
Flink 中的 Slot、Task、Subtask、并行度
我们在使用 Flink 时,经常会听到
task
,
slot
,线程 以及 并行度 这几个概念,对于初学者来说,这几个概念以及它们与内存,CPU 之间的关系经常搞不清楚,下面我们就通过这篇文章来弄清楚这些概念。
1.并行度
特定算子的子任务(
subtask
)的 个数 称之为 并行度(
parallel
)。一般情况下,一个 数据流的并行度 可以认为是其 所有算子中最大的并行度。Flink 中每个算子都可以在代码中通过
.setParallelism(n)
来重新设置并行度,而并行执行的
subtask
要发布到不同的
slot
中去执行。
2.Task 与线程
对于分布式执行的任务,Flink 将算子的
subtasks
链接成
tasks
。每个
subtask
由一个线程执行。如下图中样例数据流用 5 个
subtask
执行,因此就有 5 个并行线程。

上图中,
source
+
map
算子组成一个
subtask
,并行度为 2,
keyby
+
window
+
apply
算子组成一个
subtask
,并行度为 2,
sink
算子组成一个
subtask
,并行度为 1。
3.算子链与 slot 共享资源组
前面提到 Flink 会将算子的
subtask
链接成
task
,实际上就是通过算子链操作来实现的。将算子链接成
task
的好处:
- ✅ 它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量。
- ✅ 链行为是可以配置的;将两个算子链接在一起能使得它们在同一个线程中执行,从而提升性能。
Flink 默认会将能链接的算子尽可能地进行链接(例如两个
map
转换操作)。 此外, Flink 还提供了对链接更细粒度控制的 API 以满足更多需求。
如果想对整个作业禁用算子链,可以调用
StreamExecutionEnvironment.disableOperatorChaining()
。下列方法还提供了更细粒度的控制。需要注意的是, 这些方法只能在 DataStream 转换操作后才能被调用,因为它们只对前一次数据转换生效。例如,可以
someStream.map(...).startNewChain()
这样调用,而不能
someStream.startNewChain()
这样。
另外,一个
slot
共享资源组对应着 Flink 中的一个
slot
槽, 可以根据需要手动地将各个算子隔离到不同的
slot
中。
Transformation
Description
Start new chain以当前
operator
为起点开始新的连接。如下的两个
mapper
算子会链接在一起而
filter
算子则不会和第一个
mapper
算子进行链接。
someStream.filter(...).map(...).startNewChain().map(...)
。Disable chaining任何算子不能和当前算子进行链接。
someStream.map(...).disableChaining()
。Set slot sharing group配置算子的资源组。Flink 会将相同资源组的算子放置到同一个
slot
槽中执行,并将不同资源组的算子分配到不同的
slot
槽中,从而实现
slot
槽隔离。如果所有输入操作都在同一个资源组,资源组将从输入算子开始继承。Flink 默认的资源组名称为
default
,算子可以显式调用
slotSharingGroup("default")
加入到这个资源组中
.someStream.filter(...).slotSharingGroup("name")
。
4.Task slots 与系统资源
每个
worker
(TaskManager)都是一个 JVM 进程,可以在单独的线程中执行一个或多个
subtask
。为了控制一个 TaskManager 中接受多少个
task
,就有了所谓的
task slot
(至少一个)。
每个
task slot
代表 TaskManager 中 资源的固定子集。例如,具有 3 个
slot
的 TaskManager,会将其托管内存
1
/
3
1/3
1/3 用于每个
slot
。分配资源意味着
subtask
不会与其他作业的
subtask
竞争托管内存,而是具有一定数量的保留托管内存。注意此处没有 CPU 隔离;当前
slot
仅分离
task
的托管内存。
通过调整
task slot
的数量,用户可以定义
subtask
如何互相隔离。每个 TaskManager 有一个
slot
,这意味着每个
task
组都在单独的 JVM 中运行(例如,可以在单独的容器中启动)。具有多个
slot
意味着更多
subtask
共享同一 JVM。同一 JVM 中的
task
共享 TCP 连接(通过多路复用)和心跳信息。它们还可以共享数据集和数据结构,从而减少了每个
task
的开销。

上边例子,从图所示 5 个
subtask
用 5 个
task slot
来执行,一定是这样分配的吗?
这个还真不一定,默认情况下,上边例子只需要 2 个
slot
就可以了。

我们再看另外一个例子,当我们把并行度调大为 6。

按照并行度拆开这个任务(
task
),我们发现会有 13 个
subtask
,那么是不是就意味着需要 13 个
slot
才能执行该任务呢?
答案是否定的,实际是只需要 6 个
slot
就够了。
为什么会这样呢?我们来看两条规则:
- 1️⃣ 默认情况下,Flink 允许子任务共享
slot,即使他们是不同任务的子任务。这样的结果就是一个slot可以保存作业的整个pipeline。 - 2️⃣ Task Slot 是静态的概念,指的是 TaskManager 具有的并发执行能力。

实际上,第一个
slot
会运行 3 个
subtask
,也就是执行 3 个线程。
前面也提到了
slot
只是做了内存隔离,并没有做 CPU 隔离,但是 CPU 资源是有限的,所以我们在设置资源参数时,需要考虑一下集群可提供的资源。

那么问题又来了,上面这个图中所示需要 5 个
task slot
,但是默认情况下 Flink 会自动优化成为需要 2 个
slot
,如果我们不想使用默认的
slot
个数来执行呢,那就要通过
slot
共享组来实现了。
DataStream<String> inputDataStream = env.socketTextStream(host, port);DataStream<Tuple2<String,Integer>> resultStream = inputDataStream.flatMap(newWordCount.MyFlatMapper()).slotSharingGroup("green").keyBy(0).sum(1).setParallelism(2).slotSharingGroup("red");
resultStream.print().setParallelism(1);
这几行代码几个
subtask
?并行度是多少?用几个
task slot
?
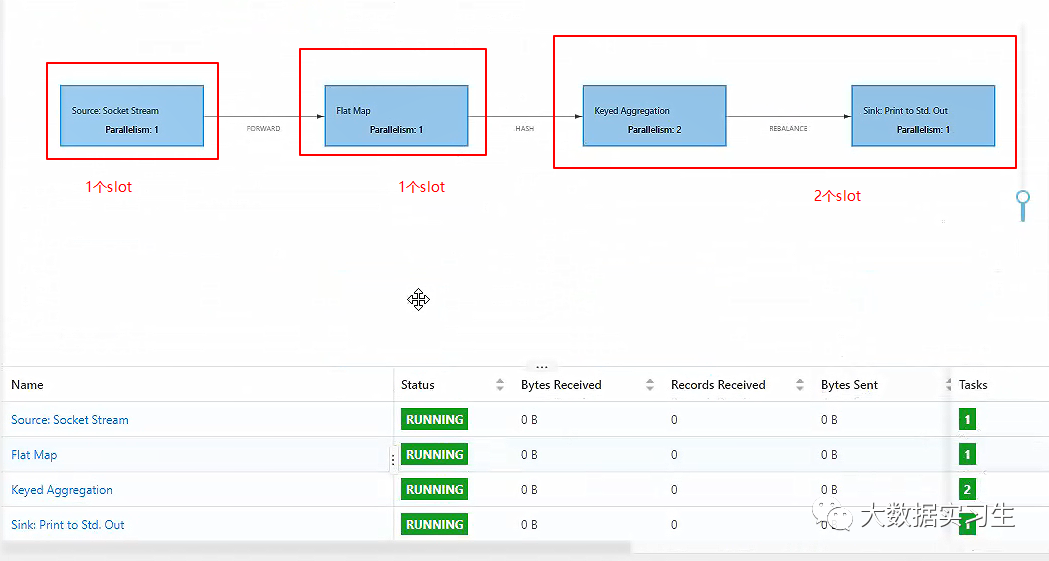
看一下以上代码运行时 Flink Web UI:

从 Web UI 界面可以看出,该任务被切分成了 5 个子
task
,按照最大并行度算子来算,这个任务的并行度应该为 2,那么这 5 个
subtask
占用了几个
slot
呢?
通过设置
slotSharingGroup
,是手动干预
slot
分配的手段之一,默认情况下,整个 StreamGraph 都会用一个默认的
default
SlotSharingGroup
,即所有的
task
都可以共用一个
slot
。
上面代码里,
source
算子并没有显式分配
slot
共享组,所以它将被分在默认的
default
共享组里,而
flatMap
算子被显式指定到了
green
共享组里,聚合算子同样被显式指定到了
red
共享组里,那么最后的
sink
算子呢?注意,默认情况下,每一个算子会与其前一个算子保持在同一个共享组内,所以
sink
算子(也就是上边的打印算子)也会被分配在
red
共享组里,按照
slot
共享组进行分组,每个分组最大的并行度相加,就是这个任务所占用的总共
slot
,所以应该是 4 个。
5.总结
通过上面几个例子,我们已经很清楚的理解这些概念了,总结以下几点:
- 1️⃣ Flink 中
slot是任务执行所申请资源的最小单元,同一个 TaskManager 上的所有slot都只是做了内存分离,并没有做 CPU 隔离。 - 2️⃣ 每一个 TaskManager 都是一个 JVM 进程,如果某个 TaskManager 上只有一个
slot,这意味着每个task组都在单独的 JVM 中运行,如果有多个slot就意味着更多subtask共享同一 JVM。 - 3️⃣ 一般情况下有多少个
subtask,就是有多少个并行线程,而并行执行的subtask要发布到不同的slot中去执行。 - 4️⃣ Flink 默认会将能链接的算子尽可能地进行链接,也就是算子链,Flink 会将同一个算子链分组内的
subtask都发到同一个slot去执行,也就是说一个slot可能要执行多个subtask,即多个线程。 - 5️⃣ Flink 可以根据需要手动地将各个算子隔离到不同的
slot中。 - 6️⃣ 一个任务所用的总共
slot为所有资源隔离组所占用的slot之和,同一个资源隔离组内,按照算子的最大并行度来分配slot。
版权归原作者 G皮T 所有, 如有侵权,请联系我们删除。