
题目:
1、在中国的星巴克有多少家
2、统计在各个国家和地区的星巴克开店数量
3、距离北极点(物理北极)最近的星巴克店是哪一家?
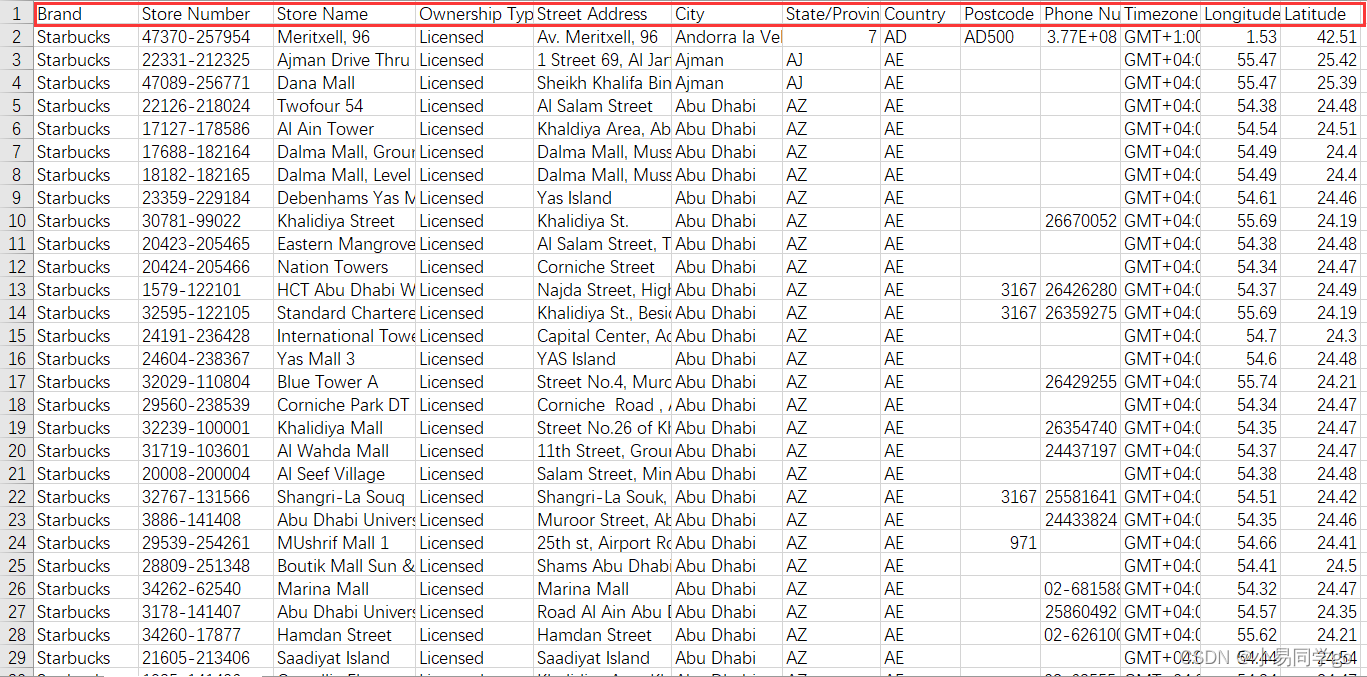
星巴克开店数据大致内容:
- Brand 品牌
- StoreNumber 店铺号码
- StoreName 店铺名称
- Ownership Type 所有权类型
- StreetAddress 街道地址
- City 店铺所在城市
- State/Province 店铺所在州/省份
- Country 店铺所在国家
- Postcode 邮编
- PhoneNumber 电话号码
- Timezone 时区
- Longitude 经度
- Latitude 维度
一、创表并装载数据
<1.创建一个yiqianbin的表>
create table if not exists yiqianbin(
Brand string,
StoreNumber string,
StoreName string,
OwnershipType string,
StreetAddress string,
City string,
State string,
Country string,
Postcode string,
PhoneNumber int,
Timezone string,
Longitude float,
Latitude float)
row format SERDE ‘org.apache.hadoop.hive.serde2.OpenCSVSerde’
WITH SERDEPROPERTIES(“separatorChar” = “,”,“quoteChar”=“”",“escapeChar” = “\”);
<2.加载数据>
load data local inpath ‘/home/yqb/hadoop_class/星巴克开店数据集.csv’ overwrite into table yiqianbin; ❤️.查询一下表以及数据是否成功导入>
❤️.查询一下表以及数据是否成功导入>
二、完成练习
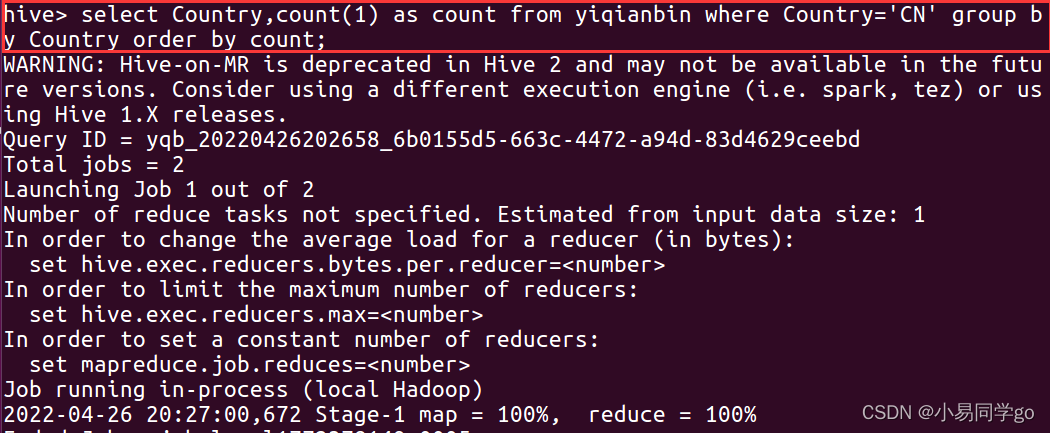
1.在中国的星巴克有多少家
select Country,count(1) as count from yiqianbin where Country=‘CN’ group by Country order by count;

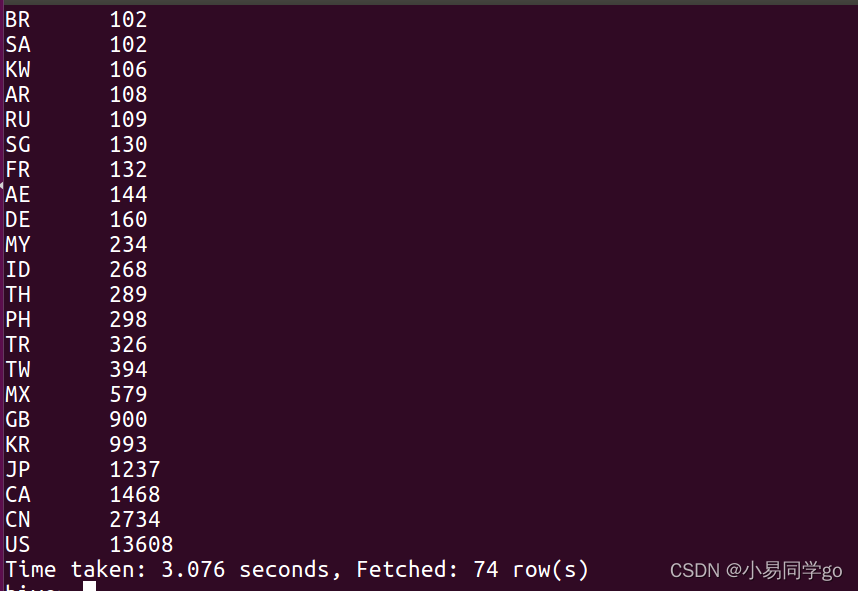
2.统计在各个国家和地区的星巴克开店数量
select Country,count(1) as count from yiqianbin group by Country order by count;
3.距离北极点(物理北极)最近的星巴克店是哪一家?
select max(float(Latitude)) from yiqianbin;
select StoreName from yiqianbin where Latitude=‘max(float(Latitude))’ limit 1;

总结
对sql语句掌握的还远远不够
版权归原作者 小易同学go 所有, 如有侵权,请联系我们删除。