
文章目录
常见的消息队列工作模式
- 至多一次:消息被确认消费后,删除消息;一般只允许被一个消费者消费,且队列中的数据不允许被重复消费。activeMQ 就是这种。
- 没有限制:消息可以被多个消费者同时消费,并且同一个消费者可以多次消费同一个记录;大数据场景。
基本概念
- 集群中的一则消息也称为 Record;
- Topic 用于分类集群中的消息-record;每个topic 可以有多个订阅者。(topic 是一种逻辑上的概念)
- 每一个Record 只属于一个Topic;
- 分区日志****partition: 用于持久化存储 topic 中的 record;生产者决定 record 发送到 topic 中的哪一个partition 中;
- Broker: 一个具体的消息服务实例;
- Leader: Broker 中语言读写数据的角色
- follower:同步leader 数据,leader如果宕机, 用于选举新leader,来读写
- 集群中的 Leader 的监控 和 Topic 元数据 存储在 Zookeeper 中
kafka 特性
- 高吞吐率
- 海量存储
Kafka 基本架构
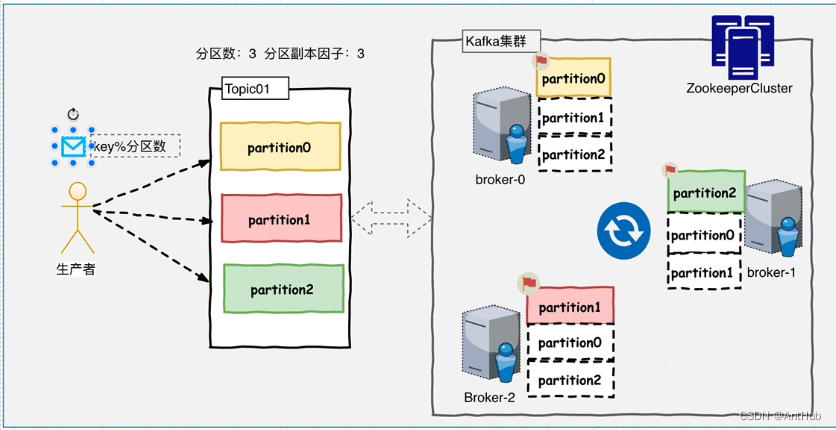
topic 分区的 目的/ 好处
- 对 topic 容量的提升:属于同一个 topic 的日志分散到多个 服务器 扩展了单机的容量,还可以扩缩容;
- 提高并发/ 分流:集群中 不同 的服务器作为不同 分区的 leader,提高 io 能力,均衡系统负载
- 在使用消费组时,增加分区也会增加 消费能力
- (每个分区需要适配 托管它的服务器)
日志存储形式
- 每组日志分区时一个有序的不可变的日志序列,分区中的每一个Record 都被分配了唯一的序列编号 称为 offset, record 会持久化;
- 时间越早,序号越小;
- 使用硬盘存储日志文件。(性能问题)
- kafka 会定期检查日志文件,然后将过期的数据从log 中移除;
- 由于分区的存在,及写入策略的不同,kafka 只能保证单个分区的先入先出的顺序性, 无法保证多个分区之间的顺序性。也就是不是严格意义上的先进先出,
- 所以,如果需要让kafka 保证顺序那就可以采用不分区的方式。
消费者,消费方式 逻辑
- 每个消费者维护自己本次消费对应分区的偏移量;
- 由上,多个消费者之间相互独立;
- 消费者在消费完一个批次的数据后,将本次消费的偏移量( 实际是offset+1,是下次读取的起始位置)提交给 kafka 集群;
- 所以,对每个消费者而言可以随意的控制 消费者的偏移量;消费者可以从一个 topic 分区中的任意位置读取数据。
消费组
- 消费者使用 Consumer Group 名称标记自己;
- 发布到Topic 的每条记录都会传递到每个 消费组 中的一个消费者;也就是说,一个分区上的消息还是仅由组中的一个 消费者 消费;
- 新加入组的实例,会接管其他消费者负责的某些分区(是否优先接管负载大的消费者的分区?)
- 组中的消费者个数 一般 不会大于 topic中 分区的数量;多的只能作为备用
- 基于的是均分策略;
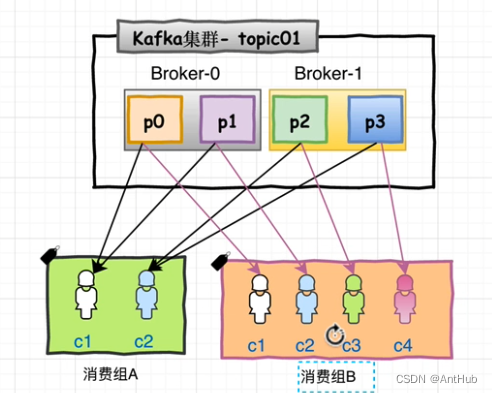
- (就是消费者的分身,是一种逻辑上的消费者,视为一个消费者;)
- (提高了消费者的吞吐量,在组中的实例间 均分消费)
- (提高了消费者的 可用性/容错性 ,一个 消费者 下线,其负责的分区将由组中的其他实例 负责处理 )
高性能
写入: 顺序写+ mmap
- mmap 内存传入 fd 直接映射文件,对应内核 PageCache;
- kafka 写入 mmap 映射的内存;OS 自动刷写磁盘(数据丢失问题?#2)
- 顺序写入;
读取:零拷贝+DMA
- 零拷贝(用户空间零拷贝): 数据不经过用户空间,从 内核缓冲区 直接拷贝到socket 缓冲区,然后发送出去;
- dma 协处理器:传统io 需要cpu 在磁盘驱动器缓冲区与内核缓冲区之间来回拷贝,过程中磁盘反复发出中断,cpu还需要反复处理中断;引入dma后 cpu 来回拷贝、中断处理 的动作由dma 完成,拷贝完成后/ 数据足够多后 通知cpu。期间 cpu 可以用于处理其他任务。
使用场景
- 解耦,异步通信,削峰填谷
- 大数据
本文转载自: https://blog.csdn.net/wwq921220/article/details/132135530
版权归原作者 AntHub 所有, 如有侵权,请联系我们删除。
版权归原作者 AntHub 所有, 如有侵权,请联系我们删除。