
ES数据存储
1、存储流程
为了将数据添加到Elasticsearch,我们需要索引(index)——一个存储关联数据的地方。实际上,索引 只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”.一个分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分。
当一个写请求发送到 es 后,es 将数据写入 memory buffer 中,并添加事务日志( translog )。如果每次一条数据写入内存后立即写到硬盘文件上,由于写入的数据肯定是离散的,因此写入硬盘的操 作也就是随机写入了。硬盘随机写入的效率相当低,会严重降低es的性能。
因此 es 在设计时在 memory buffer 和硬盘间加入了 Linux 的页面高速缓存( File system cache ) 来提高 es 的写效率。
当写请求发送到 es 后,es 将数据暂时写入 memory buffer 中,此时写入的数据还不能被查询到。默认设置下,es 每1秒钟将 memory buffer 中的数据 refresh 到 Linux 的 File system cache ,并清空 memory buffer ,此时写入的数据就可以被查询到了。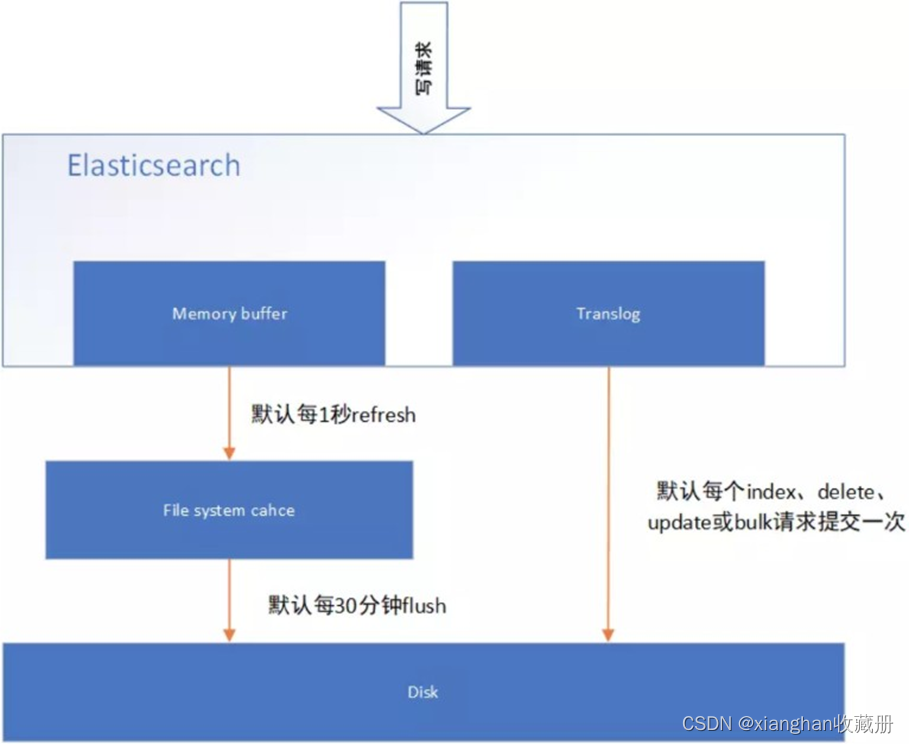
但 File system cache 依然是内存数据,一旦断电,则 File system cache 中的数据全部丢失。默认设置下,es 每30分钟调用 fsync 将 File system cache 中的数据 flush 到硬盘。因此需要通过translog 来保证即使因为断电 File system cache 数据丢失,es 重启后也能通过日志回放找回丢失的数据。
translog 默认设置下,每一个 index 、 delete 、 update 或 bulk 请求都会直接 fsync 写入硬盘。为了保证 translog 不丢失数据,在每一次请求之后执行 fsync 确实会带来一些性能问题。对于一些允许丢失几秒钟数据的场景下,可以通过设置 index.translog.durability 和index.translog.sync_interval 参数让 translog 每隔一段时间才调用 fsync 将事务日志数据写入硬盘。
2、动态更新索引
以在线动态服务的层面看,要做到实时更新条件下数据的可用和可靠,就需要在倒排索引的基础上,再 做一系列更高级的处理。
其实总结一下 Lucene 的处理办法,很简单,就是一句话:新收到的数据写到新的索引文件里。
Lucene 把每次生成的倒排索引,叫做一个段(segment)。然后另外使用一个 commit 文件,记录索引内所有的 segment。而生成 segment 的数据来源,则是内存中的 buffer。也就是说,动态更新过程如下:
- 当前索引有 3 个 segment 可用。索引状态如图 2-1;

图 2-1
- 新接收的数据进入内存 buffer。索引状态如图 2-2;

图 2-2
- 内存 buffer 刷到磁盘,生成一个新的 segment,commit 文件同步更新。索引状态如图 2-3。
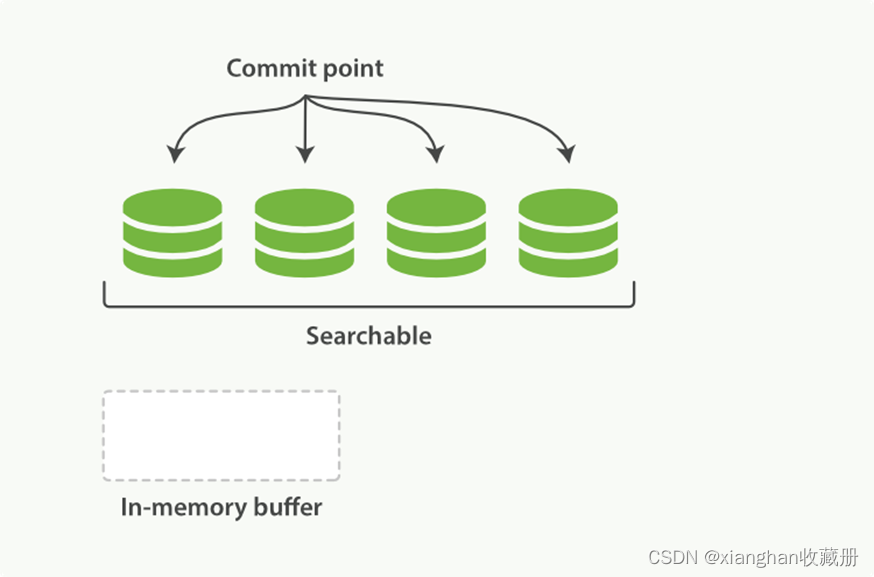
图 2-3
3、利用磁盘缓存实现的准实时检索
既然涉及到磁盘,那么一个不可避免的问题就来了:磁盘太慢了!对我们要求实时性很高的服务来说, 这种处理还不够。所以,在第 3 步的处理中,还有一个中间状态:
- 内存 buffer 生成一个新的 segment,刷到文件系统缓存中,Lucene 即可检索这个新 segment。索引状态如图 2-4。
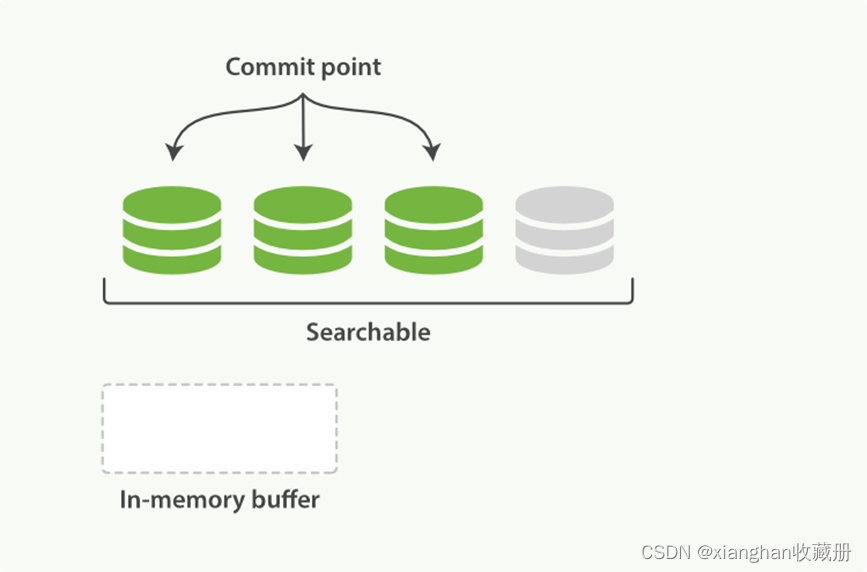
图 2-4
- 文件系统缓存真正同步到磁盘上,commit 文件更新。达到图 2-3 中的状态
这一步刷到文件系统缓存的步骤,在 Elasticsearch 中,是默认设置为 1 秒间隔的,对于大多数应用来
说,几乎就相当于是实时可搜索了。Elasticsearch 也提供了单独的
间隔还不满意的,可以主动调用该接口来保证搜索可见。
接口,用户如果对 1 秒
注:5.0 中还提供了一个新的请求参数: ?refresh=wait_for ,可以在写入数据后不强制刷新但一直等到刷新才返回。
不过对于 Elastic Stack 的日志场景来说,恰恰相反,我们并不需要如此高的实时性,而是需要更快的写入性能。所以,一般来说,我们反而会通过/_settings接口或者定制 template 的方式,加大参数:
curl -XPOST http://127.0.0.1:9200/logstash-2015.06.21/_settings -d'
{ "refresh_interval": "10s" }
如果是导入历史数据的场合,那甚至可以先完全关闭掉:
# curl -XPUT http://127.0.0.1:9200/logstash-2015.05.01 -d'
{
"settings" : { "refresh_interval": "-1"
}
}'
在导入完成以后,修改回来或者手动调用一次即可:
# curl -XPOST http://127.0.0.1:9200/logstash-2015.05.01/_refresh
4、translog 提供的磁盘同步控制
既然 refresh 只是写到文件系统缓存,那么第 4 步写到实际磁盘又是有什么来控制的?如果这期间发生主机错误、硬件故障等异常情况,数据会不会丢失?
这里,其实有另一个机制来控制。Elasticsearch 在把数据写入到内存 buffer 的同时,其实还另外记录了一个 translog 日志。也就是说,第 2 步并不是图 2-2 的状态,而是像图 2-5 这样: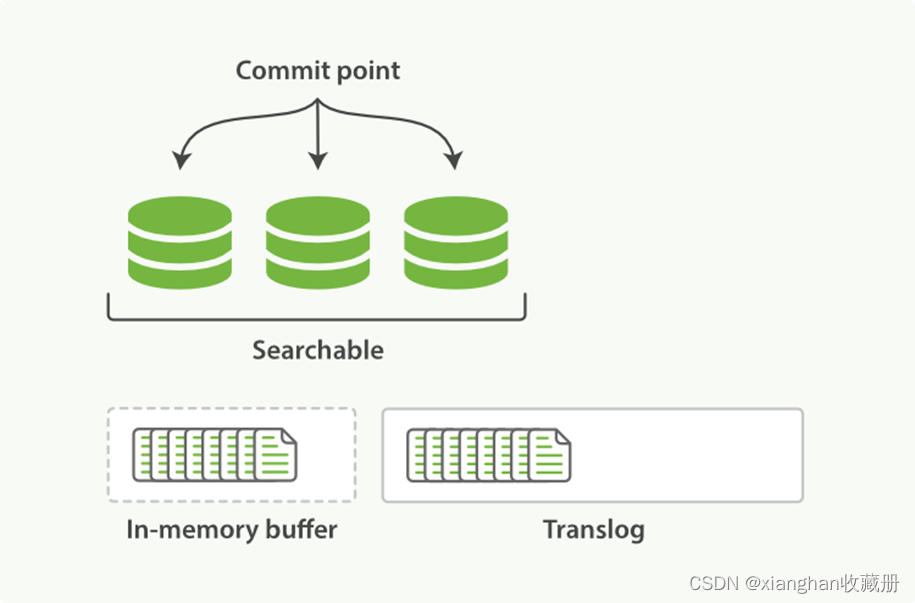
图 2-5
在第 3 和第 4 步,refresh 发生的时候,translog 日志文件依然保持原样,如图 2-6: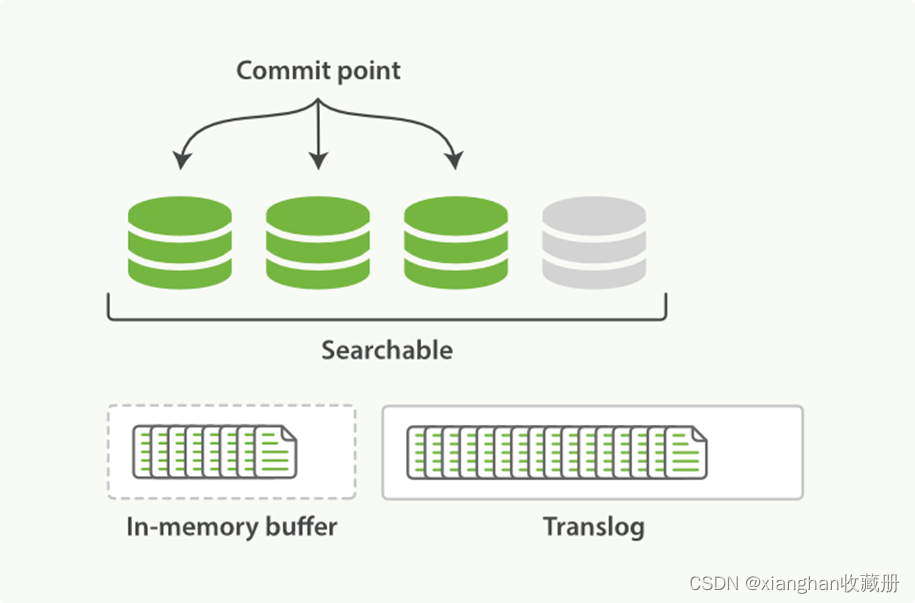
图 2-6
也就是说,如果在这期间发生异常,Elasticsearch 会从 commit 位置开始,恢复整个 translog 文件中的记录,保证数据一致性。
等到真正把 segment 刷到磁盘,且 commit 文件进行更新的时候, translog 文件才清空。这一步,叫做 flush。同样,Elasticsearch 也提供了 /_flush 接口
对于 flush 操作,Elasticsearch 默认设置为:每 30 分钟主动进行一次 flush,或者当 translog 文件大小大于 512MB (老版本是 200MB)时,主动进行一次 flush。这两个行为,可以分别通过
index.translog.flush_threshold_period
index.translog.flush_threshold_size
参数修改。
如果对这两种控制方式都不满意,Elasticsearch 还可以通过
index.translog.flush_threshold_ops
参数,控制每收到多少条数据后 flush 一次。
5、translog 的一致性
索引数据的一致性通过 translog 保证。那么 translog 文件自己呢?
默认情况下,Elasticsearch 每 5 秒,或每次请求操作结束前,会强制刷新 translog 日志到磁盘上。
后者是 Elasticsearch 2.0 新加入的特性。为了保证不丢数据,每次 index、bulk、delete、update 完成的时候,一定触发刷新 translog 到磁盘上,才给请求返回 200 OK。这个改变在提高数据安全性的同时当然也降低了一点性能。
如果你不在意这点可能性,还是希望性能优先,可以在 index template 里设置如下参数:
{
"index.translog.durability": "async"
}
五、集群路由
1、 文档路由
1)document路由到shard分片上,就叫做文档路由 ,如何路由? 2)路由算法
算法公式:shard = hash(routing)%number_of_primary_shards
例子:
一个索引index ,有3个primary shard : p0,p1,p2
增删改查 一个document文档时候,都会传递一个参数 routing number, 默认就是document文档 _id, (也可以手动指定)
Routing = _id,假设: _id = 1
算法:
Hash(1) = 21 % 3 = 0 表示 请求被 路由到 p0分片上面。
- 自定义路由请求:
PUT /index/item/id?routing = _id (默认)
PUT /index/item/id?routing = user_id(自定义路由)--- 指定把某些值固定路由到某个分片上面。
- primary shard不可变原因
即使加服务器也不能改变主分片的数量
2、增删改原理
- 客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
- coordinating node,对document进行路由,将请求转发给对应的node(有primary shard)
- 实际的node上的primary shard处理请求,然后将数据同步到replica node
- coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端
所有文章都是以专栏系列编写,建议系统性学习,更容易成为架构师!
博主每天早晚坚持写博客给与读者价值提升,为了让更多人受益,请多多关照,如果觉得文章质量有帮助到你,请关注我的博客,收藏此文,持续提升,奥利给!
另外我不打算靠运营方式拿到博客专家的认证,纯纯的科技与狠活来征服读者,就看读者的感恩之心了,祝你好运连连。
版权归原作者 xianghan收藏册 所有, 如有侵权,请联系我们删除。