
第3章 用户行为日志
3.1 用户行为日志概述
用户行为日志的内容,主要包括用户的各项行为信息以及行为所处的环境信息。收集这些信息的主要目的是优化产品和为各项分析统计指标提供数据支撑。收集这些信息的手段通常为埋点。
目前主流的埋点方式,有代码埋点(前端/后端)、可视化埋点、全埋点等。
代码埋点是通过调用埋点SDK函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对应的 OnClick 函数里面调用SDK提供的数据发送接口,来发送数据。
可视化埋点只需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就可以通过访问分析平台的“圈选”功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集 SDK 按照圈选的配置自动进行用户行为数据的采集和发送。
全埋点是通过在产品中嵌入SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。
3.2 用户行为日志内容
本项目收集和分析的用户行为信息主要有页面浏览记录、动作记录、曝光记录、启动记录和错误记录。
3.2.1 页面浏览记录
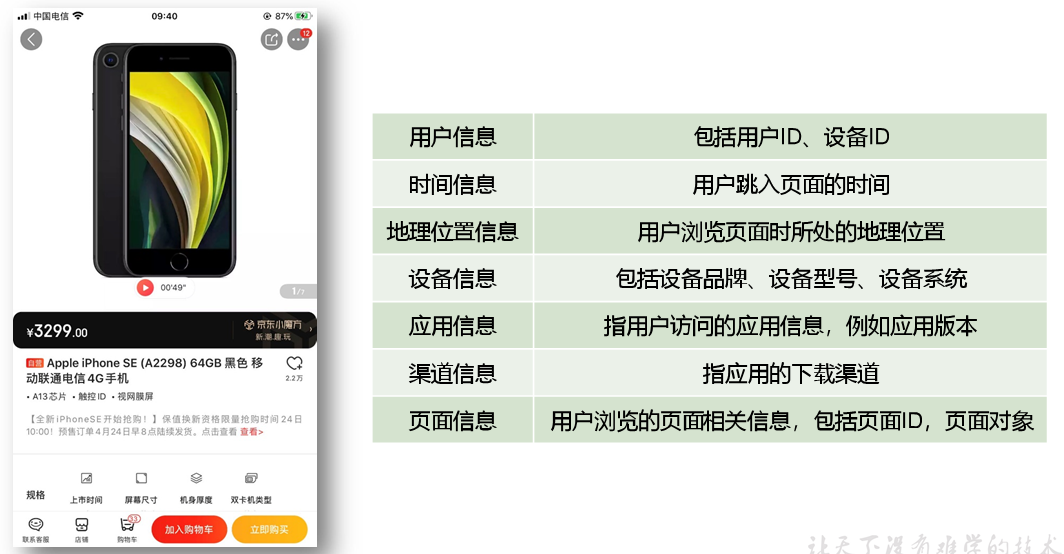
页面浏览记录,记录的是访客对页面的浏览行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息及页面信息等。
我们要收集和分析的数据主要包括页面数据、事件数据、曝光数据、启动数据和错误数据。
3.2.2 动作记录
动作记录,记录的是用户的业务操作行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息及动作目标对象信息等。

3.2.3 曝光记录
曝光记录,记录的是曝光行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息及曝光对象信息等。

3.2.4 启动记录
启动记录,记录的是用户启动应用的行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息、启动类型及开屏广告信息等。

3.2.5 错误记录
启动记录,记录的是用户在使用应用过程中的报错行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息、以及可能与报错相关的页面信息、动作信息、曝光信息和动作信息。
3.3 用户行为日志格式
我们的日志结构大致可分为两类,一是页面日志,二是启动日志。
3.3.1 页面日志
页面日志,以页面浏览为单位,即一个页面浏览记录,生成一条页面埋点日志。一条完整的页面日志包含,一个页面浏览记录,若干个用户在该页面所做的动作记录,若干个该页面的曝光记录,以及一个在该页面发生的报错记录。除上述行为信息,页面日志还包含了这些行为所处的各种环境信息,包括用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息等。
{"common":{-- 环境信息
"ar":"230000",-- 地区编码
"ba":"iPhone",-- 手机品牌
"ch":"Appstore",-- 渠道
"is_new":"1",-- 是否首日使用,首次使用的当日,该字段值为1,过了24:00,该字段置为0。
"md":"iPhone 8",-- 手机型号
"mid":"YXfhjAYH6As2z9Iq",-- 设备id
"os":"iOS 13.2.9",-- 操作系统
"uid":"485",-- 会员id
"vc":"v2.1.134"-- app版本号
},"actions":[{--动作(事件)"action_id":"favor_add",-- 动作id
"item":"3",-- 目标id
"item_type":"sku_id",-- 目标类型
"ts":1585744376605-- 动作时间戳
}],"displays":[{-- 曝光
"displayType":"query",-- 曝光类型
"item":"3",-- 曝光对象id
"item_type":"sku_id",-- 曝光对象类型
"order":1,-- 出现顺序
"pos_id":2-- 曝光位置
},{"displayType":"promotion","item":"6","item_type":"sku_id","order":2,"pos_id":1},{"displayType":"promotion","item":"9","item_type":"sku_id","order":3,"pos_id":3},{"displayType":"recommend","item":"6","item_type":"sku_id","order":4,"pos_id":2},{"displayType":"query ","item":"6","item_type":"sku_id","order":5,"pos_id":1}],"page":{-- 页面信息
"during_time":7648,-- 持续时间毫秒
"item":"3",-- 目标id
"item_type":"sku_id",-- 目标类型
"last_page_id":"login",-- 上页类型
"page_id":"good_detail",-- 页面ID"sourceType":"promotion"-- 来源类型
},"err":{--错误
"error_code":"1234",--错误码
"msg":"***********"--错误信息
},"ts":1585744374423--跳入时间戳
}
3.3.2 启动日志
启动日志以启动为单位,及一次启动行为,生成一条启动日志。一条完整的启动日志包括一个启动记录,一个本次启动时的报错记录,以及启动时所处的环境信息,包括用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息等。
{"common":{"ar":"370000","ba":"Honor","ch":"wandoujia","is_new":"1","md":"Honor 20s","mid":"eQF5boERMJFOujcp","os":"Android 11.0","uid":"76","vc":"v2.1.134"},"start":{"entry":"icon",--icon手机图标 notice 通知 install 安装后启动
"loading_time":18803,--启动加载时间
"open_ad_id":7,--广告页ID"open_ad_ms":3449,-- 广告总共播放时间
"open_ad_skip_ms":1989-- 用户跳过广告时点
},"err":{--错误
"error_code":"1234",--错误码
"msg":"***********"--错误信息
},"ts":1585744304000}
3.4 服务器和JDK准备
3.4.1 服务器准备
安装如下文档配置步骤,分别安装hadoop102、hadoop103、hadoop104三台主机。
参考:
3.4.2 阿里云服务器准备(可选)
参考:
3.4.3 编写集群分发脚本xsync
1)xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析
①rsync命令原始拷贝:
rsync-av /opt/module atguigu@hadoop103:/opt/
②期望脚本:xsync要同步的文件名称
③说明:在/home/atguigu/bin这个目录下存放的脚本,atguigu用户可以在系统任何地方直接执行。
(3)脚本实现
①在用的家目录/home/atguigu下创建bin文件夹
[atguigu@hadoop102~]$ mkdir bin
②在/home/atguigu/bin目录下创建xsync文件,以便全局调用
[atguigu@hadoop102~]$ cd /home/atguigu/bin
[atguigu@hadoop102~]$ vim xsync
在该文件中编写如下代码
#!/bin/bash#1. 判断参数个数if[$#-lt1]thenecho Not Enough Arguement!exit;fi#2. 遍历集群所有机器forhostin hadoop102 hadoop103 hadoop104
doecho====================$host====================#3. 遍历所有目录,挨个发送forfilein$@do#4 判断文件是否存在if[-e$file]then#5. 获取父目录pdir=$(cd-P$(dirname $file);pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh$host"mkdir -p $pdir"rsync-av$pdir/$fname$host:$pdirelseecho$file does not exists!fidonedone
③修改脚本xsync具有执行权限
[atguigu@hadoop102 bin]$ chmod +x xsync
④测试脚本
[atguigu@hadoop102 bin]$ xsync xsync
3.3.4 SSH无密登录配置
说明:这里面只配置了hadoop102、hadoop103到其他主机的无密登录;因为hadoop102未外配置的是NameNode,hadoop103配置的是ResourceManager,都要求对其他节点无密访问。
(1)hadoop102上生成公钥和私钥:
[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(2)将hadoop102公钥拷贝到要免密登录的目标机器上
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
(3)hadoop103上生成公钥和私钥:
[atguigu@hadoop103 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(4)将hadoop103公钥拷贝到要免密登录的目标机器上
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop104
3.3.5 JDK准备
1)卸载现有JDK(3台节点)
[atguigu@hadoop102 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps[atguigu@hadoop103 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps[atguigu@hadoop104 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
(1)rpm -qa:表示查询所有已经安装的软件包
(2)grep -i:表示过滤时不区分大小写
(3)xargs -n1:表示一次获取上次执行结果的一个值
(4)rpm -e --nodeps:表示卸载软件
2)用XShell工具将JDK导入到hadoop102的/opt/software文件夹下面
3)在Linux系统下的opt目录中查看软件包是否导入成功
[atguigu@hadoop102 software]# ls /opt/software/
看到如下结果:
jdk-8u212-linux-x64.tar.gz
4)解压JDK到/opt/module目录下
[atguigu@hadoop102 software]# tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
5)配置JDK环境变量
(1)新建/etc/profile.d/my_env.sh文件
[atguigu@hadoop102 module]# sudo vim /etc/profile.d/my_env.sh
添加如下内容,然后保存(:wq)退出
#JAVA_HOMEexportJAVA_HOME=/opt/module/jdk1.8.0_212
exportPATH=$PATH:$JAVA_HOME/bin
(2)让环境变量生效
[atguigu@hadoop102 software]$ source /etc/profile.d/my_env.sh
6)测试JDK是否安装成功
[atguigu@hadoop102 module]# java -version
如果能看到以下结果、则Java正常安装
java version “1.8.0_212”
7)分发JDK
[atguigu@hadoop102 module]$ xsync /opt/module/jdk1.8.0_212/
8)分发环境变量配置文件
[atguigu@hadoop102 module]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh
9)分别在hadoop103、hadoop104上执行source
[atguigu@hadoop103 module]$ source /etc/profile.d/my_env.sh
[atguigu@hadoop104 module]$ source /etc/profile.d/my_env.sh
3.4.6 环境变量配置说明
Linux的环境变量可在多个文件中配置,如/etc/profile,/etc/profile.d/*.sh,/.bashrc,/.bash_profile等,下面说明上述几个文件之间的关系和区别。
bash的运行模式可分为login shell和non-login shell。
例如,我们通过终端,输入用户名、密码,登录系统之后,得到就是一个login shell。而当我们执行以下命令ssh hadoop103 command,在hadoop103执行command的就是一个non-login shell。
登录Shell和非登录Shell区别
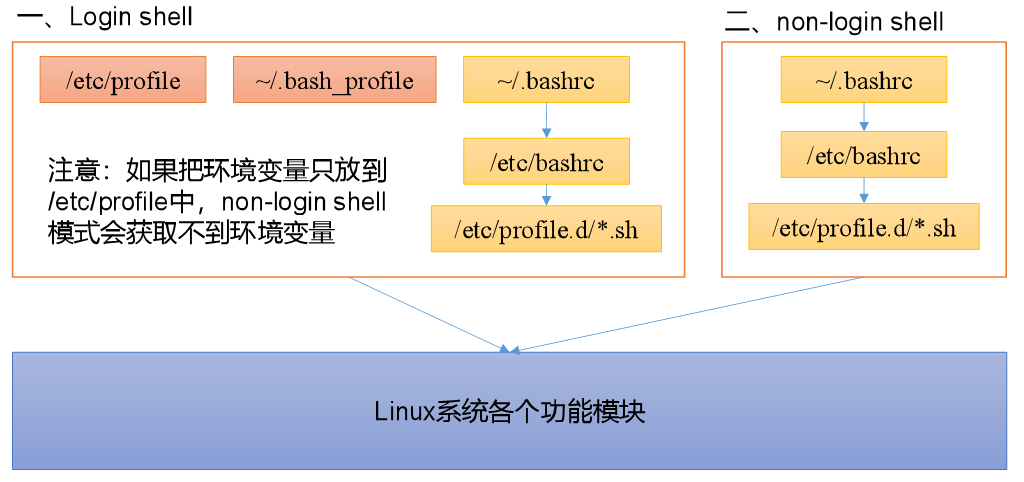
这两种shell的主要区别在于,它们启动时会加载不同的配置文件,login shell启动时会加载/etc/profile,/.bash_profile,/.bashrc。non-login shell启动时会加载~/.bashrc。
而在加载**/.bashrc(实际是/.bashrc中加载的/etc/bashrc)或/etc/profile**时,都会执行如下代码片段,
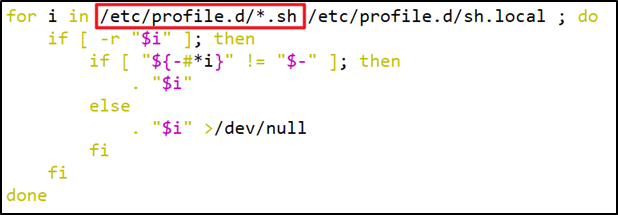
因此不管是login shell还是non-login shell,启动时都会加载/etc/profile.d/*.sh中的环境变量。
3.5 模拟数据
3.5.1 使用说明
1)将application.yml、gmall2020-mock-log-2021-10-10.jar、path.json、logback.xml上传到hadoop102的/opt/module/applog目录下
(1)创建applog路径
[atguigu@hadoop102 module]$ mkdir /opt/module/applog
(2)上传文件application.yml到/opt/module/applog目录
2)配置文件
(1)application.yml文件
可以根据需求生成对应日期的用户行为日志。
[atguigu@hadoop102 applog]$ vim application.yml
修改如下内容
# 外部配置打开# 外部配置打开
logging.config: "./logback.xml"#业务日期 注意:并不是Linux系统生成日志的日期,而是生成数据中的时间
mock.date: "2020-06-14"#模拟数据发送模式#mock.type: "http"#mock.type: "kafka"
mock.type: "log"#http模式下,发送的地址
mock.url: "http://hadoop102/applog"#kafka模式下,发送的地址
mock:
kafka-server: "hadoop102:9092,hadoop103:9092,hadoop104:9092"
kafka-topic: "ODS_BASE_LOG"#启动次数
mock.startup.count: 200#设备最大值
mock.max.mid: 500000#会员最大值
mock.max.uid: 100#商品最大值
mock.max.sku-id: 35#页面平均访问时间
mock.page.during-time-ms: 20000#错误概率 百分比
mock.error.rate: 3#每条日志发送延迟 ms
mock.log.sleep: 10#商品详情来源 用户查询,商品推广,智能推荐, 促销活动
mock.detail.source-type-rate: "40:25:15:20"#领取购物券概率
mock.if_get_coupon_rate: 75#购物券最大id
mock.max.coupon-id: 3#搜索关键词
mock.search.keyword: "图书,小米,iphone11,电视,口红,ps5,苹果手机,小米盒子"
(2)path.json,该文件用来配置访问路径
根据需求,可以灵活配置用户点击路径。
[{"path":["home","good_list","good_detail","cart","trade","payment"],"rate":20},{"path":["home","search","good_list","good_detail","login","good_detail","cart","trade","payment"],"rate":40},{"path":["home","mine","orders_unpaid","trade","payment"],"rate":10},{"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","trade","payment"],"rate":5},{"path":["home","mine","orders_unpaid","good_detail","good_spec","comment","home"],"rate":5},{"path":["home","good_detail"],"rate":10},{"path":["home"],"rate":10}]
(3)logback配置文件
可配置日志生成路径,修改内容如下
<?xml version="1.0" encoding="UTF-8"?><configuration><propertyname="LOG_HOME"value="/opt/module/applog/log"/><appendername="console"class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>%msg%n</pattern></encoder></appender><appendername="rollingFile"class="ch.qos.logback.core.rolling.RollingFileAppender"><rollingPolicyclass="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern></rollingPolicy><encoder><pattern>%msg%n</pattern></encoder></appender><!-- 将某一个包下日志单独打印日志 --><loggername="com.atgugu.gmall2020.mock.log.util.LogUtil"level="INFO"additivity="false"><appender-refref="rollingFile"/><appender-refref="console"/></logger><rootlevel="error"><appender-refref="console"/></root></configuration>
3)生成日志
(1)进入到/opt/module/applog路径,执行以下命令
[atguigu@hadoop102 applog]$ java-jar gmall2020-mock-log-2021-01-22.jar
(2)在/opt/module/applog/log目录下查看生成日志
[atguigu@hadoop102 log]$ ll
3.5.2 集群日志生成脚本
在hadoop102的/home/atguigu目录下创建bin目录,这样脚本可以在服务器的任何目录执行。
[atguigu@hadoop102 ~]$ echo$PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/atguigu/.local/bin:/home/atguigu/bin
(1)在/home/atguigu/bin目录下创建脚本lg.sh
[atguigu@hadoop102 bin]$ vim[lg.sh](http://lg.sh/)
(2)在脚本中编写如下内容
#!/bin/bashforiin hadoop102 hadoop103;doecho"========== $i =========="ssh$i"cd /opt/module/applog/; java -jar gmall2021-mock-log-2021-10-10.jar >/dev/null 2>&1 &"done
注:
①
/opt/module/applog/
为jar包及配置文件所在路径
②
/dev/null
代表Linux的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”。
- 标准输入0:从键盘获得输入
/proc/self/fd/0 - 标准输出1:输出到屏幕(即控制台)
/proc/self/fd/1 - 错误输出2:输出到屏幕(即控制台)
/proc/self/fd/2
(3)修改脚本执行权限
[atguigu@hadoop102 bin]$ chmod u+x lg.sh
(4)将jar包及配置文件上传至hadoop103的/opt/module/applog/路径
(5)启动脚本
[atguigu@hadoop102 module]$ lg.sh
(6)分别在hadoop102、hadoop103的
/opt/module/applog/log
目录上查看生成的数据
[atguigu@hadoop102 logs]$ ls
app.2020-06-14.log
[atguigu@hadoop103 logs]$ ls
app.2020-06-14.log
版权归原作者 yiluohan0307 所有, 如有侵权,请联系我们删除。