
1.网络
1.0 令牌环网(了解)
相同令牌时,才能放,相当于局域网中的锁

令牌环网和以太网都属于数字链路层,但是底层协议是不一样的
因为网络是层状结构的,所以替换底层协议,不影响传输
1.1 IP 地址
我怎么知道是要跨网络交给主机的呢?
IP 地址可以保证主机在全网的唯一性,例如:我们云服务器的连接 IP 就是唯一的
两个小故事:
- 从辽宁到云南,沿路旅游的路线如何设计
- 从哪来,到哪去--一直是不变的--IP 地址--指导我们进行路径规划
- 上一站从哪里来,下一站到哪里去--会一直变化,变化的依据是“我要去哪里”--Mac 地址

相当于 IP 是大目标,Mac 是小目标
IP 地址是什么?
IPv4,四字节,32 比特位,整数
192.168.1.1 类似风格
IP 地址为什么要交给路由器?
路由器会重新解包,和封装 数据链层协议,实现了不同区域网之间的通信,解决了底层协议的差异化
同一子网,没有路由器的话,就会底层协议需要一样

- IP 及上层是一样的,IP 协议屏蔽了底层网络的差异,靠的就是工作在 IP 层的路由器
- IP 实现了全球主机的软件虚拟层,一切皆是 IP 报文!
- 也体现了网络层状结构的优越性

Mac 地址 vs IP 地址
IP 地址,尤其是目的 IP,一般都是不会改变的,协助我们进行路径选择
max 地址,出局域网之后,源和目的都要被丢弃,每经过一个设备都要变化,让路由器重新封装
1.3 网络通信的基本脉络
示意图

路由器,可以根据 IP 地址判断目的地在哪个局域网内,IP 地址的设计非常的巧妙,它在网络层,会根据目的地,进行路径选择时选择了下一个跳转的路由器。
ifconfig --查看当前云服务器的MAC地址,IP地址

IP地址
IP协议有两个版本, IPv4和IPv6
IPv4地址解释
IPv4地址是一个4字节(即32位)的整数,它可以被看作是一个无符号整数(
unsigned int
)。这意味着它可以表示从0到 (2^{32} - 1) 之间的任何整数值,即从0到4,294,967,295(约42亿)。
四字节和32位的关系
- 4字节:在计算机中,一个字节(Byte)等于8位(bits),所以4字节就是 (4 \times 8 = 32) 位。
- 32位:指的是IPv4地址的总长度,由32个二进制位组成。
点分十进制表示法
- 点分十进制是一种常用的表示IPv4地址的方法,它将32位的二进制数分成四个8位的部分,每部分转换成十进制数,并用点(
.)分隔开。例如,IPv4地址192.168.0.1就是点分十进制格式。
每个数字的取值范围
- 在点分十进制表示法中,每个数字代表一个字节(8位),因此它们的取值范围是从0到255。这是因为8位二进制数的最大值为 (2^8 - 1 = 255)。
- 最小值:0,对应于8位全0,即
00000000。 - 最大值:255,对应于8位全1,即
11111111。
示例
- 以
192.168.0.1为例: - 第一部分
192对应于二进制11000000 - 第二部分
168对应于二进制10101000 - 第三部分
0对应于二进制00000000 - 第四部分
1对应于二进制00000001 - 合并起来就是
11000000 10101000 00000000 00000001,去掉空格后就是32位的二进制数11000000101010000000000000000001。
总结
- IPv4地址是一个32位的无符号整数,通常以点分十进制的形式表示,每个部分都是一个8位的二进制数,取值范围是0到255。这种表示方法使得IPv4地址更加易于阅读和记忆。
- IPv6,IP地址是一个16个字符,128位比特位的整数。防止 IPv4 不够用
要想普及一项技术,需要孵化出一个更大的运用场景,例如物联网使用 IPv6 的话...现在国家规定,公司要兼容 IPv6
MAC地址
- 长度为48位, 及6个字节. 一般用16进制数字加上冒号的形式来表示(例如: 08:00:27:03:fb:19)
- 在网卡出厂时就确定了, 不能修改. mac地址通常是唯一的
MAC地址通常在局域网中使用,IP地址在广域网和局域网都使用,不过我们不谈IP在局域网的使用。
在进行网络通信的时候,是不是我们的两台机器在进行通信呢?
- 网络协议中的下三层,主要解决的是,数据安全可靠的送到远端机器
- 用户使用应用层软件,完成数据发送和接收的
先把这个软件启动起来-->进程
日常网络通信的本质:就是进程间通信!!(从应用层上看,不用看网络栈的底层传输)
要进程间通信,就要先把进程标识出来
2.Socket 编程预备
2.1 端口号
定义:
- 端口号是传输层协议的一部分。
特点:
- 端口号是一个 2 字节(16 位)的整数。
- 用于标识一个进程,告诉操作系统当前的数据应交给哪个进程处理。
- IP 地址加上端口号可以唯一标识网络上某台主机的某个进程。
- 一个端口号只能被一个进程占用。

端口号 port: 无论对于 client 和 server,都能唯一的标识该主机上的一个网络应用层的进程
在公网上:
- IP 地址能标识唯一的一台主机,端口号,能表示主机上唯一的一个进程
- IP:port == 标识全网唯一的一个进程
这种** IP+port 的模式**,就叫做 **socket **(插口,插座),实现了客户端和服务器的唯二进程进行通信
例如:10086 是一个 IP,工号 12345 的员工就是 port 端口号
⭕** 端口号 vs pid**
pid 已经能标识一台主机上的进程唯一性了,为什么还要搞一个端口号??
- 不是所有的进程都要网络通信,但是所有进程都要有 pid
- 为什么不直接用 Pid 做端口?将系统和网络部分解耦合,给网络部分设计了单独的规则,防止系统修改进程 pid 造成混乱
就像一个人有身份证号还有工号,不能用工号代替身份证号,是不同场景下的,如果这样那你从公司离职了呢~
下三层通信示意图
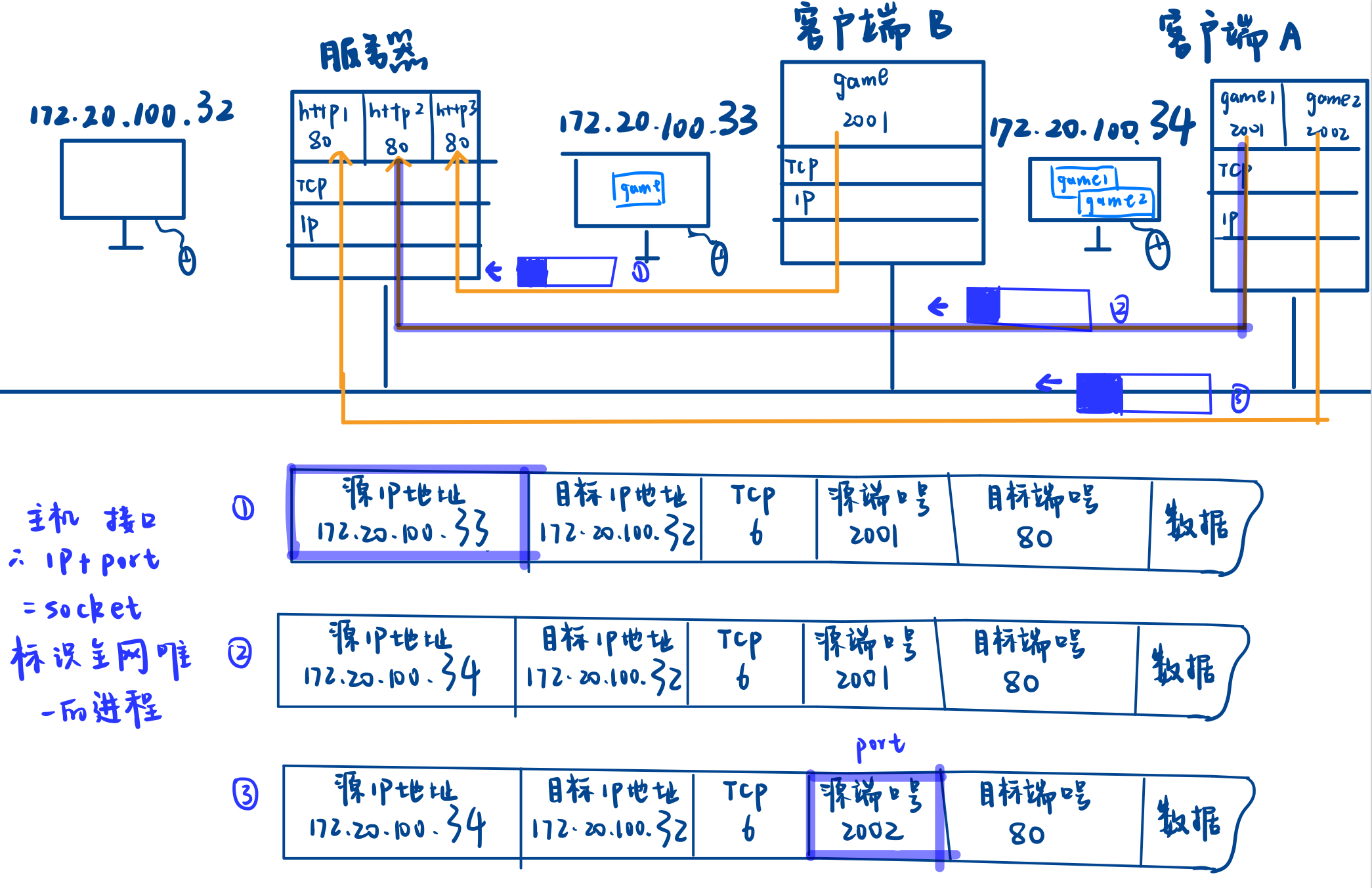
我们的客户端,如何知道服务器的端口号是多少?
每一个服务的端口号必须是众所周知的,精心设计,被客户端知晓的
- 一个进程可以绑定多个端口号吗?可以
- 一个端口号可以绑定多个进程吗?不可以
2.2 传输层协议

这张图是一个计算机网络协议栈的示意图,展示了数据在网络中传输时经过的不同层次以及每个层次的数据格式。根据图中的标注,我们可以对以下三个概念进行解释:
- 数据段(Data Segment): 数据段是在传输层(Transport Layer)处理的数据单元,通常用于描述TCP或UDP等传输协议封装的信息。在图中,“你好”这个字符串是应用层数据,在传输层会被封装成一个数据段,并添加上相应的头部信息,如序列号、确认号、源端口/目的端口等。
- 数据报(Datagram): 数据报是在网络层(Network Layer)处理的数据单元,通常用于描述IP协议封装的信息。在图中,数据段经过网络层后会变成一个数据报,它包含了原始数据段以及其他必要的头部信息,例如源IP地址、目的IP地址、TTL(Time To Live)、协议类型等。
- 数据帧(Data Frame): 数据帧是在链路层(Link Layer)处理的数据单元,通常用于描述以太网驱动程序封装的信息。在图中,数据报经过链路层后会变成一个数据帧,它包含了原始数据报以及其他必要的头部信息,例如MAC地址(源MAC地址、目的MAC地址)、FCS(Frame Check Sequence)等。
总结来说,数据段是传输层的概念,数据报是网络层的概念,而数据帧则是链路层的概念。这些不同层次的数据单元在计算机网络中起着不同的作用,它们通过层层封装和解封装来实现数据的有效传输。
TCP协议:
- TCP协议叫做传输控制协议(Transmission Control Protocol),TCP协议是一种面向连接的、可靠的、基于字节流的传输层通信协议
- TCP协议是面向连接的,如果两台主机之间想要进行数据传输,那么必须要先建立连接,当连接建立成功后才能进行数据传输。其次,TCP协议是保证可靠的协议(也意味着要做更多的事情),数据在传输过程中如果出现了丢包、乱序等情况,TCP协议都有对应的解决方法
UDP协议:
- UDP协议叫做用户数据报协议(User Datagram Protocol),UDP协议是一种无需建立连接的、不可靠的、面向数据报的传输层通信协议
- 使用UDP协议进行通信时无需建立连接,如果两台主机之间想要进行数据传输,那么直接将数据发送给对端主机就行了,但这也就意味着UDP协议是不可靠的,数据在传输过程中如果出现了丢包、乱序等情况,UDP协议本身是不知道的。
- 就像发邮件一样,邮件发出去了并不管
⭕ 传输层同时存在 **tcp 和 udp **是为什么呢?
TCP协议和UDP协议不存在哪个更好的说法?
- 可靠和不可靠都是中性词,就像化学中的惰性一样
- TCP可靠 意味着 在设计和维护上更复杂,不可靠就会相对做的事少一些更简单
- 所以这两个协议在各自特定的场景下,发光发热
TCP:银行,支付...(在网络联通的情况下,丢包可找回)
UDP:信息派发,例如直播...
2.3 网络字节序列
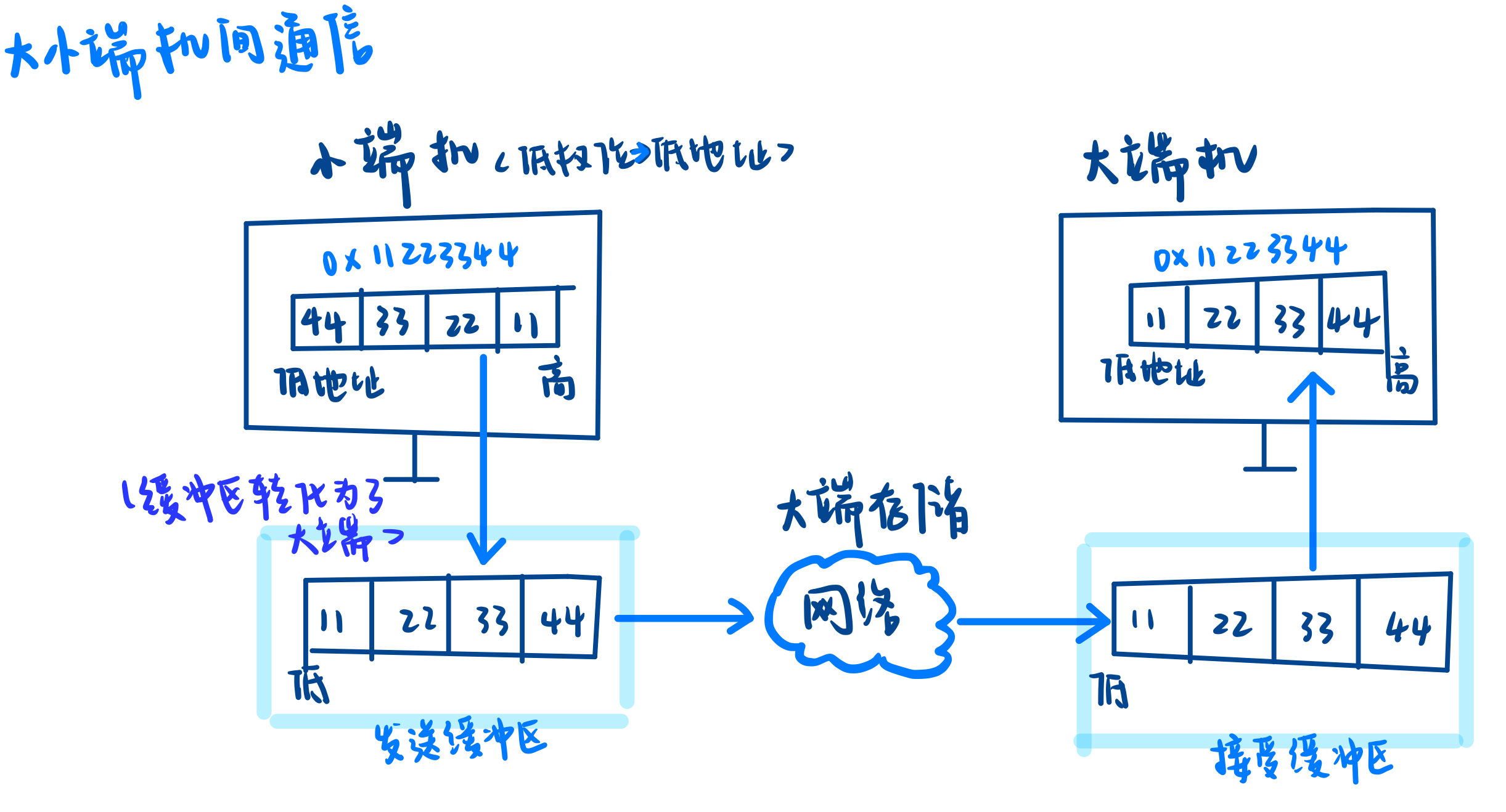
大小端:没有好坏之分,就是一种不同的选择(来源于格列夫游记里面对吃鸡蛋先吃大小端的辩论)
定义:****小端:低权值位放在低地址处(小小小)。大端反之
文件中的偏移地址也有大端小端之分, 网络数据流同样有大端小端之分. 那么如何定义网络数据流的地址呢?
网络数据传输中的大小端问题
由于我们不能保证通信双方存储数据的方式是一样的,因此网络中传输的数据必须考虑大小端问题。
TCP/IP 协议规定如下:
- 网络数据流采用大端字节序,即低地址存放高字节。
无论主机是大端机还是小端机,都必须按照 TCP/IP 协议规定的网络字节序来发送和接收数据:
发送端:
- 如果发送端是小端机,需要先将数据转换成大端字节序,然后再发送到网络中。- 如果发送端是大端机,则可以直接发送数据。
接收端:
- 如果接收端是小端机,需要先将接收到的数据转换成小端字节序,然后再进行数据识别。- 如果接收端是大端机,则可以直接进行数据识别。
sum: 大端直接发,小端缓冲区转化为大端后发送
注意事项
- 发送主机通常将发送缓冲区中的数据按内存地址从低到高的顺序发出。
- 接收主机把从网络上接收到的字节依次保存在接收缓冲区中,同样按内存地址从低到高的顺序保存。
- 因此,网络数据流的地址应规定为:先发出的数据是低地址,后发出的数据是高地址。
网络字节序与主机字节序之间的转换
为使网络程序具有可移植性,使同样的 C 代码在大端和小端计算机上编译后都能正常运行,系统提供了四个函数,可以通过调用以下库函数实现网络字节序和主机字节序之间的转换。
这些函数名很好记:
h表示主机(host)n表示网络(network)l表示 32 位长整数s表示 16 位短整数
例如,
htonl
表示将 32 位的长整数从主机字节序转换为网络字节序,例如将 IP 地址转换后准备发送。
如果主机是小端字节序,这些函数将参数做相应的大小端转换然后返回;如果主机是大端字节序,这些函数不做转换,将参数原封不动地返回。
库函数定义
#include <arpa/inet.h>
// 主机字节序转换为网络字节序
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
// 网络字节序转换为主机字节序
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
函数说明
- htonl:将 32 位的长整数从主机字节序转换为网络字节序。
- htons:将 16 位的短整数从主机字节序转换为网络字节序。
- ntohl:将 32 位的长整数从网络字节序转换为主机字节序。
- ntohs:将 16 位的短整数从网络字节序转换为主机字节序。
下篇文章将对 socker 接口开始讲解啦~
版权归原作者 lvy- 所有, 如有侵权,请联系我们删除。