
1.原理
YOLOv5是一个在COCO数据集上预训练的物体检测架构和模型系列,它代表了Ultralytics对未来视觉AI方法的开源研究,其中包含了经过数千小时的研究和开发而形成的经验教训和最佳实践。
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使得其速度与精度都得到了极大的性能提升,具体包括:输入端的Mosaic数据增强、自适应锚框计算、自适应图片缩放操作;基准端的Focus结构与CSP结构;Neck端的SPP与FPN+PAN结构;输出端的损失函数GIOU_Loss以及预测框筛选的DIOU_nms。除此之外,YOLOv5中的各种改进思路仍然可以应用到其它的目标检测算法中。
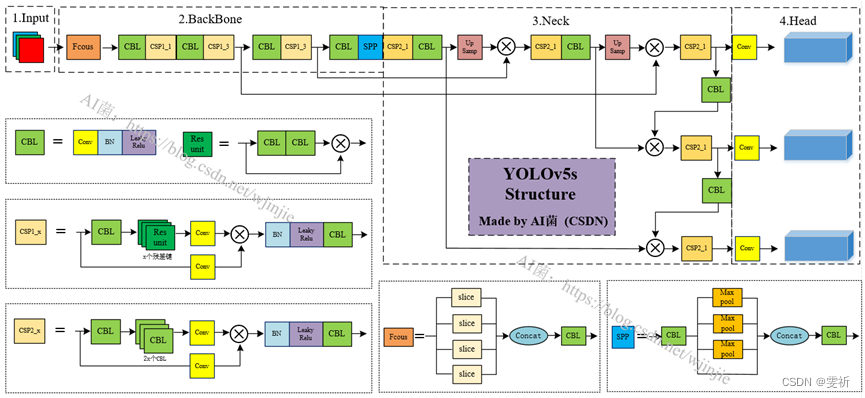
Focus结构
该结构的主要思想是通过slice操作来对输入图片进行裁剪。如下图所示,原始输入图片大小为6086083,经过Slice与Concat操作之后输出一个30430412的特征映射;接着经过一个通道个数为32的Conv层(该通道个数仅仅针对的是YOLOv5s结构,其它结构会有相应的变化),输出一个30430432大小的特征映射
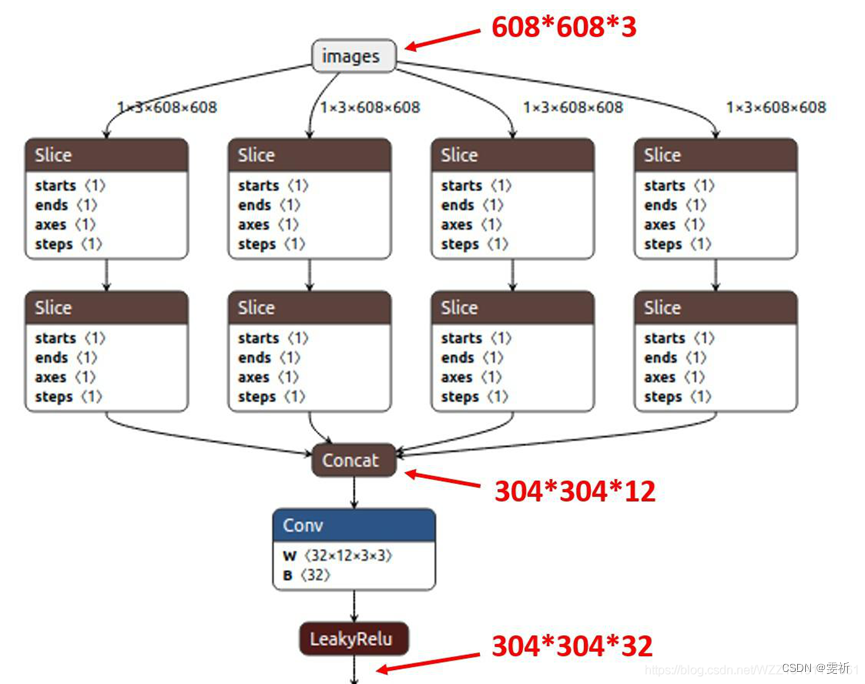
Focus是Yolov5新增的操作,右图就是将4 * 4 * 3的图像切片后变成2 * 2 * 12的特征图。
以Yolov5s的结构为例,原始608 * 608 * 3的图像输入Focus结构,采用切片操作,先变成304 * 304 * 12的特征图,再经过一次32个卷积核的卷积操作,最终变成304 * 304 * 32的特征图。
2.思维流程
2.1 进行yolov5的环境搭建
2.1.1 在Linux的ubuntu环境anaconda的安装
2.1.2 Vscode的安装和配置

2.1.3 Github上面yolov5文件的下载
Release v4.0 - nn.SiLU() activations, Weights & Biases logging, PyTorch Hub integration · ultralytics/yolov5 · GitHub
2.1.4 使用Anaconda3搭建自己的python-yolov5-4.0环境
创建环境打开终端,输入conda create -n 环境名 python=版本号
激活环境 conda activate 环境名
各种软件包的安装 pip install 安装包的名称==版本号
2.2 模型的训练
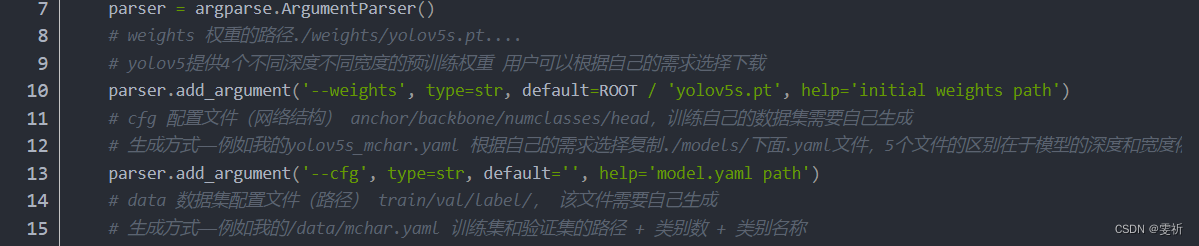
2.2.1 train.py代码基础参数配置的学习
2.2.2 数据集的拉框
Make Sense
2.2.3 使用share(虚拟机共享文件)与虚拟机进行共享
2.2.4 导入数据进行best.pt模型的训练
2.2.5 在原有模型基础上不断进行测试和改进训练
2.2.6 detect.py代码基础参数配置的学习

2.3赛题流程
2.3.1根据赛题的要求在yolov5原有代码基础上进行拓展(要求从200张图片随机选择图片,不满足者此实验不得分)

2.3.2在detect.py代码中插入movefile函数进行图片的选取

2.4 利用测试集进行代码模型的预测,完成detect.py
3.总结
总的来说,yolov5的基础并不难掌握,相关学习视频可以在b站找到。只是配置环境的步骤比较繁琐,我在文章中也没有一一列举出来,还要大家自行从csdn上面进行寻找。如果大家有需要,我可以将我b站学习yolov5的视频和csdn配置环境的文章推荐给大家。最后,希望我在比赛中的总结可以帮助大家。
版权归原作者 雯祈 所有, 如有侵权,请联系我们删除。