
简介
基本介绍
核心组件及概念
Topic :每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的。 Producer:消息生产者,发布消息到 kafka 集群的终端或服务。 consumer:从 kafka 集群中消费消息的终端或服务。 Broker: 集群中的每一个服务器都是一个Broker(代理). Partition:每个 topic 包含一个或多个 partition。kafka 分配的单位是 partition。 Segment:partition物理上由多个segment组成。 offset : 每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续递增的序列号叫做offset,偏移量offset在每个分区中是唯一的。
replica: partition 的副本,保障 partition 的高可用。 follower: replica 中的一个角色,从 leader 中复制(fentch)数据。 leader: replica 中的一个角色, producer 和 consumer 只跟 leader 交互。 controller:kafka 集群中的其中一个服务器,用来进行 leader 选举以及 各种 故障转移。 zookeeper:kafka 通过 zookeeper 来存储集群的 meta 信息。 Consumer group:high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息和partition只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。
一个Topic分为多个Partition来进行数据管理,一个Partition中的数据是有序、不可变 的,使用偏移量(offset)唯一标识一条数据,是一个long类型的数据 Partition接收到producer发送过来数据后,会产生一个递增的offset偏移量数据,同时 将数据保存到本地的磁盘文件中(文件内容追加的方式写入数据);Partition中的数据存活时间超过参数值(log.retention.{ms,minutes,hours},默认7天)的时候进行删除(默认) Consumer根据offset消费对应Topic的Partition中的数据(也就是每个Consumer消费的每个Topic的Partition都拥有自己的offset偏移量)注意:Kafka的数据消费是顺序读写的,磁盘的顺序读写速度(600MB/sec)比随机读写 速度(100k/sec)快 Kafka集群中由producer负责数据的产生,并发送到对应的Topic;Producer通 过push的方式将数据发送到对应Topic的分区 Producer发送到Topic的数据是有key/value键值对组成的,Kafka根据key的不 同的值决定数据发送到不同的Partition,默认采用Hash的机制发送数据到对应Topic的不同Partition中,配置参数为{partitioner.class}.也可以配置自定义分配机制,自定义类实现Partitioner接口,重写partition方法的方式. Producer发送数据的方式分为sync(同步)和async(异步)两种,默认为同步方式, 由参数{producer.type}决定;当发送模式为异步发送的时候,Producer提供重 试机制,默认失败重试发送3次. spring.kafka.producer.batch-size=16384 //通过这个参数来设置批量提交的数据大小,默认是16k,当积压的消息达到这个值的时候就会统一发送(发往同一分区的消息) spring.kafka.producer.properties.linger.ms=50 //这个设置是为发送设置一定是延迟来收集更多的消息,默认大小是0ms spring.kafka.producer.buffer-memory = 33554432 //生产端缓冲区大小 发送的消息会先进入到本地缓冲区(32mb),kakfa会跑一个线程,该线程去缓冲区中取16k的数据,发送到kafka,如果到 10 毫秒数据没取满16k,也会发送一次。异步的时候假如设置了缓存消息数量为200,但是一直没有200条数据,那么不可能会一直等下去,就会取16kb大小的数据,直接发,不够16kb也会发。 生产者同步发消息,在收到kafka的ack告知发送成功之前一直处于阻塞状态 生产者发消息,发送完之后不用等待broker给回复,直接执行下面的业务逻辑。可以提供回调方法,让broker异步的调用callback,告知生产者,消息发送的结果。如果告知的结果异常,再进行相应的处理操作
Kafka有两种模式消费数据:队列和发布订阅;在队列模式下,一条数据只会发 送给customer group中的一个customer进行消费;在发布订阅模式下,一条数 据会发送给多个customer进行消费 8. Kafka的Customer基于offset对kafka中的数据进行消费,对于一个customer group中的所有customer共享一个offset偏移量 9. Kafka中通过控制Customer的参数{group.id}来决定kafka是什么数据消费模式, 如果所有消费者的该参数值是相同的,那么此时的kafka就是类似于队列模式, 数据只会发送到一个customer,此时类似于负载均衡;否则就是发布订阅模式 10. Kafka的数据是按照分区进行排序的(插入的顺序),也就是每个分区中的数据是有 序的。在Consumer进行数据消费的时候,也是对分区的数据进行有序的消费的, 但是不保证所有数据的有序性(多个分区之间)(同一个分区数据先进相出) 11.Consumer Rebalance:当一个consumer group组中的消费者数量和对应Topic的分区数量一致的时候,此时一个Consumer消费一个Partition的数据; 如果不一致,那么可能出现一个Consumer消费多个Partition的数据或者不消费 数据的情况,这个机制是根据Consumer和Partition的数量动态变化的
Consumer通过poll的方式主动从Kafka集群中获取数据 Kafka的Replication指的是Partition的复制,一个Partition的所有分区中只有 一个分区是leader节点,其它分区是follower节点。Replication对Kafka的吞吐率有一定的影响,但是极大的增强了可用性。Follower节点会定时的从leader节点上获取增量数据,一个活跃的follower节点 必须满足一下两个条件: 所有的节点必须维护和zookeeper的连接(通过zk的heartbeat实现) follower必须能够及时的将leader上的writing复制过来,不能“落后太多”;落后太多,由参数{replica.lag.time.max.ms}和{replica.lag.max.messages}决定 MessageDeliverySemantics是消息系统中数据传输的可靠性保证的一个定义,主要 分为三种类型: At most once(最多一次):消息可能会丢失,但是不可能重复发送 At least once(最少一次):消息不可能丢失,但是可能重复发送 Exactly once(仅仅一次):消息只发送一次,但不存在消息的丢失 Kafka的Producer通过参数{request.required.acks}来定义确定Producer和Broker之间 是哪种消息传递类型 Ack=0,相当于异步发送,意味着producer不等待broker同步完成,消息发送完毕继续发送下一批信息。提供了最低延迟,但持久性最弱,当服务器发生故障时很可能发生数据丢失。如果leader死亡,producer继续发送消息,broker接收不到数据就会造成数据丢失。 Ack=1,producer要等待leader成功收到消息并确认,才发送下一条message。提供较低的延迟性以及较好的持久性。但是如果partition下的leader死亡,而follower尚未复制数据,数据就会丢失。 Ack=-1,leader收到所有消息,且follower同步完数据,才发送下一条数据。延迟性最差,持久性最好(即可靠性最好)。 三种参数设置性能递减,可靠性递增。 同时,Ack默认值为1,此时吞吐量与可靠性折中。实际生产中可以根据实际需求进行调整。

自动提交
配置参数:
spring.kafka.consumer.enable-auto-commit=true 提交offset延时(接收到消息后多久提交offset),默认5s
spring.kafka.consumer.auto-commit-interval.ms=5000
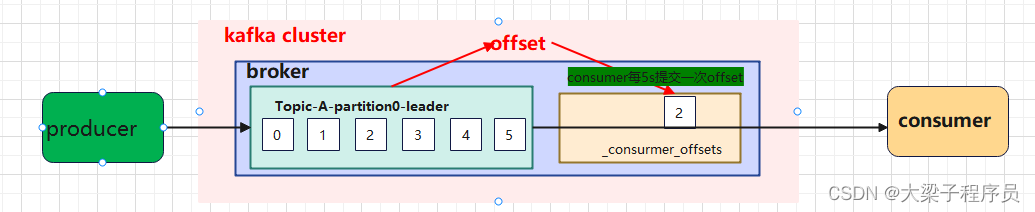
重复消费
如上图:如果消费到第二条数据时,consumer挂了,导致数据消费了但是没有提交,等consumer启动之后,会依据本地的offset 继续拉取之前消费的数据,导致重复消费数据
漏消费
如果一次性拉取5条数据,数据会被依次消费,但是5s内由于业务太过复杂,数据没有完全持久化,消费者就提交了,提交完之后,消费端挂了,等消费端起来之后,不会继续拉取之前5条数据,因为这5条数据被提交了
手动提交
虽然自动提交offset十分简单遍历,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此kafka还提供了手动提交offset的api。 手动提交分为:(通常使用异步提交方式多一些,追求效率) 同步提交 commitSync:拉取数据提交offset会进入阻塞状态,直到提交成功后才开始下一次的拉取。 异步提交 commitAsync:拉取数据和提交offset异步进行,不会管offset是否提交成功
相同点:都会将本次拉取的数据最高的偏移量进行提交 不同点:同步提交会阻塞当前线程,一直到提交成功,并且会自动失败重试。异步提交就不会有失败重试。
commitSync(同步提交):必须等待offset提交完毕才会消费下一批数据
commitAsync(异步提交):发送提交请求就会消费下一批数据

拉取消息后 「 先提交 Offset,后处理消息 」 ,如果此时处理消息的时候异常宕机,由于 Offset 已经提交了, 待 Consumer 重启后,会从之前已提交的 Offset 下一个位置重新开始消费, 之前未处理完成的消息不会被再次处理,对于该 Consumer 来说消息就丢失了。 拉取消息后 「 先处理消息,在进行提交 Offset 」 , 如果此时在提交之前发生异常宕机,由于没有提交成功 Offset, 待下次 Consumer 重启后还会从上次的 Offset 重新拉取消息,不会出现消息丢失的情况, 但是会出现重复消费的情况,这里只能业务自己保证幂等性。
数据不丢失问题
对于数据重试其实造成的影响远远小于数据丢失问题,数据重试我们落盘时可以才去去重的方式解决
生产端:采用普通的Producer.send(msg) 会立即返回,称为【发完即焚】,没有回调,如果网络出现问题,broker并没有收到其发送的消息,那么这条消息就会被丢失了。
- 更换调用方式:弃用调用发后即焚的方式,使用带回调通知函数的方法进行发送消息,即 Producer.send(msg, callback) , 这样一旦发现发送失败, 就可以做针对性处理。
- ACK 确认机制:对于集群的场景下,每个partition都有其多个副本,数据同步到副本才算是真正消息提交成功。如果leader挂了,通过选举的方式选出一个leader,这样做的目的就是为了保证数据不会丢失。而消费端只会关心leader。如果broker一直没返回ACK标识,需要将 request.required.acks 设置为 -1/ all ,-1/all 表示有多少个副本 Broker 全部收到消息,才认为是消息提交成功的标识。针对 acks = -1/ all;(ACK = 0,发送一次,不论leader是否接收。ACK = 1 (默认)等待leader接收成功即可。)
- 重试次数 retries,依据2来的,该参数表示 Producer 端发送消息的重试次数。需要将 retries 设置为大于0的数, 在 Kafka 2.4 版本中默认设置为 Integer.MAX_VALUE。另外如果需要保证发送消息的顺序性,配置如下 retries = Integer.MAX_VALUE max.in.flight.requests.per.connection = 1 这样 Producer 端就会一直进行重试直到 Broker 端返回 ACK 标识,同时只有一个连接向 Broker 发送数据保证了消息的顺序性。
- 重试时间 retry.backoff.ms: 该参数表示消息发送超时后 两次重试之间的间隔时间 ,避免无效的频繁重试,默认值为100ms, 推荐设置为300ms 。 消费端:正确的做法是: 拉取数据、 业务逻辑处理、 提交消费 Offset 位移信息。 我们还需要设置参数 enable.auto.commit = false, 采用手动提交位移的方式。 另外对于消费消息重复的情况,业务自己保证幂等性, 保证只成功消费一次即可
kafka分区分配策略-Range
RangeRobin Range策略是kafka默认的消费者分区分配策略,它是针对topic维度的,首先对同一个topic里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。
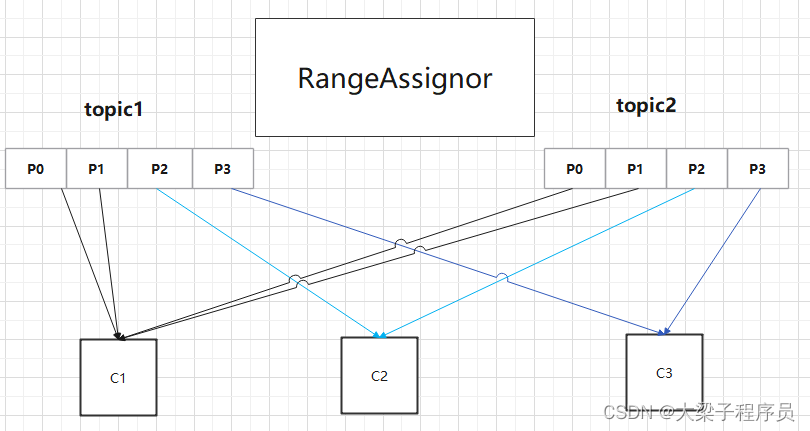
首先对于topic1中的四个分区先4/3=1分配, 每个消费者分配一个partition,最后剩一个分配给 c1
缺点: 容易造成数据倾斜,对于少量的topic来说无关紧要,但是 如果成百上千个topic会造成c1的压力要远远比其它消费者 压力大的多
kafka分区分配策略-轮询
RoundRobin RoundRobin是针对所有topic分区。它是采用轮询分区策略,是把所有的partition和所有的consumer列举出来,然后按照hashcode进行排序,最后再通过轮询算法来分配partition给每个消费者。
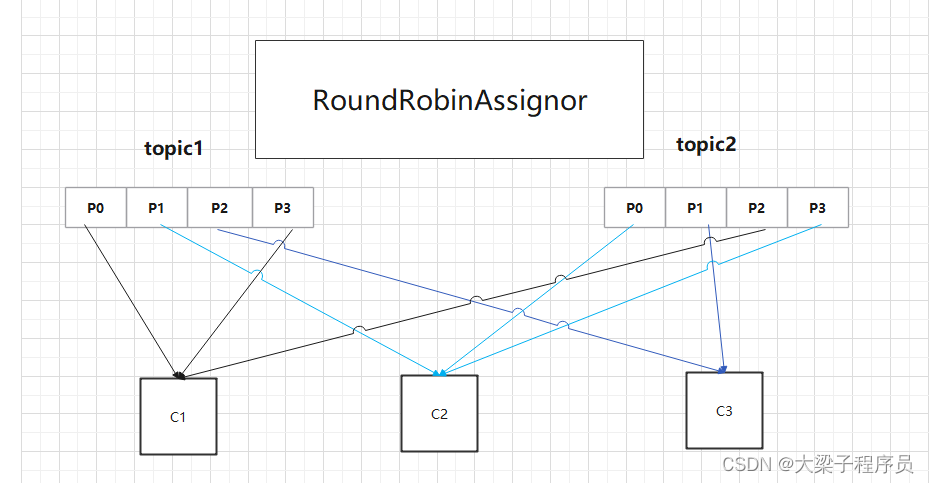
缺点1: 有可能出现不满足具体业务实际,如果正常情况下业务如右图所示消费,但有天需要只想让c1消费topic1里面数据,但这时还是可以得到topic2
缺点2: 右图分区数量是相同的,分配的就较均匀,但是分区数量不相同,并且组内消费者订阅topic不均时,这时消费者分配的partiotion就不会很均匀
综上所述,灵活性比较差,无法灵活的应对不断变更的业务需求,而且粘性缺乏严重
kafka分区分配策略-粘性
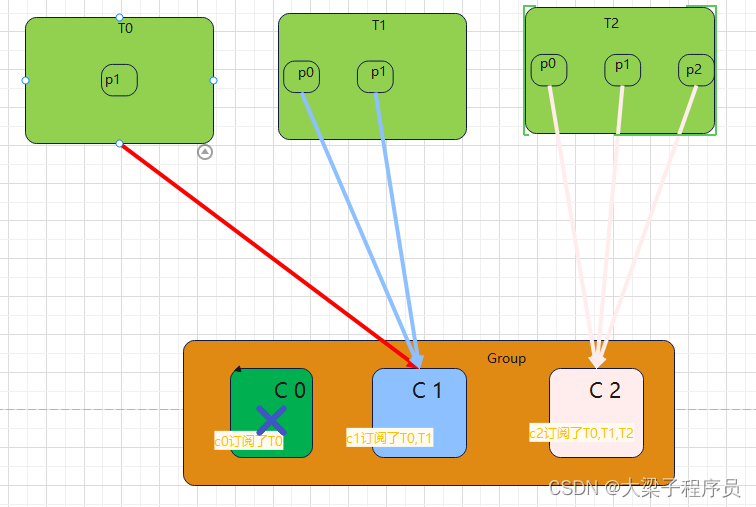
StickyAssignor策略,“sticky”这个单词可以翻译为“粘性的”,Kafka从0.11.x版本开始引入这种分配策略,它主要有两个目的: ① 分区的分配要尽可能的均匀; ② 分区的分配尽可能的与上次分配的保持相同。 当两者发生冲突时,第一个目标优先于第二个目标。鉴于这两个目标,StickyAssignor策略的具体实现要比RangeAssignor和RoundRobinAssignor这两种分配策略要复杂很多。
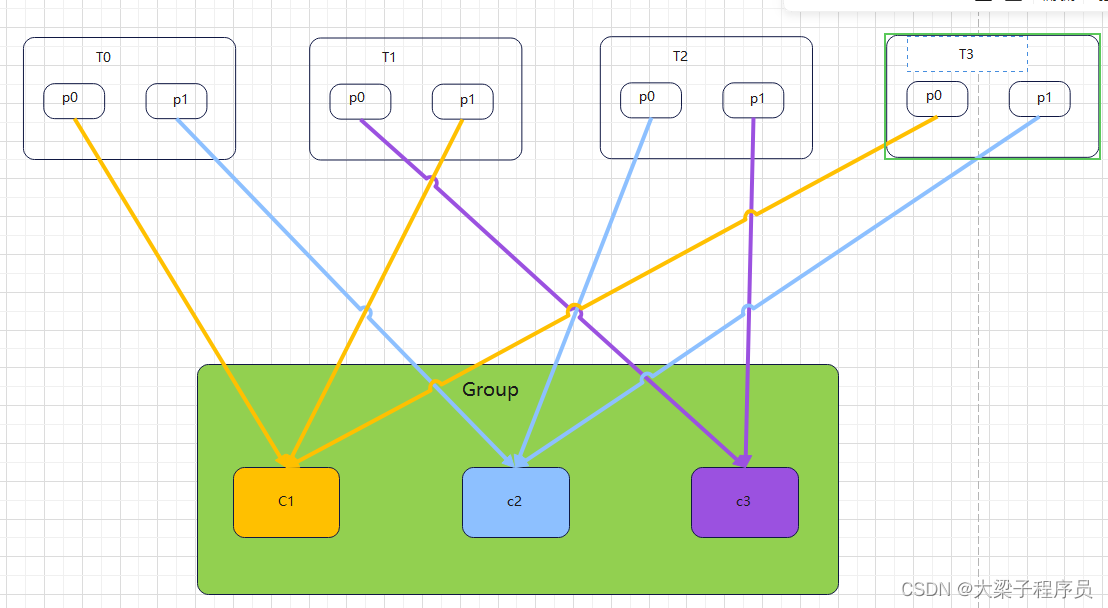
** 如果采用RoundRobinAssignor轮询策略,一个消费者挂了,结果如下:**
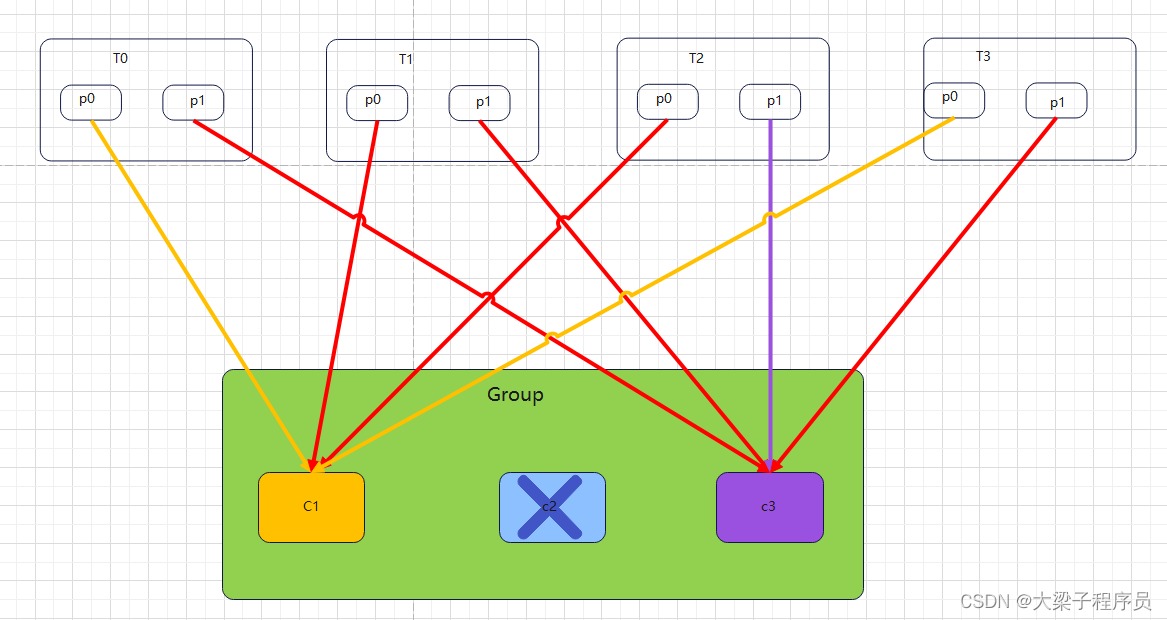
如果采用StickyAssignor策略,那么分配结果为:
可以看到分配结果中保留了上一次分配中对于消费者C0和C2的所有分配结果,并将原来消费者C1的“负担”分配给了剩余的两个消费者C0和C2,最终C0和C2的分配还保持了均衡。 如果发生分区重分配,那么对于同一个分区而言有可能之前的消费者和新指派的消费者不是同一个,对于之前消费者进行到一半的处理还要在新指派的消费者中再次复现一遍,这显然很浪费系统资源。StickyAssignor策略如同其名称中的“sticky”一样,让分配策略具备一定的“粘性”,尽可能地让前后两次分配相同,进而减少系统资源的损耗以及其它异常情况的发生。
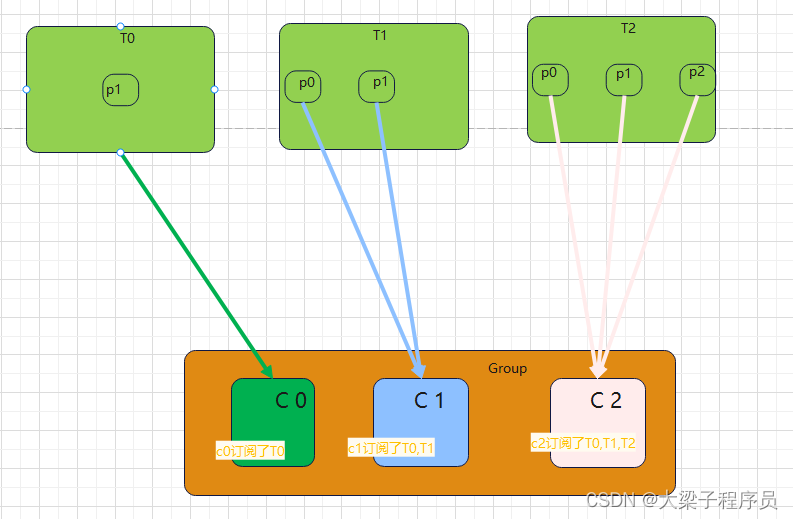
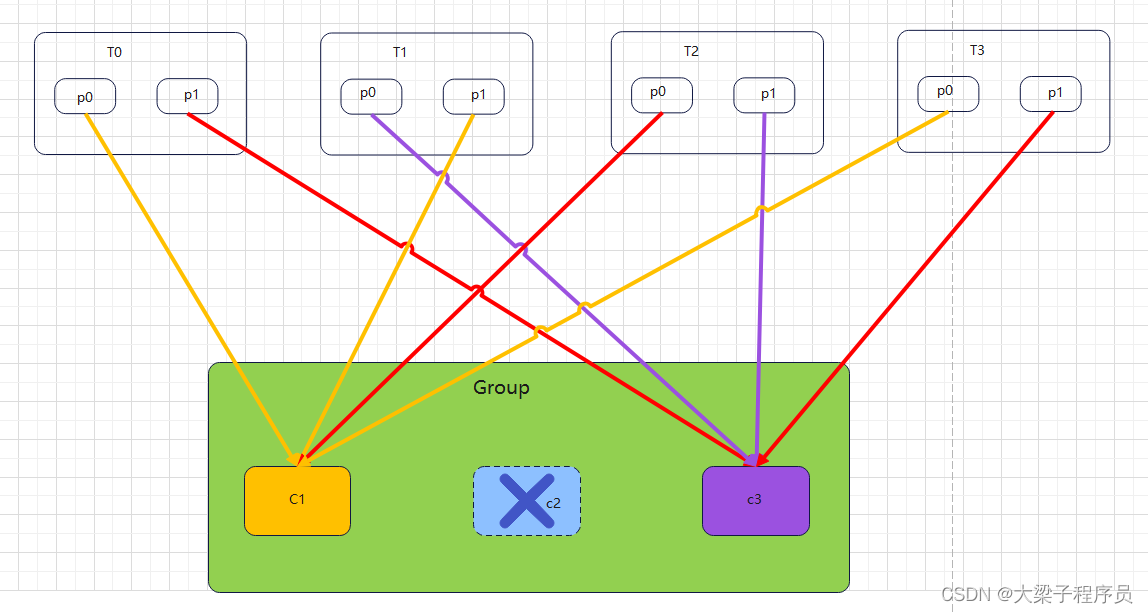
如果采用RoundRobinAssignor策略,订阅不同的主题topic,那么分配结果为:
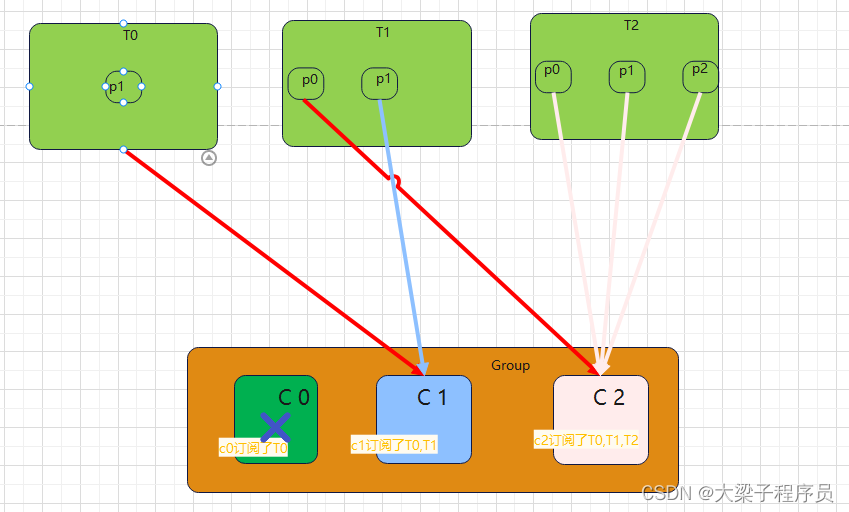
如果采用StickyAssignor策略,订阅不同主题,那么分配结果为:
可以看到StickyAssignor策略保留了消费者C1和C2中原有的5个分区的分配:t1p0、t1p1、t2p0、t2p1、t2p2。
kafka与rabbitmq吞吐量对比
rabbitmq架构
RabbitMQ 是一个分布式系统,这里面有几个抽象概念。 broker:每个节点运行的服务程序,功能为维护该节点的队列的增删以及转发队列操作请求。 master queue:每个队列都分为一个主队列和若干个镜像队列。 mirror queue:镜像队列,作为 master queue 的备份。在 master queue 所在节点挂掉之后,系统把 mirror queue 提升为 master queue,负责处理客户端队列操作请求。注意,mirror queue 只做镜像,设计目的不是为了承担客户端读写压力。如图:
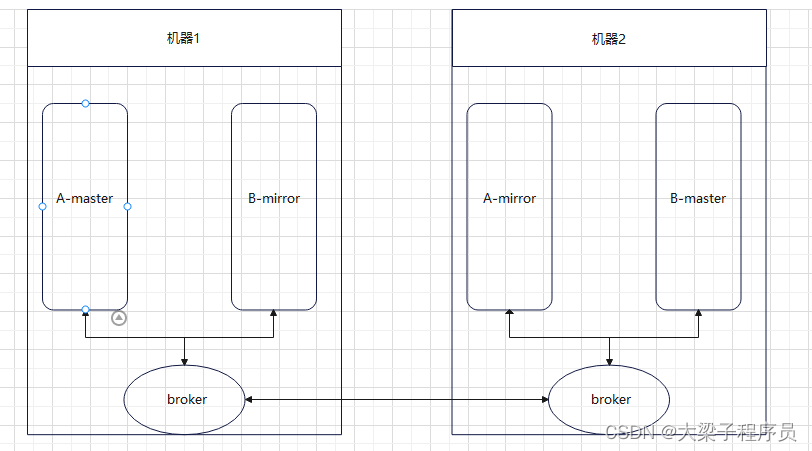
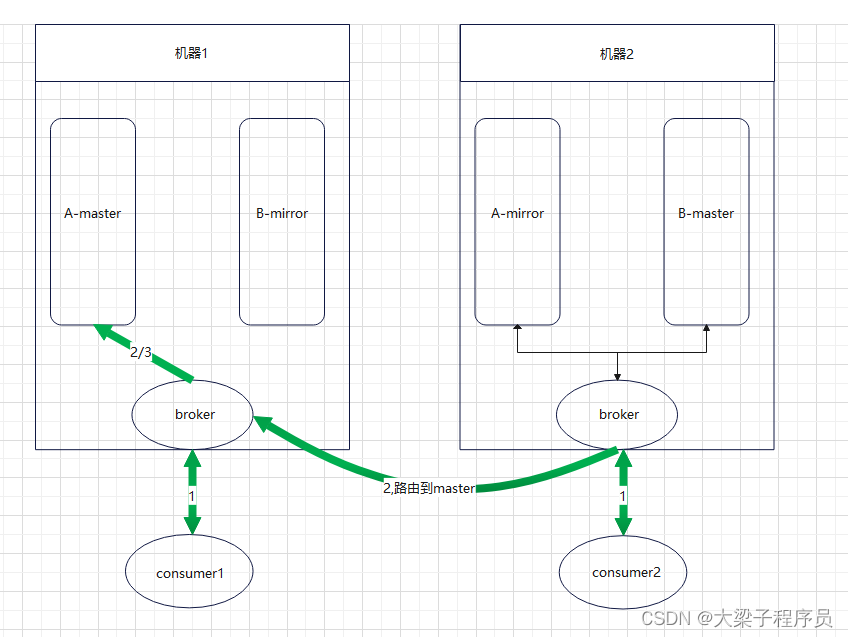
如上图所示,集群中有两个节点,每个节点上有一个broker,每个broker负责本机上队列的维护,并且borker之间可以互相通信。集群中有两个队列A和B,每个队列都分为master queue和mirror queue(备份)。那么队列上的生产消费怎么实现的呢?
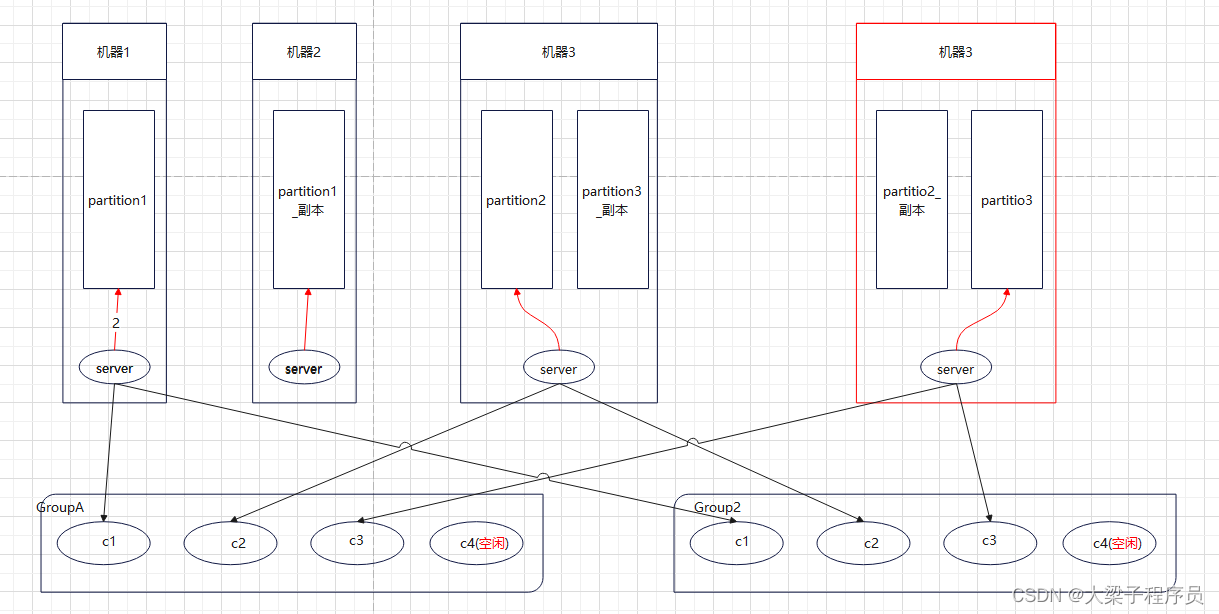
kafka集群架构
看到了 RabbitMQ 这个缺陷才设计出的一个改进版,改进的点就是:把一个队列的单一 master 变成多个 master,即一台机器扛不住 qps,那么我就用多台机器扛 qps,把一个队列的流量均匀分散在多台机器上不就可以了么?注意,多个 master 之间的数据没有交集,即一条消息要么发送到这个 master queue,要么发送到另外一个 master queue。 这里面的每个 master queue 在 Kafka 中叫做 Partition,即一个分片。一个队列有多个主分片,每个主分片又有若干副分片做备份,同步机制类似于 RabbitMQ
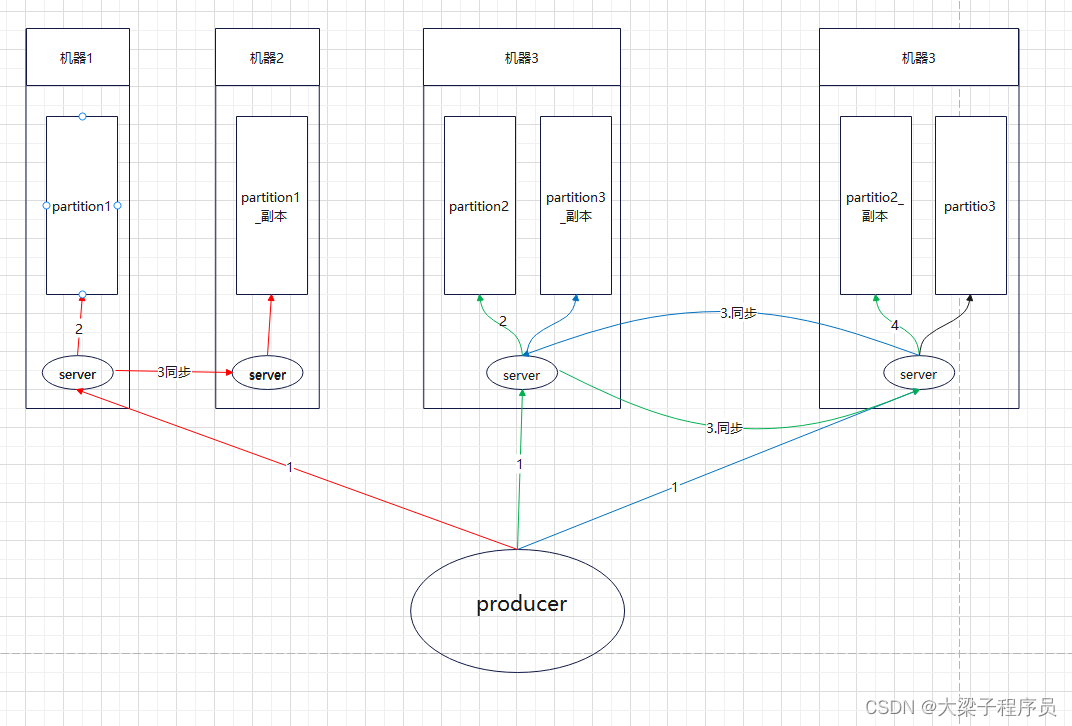
Kafka数据总线 队列读取的时候虚拟出一个 Group 的概念,一个 Topic 内部的消息,只会路由到同 Group 内的一个 consumer 上,同一个 Group 中的 consumer 消费的消息是不一样的;Group 之间共享一个 Topic,看起来就是一个队列的多个拷贝。 所以,为了达到多个 Group 共享一个 Topic 数据,Kafka 并不会像 RabbitMQ 那样消息消费完毕立马删除,而是必须在后台配置保存日期,即只保存最近一段时间的消息,超过这个时间的消息就会从磁盘删除,这样就保证了在一个时间段内, Topic 数据对所有 Group 可见(这个特性使得 Kafka 非常适合做一个公司的数据总线)。 队列读同样是读主分片,并且为了优化性能,消费者与主分片有一一的对应关系,如果消费者数目大于分片数,则存在某些消费者得不到消息。 由此可见,Kafka 绝对是为了高吞吐量设计的,比如设置分片数为 100,那么就有 100 台机器去扛一个 Topic 的流量,当然比 RabbitMQ 的单机性能好。
总结:
吞吐量较低:Kafka 和 RabbitMQ 都可以。
吞吐量高:Kafka。
实战
基本配置
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.6.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>kafka-server</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>kafka-server</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.83</version>
</dependency>
<dependency>
<groupId>com.minivision.maiot</groupId>
<artifactId>maiot-common-base</artifactId>
<version>1.4.1-SNAPSHOT</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
application.properties
server.port=9999
###########【Kafka集群】###########
spring.kafka.bootstrap-servers=172.23.189.69:9092
#==================================【初始化生产者配置】==================================#
# 重试次数
spring.kafka.producer.retries=3
# 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
#Ack=0,相当于异步发送,意味着producer不等待broker同步完成,消息发送完毕继续发送下一批信息。提供了最低延迟,但持久性最弱,当服务器发生故障时很可能发生数据丢失。如果leader死亡,producer继续发送消息,broker接收不到数据就会造成数据丢失。
#
#Ack=1,producer要等待leader成功收到消息并确认,才发送下一条message。提供较低的延迟性以及较好的持久性。但是如果partition下的leader死亡,而follower尚未复制数据,数据就会丢失。
#
#Ack=-1,leader收到所有消息,且follower同步完数据,才发送下一条数据。延迟性最差,持久性最好(即可靠性最好)。
#
#三种参数设置性能递减,可靠性递增。
#
#同时,Ack默认值为1,此时吞吐量与可靠性折中。实际生产中可以根据实际需求进行调整。
spring.kafka.producer.acks=all
# 批量大小 (通过这个参数来设置批量提交的数据大小,默认是16k,当积压的消息达到这个值的时候就会统一发送(发往同一分区的消息))
spring.kafka.producer.batch-size=16384
# 提交延时(这个设置是为发送设置一定是延迟来收集更多的消息,默认大小是0ms(就是有消息就立即发送)当这两个参数同时设置的时候,
# 只要两个条件中满足一个就会发送。比如说batch.size设置16kb,linger.ms设置50ms,那么当消息积压达到16kb就会发送,如果没有到达16kb,
# 那么在第一个消息到来之后的50ms之后消息将会发送。)
spring.kafka.producer.properties.linger.ms=50
# 当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka
# linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了
# 生产端缓冲区大小
spring.kafka.producer.buffer-memory = 33554432
#设置事务前缀
spring.kafka.producer.transaction-id-prefix= tx_
# Kafka提供的序列化和反序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 自定义分区器
spring.kafka.producer.properties.partitioner.class=com.kafkaserver.strategy.CustomizePartitioner
#==================================【初始化消费者配置】==================================#
# 默认的消费组ID
spring.kafka.consumer.properties.group.id=defaultConsumerGroup
# 是否自动提交offset
spring.kafka.consumer.enable-auto-commit=false
# 提交offset延时(接收到消息后多久提交offset)
spring.kafka.consumer.auto-commit-interval.ms=1000
# 当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
spring.kafka.consumer.auto-offset-reset=latest
# 消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
spring.kafka.consumer.properties.session.timeout.ms=120000
# 消费请求超时时间
spring.kafka.consumer.properties.request.timeout.ms=180000
# Kafka提供的序列化和反序列化类
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 消费端监听的topic不存在时,项目启动会报错(关掉)
spring.kafka.listener.missing-topics-fatal=false
spring.kafka.listener.ack-mode=manual
# 设置批量消费
spring.kafka.listener.type=batch
# 设置并发消费
spring.kafka.listener.concurrency=3
#batch和single
# 批量消费每次最多消费多少条消息
spring.kafka.consumer.max-poll-records=50
#设置默认topic
#spring.kafka.template.default-topic=radar
##设置topic分区大小
#spring.kafka.template.patitions=7
##设置重试数量
#spring.kafka.template.replications=-1
工厂创建
@Configuration
@EnableKafka
public class KafkaServerConfiguration {
//*****************生产者配置********************
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Value("${spring.kafka.producer.retries}")
private Integer retries;
@Value("${spring.kafka.producer.acks}")
private String acks;
@Value("${spring.kafka.producer.batch-size}")
private Integer batchSize;
@Value("${spring.kafka.producer.properties.linger.ms}")
private Integer lingerMs;
@Value("${spring.kafka.producer.buffer-memory}")
private Integer bufferMemory;
@Value("${spring.kafka.producer.transaction-id-prefix:tx}")
private String transactionId_Prefix;
/**
* 生产者配置信息
*/
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.ACKS_CONFIG, acks);
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.RETRIES_CONFIG, retries);
// props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG,1);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize);
props.put(ProducerConfig.LINGER_MS_CONFIG, lingerMs);
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomizePartitioner.class);
return props;
}
/**
* 生产者工厂
*/
@Bean
public ProducerFactory<String, String> producerFactory() {
DefaultKafkaProducerFactory<String, String> producerFactory = new DefaultKafkaProducerFactory<>(producerConfigs());
//添加事务id前缀
producerFactory.transactionCapable();
producerFactory.setTransactionIdPrefix(transactionId_Prefix);
return producerFactory;
}
@Bean
public ProducerFactory<String, String> producerFactory1() {
DefaultKafkaProducerFactory<String, String> producerFactory = new DefaultKafkaProducerFactory<>(producerConfigs());
//添加事务id前缀
// producerFactory.setTransactionIdPrefix(transactionId_Prefix);
return producerFactory;
}
/**
* 生产者模板
*/
@Bean(name = "kafkaTemplate")
@Primary
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory1());
}
@Bean(name = "transactionKafkaTemplate")
public KafkaTemplate<String, String> transactionKafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
/**
* kafka开启事务管理器
*/
@Bean
public KafkaTransactionManager<String, String> kafkaTransactionManager() {
return new KafkaTransactionManager<>(producerFactory());
}
//****************************消费者配置**************************
@Value("${spring.kafka.consumer.properties.group.id}")
private String groupId;
@Value("${spring.kafka.consumer.enable-auto-commit}")
private Boolean autoCommit;
@Value("${spring.kafka.consumer.auto-offset-reset}")
private String autoOffsetReset;
/**
* 请求有超时时间
*/
@Value("${spring.kafka.consumer.properties.request.timeout.ms}")
private Integer requestTimeoutMs;
/**
* 建立会话超时时间
*/
@Value("${spring.kafka.consumer.properties.session.timeout.ms}")
private Integer sessionTimeoutMs;
@Value("${spring.kafka.listener.ack-mode}")
private String ackMode;
/**
* 并发消费,表示开启几个线程去消费
*/
@Value("${spring.kafka.listener.concurrency}")
private Integer concurrency;
@Value("${spring.kafka.consumer.max-poll-records}")
private Integer maxPollRecords;
/**
* 消费者配置信息
*/
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, autoCommit);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset);
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, maxPollRecords);
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeoutMs);
props.put(ConsumerConfig.REQUEST_TIMEOUT_MS_CONFIG, requestTimeoutMs);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, Collections.singletonList(StickyAssignor.class));
return props;
}
/**
* 消费者批量工厂
*/
@Bean
public KafkaListenerContainerFactory<?> batchFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(consumerConfigs()));
//设置为批量消费,每个批次数量在Kafka配置参数中设置ConsumerConfig.MAX_POLL_RECORDS_CONFIG
factory.setBatchListener(true);
// factory.setConcurrency(concurrency);
//AckMode
/* 当每一条记录被消费者监听器(ListenerConsumer)处理之后提交
RECORD,
当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后提交
BATCH,
当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,距离上次提交时间大于TIME时提交
TIME,
当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后,被处理record数量大于等于COUNT时提交
COUNT,
TIME | COUNT 有一个条件满足时提交
COUNT_TIME,
当每一批poll()的数据被消费者监听器(ListenerConsumer)处理之后, 手动调用Acknowledgment.acknowledge()后提交
MANUAL,
手动调用Acknowledgment.acknowledge()后立即提交
MANUAL_IMMEDIATE,*/
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL);
return factory;
}
/**
* 单条数据消费工厂
*/
@Bean
public KafkaListenerContainerFactory<?> singleFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(consumerConfigs()));
//设置为批量消费,每个批次数量在Kafka配置参数中设置ConsumerConfig.MAX_POLL_RECORDS_CONFIG
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL);
factory.setReplyTemplate(kafkaTemplate());
factory.getContainerProperties().setPollTimeout(3000);
return factory;
}
/**
* 消息过滤工厂
*/
@Bean("filterContainerFactory2")
public ConcurrentKafkaListenerContainerFactory filterContainerFactory(){
ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(consumerConfigs()));
//设置提交偏移量的方式 当Acknowledgment.acknowledge()侦听器调用该方法时,立即提交偏移量
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
// 被过滤的消息将被丢弃
factory.setAckDiscarded(true);
factory.setBatchListener(true);
// 消息过滤策略
factory.setRecordFilterStrategy(consumerRecord -> {
int i = consumerRecord.value().hashCode();
if (i % 2 == 0) {
return false;
}
//返回true消息则被过滤
System.out.println(JSON.toJSONString(consumerRecord.value())+"hashcode is"+i);
return true;
});
return factory;
}
@Bean
public ConcurrentKafkaListenerContainerFactory delayContainerFactory(@Autowired ConsumerFactory consumerFactory) {
ConcurrentKafkaListenerContainerFactory container = new ConcurrentKafkaListenerContainerFactory();
container.setConsumerFactory(consumerFactory);
//禁止KafkaListener自启动
container.setAutoStartup(false);
container.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL);
return container;
}
}
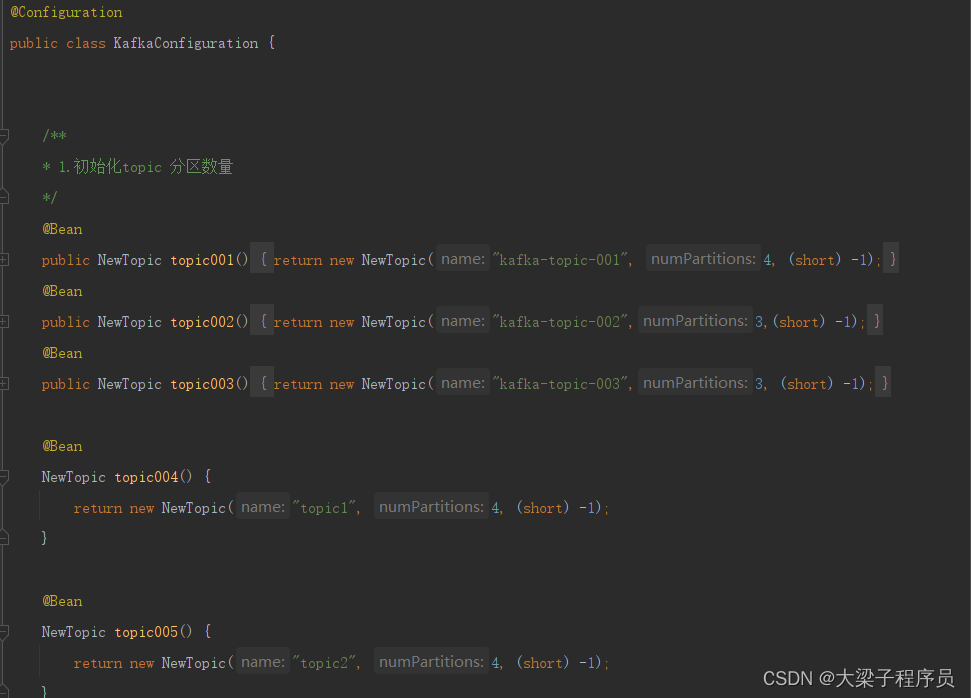
创建topic
实战-一次生产消费过程
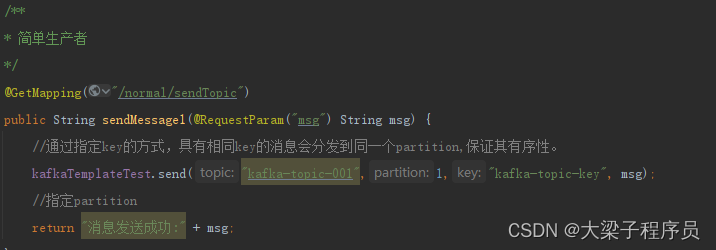
创建生产者,发送数据
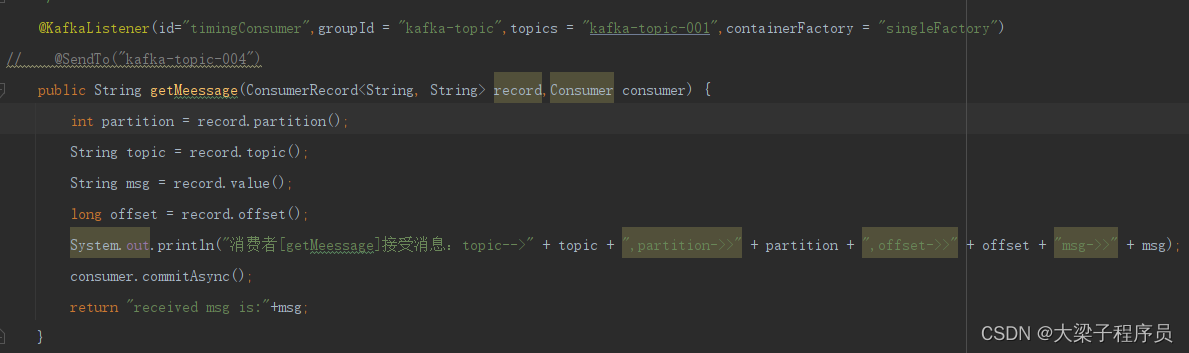
消费者消费数据:
实战-生产者回调机制
带回调的生产者
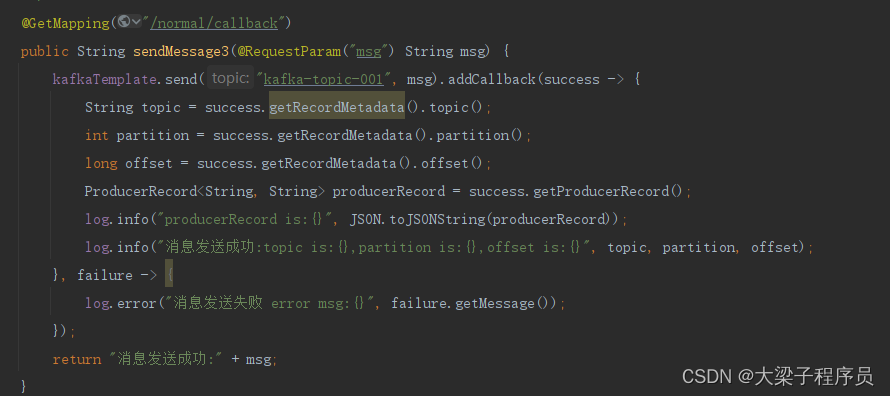
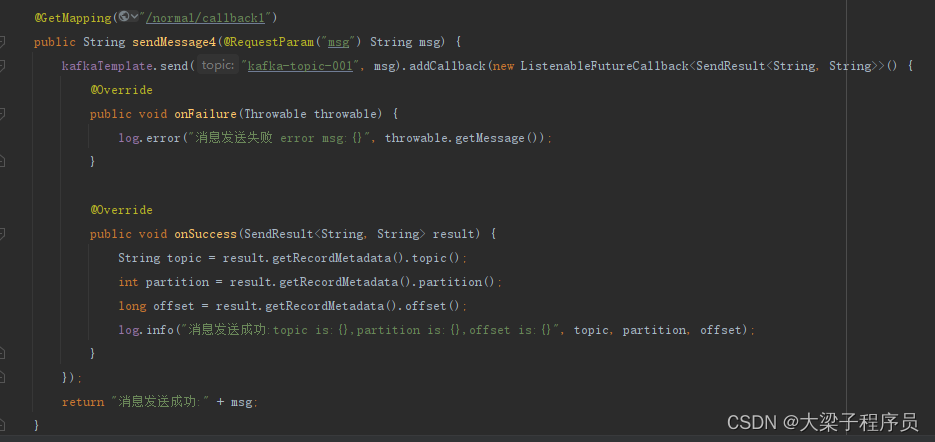
kafkaTemplate提供了一个回调方法addCallback,我们可以在回调方法中监控消息是否发送成功 或 失败时做补偿处理.可以对生产端数据丢失做一些避免措施
生产端
@RestController
@RequestMapping("/kafka/push")
public class KafkaProController {
private static final Logger log = LoggerFactory.getLogger(KafkaProController.class);
@Autowired
@Qualifier(value = "kafkaTemplate")
private KafkaTemplate<String,String> kafkaTemplate;
@Autowired
private KafkaSendResultHandler kafkaSendResultHandler;
@Autowired
@Qualifier(value = "transactionKafkaTemplate")
private KafkaTemplate<String,String> transactionKafkaTemplate;
/* @Value("${spring.kafka.template.default-topic}")
private String topic;*/
/**
* 简单生产者
*/
@GetMapping("/normal/sendTopic")
public String sendMessage1(@RequestParam("msg") String msg) throws ExecutionException, InterruptedException {
Date date = DateTimeUtil.date();
String now = DateTimeUtil.format(date, DatePattern.NORM_DATETIME_MS_PATTERN);
//通过指定key的方式,具有相同key的消息会分发到同一个partition,保证其有序性。
msg="当前消息为【"+msg+"】当前时间为:"+now;
System.out.println("发送者:"+msg);
long timeMillis = System.currentTimeMillis();
ListenableFuture<SendResult<String, String>> send = kafkaTemplate.send("kafka-topic-001", msg);
SendResult<String, String> stringStringSendResult = send.get();
long currentTimeMillis = System.currentTimeMillis();
log.info("消耗时间为:{}",currentTimeMillis-timeMillis);
return "消息发送成功:" + msg;
}
/**
* 简单生产者,消息发送到不同的topic
*/
@GetMapping("/normal/batchSendTopic")
public String sendMessage2(@RequestParam("msg") String msg) {
kafkaTemplate.send("kafka-topic-001", msg);
kafkaTemplate.send("kafka-topic-002", msg);
return "消息发送成功:" + msg;
}
/**
* 简单生产者,消息发送到不同的topic
*/
@GetMapping("/normal/callback")
public String sendMessage3(@RequestParam("msg") String msg) {
kafkaTemplate.send("kafka-topic-001", msg).addCallback(success -> {
String topic = success.getRecordMetadata().topic();
int partition = success.getRecordMetadata().partition();
long offset = success.getRecordMetadata().offset();
ProducerRecord<String, String> producerRecord = success.getProducerRecord();
log.info("producerRecord is:{}", JSON.toJSONString(producerRecord));
log.info("消息发送成功:topic is:{},partition is:{},offset is:{}", topic, partition, offset);
}, failure -> {
log.error("消息发送失败 error msg:{}", failure.getMessage());
});
return "消息发送成功:" + msg;
}
/**
* @Description 异步发送
* @Author zhangguoliang
* @Date 2022/9/16
* @Param [msg]
* @return java.lang.String
*/
@GetMapping("/normal/callback1")
public String sendMessage4(@RequestParam("msg") String msg) {
kafkaTemplate.send("kafka-topic-002", msg).addCallback(new ListenableFutureCallback<SendResult<String, String>>() {
@Override
public void onFailure(Throwable throwable) {
log.error("消息发送失败 error msg:{}", throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, String> result) {
String topic = result.getRecordMetadata().topic();
int partition = result.getRecordMetadata().partition();
long offset = result.getRecordMetadata().offset();
log.info("消息发送成功:topic is:{},partition is:{},offset is:{}", topic, partition, offset);
}
});
return "消息发送成功:" + msg;
}
/*
* 全局回调设置
*/
@GetMapping("/normal/globalCallback")
public String sendMessage5(@RequestParam("msg") String msg) {
//全局回调设置
//kafkaTemplate.setProducerListener(kafkaSendResultHandler);
kafkaTemplate.send("kafka-topic-001", msg);
return "消息发送成功:" + msg;
}
/**
* 无需事务管理器管理事务-发送消息
*/
//比如我要发送订单给积分业务处理积分情况,后续业务是扣除金钱余额,但后续扣除的时发现余额不足,
// 但新增积分消息已经发送出去了,这时候可以采用该方法,要么成功要么都不成功
@GetMapping("/normal/transaction")
public void send(@RequestParam String msg) {
transactionKafkaTemplate.executeInTransaction(kafkaOperations -> {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("kafka-topic-001", msg);
kafkaOperations.send(producerRecord);
throw new RuntimeException("fail");
});
}
@GetMapping("/normal/transaction1")
@Transactional
public void transactionSend(@RequestParam String msg) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("kafka-topic-001", msg);
kafkaTemplate.send(producerRecord);
throw new RuntimeException("fail");
}
/**
* 批量推送数据
*/
@GetMapping("/normal/batchPushMessage")
public void batchPushMessage(@RequestParam("pushQuantity") Integer pushQuantity){
for (int i = 0; i < pushQuantity; i++) {
String msg = "这是第" + (i + 1) + "条数据";
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("kafka-topic-003", msg);
kafkaTemplate.send(producerRecord);
}
}
/**
* 批量发送消息,分配消费者
*/
@GetMapping("/normal/batchPushMessageStrategy")
public void batchPushMessageStrategy(@RequestParam("pushQuantity") Integer pushQuantity) throws InterruptedException {
for (int i = 0; i < pushQuantity; i++) {
String msg = "【topic1】这是第" + (i + 1) + "条数据";
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("topic1", msg);
kafkaTemplate.send(producerRecord);
msg = "【topic2】这是第" + (i + 1) + "条数据";
ProducerRecord<String, String> producerRecord1 = new ProducerRecord<>("topic2", msg);
kafkaTemplate.send(producerRecord1);
}
Thread.sleep(3000);
System.out.println(TopicComponent.map);
}
//==================================================================================================================
@GetMapping("/send1")
public String send1(String msg) {
// ProducerRecord<String, String> producerRecord = new ProducerRecord<>("topic001", "000111", message);
kafkaTemplate.send("topic001",msg).addCallback(
success ->{
String topic = success.getRecordMetadata().topic();
int partition = success.getRecordMetadata().partition();
long offset = success.getRecordMetadata().offset();
System.out.println("send1:{}================{} topic:" + topic + " partition:" + partition + " offset:" + offset);
},
failure ->{
String message1 = failure.getMessage();
System.out.println(message1);
}
);
return "success";
}
@GetMapping("/send2")
public String send2(String msg) {
kafkaTemplate.send("topic002","000222",msg).addCallback(
success ->{
String topic = success.getRecordMetadata().topic();
int partition = success.getRecordMetadata().partition();
long offset = success.getRecordMetadata().offset();
System.out.println("send:{}================{} topic:" + topic + " partition:" + partition + " offset:" + offset);
},
failure ->{
String message1 = failure.getMessage();
System.out.println(message1);
}
);
return "success";
}
/**
* 批量发送数据发到kafka队列里
* @param msgs
*/
@GetMapping("/send3")
public void send3(@RequestParam List<String> msgs) {
msgs.forEach(msg->{
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("radar", msg);
kafkaTemplate.send(producerRecord);
});
}
@GetMapping("/send4")
public void sendData(@RequestParam String msg) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("t0", msg);
kafkaTemplate.send(producerRecord);
}
@GetMapping("/send5")
public void send5(@RequestParam String msg) {
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("t1", msg);
kafkaTemplate.send(producerRecord);
}
@GetMapping("/send6")
public void send6() {
for (int i = 0; i < 10; i++) {
String msg = "这是第" + (i + 1) + "条数据";
ProducerRecord<String, String> producerRecord = new ProducerRecord<>("topic001", msg);
kafkaTemplate.send(producerRecord);
}
}
}
消费端
@Component
public class TopicComponent {
private static final Logger log = LoggerFactory.getLogger(TopicComponent.class);
public static Map<String, Set<String>> map=new HashMap<>();
@Value("${kafka.topic.group:test_topic001_topic002}")
private String topic001002;
/**
* 简单消费
*/
@KafkaListener(id="timingConsumer",groupId = "kafka-topic-001",topics = "kafka-topic-001",containerFactory = "singleFactory")
// @SendTo("kafka-topic-002")
public String getMeessage(ConsumerRecord<String, String> record,Consumer consumer,Acknowledgment acknowledgment) {
int partition = record.partition();
String topic = record.topic();
String msg = record.value();
long offset = record.offset();
System.out.println("消费者[getMeessage]接受消息:topic-->" + topic + ",partition->>" + partition + ",offset->>" + offset + "msg->>" + msg+"发送到kafka-topic-002");
consumer.commitSync();
return "topic2-received msg is:"+msg;
}
/**
* 简单消费
*/
// @KafkaListener(groupId = "subscribeGroup",topics = "kafka-topic-001",containerFactory = "singleFactory")
// @SendTo("kafka-topic-002")
public String getMeessagesSubscribe(ConsumerRecord<String, String> record,Consumer consumer,Acknowledgment acknowledgment) {
int partition = record.partition();
String topic = record.topic();
String msg = record.value();
long offset = record.offset();
System.out.println("消费者[getMeessagesSubscribe]接受消息:topic-->" + topic + ",partition->>" + partition + ",offset->>" + offset + "msg->>" + msg);
// acknowledgment.acknowledge();
consumer.commitSync();
return "received msg is:"+msg;
}
@KafkaListener(groupId = "kafka-topic",topics = {"kafka-topic-002"},containerFactory = "singleFactory")
public void getBatchMeessage(ConsumerRecord<String, String> record,Acknowledgment acknowledgment) {
int partition = record.partition();
String topic = record.topic();
String msg = record.value();
long offset = record.offset();
acknowledgment.acknowledge();
System.out.println("消费者[getBatchMeessage]接受消息:topic-->" + topic + ",partition->>" + partition + ",offset->>" + offset + ",msg->>" + msg);
}
//1.过滤消费
// @KafkaListener(groupId = "kafka-topic",topics = "kafka-topic-003",containerFactory = "filterContainerFactory2",errorHandler = "myConsumerAwareErrorHandler")
//2.并发消费
@KafkaListener(groupId = "kafka-topic",topics = "kafka-topic-003",containerFactory = "batchFactory",errorHandler = "myConsumerAwareErrorHandler")
//3.initialOffset初始消费偏移量,初始偏移量的意思是每次服务重启时,重新从初始偏移量的地方下拉数据再次消费,与提交无关
// @KafkaListener(groupId = "kafka-topic-005",topicPartitions =
// {@TopicPartition(topic = "kafka-topic-005",
// partitionOffsets = {@PartitionOffset(partition = "0",initialOffset = "5"),@PartitionOffset(partition = "1",initialOffset = "5")})},containerFactory = "batchFactory")
/* @KafkaListener(groupId = "kafka-topic-003",topicPartitions =
{@TopicPartition(topic = "kafka-topic-003",partitions = {"0","1","2"})},containerFactory = "batchFactory")*/
public void consurmTopic003(List<ConsumerRecord<String,String>> consumerRecords,Consumer consumer,Acknowledgment acknowledgment){
log.info("consumerRecords size is:{}",consumerRecords.size());
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
log.info("【当前线程thredName is】:{},【offset is】:{},【msg is】:{},【topic is】:{},【patition is】:{}",Thread.currentThread().getName(),
consumerRecord.offset(),consumerRecord.value(),
consumerRecord.topic(),consumerRecord.partition());
}
//手动异步提交
acknowledgment.acknowledge();
}
// @KafkaListener(groupId = "kafka-topic",topics = "kafka-topic-004",containerFactory = "singleFactory")
public void consurmTopic004(String record,Consumer consumer){
System.out.println("我是【kafka-topic-004】->msg:"+record);
//手动异步提交
consumer.commitAsync();
}
//****************************以下是测试消费者分区分配策略展示,分区分配策略分为:RoundRobin(轮询),RangeRobin(Range),StickyAssignor(粘性)********************************
@KafkaListener(groupId = "topic",topics = {"topic1","topic2"},containerFactory = "batchFactory")
public void comsurm01(List<ConsumerRecord<String,String>> consumerRecords,Acknowledgment acknowledgment){
Set<String> hashSet = new HashSet<>();
try {
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
log.info("消费者01【topic is】:{},【partition is】:{},【msg is】:{}", consumerRecord.topic(), consumerRecord.partition(), consumerRecord.value());
hashSet.add(consumerRecord.topic()+"-p"+consumerRecord.partition());
System.out.println("c1:"+"【"+consumerRecord.topic()+"-p"+consumerRecord.partition()+"】");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
map.put("c1",hashSet);
acknowledgment.acknowledge();
}
}
@KafkaListener(groupId = "topic",topics = {"topic1","topic2"},containerFactory = "batchFactory")
public void comsurm02(List<ConsumerRecord<String,String>> consumerRecords,Acknowledgment acknowledgment){
Set<String> hashSet = new HashSet<>();
try {
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
log.info("消费者01【topic is】:{},【partition is】:{},【msg is】:{}", consumerRecord.topic(), consumerRecord.partition(), consumerRecord.value());
hashSet.add(consumerRecord.topic()+"-p"+consumerRecord.partition());
System.out.println("c2:"+"【"+consumerRecord.topic()+"-p"+consumerRecord.partition()+"】");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
map.put("c2",hashSet);
acknowledgment.acknowledge();
}
}
@KafkaListener(groupId = "topic",topics = {"topic1","topic2"},containerFactory = "batchFactory")
public void comsurm03(List<ConsumerRecord<String,String>> consumerRecords,Acknowledgment acknowledgment){
Set<String> hashSet = new HashSet<>();
try {
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
log.info("消费者01【topic is】:{},【partition is】:{},【msg is】:{}", consumerRecord.topic(), consumerRecord.partition(), consumerRecord.value());
hashSet.add(consumerRecord.topic()+"-p"+consumerRecord.partition());
System.out.println("c3:"+"【"+consumerRecord.topic()+"-p"+consumerRecord.partition()+"】");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
map.put("c3",hashSet);
acknowledgment.acknowledge();
}
}
}
消费端全局异常处理
@Component
public class ListenerErrorHandler {
@Bean
public ConsumerAwareListenerErrorHandler myConsumerAwareErrorHandler() {
return new ConsumerAwareListenerErrorHandler() {
@Override
public Object handleError(Message<?> message, ListenerExecutionFailedException exception,
Consumer<?, ?> consumer) {
System.out.println("--- 发生消费异常 ---");
System.out.println(message.getPayload());
System.out.println(exception);
return null;
}
};
}
}
生产端发送成功异常全局处理搭配回调使用
@Component
public class KafkaSendResultHandler implements ProducerListener {
private static final Logger log = LoggerFactory.getLogger(KafkaProController.class);
@Override
public void onSuccess(ProducerRecord producerRecord, RecordMetadata recordMetadata) {
String topic = recordMetadata.topic();
int partition = recordMetadata.partition();
long offset = recordMetadata.offset();
log.info("消息发送成功:topic is:{},partition is:{},offset is:{}", topic, partition, offset);
}
@Override
public void onError(ProducerRecord producerRecord, Exception exception) {
log.error("消息发送失败 error msg:{}", exception.getMessage());
}
}
自定义生产端数据发送分区策略
@Component
public class CustomizePartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
// 获取topic的分区列表
List<PartitionInfo> partitionInfoList = cluster.availablePartitionsForTopic(topic);
int partitionCount = partitionInfoList.size();
Random random = new Random();
int i = random.nextInt(partitionCount);
return i ;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
定时启动消费器
@EnableScheduling
@Component
public class CronTimer {
/**
* @KafkaListener注解所标注的方法并不会在IOC容器中被注册为Bean,
* 而是会被注册在KafkaListenerEndpointRegistry中,
* 而KafkaListenerEndpointRegistry在SpringIOC中已经被注册为Bean
**/
@Autowired
private KafkaListenerEndpointRegistry registry;
@Autowired
private KafkaTemplate<String,String> kafkaTemplateTest;
/**
* 定时启动监听器,用来消费某一时间段的数据
* @param
* @author yh
* @date 2022/5/11
* @return
*/
@Scheduled(cron = "0 51 19 * * ?")
public void startListener() {
System.out.println("启动监听器..." + new Date());
// "timingConsumer"是@KafkaListener注解后面设置的监听器ID,标识这个监听器
if (!registry.getListenerContainer("timingConsumer").isRunning()) {
registry.getListenerContainer("timingConsumer").start();
}
//通过指定key的方式,具有相同key的消息会分发到同一个partition,保证其有序性。
// registry.getListenerContainer("timingConsumer").resume();
}
/**
* 定时停止监听器
* @param
* @author yh
* @date 2022/5/11
* @return
*/
@Scheduled(cron = "0 54 19 * * ?")
public void shutDownListener() {
System.out.println("关闭监听器..." + new Date());
registry.getListenerContainer("timingConsumer").pause();
}
}
版权归原作者 大梁子程序员 所有, 如有侵权,请联系我们删除。