
Kafka学习笔记三(生成数据发送与分区)
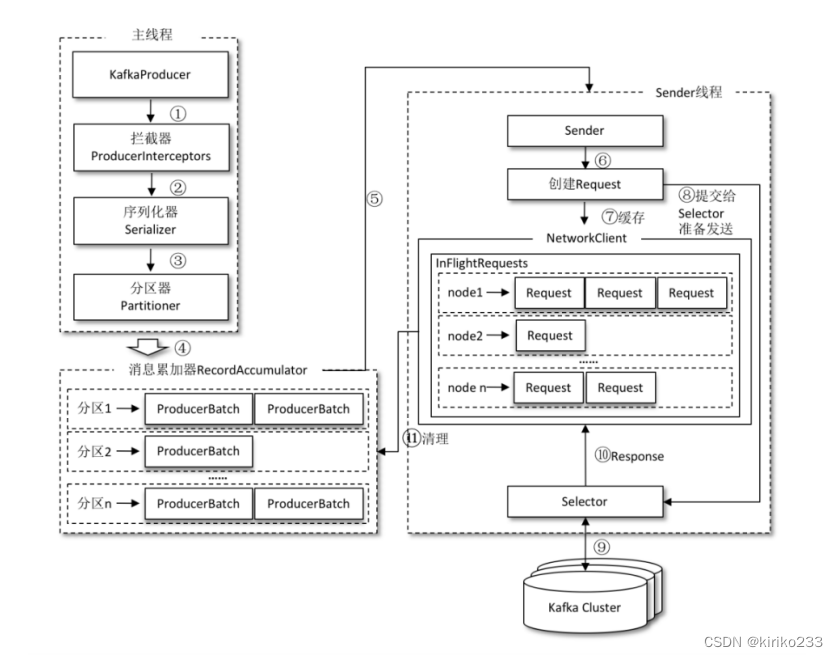
Kafka的消息从生产者到集群总共分为两个线程
一个是main,一个是sender
- main 线程用于把消息放到 RecordAccumulator 寄存器中寄存
- sender线程会通过 IO 和 kafka server 进行交互发送消息
首先讲main线程内
- KafkaProducer将发送的数据封装成一个 ProducerRecord 对象。内容包括:- topic:string 类型,NotNull。- partition:int 类型,可选。- timestamp:long 类型,可选。- key:string 类型,可选。- value:string 类型,可选。- headers:array 类型,Nullable。
- ProducerInterceptor- 拦截器最早在0.10.0.0引入,Kafka一共有两种拦截器,这种生产者拦截器主要用来在消息发送前做一些处理
- Serializer- 生产者发送的数据需要通过序列化之后,将对象啊转换成字节数组才能通过网络发送给Kafka。- 相对的,消费者需要使用反序列化将从Kafka里接收到的字节数组转换成相应的对象。
- Partitioner- 分区选择器,默认是对key进行计算,然后对于总分区数取模得到被发送的分区数,当然实现Producer时可以自定义Partition,或者指定特定的分区。- 分区器的作用就是为消息分配消息- 单个分区的消息是有序的。
- RecordAccumulator- 主线程调用send()方法将已经和topic和分区绑定好的消息,以分区为单位维护一个双端队列,将消息缓存起来。- 当达到一定的条件,会唤醒Sender线程发送RecordAccumulator里面的消息。- buw er.memory:设置生产者内存缓冲区的大小,默认为 33554432Byte(32M)。如果应用程序发送消息的速度大于缓冲区往服务器发送的速度,那么就会导致缓冲区空间不足,这时候 send() 方法要么阻塞要么抛出异常,取决于 max.block.ms 参数,表示在抛出异常之前可用阻塞一段时间。max.block.ms:该参数指定了在调用 send() 方法或者使用 partitionsFor() 方法获取元数据时生产者的阻塞时间,默认为 60000ms(1分钟)。当生产者的发送缓冲区已满或者没有可用的元数据的时候,就会阻塞。如果阻塞到达设定的时间,生产者就会抛出超时异常。- batch.size:批次大小,默认 16384Byte(16K)。当有多个消息需要发送到同一个分区的时候,生产者会将他们放到同一个批次里,该参数指定了一个批次可以使用的内存大小,按照字节计算,当批次被填满,批次里的消息会被发送出去,当然生产者不一定都会等批次被填满才发送,半满的批次甚至只有一个消息的批次也有可能被发送。- linger.ms:等待时间,默认 0ms,即来一条发一条。该参数指定了生产者在发送批次之前等待更多消息加入批次的时间,生产者会在批次填满或者达到这个时间时把批次发送出去,默认情况下,只要有可用的线程,生产者就会把消息发送出去,就算批次里只有一个消息。把 linger.ms 设置成比 0 大的数,让生产者在发送批次之前等待一会儿,使更多消息加入到这个批次,这样虽然会增加延迟,但是也会提升吞吐量,因为一次性发送更多消息,每个消息的开销就变小了。- compression.type:消息压缩算法,默认不启用压缩。可以指定为:gzip、snappy、lz4或 zstd,使用压缩可以降低网络传输开销和存储开销,这往往是 Kafka 发送消息的瓶颈所在。- retries:发生错误后,消息重发的次数,默认为 2147483647(int 最大值)。如果达到设定值,生产者就会放弃重试并返回错误。默认情况下,每次重试之间会等待 100 ms,不过可以通过 retry.backow .ms 参数来改变这个时间间隔。- retry.backow .ms:发生错误后,消息重发的间隔时间,默认为 100ms。- max.request.size:限制生产者在单次请求中发送的字节量,以避免发送庞大的请求。-
//核心代码如下// 缓冲区大小 buffer.memory,默认为 32mproperties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);// 批次大小 batch.size,默认为 16kproperties.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);// 等待时间 linger.ms,默认为 0ms,即来一条发一条properties.put(ProducerConfig.LINGER_MS_CONFIG,1);// 数据压缩 compression.type,默认为不启用压缩,可配置值:gzip、snappy、1z4 或zstdproperties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");- RecordAccumulator的内部为每个分区都维护了一个双端队列,队列中的内容就是ProducerBatch,即Deque<ProducerBatch>。ProducerBatch中可以包含一至多个ProducerRecord。
kafka生产者架构执行步骤
- 主线程KafkaProducer创建消息对象ProducerRecord,然后通过生产者拦截器。
- 生产者拦截器对消息的key ,value做一定的处理,交给序列化器。
- 序列化器对消息key和vlue做序列化处理,然后给分区器。
- 分区器给消息分配分区、并发送给消息收集器。
- 将一条ProducerRecord添加到RecordAccumulator,首先会根据分区确定对应分区所在的双端队列,在双端队列获取尾部的一个ProducerBatch对象,查看该ProducerBatch是否可以写入该ProducerRecord消息,如果可以则写入,不能的话,会在双端队列末尾在创建一个ProducerBatch对象,创建时会评估这条消息是否是否超过batch.size参数的大小。如果不超过,就以batch.size参数的大小来创建ProducerBatch对象。通知sender线程发送消息。
- sender线程获取RecordAccumulator中的消息,需要将原本的<分区,Deque>形式再次封装成<Node,List的形式,其中Node节点表示Kafka集群中的broker节点。对于网络连接而言,生产者客户端是与具体broker节点建立连接,也就是向具体的broker节点发送消息。而并不关心消息属于哪个分区;sender线程还会进一步封装成<Node,Request>的形式,这样就可以将请求发往各个Node了。这里的Request是指kafka的各种请求协议。
- sender线程发往Kafka之前还会保存到InFlightRequest中,InFlightRequest保存对象的具体形式为Map<NodeId,Deque>,他的主要作用是缓存了已经发出去但是还没有收到相应的请求。
- sender将Request交给Selector准备发送。
- Selector将Request发送到对应的kafka节点(Broker)。
- Selector相应结果反馈给InFlightRequest。
- 主线程清理RecordAccumulator已经发送完毕的消息。
数据分区发送
在 Kafka 中,Topic 是一个逻辑上的概念,而 Partition 则是一个物理上的概念,消息最终都是存储在Partition 中的,但主题中的每条消息只会保存在一个分区中,而不会在多个分区中被保存多份。
- Kafka 支持使用分区来解决水平扩展的问题,同时还可以解决消息顺序读取的问题,其实还可以解决负载均衡的问题。 - 水平扩展:通过分区可以把海量数据按照分区切割成一块一块的数据存储在多台 Broker 上;- 消息顺序读取:将需要顺序处理的消息,按照一定的顺序发送到同一个分区中,订阅了这个分区的消费者就可以按照相同的顺序对消息进行处理;- 提高并行度:生产者可以以分区为单位发送数据,消费者可以以分区为单位消费数据;- 负载均衡:合理控制分区的任务,可以实现负载均衡的效果。
发送分区策略
有了分区之后,我们自然希望数据能均匀地分布到各个分区上,而不是某个分区数据满了,其他分区却一条数据都没有,这样就造成了数据倾斜。那么,怎么才能将数据均匀地分布到各个分区上呢?这就要依赖于分区策略了。在 Kafka 中,分区器的顶级接口是 Partitioner 接口.
在Kafka的早期版本里
- 分区接口类包括两个方法(partition、close),且只有一个实现类,即DefaultPartitioner类 - 如果ProducerRecord指定分区,则直接使用指定分区;- 如果ProducerRecord没指定分区,指定key,则基于key hash对分区数求余,即为分区;- 如果ProducerRecord既没指定分区也没指定key,则采用round-robin方式随机轮询。
在后续版本中
分区接口类包括三个方法(partition、close、onNewBatch),实现类也增加到三个:
- DefaultPartitioner、RoundRobinPartitioner、UniformStickyPartitioner
- DefaultPartitioner和UniformStickyPartitioner都涉及StickPartitioner - 如果ProducerRecord未携带key信息,两者是等同的。 - 使用StickPartitioner- 如果携带key信息: - DefaultPartitioner继续保持之前版本的实现方式,即基于key hash对分区数求余;- 而UniformStickyPartitioner并不关心key信息,一直使用StickPartitioner。
- RoundRobinPartitioner - RoundRobinPartitioner也是不关心key信息,均采用round-robin方式随机轮询。
粘性分区StickPartitioner(KIP-480)
- Record batches很大程度上会影响records从producer到broker的时延。较小的batches会导致更多的请求、队列、更高延迟。
- 一般来说,即使linger.ms=0,较大的batches也会减少延迟。在启用linger.ms(即>0),如果数据量不够填充一个batch(只能等linger.ms达到满足条件才会触发发送),就会进一步增加时延。如果能够找到一种方法来增加批处理的大小,以便在linger.ms之前触发发送,这将进一步减少延迟。
- 早期版本(2.4之前)在没有指定分区和键的情况下,默认分区器分区以循环方式展开:这意味着一系列连续记录中的每个记录都将被发送到不同的分区,直到我们用完分区并重新开始。虽然这会将记录均匀地分布在分区中,但也会导致更多的batchs变得更小。可以考虑让所有记录都使用一个指定的分区(或几个分区)并在一个更大的批中一起发送。
- StickPartitioner通过“粘住”分区直到batches已满(或在linger.ms启动时发送),然后再创建新的batches,这样的话,与默认分区器相比会减少时延。即使在linger.ms为0并立即发送的情况下,也可以看到StickPartitioner会减少时延。发送一系列batches后,粘性分区将发生更改。随着时间的推移,记录应该均匀地分布在所有分区中。
自定义分区策略
分区器相比会减少时延。即使在linger.ms为0并立即发送的情况下,也可以看到StickPartitioner会减少时延。发送一系列batches后,粘性分区将发生更改。随着时间的推移,记录应该均匀地分布在所有分区中。
自定义分区策略
除去了Kafka自带的这些分区策略之外,也可以根据自己业务的需求去实现Partitioner接口重写其方法,自定义自己需要的分区器。
本文转载自: https://blog.csdn.net/kiriko233/article/details/135256095
版权归原作者 kiriko233 所有, 如有侵权,请联系我们删除。
版权归原作者 kiriko233 所有, 如有侵权,请联系我们删除。