
文章目录
MapReduce 核心思想
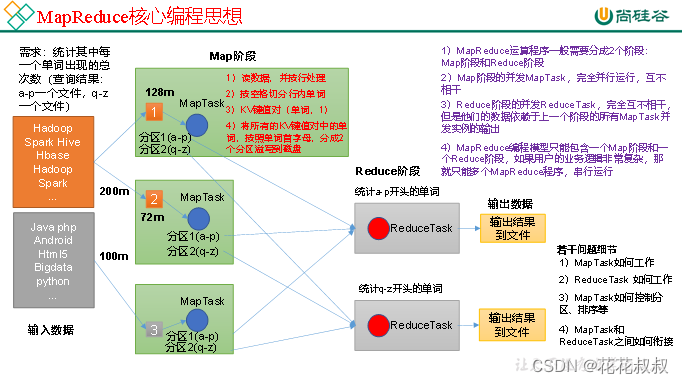
MapReduce分为Map阶段和Reduce阶段。
Map阶段:前两个MapTask对黄色的区域进行统计,最后一个MapTask对灰色区域进行统计,Map阶段先将数据读到内存,之后对数据进行处理,按照空格将单词且分为一个一个的单词,KV键值第一个是单词,第二个是1,因为每一个单词被统计时候,就是相当于出现过一次,然后对所有的KV键值对,按照单词的首字母进行分区处理,分为两个区,分完区之后,将所有的分区数据溢写到磁盘中。
分区的时候,每一个MapTask都会有自己独有的分区溢写到磁盘。
Reduce阶段:ReduceTask主动从溢写的磁盘中拉去数据到内存,对分区中的数据进行逻辑操作,比如说单词的累加计数等等,也可以是减法或者是乘法。
其实在进入Reduce之前,是有一个操作,可以让两个相同的数据,比如说 atguigu,1 atguigu , 1 这两键值对合写成为<atguigu , (1,1)> Reduce阶段只要关心逻辑操作就可以了。
MapReduce工作流程
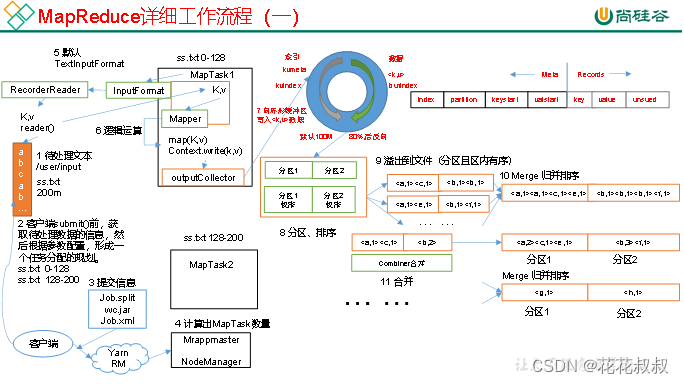
待处理文本是一堆单词,客户端形成切片,然后将切片提交给Yarn,此时Yarn通过切片数目分配MapTask数量,当分配了足够的MapTask之后,会从文本中读取一定的数据,形成KV键值对,之后分区,分区之后溢出到磁盘中。
Reduce会从磁盘中将数据拉取到,进行一系列操作,最后输出结果。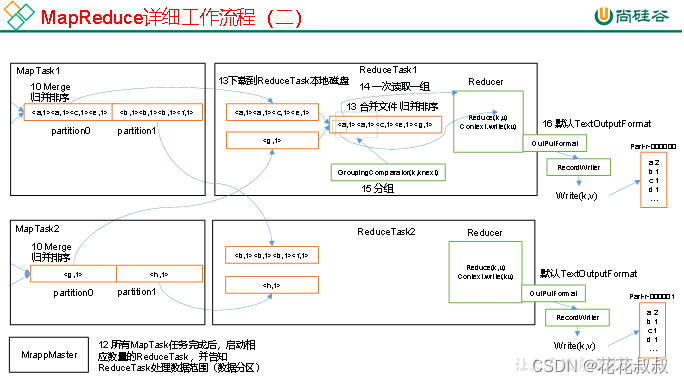
本文转载自: https://blog.csdn.net/qq_52077949/article/details/124994735
版权归原作者 花花叔叔 所有, 如有侵权,请联系我们删除。
版权归原作者 花花叔叔 所有, 如有侵权,请联系我们删除。