
一、实验目的
这次实验中,对bilibli的数据信息进行研究,通过运用大数据处理框架 Spark、Hadoop 及数据可视化技术,对这些数据进行存储、处理和分析,并对点赞、收藏、播放、视频类型分类。
本实验展示了如何利用Hadoop技术对Bilibili平台的数据进行分析,特别是关注每周的热门词条。这些分析可以帮助理解用户的喜好和趋势,为内容创作者和平台运营提供数据支持。未来的工作可以进一步扩展,包括更复杂的数据处理和更精细的分析技术应用。
二、实验环境
实验工具和技术
VMware 17:主要产品和服务包括虚拟机软件、云管理平台以及与云计算相关的各种解决方案。
CentOS 07:是一个基于开源代码的自由Linux发行版,它源自于Red Hat Enterprise Linux(RHEL)的开源代码。
jdk-8u241-linux-x64:JDK包括了Java编译器(javac)、Java运行时环境(JRE)、Java虚拟机(JVM)以及其他工具和库。
Hadoop 3.3.0:作为分布式计算框架,用于处理大规模数据。
MapReduce:用于编写分布式计算程序,处理和分析数据。
Mysql 5.7.29:MySQL广泛用于Web应用程序的后端数据存储和管理
Hive 3.1.2:用于数据清洗和预处理。
Python 3.11.0:爬取网站数据。
PyCharm 2023.2:筛取获取到的有用信息
DataGrip 2021.3.1:连接虚拟机hive数据库,以方便使用sql命令进行创建表格、修改表格等操作。
FinalShell 3.9.2.2:用于管理和连接远程服务器、虚拟机和云实例。
FIneBI 5.1:可视化工具用于生成数据报告和图表
1.配置VMware环境
在nat模式中配置 子网IP地址为192.168.88.0(与后续虚拟机的ip对应)
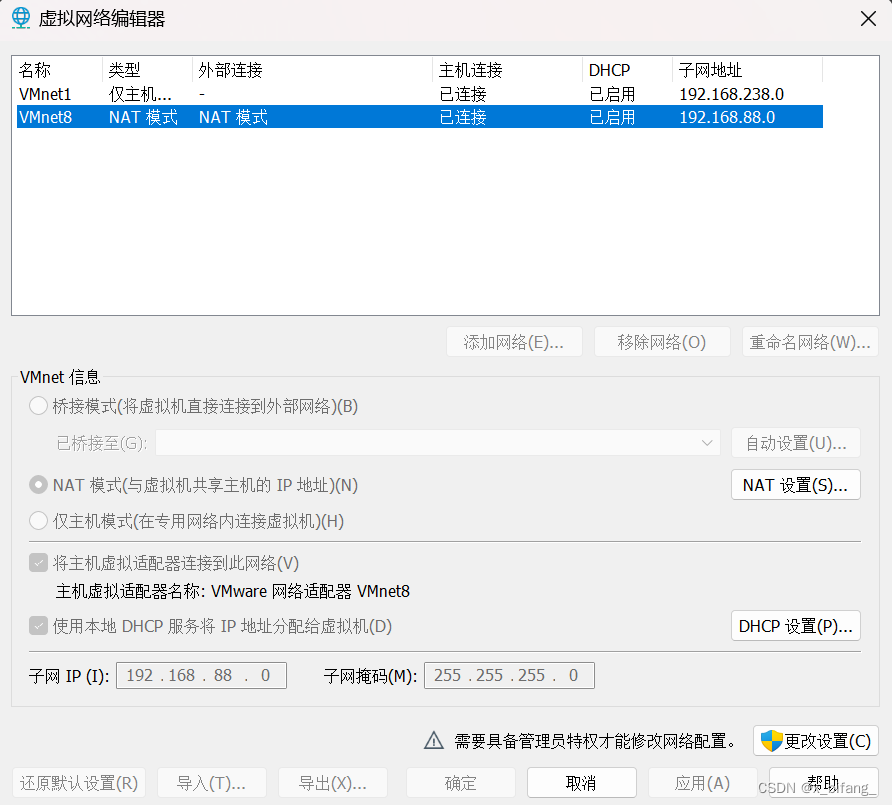
将网关地址改为192.168.88.2
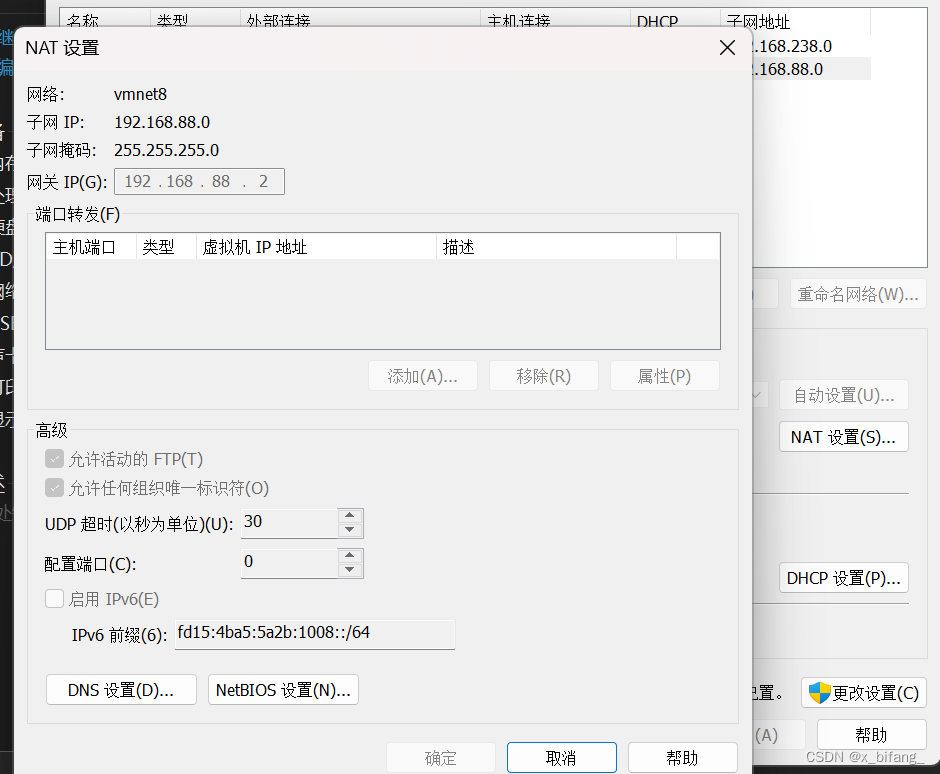
配置windows本地虚拟网卡

将第一台虚拟机导入 并登录
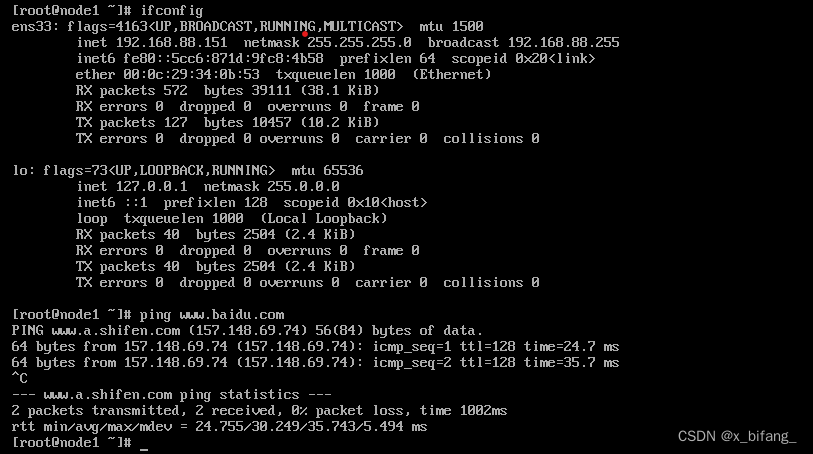
 验证是否安装成功
验证是否安装成功
安装第二台虚拟机,第二台虚拟机依赖于第一台虚拟机,所以要找到第一台的 .vmx文件
导入完成后验证第二台是否安装成功
第三台同第二台一样
2.FinalShell
配置windows上的host文件,使用主机名访问3台虚拟机
FinalShell连接node
3.Apache Hadoop 安装部署及集群搭建(分布式安装)
集群规划
主机
角色
node1
NN DN RM NM
node2
SNN DN NM
node3
DN NM
安装jdk1.8
查看一下三台虚拟机的名称

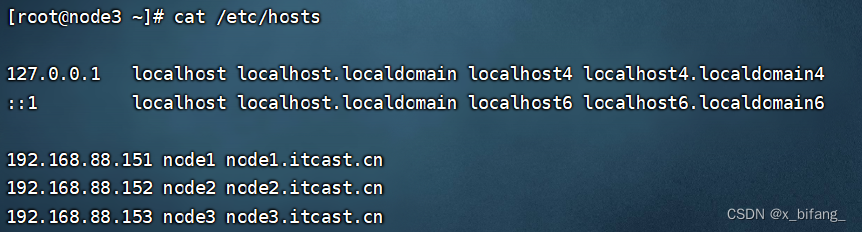
查看映射cat /etc/hosts
关闭防火墙 禁止开机启动firewalld服务
systemctl stop firewalld.service #停止firewalld服务
systemctl disable firewalld.service #开机禁用firewalld服务


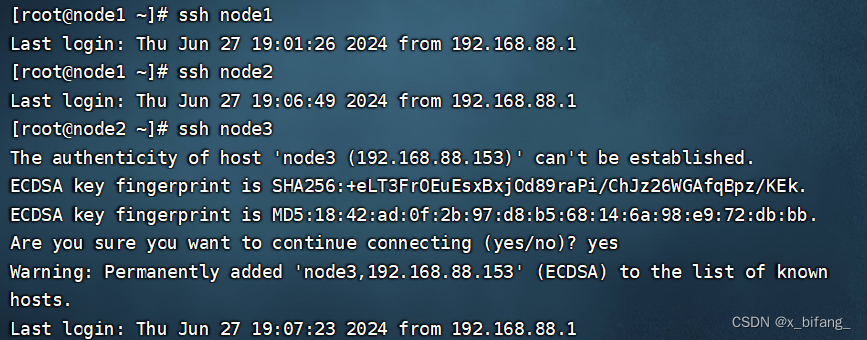
验证SSH免密登录功能
集群时间同步 ntpdate ntp5.aliyun.coml

创建data server software三个目录

上传安装包,解压安装包 在第一台机器安装,后发送给其他两台机器
jdk1.8安装在/export/server下 (拖拽即可)


解压并删除 tar -zxvf jdk-8u241-linux-x64.tar.gz
rm -rf jdk-8u241-linux-x64.tar.gz

配置环境变量 vim /etc/profile
重新加载环境变量文件 source /etc/profile 并验证安装是否成功

在node1绝对路径下 远程拷贝给其他虚拟机
jdk1.8:
scp -r /export/server/jdk1.8.0_241/ root@node2:/export/server/
scp -r /export/server/jdk1.8.0_241/ root@node3:/export/server/
环境变量:
scp /etc/profile root@node2:/etc/
scp /etc/profile root@node3:/etc/
重新加载环境变量文件 source /etc/profile node2/3 jdk安装成功
安装Hadoop
Hadoop修改环境变量
将hadoop安装包拖至/export/server


解压 删除
rm -rf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
tar -zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz

修改Hadoop配置文件
hadoop-env.sh
文件最后添加
export JAVA_HOME=/export/server/jdk1.8.0_241
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
core-site.xml
core-site.xml
<property><name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
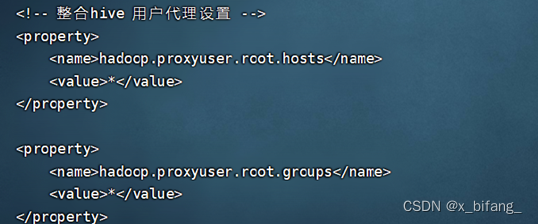
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
<name>fs.trash.interval</name>
<value>1440</value>
hdfs-site.xml
<property><name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
mapred-site.xml
<property><name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <property><name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property> <property><name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property> <property><name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property> <property><name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property> <property><name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>yarn-site.xml
<property><name>yarn.resourcemanager.hostname</name>
<value>node1</value>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property> <property><name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>workers
node1.itcast.cn
node2.itcast.cn
node3.itcast.cn
配置完成后使用scp同步给其他虚拟机 在node1 /export/server 目录下
scp -r hadoop-3.3.0 root@node2:$PWD
scp -r hadoop-3.3.0 root@node3:$PWD
将Hadoop添加到环境变量

将配置文件拷贝给node2与node3

重启环境变量 输出hadoop验证

格式化操作(初始化操作) NameNode format 只能使用一次

shell脚本一键启停 (需要配置好机器之间的SSH免密登录和workers文件)

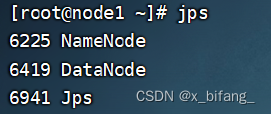
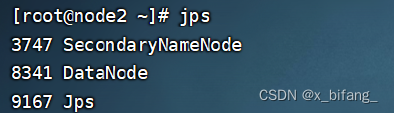
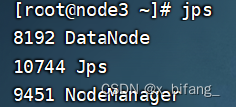

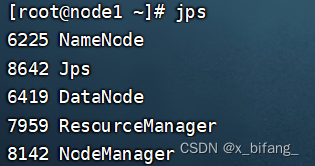
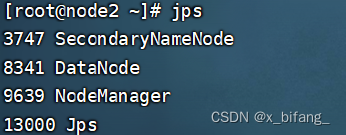

此时启动成功
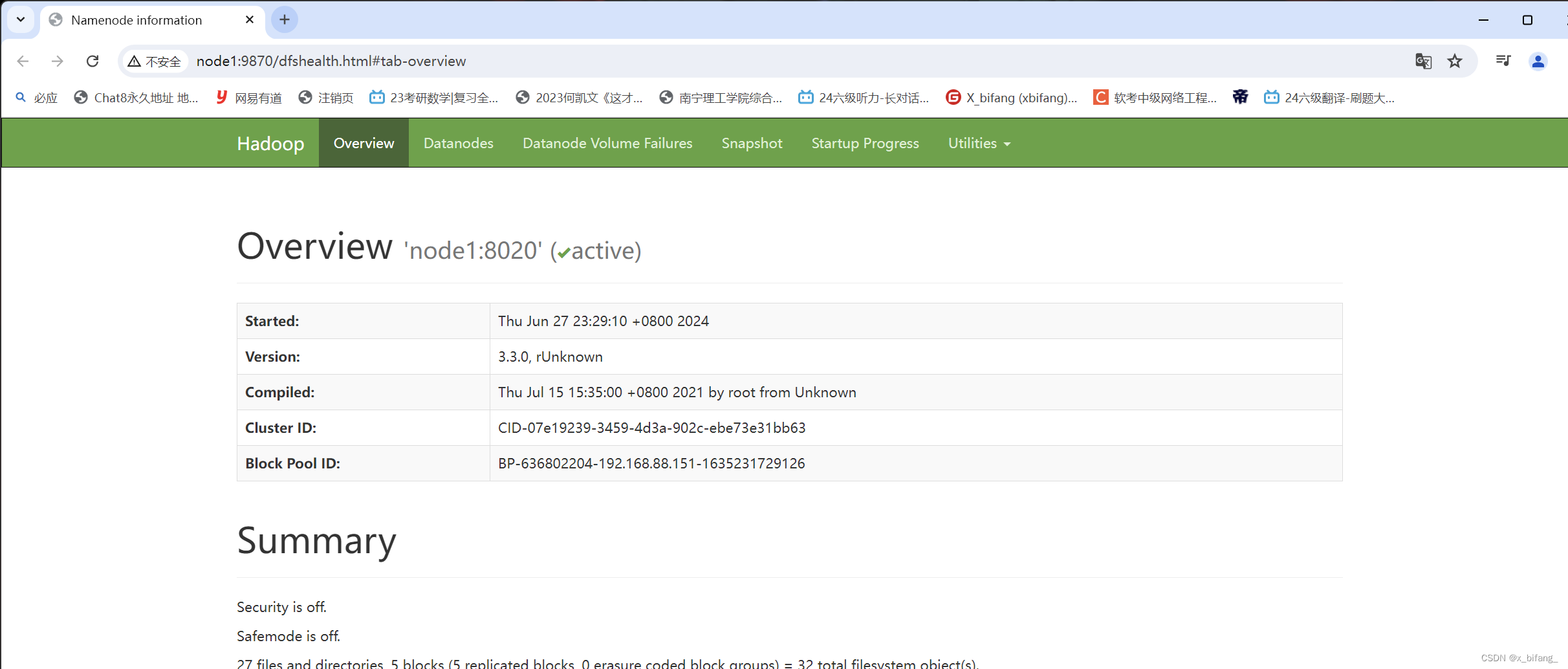
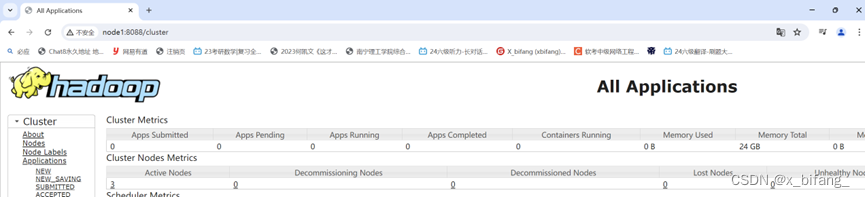
使用浏览器查看
HDFS集群:http://node1:9870/ YARN集群:http://node1:8088/
4.Apache hive安装部署(远程模式配置)
Hadoop与Hive整合

MySQL安装
在第一台机器上(node1)安装
卸载Centos7自带的mariadb

安装MySQL 创建mysql文件夹 上传MySQL安装包

解压MySQL安装包

安装依赖

安装MySQL

MySQL初始化 更改所属组 启动mysql

查看日志并查看临时密码


复制密码登录MySQL

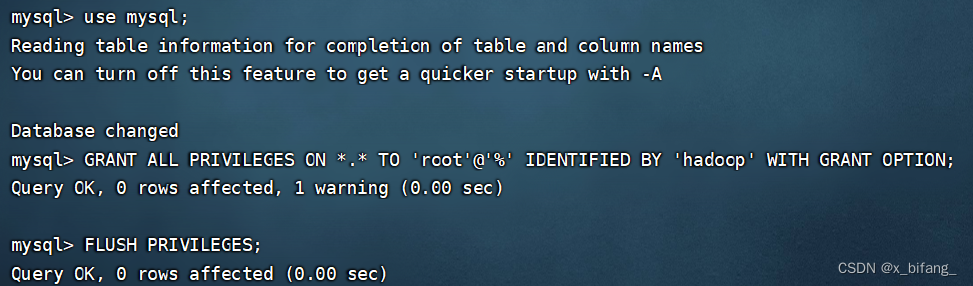
重设密码 这里设置为123456

授权

MySQL安装并启动成功

将MySQL设置为开机自启动
Hive安装(只需要一台虚拟机安装就可以)
安装包上传至安装目录下

解压Hive

解决Hive与Hadoop之间guava版本差异

修改Hive配置文件
hive-env.sh
cd /export/server/apache-hive-3.1.2-bin/conf
mv hive-env.sh.template hive-env.sh
vim hive-env.sh
export HADOOP_HOME=/export/server/hadoop-3.3.0
export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2-bin/conf
export HIVE_AUX_JARS_PATH=/export/server/apache-hive-3.1.2-bin/lib
hive-site.xml
vim hive-site.xml
<configuration>
<!-- 存储元数据mysql相关配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- H2S运行绑定host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node1</value>
</property>
<!-- 远程模式部署metastore metastore地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
<!-- 关闭元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>
上传mysql jdbc驱动到hive安装包lib下

初始化元数据


hive安装完成
metastore服务启动
前台启动

后台启动



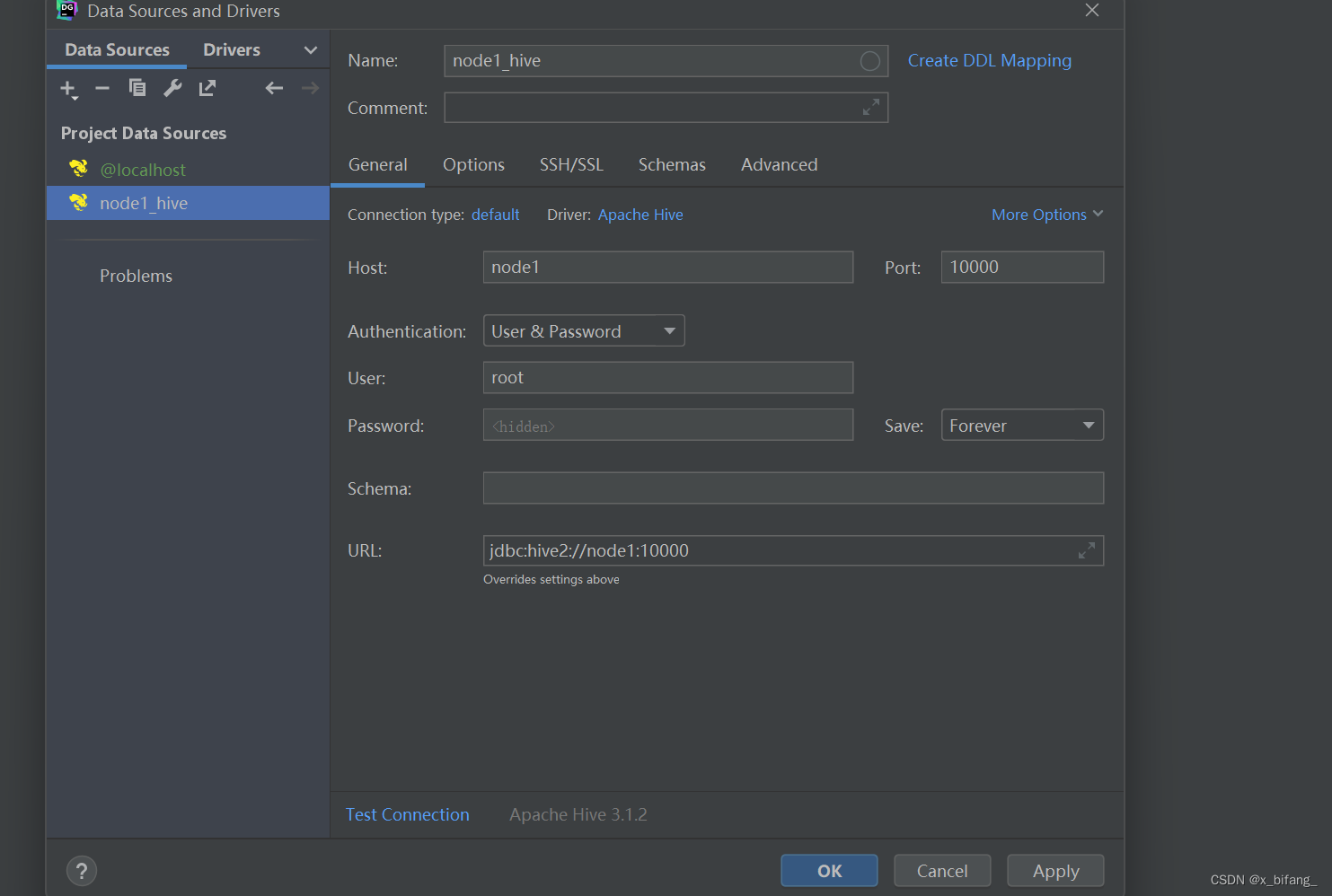
5.DataGrip配置
创建测试链接文件:1.sql
链接hive

三、操作流程
数据集收集
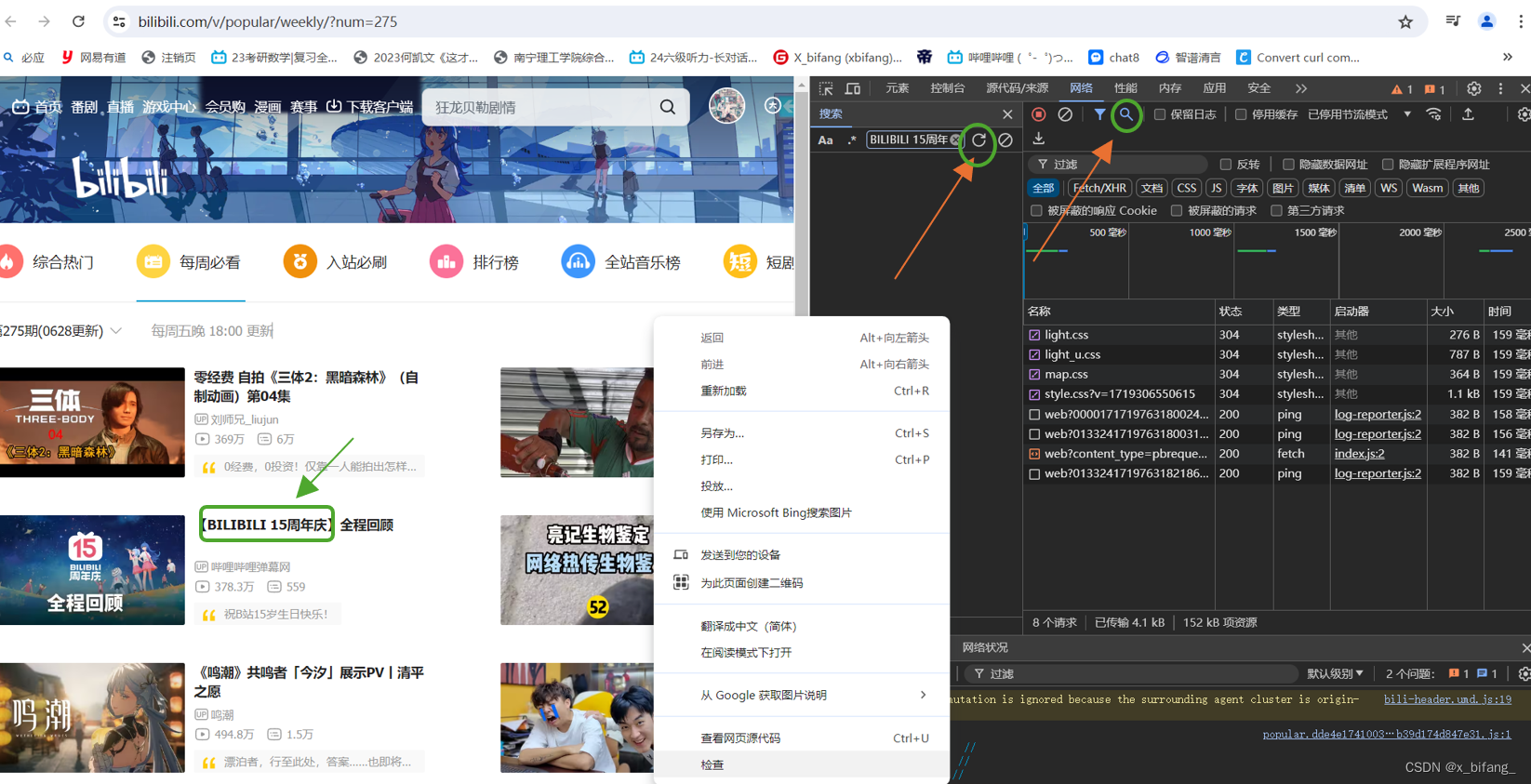
bilibili每周必看数据获取
右键检查,在网络中输入每周必看的标题(随便一个就可以)
刷新完后 它会自动选择一个文件,右键该文件选择以cURL(cmd)格式复制
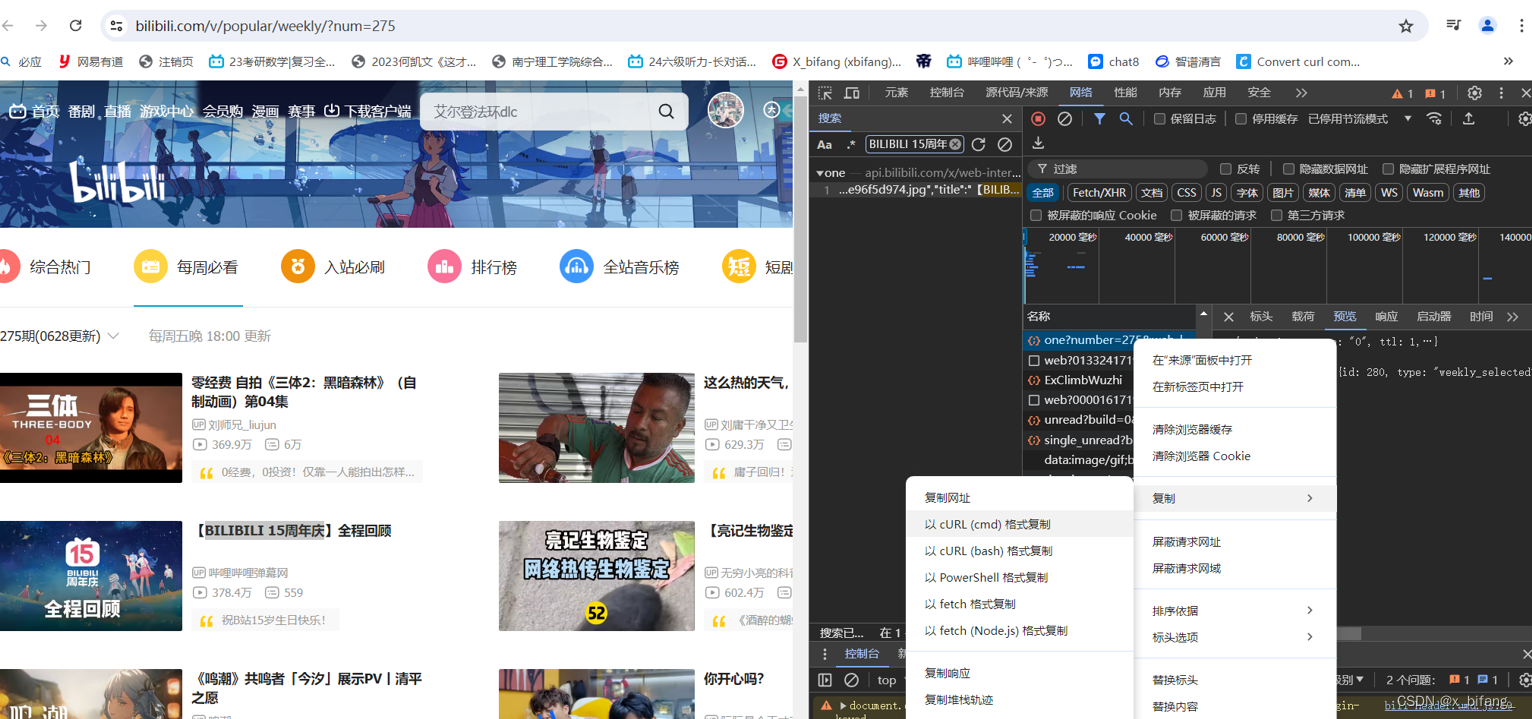
将复制的cURL粘贴到该网站:https://spidertools.cn/#/curl2Request
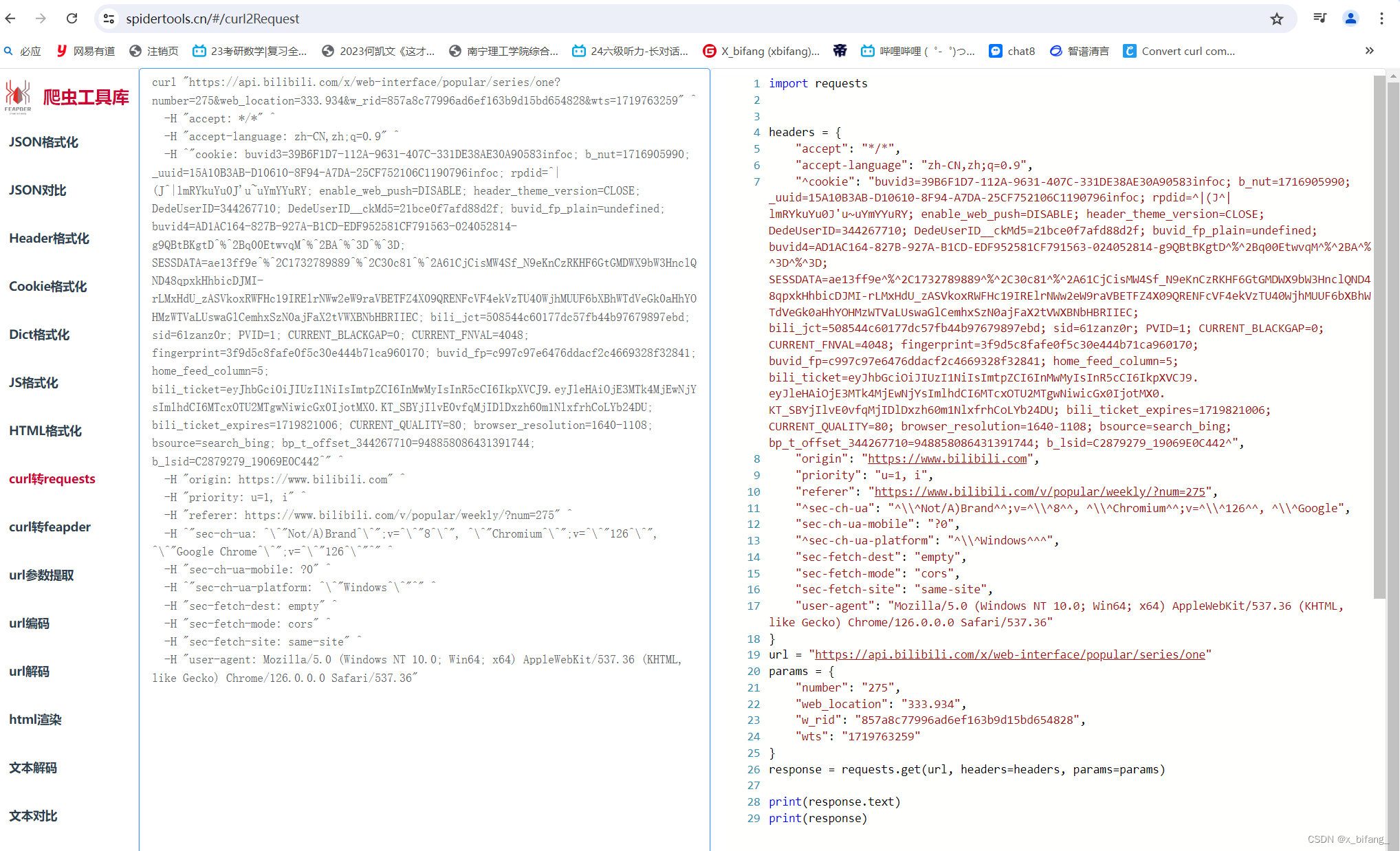
复制右侧代码到Pycharm中 并在后面修改26行,并添加后续内容,使其生成json文件

下面为运行结果
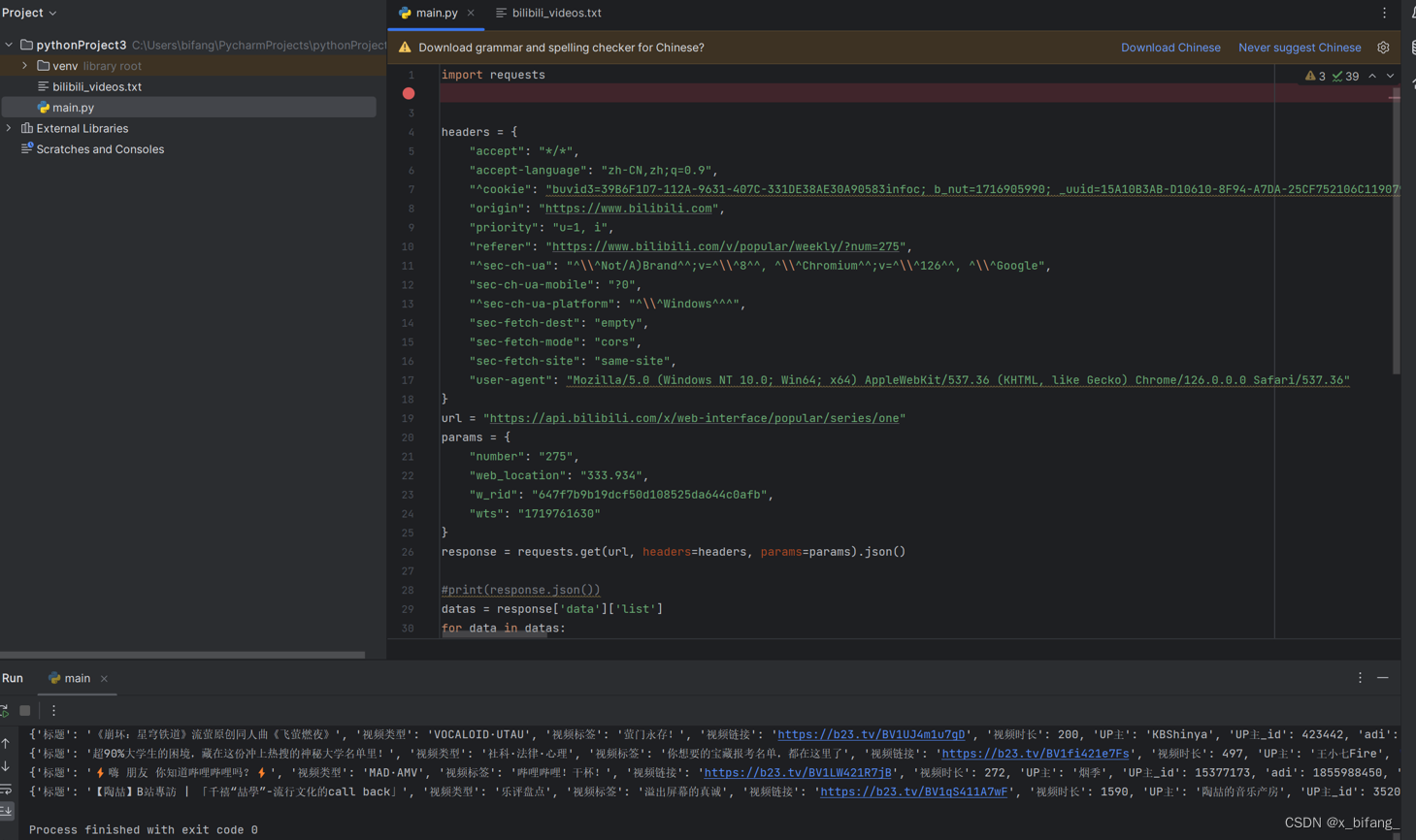
将该文本件输入到txt文件中

至此python爬取每周必看完成
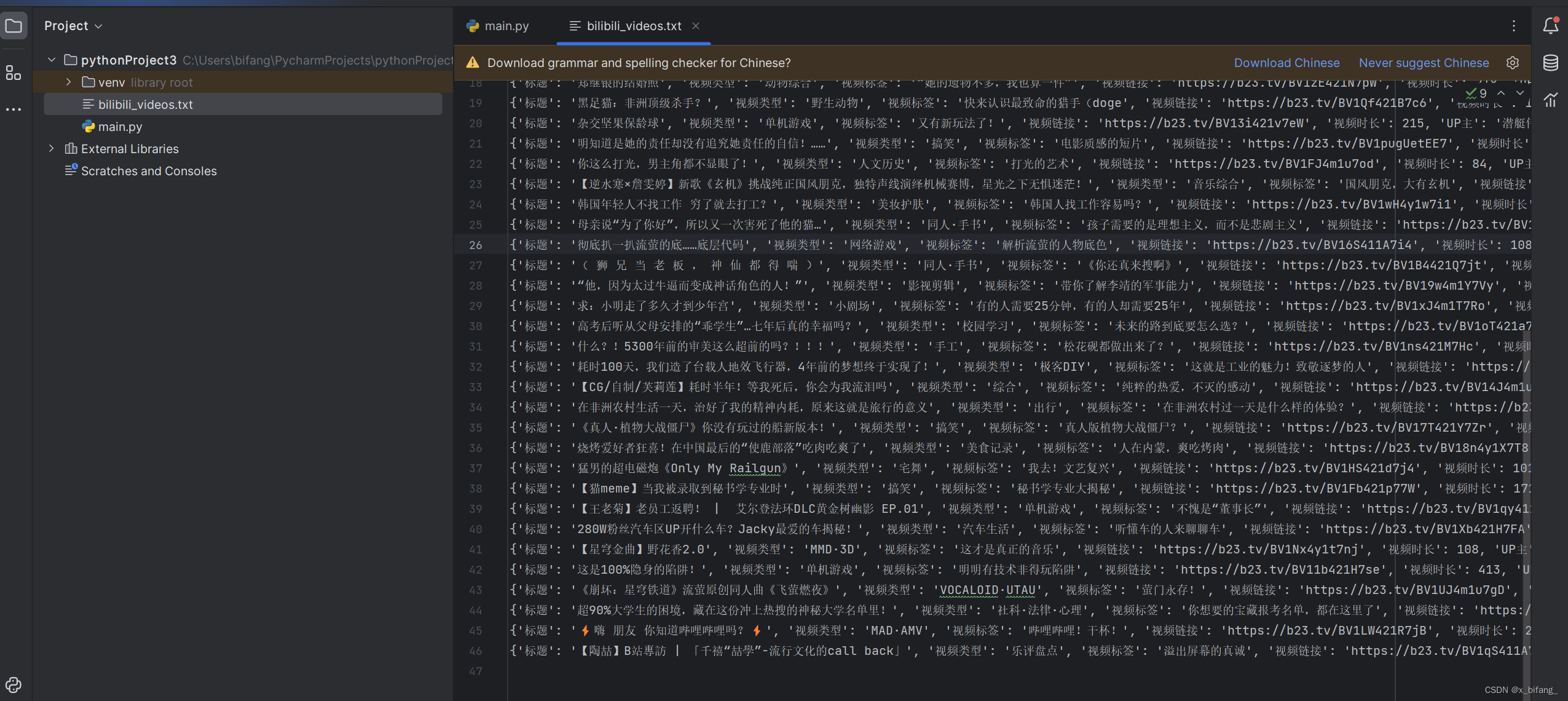
数据预处理
将各个信息即:标题:、视频类型:、视频标签:、视频链接:、视频时长:、UP主:、UP主_id:、adi:、投币数:、弹幕数:、收藏数:、点赞数:、评论数:、分享数:、播放数:删除,将各个不同类型的数据用table制表符分开

打开DataGrip 创建一个新项目

创建SQL File

在创建的新SQL文件中编辑如下内容:
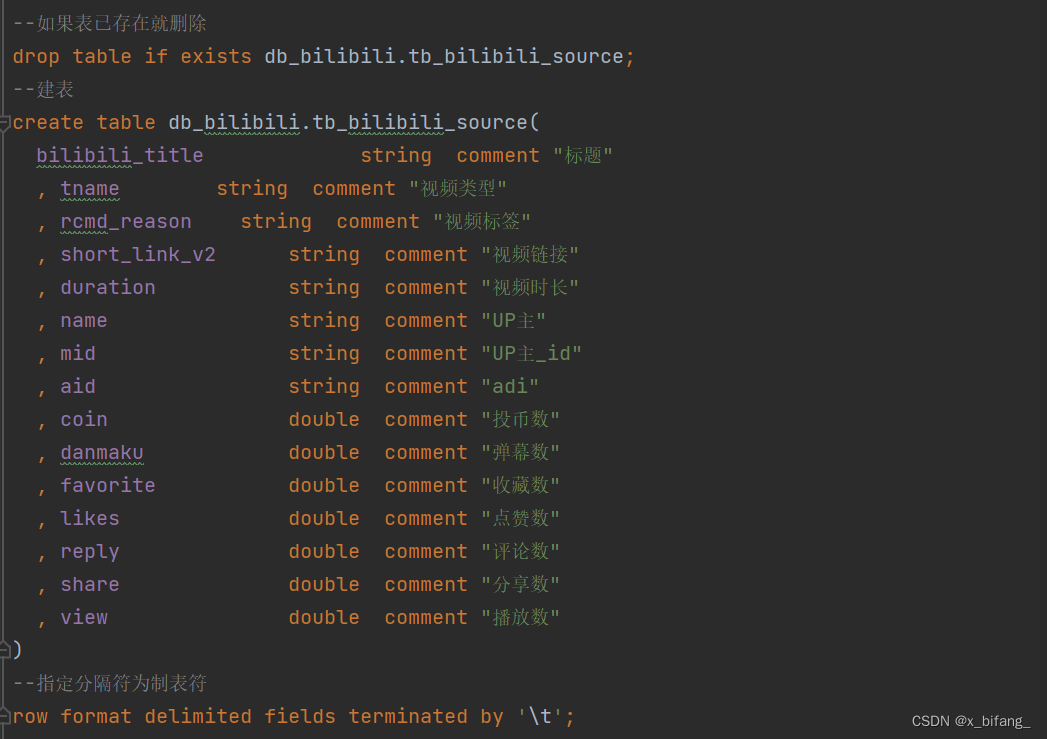
建库建表 db_bilibili.tb_bilibili_source


切换数据库

建数据表
加载数据(本地加载) 上传表数据至 FinalShell (虚拟机node1上)

加载数据到表中
load data local inpath '/root/hivedata/data1.tsv' into table db_bilibili.tb_bilibili_source;

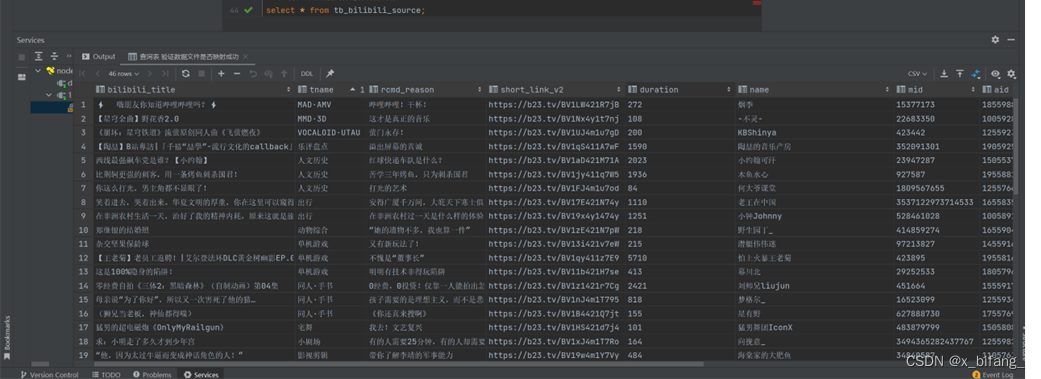
查询表 验证数据文件是否映射成功 select * from tb_bilibili_source;
数据分析
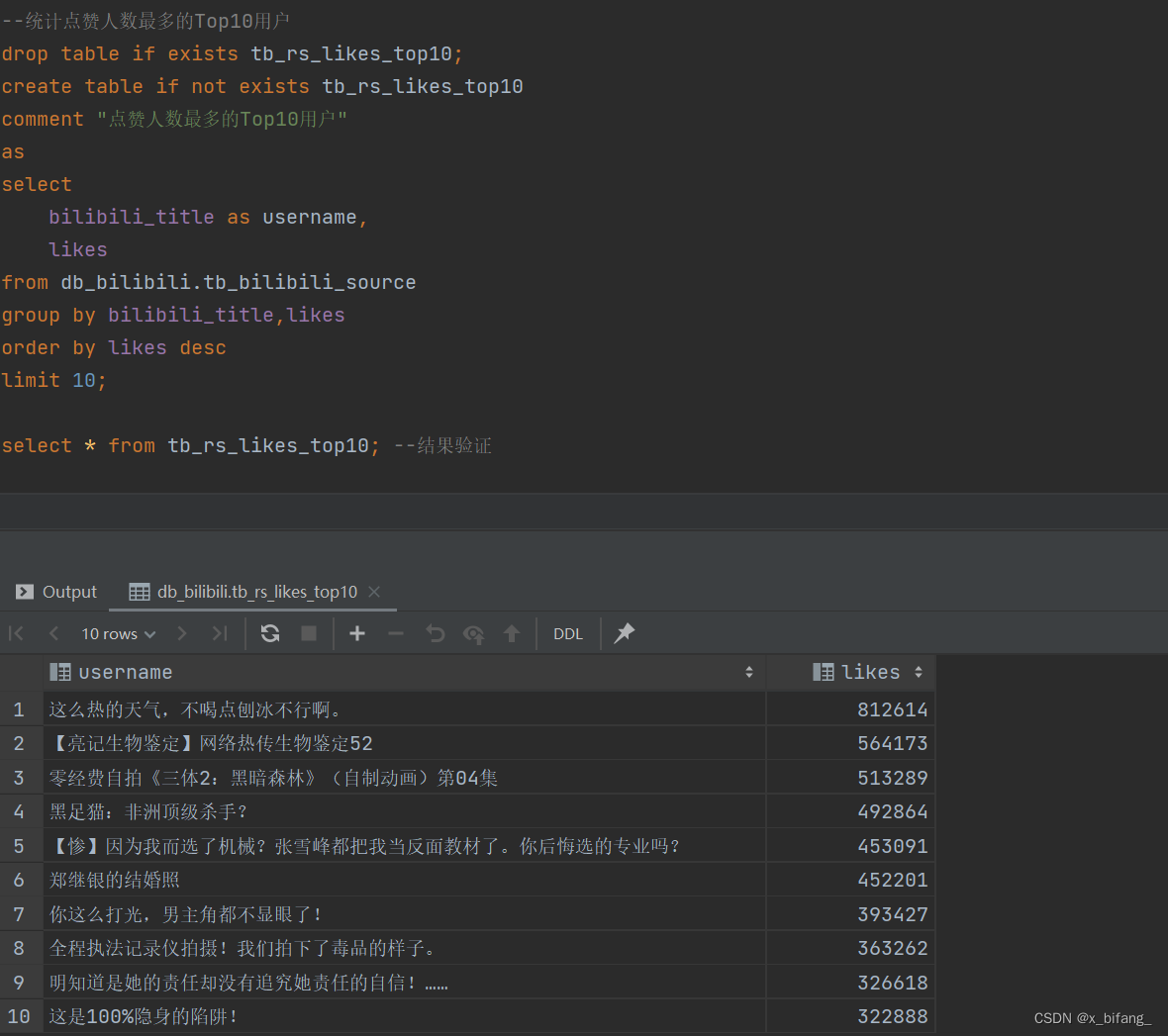
创建一个名为 tb_rs_likes_top10 的表,以统计点赞人数最多的Top10用户选中bilibili_title、likes,根据likes中记录的数字进行排序,并只记录前十条记录到新表中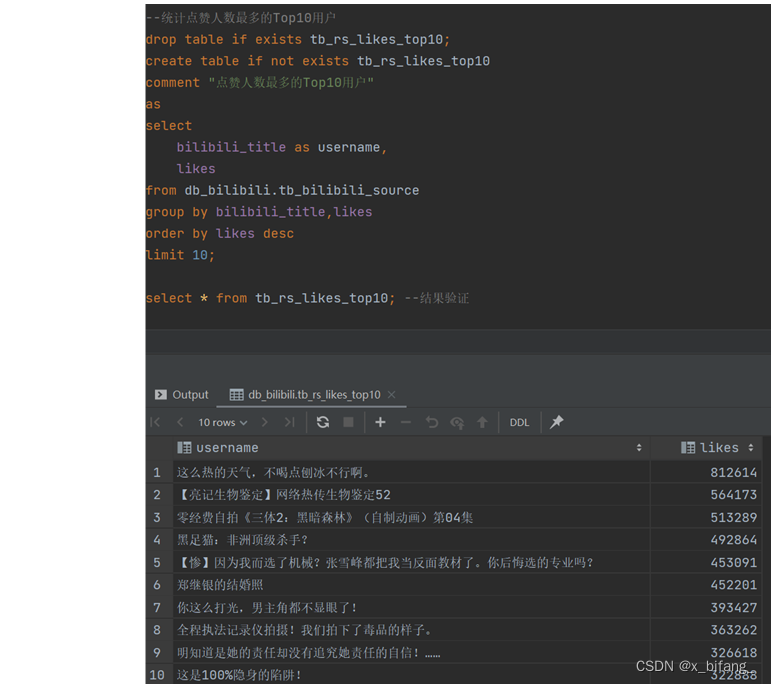
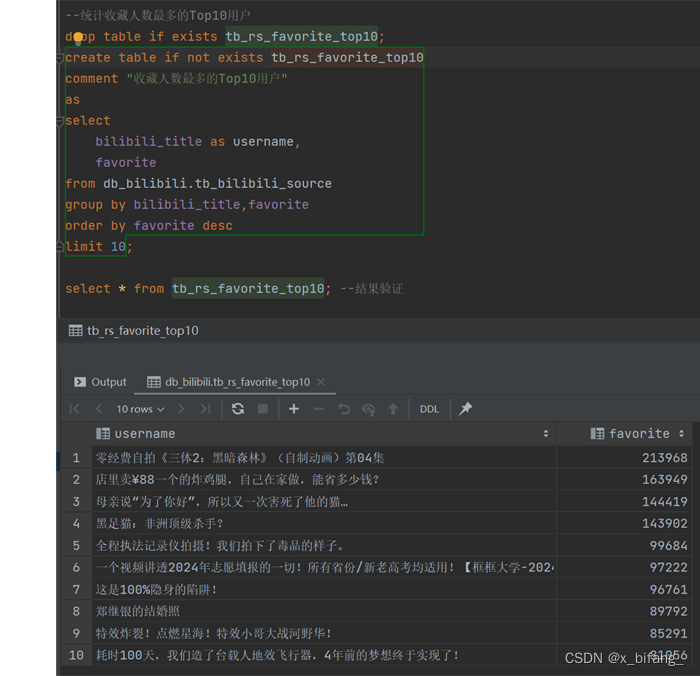
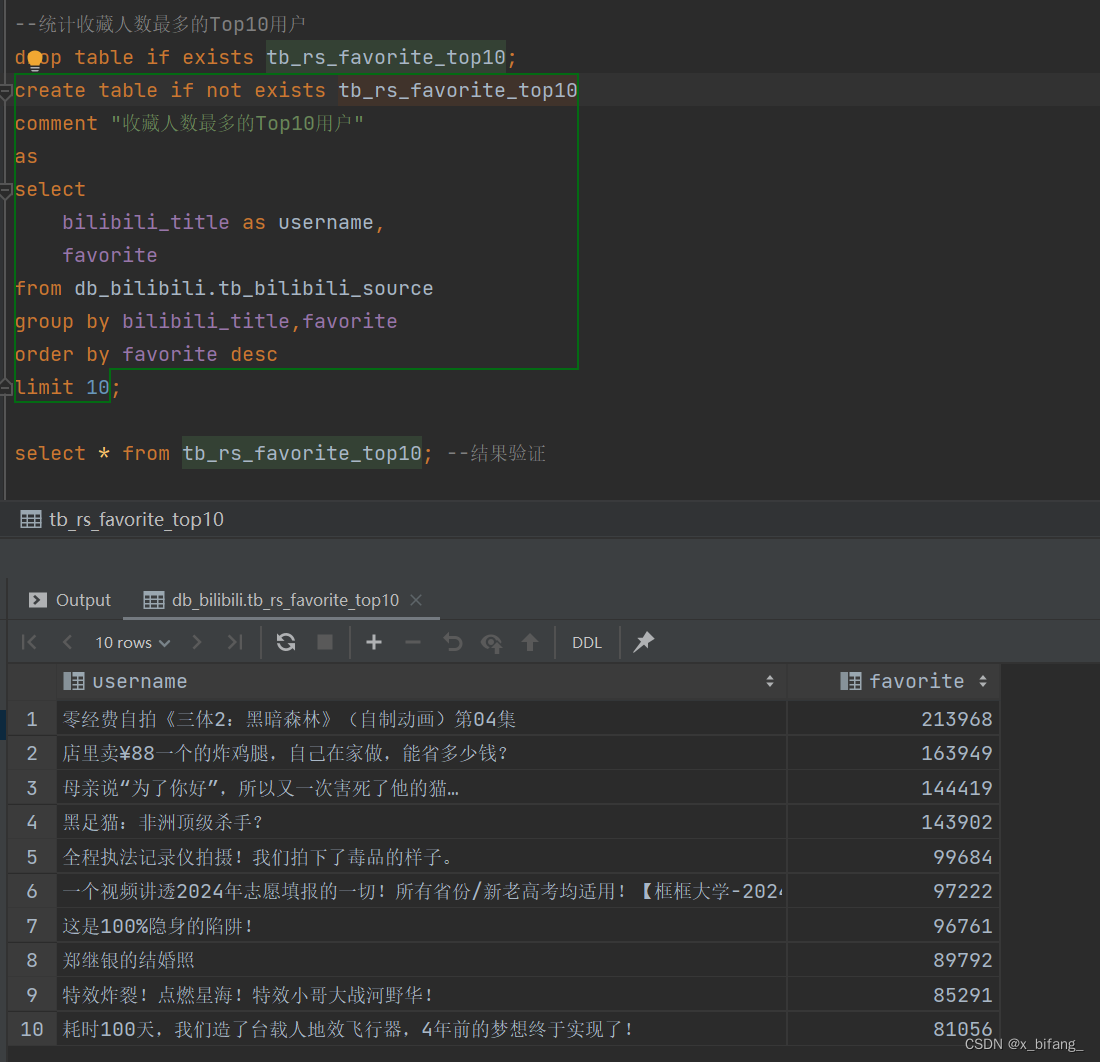
创建一个名为 tb_rs_favorite_top10 的表,以统计收藏人数最多的Top10用户;选中bilibili_title、favorite,根据favorite中记录的数字进行排序,并只记录前十条记录到新表中
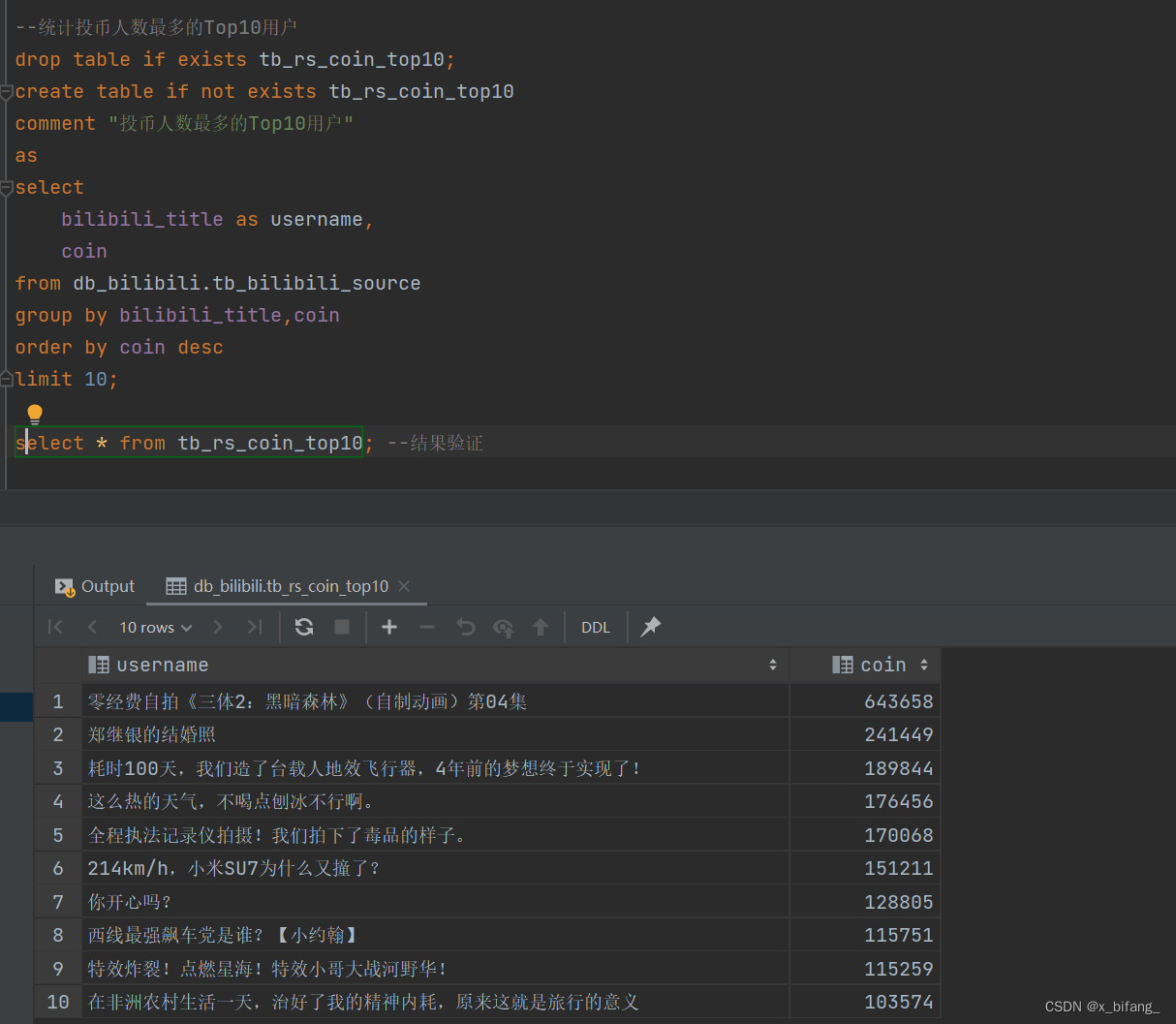
创建一个名为 tb_rs_coin_top10 的表,以统计投币人数最多的Top10用户;选中bilibili_title、coin,根据coin中记录的数字进行排序,并只记录前十条记录到新表中
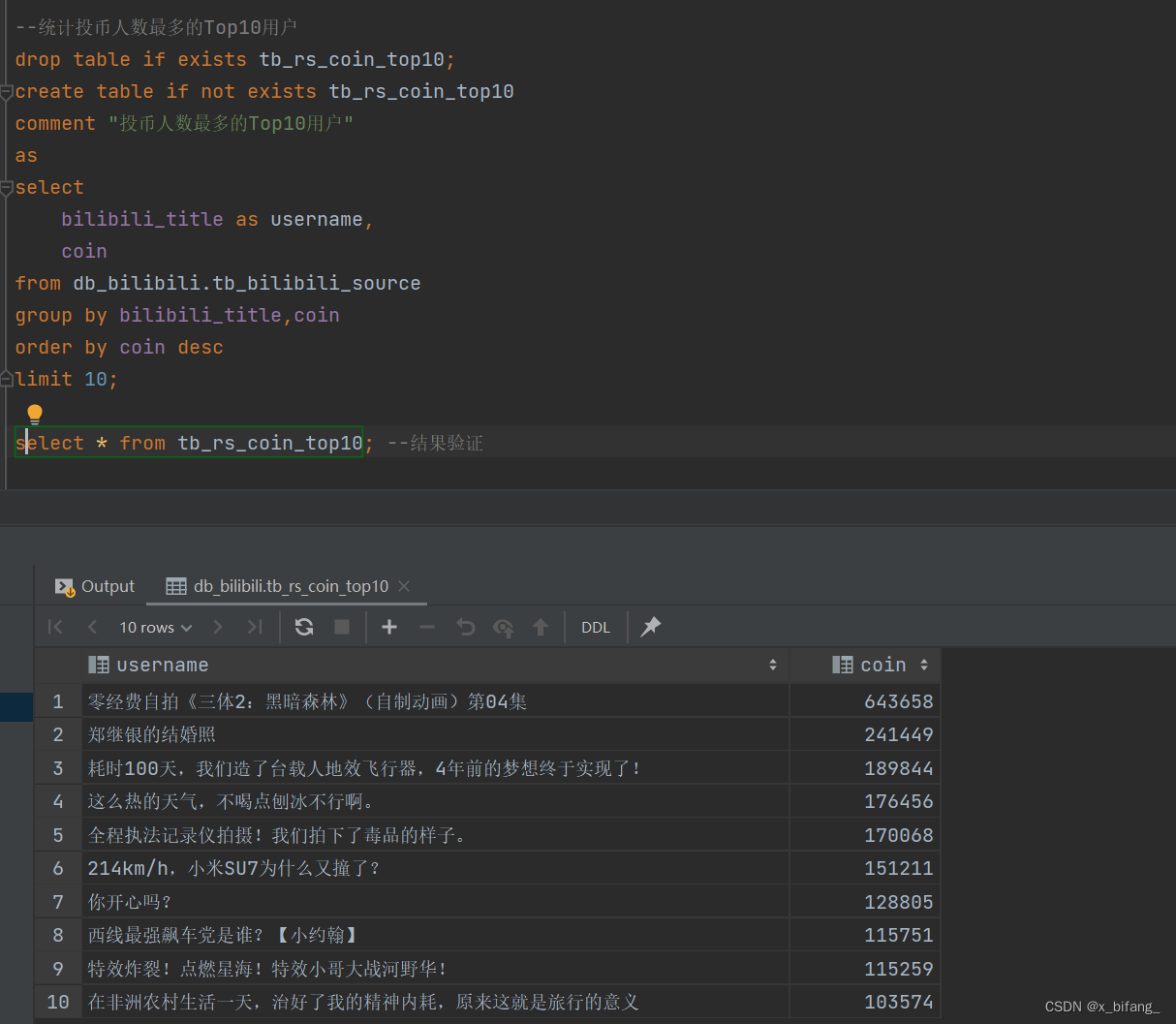
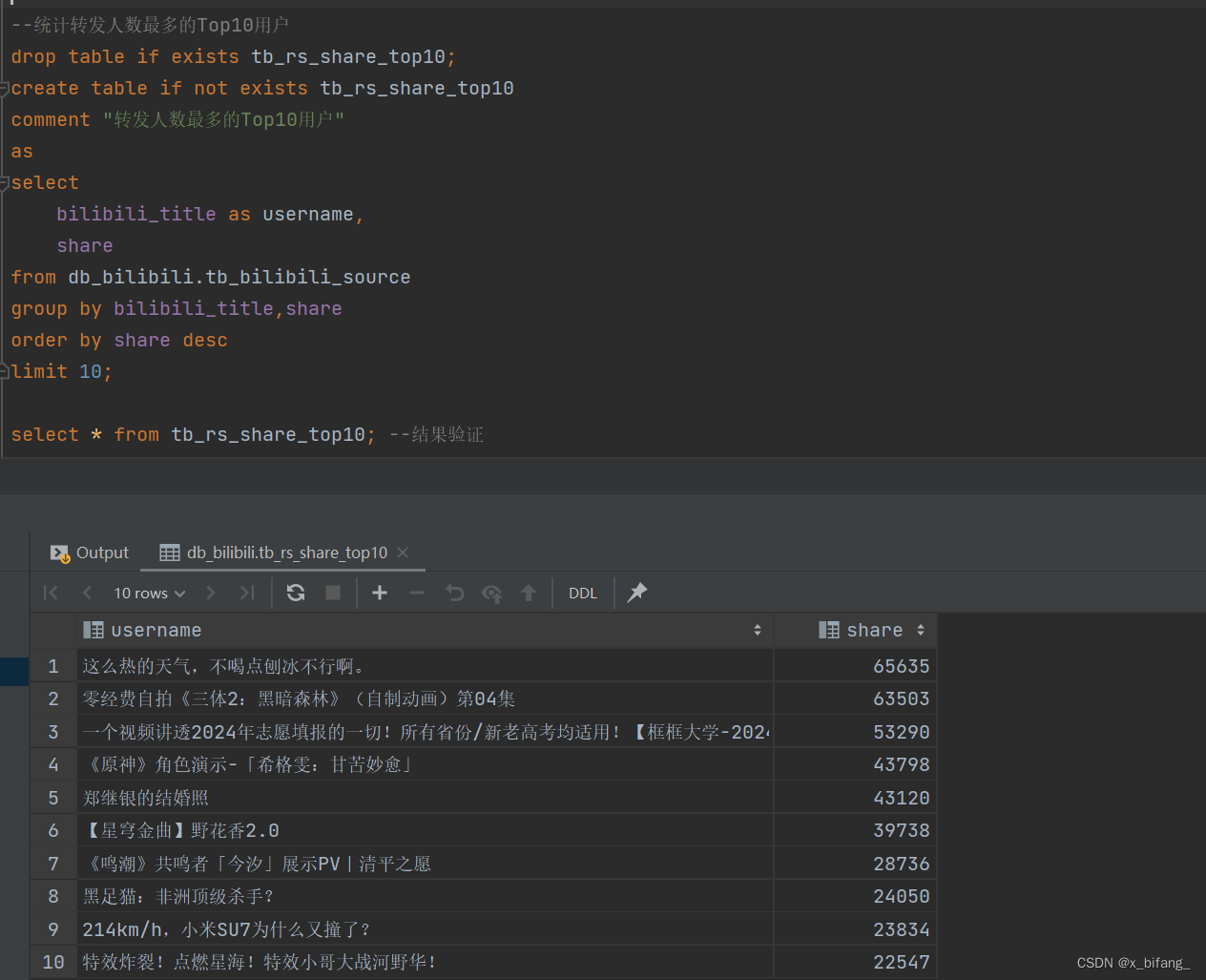
创建一个名为 tb_rs_share_top10 的表,以统计分享人数最多的Top10用户;选中bilibili_title、share,根据share中记录的数字进行排序,并只记录前十条记录到新表中

创建一个名为tb_rs_video_style的新表,用于存储统计后的视频类型分布数据,从 db_bilibili.tb_bilibili_source 表中选择视频标题和类型,并计算每种组合下的唯一视频数量。
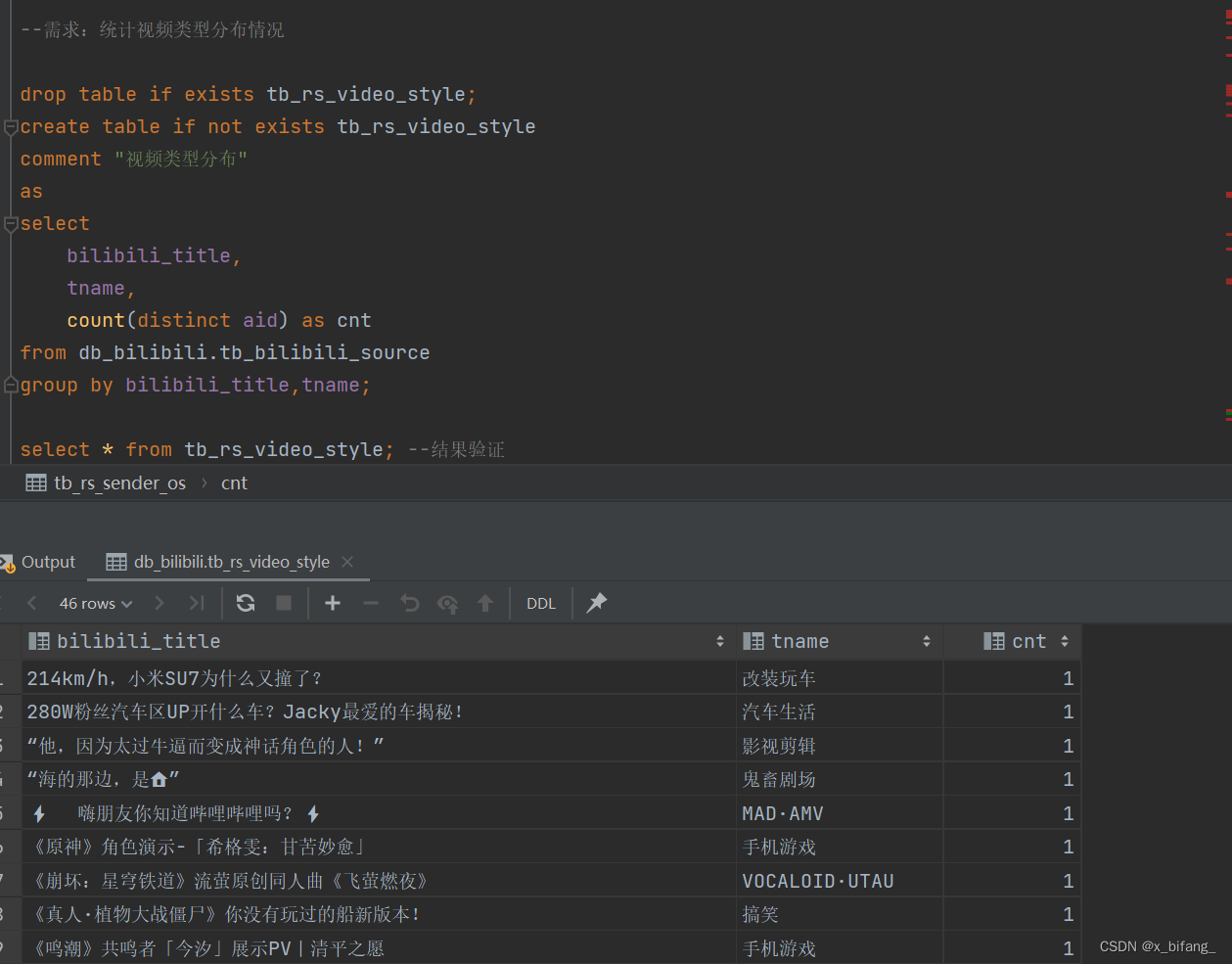
可视化
基于FineBI实现可视化报表
**FineBI配置 **
将Hive的驱动jar包放入FineBI的lib目录下:webapps\webroot\WEB-INF\lib

安装驱动包隔离插件


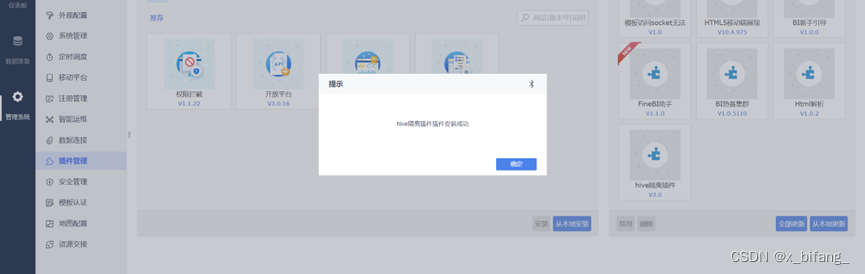
重启后配置成功
连接数据库

在空处创建名为bilibili的数据连接 数据库与DateGrip中的数据库名称相同:db_bilibili
主机为:node1 端口为:10000 认证方式:用户名密码
用户名:root 密码:无
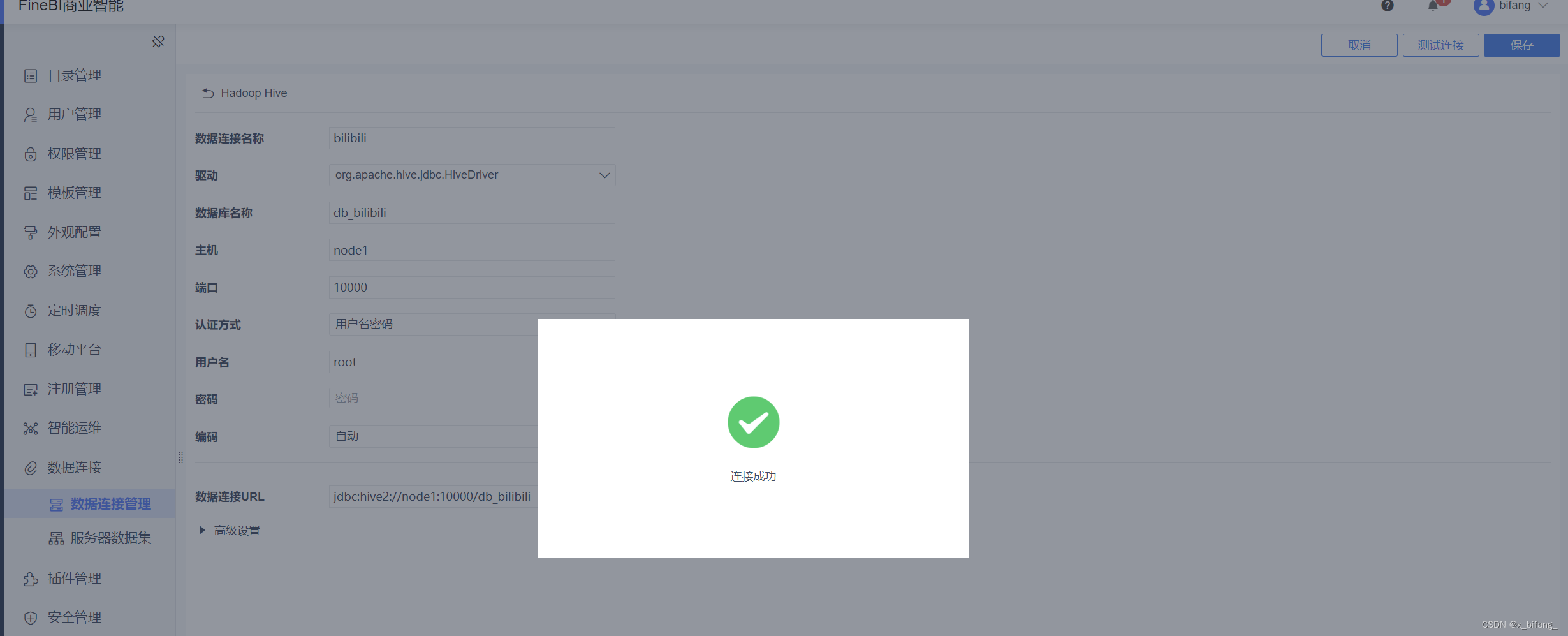
点击数据准备,创建bilibili的文件夹,在文件夹中创建名为 每周必看 业务包
创建《每周必看》业务包

点开每周必看,添加数据库表

选中之前筛选的数据库表5张表
之前创建的表有: tb_rs_cion_top10 ; tb_rs_favorite_top10 ;
tb_rs_likes_top10 ; tb_rs_share_top10;
tb_rs_video_style
下图中框选的

导入数据库表成功
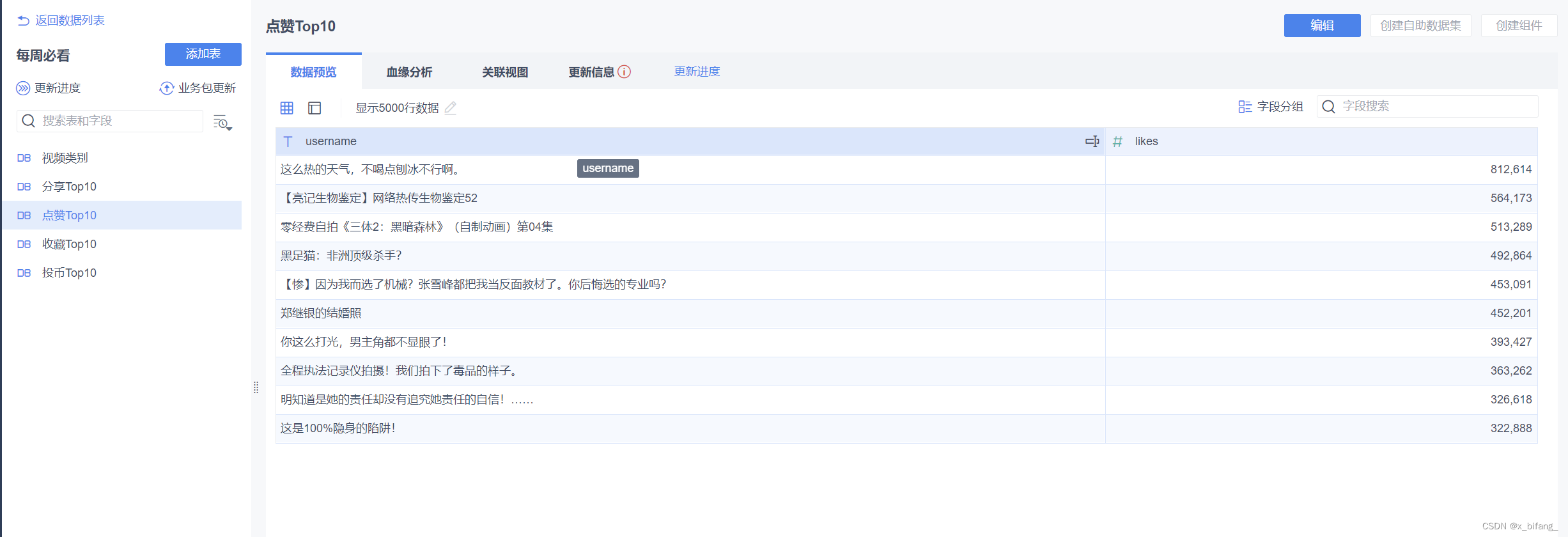
绘制报表
仪表盘创建bilibili
组件中添加数据表
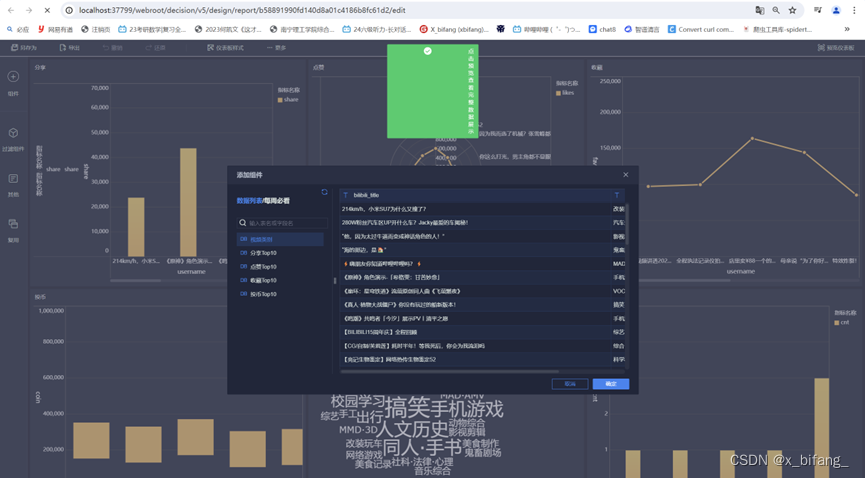
四、可视化结果
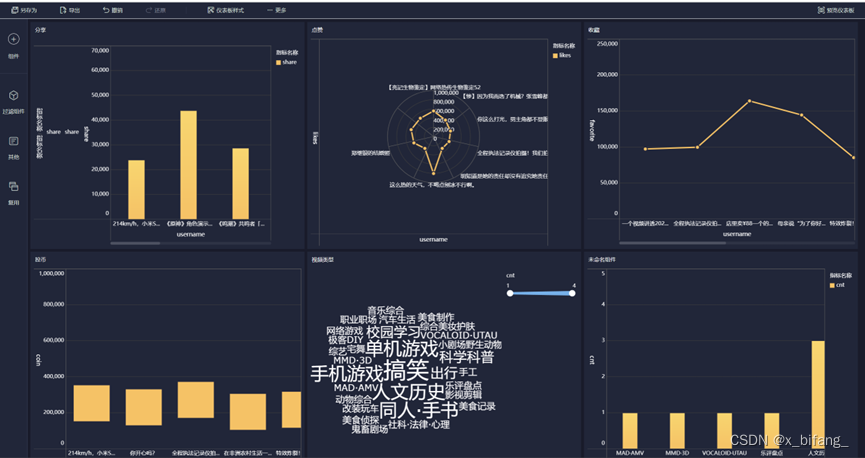
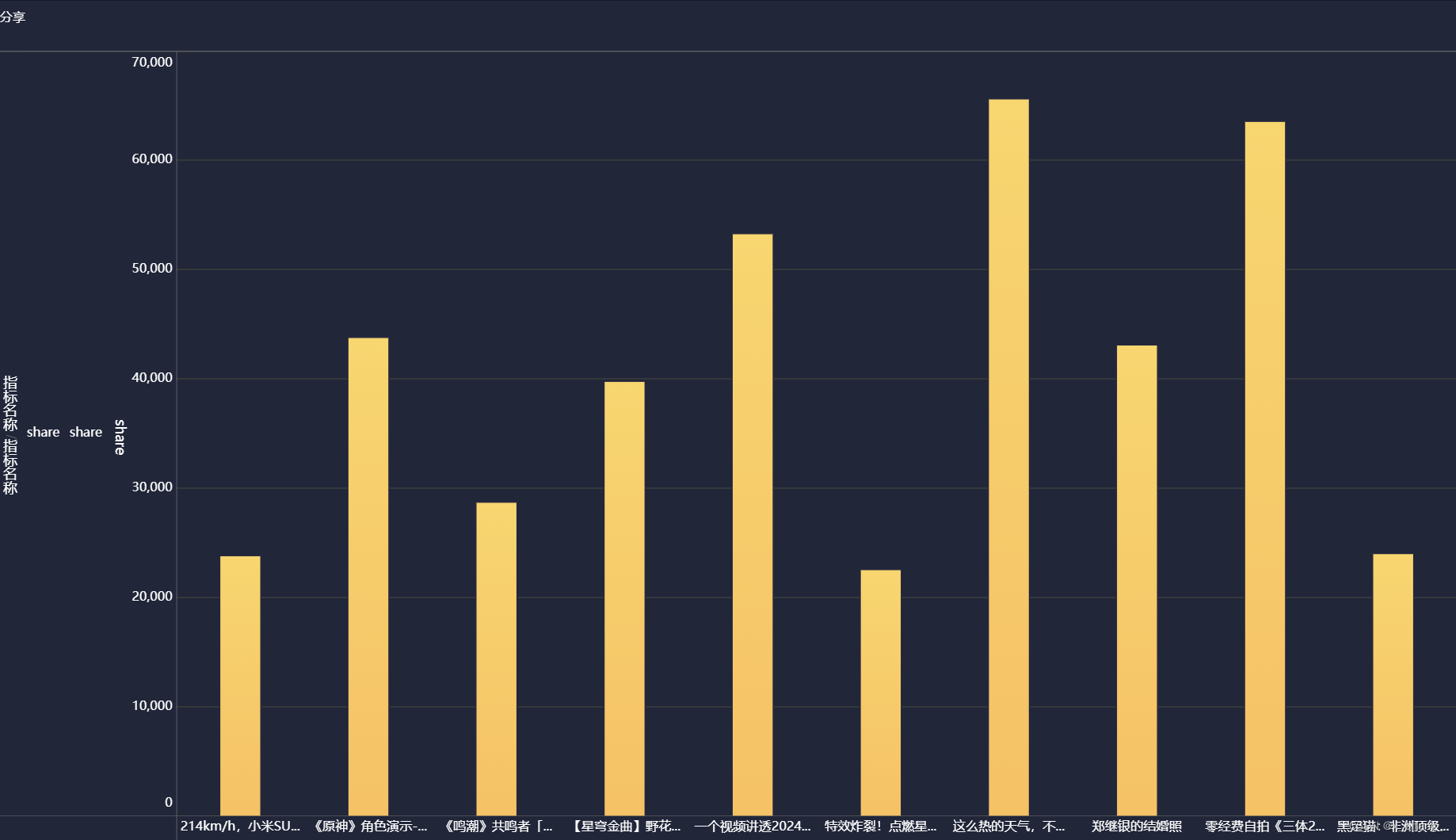
分享柱状图
点赞雷达图

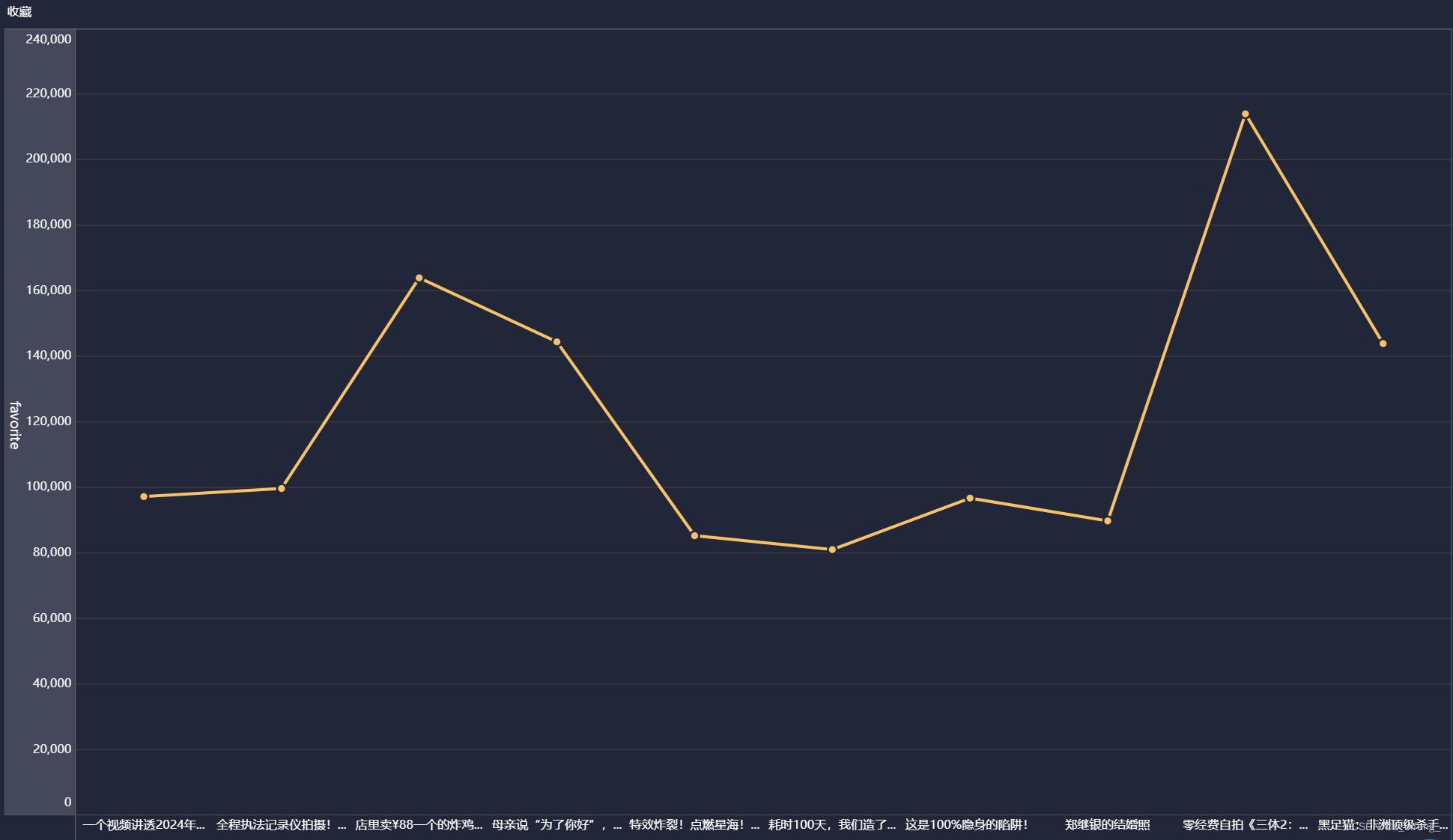
收藏折线图
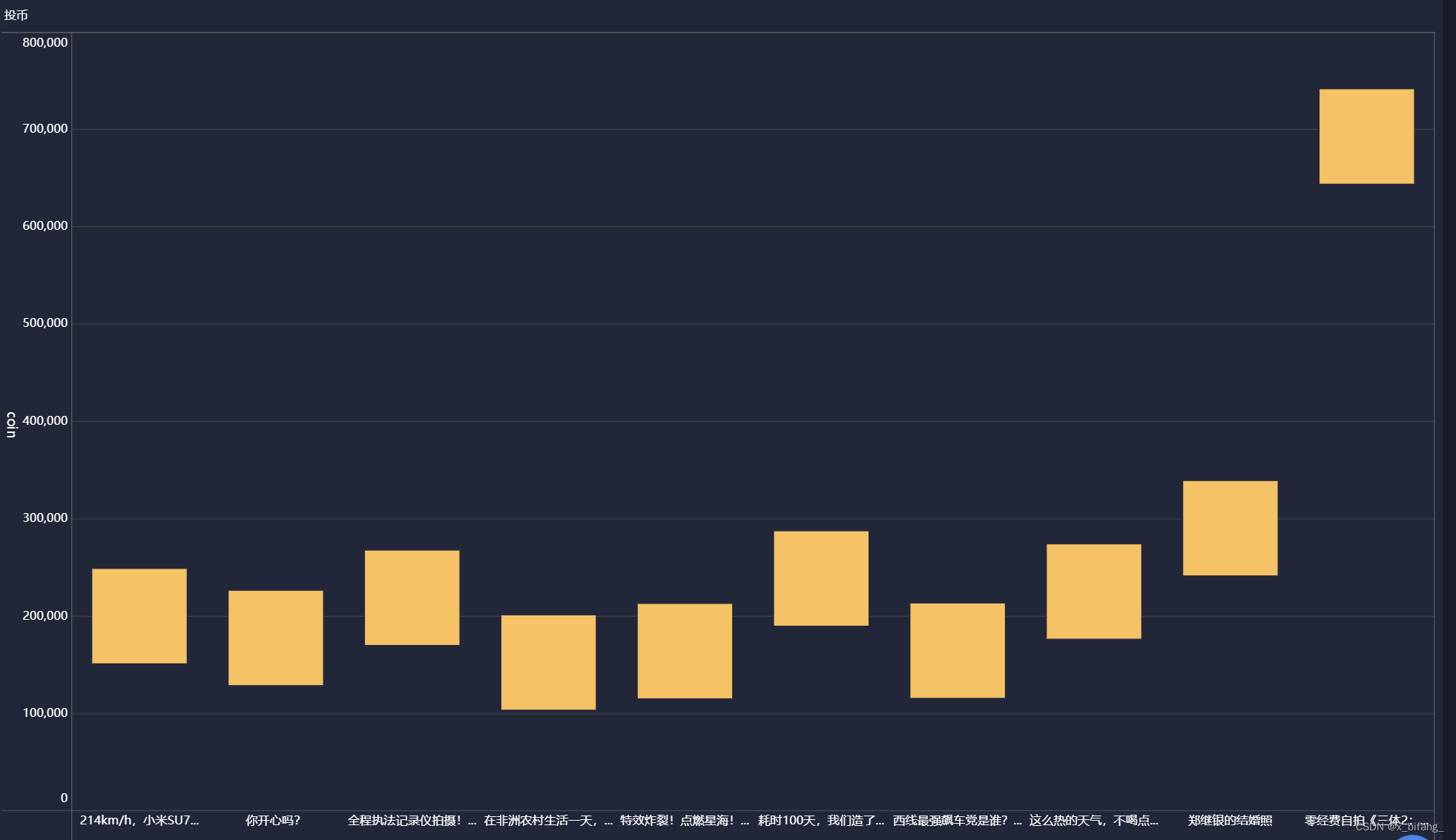
投币瀑布图
视频类型词云
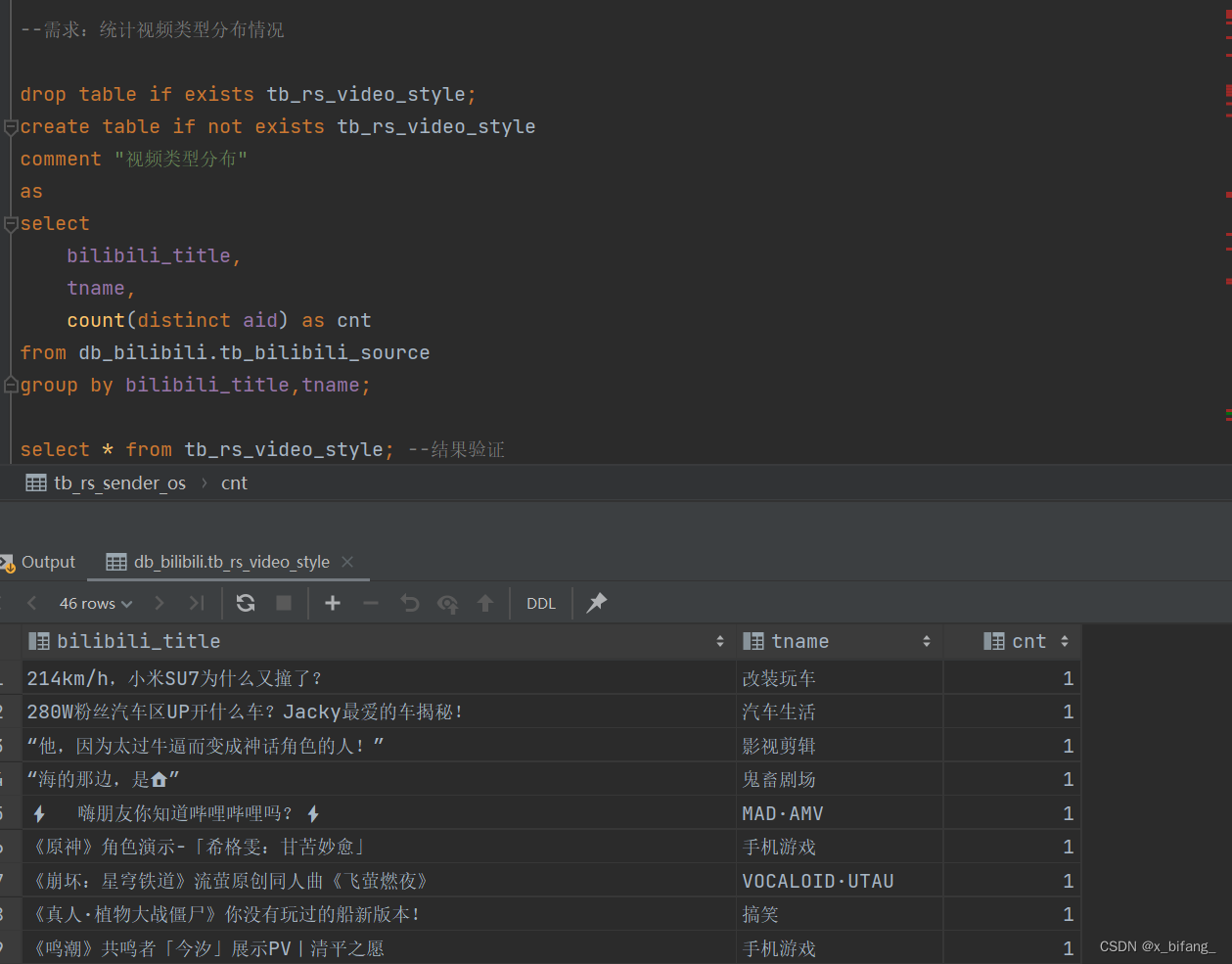

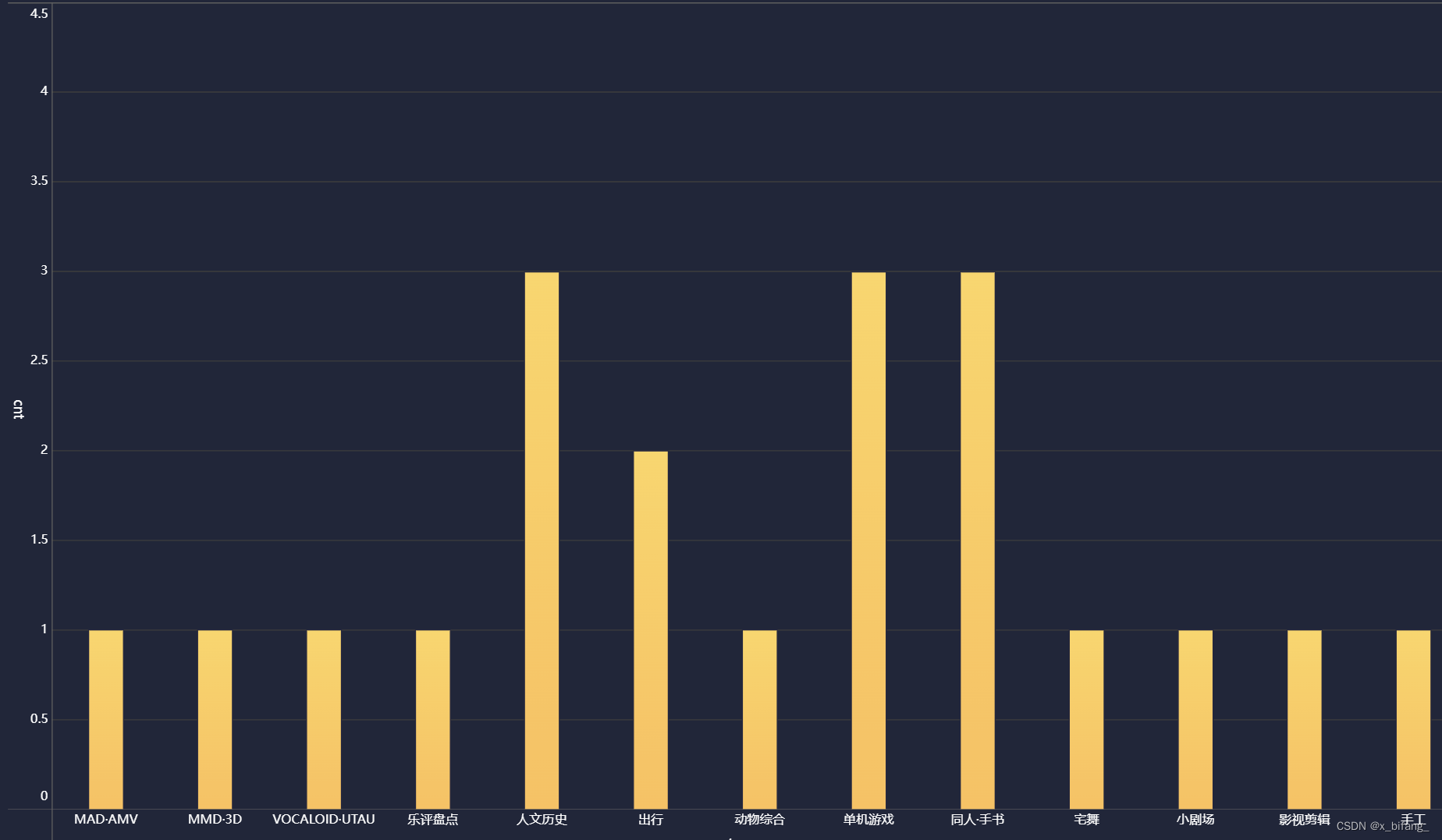
视频类型柱状图
五、遇到的问题
虚拟机在导入到VMware中会出现下面的选项

注意要选择我已移动,选错了就要删除重来
java -version没有找到
在node1上安装完jdk1.8后,并配置完环境变量,再将环境变量文件与jdk文件分发给node2与node3,在node2与node3上输入java -version没有找到

解决:重启配置文件

中文乱码问题
修改Hive存储的元数据信息
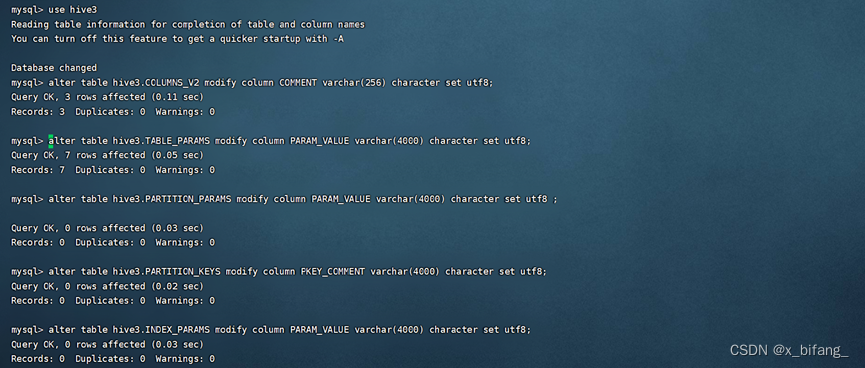
在使用DataGrip时遇到了连接不到本地hive的问题
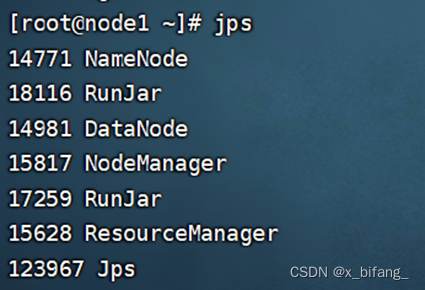
经过反复网上查阅后,了解到连接时需要在虚拟机上开启 HDFS集群、YARN集群、mysql、metastore,之后在开启hive与二代hive,此时使用jps查询
如下,即为连接成功

版权归原作者 x_bifang_ 所有, 如有侵权,请联系我们删除。