

我们在有关词干的文章中讨论了文本归一化。但是,词干并不是文本归一化中最重要(甚至使用)的任务。我们还进行了其他一些归一化技术的研究,例如Tokenization,Sentencizing和Lemmatization。但是,还有其他一些用于执行此重要预处理步骤的小方法,将在本文中进行讨论。

请记住,没有适用于所有情况的“正确”归一化方法列表。实际上,随着我们对NLP的深入研究,越来越多的人意识到NLP并不像人们想象的那样具有普遍性。尽管有许多有趣的通用工具箱和预制管道,但更精确的系统是针对上下文量身定制的系统。
因此,不应将本文归一化的步骤列表作为硬性规则,而应将其作为对某些文章进行文本归一化的准则。还必须指出的是,在极少数情况下,您可能不想归一化输入-文本中其中更多变化和错误很重要时(例如,考虑测试校正算法)。
了解我们的目标——为什么我们需要文本归一化
让我们从归一化技术的明确定义开始。自然语言作为一种人力资源,倾向于遵循其创造者随机性的内在本质。这意味着,当我们“产生”自然语言时,我们会在其上加上随机状态。计算机不太擅长处理随机性(尽管使用机器学习算法已将随机性的影响降到最低)。
当我们归一化自然语言时,我们会尝试减少其随机性,使其更接近预定义的“标准”。这有助于减少计算机必须处理的不同信息的数量,从而提高效率。
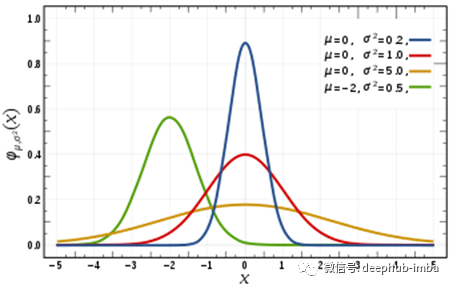
通过归一化,我们希望使“文本分布”更接近“正态”分布。
当我们归一化自然语言资源时,我们尝试减少其中的随机性
在那篇关于词干的文章中,我提到了归一化试图使事物更接近“正态分布”。在某种意义上说是正确的,当我们归一化自然语言输入时,我们希望以“良好”和“可预测”的形状使事物“符合预期”,例如遵循正态分布。
除了数学领域之外,我们还可以讨论**将归一化数据输入到我们的NLP系统中的好处**。
首先,通过减少随机性,我们减少了待处理的输入变量,提高了总体性能并避免了误报(想象一下,如果软件日志行中没有错字,就会触发警告。)。对于系统和信息检索任务来说,这是非常正确的(想象一下,如果Google的搜索引擎仅与您键入的单词完全匹配!)。

从某种意义上讲,可以将归一化与“去除尖锐边缘”方法进行比较。
其次,尤其是在讨论机器学习算法时,如果我们使用的是字词袋或TF-IDF字典等简单的旧结构,则归一化会降低输入的维数;或降低载入数据所需的处理量。
第三,归一化有助于在将输入传递给我们的决策NLP算法之前对其进行处理。在这种情况下,我们确保我们的输入将在处理之前遵循“合同”。
最后,如果正确完成,归一化对于从自然语言输入中可靠地提取统计数据非常重要-就像在其他领域(例如时间序列分析)一样,归一化是NLP数据科学家/分析师/工程师手中重要的一步。
我们归一化的对象是什么?
这是一个重要的问题。在进行文本归一化时,我们应该确切地知道我们要标归一什么以及为什么要归一化。另外,输入数据的特点有助于确定我们将要用来归一化输入的步骤。我们最感兴趣的是两件事:
**句子结构:**它总是以标点符号结尾吗?会出现重复的标点符号吗?我们是否应该删除所有标点符号?此外,可以使用更具体的结构(就像主谓宾结构),但很难实现。
词汇: 这是需要注意的核心内容之一。大多数时候,我们希望我们的词汇量尽可能小。原因是,在NLP中,词汇是我们的主要特征,而当我们在这些词汇中的变化较少时,我们可以更好地实现目标。
实际上,我们可以通过分解成更简单的问题来对这两个方面进行归一化。以下是最常见的方法:
→删除重复的空格和标点符号。
→去除口音(如果您的数据包含来自“外国”语言的变音符号-这有助于减少与编码类型有关的错误)。
→去除大写字母(通常,使用小写单词可获得更好的结果。但是,在某些情况下,大写字母对于提取信息(例如名称和位置)非常重要)。
→删除或替换特殊字符/表情符号(例如:删除主题标签)。
→替换单词缩写(英语中很常见;例如:“我”→“我是”)。
→将单词数字转换为阿拉伯数字(例如:“二十三”→“ 23”)。
→为特殊符号替换(例如:“ $ 50”→“钱”)。
→缩写标准化(例如:“ US”→“美国” /“美国”,“ btw”→“顺便说一下”)。
→标准化日期格式,社会保险号或其他具有标准格式的数据。
→拼写纠正(可以说一个单词可以用无限方式拼写错误,因此拼写纠正可以通过“更正”来减少词汇变化)–如果您要处理推特,即时消息和电子邮件等开放用户输入的数据,这一点非常重要。
→通过词干去除性别/时间/等级差异。
→将稀有单词替换为更常见的同义词。
→停止定型化(比归一化技术更常见的降维技术)。
在本文中,我将只讨论其中一部分的实现。
如何做归一化工作
要选择我们将要使用的归一化步骤,我们需要一项特定的任务。对于本文,我们将假设我们要提取3000个#COVIDIOTS主题标签的情绪集,以了解人们对COVID-19流行的看法。
我获得了这些推文,可以在这里下载。我还使用这个名为best-profanity的漂亮工具来审查不好的文字,如果需要,可以将其添加到规范化管道中。他们也不包含撰写内容的人。
但是,我并没有继续删除每条推文中的姓名或检查任何政治立场等,因为这不是本文的目的,并且可以单独撰写另一篇文章(关于自动审查)。
在这种情况下,我们要执行以下步骤:删除重复的空白和标点符号;缩写替代;拼写更正。另外,我们已经讨论了定形化,下面我们使用它。
在完成代码部分之后,我们将统计分析应用上述归一化步骤的结果。
关于规范化的一件重要事情是函数的顺序很重要。我们可以说归一化是NLP预处理管道中的管道。如果我们不谨慎,则可能删除对以后的步骤很重要的信息(例如在定形之前删除停用词)。
我们甚至可以将这些步骤分为两个连续的组:“标记前步骤”(用于修改句子结构的步骤)和“标记后步骤”(仅用于修改单个标记的步骤),以避免重复标记步骤。但是,为简单起见,我们使用.split()函数。
像生产线一样,归一化步骤的顺序也很重要。
将推文解析为字符串列表之后,就可以开始创建函数了。顺便说一句,我在列表周围使用了一个名为tqdm的漂亮模块,因此一旦应用归一化过程,我们就会获得漂亮的进度条。以下是所需的导入:
fromsymspellpy.symspellpyimportSymSpell, Verbosity
importpkg_resources
importre, string, json
importspacy
fromtqdmimporttqdm
#Or, for jupyter notebooks:
#from tqdm.notebook import tqdm
删除重复的空白和重复的标点符号(和网址):
这一步骤用简单的正则表达式替换完成。有改进的余地,但是可以满足我们的期望(这样,我们就不会有多种尺寸的标度和感叹号标记)。我们删除网址,因为这会减少很多我们拥有的不同令牌的数量(我们首先这样做,因为标点替换可能会阻止它)。
defsimplify_punctuation_and_whitespace(sentence_list):
norm_sents = []
print("Normalizing whitespaces and punctuation")
forsentenceintqdm(sentence_list):
sent = _replace_urls(sentence)
sent = _simplify_punctuation(sentence)
sent = _normalize_whitespace(sent)
norm_sents.append(sent)
returnnorm_sents
def_replace_urls(text):
url_regex = r'(https?:\/\/(?:www\.|(?!www))[a-zA-Z0-9][a-zA-Z0-9-]+[a-zA-Z0-9]\.[^\s]{2,}|www\.[a-zA-Z0-9][a-zA-Z0-9-]+[a-zA-Z0-9]\.[^\s]{2,}|https?:\/\/(?:www\.|(?!www))[a-zA-Z0-9]+\.[^\s]{2,}|www\.[a-zA-Z0-9]+\.[^\s]{2,})'
text = re.sub(url_regex, "<URL>", text)
returntext
def_simplify_punctuation(text):
"""
This function simplifies doubled or more complex punctuation. The exception is '...'.
"""
corrected = str(text)
corrected = re.sub(r'([!?,;])\1+', r'\1', corrected)
corrected = re.sub(r'\.{2,}', r'...', corrected)
returncorrected
def_normalize_whitespace(text):
"""
This function normalizes whitespaces, removing duplicates.
"""
corrected = str(text)
corrected = re.sub(r"//t",r"\t", corrected)
corrected = re.sub(r"( )\1+",r"\1", corrected)
corrected = re.sub(r"(\n)\1+",r"\1", corrected)
corrected = re.sub(r"(\r)\1+",r"\1", corrected)
corrected = re.sub(r"(\t)\1+",r"\1", corrected)
returncorrected.strip(" ")
缩写替换
使用维基百科中的缩略词列表,我们遍历句子并用它们的实际单词替换这些缩略词(这需要在标记化之前发生,因为一个标记被分成两部分)。这有助于以后句子结构的改进。该列表可在此处下载。
defnormalize_contractions(sentence_list):
contraction_list = json.loads(open('english_contractions.json', 'r').read())
norm_sents = []
print("Normalizing contractions")
forsentenceintqdm(sentence_list):
norm_sents.append(_normalize_contractions_text(sentence, contraction_list))
returnnorm_sents
def_normalize_contractions_text(text, contractions):
"""
This function normalizes english contractions.
"""
new_token_list = []
token_list = text.split()
forword_posinrange(len(token_list)):
word = token_list[word_pos]
first_upper = False
ifword[0].isupper():
first_upper = True
ifword.lower() incontractions:
replacement = contractions[word.lower()]
iffirst_upper:
replacement = replacement[0].upper()+replacement[1:]
replacement_tokens = replacement.split()
iflen(replacement_tokens)>1:
new_token_list.append(replacement_tokens[0])
new_token_list.append(replacement_tokens[1])
else:
new_token_list.append(replacement_tokens[0])
else:
new_token_list.append(word)
sentence = " ".join(new_token_list).strip(" ")
returnsentence
拼写矫正
现在,这是一个棘手的问题。它可能会引起一些不需要的更改(大多数可纠正拼写的词典缺少重要的上下文单词,因此他们将它们视为拼写错误)。因此,您必须有意识地使用它。有很多方法可以做到这一点。我选择使用名为symspellpy的模块,该模块的速度非常快(这很重要!),并且可以很好地完成这项工作。做到这一点的另一种方法是,训练一个深度学习模型来基于上下文进行拼写校正,但这完全是另一回事了。
defspell_correction(sentence_list):
max_edit_distance_dictionary= 3
prefix_length = 4
spellchecker = SymSpell(max_edit_distance_dictionary, prefix_length)
dictionary_path = pkg_resources.resource_filename(
"symspellpy", "frequency_dictionary_en_82_765.txt")
bigram_path = pkg_resources.resource_filename(
"symspellpy", "frequency_bigramdictionary_en_243_342.txt")
spellchecker.load_dictionary(dictionary_path, term_index=0, count_index=1)
spellchecker.load_bigram_dictionary(dictionary_path, term_index=0, count_index=2)
norm_sents = []
print("Spell correcting")
forsentenceintqdm(sentence_list):
norm_sents.append(_spell_correction_text(sentence, spellchecker))
returnnorm_sents
def_spell_correction_text(text, spellchecker):
"""
This function does very simple spell correction normalization using pyspellchecker module. It works over a tokenized sentence and only the token representations are changed.
"""
iflen(text) <1:
return""
#Spell checker config
max_edit_distance_lookup = 2
suggestion_verbosity = Verbosity.TOP# TOP, CLOSEST, ALL
#End of Spell checker config
token_list = text.split()
forword_posinrange(len(token_list)):
word = token_list[word_pos]
ifwordisNone:
token_list[word_pos] = ""
continue
ifnot'\n'inwordandwordnotinstring.punctuationandnotis_numeric(word) andnot (word.lower() inspellchecker.words.keys()):
suggestions = spellchecker.lookup(word.lower(), suggestion_verbosity, max_edit_distance_lookup)
#Checks first uppercase to conserve the case.
upperfirst = word[0].isupper()
#Checks for correction suggestions.
iflen(suggestions) >0:
correction = suggestions[0].term
replacement = correction
#We call our _reduce_exaggerations function if no suggestion is found. Maybe there are repeated chars.
else:
replacement = _reduce_exaggerations(word)
#Takes the case back to the word.
ifupperfirst:
replacement = replacement[0].upper()+replacement[1:]
word = replacement
token_list[word_pos] = word
return" ".join(token_list).strip()
def_reduce_exaggerations(text):
"""
Auxiliary function to help with exxagerated words.
Examples:
woooooords -> words
yaaaaaaaaaaaaaaay -> yay
"""
correction = str(text)
#TODO work on complexity reduction.
returnre.sub(r'([\w])\1+', r'\1', correction)
defis_numeric(text):
forcharintext:
ifnot (charin"0123456789"orcharin",%.$"):
returnFalse
returnTrue
合理化
如果您一直关注我的系列文章,那么您已经知道我已经实现了自己的lemmatizer。但是,为了简单起见,我选择在这里使用传统方法。它快速而直接,但是您可以使用任何其他所需的工具。我还决定删除(替换)所有标签。对于情感分析,我们并不是真的需要它们。
deflemmatize(sentence_list):
nlp = spacy.load('en')
new_norm=[]
print("Lemmatizing Sentences")
forsentenceintqdm(sentence_list):
new_norm.append(_lemmatize_text(sentence, nlp).strip())
returnnew_norm
def_lemmatize_text(sentence, nlp):
sent = ""
doc = nlp(sentence)
fortokenindoc:
if'@'intoken.text:
sent+=" @MENTION"
elif'#'intoken.text:
sent+= " #HASHTAG"
else:
sent+=" "+token.lemma_
returnsent
最后,我们将所有步骤加入“pipeline”函数中:
defnormalization_pipeline(sentences):
print("##############################")
print("Starting Normalization Process")
sentences = simplify_punctuation_and_whitespace(sentences)
sentences = normalize_contractions(sentences)
sentences = spell_correction(sentences)
sentences = lemmatize(sentences)
print("Normalization Process Finished")
print("##############################")
returnsentences
在Google Colab Notebook中运行函数
结果
您可能想知道:应用这些任务的结果是什么?我已经运行了一些计数功能并绘制了一些图表来帮助解释,但我必须清楚一件事:数字表示不是表达文本归一化重要性的最佳方法。
相反,当将文本规范化应用于NLP应用程序时,它可以通过提高效率,准确性和其他相关分数来发挥最佳作用。我将指出一些可以从统计数据中清楚看到的好处。
首先,我们可以清楚地看到不同令牌总数的减少。在这种情况下,我们将令牌数量减少了约32%。
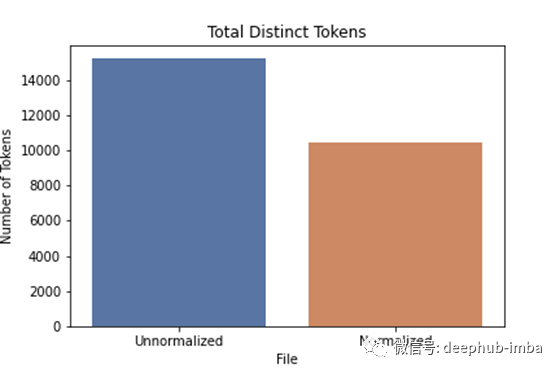
将归一化应用于我们的数据后,我们将令牌数量减少了约32%。
Distinctwordsinunnormalized: 15233–80%ofthetextcorrespondto4053distinctwords.
Distinctwordsinnormalized: 10437–80%ofthetextcorrespondto1251distinctwords.
现在,通用令牌的数量出现了更大的差异。这些令牌包括了所有数据的大约80%。通常,我们通过大约10–20%的令牌范围构成了文本的80%。
通过应用归一化,我们将最常见的令牌数量减少了69%!非常多!这也意味着我们对此数据的任何机器学习技术都将能够更好地推广。
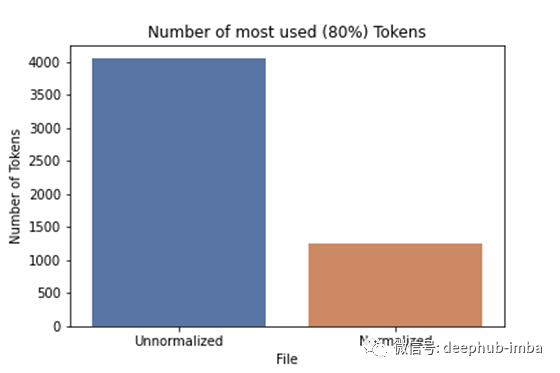
归一化后,最常见的令牌数量减少了69%。
现在,关于文本归一化的一件重要的事是,为了使文本规范化有用,它必须保留默认的自然语言结构。我们可以通过数据本身看到这一点。一个例子是,如果做得好,归一化后的句子将不会变得越来越小。
在下面的直方图中显示了这一点,它表明,尽管归一化后我们的1尺寸句子较少,而2尺寸句子较多,但其余分布遵循未归一化数据的结构(请注意,我们的曲线稍微接近正态分布曲线)。
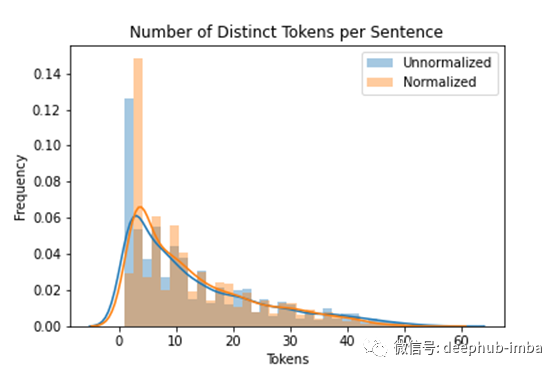
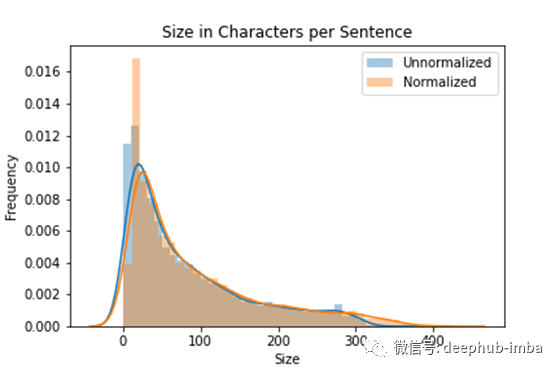
归一化对整体句子结构影响不大。
另一个有助于我们可视化的工具是Boxplot。它显示了我们的数据如何分布,包括均值,四分位数和离群值。总而言之,我们希望我们的中线与未规范化数据的中线相同(或接近)。我们还希望框(大多数数据的分布)保持在相似的位置。如果我们能够增加数据量的大小,这意味着我们在中位数周围的数据比归一化之前要多(这很好)。此外,我们要减少离群值。
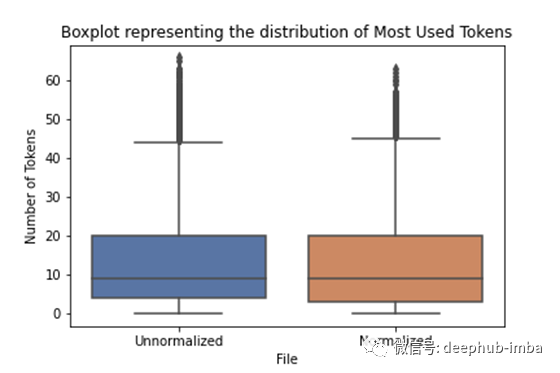
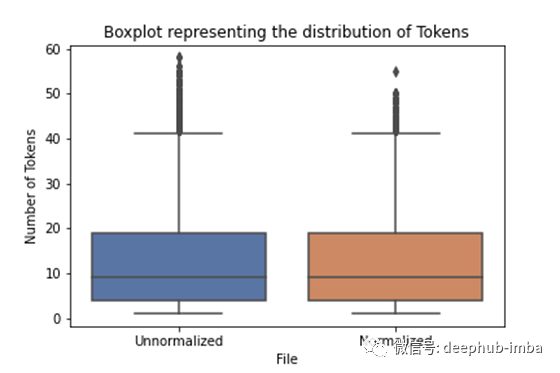
归一化之后,我们能够增加四分位间距(大多数标记所在的位置)。我们还保持相同的中线并减少了异常值。这意味着我们没有破坏我们的文本,但是使它变得不那么复杂)。
结论
我希望在本文中能够解释什么是文本归一化,为什么要这样做以及如何做。
这是几个链接和一个用于进一步研究的文档:
链接:http://mlwiki.org/index.php/Text_Normalization
链接:https://www.aclweb.org/anthology/W18-3902/
作者:Tiago Duque
翻译:孟翔杰
关注 deephub-imba 发送 20200421 即可获取 本文相关资源
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********