
一、前言
与其他的数据存储引擎类似,clickhouse承载着大数据量级的数据存储,对于数据的备份与恢复也是必须考虑的,本文将通过操作演示下如何对clickhouse数据进行备份与恢复。
官网说明:
官网备份操作说明
clickhouse可以通过手动进行数据恢复,也可以通过工具进行恢复;
二、clickhouse 数据手动备份与恢复演示
ClickHouse 允许使用 ALTER TABLE ... FREEZE PARTITION ... 查询以创建表分区的本地副本。
这是利用硬链接(hardlink)到 /var/lib/clickhouse/shadow/ 文件夹中实现的,所以它通常不会因为旧数据而占用额外的磁盘空间。 创建的文件副本不由 ClickHouse 服务器处理,所以不需要任何额外的外部系统就有一个简单的备份。防止硬件问题,最好将它们远程复制到另一个位置,然后删除本地副本。
在正式操作之前,再温馨提示下,clickhouse使用rpm的方式安装时,几个安装后的数据文件目录位置:
bin/ /usr/bin
conf/ /etc/clickhouse-server
lib/ /var/lib/clickhouse
log/ /var/log/clickhouse
2.1 数据准备
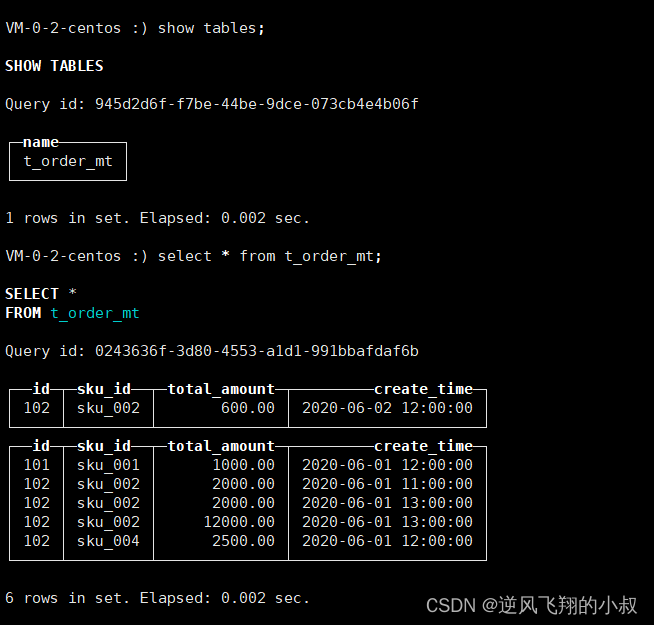
在默认的数据库下,之前我们创建了下面这张表,并且有几条数据;
2.2 创建备份路径
创建用于存放备份数据的目录 shadow,如果之前目录存在,先清空目录下的数据

2.3 执行备份命令
echo -n 'alter table t_order_mt freeze' | clickhouse-client
或者在客户端命令行执行
alter table t_order_mt freeze;
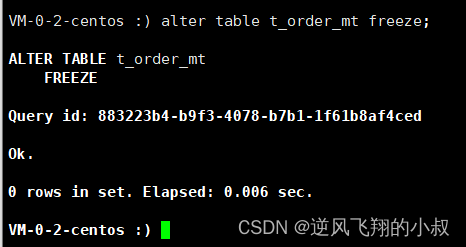
注意:使用了冻结命令之后并不会锁表
执行完毕上面的命令之后,在shadow目录下会多出下面的几个目录和相关的文件

一路cd进去,可以发现里面其实就是存放了按照分区存放的数据;

2.4 **将备份数据保存到其他路径 **
以上shadow相当于是数据文件备份的一个中间临时目录,因此需要将备份数据转移到其他目录,方便后面进行数据恢复时使用,按照下面的步骤依次执行;
#创建备份存储路径
sudo mkdir -p /var/lib/clickhouse/backup/
#拷贝数据到备份路径
sudo cp -r /var/lib/clickhouse/shadow/ /var/lib/clickhouse/backup/my-backup-name
#为下次备份准备,删除 shadow 下的数据
sudo rm -rf /var/lib/clickhouse/shadow/*
执行过程


ClickHouse 是使用文件系统硬链接来实现即时备份,而不会导致 ClickHouse 服务停机(或
锁定)。这些硬链接可以进一步用于有效的备份存储。在支持硬链接的文件系统(例如本地
文件系统或 NFS)上,将 cp 与-l 标志一起使用(或将 rsync 与–hard-links 和–numeric-ids 标志 一起使用)以避免复制数据。*注意:仅拷贝分区目录,注意目录所属的用户要是 **clickhouse *
2.5 数据恢复
模拟删除备份过的表
drop table t_order_mt;

重新创建表
create table t_order_mt(
id UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,sku_id);

将备份复制到 detached 目录
执行下面的命令
sudo cp -rl /var/lib/clickhouse/backup/my-backup-name/1/store/ecc/ecce0769-b776-4d10-acce-0769b776ed10/* /var/lib/clickhouse/data/default/t_order_mt/detached/

执行 attach命令
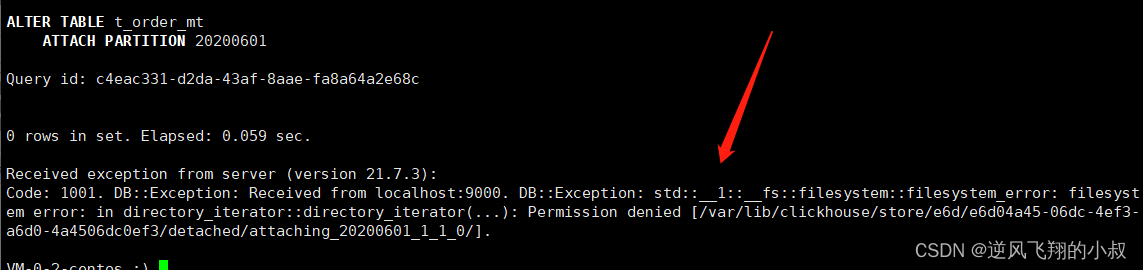
执行时如果出现上面的报错,说明clickhouse这个用户无操作权限,需要做一下授权

然后再次执行上面的attach命令,这时就attach成功了
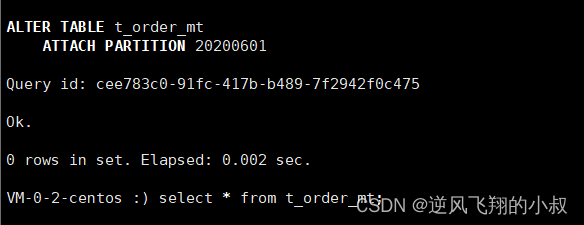
执行完成后,查询下当前这张表,发现数据就恢复回去了

三、使用 clickhouse-backup做数据备份与恢复
上面,我们演示了手动做clickhouse的数据备份与恢复的过程,过程还是有点麻烦的,其实我们可以使用 Clickhouse 的备份工具 clickhouse-backup 帮我们自动化实现,工具地址:
clickhouse-backup 工具下载地址
前置准备
1、上传安装包工具

2、使用rpm安装
sudo rpm -ivh clickhouse-backup-1.0.0-1.x86_64.rpm

注意:安装完毕后,默认在 /etc/clickhouse-backup/ 目录下

3、配置相关文件
配置文件大概长下面这样,核心要配置的文件默认情况下主要是下面几个
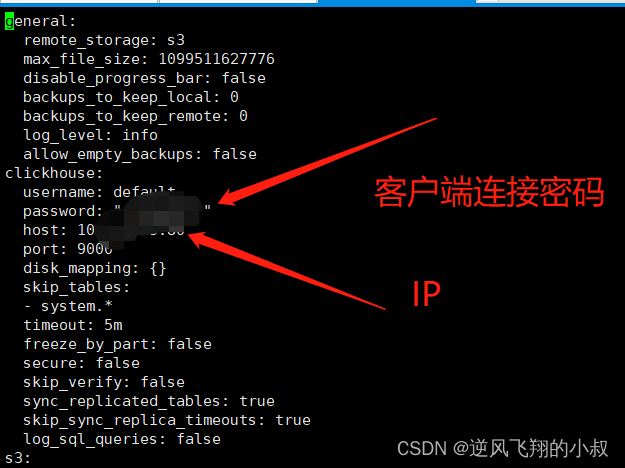
常用操作命令与数据表的备份操作
1、查看可用命令
clickhouse-backup help

2、显示要备份的表
clickhouse-backup tables

3、查看现有的本地备份
clickhouse-backup list
执行这个命令,发现上面我们做手动备份时候创建的目录被识别到了

注意,为了不影响后面使用命令备份数据造成混淆,建议先把之前的该目录下文件删除掉
4、创建备份
sudo clickhouse-backup create

执行完成后,在 : /var/lib/clickhouse/backup 目录下就产生了新的备份数据;
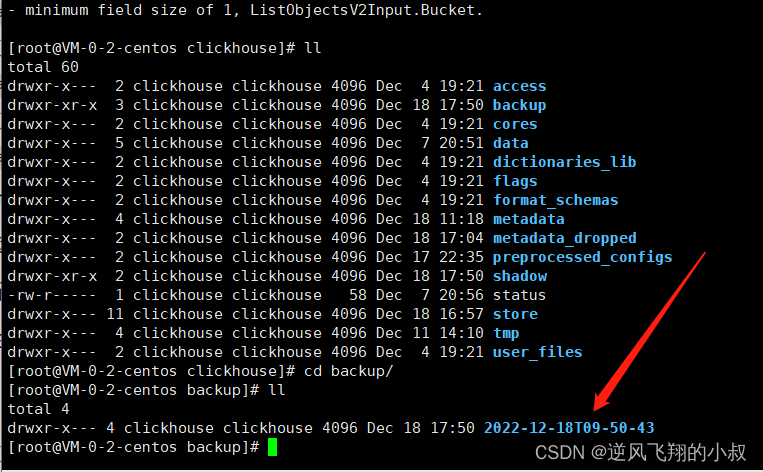
通过这种方式备份出来的数据和文件,看起来包含的内容更加全面
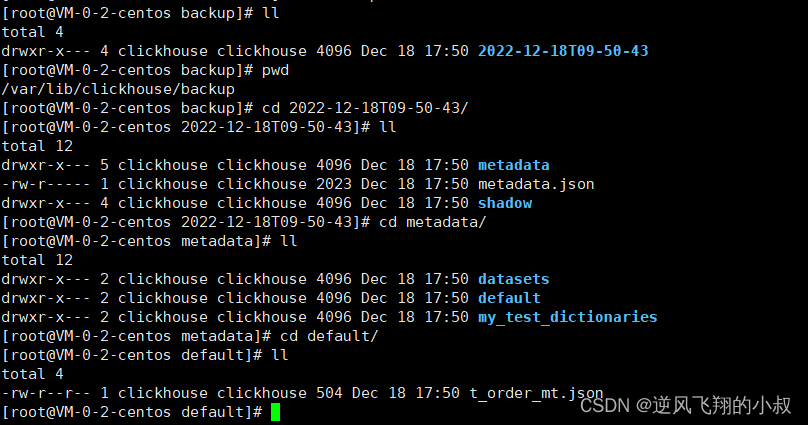
数据恢复操作
1、模拟删除备份过的表
删除default数据库
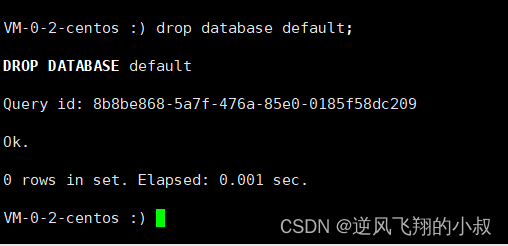
2、从备份还原
执行下面的命令进行数据恢复
sudo clickhouse-backup restore 2022-12-18T09-50-43
相关参数补充说明
--schema 参数:只还原表结构;
--data 参数:只还原数据;
--table 参数:备份(或还原)特定表。也可以使用一个正则表达式,例如,针对特定的
数据库:--table=dbname.*
执行这个命令时,会将系统中所有备份过的数据表都执行一次,如果已经存在了,会跳过
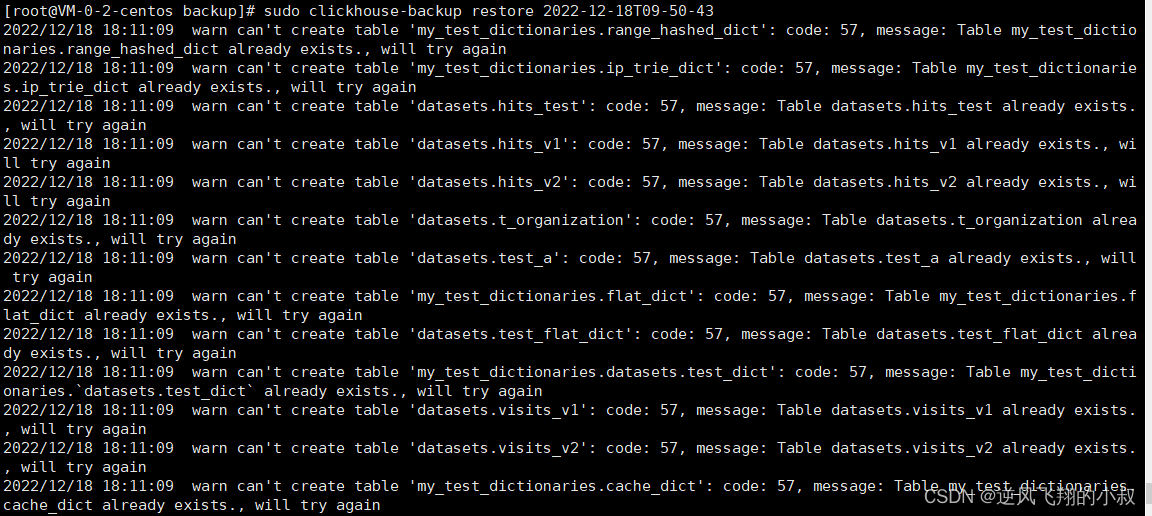
3、数据检查
可以发现数库和数据表已经恢复回来了
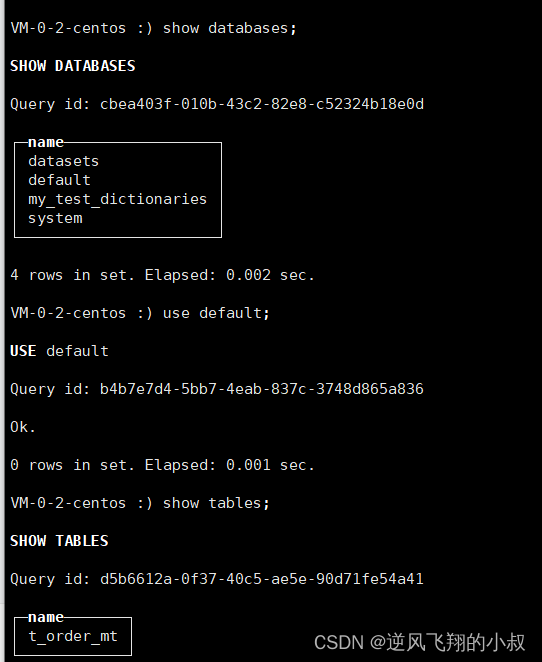
其他补充说明
1、api文档链接
2、注意事项
切勿更改文件夹/var/lib/clickhouse/backup 的权限,可能会导致数据损坏
3、关于远程备份说明
- 较新版本才支持,需要设置 config 里的 s3 相关配置;
- 上传到远程存储:sudo clickhouse-backup upload xxxx;
- 从远程存储下载:sudo clickhouse-backup download xxxx;
- 保存周期: backups_to_keep_local,本地保存周期,单位天;backups_to_keep_remote,远程存储保存周期,单位天;0 均表示不删除;
版权归原作者 逆风飞翔的小叔 所有, 如有侵权,请联系我们删除。