
一、为什么要分库分表
如果一个网站业务快速发展,那这个网站流量也会增加,数据的压力也会随之而来,比如电商系统来说双十一大促对订单数据压力很大,Tps十几万并发量,如果传统的架构(一主多从),主库容量肯定无法满足这么高的Tps,业务越来越大,单表数据超出了数据库支持的容量,持久化磁盘IO,传统的数据库性能瓶颈,产品经理业务·必须做,改变程序,数据库刀子切分优化。数据库连接数不够需要分库,表的数据量大,优化后查询性能还是很低,需要分。
二、什么是分库分表
分库分表方案是对关系型数据库数据存储和访问机制的一种补充。
分库:将一个库的数据拆分到多个相同的库中,访问的时候访问一个库
分表:把一个表的数据放到多个表中,操作对应的某个表就行
三、分库分表的几种方式
1.垂直拆分
(1) 数据库垂直拆分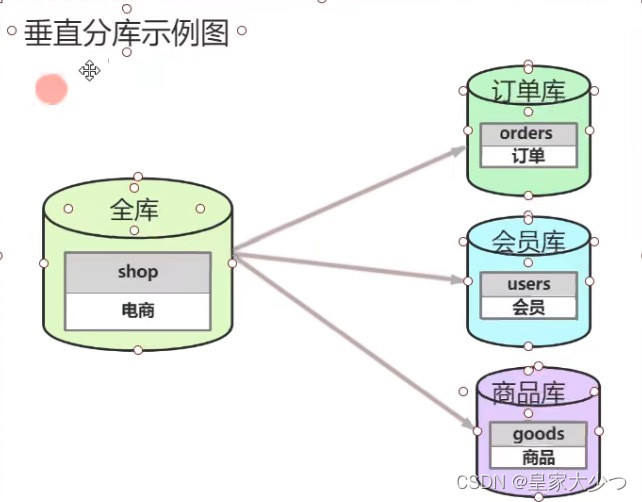 根据业务拆分,如图,电商系统,拆分成订单库,会员库,商品库
根据业务拆分,如图,电商系统,拆分成订单库,会员库,商品库
(2)表垂直拆分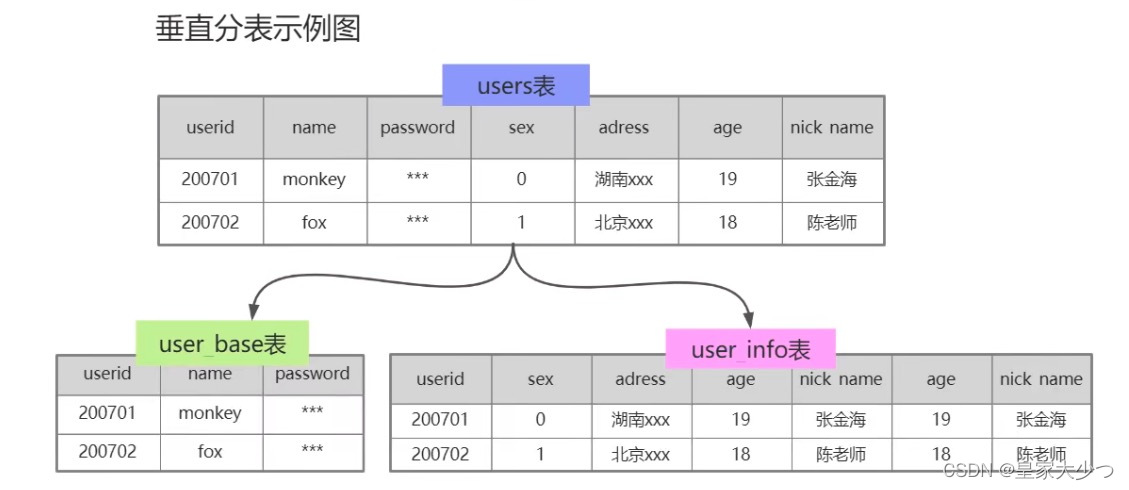
根据业务去拆分表,如图,把user表拆分成user_base表和user_info表,use_base负责存储登录,user_info负责存储基本用户信息
垂直拆分特点
1.每个库(表)的结构都不一样
2.每个库(表)的数据至少一列一样
3.每个库(表)的并集是全量数据
垂直拆分优缺点
优点:
1.拆分后业务清晰(专库专用按业务拆分)
2.数据维护简单,按业务不同,业务放到不同机器上
缺点:
1.如果单表的数据量,写读压力大
2.受某种业务决定,或者被限制,也就是说一个业务往往会影响到数据库的瓶颈(性能问题,如双十一抢购)
3.部分业务无法关联join,只能通过java程序接口去调用,提高了开发复杂度
2. 水平拆分
(1) 数据库水平拆分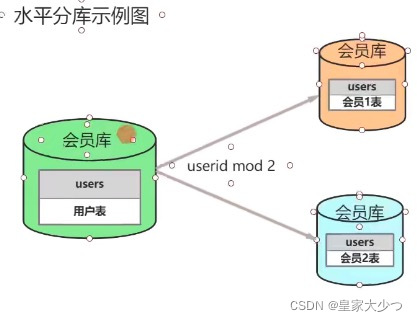
如图,按会员库拆分,拆分成会员1库,会员2库,以userId拆分,userId尾号0-5为1库
6-9为2库,还有其他方式,进行取模,偶数放到1库,奇数放到2库
(2) 表水平拆分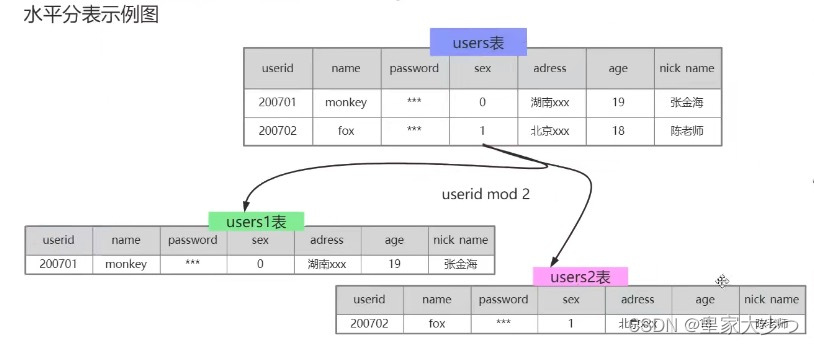
如图把users表拆分成users1表和users2表,以userId拆分,进行取模,偶数放到users1表,奇数放到users2表
水平拆分的其他方式
- range来分,每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了,优点:扩容的时候,就很容易,因为你只要预备好,给每个月都准备一个库就可以了,到了一个新的月份的时候,自然而然,就会写新的库了 缺点:大部分的 请求,都是访问最新的数据。实际生产用range,要看场景,你的用户不是仅仅访问最新的数据,而是均匀的访问现在的数据以及历史的数据
- hash分发,优点:可以平均分配每个库的数据量和请求压力 缺点:扩容起来比较麻烦,会有一个数据迁移的这么一个过程
水平拆分特点
1.每个库(表)的结构都一样
2.每个库(表)的数据都不一样
3.每个库(表)的并集是全量数据
水平拆分优缺点
优点:
1.单库/单表的数据保持在一定量(减少),有助于性能提高
2.提高了系统的稳定性和负载能力
3.拆分表的结构相同,程序改造较少。
缺点:
1.数据的扩容很有难度维护量大
2.拆分规则很难抽象出来
3.分片事务的一致性问题部分业务无法关联join,只能通过java程序接口去调用
四、分库分表带来的问题
- 分布式事务
- 跨库join查询
- 分布式全局唯一id
- 开发成本 对程序员要求高
五、分库分表技术如何选型
分库分表的开源框架
jdbc 直连层:shardingsphere、tddl
proxy 代理层:mycat,mysql-proxy(360)
jdbc直连层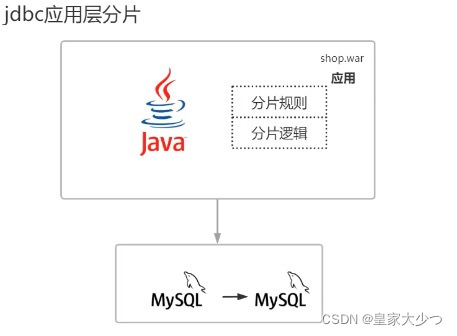
jdbc直连层又叫jdbc应用层,是因为所有分片规则,所有分片逻辑,包括处理分布式事务
所有这些问题它都是在应用层,所有项目都是由war包构成的,所有分片都写成了jar包,放到了war包里面,java需要虚拟机去运行的,虚拟机运行的时候就会把war包里面的字节文件进行classLoder加载到jvm内存中,所有分片逻辑都是基于内存方进行操作的
proxy代理层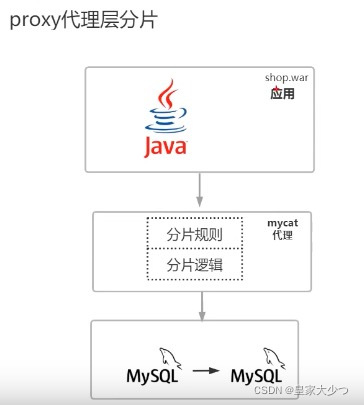
如图,proxy代理层,所有分片规则,所有分片逻辑,包括处理分布式事务都在mycat写好了,所有分片逻辑都是基于mycat方进行操作
jdbc直连层和proxy代理层优缺点
- jdbc直连层性能高,只支持java语言,支持跨数据库
- proxy代理层开发成本低,支持跨语言,不支持跨数据库
版权归原作者 请叫我黄同学 所有, 如有侵权,请联系我们删除。