
Dataset 的基础知识
一、Dataset简介
Dataset是从Spark1.6 Alpha版本中引入的一个新的数据抽线结构,最懂在Spark2.0版本被定义成Spark新特性。
RDD, DataFrame,Dataset数据对比
1 RDD数据没有数据类型和元数据信息
2 DataFrame添加了Schema信息,每一行的类型固定为Row,每一列的值无法直接访问
3 在RDD的基础上增加了一个数据类型,可以拥有严格的错误检查机制。
4 Dataset和DataFrame拥有完全相同的成员函数
二、Dataset对象的创建
从RDD生成Dataset
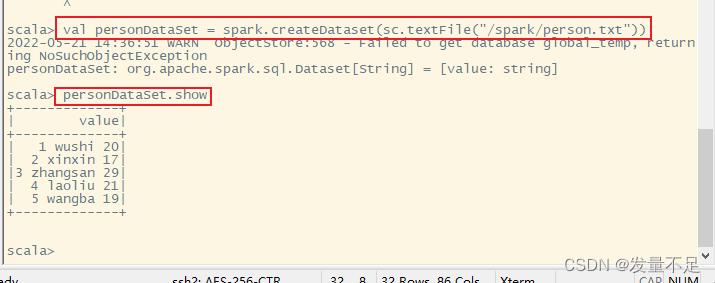
val personDataSet = spark.createDataset(sc.textFile("/spark/person.txt"))
查看结构
personDataSet.show
DateSet 可以直接转换为DataFrame
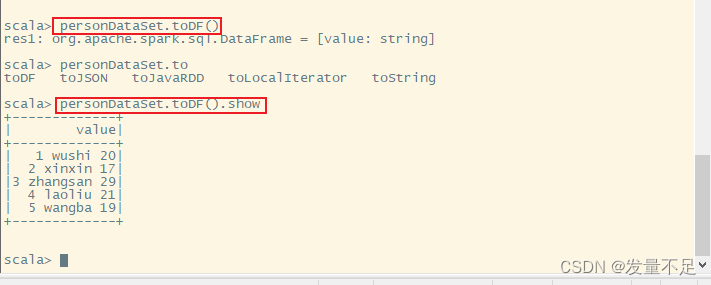
personDataSet.toDF()
personDataSet.toDF().show
RDD****转换为DataFrame
通常有两种方法实现基于RDD转换到DataFrame,第一种情况当一直RDD的数据结构(元数据信息),可以通过反射机制来推断生产Schema,另外一种情况,如果不清楚Dataset的数据结构,可以通过编程接口实现。
一、反射机制创建DataFrame
Step1 添加依赖(在项目里的一个pom.xml的文件里面)
#依赖需要添加到标签
#<dependencies>
<依赖添加位置>
#</dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.2</version>
</dependency>
Step 2 编写代码:
一:反射创建DataFrame
创建一个名为CaseClassSchema的scala项目
package cn.itcast
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
case class Person(id:Int,name:String,age:Int)
object CaseClassSchema {
def main(args: Array[String]): Unit = {
val spark : SparkSession=SparkSession.builder()
.appName("CaseClassSchema")
.master("local[2]")
.getOrCreate()
//2.获取SparkContext对象
val sc:SparkContext=spark.sparkContext
//设置日志打印级别
sc.setLogLevel("WARN")
//3.读取文件
val data: RDD[Array[String]]=
sc.textFile("F://spark_chapter02//src//main//scala//cn//itcast//person.txt").map(x=>x.split(" "))
//4.将RDD与样例关联
val personRdd: RDD[Person]=
data.map(x=>Person(x(0).toInt,x(1),x(2).toInt))
//5.获取DataFrame
//手动导入隐式转换
import spark.implicits._
val personDF:DataFrame=personRdd.toDF
//-----------DSL风格操作开始----------------
//1.显示DataFrame的数据,默认显示20行
personDF.show()
//2.显示DataFrame的schema信息
personDF.printSchema()
//3.统计DataFrame中年龄大于30岁的人数
println(personDF.filter($"age">30).count())
//-----------DSL风格操作结束----------------
//-----------SQL风格操作开始----------------
//将DataFrame注册成表
personDF.createOrReplaceTempView("t_person")
spark.sql("select * from t_person").show()
spark.sql("select * from t_person where name='zhangsan'").show()
//-----------SQL风格操作结束----------------
//关闭资源操作
sc.stop()
spark.stop()
}
}
二、编程方式定义Schema,创建DataFrame
编程方式的步骤
Step1 : 创建一个Row对象结构的RDD
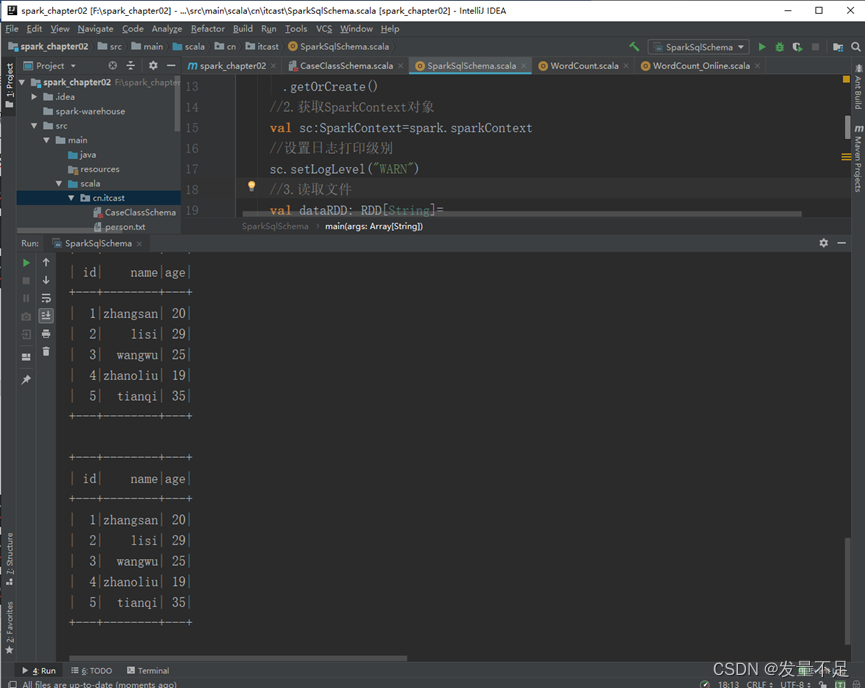
创建一个名为SparkSqlSchema的scala文件
package cn.itcast
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StructType,StructField,StringType}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
//case class Person(id:Int,name:String,age:Int)
object SparkSqlSchema {
def main(args: Array[String]): Unit = {
val spark : SparkSession=SparkSession.builder()
.appName("SparkSqlSchema")
.master("local[2]")
.getOrCreate()
//2.获取SparkContext对象
val sc:SparkContext=spark.sparkContext
//设置日志打印级别
sc.setLogLevel("WARN")
//3.读取文件
val dataRDD: RDD[String]=
sc.textFile("F://spark_chapter02//src//main//scala//cn//itcast//person.txt")
//4.将RDD与样例关联
val dataArrayRDD:RDD[Array[String]]=dataRDD.map(_.split(" "))
//5.加载数据到Row对象中
val personRDD: RDD[Row]=dataArrayRDD.map(x=>Row(x(0).toInt,x(1),x(2).toInt))
//6.创建Schema
val schema:StructType=StructType(Seq(
StructField("id",IntegerType,false),
StructField("name",StringType,false),
StructField("age",IntegerType,false)
))
//7.利用personRDD与Schema创建DataFrame
val personDF:DataFrame = spark.createDataFrame(personRDD,schema)
//8.DSL操作显示DataFrame的数据结果
personDF.show()
//9.将DataFrame注册成表
personDF.createOrReplaceTempView("t_person")
//10.sql语句操作
spark.sql("select * from t_person").show()
//11.关闭资源
sc.stop()
spark.stop()
}
}
本文转载自: https://blog.csdn.net/m0_57781407/article/details/126514865
版权归原作者 发量不足 所有, 如有侵权,请联系我们删除。
版权归原作者 发量不足 所有, 如有侵权,请联系我们删除。