的这些优势是在特定场景下才能体现的,并不能完全取代传统的DNS。因为如果每次访问都先通过HTTP-DNS拿取主机地址的话,效率和性能都太低,对于手机类智能设备还会导致耗电和流量增加。因此我们需要结合传统DNS和HTTP-DNS的优势,既要保证大部分情况下的性能和效率,也要保证异常情况下的故障快速处理。
具体的做法为:正常情况下我们通过传统DNS完成业务请求,异常重试的时候通过HTTP-DNS完成请求。如图3所示简要的说明了整体流程。
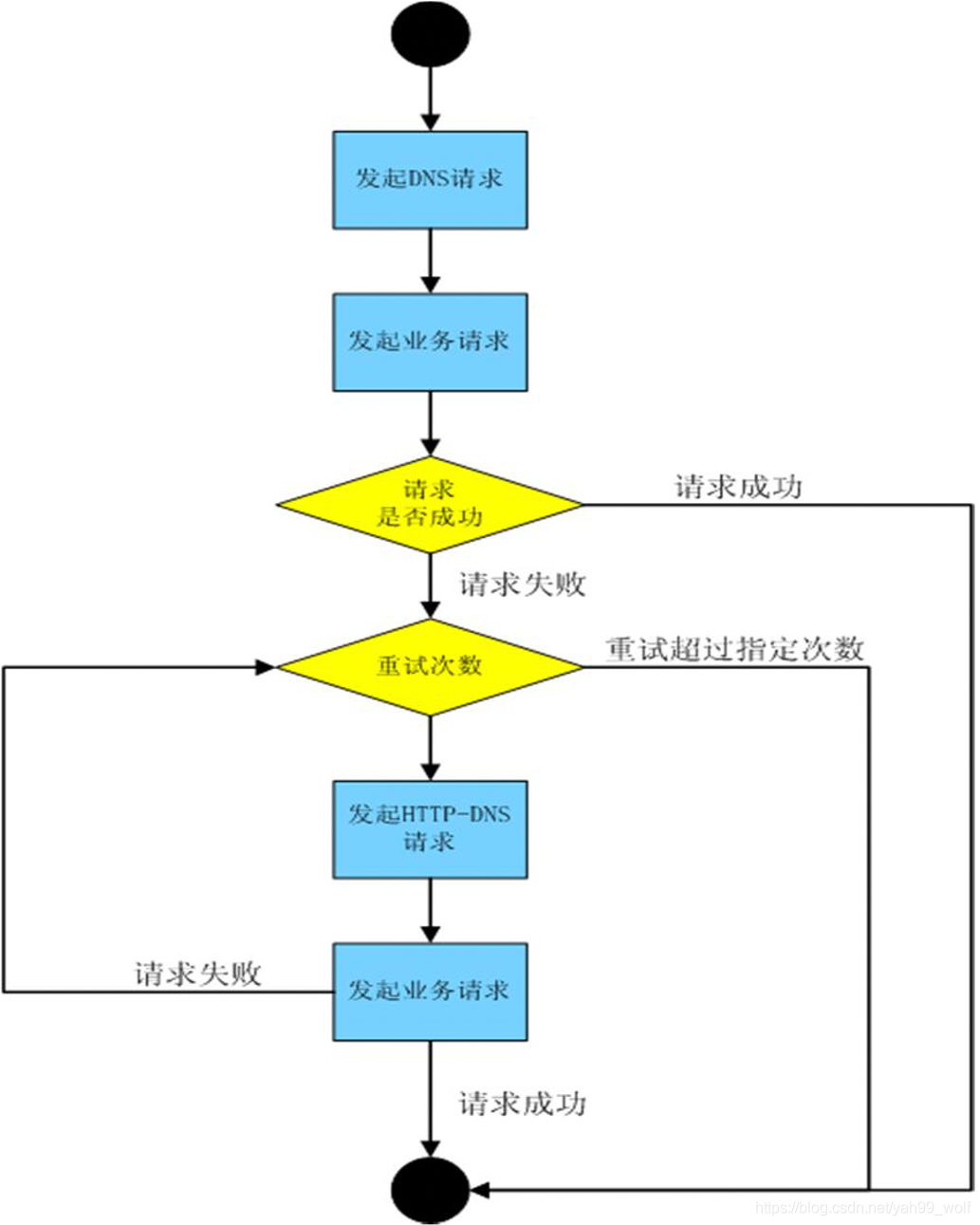
HTTPDNS案例
定义:不走传统的DNS解析,而是自己搭建基于HTTP协议的DNS服务器集群,分布在多个地点和多个运营商,当客户端需要DNS解析的时候,直接通过HTTP协议进行请求这个服务器集群,获得就近的地址。
- 在客户端的SDK里动态请求服务端,获取HTTPDNS服务器的ip列表,缓存到本地。SDK也会在本地缓存DNS域名解析的结果。这个缓存和本地DNS的缓存不一样,不是整个运营商统一做的,而是手机应用来做的,如何更新,何时更新。
- 如果本地无,就需要请求HTTPDNS的服务器,在本地的ip列表中,选择一个发出HTTP请求,返回一个要访问的网站的ip列表。手机客户端知道手机坐在的运营商,可以精确做到全局负载均衡。
- HTTPDNS的缓存设计解析的过程不需要本地DNS服务递归调用一大圈,一个HTTP请求直接搞定,本地也有缓存,过期时间,更新时间都可以自己控制。缓存设计模式三层:客户端,缓存,数据源- 对于应用架构,就是应用,缓存,数据库。tomcat,redis,mysql- 对于HTTPDNS来说,就是手机客户端,dns缓存,httpdns服务器例如dns缓存在内存中,也可以持久化到存储上,app重启后,就可以尽快的从存储中加载上次积累的解析结果。sdk中的缓存会严格按照缓存过期时间,如果没有命中,或已经过期,则不允许使用过期记录,会发起一次解析,保障记录是新的。解析可以是同步或异步的。同步更新的优点是实时性好,缺点是如果有多个请求都发现过期的时候,会同时请求HTTPDNS,浪费资源。对应到应用架构中缓存的Cache-Aside机制,先读缓存,不命中读数据库,同时写入到缓存。异步的优点是多个请求都过期的情况可以合并为一个,同时可以在即将过期的时候,创建一个任务进行预加载,防止过期之后再刷新成为预加载。缺点是当请求拿到过期数据,如果可以请求就没问题,如果不能请求,则失败,等下次缓存更新后,再请求方能成功。对应于应用架构中缓存的Refresh-Ahead机制,即业务仅仅访问缓存,当过期就定期刷新。
- HTTPDNS调度设计客户端嵌入了SDK,在客户端HTTPDNS服务端可以根据手机的国家,省市地点,运营商,选择最佳的服务节点。
基于IP欺骗的GSLB
HTTP重定向方案解决了判断不准确的问题,但只能针对HTTP协议应用使用。
对于HTTP协议以外的访问,就需要使用基于IP欺骗(又称三角传输)的GSLB。基于IP欺骗(三角传输)的GSLB工作流程,大致如下图:
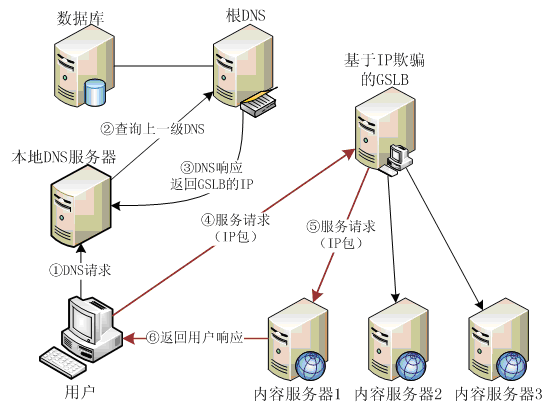
基于IP欺骗的方案同样需要首先将GSLB设备的IP地址在DNS中登记为域名的A记录,这样用户对该域名的请求包都会先发送到GSLB设备。如上图所示,GSLB设备首次收到服务请求包后,会选择一个最合适的服务器,并将服务请求包发送到该服务器。服务器在向用户发送响应包时,将其源IP地址字段改为GSLB设备的IP,发送给用户。
基于IP欺骗的GSLB 更改IP首部实现使用跳转.并利用IP tunneling技术实现只对请求负载均衡(响应直接返回).
a. 请求的域名均解析为GSLB机器的IP.
b. GSLB机器可以解析出目标地址,然后封装IP包发给目标地址.
c. 目标服务器收到请求包并处理,解析出被封装的IP包可以得到客户端地址,把响应直接返回.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ageCJHsO-1632790601835)(https://chongit.github.io/image/gslb/vs-tun.jpg)]
这样,整个过程对用户来说,感觉到的只是GSLB设备在为其提供服务,并不知道其中经历这样一个三角传输的过程。而且这种方案可以对所有类型的访问如HTTP、FTP等进行重定向,但其速度和效率相对比前两种方案要差一点,因为用户所有的访问请求都通过三个点才能响应,经历了更多的路径和处理,所以其主要作为HTTP重定向方案的补充方案在同一GSLB设备中实现。
特点
- 这个方案能解决不能获得源IP和HTTP Only的问题,也不会成为性能瓶颈.但由于是IP层的LB,因此得到的信息很有限,也就是做分发的策略会很有限.
- 实现方式主要就是LVS的
VS/TUN模式.如果自己编写会更灵活,但难度较大.
服务器群选择策略
上文中介绍的三种方案,解决了如何将用户引导到指定服务器群的问题,而在此之前, GSLB内部 首先需要使用某种方式选出最适合用户的服务器群,也就是GSLB在选择服务器群时所采用的策略。
接下来介绍一些常用的GSLB策略。
地理区域或用户自定义区域:将若干条IP地址前缀划分一个区域为。根据用户本地DNS的IP地址,将特定IP范围的用户优先分配到某个通过健康检查的站点。IP地址权重:可以为DNS应答中的每个IP地址分配权重,权重决定与其他候选IP相比分配到该IP的流量比例。往返时间(Round Trip Time, RTT):RTT策略是基于区域之外最常用的策略。有两种模式的RTT测量:Active RTT测量与Passive RTT测量。在实际部署中,由于网络限制和性能原因,Active RTT往往无法使用,Passive RTT更实用一些。
a) Active RTT 测量:
当GSLB Controller收到来自LDNS的DNS请求时,GSLB Controller会通知所有站点负载均衡设备对该LDNS进行RTT测量。根据采集到的RTT值,GSLB Controller会选择RTT值最小的站点的VIP返回给LDNS。
由于Active RTT采用DNS Query或ICMP进行RTT测量,在有些网络中可能会被安全策略所过滤而无法工作。
Active RTT测量会产生额外的DNS Query或ICMP流量,在有些网络中用户不希望有太多类似的非用户流量。
b) Passive RTT测量:
Passive RTT测量指从内容站点收到一个用户发出连接请求(发送TCN SYN)到接收到用户的确认(收到TCP ACK)所经历的时间。而不是简单的PING的响应时间,可以更精确的衡量访问最快的站点。
Passive RTT测量不会主动去进行测量,也不会产生额外的数据流量,而是在用户向返回的VIP建立连接时进行采集。
Passive RTT的测量值真正反映了用户的上网感受,在运营商网络中也不会产生额外流量。也不会受到其他运营商或网络的安全策略的影响。
阿里云智能DNS解析
传统DNS解析,不判断访问者来源,会随机选择其中一个IP地址返回给访问者。而智能DNS解析,会判断访问者的来源,为不同的访问者智能返回不同的IP地址,可使访问者在访问网站时可获取用户指定的IP地址,能够减少解析时延,并提升网站访问速度的功效。
概述
传统DNS解析,不判断访问者来源,会随机选择其中一个IP地址返回给访问者。而智能DNS解析,会判断访问者的来源,为不同的访问者智能返回不同的IP地址,可使访问者在访问网站时可获取用户指定的IP地址,能够减少解析时延,并提升网站访问速度的功效。
1 . 传统DNS解析示例
例如域名www.dns-example.com,有三台服务器,分别是联通IP,移动IP,电信IP,DNS解析配置如下:
- 将域名 指向 联通IP地址 (1.1.1.1)
- 将域名 指向 移动IP地址 (2.2.2.2)
- 将域名 指向 电信IP地址 (3.3.3.3)
可实现的解析效果:
传统DNS解析不判断访问者的来源,会将1.1.1.1、2.2.2.2、3.3.3.3三个地址全部返回给访问者的LocalDNS,由访问者的LocalDNS通过随机或者优选的方式将其中一个IP地址返回给访问者,传统DNS解析有可能会造成访问者跨网访问。
2 . 智能DNS解析示例
例如域名www.dns-example.com,有三台服务器,分别是联通IP,移动IP,电信IP,DNS解析配置如下:
- 解析线路配置 默认线路 指向 联通IP地址 (1.1.1.1)
- 解析线路配置 移动线路 指向 移动IP地址 (2.2.2.2)
- 解析线路配置 电信线路 指向 电信IP地址 (3.3.3.3)
可实现的解析效果
云解析会判断访问者的来源,为来源于移动运营商的访问者云解析返回2.2.2.2的解析地址,为来源于电信运营商的访问者云解析返回3.3.3.3的解析地址,其他来源的访问者云解析返回1.1.1.1的解析地址
实现原理
云解析是通过识别LOCALDNS的出口IP,来判断访问者来源。
如客户端LOCALDNS支持EDNS
因为云解析DNS支持 edns-client-subnet ,所以在获取访问者来源IP时,优先获取 edns-client-subnet 扩展里携带的IP ,如果edns-client-subnet 扩展里存在IP,云解析DNS会以该IP来判断访问者的地理位置 ;如果不存在,则以LocalDNS出口ip来判断访问者的地理位置。
如客户端LocalDNS不支持EDNS
LocalDNS会迭代请求至云解析DNS,云解析DNS根据访问者LocalDNS出口IP来判断访问者的地址位置,实现智能解析。
如客户端LocalDNS变相支持EDNS
用户发起DNS请求,递归到LocalDNS,则LocalDNS将本次请求发送到二级节点,通过二级节点向云解析DNS发起请求,此时云解析DNS会根据LocalDNS二级节点的地域位置返回具体的细分线路解析结果。
场景一:运营商线路智能解析
1 . 登录云解析DNS控制台
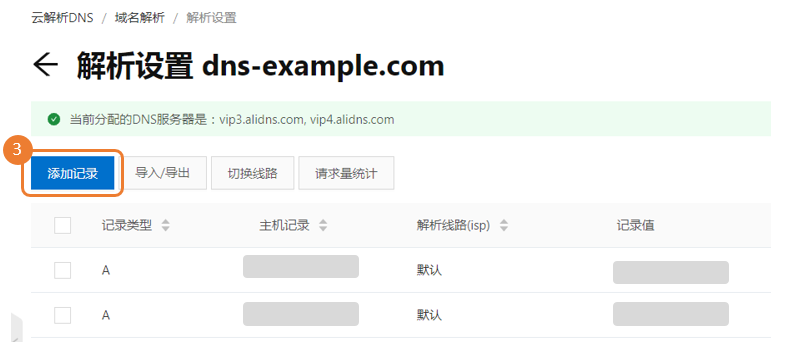
2 . 在域名解析页面,全部域名页签下,单击 域名,进入 解析设置页面。
3 . 在解析设置页面,单击 添加记录 按钮
示例:
如果您拥有3台服务器,分别位于 电信、联通、移动,添加记录时,在解析线路选择时,按如下配置:
- 默认线路:电信IP(10.10.10.10)
- 联通线路:联通IP(1.1.1.1)
- 移动线路:移动IP(2.2.2.2)
实现效果则是:
云解析会智能判断出访问者的来源,并返回配置的记录;
- 例如访问者来源于联通运营商,云解析则智能返回联通的IP地址1.1.1.1。
- 访问者如果来源于移动运营商,云解析则返回移动IP2.2.2.2。
- 访问者来源不属于联通和移动的运营商,则云解析返回默认线路配置的电信IP地址(10.10.10.10)。
以上解析线路的配置结果,可实现根据不同的访问者来源智能返回指定的IP地址。
场景二:阿里云线路智能解析
1 . 参考上述步骤,登录云解析DNS控制台,并进入解析设置页面
2 . 在解析设置页面,单击 添加记录 按钮
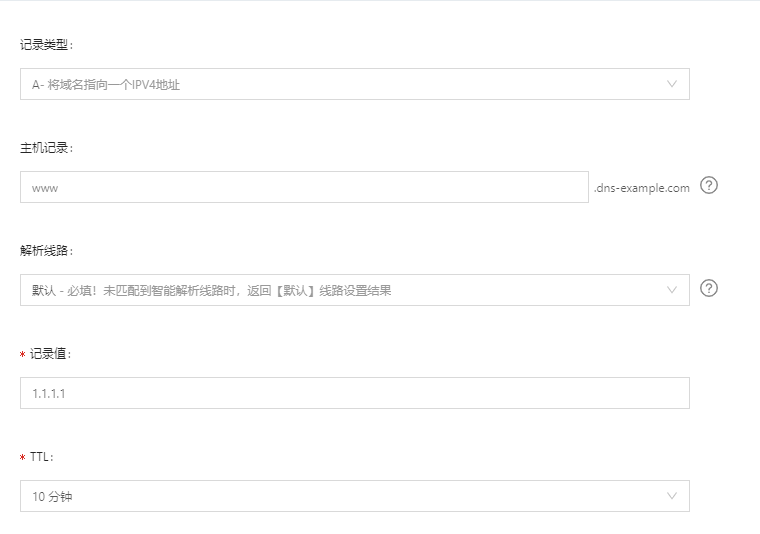
示例:
如果您拥有3台阿里云服务器,分别位于 华东1-杭州、华东2-上海、华北2-北京,添加记录时,在解析线路选择时,按如下配置:
- 默认线路:华东1-杭州(1.1.1.1)
- 阿里云华东2-上海线路:华东2-上海(2.2.2.2)
- 阿里云华北2-北京线路:华北2-北京(3.3.3.3)
默认线路:华东1-杭州(1.1.1.1)
阿里云华东2-上海线路:华东2-上海(2.2.2.2)
[!阿里阿里云华北2-北京线路:华北2-北京(3.3.3.3)
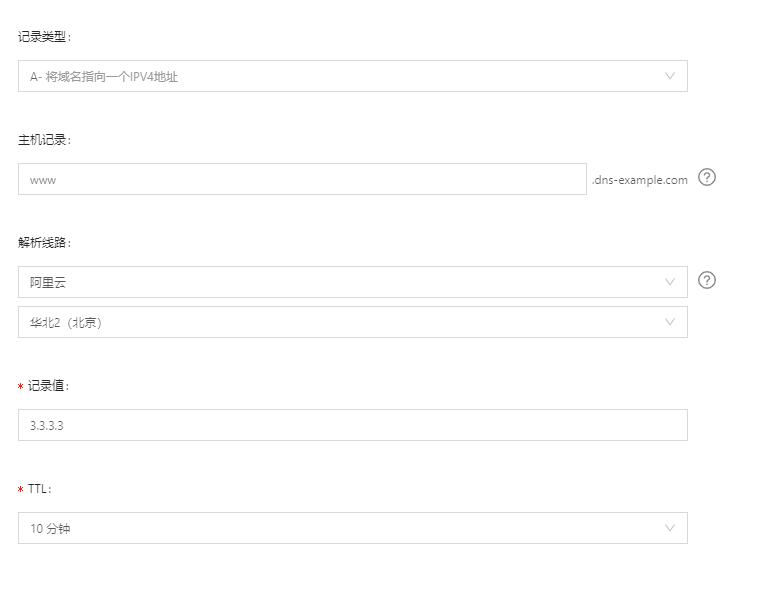 ](htt
](htt
云解析会智能判断出访问者的来源,并返回配置的记录;
- 例如访问者来源于阿里云华东2-上海地区,云解析则智能返回华东2-上海的IP地址2.2.2.2。
- 访问者如果来源于阿里云华北2-北京地区,云解析则智能返回华北2-北京的IP地址3.3.3.3。
- 访问者来源不属于阿里云华东2-上海地区和阿里云华北2-北京地区,则云解析返回默认线路配置的华东1-杭州IP地址(1.1.1.1)。
支持线路
云解析DNS当前能够识别出用户来源的解析线路如下:
解析线路子级线路阿里云华北1 (青岛)华北2 (北京)华北3 (张家口)华北5 (呼和浩特)华东1 (杭州)华东2 (上海)华北6(乌兰察布)华南1 (深圳)华南2 (河源)华南3 (广州)西南1(成都)中国(香港)新加坡澳大利亚(悉尼)马来西亚(吉隆坡)印度尼西亚(雅加达)日本(东京)德国(法兰克福)英国(伦敦)美国(硅谷)美国(弗吉尼亚)印度(孟买)中东东部1(迪拜)线路名称线路省份默认全局中国联通/中国电信/中国移动/中国教育网山东、江苏、安徽、浙江、福建、上海广东、广西、海南湖北、湖南、河南、江西北京、天津、河北、山西、内蒙古宁夏、新疆、青海、陕西、甘肃四川、云南、贵州、西藏、重庆辽宁、吉林、黑龙江中国鹏博士安徽、北京、重庆、福建、甘肃广东、广西、贵州、海南、河北、黑龙江、河南、湖北、湖南、江苏、江西、吉林、辽宁、内蒙古、宁夏、青海、陕西、山东、上海、山西、四川、天津、新疆、西藏、云南、浙江中国广电网黑龙江、山东、内蒙古、宁夏、湖南、贵州、青海、辽宁、河南、吉林、甘肃、河北、江苏、安徽、福建、海南、湖北、陕西、上海、陕西、四川、天津、西藏、新疆、浙江、北京、重庆、广东、广西、江西、云南线路名称大洲国家(地区)境外--境外大洋洲澳大利亚,新西兰,斐济,帕劳境外亚洲阿联酋,香港,印度尼西亚,印度,日本,柬埔寨,韩国,老挝,缅甸,澳门,马尔代夫,马来西亚,尼泊尔,菲律宾,沙特阿拉伯,新加坡,泰国,台湾,越南,蒙古,巴基斯坦,朝鲜,哈萨克斯坦,乌兹别克斯坦,土耳其,伊朗,伊拉克,以色列,科威特,黎巴嫩,卡塔尔,叙利亚境外欧洲奥地利,瑞士,德国,西班牙,法国,英国,意大利,荷兰,俄罗斯,瑞典,捷克,比利时,爱尔兰,丹麦,芬兰,冰岛,匈牙利,波兰,斯洛伐克,白俄罗斯,立陶宛,乌克兰,保加利亚,克罗地亚,葡萄牙,罗马尼亚,斯洛文尼亚境外北美洲加拿大,墨西哥,美国,古巴境外南美洲阿根廷,巴西,哥伦比亚、委内瑞拉、厄瓜多尔、秘鲁、玻利维亚、智利、巴拉圭、乌拉圭境外非洲南非,埃及,尼日利亚,安哥拉,加纳,科特迪瓦,肯尼亚,塞舌尔,阿尔及利亚,喀麦隆,摩洛哥,塞内加尔,苏丹,南苏丹线路名称地区省份默认--中国地区华东山东、江苏、安徽、江西、浙江、福建、上海中国地区华南广东、广西、海南中国地区华中湖北、湖南、河南中国地区华北北京、天津、河北、山西、内蒙古中国地区西北宁夏、新疆、青海、陕西、甘肃中国地区西南四川、云南、贵州、西藏、重庆中国地区东北辽宁、吉林、黑龙江
版本对比
云解析DNS不同版本提供的解析线路不同,参考如下:
功能/版本免费版个人版企业标准版企业旗舰版智能解析联通/电信/移动/教育网/境外联通/电信/移动/鹏博士/教育网/广电网,境外阿里云线路,分省(联通/电信/移动/鹏博士/教育网/广电网),境外/大洲/国家(地区)包含所有固定智能解析线路,支持自定义IP范围解析
参考文献:
http://c.biancheng.net/view/6457.html
https://blog.csdn.net/m0_37812513/article/details/78775629
https://blog.csdn.net/stpeace/article/details/43166377
https://www.cnblogs.com/machangwei-8/p/10353137.html
https://blog.csdn.net/zd8582zd/article/details/49120893
https://blog.csdn.net/zd8582zd/article/details/49120893
https://itlemon.blog.csdn.net/article/details/81358387
https://blog.csdn.net/yunqiinsight/article/details/102544840
https://www.cnblogs.com/milovetingting/p/14209352.html
https://www.cnblogs.com/jimmyhe/p/11279762.html
https://blog.csdn.net/grace_yi/article/details/89419106
https://blog.csdn.net/u010340143/article/details/9062213
https://www.cnblogs.com/jimmyhe/p/11279762.html
https://help.aliyun.com/document_detail/29730.html
版权归原作者 40岁资深老架构师尼恩 所有, 如有侵权,请联系我们删除。