
实时计算Flink版支持通过DataStream作业的方式运行支持规则动态更新的Flink CEP作业。本文结合实时营销中的反作弊场景,为您介绍如何基于Flink全托管快速构建一个动态加载最新规则来处理上游Kafka数据的Flink CEP作业。
背景信息
在电商平台投放广告时,广告主通常有预算限制。例如对于按点击次数计算费用的广告而言,如果有黑灰产构造虚假流量,攻击广告主,则会很快消耗掉正常广告主的预算,使得广告内容被提前下架。在这种情况下,广告主的利益受到了损害,容易导致后续的投诉与纠纷。
为了应对上述作弊场景,我们需要快速辨识出恶意流量,采取针对性措施(例如限制恶意用户、向广告主发送告警等)来保护用户权益。同时考虑到可能有意外因素(例如达人推荐、热点事件引流)导致流量骤变,我们也需要动态调整用于识别恶意流量的规则,避免损害正常用户的利益。
本文为您演示如何使用Flink动态CEP解决上述问题。我们假设客户的行为日志会被存放入消息队列Kafka中,Flink CEP作业会消费Kafka数据,同时会去轮询RDS数据库中的规则表,拉取策略人员添加到数据库的最新规则,并用最新规则去匹配事件。针对匹配到的事件,Flink CEP作业会发出告警或将相关信息写入其他数据存储中。示例中整体数据链路如下图所示。
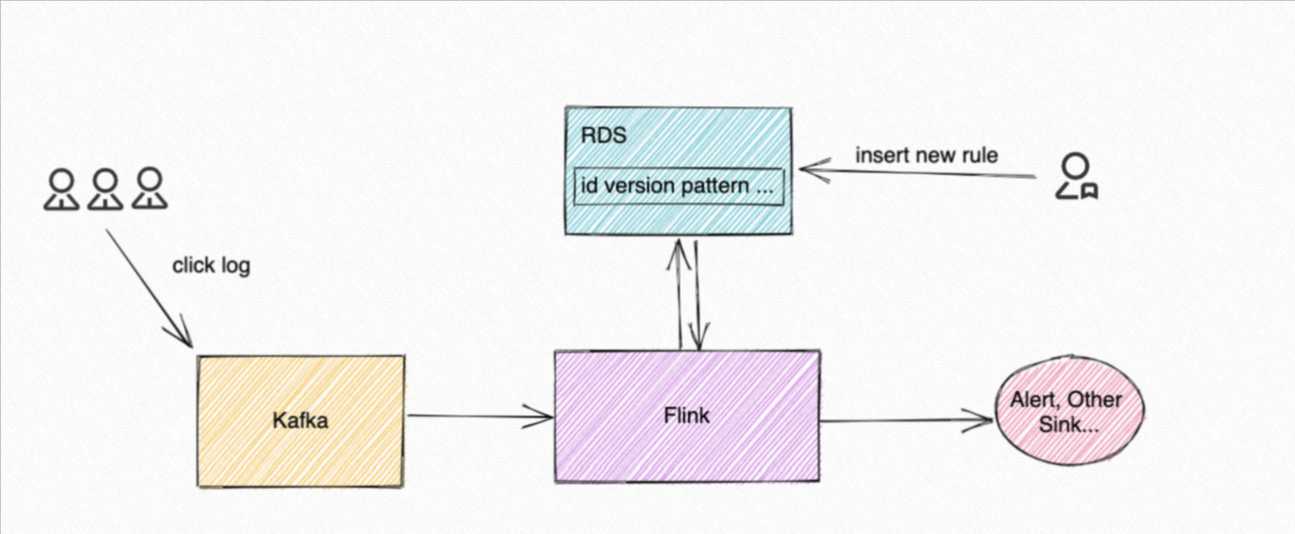
实际演示中,我们会先启动Flink CEP作业,然后插入规则1:连续3条action为0的事件发生后,下一条事件的action仍非1,其业务含义为连续3次访问该产品后最后没有购买。在匹配到相应事件并进行处理后,我们会动态更新规则1内容为连续5条action为0或2的事件发生后,下一条事件的action仍非1,来应对流量整体增加的场景,同时插入一条规则2,它将和规则1的初始规则一样,用于辅助展示多规则支持等功能。当然,您也可以添加一个全新规则。
前提条件
- 如果您使用RAM用户或RAM角色等身份访问,需要确认已具有Flink控制台相关权限,详情请参见权限管理。
- 已创建Flink工作空间,详情请参见开通实时计算Flink版。
- 上下游存储- 已创建RDS MySQL实例,详情请参见创建RDS MySQL实例。- 已创建消息队列Kafka实例,详情请参见概述。
- 仅实时计算引擎VVR 6.0.2及以上版本支持动态CEP功能。
操作流程
本文为您介绍如何编写Flink CEP作业检测行为日志中的异常事件序列去发现恶意流量,并演示如何进行规则的动态更新。具体的操作流程如下:
- 步骤一:准备测试数据
- 步骤二:配置IP白名单
- 步骤三:开发并启动Flink CEP作业
- 步骤四:插入规则
- 步骤五:更新匹配规则,并查看更新的规则是否生效
步骤一:准备测试数据
准备上游Kafka Topic
- 登录云消息队列 Kafka 版控制台。
- 创建一个名称为demo_topic的Topic,存放模拟的用户行为日志。操作详情请参见步骤一:创建Topic。
准备RDS数据库
在DMS数据管理控制台上,准备RDS MySQL的测试数据。
- 使用高权限账号登录RDS MySQL。详情请参见通过DMS登录RDS MySQL。
- 创建rds_demo规则表,用来记录Flink CEP作业中需要应用的规则。在已登录的SQLConsole窗口,输入如下命令后,单击执行。
CREATE DATABASE cep_demo_db;USE cep_demo_db;CREATE TABLE rds_demo ( `id` VARCHAR(64), `version` INT, `pattern` VARCHAR(4096), `function` VARCHAR(512));每行代表一条规则,包含id、version等用于区分不同规则与每个规则不同版本的字段、描述CEP API中的模式对象的pattern字段,以及描述如何处理匹配模式的事件序列的function字段。
步骤二:配置IP白名单
为了让Flink能访问RDS MySQL实例,您需要将Flink全托管工作空间的网段添加到在RDS MySQL的白名单中。
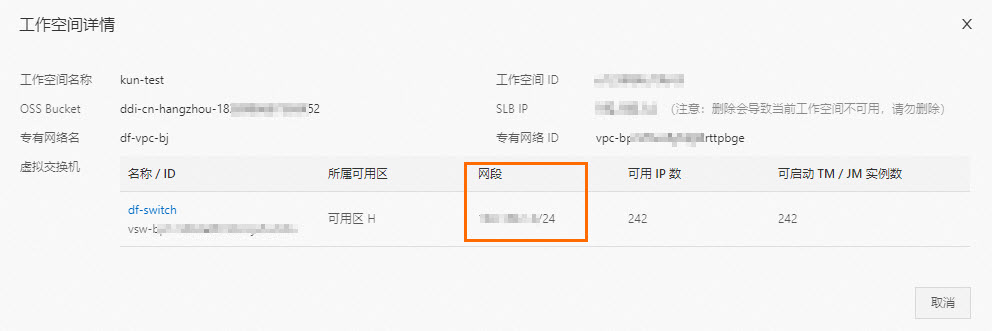
- 获取Flink全托管工作空间的VPC网段。1. 登录实时计算控制台。2. 在目标工作空间右侧操作列,选择更多 > 工作空间详情。3. 在工作空间详情对话框,查看Flink全托管虚拟交换机的网段信息。
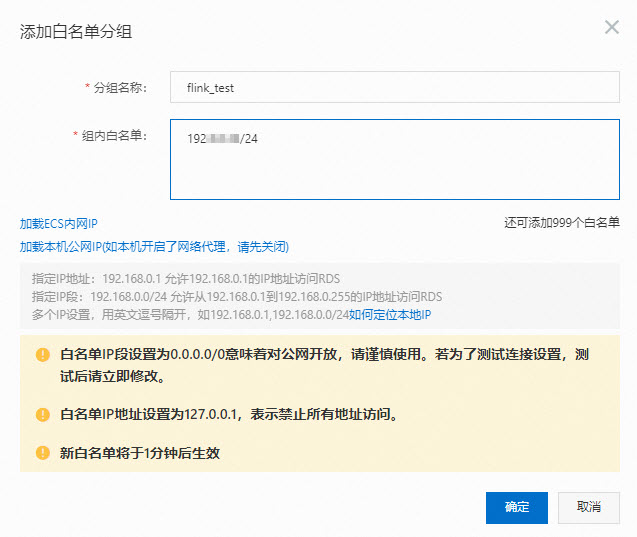
- 在RDS MySQL的IP白名单中,添加Flink全托管网段信息。操作步骤详情请参见设置IP白名单。
步骤三:开发并启动Flink CEP作业
说明
本文中所有代码都可以在Github仓库下载。本文档接下来会描述重点部分实现,方便您参考。
- 配置Maven项目中的pom.xml文件所使用的仓库。pom.xml文件的配置详情,请参见Kafka DataStream Connector。
- 在作业的Maven POM文件中添加flink-cep作为项目依赖。
<dependency> <groupId>com.alibaba.ververica</groupId> <artifactId>flink-cep</artifactId> <version>1.15-vvr-6.0.2-api</version> <scope>provided</scope></dependency> - 开发作业代码。1. 构建Kafka Source。代码编写详情,请参见Kafka DataStream Connector。2. 构建CEP.dynamicPatterns()。为支持CEP规则动态变更与多规则匹配,阿里云实时计算Flink版定义了CEP.dynamicPatterns() API。该API定义代码如下。
public static <T, R> SingleOutputStreamOperator<R> dynamicPatterns( DataStream<T> input, PatternProcessorDiscovererFactory<T> discovererFactory, TimeBehaviour timeBehaviour, TypeInformation<R> outTypeInfo)使用该API时,所需参数如下。您可以跟进实际使用情况,更新相应的参数取值。参数****说明DataStream<T> input输入事件流。PatternProcessorDiscovererFactory<T> discovererFactory工厂对象。工厂对象负责构造一个探查器(PatternProcessorDiscoverer),探查器负责获取最新规则,即构造一个PatternProcessor接口。TimeBehaviour timeBehaviour描述Flink CEP作业如何处理事件的时间属性。参数取值如下:- TimeBehaviour.ProcessingTime:代表按照Processing Time处理事件。- TimeBehaviour.EventTime:代表按照Event Time处理事件。TypeInformation<R> outTypeInfo描述输出流的类型信息。关于DataStream、TimeBehaviour、TypeInformation等Flink作业常见概念详情,请参见DataStream、TimeBehaviour和TypeInformation。这里重点介绍PatternProcessor接口,一个PatternProcessor包含一个确定的模式(Pattern)用于描述如何去匹配事件,以及一个PatternProcessFunction用于描述如何处理一个匹配(例如发送警报)。除此之外,还包含id与version等用于标识PatternProcessor的信息。因此一个PatternProcessor既包含规则本身,又指明了规则触发时,Flink作业应如何响应。更多背景请参见提案。而patternProcessorDiscovererFactory用于构造一个探查器去获取最新的PatternProcessor,我们在示例代码中提供了一个默认的周期性扫描外部存储的抽象类。它描述了如何启动一个Timer去定时轮询外部存储拉取最新的PatternProcessor。public abstract class PeriodicPatternProcessorDiscoverer<T> implements PatternProcessorDiscoverer<T> { ... @Override public void discoverPatternProcessorUpdates( PatternProcessorManager<T> patternProcessorManager) { // Periodically discovers the pattern processor updates. timer.schedule( new TimerTask() { @Override public void run() { if (arePatternProcessorsUpdated()) { List<PatternProcessor<T>> patternProcessors = null; try { patternProcessors = getLatestPatternProcessors(); } catch (Exception e) { e.printStackTrace(); } patternProcessorManager.onPatternProcessorsUpdated(patternProcessors); } } }, 0, intervalMillis); } ...}实时计算Flink版提供了JDBCPeriodicPatternProcessorDiscoverer的实现,用于从支持JDBC协议的数据库(例如RDS或者Hologres等)中拉取最新的规则。在使用时,您需要指定如下参数。参数****说明jdbcUrl数据库JDBC连接地址。jdbcDriver数据库驱动类类名。tableName数据库表名。initialPatternProcessors当数据库的规则表为空时,使用的默认PatternProcessor。intervalMillis轮询数据库的时间间隔。在实际代码中您可以按如下方式使用,作业将会匹配到的规则打印到Flink TaskManager的输出中。// import ......public class CepDemo { public static void main(String[] args) throws Exception { ...... // DataStream Source DataStreamSource<Event> source = env.fromSource( kafkaSource, WatermarkStrategy.<Event>forMonotonousTimestamps() .withTimestampAssigner((event, ts) -> event.getEventTime()), "Kafka Source"); env.setParallelism(1); // keyBy userId and productionId // Notes, only events with the same key will be processd to see if there is a match KeyedStream<Event, Tuple2<Integer, Integer>> keyedStream = source.keyBy( new KeySelector<Event, Tuple2<Integer, Integer>>() { @Override public Tuple2<Integer, Integer> getKey(Event value) throws Exception { return Tuple2.of(value.getId(), value.getProductionId()); } }); SingleOutputStreamOperator<String> output = CEP.dynamicPatterns( keyedStream, new JDBCPeriodicPatternProcessorDiscovererFactory<>( JDBC_URL, JDBC_DRIVE, TABLE_NAME, null, JDBC_INTERVAL_MILLIS), TimeBehaviour.ProcessingTime, TypeInformation.of(new TypeHint<String>() {})); output.print(); // Compile and submit the job env.execute("CEPDemo"); }}说明为了方便演示,我们在Demo代码里将输入数据流按照id和product id做了一步keyBy,再与CEP.dynamicPatterns()连接使用。这意味着只有具有相同id和product id的事件会被纳入到规则匹配的考虑中,Key不同的事件之间不会产生匹配。 - 在实时计算控制台上,上传JAR包并部署JAR作业,具体操作详情请参见部署作业。为了让您可以快速测试使用,您需要下载实时计算Flink版测试JAR包。部署时需要配置的参数填写说明如下表所示。说明由于目前我们上游的Kafka Source暂无数据,并且数据库中的规则表为空。因此作业运行起来之后,暂时会没有输出。配置项说明部署作业类型选择为JAR。部署模式选择为流模式。部署名称填写对应的JAR作业名称。引擎版本从VVR 3.0.3版本(对应Flink 1.12版本)开始,VVP支持同时运行多个不同引擎版本的JAR作业。如果您的作业已使用了Flink 1.12及更早版本的引擎,您需要按照以下情况进行处理:- Flink 1.12版本:停止后启动作业,系统将自动将引擎升级为vvr-3.0.3-flink-1.12版本。- Flink 1.11或Flink 1.10版本:手动将作业引擎版本升级到vvr-3.0.3-flink-1.12或vvr-4.0.8-flink-1.13版本后重启作业,否则会在启动作业时超时报错。JAR URL上传打包好的JAR包,或者直接上传我们提供的测试JAR包。Entry Point Class填写为
com.alibaba.ververica.cep.demo.CepDemo。Entry Point Main Arguments如果您是自己开发的作业,已经配置了相关上下游存储的信息,则此处可以不填写。但是,如果您是使用的我们提供的测试JAR包,则需要配置该参数。代码信息如下。--kafkaBrokers YOUR_KAFKA_BROKERS --inputTopic YOUR_KAFKA_TOPIC --inputTopicGroup YOUR_KAFKA_TOPIC_GROUP --jdbcUrl jdbc:mysql://YOUR_DB_URL:port/DATABASE_NAME?user=YOUR_USERNAME&password=YOUR_PASSWORD--tableName YOUR_TABLE_NAME --jdbcIntervalMs 3000其中涉及的参数及含义如下:- kafkaBrokers:Kafka Broker地址。- inputTopic:Kafka Topic名称。- inputTopicGroup:Kafka消费组。- jdbcUrl:数据库JDBC连接地址。说明本示例所使用的JDBC URL中对应的账号和密码需要为普通账号和密码,且密码里仅支持英文字母和数字。在实际场景中,您可根据您的需求在作业中使用不同的鉴权方式。- tableName:目标表名称。- jdbcIntervalMs:轮询数据库的时间间隔。说明- 需要将以上参数的取值修改为您实际业务上下游存储的信息。- 参数信息长度不要大于1024,且不建议用来传复杂参数,复杂参数指包括了换行、空格或者其他特殊字符的参数(仅支持英文字母和数字)。如果您需要传入复杂参数,请使用附加依赖文件来传输。 - 在部署详情页签中的其他配置,添加如下作业运行参数。
kubernetes.application-mode.classpath.include-user-jar: 'true' classloader.resolve-order: parent-first运行参数配置步骤详情请参见运行参数配置。 - 在运维中心 > 作业运维页面,单击目标作业操作列下的启动。作业启动参数配置详情请参见作业启动。
步骤四:插入规则
启动Flink CEP作业,然后插入规则1:连续3条action为0的事件发生后,下一条事件的action仍非1,其业务含义为连续3次访问该产品后最后没有购买。
- 使用普通账号登录RDS MySQL。详情请参见通过DMS登录RDS MySQL。
- 插入动态更新规则。将JSON字符串与id、version、function类名等拼接后插入到RDS中。
INSERT INTO rds_demo ( `id`, `version`, `pattern`, `function`) values( '1', 1, '{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":null,"nodes":[{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":{"className":"com.alibaba.ververica.cep.demo.condition.EndCondition","type":"CLASS"},"type":"ATOMIC"},{"name":"start","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["LOOPING"],"times":{"from":3,"to":3,"windowTime":null},"untilCondition":null},"condition":{"expression":"action == 0","type":"AVIATOR"},"type":"ATOMIC"}],"edges":[{"source":"start","target":"end","type":"SKIP_TILL_NEXT"}],"window":null,"afterMatchStrategy":{"type":"SKIP_PAST_LAST_EVENT","patternName":null},"type":"COMPOSITE","version":1}', 'com.alibaba.ververica.cep.demo.dynamic.DemoPatternProcessFunction');为了方便您使用并提高数据库中的Pattern字段的可读性,实时计算Flink版定义了一套JSON格式的规则描述,详情请参见动态CEP中规则的JSON格式定义。上述SQL语句中的pattern字段的值就是按照JSON格式的规则,给出的序列化后的pattern字符串。它的物理意义是去匹配这样的模式:连续3条action为0的事件发生后,下一条事件的action仍非1。说明在下文的EndCondition对应的代码中,定义了action仍非1。- 对应的CEP API描述如下。Pattern<Event, Event> pattern = Pattern.<Event>begin("start", AfterMatchSkipStrategy.skipPastLastEvent()) .where(new StartCondition("action == 0")) .timesOrMore(3) .followedBy("end") .where(new EndCondition());- 对应的JSON字符串如下。{ "name": "end", "quantifier": { "consumingStrategy": "SKIP_TILL_NEXT", "properties": [ "SINGLE" ], "times": null, "untilCondition": null }, "condition": null, "nodes": [ { "name": "end", "quantifier": { "consumingStrategy": "SKIP_TILL_NEXT", "properties": [ "SINGLE" ], "times": null, "untilCondition": null }, "condition": { "className": "com.alibaba.ververica.cep.demo.condition.EndCondition", "type": "CLASS" }, "type": "ATOMIC" }, { "name": "start", "quantifier": { "consumingStrategy": "SKIP_TILL_NEXT", "properties": [ "LOOPING" ], "times": { "from": 3, "to": 3, "windowTime": null }, "untilCondition": null }, "condition": { "expression": "action == 0", "type": "AVIATOR" }, "type": "ATOMIC" } ], "edges": [ { "source": "start", "target": "end", "type": "SKIP_TILL_NEXT" } ], "window": null, "afterMatchStrategy": { "type": "SKIP_PAST_LAST_EVENT", "patternName": null }, "type": "COMPOSITE", "version": 1} - 通过Kafka Client向demo_topic中发送消息。在本Demo中,您也可以使用消息队列Kafka提供的快速体验消息收发页面发送测试消息。
1,Ken,0,1,16620227770001,Ken,0,1,16620227780001,Ken,0,1,16620227790001,Ken,0,1,1662022780000 demo_topic字段说明如下表所示。字段****说明id用户ID。username用户名。action用户动作,取值如下:- 0代表浏览操作。- 1代表购买动作。- 2代表分享操作。product_id商品ID。event_time该行为发生的事件时间。
demo_topic字段说明如下表所示。字段****说明id用户ID。username用户名。action用户动作,取值如下:- 0代表浏览操作。- 1代表购买动作。- 2代表分享操作。product_id商品ID。event_time该行为发生的事件时间。 - 查看JobManager日志中打印的最新规则和TaskManager日志中打印的匹配。- 在JobManager日志中,通过JDBCPeriodicPatternProcessorDiscoverer关键词搜索,查看最新规则。
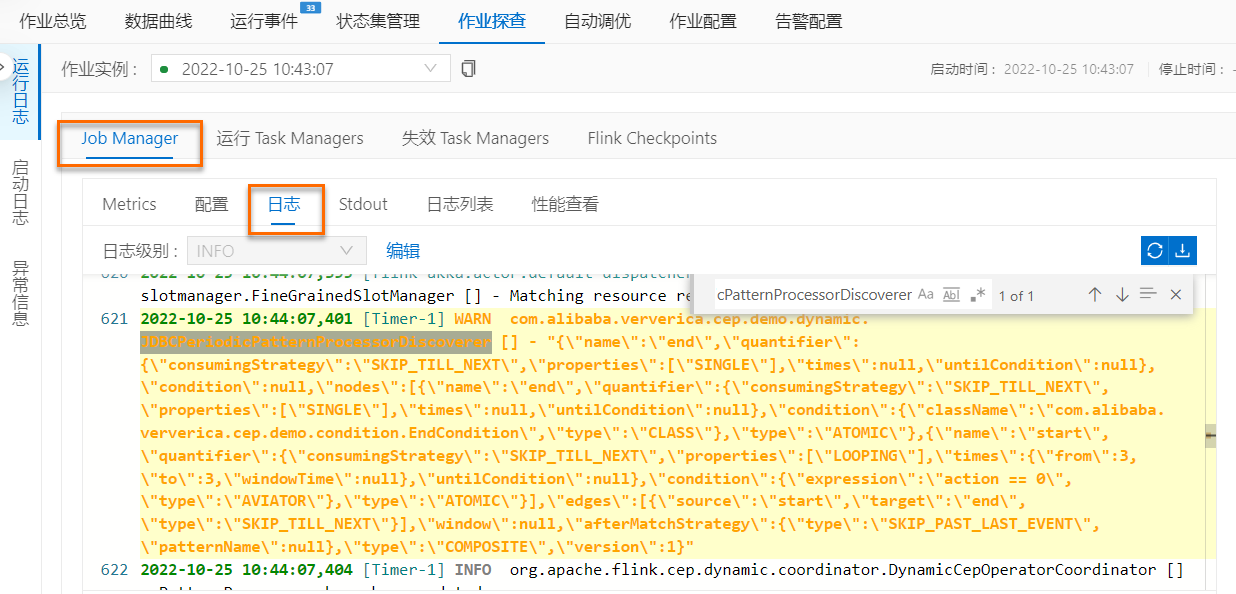 - 在TaskManager中以.out结尾的日志文件中,通过
- 在TaskManager中以.out结尾的日志文件中,通过A match for Pattern of (id, version): (1, 1)关键词搜索,查看日志中打印的匹配。
步骤五:更新匹配规则,并查看更新的规则是否生效
在匹配到相应事件并进行处理后,动态更新规则1内容为连续5条action为0或为2的事件发生后,下一条事件的action仍非1,来应对流量整体增加的场景,同时插入一条规则2,它将和规则1的初始规则一样,用于辅助展示多规则支持等功能。
- 使用在RDS控制台上,更新匹配规则。1. 使用普通账号登录RDS MySQL。详情请参见通过DMS登录RDS MySQL。2. 将StartCondition中的action == 0修改为action == 0 || action == 2,并且我们将重复出现的次数从>=3改为>=5,对应SQL语句如下。
INSERT INTO rds_demo(`id`, `version`, `pattern`, `function`) values('1', 2, '{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":null,"nodes":[{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":{"className":"com.alibaba.ververica.cep.demo.condition.EndCondition","type":"CLASS"},"type":"ATOMIC"},{"name":"start","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["LOOPING"],"times":{"from":5,"to":5,"windowTime":null},"untilCondition":null},"condition":{"expression":"action == 0 || action == 2","type":"AVIATOR"},"type":"ATOMIC"}],"edges":[{"source":"start","target":"end","type":"SKIP_TILL_NEXT"}],"window":null,"afterMatchStrategy":{"type":"SKIP_PAST_LAST_EVENT","patternName":null},"type":"COMPOSITE","version":1}','com.alibaba.ververica.cep.demo.dynamic.DemoPatternProcessFunction');3. 再插入一条记录的id为2新规则。它和规则1的版本1一样,其StartCondition仍为action == 0且重复出现的次数为>=3。INSERT INTO rds_demo(`id`, `version`, `pattern`, `function`) values('2', 1, '{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":null,"nodes":[{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":{"className":"com.alibaba.ververica.cep.demo.condition.EndCondition","type":"CLASS"},"type":"ATOMIC"},{"name":"start","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["LOOPING"],"times":{"from":3,"to":3,"windowTime":null},"untilCondition":null},"condition":{"expression":"action == 0","type":"AVIATOR"},"type":"ATOMIC"}],"edges":[{"source":"start","target":"end","type":"SKIP_TILL_NEXT"}],"window":null,"afterMatchStrategy":{"type":"SKIP_PAST_LAST_EVENT","patternName":null},"type":"COMPOSITE","version":1}','com.alibaba.ververica.cep.demo.dynamic.DemoPatternProcessFunction'); - 在Kafka控制台上发送8条简单的消息,来触发匹配。8条简单的消息示例如下。
1,Ken,0,1,16620227770001,Ken,0,1,16620227770001,Ken,0,1,16620227770001,Ken,2,1,16620227770001,Ken,0,1,16620227770001,Ken,0,1,16620227770001,Ken,0,1,16620227770001,Ken,2,1,1662022777000 - 在TaskManager中以.out结尾的日志文件中,查看匹配结果。- 如果要搜规则1在更新为版本2之后的匹配,可以通过
A match for Pattern of (id, version): (1, 2)关键词,查匹配结果。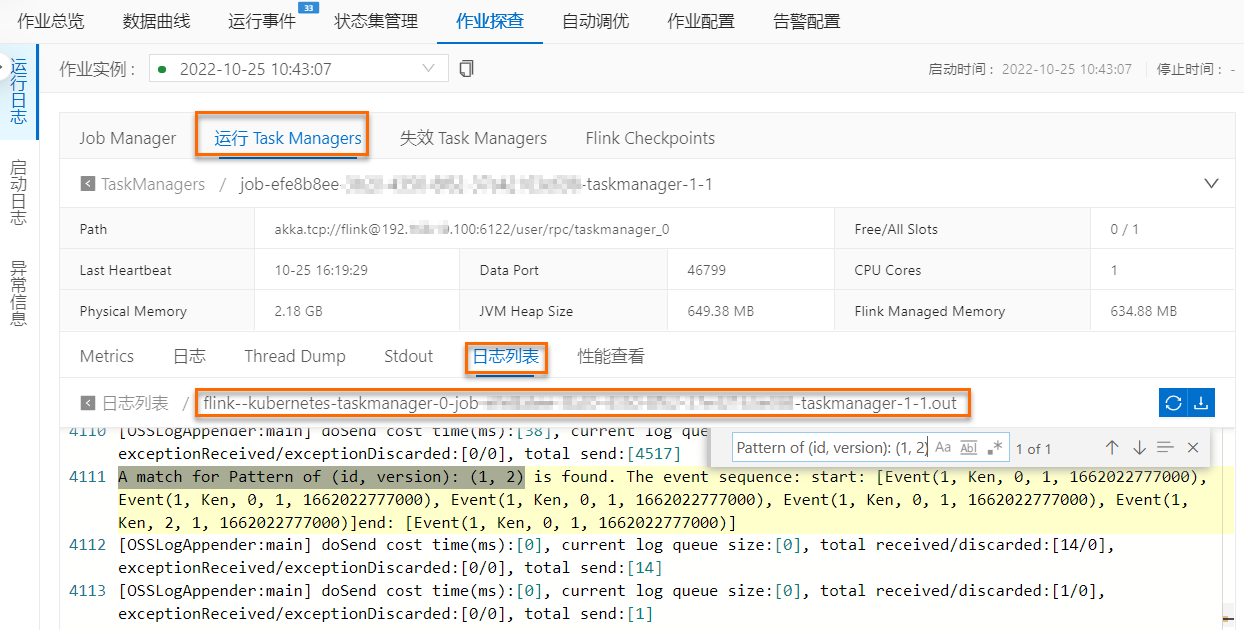 - 如果要搜规则2在版本为1的匹配,可以通过
- 如果要搜规则2在版本为1的匹配,可以通过A match for Pattern of (id, version): (2, 1)关键词,查匹配结果。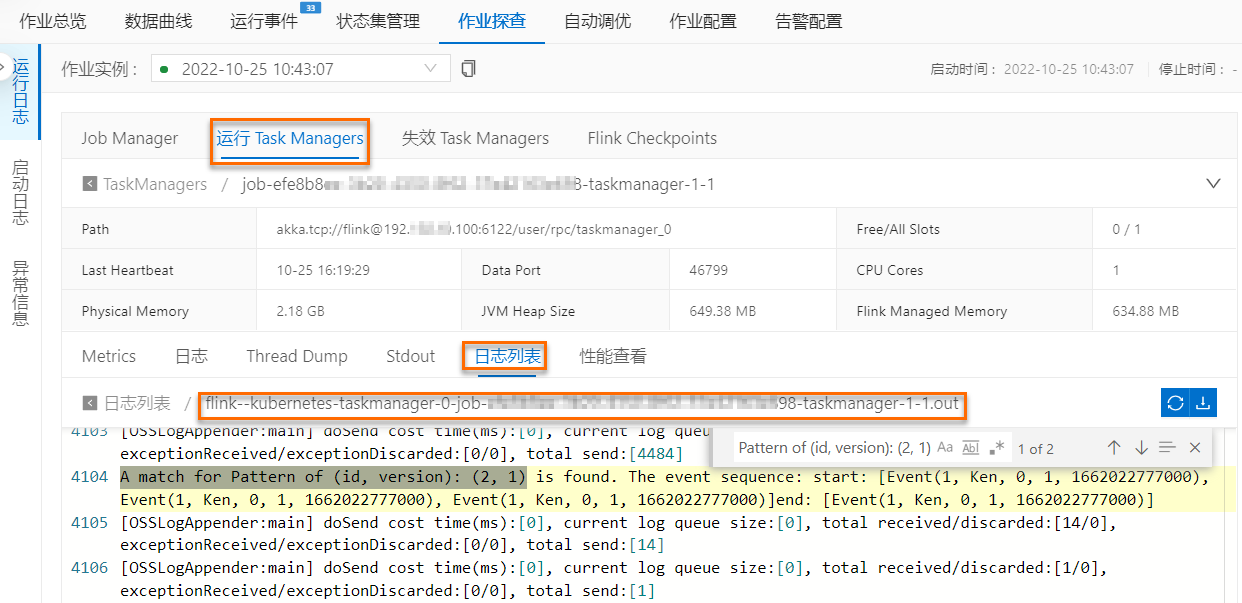 如上图中蓝框内结果所示,Flink CEP作业按照id为1,version为2的规则匹配到1次5个action为0或2的事件+1个action非1的1个事件的事件序列后输出结果,代表动态修改的规则成功生效;而对于id为2,version为1的规则,如上图中橙色框内结果所示,Flink CEP作业匹配到2次3个action为0的事件+1个action非1的1个事件的事件序列后输出结果,代表动态新增的规则也在作业中被采用。
如上图中蓝框内结果所示,Flink CEP作业按照id为1,version为2的规则匹配到1次5个action为0或2的事件+1个action非1的1个事件的事件序列后输出结果,代表动态修改的规则成功生效;而对于id为2,version为1的规则,如上图中橙色框内结果所示,Flink CEP作业匹配到2次3个action为0的事件+1个action非1的1个事件的事件序列后输出结果,代表动态新增的规则也在作业中被采用。
版权归原作者 soso1968 所有, 如有侵权,请联系我们删除。