
随着信息技术的飞速发展,系统的业务功能不断扩大,产生的日志与日俱增,导致应用软件的运行速度越来越慢,不能很好地满足用户对软件性能的需求。基于此,重点研究了 MySQL 分区技术在大数据量软件日志中的应用,通过 MySQL 数据库的分区技术提升数据库的性能,从而保障软件的稳定运行,为大数据量的系统提供优质服务。
1 概述
在数字经济时代, 随着信息技术的不断发展, 许多企业每个月都产生巨大的日志, 短时间内海量日志查询面临着极大的挑战。 因为传统的 MySQL 数据库存储技术处理大数据量的能力不足,MySQL 数据库表是以文件方式存储到磁盘中, 对于大数据量的情况通过索引的存储结构搜索数据, 显然非常耗时。 如果想搜索和实时分析日志,传统的 MySQL 单表单区的方式无法在一个合理的响应时间内处理大量的数据, 因此 MySQL 分区技术应运而生。
2 MySQL 分区技术
MySQL 分区是使用 MyISAM 引擎的一张表主要对应 3 个文件:
( 1 ) frm 存放表结构;
( 2 ) myd 存放表数据;
( 3 ) myi 存表索引。
如果一张表的数据量太大,那么 myd 、 myi 也会变得很大, 查找数据就会变得很慢。这时可以利用 MySQL 的分区功能, 在物理上将这一张表对应的 3 个文件, 分割成许多个小块, 这样在查找一条数据时, 就不用全部查找了, 只要知道这条数据在哪一块, 然后在对应位置查找。 如果表的数据太大, 可能一个磁盘放不下, 就可以把数据分配到不同的磁盘里。 数据库分区技术就是把一张表的数据分成 N 多个区块, 这些区块可以在同一个磁盘上, 也可以在不同的磁盘上。
通俗地讲, 表分区是将一张大表, 根据条件分割成若干张小表。 假设某日志表的记录超过了 700 万条, 为了更好地体现分区的优势, 在进行表分区时, 可以优先选择日志表的一些特性作为分区的条件, 例如, 记录时间、 日志类型等。 分区类别主要有 RANGE 分区、 LIST分区、 HASH 分区、 KEY 分区、 子分区。 在此主要探讨RANGE 分区在海量日志中的研究与应用。
在某物联网软件运行过程中, 需要每隔 20 min 或30 min 检测终端设备是否通联, 每检测一个终端设备需要记录下该设备的运行状态、 设备 IP 、 Mac 等信息。 在上百个设备中, 平均每天能产生上千条设备运行日志, 一个月便能产生数万条日志。 用户需要每天不定时查看这些运行日志, 以便观测设备的运行状态。 用户可以通过日期条件查询每天设备运行状态并以表格的形式显示出来。
3 设计方案与实现
为了更直观地展示此次需求改造方案, 利用 Visio工具, 制作改造方案, 如图 1 所示。 主要对设备日志表进行优化和改造, 针对设备日志表, 按照提前约定的分区规则, 利用 MySQL 数据库分区技术对表中的数据进行分区存储, 使其存储到不同的分区文件中。 对于与设备日志记录表有关联的功能模块, 采用数据层面的优化方式, 减少从数据量较大的表中查询数据的次数。

3.1 数据库结构改造
通过观察, 分析设备日志记录表的数据可知, 从2020 年系统部署使用以来, 数据量与日俱增, 总计 50多万条, 相当于每天产生 600 多条数据, 平均每月的数据量 2 万条左右。 针对这种情况, 为了不增加维护成本, 采用对数据表进行分区处理的方式, 并按照数据量级进行分割数据。 当数据量规模较小时, 以 5 万为单位级进行数据分割; 当数据量规模较大时, 以 10 万为单位级进行数据分割。
分区表具有较强的可维护性, 在面对数以万计的数据时, 能够非常容易地将分区合并、 新增和删除, 使数据更容易被管理和维护。 在数据查询方面, 能够加快数据的查询速度、 提高查询的效率, 但分区技术不能够提高全表检索的速度, 只能通过条件查询来加快查询的速度。
设备日志记录表 ( device_record_log ) 的字段设计包含自增主键字段 ( device_id )、 设备名称 ( device_ti-tle )、 设备类别 ( device_type )、 设备序号 ( device_in-dex )、 设备型号( device_model )、 设备 ( sn )、 设备 Mac( device_mac )、 设备网址 ( device_ip )、 子网掩码 ( de-vice_netmask )、 设备网关 ( device_gateway )、 设备检测日期 (device_checkin_date )、 检测类型 ( checkin_type )、故障类型 ( error_type )、 故障备注 ( error_remark )、 备注 ( error_remark1 )。
采用水平分区的方式对设备日志记录表进行优化。
首先, 查询 device_id 的最大值, 计算需要分区的最小数量;
然后, 调整单表结构, 将单表文件拆分成多份文件, 成为分区表, 使得一张单表具有多张表的存储功能, 在应对存储大数据量时, 不致于让单表的压力过大, 数据的查询和存储效率明显提高。
详细步骤如下:
打开命令框, 登录 MySQL , 打开指定数据库, 输入以下 SQL 语句, 使 device_record_log 表具有分区结构:
alter table device_error_log partition by RANGE(device_id)
(PARTITION PART01 values less than (50000)
PARTITION PART02 values less than(100000)
PARTITION PART03 VALUES less than( 200000)
PARTITION PART04 VALUES less than(300000)
PARTITION PART05 VALUES less than(400000)
PARTITION PART06 VALUES less than(500000)
PARTITION PART07 VALUES less than( 600000)
PARTITION PART08 VALUES less than( 700000)
PARTITION PART09 VALUES less than(800000)
PARTITION PART10 VALUES less than(900000));
device_record_log 表中的数据是 device_id 小于 5 万的数据, 全部分割到 P1 这个分区中; 大于 5 万并小于10 万的数据存储到 P2 这个分区中; 大于 10 万并小于20 万的数据存储到 P3 这个分区中; 大于 20 万并小于30 万的数据存储到 P4 这个分区中。 以此类推, 将原有单表的数据分别存储到对应的分区中, 将原有的单表对应单文件存储模式, 改为单表多文件存储模式, 在大规模数据下, 减轻单文件存储的压力。 在指定条件下的查询, 数据库分区搜索引擎会根据索引在相应的表分区中搜索。 例如, 需要查询的是某月的数据, MySQL 数据库会先通过分区层打开并锁住所有的底层表, 优化器先判断是否可以过滤部分分区, 如果可以, 则调用对应的存储引擎接口访问对应分区的数据; 否则, 异步读取各分区的数据。 由于分区数据量远小于只有单表存储的数据量, 相当于小文件操作, 从而极大提高了读取效率,节省了查询时间, 加快了数据库的响应速度, 实现了数据查询速度的优化。
3.2 功能模块改造
海量日志查询是一个非常耗性能的过程, 对数据库的性能要求非常高。 如果能够在结合 MySQL 数据库分区技术的基础上, 合理地改造查询功能, 使其不要在非必要的时候进行全表、 全区数据扫描, 就能够加快查询的速度, 实现对系统功能的优化。
假如需要得到最近一个月的日志数据, 以每月 2 万多条数据计算, 一个分区至少存储 5 万条, 一个月的数据在同一个分区中, 这样查询数据不用跨区扫描, 节省时间; 假如需要查询近一年的日志数据量, 此时日志数据已经存储在不同分区中, 跨区扫描的时间将比在同一个分区的时间长很多, 需要将查询功能优化处理, 利用单分区查询的优势, 按照分区段的限制, 先查询一个分区内的数据, 再根据条件查询另一个分区内的数据, 最后分页展示给用户, 达到快速显示的效果, 提高系统的性能。 示例 SQL 语句如下:
SELECT a.* FROM device_error_log a wherea.id < 50000
SELECT b.* FROM device_error_log b whereb.id > 50000 and b.id < 100000
SELECT c.* FROM device_error_log c wherec.id > 100000 and b.id < 200000
SELECT d.* FROM device_error_log d whered.id > 500000 and b.id < 600000
4 实验及结果分析
4.1 实验环境
硬件环境: 实验均在笔记本电脑上进行、 Windows 1164 位操作系统、 Intel (R) Core (TM) i7-10875H 处理器、 16G 内存、 500G 硬盘。
软件环境: 实验选用 MySQL5.6 版本。
4.2 实验结果及对比分析
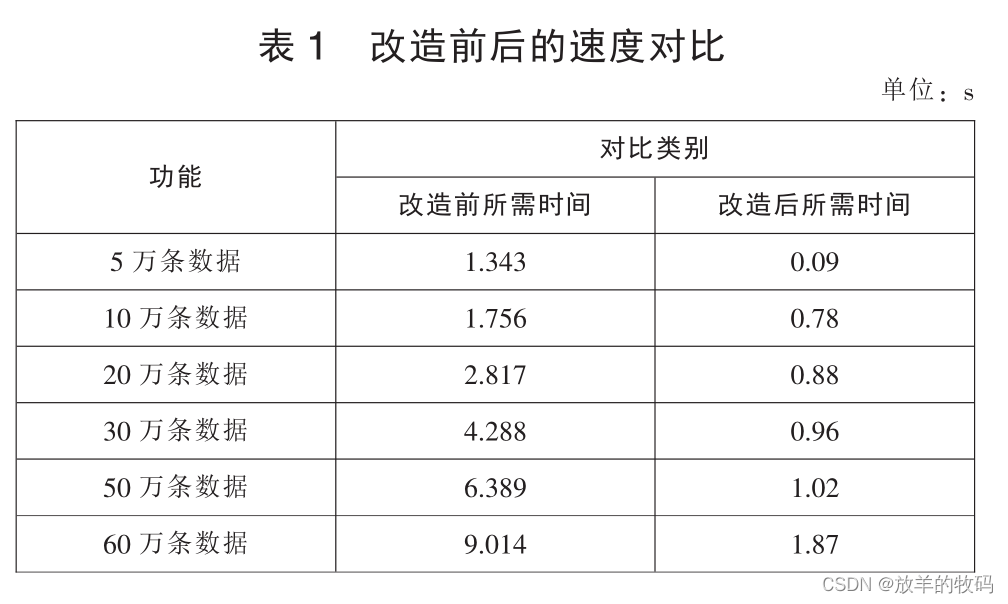
在相同的实验环境下, 针对同一张表, 模拟不同数量级数据, 将具有表分区功能的表和原生表做对比实验。 在同样的联合多张表 SQL 语句下, 分两种情况测试数据查询的效率: 一种具有表分区; 另一种不具有表分区。 从表 1 中可以看出随着数据量不断增大, 改造前与改造后所需时间差距明显拉大, 改造后所需时间比改造前缩短很多, 查询效率明显提高。
5 结语
MySQL 分区技术将数据库的优势引入处理海量日志数据的项目中, 降低了系统项目使用后期更换数据库的风险, 满足了企业对系统开发的需求, 减少了系统维护的成本, 延长了系统项目的使用寿命。 从 MySQL 分区技术的概念理论入手, 概述了数据库分区技术的使用场景, 深入讲解了 MySQL 分区的分类及分区的使用方法, 通过实验数据验证数据库分区技术的可行性和优越性。测试结果显示, 将 MySQL 数据库分区技术应用到海量日志的系统项目中, 成功解决了企业系统应对海量数据时存在的性能问题, 达到了预期的效果。
版权归原作者 放羊的牧码 所有, 如有侵权,请联系我们删除。