
文章目录
代码地址:
爬取官网成绩: 爬取官网成绩 (gitee.com)
获取到这个接口之后后序选课、课程表等功能都是可以完成的。
HTTP协议是无状态的协议。一旦数据交换完毕,客户端与服务器端的连接就会关闭,再次交换数据需要建立新的连接,这就意味着服务器无法从连接上跟踪会话。也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是哪个用户。如何确定某一个用户呢?可以通过cookie。
第一次登录后服务器后,如果服务器需要记录该用户状态,就使用response向客户端浏览器颁发一个cookie,浏览器会把cookie数据保存在本地。该用户发送第二次请求的时候,就会自动的把上次请求存储的cookie数据自动的携带给服务器,服务器检查该cookie存储name,value等信息,以此来辨认用户状态,服务器还可以根据需要修改cookie的内容。
cookie就相当于是服务器给客户端们颁发一个通行证,每人一个,无论谁访问都必须携带自己通行证。这样服务器就能从通行证上确认客户身份,这就是Cookie的工作原理。

分析登录到首页和信息门户也,两次的cookie是不一样的。 首页的Cookie是比较多的

发送获取成绩接口的请求是登录到教务系统的cookie。

selenium
Selenium是一系列基于Web的自动化工具,提供一套测试函数,用于支持Web自动化测试。函数非常灵活,能够完成界面元素定位、窗口跳转、结果比较。具有如下特点:
使用这个框架需要配套 google浏览器和google driver 这两个版本需要相互适配。

一个简单为WebDriver代码
查看浏览器的版本 129.0版本,需要下载对应版本的driver,否则代码不能运行。
driver下载网址:
Chrome for Testing availability (googlechromelabs.github.io)

导入maven坐标
<dependencies>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.19.1</version>
</dependency>
</dependencies>
 打开一个网站: 左上角会显示浏览器正在接收测试软件的控制。
打开一个网站: 左上角会显示浏览器正在接收测试软件的控制。
HttpCilent
HttpClient是Apache Jakarta Common下的子项目,用来提供高效的、最新的、功能丰富的支持HTTP协议的客户端编程工具包,并且它支持HTTP协议最新的版本和建议。HttpClient已经应用在很多的项目中,比如Apache Jakarta上很著名的另外两个开源项目Cactus和HTMLUnit都使用了HttpClient。

可以将httpclient封装成工具类在项目中使用。
HttpClient调用第三方服务-CSDN博客
爬取官网接口
需要拿到cookie,需要自动跳转到登录和注册页面。
首先在登录页面: 需要输入用户名和密码。 这个验证码是基于时间戳生成的,每一次的验证码都不一样。本质是一个图片,可以拿到这个图片存放到本地,在返回给前端。为了增加用户的体验感觉,使用百度的API识别验证码图片,提高用户的体验感。

打开页面是这样的,需要点击登录才能跳转到登录页面。获取到登录按钮,通过driver去点击登录。

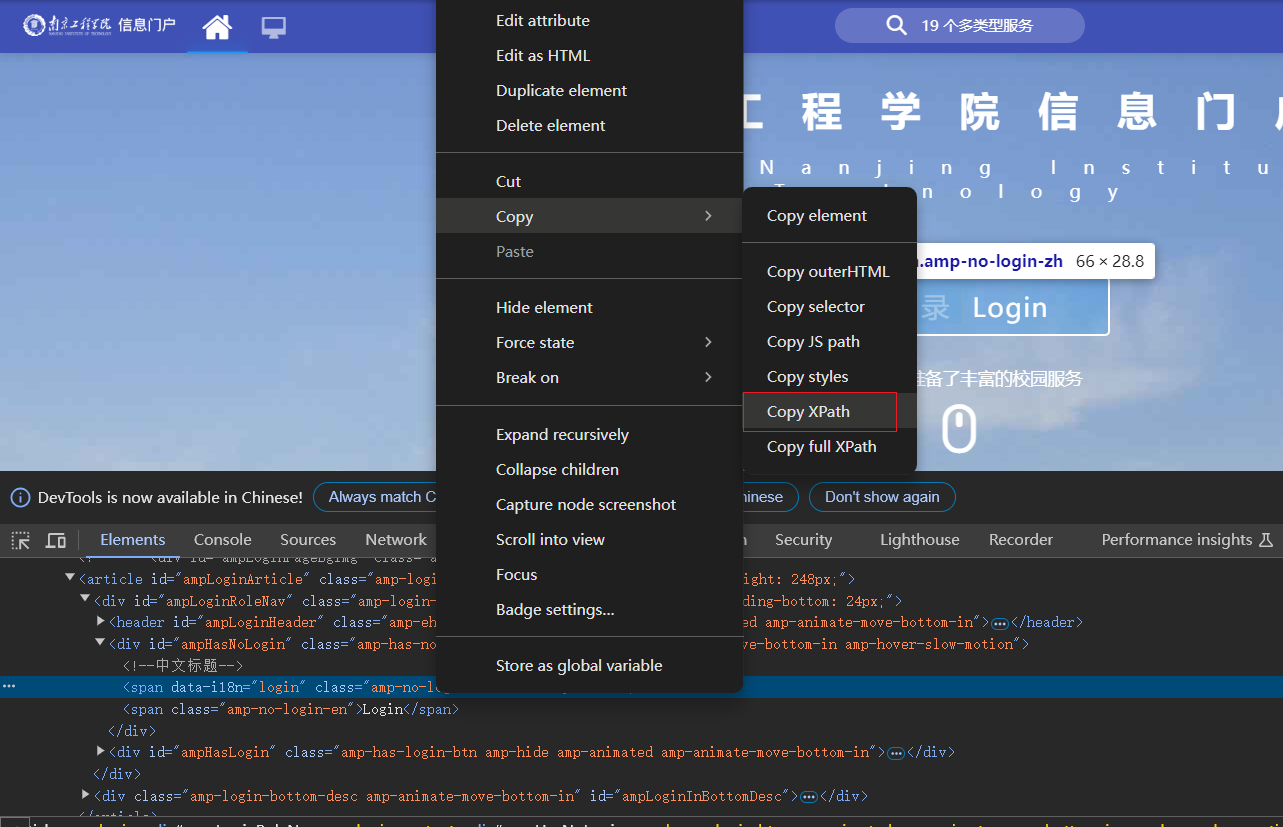
/html/body/div[1]/article[1]/article/div[1]/div[1] 点击下面full path也可以,浏览器会自动点击登录按钮。
WebElement element = wait.until(ExpectedConditions.visibilityOfElementLocated(By.xpath("/html/body/div[1]/article[1]/article/div[1]/div[1]")));
element.click();

//通过id 拿到用户名和密码的元素 通过sendkeys设置其中的值
WebElement username = wait.until(ExpectedConditions.visibilityOfElementLocated(By.id("username")));
WebElement password = wait.until(ExpectedConditions.visibilityOfElementLocated(By.id("password")));
username.sendKeys("123456"));
password.sendKeys("abc");

找到验证码:
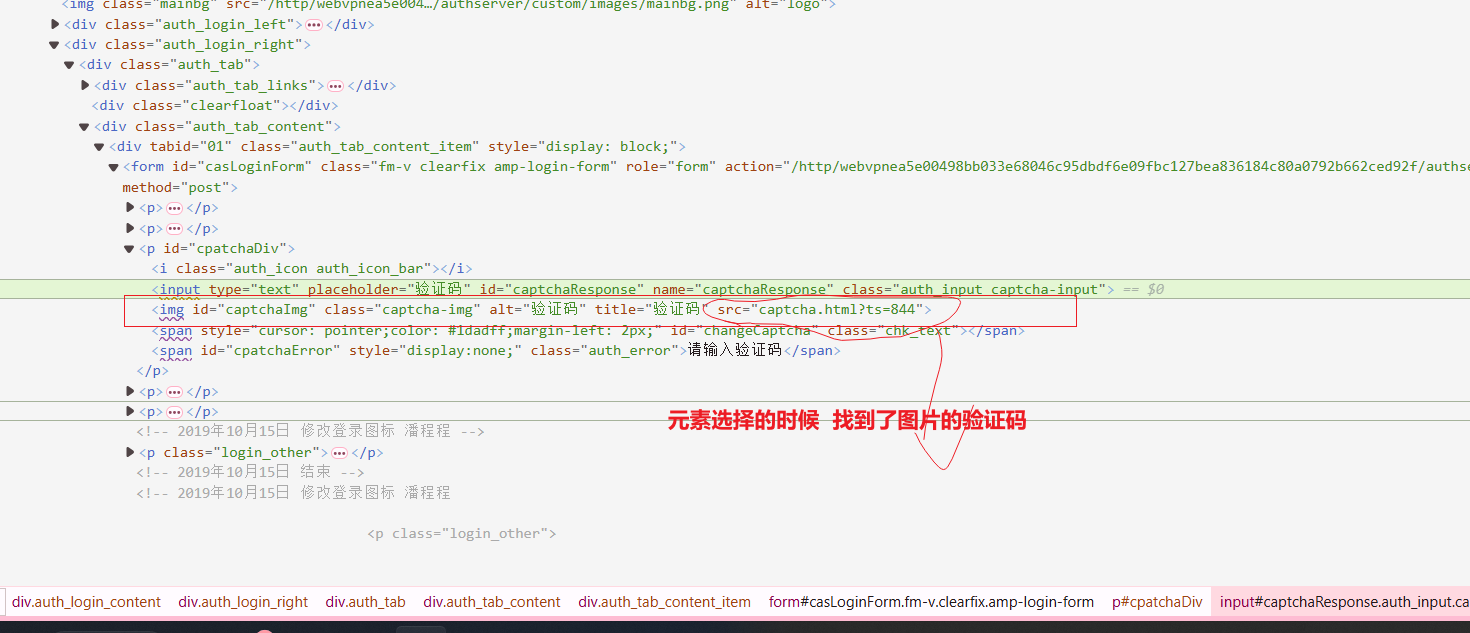
 点进去每一次刷新的验证码都不一样的。
点进去每一次刷新的验证码都不一样的。
WebElement captchaElement = driver.findElement(By.id("captchaImg")); //扎到这个元素
File screenshot = captchaElement.getScreenshotAs(OutputType.FILE); //进行截图
File destinationFile = new File("captcha.png");
try {
FileHandler.copy(screenshot, destinationFile); //将截图拷贝到当前目录下面来
} catch (IOException e) {
throw new RuntimeException(e);
}

调用百度云的接口进行识别。也可以自己训练本地的模型。
AipOcr client = new AipOcr(APP_ID, API_KEY, SECRET_KEY);
String path = destinationFile.getAbsolutePath();
org.json.JSONObject res = client.basicGeneral(path, new HashMap<String, String>());
String wordsResultJson = res.get("words_result").toString();
JSONArray wordsResultArray = JSON.parseArray(wordsResultJson);
JSONObject firstResult = wordsResultArray.getJSONObject(0);
String words = firstResult.getString("words");
String rescode = words.replaceAll(" ", ""); //去掉空格
System.out.println(rescode);
//将识别出来的验证码填充到框框中去
WebElement code = wait.until(ExpectedConditions.visibilityOfElementLocated(By.id("captchaResponse")));
code.sendKeys(rescode);

//点击登录按钮
WebElement loginButton = wait.until(ExpectedConditions.elementToBeClickable(By.xpath("//*[@id=\"casLoginForm\"]/p[5]/button")));
loginButton.click();
运行代码发现成功了。

观察发现,虽然登录成功了,但是浏览器的地址并没有变化,如果浏览器的地址发生了变化需要进行刷新。

点击教务系统

发现网址变了,所以这边也需要修改对应的网址。

for (String winHandle : driver.getWindowHandles()) {
driver.switchTo().window(winHandle);
}
//因为需要等待五秒钟 五秒钟后可以直接刷新页面即可进来
driver.navigate().refresh();
进入到了教育系统的页面

Map<String, String> map = new HashMap<>();
Set<Cookie> cookies = driver.manage().getCookies(); //拿到所有的cookie 存放到map中去
for (Cookie cookie : cookies) {
map.put(cookie.getName(), cookie.getValue());
}
StringBuffer sb = new StringBuffer();
sb.append("JSESSIONID=" + map.get("JSESSIONID") + ";");
sb.append("iPlanetDirectoryPro=" + map.get("iPlanetDirectoryPro") + ";");
sb.append("route=" + map.get("route"));
到这第一步就算完成了,拿到了cookie。

HttpClient
导入HttpClient的包
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.13</version>
</dependency>
请求的URL
https://ensdp.njit.edu.cn:10443/http/webvpn3e1a11b7208e283ab07ade5d2913fc13d6f6fe09d2dc7372db2a51a14aa4167a/jwglxt/cjcx/cjcx_cxXsgrcj.html?doType=query&gnmkdm=N305005&enlink-vpn
携带了get和post的请求参数。 xnm 和xqm 确定了哪个学期。 还有一些查询参数 包括是否降序等等。
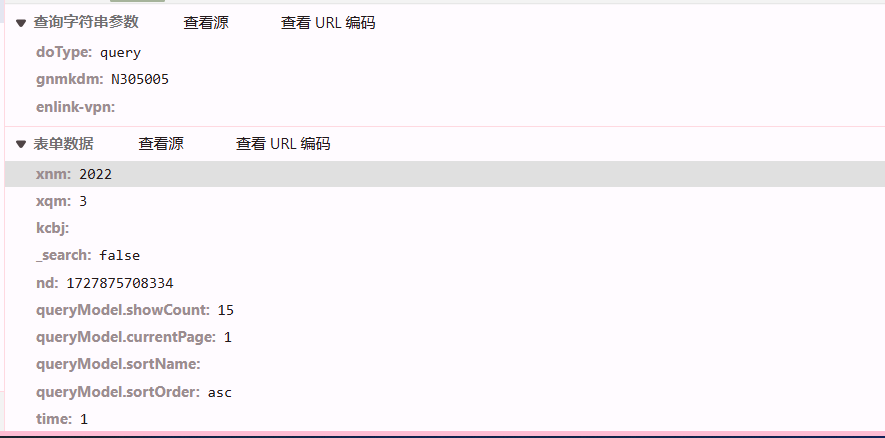
这是响应的数据,成绩相关的数据都在items中。

public class Score {
private Integer id;
private String StudentName; //学生姓名
private String StudentId; //学生学号
private String CourseName; //课程名称
private String type; //课程类型
private Double credit; //课程学分
private String score; //课程成绩 有的课程是优秀 不是分数
}
发送post请求代码:
public static String executePostRequest(String targetURL, Map<String, String> params, String cookie) {
CloseableHttpClient httpClient = HttpClients.createDefault(); //创建httpCilent
String responseBody = null; // 用于存储响应内容
try {
// 创建一个HttpPost实例,设置请求的URL
HttpPost httpPost = new HttpPost(targetURL);
// 设置请求头,模拟AJAX请求
httpPost.setHeader("X-Requested-With", "XMLHttpRequest");
httpPost.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36");
httpPost.setHeader("Host", "ensdp.njit.edu.cn:10443");
httpPost.setHeader("Origin", "https://ensdp.njit.edu.cn:10443");
httpPost.setHeader("Referer", "https://ensdp.njit.edu.cn:10443/http/webvpn3e1a11b7208e283ab07ade5d2913fc13d6f6fe09d2dc7372db2a51a14aa4167a/jwglxt/kbcx/xskbcx_cxXskbcxIndex.html?gnmkdm=N2151&layout=default");
httpPost.setHeader("Cookie", cookie);
httpPost.setHeader("Content-Type", "application/x-www-form-urlencoded;charset=UTF-8");
// 将参数转换为表单数据格式
String postParams = params.entrySet().stream()
.map(entry -> entry.getKey() + "=" + entry.getValue())
.collect(Collectors.joining("&"));
StringEntity entity = new StringEntity(postParams, StandardCharsets.UTF_8);
httpPost.setEntity(entity);
// 执行POST请求,获取HttpResponse对象
HttpResponse response = httpClient.execute(httpPost);
System.out.println(httpPost.getURI());
// 获取响应的状态码并打印
int statusCode = response.getStatusLine().getStatusCode();
System.out.println("状态码: " + statusCode);
// 获取响应实体
HttpEntity responseEntity = response.getEntity();
if (responseEntity != null) {
// 将响应实体转换为字符串
responseBody = EntityUtils.toString(responseEntity, StandardCharsets.UTF_8);
}
} catch (ClientProtocolException e) {
// 处理客户端协议异常
throw new RuntimeException(e);
} catch (IOException e) {
// 处理I/O异常
throw new RuntimeException(e);
} finally {
// 确保关闭HttpClient对象,释放资源
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
// System.out.println(responseBody);
return responseBody;
}
处理拿到的响应结果
responseBody是一个json格式的字符串,先转为json格式。拿到json中的items 数组。遍历items数组,每一个都是一个json对象。 这里使用了fastJson的库。
String responseBody = executePostRequest(url, params,cookie);
//打印了响应结果
System.out.println("响应结果: " + responseBody);
JSONObject jsonObject = JSON.parseObject(responseBody);
JSONArray kbList = jsonObject.getJSONArray("items"); //拿到所有的成绩
List<Score> scores = new ArrayList<>();
for (Object o : kbList) {
JSONObject jsonObject1 = (JSONObject) o;
String StudentName = jsonObject1.getString("xm");
String StudentId = jsonObject1.getString("xh");
String courseName = jsonObject1.getString("kcmc");
String grade = jsonObject1.getString("cj");
String type = jsonObject1.getString("kcxzmc") + "课";
double credit = Double.parseDouble(jsonObject1.getString("xf"));
Score score = new Score(null, StudentName, StudentId, courseName, type, credit, grade);
scores.add(score);
}
代码运行结果

版权归原作者 全栈阿星 所有, 如有侵权,请联系我们删除。