
文章目录
前言
之前因项目需求,自己学习并写了一个python接口自动化的小框架,基于python+requests+pytest+allure,支持Excel、yaml用例数据存储并参数化,生成领导都喜欢的allure报告。博主的代码功底不咋样,望大佬们多指点指点。后面会分不同的章节一一讲解,希望能对你有所帮助。
一、框架目录介绍
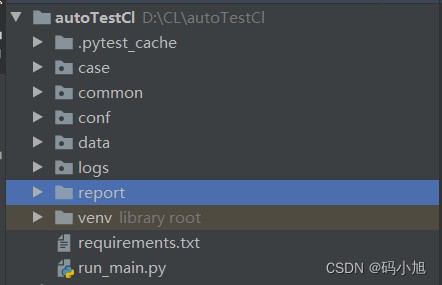
case:用例存放目录
common:存放公共方法目录
conf:存放配置文件目录
data:存放测试数据目录
logs :存放日志目录
report:存放报告目录
run_main.py:用例总执行入口
如上所示,框架的整体目录结构还是分工明确的,封装的方法并不适用每个项目,需要根据自己所在的项目改动,那么下面将每个模块的代码及功能展示。
1、common模块
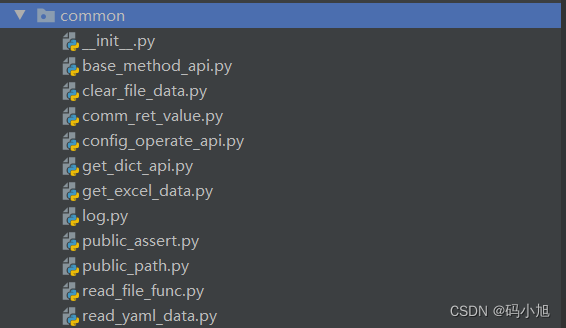
该模块主要存放公共方法,如读取Excel、yaml用例数据,jsonpath断言、日志、configparser读取配置文件、requests二次封装等。根据自己项目所需,封装适合自己的方法,方便后续操作。
读取Excel代码
# coding=utf-8# @Time : 2022/3/11 9:27# @Author : 梗小旭# @File : get_excel_data.pyimport os
from openpyxl import load_workbook
from common.public_path import DIR
from common.config_operate_api import Config
classGetExcelData():"""
封装读取Excel数据
"""def__init__(self,sheet):
self.path=eval(Config().getconf("excel_path").path)#excel文件路径
self.excel_path=os.path.join(DIR,self.path)
self.wb = load_workbook(self.excel_path)
self.ws = self.wb[sheet]
self.max_columns = self.ws.max_column #最大列数
self.max_rows=self.ws.max_row #最大行数defget_row_case_list(self,row=None):"""
按行获取Excel中的用例数据,返回list,如果row=None时,返回整个sheet页所有数据(除表头),
如果row为具体数字时,读取sheet对应的行数数据
:param row: 行数,第一行数据为title,默认已把值加1
:return:
"""
case_list =[]#返回的所有case数据#当row为None返回当前sheet页中所有用例数据if row==None:for i inrange(self.max_rows):
temp_case_list=[]for each in self.ws.iter_cols(min_col=0):
temp_case_list.append(each[i].value)#openpy的iter_cols用法会读取所有行包含空行(做了格式其他的改变,也会读取),加判断去除空行if temp_case_list[0]!=Noneand temp_case_list[:-1]!=None:
case_list.append(temp_case_list)#去除表头数据del case_list[0]return case_list
else:for i inrange(1,self.max_columns+1):
value=self.ws.cell(row=row+1,column=i).value
case_list.append(value)return case_list
defget_row_case_dict(self,row=None):"""
按行获取Excel中的用例数据,如果row=None时,返回的数据是全部用例数据,格式为list中存在多个dict
如果row等于具体数字时,读取对应行的数据
:param row: 行数
:return:
"""
case_title_list=self.get_row_case_list(row=0)#获取sheet页第一行,即titleif row==None:
all_case_dict_list=[]#存每个用例的dict格式的list
all_case_list = self.get_row_case_list()forcasein all_case_list:
temp_case_dict=dict(zip(case_title_list,case))
all_case_dict_list.append(temp_case_dict)return all_case_dict_list
else:
case_list=self.get_row_case_list(row=row)#通过title和一行的数据使用zip合并成字典
case_dict=dict(zip(case_title_list,case_list))return case_dict
defget_case_data(self,row=None):"""
按行获取Excel中用例数据,并把数据中提取url、data、expected_result值,
返回tuple,其中从Excel中读取的键值对数据需要用eval格式转成字典格式
row==None时返回全部用例数据
:param row: 行数
:return:
"""if row==None:
all_case_list =[]#list存多个tuple,每个tuple中有url,data,expected_result
all_case_dict_list = self.get_row_case_dict()for temp_case_dict in all_case_dict_list:
temp_list=[]
temp_list.append(temp_case_dict["url"])
data = temp_case_dict["data"]
temp_list.append(eval(data))
temp_list.append(temp_case_dict["expected_result"])
all_case_list.append(tuple(temp_list))return all_case_list
else:
case_dict=self.get_row_case_dict(row=row)
new_case_list=[]
new_case_list.append(case_dict["url"])
data=case_dict["data"]
new_case_list.append(eval(data))
new_case_list.append(case_dict["expected_result"])returntuple(new_case_list)
读取yaml代码(支持场景关联)
# coding=utf-8# @Time : 2022/3/16 14:58# @Author : 梗小旭# @File : read_yaml_data.pyimport os
import yaml
from common.public_path import DIR
from common.read_file_func import execute_func
from common.get_dict_api import update_dict_val,add_params
classReadYamlData():def__init__(self,filename):
self.path=os.path.join(DIR,f"data/{filename}.yaml")defread_yaml_case(self):"""
读取yaml文件中数据并返回
:return:
"""withopen(self.path,"r",encoding="utf-8")as f:
data=f.read()
result=yaml.load(data,Loader=yaml.FullLoader)return result
defyaml_to_list(self,n=None):"""
把读取yaml的数据转成list中多个tuple,每个tuple放url,data,expected_result,参数化使用
当yaml文件中存在rules规则时,表明该条用例存在接受其他接口传参,读取rules下的规则数据,如下:
position:想要修改数据字典中的key的路径,例如["department","id"],配置文件中写department.id,通过split分解
method:需要调用的函数名称
module:需要调用的函数所在模块及文件路径,例如:interface_data.jiekou,interface_data模块名,jiekou文件名称
params:调用函数所需要的传参,不需要传参时,默认写[]
:param n 对应第几条用例,n为None时,返回全部用例
:return:
"""
result=self.read_yaml_case()
all_case_list=[]for temp_case in result:
case_list=[]#判断读取的数据中是否存在rules规则if"rules"in temp_case:
data = temp_case['data']for rules in temp_case["rules"]:
position=rules["position"].split('.')
func_name=rules["method"]
module_name=rules["module"]
params=rules["params"]#读取配置文件中的函数,并执行函数返回值
result=execute_func(func_name=func_name, module_name=module_name,params=params)#更新data值
update_dict_val(data,position,val=result)#把数据加到all_case_list中
case_list.append(temp_case["url"])
case_list.append(data)
case_list.append(temp_case["expected_result"])
all_case_list.append(tuple(case_list))else:
case_list.append(temp_case["url"])
case_list.append(temp_case["data"])
case_list.append(temp_case["expected_result"])
all_case_list.append(tuple(case_list))#判断n的值,为None时,返回所有的值,n为具体数字时,返回某个案例if n==None:return all_case_list
else:return all_case_list[n-1]
jsonpath断言封装代码
# coding=utf-8# @Time : 2022/3/17 21:23# @Author : 梗小旭# @File : public_assert.pyimport jsonpath
defassert_res(res,expected_result):"""
传入响应体的json格式数据和Excel或yaml中读取的预期结果值,预期结果逐一判断,有一个不符合则返回False
:param res: 请求返回的响应体数据
:param expected_result: 预期结果值,例如:'$.code=201;$.success=False;$.message=用户名或密码错误'
注意:字符串里面不能写引号,比如不能$.message=“用户名或密码错误”,正确写法是:$.message=用户名或密码错误
:return:
"""for exp in expected_result.split(";"):
rule=exp.split("=")[0]#jsonpath提取规则
exp_value=exp.split("=")[1]#预期结果值
reality_value=jsonpath.jsonpath(res,rule)[0]#真实返回值#预期结果中存在特殊False和True,读取时要用eval把str类型转成bool,才能和返回值对比判断if exp_value=='False'or exp_value=='True':
exp_value=eval(exp_value)ifstr(exp_value)==str(reality_value):continueelse:returnFalsereturnTrue
requests二次封装(get、post)
# coding=utf-8# @Time : 2022/3/10 15:52# @Author : 梗小旭# @File : base_method_api.pyfrom common.log import log
import requests
import traceback
from common.config_operate_api import Config
classBaseMethodApi():def__init__(self):
self.conf = Config().getconf("enviro")
self.host=self.conf.host
self.url=self.conf.url
self.data=self.conf.data
defget_token_data(self):"""
获取当前环境下的token值
:return: 返回登录成功的token值
"""
complete_ulr ="http://"+ self.host + self.url # 完整url
res=requests.post(url=complete_ulr,json=eval(self.data),headers=self.choice_headers())
token=res.json()['data']['token']['access_token']return token
defchoice_headers(self,type=None):"""
封装选择请求头信息,type等于None时,请求头不传token,等于其他值时传token
:param type:
:return:
"""
headers ={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36","Content-Type":"application/json; charset=utf-8"}iftype:
headers["Authorization"]=self.get_token_data()return headers
else:return headers
defget(self,url,params=None,headers=None,files=None):"""
get请求
:param url: 请求路径
:param params: 请求参数
:param headers: 请求头
:param files: 请求文件
:return:
"""try:
log.info("============请求信息============")
complete_ulr="http://"+self.host+url#完整urlifnot headers:
headers=self.choice_headers(type=1)else:
headers=self.choice_headers()
res=requests.get(url=complete_ulr,params=params,headers=headers,files=files)
log.info(f"请求url:{complete_ulr}")
log.info(f"请求参数:{params}")
log.info(f"请求头:{headers}")
log.info("============响应信息============")
log.info(f"响应状态码:{res.status_code}")
log.info(f"响应结果:{res.text}")return res
except:
log.error("============请求失败信息============")
log.error(f"请求异常:{traceback.print_exc()}")defpost(self,url,data=None,json_data=None,headers=None,files=None):"""
post请求
:param url: 请求路径
:param data: 原始请求参数
:param json_data: json格式请求参数
:param headers: 请求头
:param files: 请求文件
:return:
"""try:
log.info("============请求信息============")
complete_ulr="http://"+self.host+url#完整urlifnot headers:
headers=self.choice_headers(type=1)else:
headers=self.choice_headers()
res=requests.post(url=complete_ulr,data=data,json=json_data,headers=headers,files=files)
log.info(f"请求url:{complete_ulr}")if json_data==None:
log.info(f"请求参数:{data}")else:
log.info(f"请求参数:{json_data}")
log.info(f"请求头:{headers}")
log.info("============响应信息============")
log.info(f"响应状态码:{res.status_code}")
log.info(f"响应结果:{res.text}")return res
except:
log.error("============请求失败信息============")
log.error(f"请求异常:{traceback.print_exc()}")
configparser读取配置文件
#coding=utf-8import os
from configparser import ConfigParser
classDictionary(dict):'''
把config.ini中的参数添加值dict
'''def__getattr__(self, keyname):#如果key值不存在则返回默认值"not find config keyname"return self.get(keyname,"config.ini中没有找到对应的keyname")classConfig(object):'''
ConfigParser二次封装,在字典中获取value
'''def__init__(self):# 设置配置文件路径
current_dir = os.path.dirname(__file__)
top_one_dir = os.path.dirname(current_dir)
file_name = top_one_dir +"/conf/config.ini"# 实例化ConfigParser对象
self.config = ConfigParser()
self.config.read(file_name,encoding="utf-8")#根据section把key、value写入字典for section in self.config.sections():setattr(self, section, Dictionary())for keyname, value in self.config.items(section):setattr(getattr(self, section), keyname, value)defgetconf(self, section):'''
用法:
conf = Config()
info = conf.getconf("main").url
'''if section in self.config.sections():passelse:print(" 找不到该 section")returngetattr(self, section)
递归遍历字典常用方法
#coding=utf-8from typing import Dict,List
defget_dict(dict_value ,obj_key ,default=None):"""
遍历字典,得到想要的value
:param dict_value: 所需要遍历的字典
:param obj_key: 所需要value的键
:param default:进行取值中报错时所返回的默认值 (default: None)
:return:
"""for k ,v in dict_value.items():if k == obj_key:return v
else:iftype(v)isdict:# 如果键对应的值还是字典
re = get_dict(v ,obj_key ,default)# 递归if re isnot default:return re
defget_list_dict(list_value ,obj_key,obj_value):"""
遍历列表中的每个字典,判断obj_key,obj_value值是否存在,存在则任何True,否则False
:param list_value: 所需要遍历的列表
:param obj_key: 想要判断的key
:param obj_value: 想要判断的value
:return:
"""for dict_value in list_value:for k ,v in dict_value.items():if k == obj_key and v == obj_value:returnTrueelse:continue#列表中所有数据都不存在时,返回FalsereturnFalsedefupdata_dict_value(dict_data ,obj_key,update_value=None):"""
遍历字典,得到想要的key对象,给读取文件时修改值,如果obj_key存在一样的情况下,就会改错
:param dict_value: 所需要遍历的字典
:param obj_key: 所需要value的键
:return:
"""for k ,v in dict_data.items():if k == obj_key:
dict_data[k]=update_value
else:iftype(v)isdict:# 如果键对应的值还是字典
updata_dict_value(v ,obj_key,update_value)# 递归defupdate_dict_val(data:Dict, key_list:List, val:int,i=0):"""
传入data字典格式数据,根据对应的key_list,把对应的key的val值修改
:param data: 传入的字典数据
:param key_list: 传入修改的key list,例如["department","id"],配置文件中写department.id,通过split分解
:param val: 想要修改的值
:param i: i值默认为0,递归时默认+1
:return:
"""if i==len(key_list)-1:
data[key_list[i]]= val
returnreturn update_dict_val(data[key_list[i]], key_list, val,i=i+1)defadd_params(func_str,params):"""
根据传入的函数名称,和函数所需要的数据来拼接成函数传参的字符串格式,通过eval转成可以执行的函数
:param func_str: 函数的名称,必须传字符串
:param params: 函数所需要的参数,params是一个list,例如函数为:add(a,b,c=4),huanc
:return:
"""
value =",".join([str(i)for i in params])
val =f'{func_str}({value})'returneval(val)
log日志封装
#coding=utf-8import logging
from common.public_path import DIR
import time
import os
defget_log(logger_name):"""
:param logger_name: 填项目名称表示哪个项目
:return:
"""#创建一个logger
logger = logging.getLogger(logger_name)
logger.setLevel(logging.INFO)#获取本地时间,转换为设置的格式#rq = time.strftime('%Y%m%d%H%M',time.localtime(time.time()))
rq = time.strftime("%Y_%m_%d_")#设置日志文件存放路径,日志文件名#设置所有日志和错误日志的存放路径# 通过getcwd.py文件的绝对路径来拼接日志存放路径
all_log_path = os.path.join(DIR,'logs/info_logs/')
error_log_path = os.path.join(DIR,'logs/error_logs/')#设置日志文件名
all_log_name = all_log_path + rq +'.log'
error_log_name = error_log_path + rq +'.log'#创建handler#创建一个handler,写入所有日志
fh = logging.FileHandler(all_log_name,encoding="utf-8")
fh.setLevel(logging.INFO)#创建一个handler,写入错误日志
eh = logging.FileHandler(error_log_name,encoding="utf-8")
eh.setLevel(logging.ERROR)#创建一个handler,输出到控制台
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)#定义日志输出格式#以时间-日志器名称-日志级别-日志内容的形式展示
all_log_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')# 以时间-日志器名称-日志级别-文件名-函数行号-错误内容
error_log_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(module)s - %(lineno)s - %(message)s')# 将定义好的输出形式添加到handler
fh.setFormatter(all_log_formatter)
ch.setFormatter(all_log_formatter)
eh.setFormatter(error_log_formatter)# 给logger添加handler
logger.addHandler(fh)
logger.addHandler(eh)
logger.addHandler(ch)return logger
#实例化log,调用时,直接调用log
log = get_log("CL接口自动化")
2、conf模块

该模块主要放配置数据,ini文件中数据格式如下,可存放环境数据、文件路径、邮箱等,根据自己需要配置
[enviro]
host=127.0.0.1:8000
url=/interface/login
data={'username':'zwx','password':'123123'}[excel_path]
path='data/case_data.xlsx'
3、data模块
该模块下存放参数化用例数据,支持yaml或者Excel,使用common中封装读取方法,读取测试用例并参数化使用。
yaml文件格式如下(如果不需要接口关联,可以不用写rules,后续文章会讲解):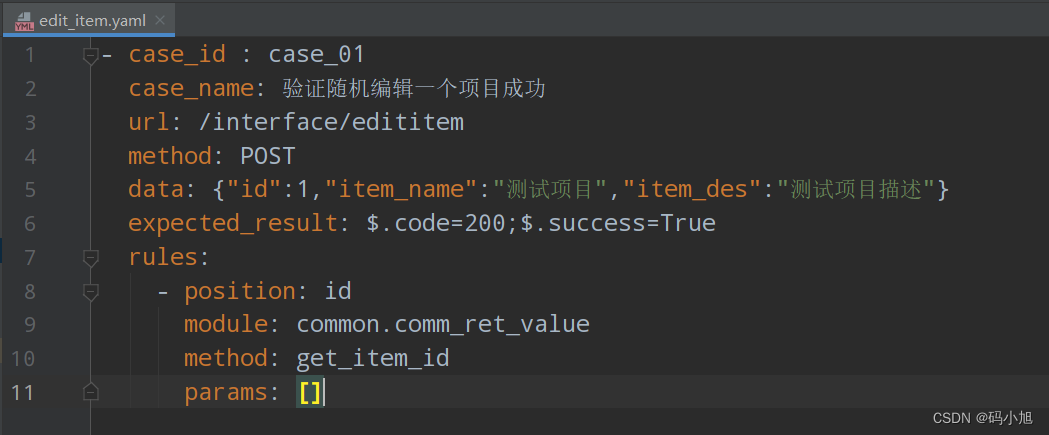
Excel文件格式如下(可以用sheet页区分不同模块或接口的用例):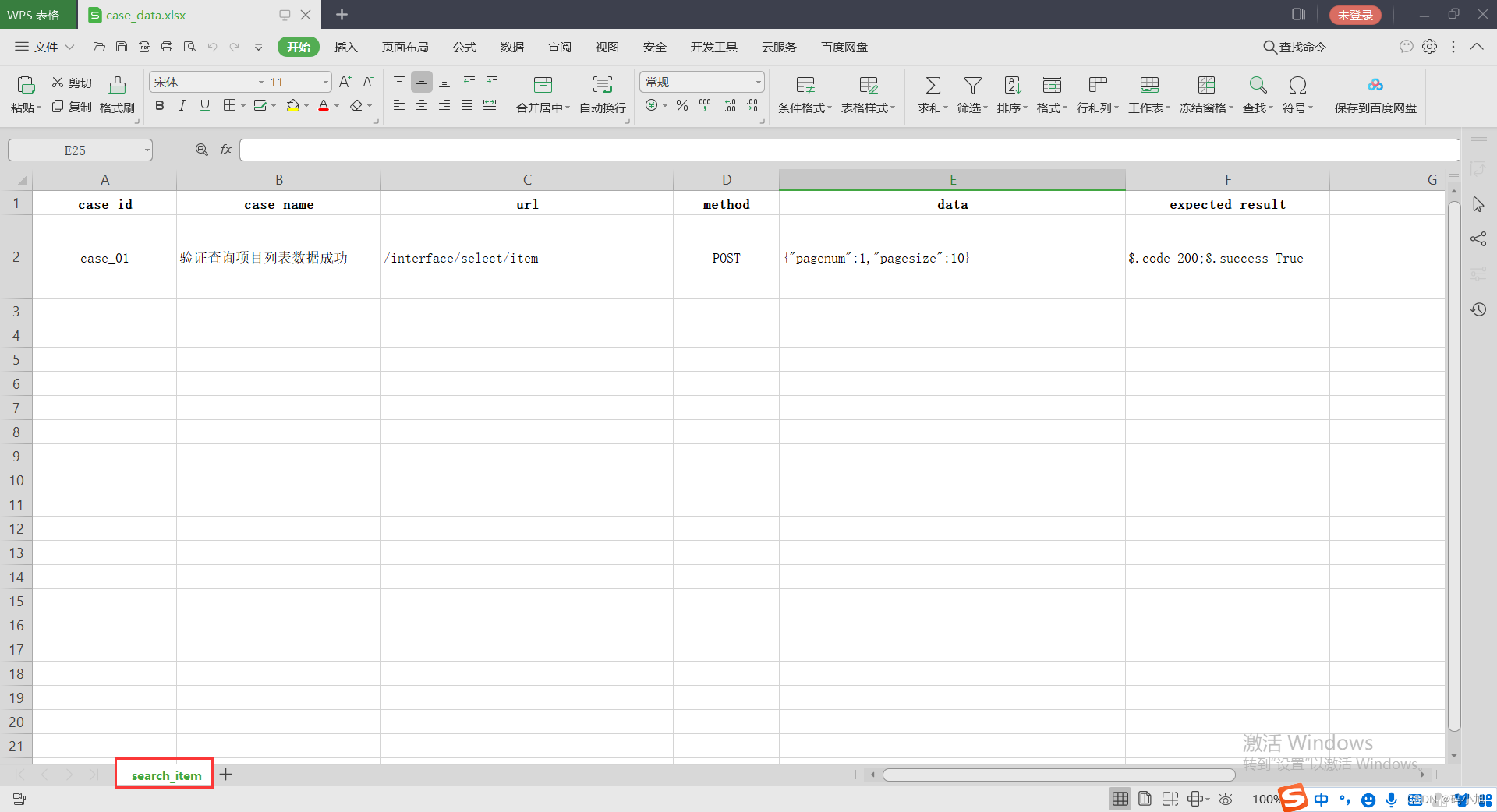
4、case模块
case模块主要用于存放测试用例,简单写了两条查询项目的接口用例,用例存放在yaml中,这里采用jsonpath断言,通过封装好的读取yaml数据的方法,读取数据后通过parametrize参数化,如下:
yaml文件:
-case_id: case_01
case_name: 验证查询项目列表数据成功
url: /interface/select/item
method: POST
data:{"pagenum":1,"pagesize":10}expected_result: $.code=200;$.success=True
-case_id: case_02
case_name: 验证查询页数pagenum为-1时,查询失败
url: /interface/select/item
method: POST
data:{"pagenum":-1,"pagesize":10}expected_result: $.code=2003;$.success=False;$.msg=查询项目数据失败
用例文件:
# coding=utf-8# @Time : 2022/5/24 11:17# @Author : 梗小旭# @File : test_search_item.pyimport pytest
from common.base_method_api import BaseMethodApi
from common.read_yaml_data import ReadYamlData
from common.public_assert import assert_res
from common.get_excel_data import GetExcelData
case_list=ReadYamlData("search_item").yaml_to_list()#读取该文件下所有测试用例@pytest.mark.parametrize("url,data,expected_result",case_list)deftest_login(url,data,expected_result):
bma=BaseMethodApi()
res=bma.post(url=url,json_data=data)
result=res.json()assert assert_res(result,expected_result)if __name__ =='__main__':
pytest.main(["-s","test_search_item.py"])
5、run_main.py执行文件
该文件执行所有用例,代码如下:
# coding=utf-8# @Time : 2022/3/10 15:33# @Author : 梗小旭# @File : run_main.pyimport os
import shutil
from common.public_path import DIR
path=DIR+'/report'if os.path.exists(path):
shutil.rmtree(path)
os.system("pytest -s -q --alluredir report")#生成allure报告
os.system("allure generate report/ -o report/html --clean")#清除报告数据
6、log模块
该模块主要放info和error日志数据,如下: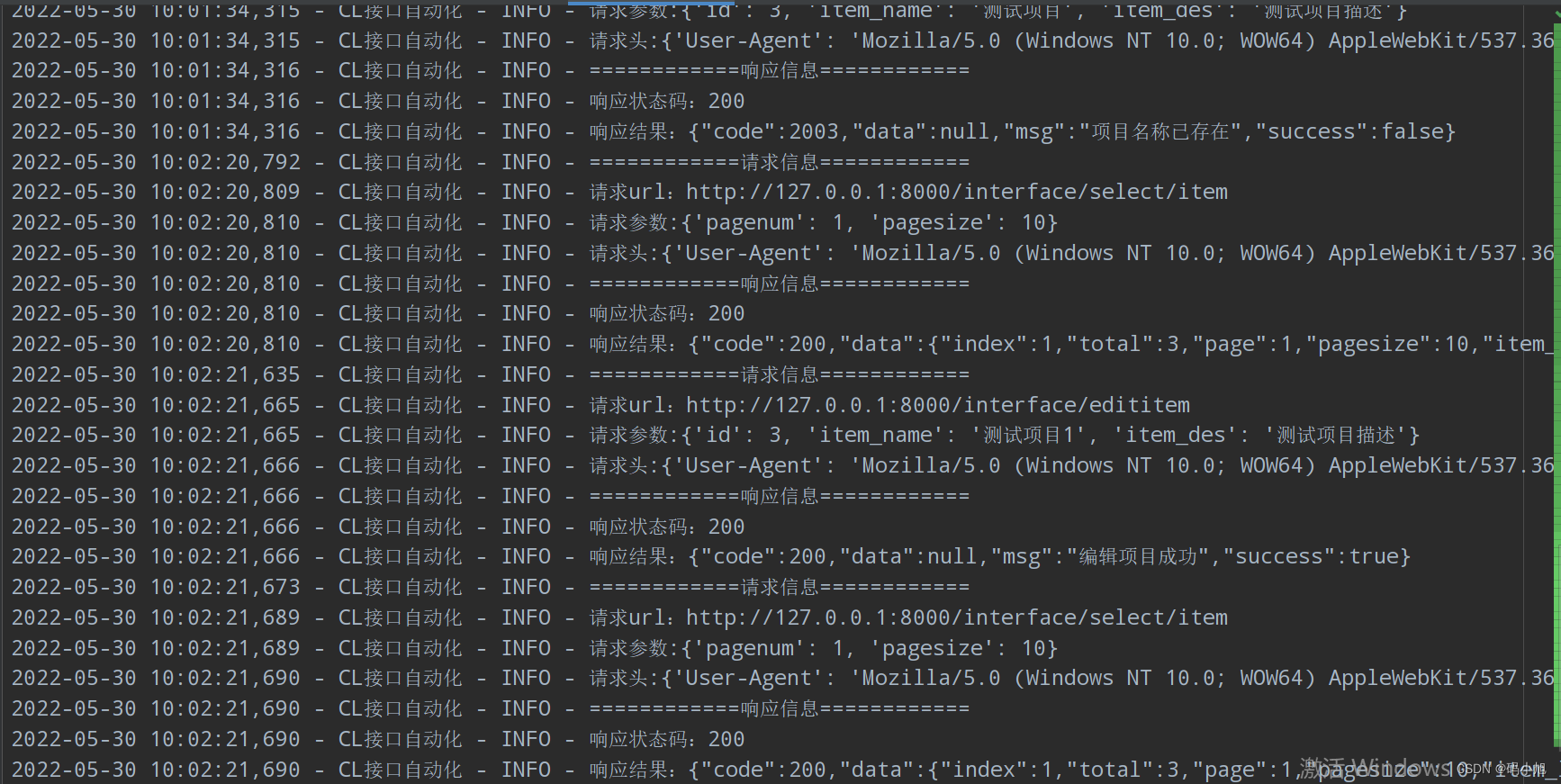
7、report模块
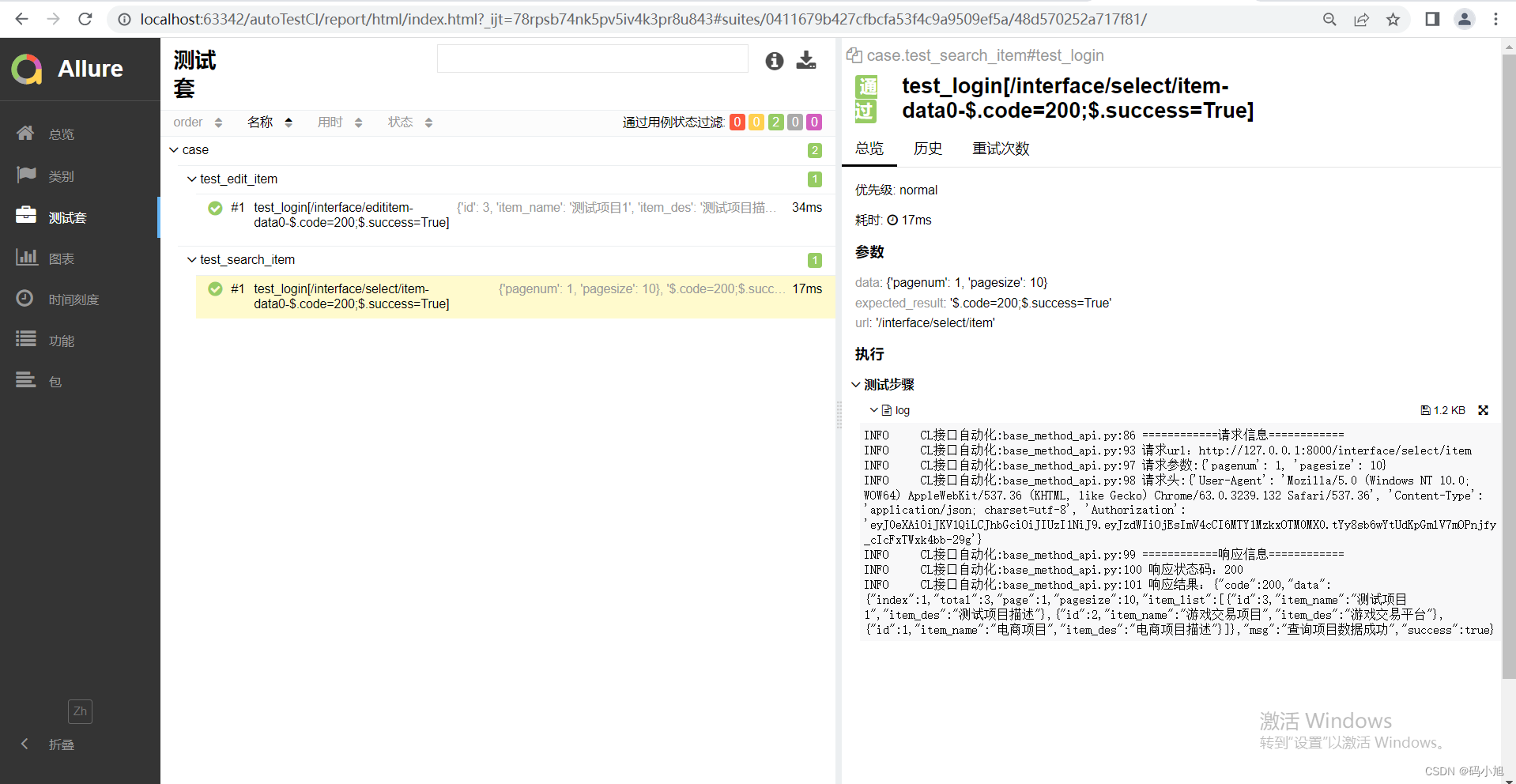
该模块存放执行生成的allure报告数据,可以通过allure添加步骤,描述、优先级等详细信息,本文未添加,用例标题可通过在parametrize中ids参数中添加,报告如下: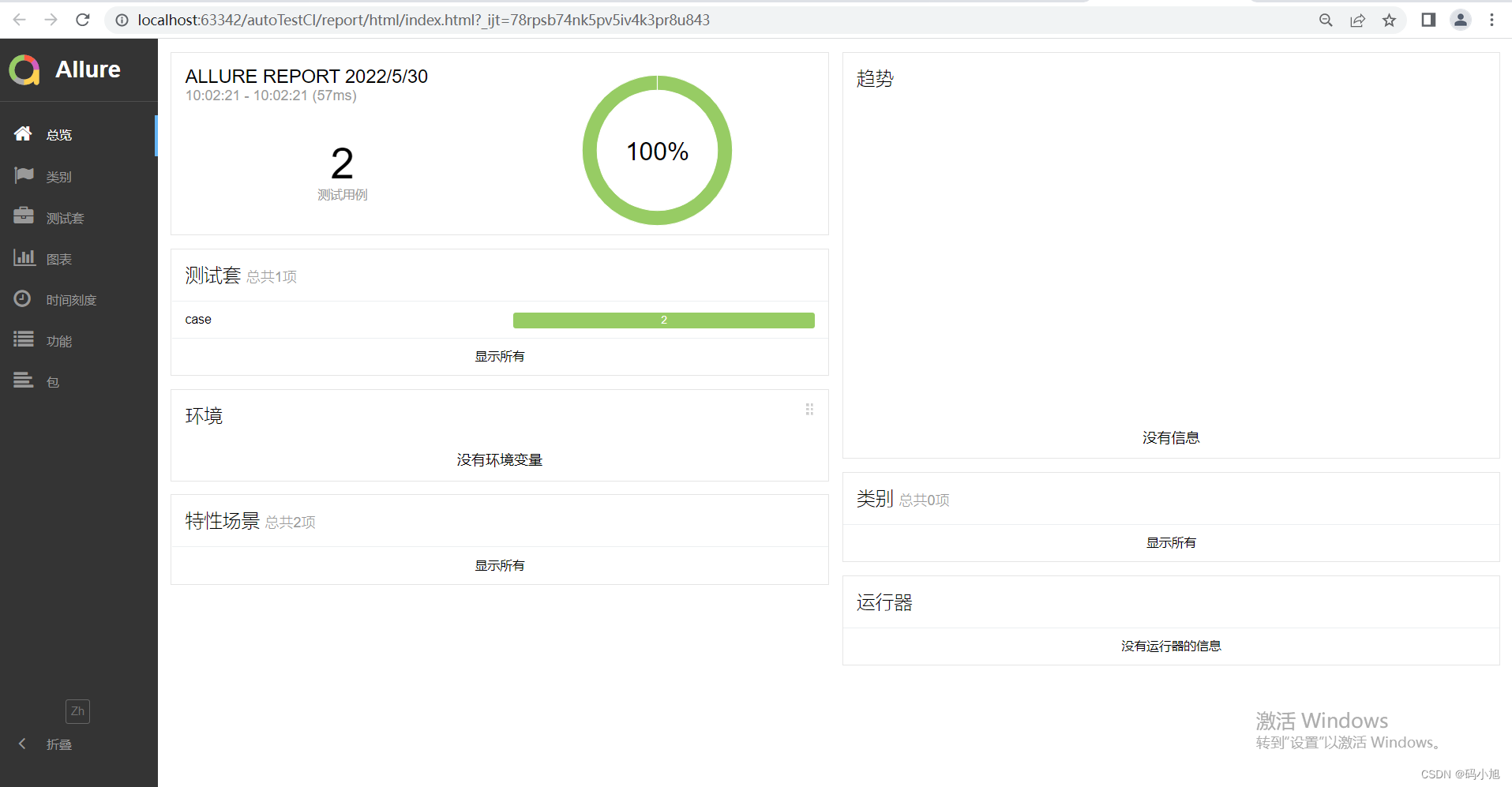
二、接口关联(场景测试)
在我们做接口测试时,接口关联的测试必不可少且非常重要的,那么我们在做接口自动化时,接口关联的场景我们如何做呢?
1、假如B接口的入参需要A接口的返回值,那么执行A接口的用例后把返回值存在文件中,B接口用例执行时读取文件中数据,形成接口关联。这样做虽然可以,但是存在一个问题,会导致每条用例不独立,如果接口A失败了,接口B的用例全部失败。
2、假如B接口的入参需要A接口的返回值,接口A单独写用例,不存返回值数据。单独封装一个接口A的方法返回值,接口B使用数据时调用封装的A方法,实现接口A和接口B的用例解耦。
本文中使用的是第2种方式,在yaml文件中增加rules规则,存在rules规则时,会调用对应模块的方法获取返回值,并修改这条用例的position字段值。大佬们有其他方法可以在评论区下留言。
rules:-position: id
module: common.comm_ret_value
method: get_item_id
params:[]
三、接口自动化平台
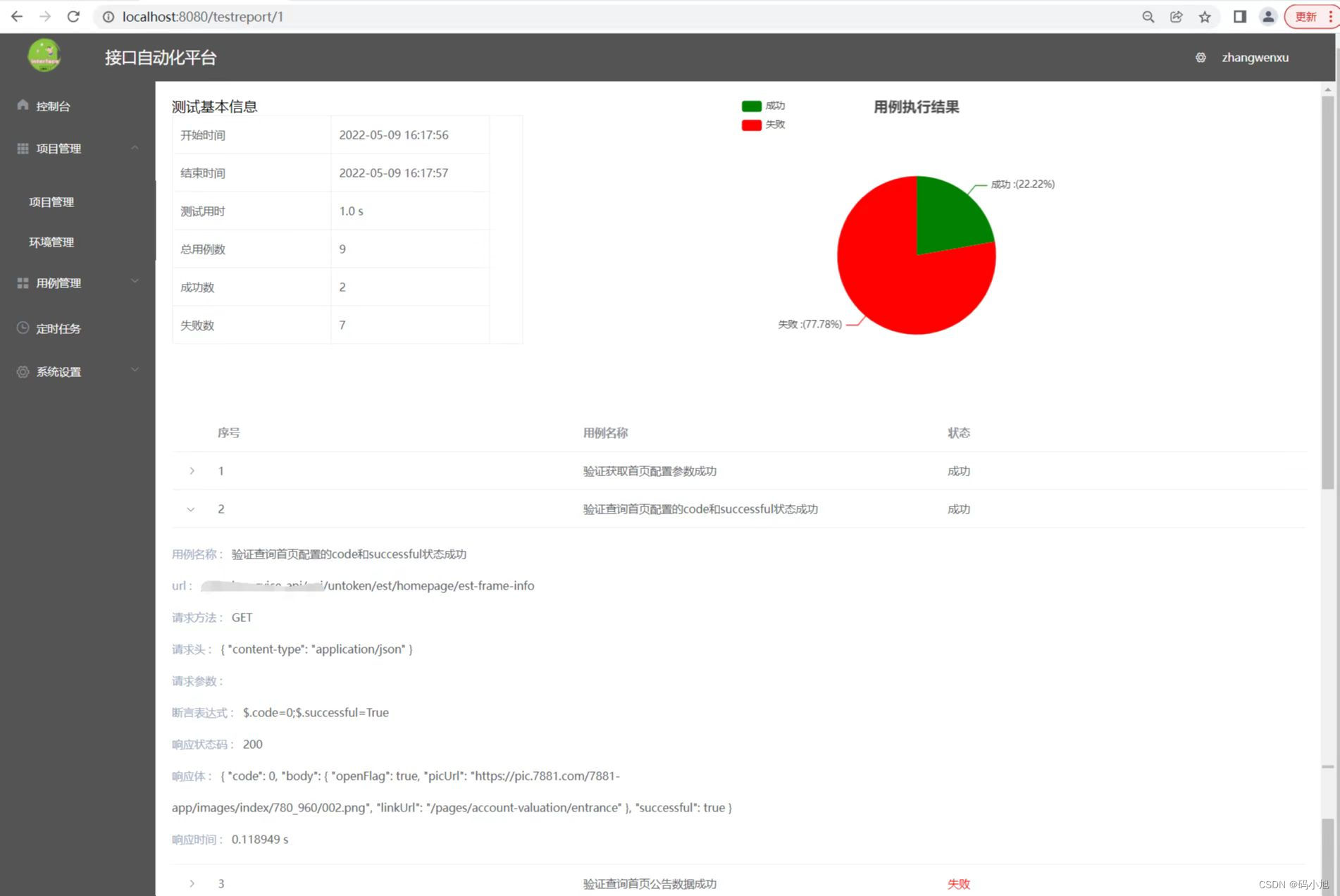
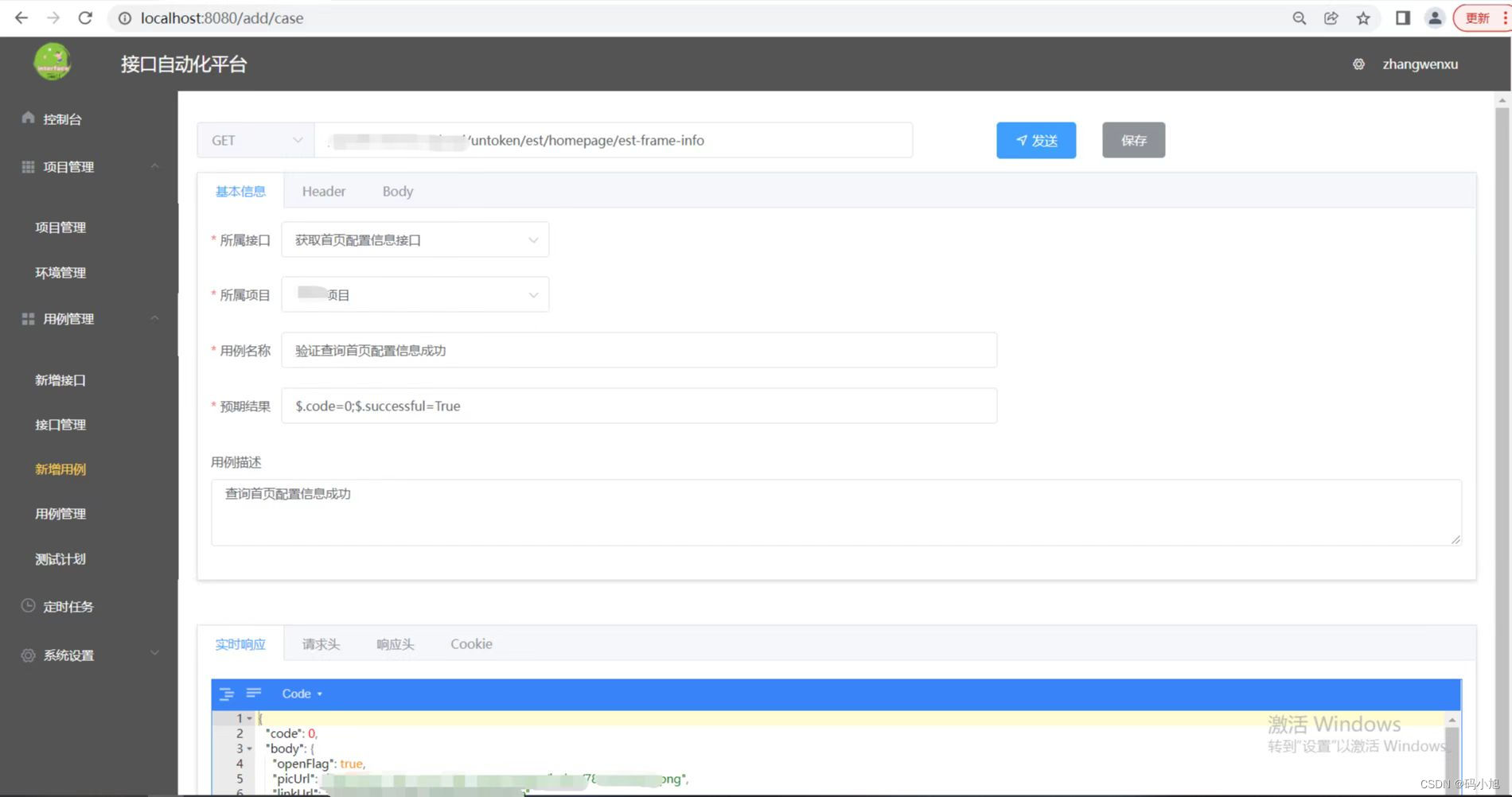
最近自己也写了一个接口自动化小平台,仅供自己学习使用,功能还未完善,完善后续更新出来,采用vue+fastapi前后端分离实现,话不多说,上图: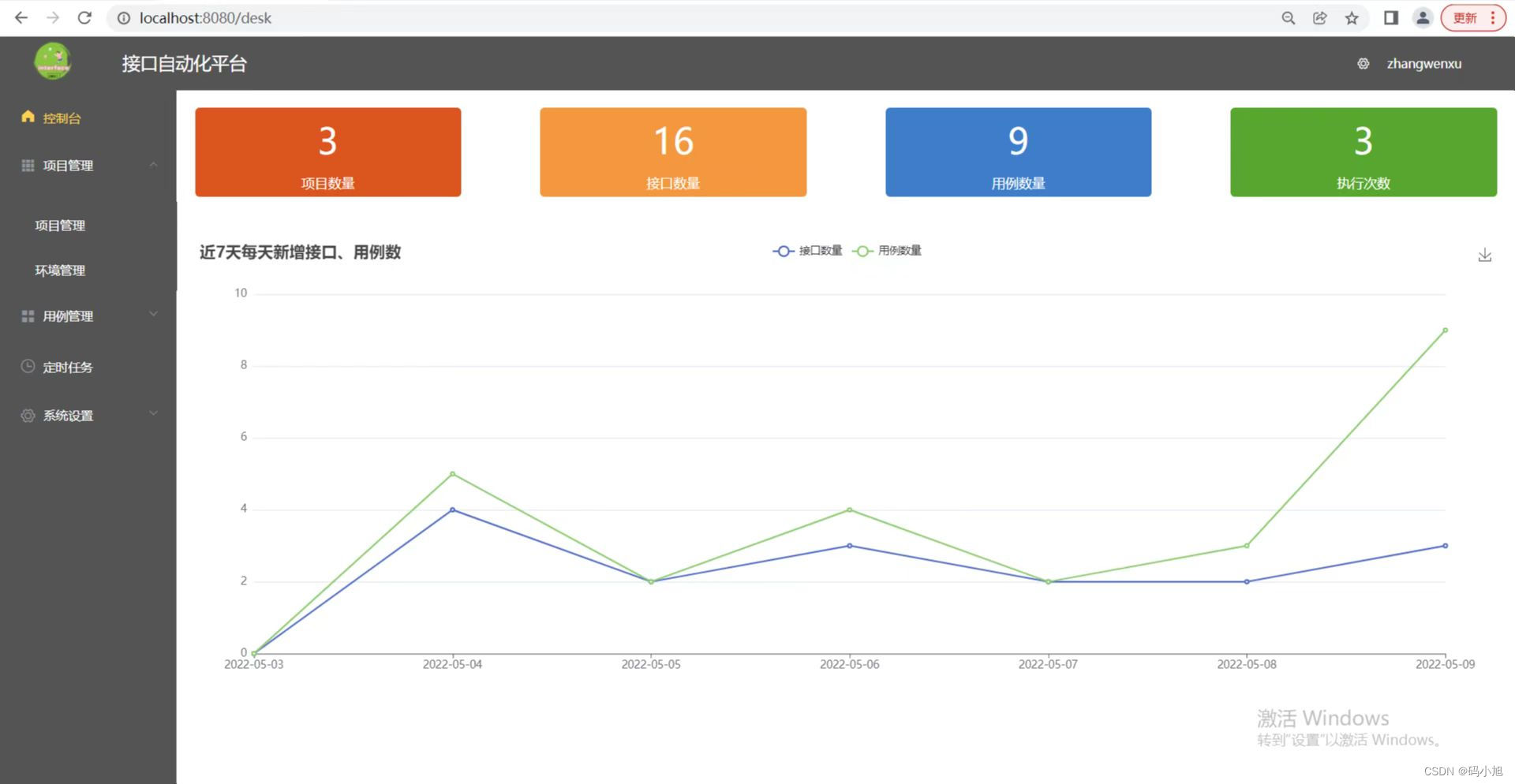
总结
目前框架只实现了基本的功能,未涉及到当接口用例过多时,接口变动,如何快速修改用例,pytest的失败重试、数据库校验、Jenkins集成等问题,后续在根据项目需求加上对应功能。希望大佬们给点好的建议改进改进。
版权归原作者 码小旭 所有, 如有侵权,请联系我们删除。