
前提准备
Linux:CentOS-7-x86_64-DVD-1708.iso
Hadoop:hadoop-2.7.3.tar.gz
Java:jdk-8u181-linux-x64.tar.gz
Anaconda:Anaconda3-2021.11-Linux-x86_64.sh
Spark:spark-2.4.0-bin-without-hadoop.tgz
(一) Hadoop集群搭建
观看我的另一篇文章:
https://blog.csdn.net/2202_75334392/article/details/132863607?spm=1001.2014.3001.5502
(二)Anaconda环境搭建
可以观看我的另一篇文章:
https://blog.csdn.net/2202_75334392/article/details/133420659?spm=1001.2014.3001.5502
(三)创建pyspark环境
conda create -n pyspark python=3.6 # 基于python3.6创建pyspark虚拟环境
conda activate pyspark # 激活pyspark虚拟环境
pip下载pyhive、pyspark、jieba包
pip install pyspark==2.4.0 jieba pyhive -i https://pypi.tuna.tsinghua.edu.cn/simple
(四)Spark Local模式搭建
1.Spark下载、上传和解压
该环境搭建spark使用spark-2.4.0版本
下载地址:Index of /dist/spark/spark-2.4.0
2.上传Spark压缩包
一样运用xshell上传文件
3.解压上传好的压缩包
cd /opt/software
tar -zxvf spark-2.4.0-bin-without-hadoop.tgz -C /optcd /opt
解压之后进行重命名,重命名为
spark-2.4.0mv spark-2.4.0-bin-without-hadoop/ spark-2.4.0


4.配置环境变量
vim /etc/profile
路径根据你自己的修改
export JAVA_HOME=/opt/jdk-1.8
export HADOOP_HOME=/usr/local/hadoop
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PAT
export SPARK_HOME=/opt/spark-2.4.0
export PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$PATH
vi ~/.bashrc
export JAVA_HOME=/opt/jdk-1.8
export PYSPARK_PYTHON=/opt/anaconda3/envs/pyspark/bin/python
export PATH=$JAVA_HOME/bin:$PATH
再刷新配置文件
source /etc/profile
source ~/.bashrc
(五)配置Spark配置文件
cd /opt/spark-2.4.0/conf
1.spark-env.sh
cp spark-env.sh.template spark-env.sh
在文件后面追加下面的内容
export JAVA_HOME=/opt/jdk1.8.0
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)

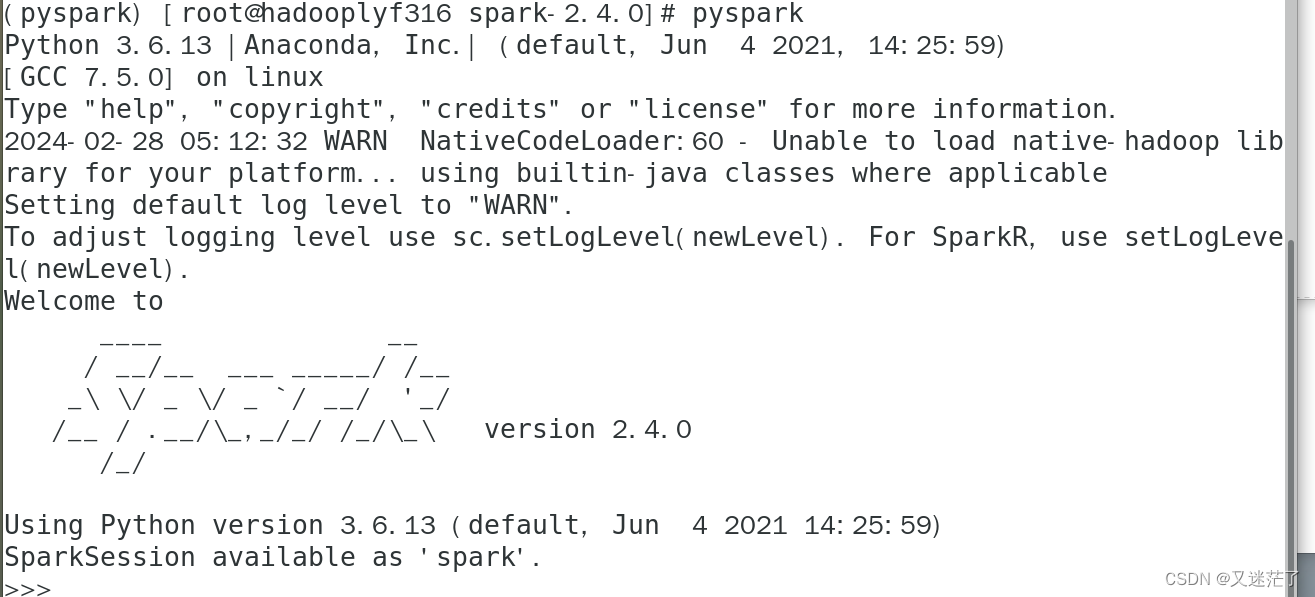
2.测试
如果报以下错误,就输入conda activate pyspark 激活环境

成功启动是下图界面
版权归原作者 又迷茫了 所有, 如有侵权,请联系我们删除。