
在 eCommerce 里的应用中,我们可以对图像来进行搜索从而达到更好的应用体验。如果你之前阅读过我的文章 “Elasticsearch:如何使用 Elasticsearch 和 Python 构建面部识别系统”,可能对这个并不陌生。我们可以通过对图片的处理,把它变成向量,然后我们再进行向量搜索,从而达到搜索的目的。
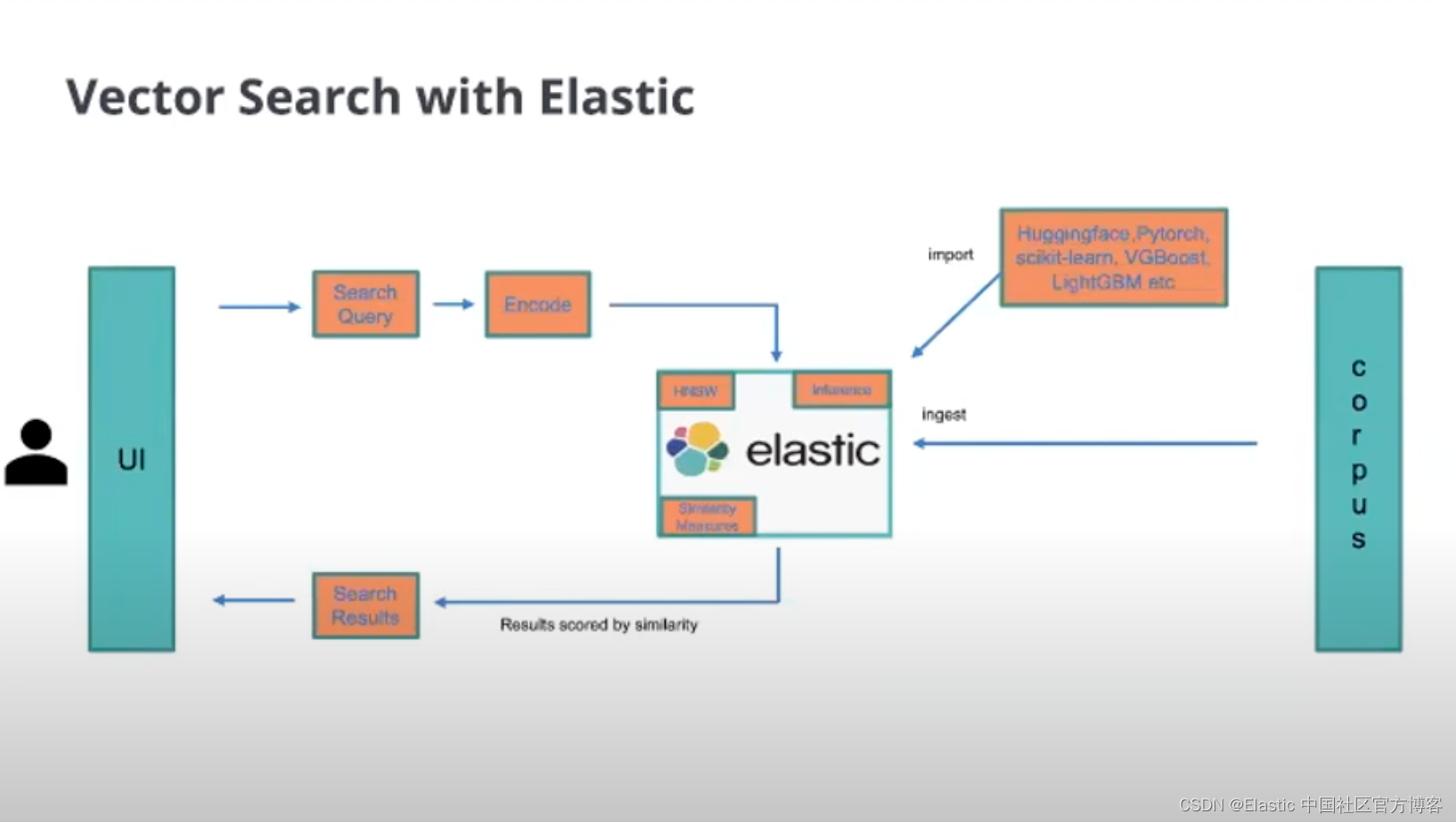
在今天的 demo 中,我们来展示如何使用 Elasticsearch 来搜素图片。展示的代码可以在 GitHub - liu-xiao-guo/flask-elastic-nlp 找到。我们可以使用如下的命令来下载代码:
git clone https://github.com/liu-xiao-guo/flask-elastic-nlp
前提条件
你首先需要安装 Elasticsearch v8.3.0+ 及 Python v3.9+。你需要安装如下的5个 NLP 的模型:
- dslim/bert-base-ner
- sentence-transformers/clip-ViT-B-32-multilingual-v1
- distilbert-base-uncased-finetuned-sst-2-english
- bert-base-uncased
- sentence-transformers/msmarco-MiniLM-L-12-v3
- deepset/tinyroberta-squad2
Elasticsearch 资源
要并行运行所有模型,你将需要约 21GB 的内存,因为模型已加载到内存中。
如果你的计算机没有足够的内存,那么你可以配置更少的内存,并且始终只同时运行 1 或 2 个模型,具体取决于您有多少可用内存。 要更改 docker-compose 的值,请转到 es-docker/.env 文件并更改 MEM_LIMIT。这个非常重要。如果你的电脑没有足够的内存,而你配置 21G,极有可能你的 docker 运行不起来。我们需要调整 .env 文件里的内存大小。你如果是在 macOS 上,你可以调整如下的内存配置:

安装 Elastic Stack
我们首先来安装 Elasticsearch 及 Kibana。我们进入到 es-docker 目录中:
$ pwd
/Users/liuxg/python/flask-elastic-nlp
$ cd es-docker/
$ ls -al
total 24
drwxr-xr-x 4 liuxg staff 128 Aug 23 14:42 .
drwxr-xr-x 18 liuxg staff 576 Aug 23 10:24 ..
-rw-r--r-- 1 liuxg staff 733 Aug 23 15:43 .env
-rw-r--r-- 1 liuxg staff 4599 Aug 23 14:52 docker-compose.yml
$ docker-compose up
在运行上面的命令之前,我们可以查看当前目录下的 .env 文件的配置。针对我的情况,我修改了最新的 Elastic Stack 版本为8.3.3。执行上面的命令后,它会自动下载 Elasticsearch 及 Kibana 的镜像,并启动 docker;
在这期间,如果你的安装挂掉了,极有可能是你的内存不够而造成的。你需要修改当前目录下的 .env 文章中的这个项:
MEM_LIMIT=21474836480
如果我的安装成功的话,我们可以使用如下的命令来查看:
curl -k -u elastic:changeme https://localhost:9200
$ curl -k -u elastic:changeme https://localhost:9200
{
"name" : "es01",
"cluster_name" : "elastic-nlp-8.3.3",
"cluster_uuid" : "RWAp5DntThedGCsN0Ae3Pw",
"version" : {
"number" : "8.3.3",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "801fed82df74dbe537f89b71b098ccaff88d2c56",
"build_date" : "2022-07-23T19:30:09.227964828Z",
"build_snapshot" : false,
"lucene_version" : "9.2.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
如果你看到上面的输出,则标明你的 Elasticsearch 的安装是成功的。我们也可以打开地址 http://localhost:5601 来登录 Kibana:
我们可以通过如下的命令来查看运行中的 docker 容器:
docker ps
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a2393f9bd322 docker.elastic.co/kibana/kibana:8.3.3 "/bin/tini -- /usr/l…" 13 minutes ago Up 13 minutes (healthy) 0.0.0.0:5601->5601/tcp elastic-nlp_kibana_1
4ba6f28c6492 docker.elastic.co/elasticsearch/elasticsearch:8.3.3 "/bin/tini -- /usr/l…" 13 minutes ago Up 13 minutes (healthy) 0.0.0.0:9200->9200/tcp, 9300/tcp elastic-nlp_es01_1
从上面的输出中,我们可以看出来有两个容器在运行:一个是 Elasticsearch 而另外一个是 Kibana。
配资 Python env
为了避免我们的 Python 安装和系统的安装混在一起,我们执行如下的命令:
$ cd flask-elastic-nlp
$ python3 -m venv .venv
$ source .venv/bin/activate
$ pip install -r requirements.txt
在安装 requirements.txt 中的 Python 包时,我们可能会遇到有些安装包不存在,这个主要看你是从哪里进行安装的。我对 requirements.txt 做了一点修改。它最终的内容是这样的:
requirements.txt
flask==2.0.2
wtforms==3.0.1
flask-wtf==1.0.1
python-dotenv==0.19.2
Werkzeug~=2.0.3
sentence-transformers~=2.2.0
ftfy~=6.1.1
# image-embeddings
pandas~=1.3.5
elasticsearch~=8.3.3
Pillow~=9.0.1
tqdm~=4.62.3
# eland
eland~=8.2.0
torch~=1.11.0
torchvision~=0.13.1
transformers~=4.19.2
这样我们的 Python 环境就配置好了。
上传 NLP 模型
让我们将模型加载到应用程序中。 我们使用 eland python 客户端来加载模型。 有关更多详细信息,请遵循文档。我们也可以参考文章 “Elasticsearch:使用向量搜索来查询及比较文字 - NLP text embedding” 来上传模型。在上面安装 Python 的过程中,我们已经安装好 eland。我们可以直接使用如下的命令来上传模型:
# wait until each model is loaded and started. If you do not have enough memory, you will see errors sometimes confusing
$ eland_import_hub_model --url https://elastic:changeme@localhost:9200 --hub-model-id dslim/bert-base-NER --task-type ner --start --insecure
$ eland_import_hub_model --url https://elastic:[email protected]:9200 --hub-model-id sentence-transformers/clip-ViT-B-32-multilingual-v1 --task-type text_embedding --start --insecure
$ eland_import_hub_model --url https://elastic:[email protected]:9200 --hub-model-id distilbert-base-uncased-finetuned-sst-2-english --task-type text_classification --start --insecure
$ eland_import_hub_model --url https://elastic:[email protected]:9200 --hub-model-id bert-base-uncased --task-type fill_mask --start --insecure
$ eland_import_hub_model --url https://elastic:[email protected]:9200 --hub-model-id sentence-transformers/msmarco-MiniLM-L-12-v3 --task-type text_embedding --start --insecure
$ eland_import_hub_model --url https://elastic:[email protected]:9200 --hub-model-id deepset/tinyroberta-squad2 --task-type question_answering --start --insecure
我们在项目的根目录中分别打入上面的命令:
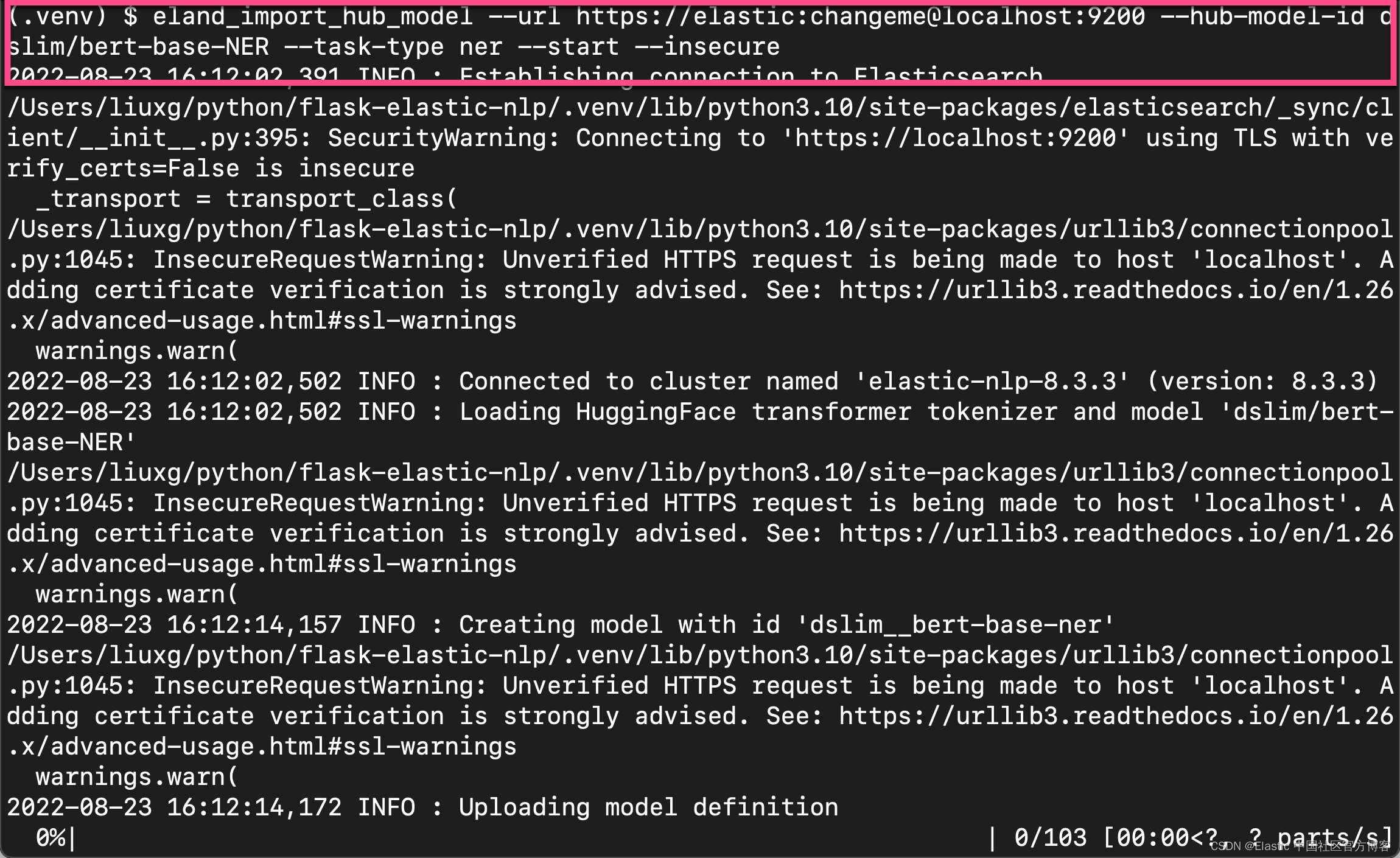
我们回到 Kibana 的界面:
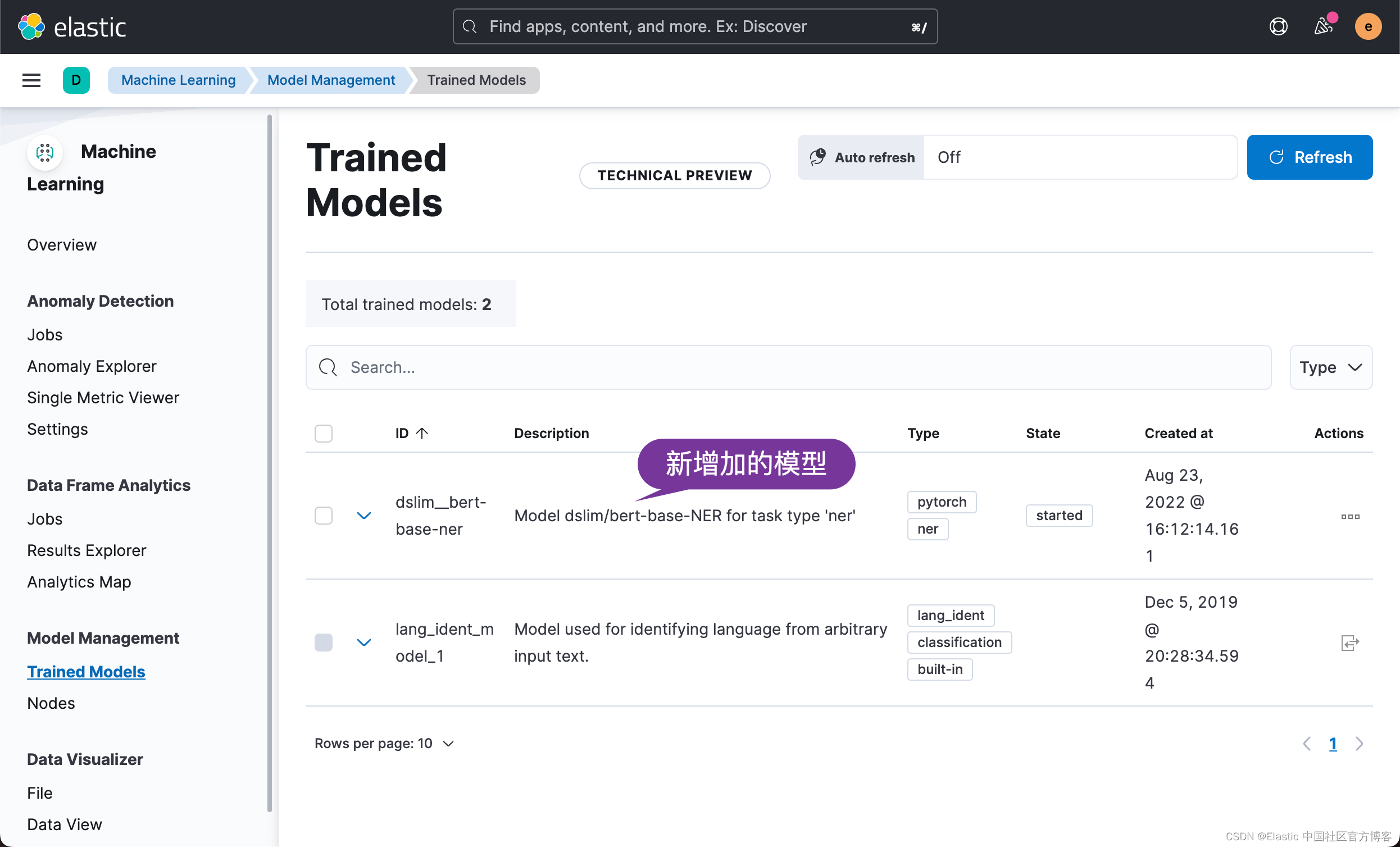
我们按照同样的方法把剩下的4个模型都上传到 Elasticsearch 中:

这样我们最终看到所有的模型都被上传了:
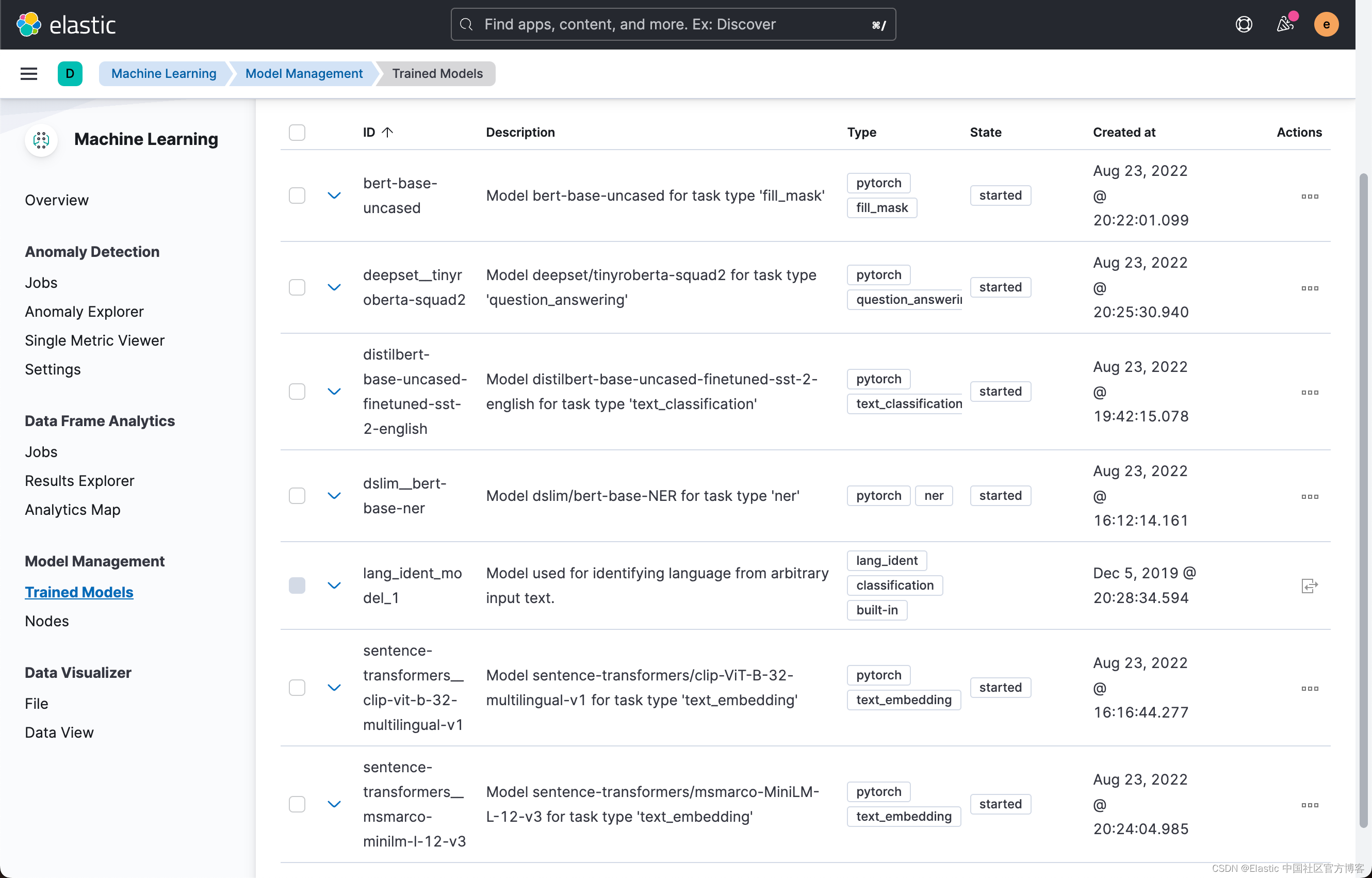
如果你在屏幕中看到缺少某些模型并看到一条消息。 需要 ML 作业和经过训练的模型同步,继续并单击链接以同步模型。
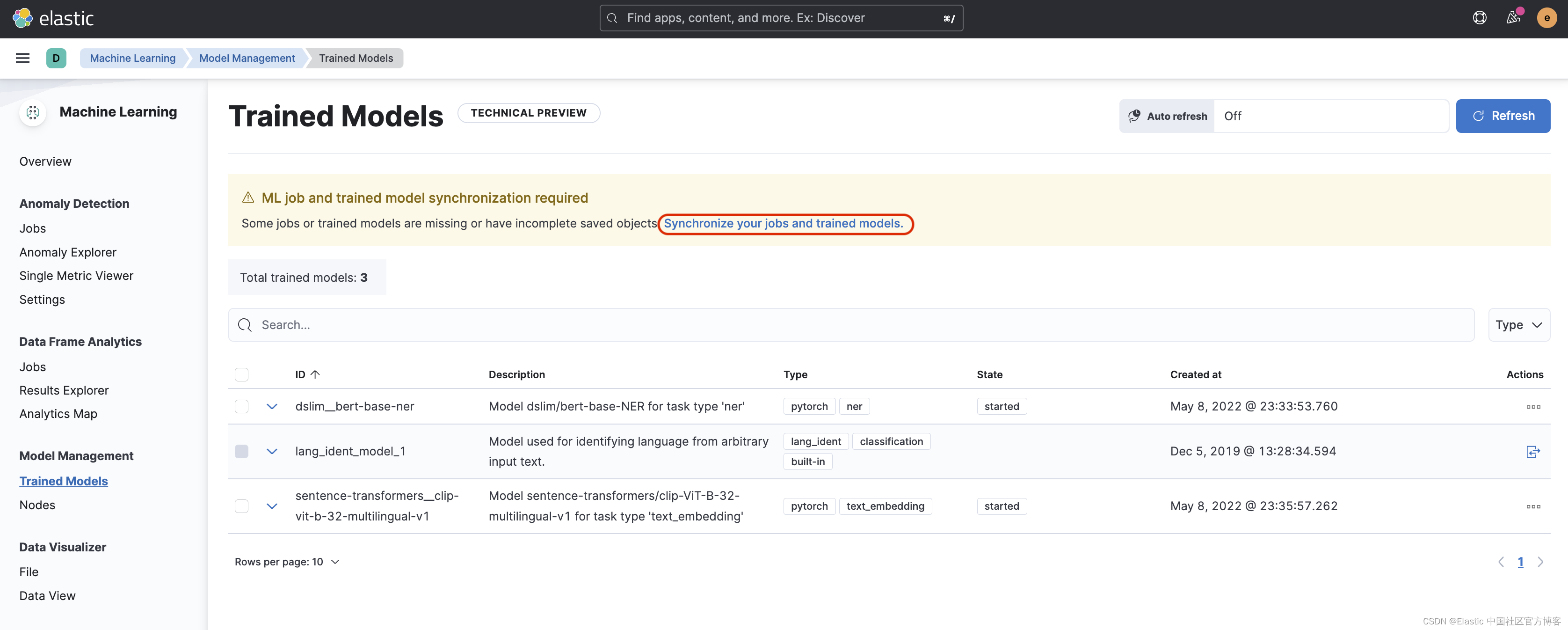
导入数据索引
我们还需要在烧瓶应用程序中使用的数据索引。 在此过程中,脚本还将从 Unsplash 下载数据集。
确保设置了 Python 环境。
$ cd embeddings
$ python3 build-datasets.py --es_host "https://127.0.0.1:9200" --es_user "elastic" --es_password "changeme" --no-verify_certs --delete_existing
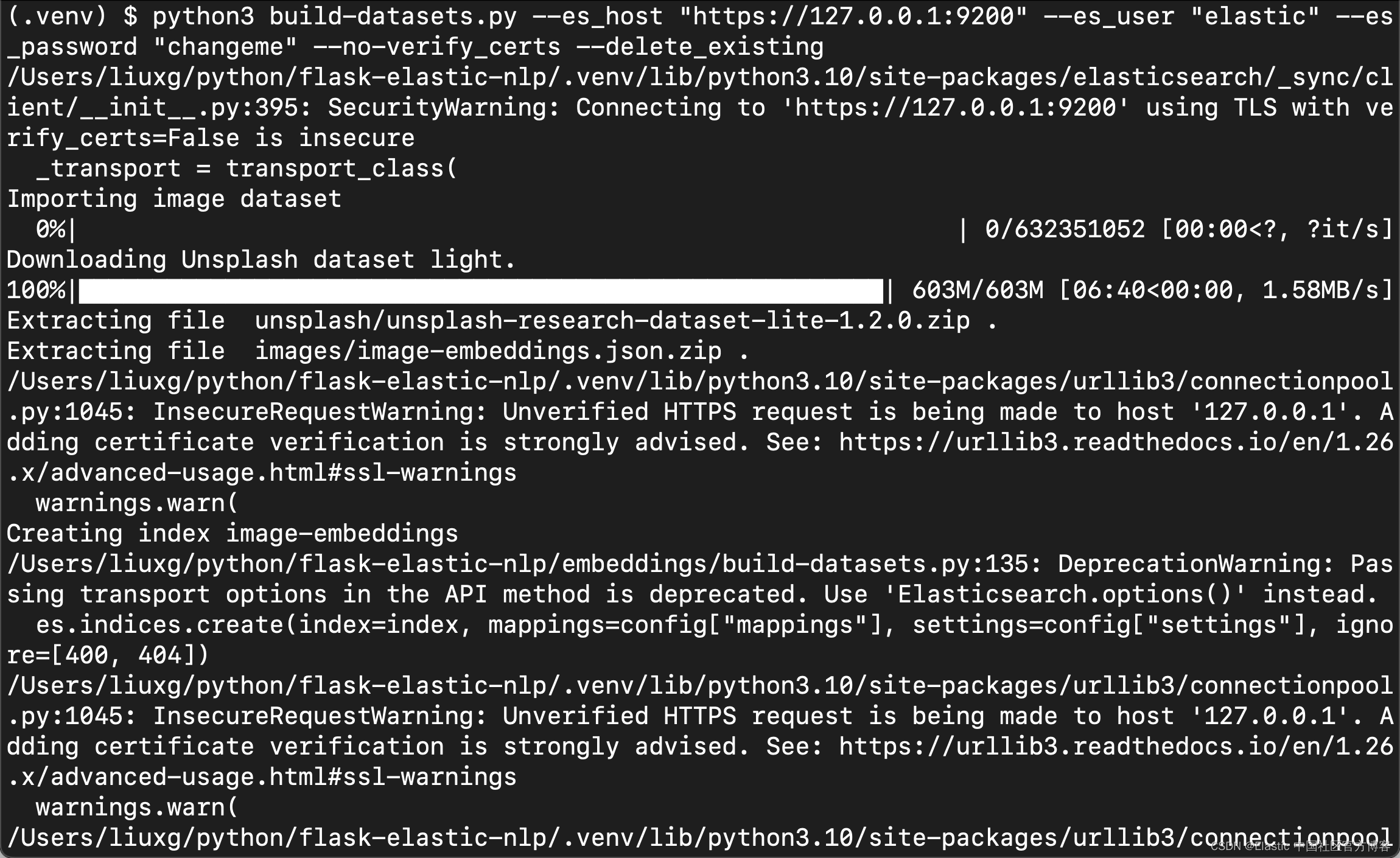
等运行完上面的命令后,我们会发现:
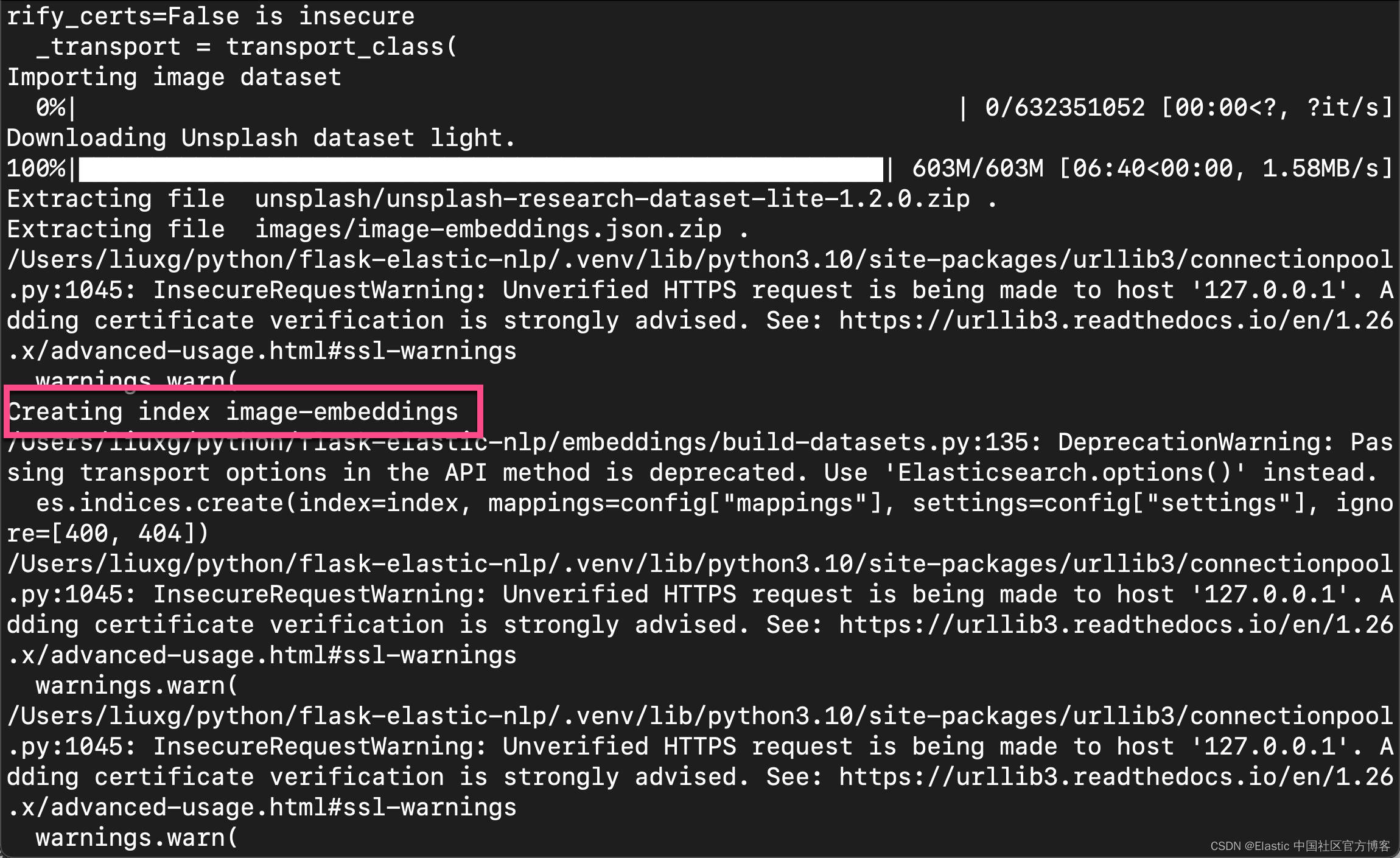
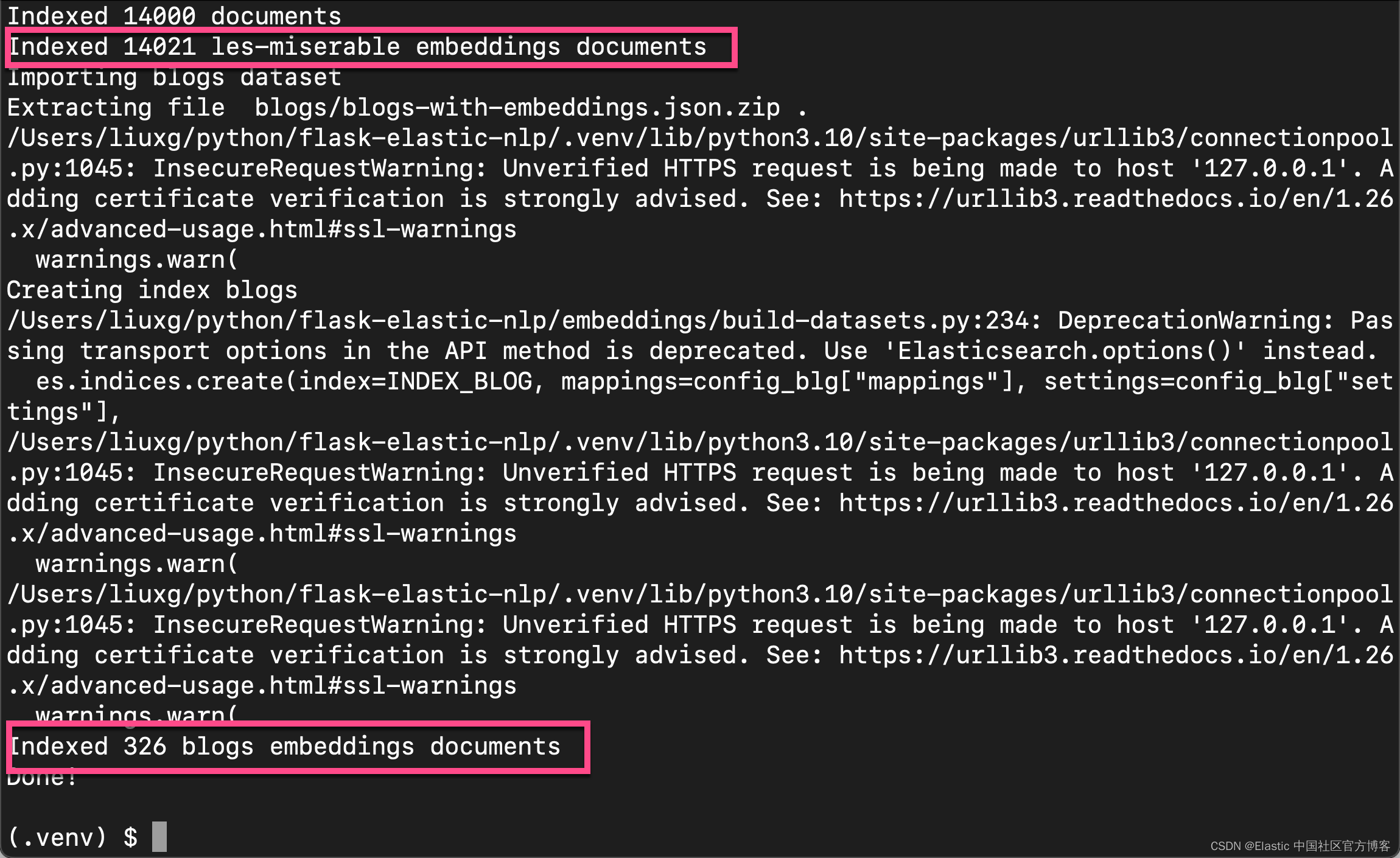
这里的 blogs 也就是我们在另外一篇文章 “Elasticsearch:使用向量搜索来查询及比较文字 - NLP text embedding” 中使用到的索引。 我们可以通过如下的命令来查看新生成的索引:
GET _cat/indices
上面的命令返回:
yellow open image-embeddings sO3-86hmQ_e9fg1uaYw9Xw 1 1 19833 0 197.4mb 197.4mb
yellow open blogs JiZuoqCFQkapgMgpeM0D-Q 1 1 326 0 3.8mb 3.8mb
yellow open les-miserable-embedded ZExnlOVnShC5P_2wdIdvhw 1 1 14021 0 107mb 107mb
从上面的输出中,我们可以看到有三个索引被生成。我们可以通过如下的命令来查看每个索引的 mapping:
GET image-embeddings/_mapping
{
"image-embeddings": {
"mappings": {
"properties": {
"ai_description": {
"type": "text"
},
"exif_camera_make": {
"type": "keyword"
},
"exif_camera_model": {
"type": "keyword"
},
"exif_iso": {
"type": "integer"
},
"image_embedding": {
"type": "dense_vector",
"dims": 512,
"index": true,
"similarity": "cosine"
},
"photo_description": {
"type": "text"
},
"photo_id": {
"type": "keyword"
},
"photo_image_url": {
"type": "keyword"
},
"photo_url": {
"type": "keyword"
},
"photographer_first_name": {
"type": "keyword"
},
"photographer_last_name": {
"type": "keyword"
},
"photographer_username": {
"type": "keyword"
}
}
}
}
}
从上面,我们可以看出来 image_embedding 字段是一个 512 维度的 dense_vector 字段。它可以进行向量搜索。
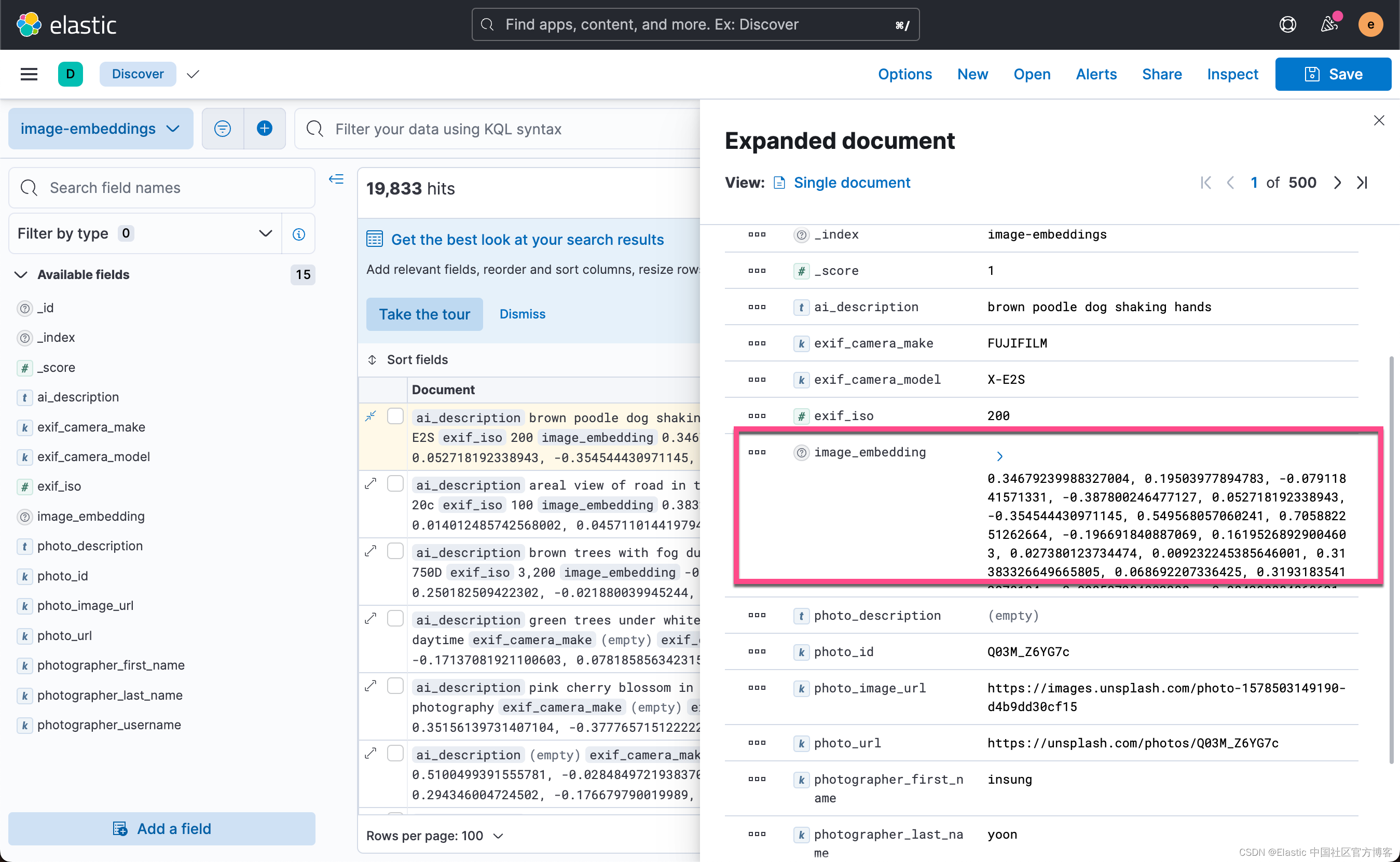
运行 Flash App
确保设置了 Python 环境。
# In the main directory
# !!! configure file `.env` with values pointing to your Elasticsearch cluster
$ flask run --port=5001
# Access URL `127.0.0.1:5001`
我们在电脑的浏览器中打开 http://localhost:5001:
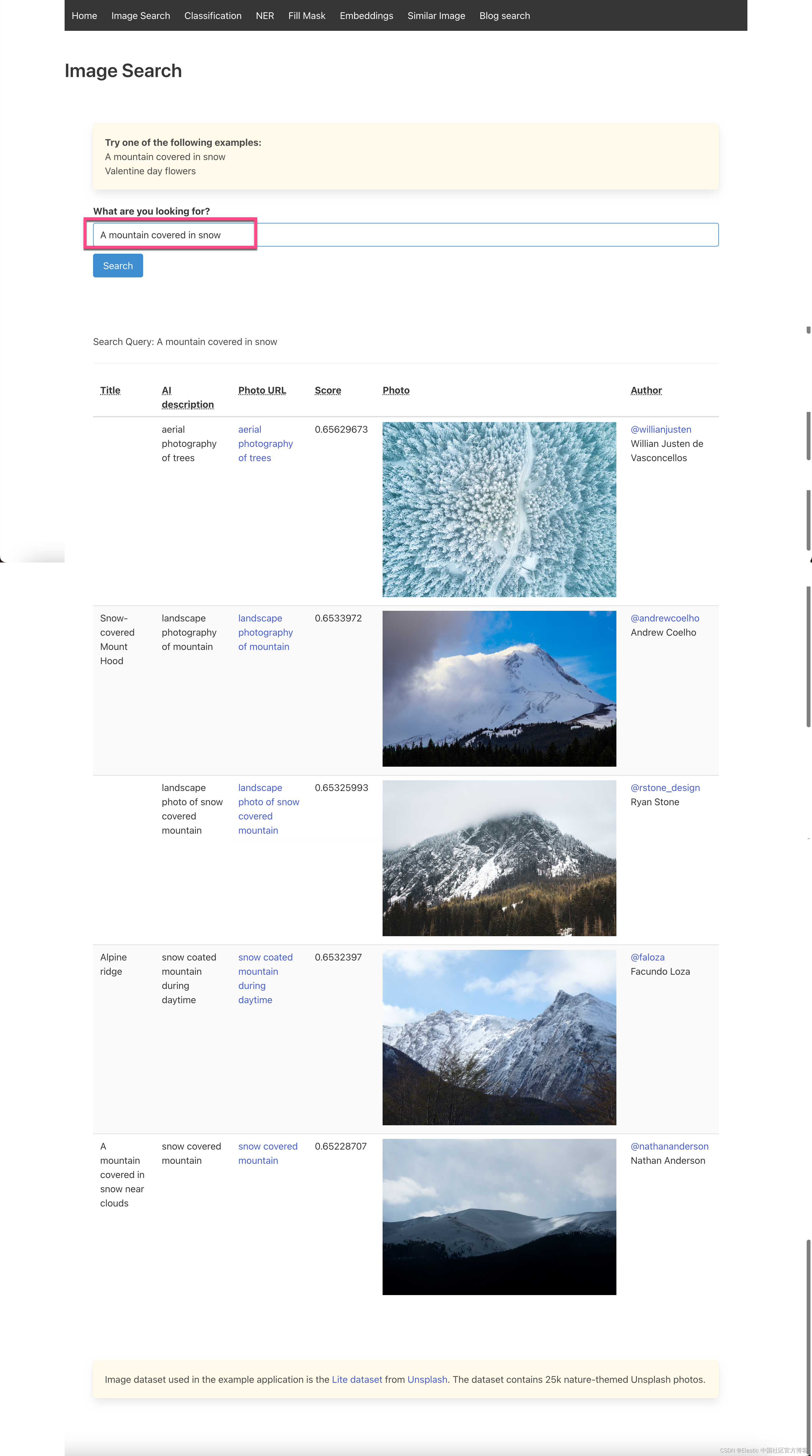
当我们输入 “A mountain covered in snow” 时,我们可以看到上面显示的画面。我们也可以使用上面的另外一个例子 “Valentine day flowers”,我们可以看到如下的搜索结果:

我打入了一个中文的句子 “我喜欢北京”:
我们也可以搜索一个相同的图片,比如我们搜索如下的图片:

我们进行搜索:
从上面,我们可以看到被搜索出来的图片。
版权归原作者 Elastic 中国社区官方博客 所有, 如有侵权,请联系我们删除。