
文章目录
什么是Hive
Hive是建立在Hadoop上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载,可以简称为ETL。
Hive 定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户直接查询Hadoop中的数据,同时,这个语言也允许熟悉MapReduce的开发者开发自定义的mapreduce任务来处理内建的SQL函数无法完成的复杂的分析任务。
Hive中包含的有SQL解析引擎,它会将SQL语句转译成M/R Job,然后在Hadoop中执行。
通过这里的分析我们可以了解到Hive可以通过sql查询Hadoop中的数据,并且sql底层也会转化成
mapreduce任务,所以hive是基于hadoop的。
Hive的数据存储
Hive的数据存储基于Hadoop的 HDFS
Hive没有专门的数据存储格式
Hive默认可以直接加载文本文件(TextFile),还支持SequenceFile、RCFile等文件格式
针对普通文本数据,我们在创建表时,只需要指定数据的列分隔符与行分隔符,Hive即可解析里面的数据
Hive的系统架构
如下图:下面表示是Hadoop集群,上面是Hive,从这也可以看出来Hive是基于Hadoop的。
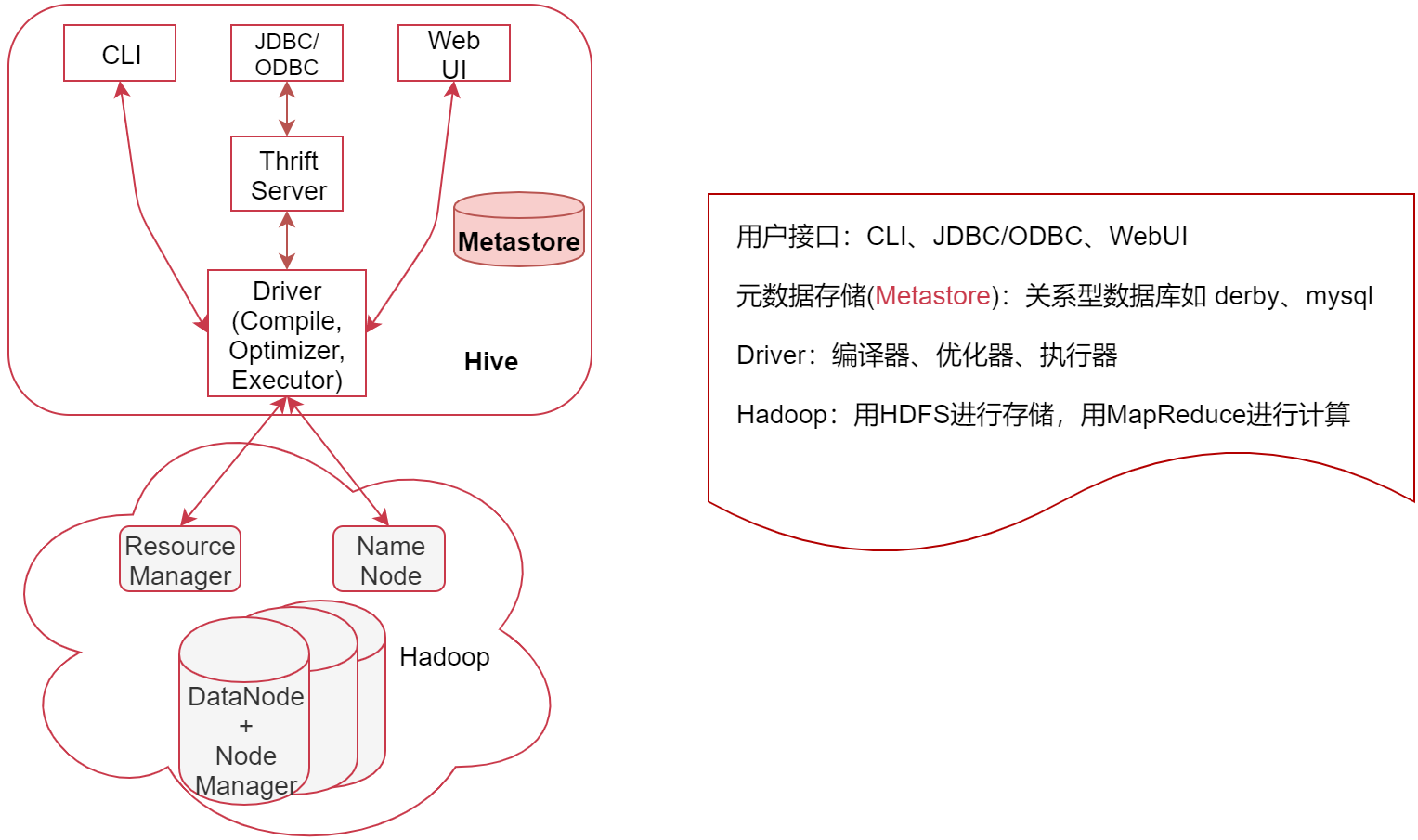
看右边的几个概念的解释
- 用户接口,包括 CLI、JDBC/ODBC、WebGUI CLI,即Shell命令行,表示我们可以通过shell命令行操作Hive JDBC/ODBC 是 Hive 的Java操作方式,与使用传统数据库JDBC的方式类似
- 元数据存储(Metastore),注意:这里的存储是名词,Metastore表示是一个存储系统 Hive中的元数据包括表的相关信息,Hive会将这些元数据存储在Metastore中,目前Metastore只支持 mysql、derby。
- Driver:包含:编译器、优化器、执行器 编译器、优化器、执行器可以完成 Hive的 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划最终存储在 HDFS 中,并在随后由 MapReduce 调用执行
- Hadoop:Hive会使用 HDFS 进行存储,利用 MapReduce 进行计算Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(特例 select * from table 不会生成 MapRedcue 任务,如果在SQL语句后面再增加where过滤条件就会生成MapReduce任务了。)
在这有一点需要注意的,就是从Hive2开始,其实官方就不建议默认使用MapReduce引擎了,而是建议使用Tez引擎或者是Spark引擎,不过目前一直到最新的3.x版本中mapreduce还是默认的执行引擎
其实大数据计算引擎是有几个发展阶段的,首先是第一代大数据计算引擎:MapReduce
接着是第二代大数据计算引擎:Tez,Tez的存在感比较低,它是源于MapReduce,主要和Hive结合在一起使用,它的核心思想是将Map和Reduce两个操作进一步拆分,这些分解后的元操作可以灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可以形成一个大的作业,这样可以提高计算效率,我们在实际工作中Hive使用的就是 Tez引擎,替换Hive的执行引擎也很简单,只需要把Tez安装好(Tez也是支持在YARN上执行的),然后到Hive中配置一下就可以了,不管使用什么引擎,不会对我们使用hive造成什么影响,也就说对上层的使用没有影响
接着是第三代大数据计算引擎:Spark,Spark在当时属于一个划时代的产品,改变了之前基于磁盘的计算思路,而是采用内存计算,就是说Spark把数据读取过来以后,中间的计算结果是不会进磁盘的,一直到出来最终结果,才会写磁盘,这样就大大提高了计算效率,而MapReduce的中间结果是会写磁盘的,所以效率没有Spark高。Spark的执行效率号称比MapReduce 快100倍,当然这需要在一定数据规模下才会差这么多,如果我们就计算几十兆或者几百兆的文件,你去对比发现其实也不会差多少,后面我们也会学到Spark这个基于内存的大数据计算引擎
注意:spark也是支持在YARN上执行的其实目前还有第四代大数据计算引擎,:Flink,Flink是一个可以支持纯实时数据计算的计算引擎,在实时计算领域要优于Saprk,Flink和Spark其实是有很多相似之处,在某些方面他们两个属于互相参考,互相借鉴,互相成长,Flink后面我们也会学到,等后面我们讲到这个计算引擎的时候再详细分析。注意:Flink也是支持在YARN上执行的。所以发现没有,MapReduce、Tez、Spark、Flink这些计算引擎都是支持在yarn上执行的,所以说Hdoop2中对架构的拆分是非常明智的。
解释完这些名词之后其实我们就对这个架构有了一个基本理解,
再看来这个图用户通过接口传递Hive SQL,然后经过Driver对SQL进行分析、编译,生成查询计划,查询计划会存储在HDFS中,然后再通过MapReduce进行计算出结果,这就是整个大的流程。
其实在这里我们可以发现,Hive这个哥们是既不存储数据,也不计算数据,这些活都给了Hadoop来干,Hive底层最核心的东西其实就是Driver这一块,将SQL语句解析为最终的查询计划。
Metastore
接着来看一下Hive中的元数据存储,Metastore
Metastore是Hive元数据的集中存放地。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在的hdfs目录等。Metastore默认使用内嵌的derby数据库。Derby数据库的缺点:在同一个目录下一次只能打开一个会话。使用derby存储方式时,Hive会在当前目录生成一个derby.log文件和一个metastore_db目录,metastore_db里面会存储具体的元数据信息,没有办法使用之前的元数据信息了。推荐使用MySQL作为外置存储引擎,可以支持多用户同时访问以及元数据共享。
Hive VS Mysql
为了加深对Hive的理解,下面我们拿Hive和我们经常使用的Mysql做一个对比
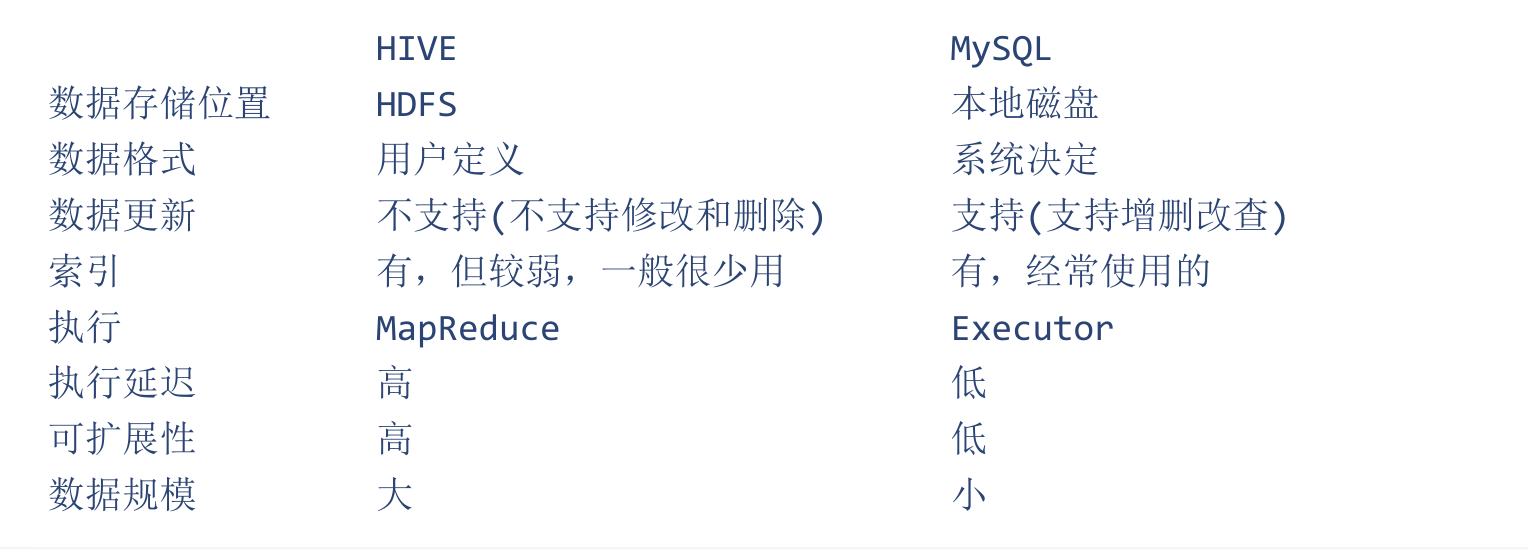
数据库 VS 数据仓库
Hive是一个数据仓库,咱们平时经常使用的mysql属于数据库,那数据库和数据仓库到底有什么区别呢?下面我们来分析一下
- 数据库:传统的关系型数据库主要应用在基本的事务处理,例如银行交易之类的场景 数据库支持增删改查这些常见的操作。
- 数据仓库:主要做一些复杂的分析操作,侧重决策支持,相对数据库而言,数据仓库分析的数据规模要大得多。但是数据仓库只支持查询操作,不支持修改和删除 这些都是明面上的一些区别, 其实数据库与数据仓库的本质区别就是 OLTP与OLAP 的区别
OLTP VS OLAP
那这里的OLTO和OLAP又是什么意思呢?
- OLTP(On-Line Transaction Processing):操作型处理,称为联机事务处理,也可以称为面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性等问题
- OLAP(On-Line Analytical Processing):分析型处理,称为联机分析处理,一般针对某些主题历史数据进行分析,支持管理决策。
其实从字面上来对比,OLTP 和 OLAP 只有一个单词不一样
OLTP侧重于事务,OLAP侧重于分析
所以数据库和数据仓库的特性是不一样的,不过我们平时在使用的时候,可以把Hive作为一个数据库来操作,但是你要知道他们两个是不一样的。数据仓库的概念是比数据库要大的
Hive安装部署
首先要下载Hive的安装包,进入Hive的官网,找到download下载链接
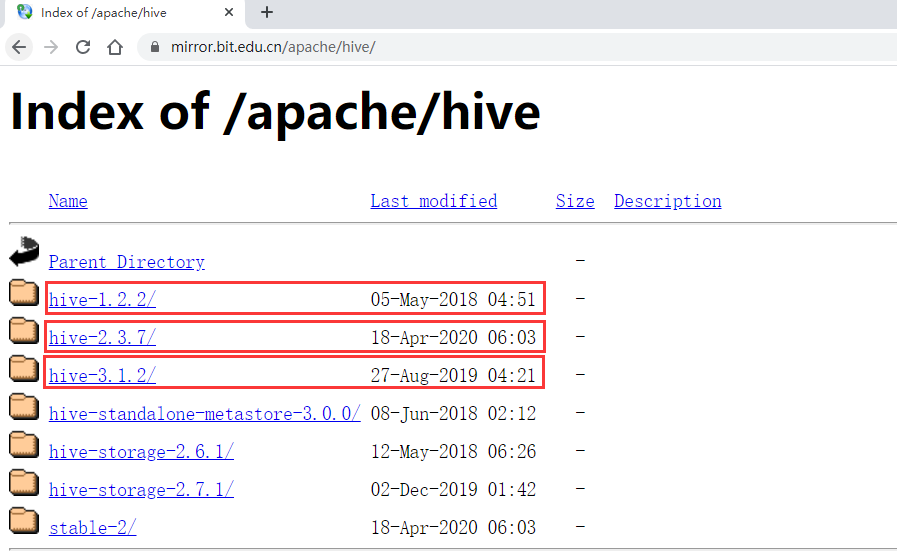
发现目前hive主要有三大版本,Hive1.x、Hive2.x、Hive3.x
Hive1.x已经2年没有更新了,所以这个版本后续基本不会再维护了,不过这个版本已经迭代了很多年了,也是比较稳定的
Hive2.x最近一直在更新
Hive3.x上次是19年8月份更新的,也算是一直在维护
那我们到底选择哪个版本呢?注意了,在选择Hive版本的时候我们需要注意已有的Hadoop集群的版本。因为Hive会依赖于Hadoop,所以版本需要兼容才可以。
具体Hive和Hadoop的版本对应关系可以在download页面下的news列表里面看到。
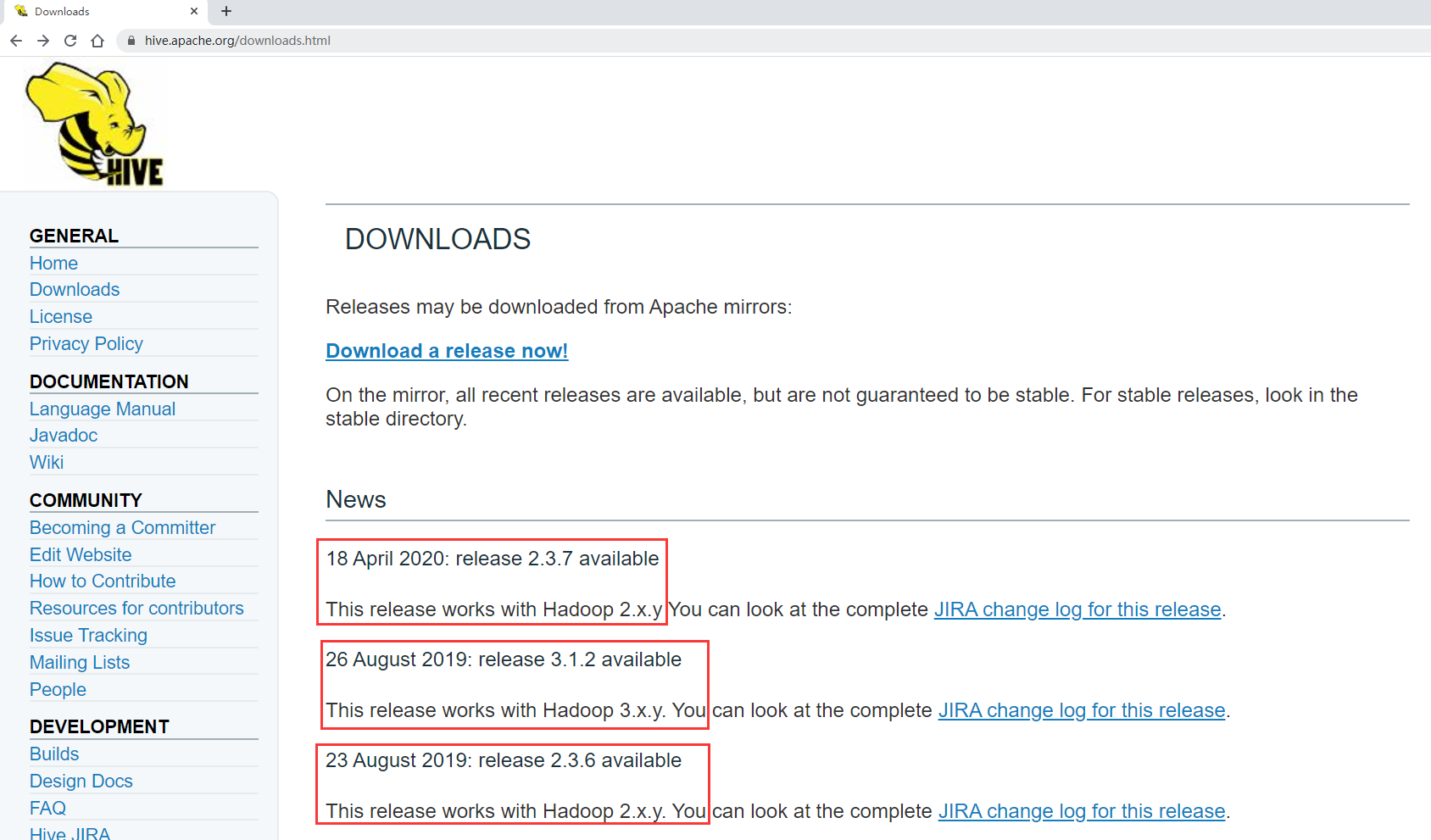
按照这里面说的hive2.x的需要在hadoop2.x版本中运行,hive3.x的需要在hadoop3.x版本中运行。所以在这里我们最好是使用Hive3.x的版本
那我们就下载hive-3.1.2这个版本,如果想要下载其它历史版本的话这里面还找不到,不过可以使用
apache的一个通用archive地址
下载链接
在这里面就可以找到hive的所有历史版本了
下面开始安装Hive
Hive相当于Hadoop的客户端工具,安装时不一定非要放在集群的节点中,可以放在任意一个集群客户端节点上都可以
1:接着把下载好的hive安装包上传到bigdata04机器的/data/soft目录中,并且解压
[root@bigdata04 soft]# ll
-rw-r--r--. 1 root root 278813748 May 523:08 apache-hive-3.1.2-bin.tar.gz
[root@bigdata04 soft]# tar -zxvf apache-hive-3.1.2-bin.tar.gz
2:接着需要修改配置文件,进入hive的conf目录中,先对这两个模板文件重命名
[root@bigdata04 soft]# cd apache-hive-3.1.2-bin/conf/[root@bigdata04 conf]# mv hive-env.sh.template hive-env.sh[root@bigdata04 conf]# mv hive-default.xml.template hive-site.xml
3:然后再修改这两个文件的内容
注意:在 hive-env.sh 文件的末尾直接增加下面三行内容,【根据实际的路径配置】
[root@bigdata04 conf]# vi hive-env.sh.....
exportJAVA_HOME=/data/soft/jdk1.8
exportHIVE_HOME=/data/soft/apache-hive-3.1.2-bin
exportHADOOP_HOME=/data/soft/hadoop-3.2.0
注意:在hive-site.xml文件中根据下面property中的name属性的值修改对应value的值,这些属性默认里面都是有的,所以都是修改对应的value的值即可
由于这里面需要指定Metastore的地址,Metastore我们使用Mysql,所以需要大家提前安装好Mysql,我这里使用的是Mysql8.0.16版本,Mysql安装包会提供给大家,建议大家直接在自己的windows机器中安装Mysql即可,当然了,你在Linux中安装也可以。
我这里Mysql的用户名是root、密码是admin,在下面的配置中会使用到这些信息,大家可以根据自己实际的用户名和密码修改这里面的value的值
[root@bigdata04 conf]# vi hive-site.xml<property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://192.168.182.1:3306/hive?serverTimezone=Asia/Shanghai<</property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>admin</value></property><property><name>hive.querylog.location</name><value>/data/hive_repo/querylog</value></property><property><name>hive.exec.local.scratchdir</name><value>/data/hive_repo/scratchdir</value></property><property><name>hive.downloaded.resources.dir</name><value>/data/hive_repo/resources</value></property>
注意mysql驱动包的版本,要和我们安装的版本保持一致:mysql-connector-java-8.0.16.jar
[root@bigdata04 lib]# ll........
-rw-r--r--. 1 root root 2293144 Mar 202019 mysql-connector-java-8.0.16.jar
5:修改bigdata01中的core-site.xml,然后同步到集群中的另外两个节点上
如果不增加这个配置,使用beeline连接hive的时候会报错
[root@bigdata01 hadoop]# vi core-site.xml<property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>[root@bigdata01 hadoop]# scp -rq etc/hadoop/core-site.xml bigdata02:/data/soft[root@bigdata01 hadoop]# scp -rq etc/hadoop/core-site.xml bigdata03:/data/soft
注意:bigdata04这个客户端节点上不需要修改这个配置就可以了。
6:最后建议修改一下bigdata04的hosts文件,否则这个节点上无法识别集群中节点的主机名,使用起来不方便,顺便也修改一下bigdata01、bigdata02、bigdata03上的hosts,让这几台机器互相认识一下
[root@bigdata01 ~]# vi /etc/hosts192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03
192.168.182.103 bigdata04
[root@bigdata02 ~]# vi /etc/hosts192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03
192.168.182.103 bigdata04
[root@bigdata03 ~]# vi /etc/hosts192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03
192.168.182.103 bigdata04
[root@bigdata04 ~]# vi /etc/hosts192.168.182.100 bigdata01
192.168.182.102 bigdata03
192.168.182.103 bigdata04
7:初始化Hive的Metastore
[root@bigdata04 apache-hive-3.1.2-bin]# bin/schematool -dbType mysql -initSchema
Exception in thread "main" java.lang.RuntimeException: com.ctc.wstx.exc.WstxP
但是执行之后发现报错了,提示hive-site.xml文件中的第3215行内容有问题
其实这个是原始配置文件本身就有的问题,最直接的就是把这一行直接删掉,删除之后的效果如下:其实就是把hive.txn.xlock.iow对应的description标签内容删掉,这样就可以了
<property><name>hive.txn.xlock.iow</name><value>true</value><description></description></property>
修改后再执行初始化命令,初始化Metastore,这个过程需要等一会
初始化成功以后,查看本地Mysql数据库,发现会自动创建hive数据库和一堆表,看到这些就说明Metastore初始化成功了
这样Hive就安装好了,注意了,目前针对Hive不需要启动任何进程,接下来我们就可以开始使用了。
Hive的使用方式
操作Hive可以在Shell命令行下操作,或者是使用JDBC代码的方式操作,下面先来看一下在命令行中操作的方式。
命令行方式
针对命令行这种方式,其实还有两种使用
第一个是使用bin目录下的hive命令,这个是从hive一开始就支持的使用方式
后来又出现一个beeline命令,它是通过HiveServer2服务连接hive,它是一个轻量级的客户端工具,所以后来官方开始推荐使用这个。具体使用哪个我觉得属于个人的一个习惯问题,特别是一些做了很多年大数据开发的人,已经习惯了使用hive命令,如果让我使用beeline会感觉有点别扭。针对我们写的hive sql通过哪一种客户端去执行结果都是一样的,没有任何区别,所以在这里我们使用哪个就无所谓了。
1:先看第一种,这种直接就可以连进去
[root@bigdata04 apache-hive-3.1.2-bin]# bin/hive
Hive-on-MR is deprecated in Hive 2 and may not be available in the future ver
Hive Session ID = 32d36bcb-21b8-488f-8c13-85efd319395a
hive>
这里有一行信息提示,从Hive2开始Hive-on-MR就过时了,并且在以后的版本中可能就不维护了,建议使用其它的计算引擎,例如:spark或者tez
如果你确实想使用MapReduce引擎,那建议你使用Hive1.x的版本。
下面以hive开头的内容就是说明我们进入了Hive的命令行中,在这里就可以写Hive的SQL了。 我们先查看一下目前有哪些表,后面的ok表示执行成功,现在默认是空的
hive> show tables;
OK
Time taken: 0.18 seconds
创建一个表
hive> create table t1(id int,name string);
OK
Time taken: 1.064 seconds
向表里面添加数据,注意,此时就产生了MapReduce任务
hive> insert into t1(id,name) values(1,"zs");
Query ID = root_20200506162317_02b2802a-5640-4656-88e6-1e4eaa811017
Total jobs=3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
sethive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
sethive.exec.reducers.max=<number>
In order to set a constant number of reducers:
setmapreduce.job.reduces=<number>
Starting Job = job_1588737504319_0001, Tracking URL = http://bigdata01:8088/p
Kill Command = /data/soft/hadoop-3.2.0/bin/mapred job -kill job_158873750431
Hadoop job information for Stage-1: number of mappers: 1; number of reducers:
2020-05-06 16:23:36,954 Stage-1 map =0%, reduce =0%
2020-05-06 16:23:47,357 Stage-1 map =100%, reduce =0%, Cumulative CPU 3.112020-05-06 16:23:56,917 Stage-1 map =100%, reduce =100%, Cumulative CPU 5.
MapReduce Total cumulative CPU time: 5 seconds 160 msec
Ended Job = job_1588737504319_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://bigdata01:9000/user/hive/warehouse/t1/.hive-st
Loading data to table default.t1
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.16 sec HDFS Read: 1520
Total MapReduce CPU Time Spent: 5 seconds 160 msec
OK
Time taken: 41.534 seconds
查询数据,为什么这时没有产生mapreduce任务呢?因为这个计算太简单了,不需要经过mapreduce任务就可以获取到结果,直接读取表对应的数据文件就可以了。
可以输入quit退出hive的命令行,或者直接按ctrl+c也可以退出
2:接着看一下第二种方式
[root@bigdata04 apache-hive-3.1.2-bin]# bin/hiveserver2
which: no hbase in(.:/data/soft/jdk1.8/bin:/data/soft/hadoop-3.2.0/bin:/usr/
2020-05-06 16:43:11: Starting HiveServer2
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in[jar:file:/data/soft/apache-hive-3.1.2-bin/lib/log4j-
SLF4J: Found binding in[jar:file:/data/soft/hadoop-3.2.0/share/hadoop/common
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanati
SLF4J: Actual binding is of type[org.apache.logging.slf4j.Log4jLoggerFactory
Hive Session ID = 008af6a0-4f7a-47f0-b45a-4445ff9fa7a7
Hive Session ID = 670a0c62-7744-4949-a25f-02060d950f90
Hive Session ID = 7aa43b1a-eafb-4848-9d29-4fe3eee0cbb7
Hive Session ID = a5c20828-7f39-4ed6-ba5e-2013b5250fe3
注意了,启动hiveserver2服务之后,最下面会输出几行Hive Session ID的信息,一定要等到输出4行以后再使用beeline去连接,否则会提示连接拒绝
hiveserver2默认会监听本机的10000端口,所以命令是这样的
bin/beeline -u jdbc:hive2://localhost:10000
当hiveserver2服务没有真正启动成功之前连接会提示这样的信息
[root@bigdata04 apache-hive-3.1.2-bin]# bin/beeline -u jdbc:hive2://localhost
Connecting to jdbc:hive2://localhost:10000
20/05/06 16:44:21 [main]: WARN jdbc.HiveConnection: Failed to connect to loca
Could not open connection to the HS2 server. Please check the server URI and
Error: Could not open client transport with JDBC Uri: jdbc:hive2://localhost:
Beeline version 3.1.2 by Apache Hive
等待hiveserver2服务真正启动之后再连接,此时就可以连接进去了
[root@bigdata04 apache-hive-3.1.2-bin]# bin/beeline -u jdbc:hive2://localhost
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in[jar:file:/data/soft/apache-hive-3.1.2-bin/lib/log4j-
SLF4J: Found binding in[jar:file:/data/soft/hadoop-3.2.0/share/hadoop/common
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanati
SLF4J: Actual binding is of type[org.apache.logging.slf4j.Log4jLoggerFactory
Connecting to jdbc:hive2://localhost:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://localhost:10000>
添加数据
0: jdbc:hive2://localhost:10000> insert into t1(id,name) values(1,"zs");
发现添加数据报错,提示匿名用户对/tmp/hadoop-yarn没有写权限
解决方法有两个
- 给hdfs中的/tmp/hadoop-yarn设置777权限,让匿名用户具备权限 可以直接给tmp及下面的所有目录设置777权限 hdfs dfs -chmod -R 777 /tmp
- 在启动beeline的时候指定一个对这个目录有操作权限的用户 bin/beeline -u jdbc:hive2://localhost:10000 -n root
此时使用bin/hive命令行查看也是可以的,这两种方式维护的是同一份Metastore
hive>select * from t1;
OK
1 zs
Time taken: 2.438 seconds, Fetched: 1 row(s)
注意:在beeline后面指定hiveserver2的地址的时候,可以指定当前机器的内网ip也是可以的。
退出beeline客户端,按 ctrl+c 即可。
后面我们使用的时候我还是使用hive命令,已经习惯用这个了,还有一个就是大家如果也用这个的话,别人是不是感觉你也是老司机了,但是你要知道官方目前是推荐使用beeline命令的。
在工作中我们如果遇到了每天都需要执行的命令,那我肯定想要把具体的执行sql写到脚本中去执行,但是现在这种用法每次都需要开启一个会话,好像还没办法把命令写到脚本中。
注意了,hive后面可以使用 -e 命令,这样这条hive命令就可以放到脚本中定时调度执行了。 因为这样每次hive都会开启一个新的会话,执行完毕以后再关闭这个会话。
[root@bigdata04 apache-hive-3.1.2-bin]# bin/hive -e "select * from t1"
Hive Session ID = efadf29a-4ed7-4aba-84c8-f48881f0dbfd
Logging initialized using configuration in jar:file:/data/soft/apache-hive-3.
Hive Session ID = 65b9718b-4030-4c0f-a557-43ff473d9396
OK
1 zs
Time taken: 3.263 seconds, Fetched: 1 row(s)[root@bigdata04 apache-hive-3.1.2-bin]#
JDBC方式
JDBC这种方式也需要连接hiveserver2服务,前面我们已经启动了hiveserver2服务,在这里直接使用就可以了
创建maven项目 db_hive
在pom中添加hive-jdbc的依赖
<!-- hive-jdbc驱动 --><dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><version>3.1.2</version></dependency>
开发代码,创建包名: com.imooc.hive
创建类名: HiveJdbcDemo
代码如下:
packagecom.imooc.hive;importjava.sql.Connection;importjava.sql.DriverManager;importjava.sql.ResultSet;importjava.sql.Statement;/**
* JDBC代码操作 Hive
* 注意:需要先启动hiveserver2服务
*/publicclassHiveJdbcDemo{publicstaticvoidmain(String[] args)throwsException{//指定hiveserver2的连接String jdbcUrl ="jdbc:hive2://192.168.182.103:10000";//获取jdbc连接,这里的user使用root,就是linux中的用户名,password随便指定即Connection conn =DriverManager.getConnection(jdbcUrl,"root","any")//获取StatementStatement stmt = conn.createStatement();//指定查询的sqlString sql ="select * from t1";//执行sqlResultSet res = stmt.executeQuery(sql);//循环读取结果while(res.next()){System.out.println(res.getInt("id")+"\t"+res.getString("name"));}}}
执行代码,可以看到查询出来的结果,但是会打印出来一堆红色的警告信息
SLF4J:Class path contains multiple SLF4J bindings.SLF4J:Found binding in [jar:file:/D:/.m2/org/apache/logging/log4j/log4j-slf4
SLF4J:Found binding in [jar:file:/D:/.m2/org/slf4j/slf4j-log4j12/1.6.1/slf4j
SLF4J:See http://www.slf4j.org/codes.html#multiple_bindings for an explanati
SLF4J:Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactoryERRORStatusLoggerNo log4j2 configuration file found. Usingdefault configur
1 zs
分析上面的警告信息,发现现在是有两个log4j的实现类,需要去掉一个,还有就是缺少log4j2的配置文件,注意log4j2的配置文件是xml格式的,不是properties格式的
1: 去掉多余的log4j依赖,从日志中可以看到日志的路径
这两个去掉哪个都可以,这两个都是hive-jdbc这个依赖带过来的,所以需要修改pom文件中hive-jdbc中的依赖
2:在项目的resources目录中增加log4j2.xml配置文件
<?xml version="1.0" encoding="UTF-8"?><Configurationstatus="INFO"><Appenders><Consolename="Console"target="SYSTEM_OUT"><PatternLayoutpattern="%d{YYYY-MM-dd HH:mm:ss} [%t] %-5p %c{1}:%
</Console>
</Appenders>
<Loggers>
<Root level="info"><AppenderRefref="Console"/></Root></Loggers></Configuration>
Set命令的使用
在hive命令行中可以使用set命令临时设置一些参数的值,
其实就是临时修改hive-site.xml中参数的值,不过通过set命令设置的参数只在当前会话有效,退出重新打开就无效了。如果想要对当前机器上的当前用户有效的话可以把命令配置在 /.hiverc文件中。所以总结一下,使用set命令配置的参数是当前会话有效,在/.hiverc文件中配置的是当前机器中的当前用户有效,而在hive-site.xml中配置的则是永久有效了,在hive-site.xml中有一个参数是hive.cli.print.current.db ,这个参数可以显示当前所在的数据库名称,默认值为 false 。在这里我们设置为true
hive>set hive.cli.print.current.db =true;
hive (default)>
还有一个参数 hive.cli.print.header 可以控制获取结果的时候显示字段名称,这样看起来会比较清晰
hive (default)>select*from t1;
OK
1 zs
Time taken: 0.184 seconds, Fetched: 1row(s)
hive (default)>set hive.cli.print.header =true;
hive (default)>select*from t1;
OK
t1.id t1.name
1 zs
Time taken: 0.202 seconds, Fetched: 1row(s)
如果我们想查看一下hive的历史操作命令如何查看呢?
linux中有一个history命令可以查看历史操作命令
hive中也有类似的功能,hive中的历史命令会存储在当前用户目录下的 .hivehistory 目录中
[root@bigdata04 apache-hive-3.1.2-bin]# more ~/.hivehistory
show tables;exit
Hive的日志配置
我们每次进入hive命令行的时候都会出现这么一坨日志,看着很恶心,想要去掉,怎么办呢?
通过分析日志可知,现在也是有重复的日志依赖,所以需要删除一个,
/data/soft/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar
/data/soft/hadoop-3.2.0/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar
这里是hive中的一个日志依赖包和hadoop中的日志依赖包冲入了,那我们只能去掉Hive的了,因为hadoop是共用的,尽量不要删它里面的东西。为了保险起见,我们可以使用mv给这个日志依赖包重命名,这样它就不生效了
[root@bigdata04 lib]# mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0
这个时候再进入hive命令行就没有那些日志了,剩下的这些属于正常的
还有就是当我们遇到Hive执行发生错误的时候,我们要学会去查看Hive的日志信息,通过日志的提示来分析,找到错误的根源,帮助我们及时解决错误。
那我们在哪里查看Hive日志呢,我们可以通过配置文件来找到默认日志文件所在的位置。
在hive的conf目录下有一些log4j的模板配置文件,我们需要去修改一下,让它生效。首先是 hive-log4j.properties.template 这个文件,去掉 .template 后缀,修改里面的 property.hive.log.level 和 property.hive.log.dir 参数.
[root@bigdata04 conf]# mv hive-log4j2.properties.template hive-log4j2.propert[root@bigdata04 conf]# vi hive-log4j2.properties
property.hive.log.level = WARN
property.hive.root.logger = DRFA
property.hive.log.dir = /data/hive_repo/log
property.hive.log.file = hive.log
property.hive.perflogger.log.level = INFO
然后修改 hive-exec-log4j2.properties.template 这个文件,去掉 .template 后缀修改里面的
[root@bigdata04 conf]# mv hive-exec-log4j2.properties.template hive-exec-log4[root@bigdata04 conf]# vi hive-exec-log4j2.properties
property.hive.log.level = WARN
property.hive.root.logger = FA
property.hive.query.id = hadoop
property.hive.log.dir = /data/hive_repo/log
property.hive.log.file =${sys:hive.query.id}.log
这样后期分析日志就可以到 /data/hive_repo/log 目录下去查看了。
Hive中数据库的操作
- 查看数据库列表
hive (default)>showdatabases;
OK
database_name
defaultTime taken: 0.033 seconds, Fetched: 1row(s)
hive (default)>
- 选择数据库
hive (default)>usedefault;
OK
Time taken: 0.024 seconds
default是默认数据库,默认就在这个库里面
咱们前面说过hive的数据都是存储在hdfs上,那这里的default数据库在HDFS上是如何体现的?
在 hive-site.xml 中有一个参数 hive.metastore.warehouse.dir
<property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value><description>location of default database for the warehouse</description></property>
它的默认值是 /user/hive/warehouse ,表示hive的default默认数据库对应的hdfs存储目录。
那我们到HDFS上看一下,发现确实有这个目录,并且这个目录下还有一个t1目录,其实这个t1就是我们前面在default数据库中创建的那个t1表,从这可以看出来,hive中的数据库和hive中的表,在hdfs上面的体现其实都是目录。

- 创建数据库
hive (default)>createdatabase mydb1;
OK
Time taken: 0.159 seconds
这个数据库在hdfs上的对应目录在哪呢?来看一下
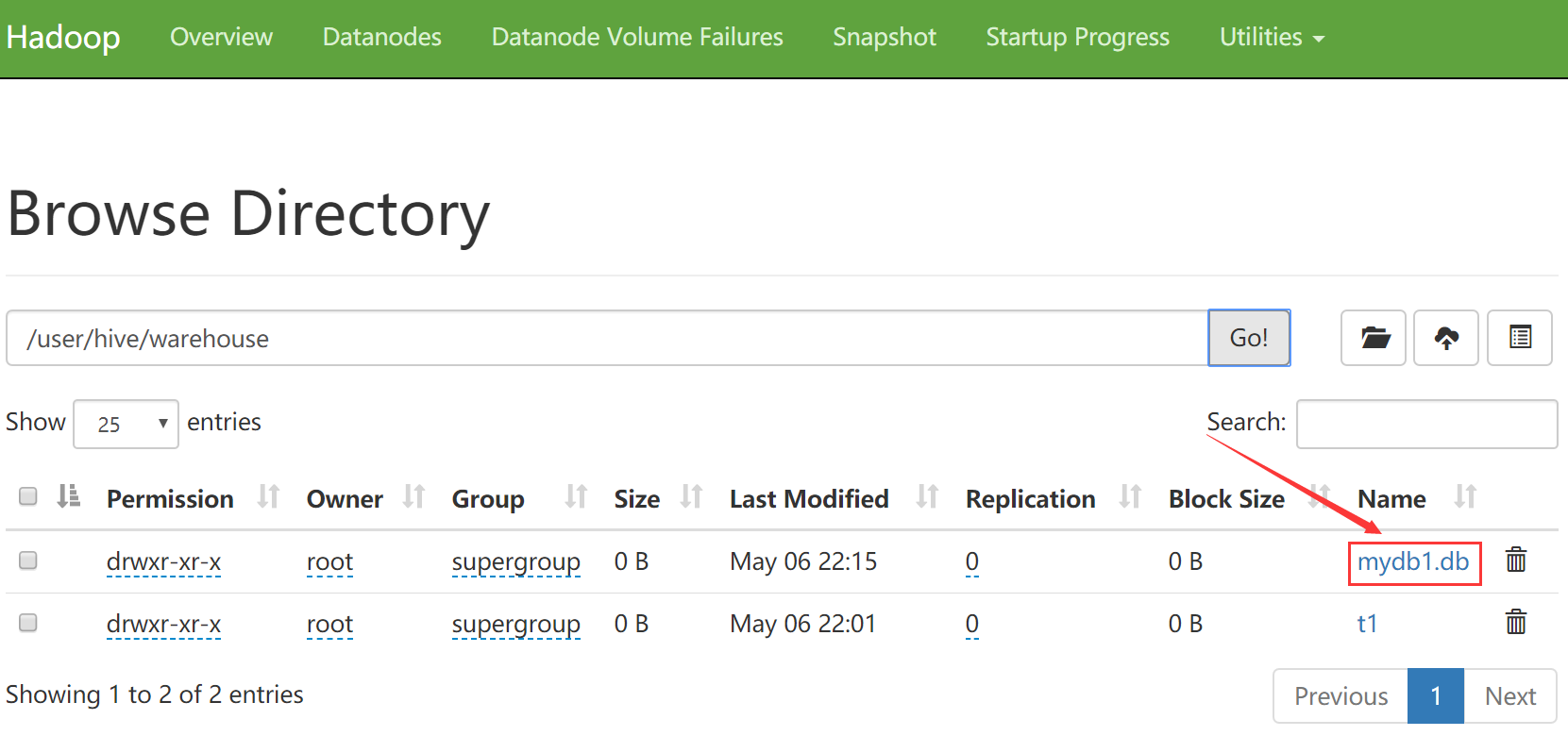
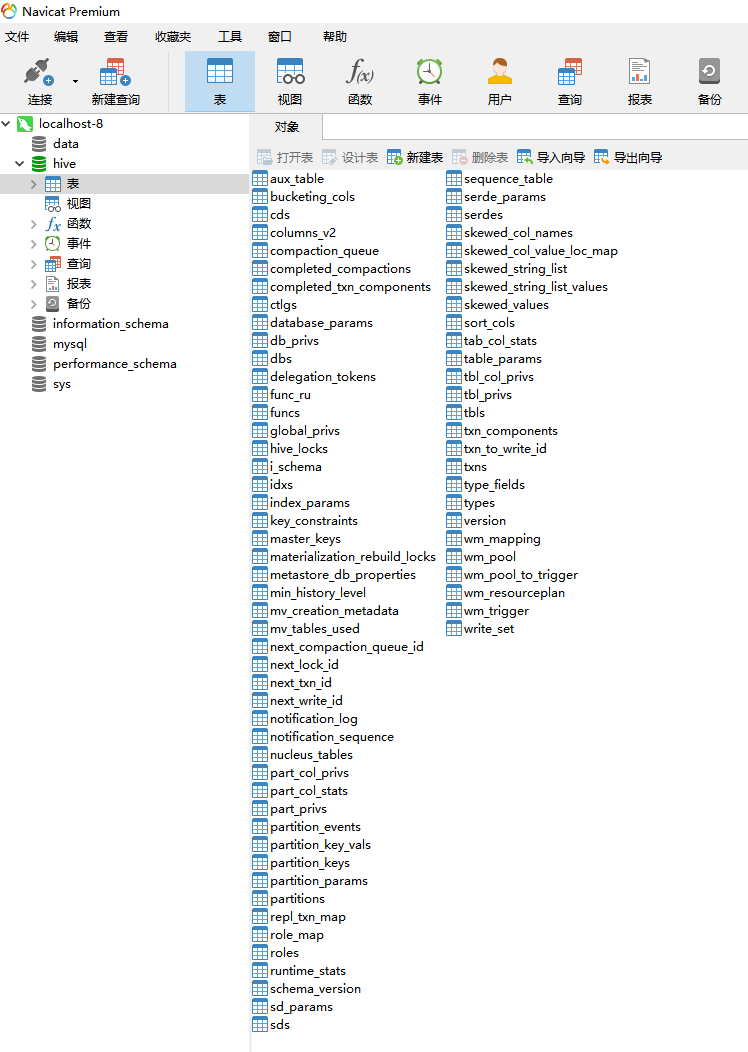
到metastore中确认一下
如果你不希望创建的数据库在这个目录下面,想要手工指定,那也是可以的,在创建数据库的时候通过location来指定hdfs目录的位置
hive (default)>createdatabase mydb2 location '/user/hive/mydb2';
OK
Time taken: 0.086 seconds
Hive中表的操作
- 创建表
hive (default)>createtable t2(id int);
OK
Time taken: 0.18 seconds
- 查看表信息 显示当前数据库中所有的表名
hive (default)>showtables;
OK
tab_name
t1
t2
Time taken: 0.039 seconds, Fetched: 2row(s)
- 查看表结构信息
hive (default)>desc t2;
OK
- 查看表的创建信息
hive (default)>showcreatetable t2;
OK
createtab_stmt
CREATETABLE`t2`(`id`int)ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://bigdata01:9000/user/hive/warehouse/t2'
TBLPROPERTIES ('bucketing_version'='2','transient_lastDdlTime'='1588776407')Time taken: 0.117 seconds, Fetched: 13row(s)
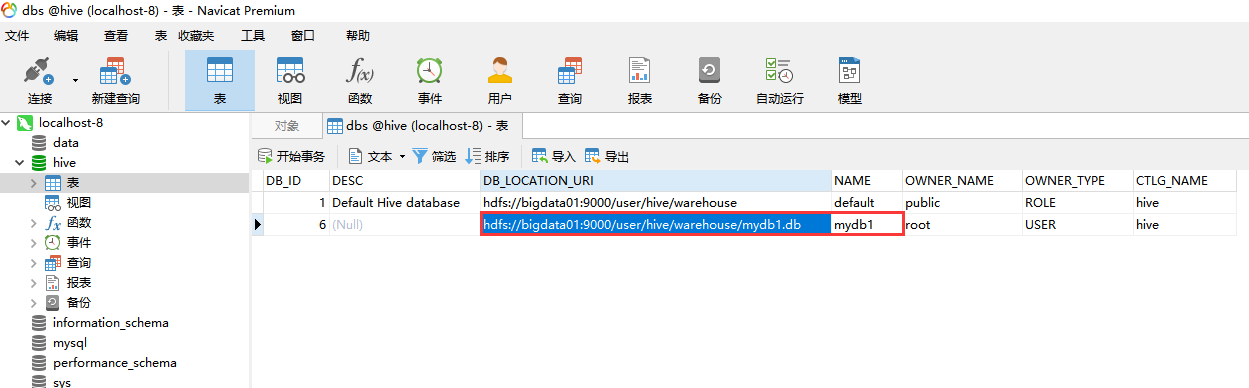
从这里的location可以看到这个表在hdfs上的位置。注意了:表中的数据是存储在hdfs中的,但是表的名称、字段信息是存储在metastore中的
到metastore中看一下
先看tbls表,这个里面中存储的都是在hive中创建的表
可以看到DB_ID 为1
可以到dbs表中看到默认default数据库的id就是1。
TBL_NAME 是这个表的名称。

- 对表名进行重命名
hive (default)>altertable t2 renameto t2_bak;
OK
Time taken: 0.25 seconds
hive (default)>showtables;
OK
tab_name
t1
t2_bak
Time taken: 0.138 seconds, Fetched: 2row(s)
- 加载数据 咱们前面向表中添加数据是使用的insert命令,其实使用insert向表里面添加数据只是在测试的时候使用,实际中向表里面添加数据很少使用insert命令的 向表中加载数据可以使用load命令 以t2_bak为例,在bigdata04机器的 /data/soft/hivedata 下有一个 t2.data 文件,将其加载到 t2_bak表中
[root@bigdata04 hivedata]# pwd/data/soft/hivedata
[root@bigdata04 hivedata]# more t2.data12345
hive (default)>loaddatalocal inpath '/data/soft/hivedata/t2.data'into tab
Loading datatotabledefault.t2_bak
OK
Time taken: 0.539 seconds
查看表中的内容
hive (default)>select*from t2_bak;
OK
12345Time taken: 0.138 seconds, Fetched: 5row(s)
我们到hdfs上去看一下这个表,发现刚才的文件其实就是上传到了t2_bak目录中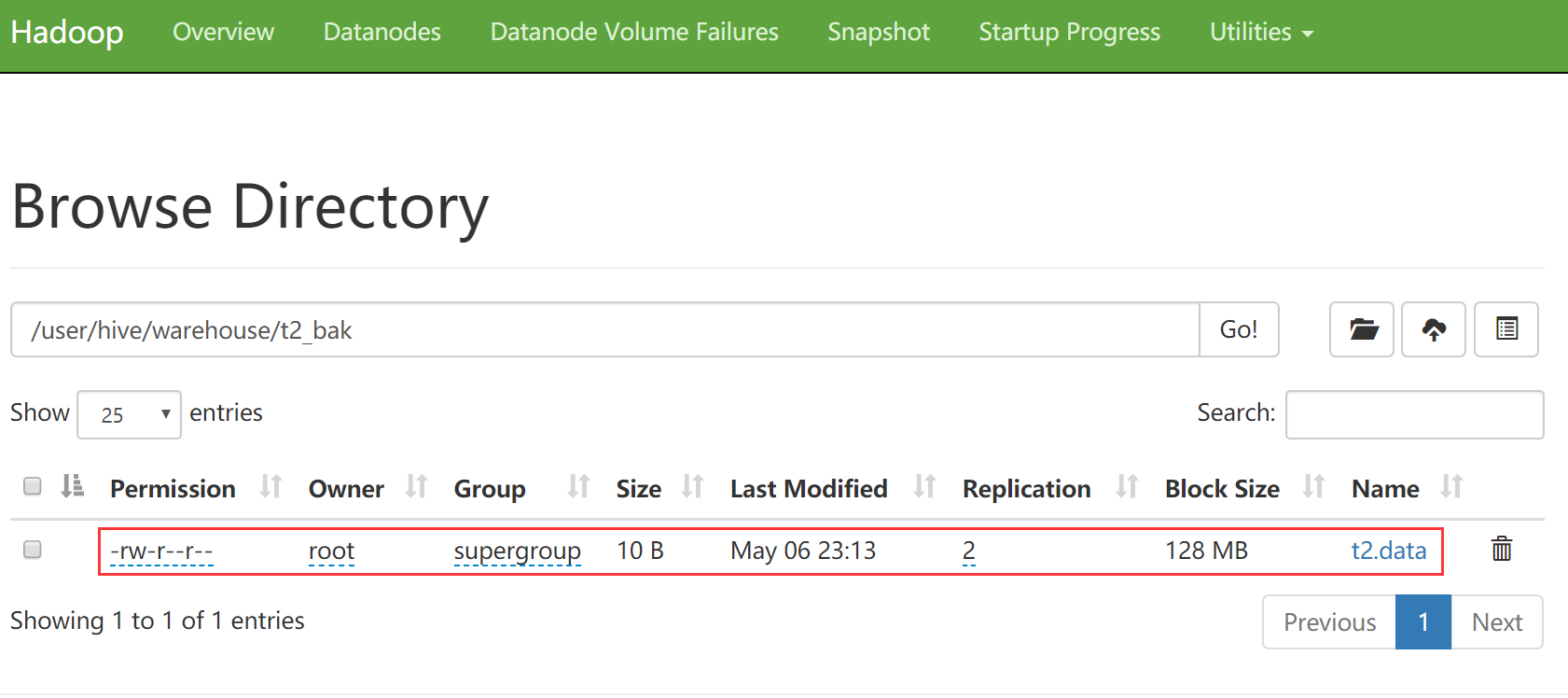
- 表增加字段及注释、删除表 在工作中会有给已存在的表增加字段的需求,需要使用alter命令 在这里我们给t2_bak表增加一个name字段,重新查看表结构信息,再查询一下这个表中的数据,结果发现,第二列为null,这是正常的,因为我们的数据数据文件中就只有一列,第二列查询不到,就显示为null,不会报错,这一点要注意一下。
hive (default)>altertable t2_bak addcolumns(name string);
OK
Time taken: 0.175 seconds
hive (default)>desc t2_bak;
OK
col_name data_type comment
id int
name string
Time taken: 0.121 seconds, Fetched: 2row(s)
hive (default)>select*from t2_bak;
OK
t2_bak.id t2_bak.name
1NULL2NULL3NULL4NULL5NULL1NULL2NULL3NULL4NULL5NULLTime taken: 0.199 seconds, Fetched: 10row(s)
现在我们通过desc查询表中的字段信息发现都没有注释,所以想要给字段加一些注释,以及表本身也可以增加注释,都是使用comment关键字重新创建一个表t2
注意:在建表语句中,缩进不要使用tab制表符,否则拷贝到hive命令行下执行会提示语句错误,这里的缩进需要使用空格。
createtable t2(
age intcomment'年龄')comment'测试';
Hive中的数据类型
hive作为一个类似数据库的框架,也有自己的数据类型,便于存储、统计、分析。
Hive中主要包含两大数据类型
- 一类是基本数据类型
- 一类是复合数据类型 基本数据类型:常用的有INT,STRING,BOOLEAN,DOUBLE等 复合数据类型:常用的有ARRAY,MAP,STRUCT等
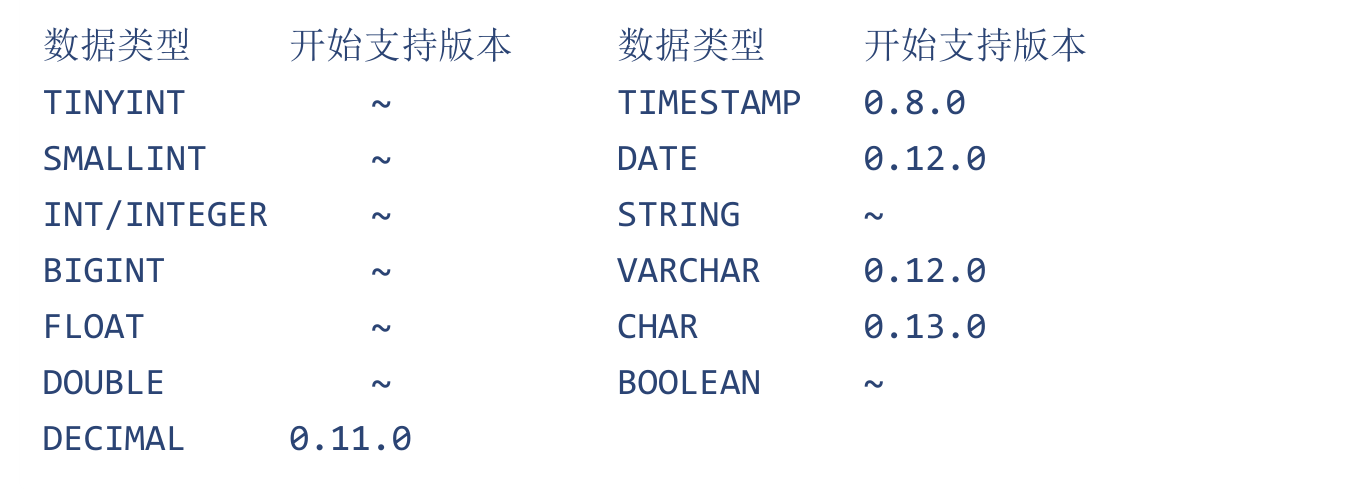
基本数据类型
一般数字类型我们可以试验int,小数可以使用double,日期可以使用date类型、还有就是boolean类型,这些算是比较常见的了,前面我们在建表的时候基本都用过了。这些基本数据类型倒没有什么特殊之处
复合数据类型
在这里我们主要分析这三个, array,map和struct

Array
先来看Array,这个表示是一个数组结构
在这里举一个例子:学生有多个爱好,有两个学生,zhangsan、lisi,
zhangsan的爱好是swing、sing、coding
lisi的爱好是music、football
每个学生的爱好都是不固定的,有多有少,如果根据学生的每一个爱好都在表里面增加一列,这样就不合适了,后期可能要经常增加列存储不同的爱好。
如果我们如果把每个学生的爱好都拼接为一个字符串保存到一个字段中,这样针对存储层面来说是没有问题的,但是后期需要根据爱好的增加而修改字段,这样操作起来很不方便,如果想获取每个学生的1个爱好,这样是没办法直接获取的,因为这些爱好是以字符串的形式保存在一个字段中的。为了方便存储和使用,我们针对学生的爱好这种数据个数不固定的场景,可以使用数组的形式来存储。
测试数据是这样的
[root@bigdata04 hivedata]# more stu.data1 zhangsan swing,sing,coding
2 lisi music,football
来建一张表,指定了一个array数组类型的字段叫favors,数组中存储字符串,数组中的元素怎么分割呢?通过 collection items terminated by ‘,’ 指定的
createtable stu(
id int,
name string,
favors array<string>)row format delimited
fieldsterminatedby'\t'
collection items terminatedby','linesterminatedby'\n';
向表中加载数据
hive (default)>loaddatalocal inpath '/data/soft/hivedata/stu.data'intotable stu
Loading datatotabledefault.stu
OK
Time taken: 1.478 seconds
查询数组中的某一个元素,使用 arrayName[index]
hive (default)>select*from stu;
OK
stu.id stu.name stu.favors
1 zhangsan ["swing","sing","coding"]2 lisi ["music","football"]Time taken: 1.547 seconds, Fetched: 2row(s)
hive (default)>select id,name,favors[1]from stu;
OK
1 zhangsan sing
2 lisi football
Time taken: 0.631 seconds, Fetched: 2row(s)
角标是从0开始的,如果获取到了不存在的角标则返回null。这就是Array类型的使用了
Map
下面来说一下另外一种常见的集合——map,我们知道map集合里面存储的是键值对,每一个键值对属于Map集合的一个item,这里给大家举个例子,有两个学生zhangsan、lisi,每个学生有语文、数学、英语,成绩如下:
[root@bigdata04 hivedata]# more stu2.data1 zhangsan chinese:80,math:90,english:100
2 lisi chinese:89,english:70,math:88
针对学生的成绩信息最好也是存储到一个字段中,方便管理和使用,发现学生的成绩都是key-value类型的,所以非常适合使用map类型。建表语句如下:指定scores字段类型为map格式。通过 collection items terminated by ‘,’ 指定了map中元素之间的分隔符。通过 map keys terminated by ‘:’ 指定了key和value之间的分隔符。
createtable stu2(
id int,
name string,
scores map<string,int>)row format delimited
fieldsterminatedby'\t'
collection items terminatedby','
map keysterminatedby':'linesterminatedby'\n';
向表中加载数据
hive (default)>loaddatalocal inpath '/data/soft/hivedata/stu2.data'into t
Loading datatotabledefault.stu2
OK
Time taken: 0.521 seconds
查询所有学生的语文和数学成绩
hive (default)>select id,name,scores['chinese'],scores['math']from stu2;
id name _c2 _c3
1 zhangsan 80902 lisi 8988Time taken: 0.232 seconds, Fetched: 2row(s)
在这注意一下,我们取数据是根据元素中的key获取的,和map结构中元素的位置没有关系
Struct
再来介绍最后一种复合类型struct,有点像java中的对象,举个例子说明一下,
某学校有2个实习生,zhangsan、lisi,每个实习生都有地址信息,一个是户籍地所在的城市,一个是公司所在的城市,我们来组织一下数据
[root@bigdata04 hivedata]# more stu3.data1 zhangsan bj,sh
2 lisi gz,sz
针对这里面的地址信息,不能懒省事使用字符串,否则后期想要获取他们对应的户籍地城市或者公司所在的城市信息时就比较麻烦了。所以在这我们可以考虑使用Struct类型
建表语句如下:
createtable stu3(
id int,
name string,
address struct<home_addr:string,office_addr:string>)row format delimited
fieldsterminatedby'\t'
collection items terminatedby','linesterminatedby'\n';
加载数据
hive (default)>loaddatalocal inpath '/data/soft/hivedata/stu3.data'into t
Loading datatotabledefault.stu3
OK
Time taken: 0.447 seconds
Struct和Map的区别
如果从建表语句上来分析,其实这个Struct和Map还是有一些相似之处的
来总结一下:
- map中可以随意增加k-v对的个数
- struct中的k-v个数是固定的
- map在建表语句中需要指定k-v的类型
- struct在建表语句中需要指定好所有的属性名称和类型
- map中通过[]取值
- struct中通过.取值,类似java中的对象属性引用
- map的源数据中需要带有k-v
- struct的源数据中只需要有v即可
总体而言还是map比较灵活,但是会额外占用磁盘空间,因为他比struct多存储了数据的key。 struct只需要存储value,比较节省空间,但是灵活性有限,后期无法动态增加k-v
案例:复合数据类型的使用
在这里我们把前面学到的这三种复合数据类型结合到一块来使用一下。
有一份数据是这样的
[root@bigdata04 hivedata]# more student.data1 zhangsan english,sing,swing chinese:80,math:90,english:10
2 lisi games,coding chinese:89,english:70,math:88 gz,sz
根据这份数据建表,根据咱们前面的学习,这里面这几个字段分别是int类型、string类型,array类型,map类型,struct类型。
其实也不一定非要使用这些复合类型,主要是需要根据具体业务分析,使用复合数据类型可以更方便的操作数据。
createtable student (
id intcomment'id',
name string comment'name',
favors array<string>,
scores map<string,int>,
address struct<home_addr:string,office_addr:string>)row format delimited
fieldsterminatedby'\t'
collection items terminatedby','
map keysterminatedby':'linesterminatedby'\n';
加载数据
hive (default)> load data local inpath '/data/soft/hivedata/student.data' into student
Loading data to table default.student
查询数据
hive (default)>select * from student;
OK
student.id student.name student.favors student.scores student.addre
1 zhangsan ["english","sing","swing"]{"chinese":80,"math":2 lisi ["games","coding"]{"chinese":89,"english":70,"math":88}
Time taken: 0.168 seconds, Fetched: 2 row(s)
思考题
问:在mysql中有一张表student(id,name),还有一张表address(stu_id,home,school),还有联系方式表contact(stu_id,mine,parents,others)。如果把这三张表迁移到hive中,如何迁移?
答:
可以一一对应迁移,优点是迁移成本非常低,包括DDL和业务逻辑,几乎不需要修改,可以直接使用。缺点是产生大量的表连接,造成查询慢。可以一对多,mysql中的多张关联表可以创建为hive中的一张表。优点是减少表连接操作。缺点是迁移成本高,需要修改原有的业务逻辑。实际上,在我们日常的开发过程中遇到这样的问题,要想比较完美、顺利的解决,一般都分为两个阶段,第一个阶段,现在快捷迁移,就是上面说的一一对应,让我们的系统能跑起来,在此基础之上呢,再做一张大表,尽量包含以上所有字段,例如:stu(id, name, address struct<home,school>, contact struct<…>);等第二个阶段完工之后了,就可以跑在新的系统里面了。
Hive中的表类型
在Mysql中没有表类型这个概念,因为它就只有一种表。
但是Hive中是有多种表类型的,我们可以分为四种,内部表、外部表、分区表、桶表。 下面来一个一个学习一下这些类型的表
内部表
内部表也可以称为受控表,它是Hive中的默认表类型,表数据默认存储在 warehouse 目录中。在加载数据的过程中,实际数据会被移动到warehouse目录中,就是咱们前面在使用load加载数据的时候,数据就会被加载到warehouse中表对应的目录中。当我们删除表时,表中的数据和元数据将会被同时删除。实际上,我们前面创建的表都属于受控表,前面我们已经演示了,创建一张表,其对应就,在metastore中存储表的元数据信息,当我们一旦从hive中删除一张表之后,表中的数据会被删除,在metastore中存储的元数据信息也会被删除。这就是内部表的特性。
外部表
建表语句中包含 External 的表叫外部表。表的定义和数据的生命周期互相不约束,数据只是表对hdfs上的某一个目录的引用而已,当删除表定义的时候,数据依然是存在的。仅删除表和数据之间引用关系,所以这种表是比较安全的,就算是我们误删表了,数据还是没丢的。我们来创建一张外部表,看一下外部表的建表语句该如何来写。
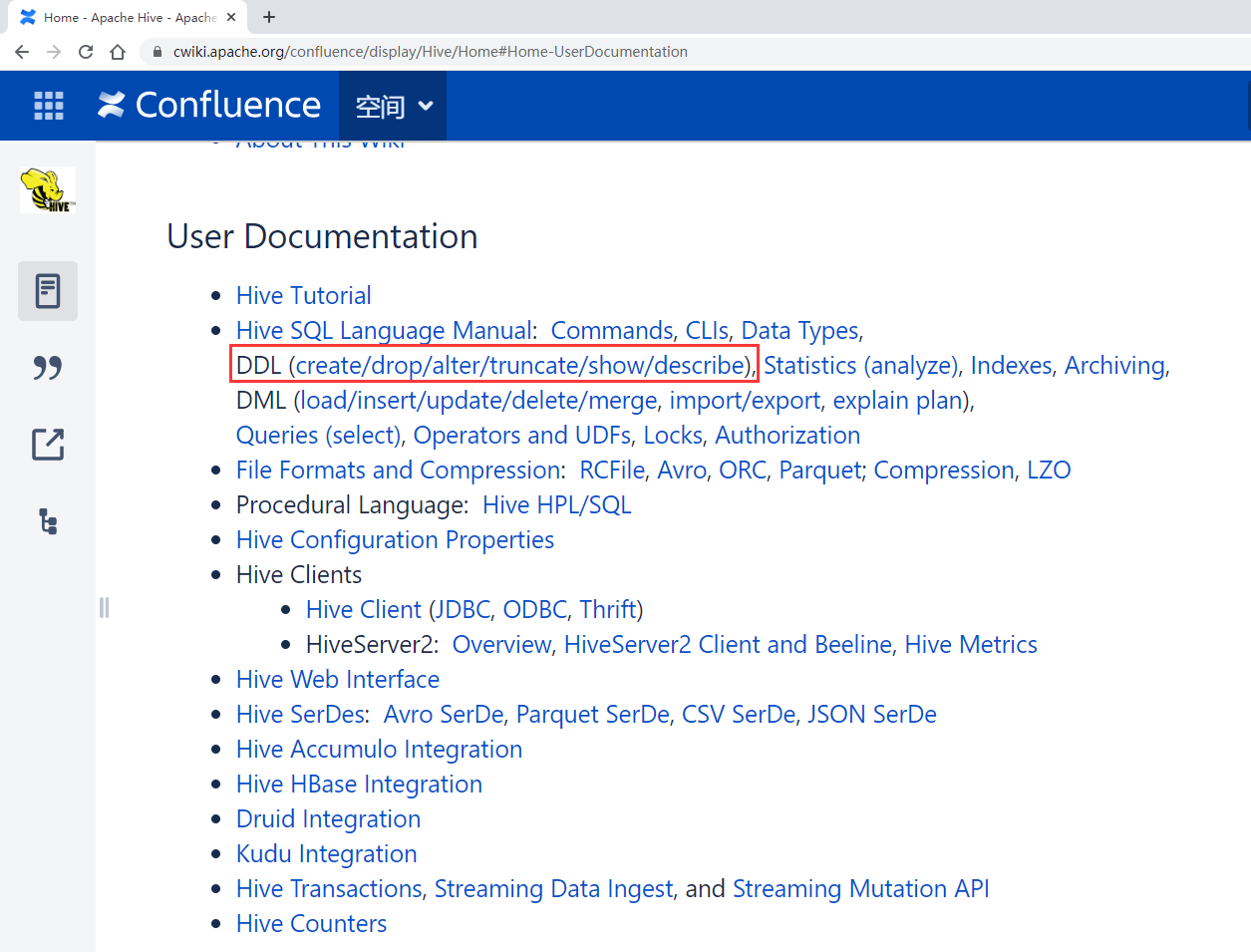
官网中的案例如下:
主要就是在建表语句中增加了EXTERNAL 以及在最后通过locatin指定了这个表数据的存储位置,注意这个路径是hdfs的路径
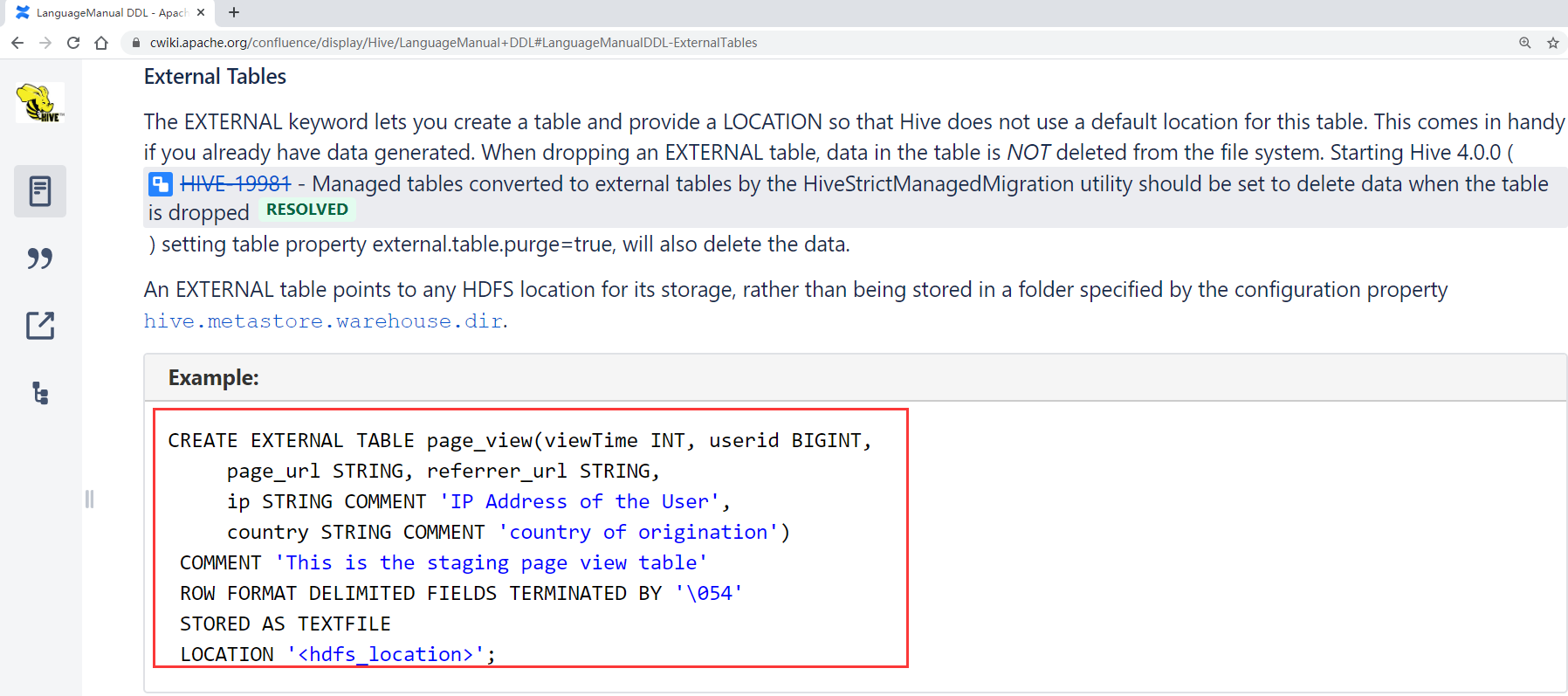
CREATE EXTERNAL TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT'IP Address of the User',
country STRING COMMENT'country of origination')COMMENT'This is the staging page view table'ROW FORMAT DELIMITED FIELDSTERMINATEDBY'\054'
STORED AS TEXTFILE
LOCATION '<hdfs_location>';
那根据这个格式我们自己来创建一个外部表
create external table external_table (key string
) location '/data/external';
表创建完以后到hdfs上查询,如果指定的目录不存在会自动创建
[root@bigdata04 hivedata]# hdfs dfs -ls /data
Found 1 items
drwxr-xr-x - root supergroup 02020-05-07 13:29 /data/external
此时到hdfs的 /user/hive/warehouse/ 目录下查看,是看不到这个表的目录的,因为这个表的目录是我们刚才通过location指定的目录

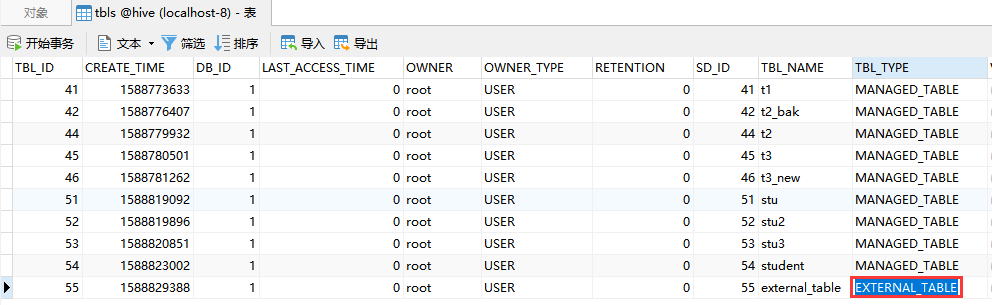
我们再来看一下metastore中的tbls表,这里看到external_table的类型是外部表。
下面我们往这个外部表中加载数据,原始数据文件为 external_table.data
`
[root@bigdata04 hivedata]# more external_table.data
a
b
c
d
e
加载数据
hive (default)> load data local inpath '/data/soft/hivedata/external_table.dat
Loading data to table default.external_table
OK
Time taken: 0.364 seconds
此时加载的数据会存储到hdfs的 /data/external 目录下
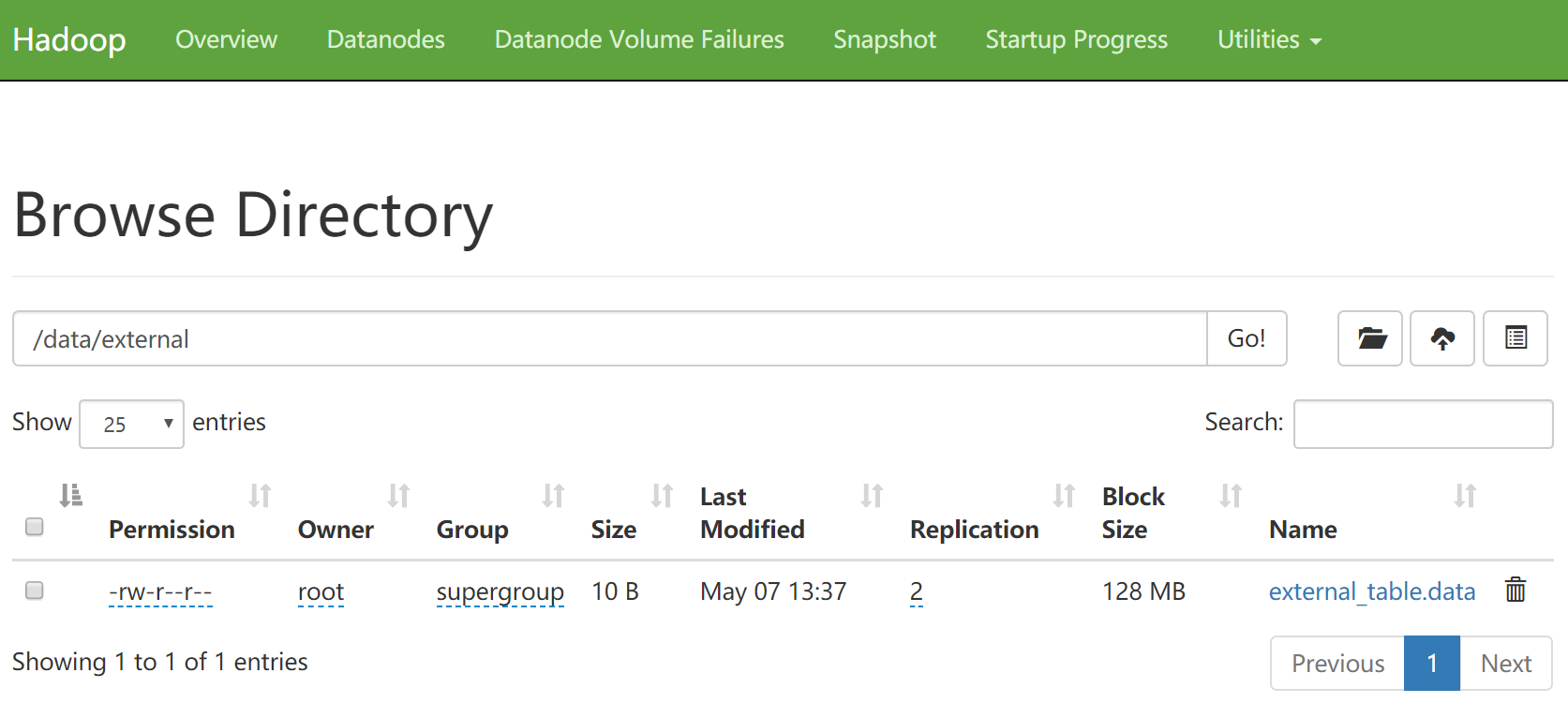
这个其实就是前面我们所的外部表的特性,外部表被删除时,只会删除表的元数据,表中的数据不会被删除。
注意:实际上内外部表是可以互相转化的,需要我们做一下简单的设置即可。
内部表转外部表 alter table tblName set tblproperties (‘external’=‘true’);
外部表转内部表 alter table tblName set tblproperties (‘external’=‘false’);
在实际工作中,我们在hive中创建的表95%以上的都是外部表。
因为大致流程是这样的,我们先通过flume采集数据,把数据上传到hdfs中,然后在hive中创建外部表和hdfs上的数据绑定关系,就可以使用sql查询数据了,所以连load数据那一步都可以省略了,因为是先有数据,才创建的表。
分区表
假设我们的web服务器每天都产生一个日志数据文件,Flume把数据采集到HDFS中,每一天的数据存储到一个日期目录中。我们如果想查询某一天的数据的话,hive执行的时候默认会对所有文件都扫描一遍,然后再过滤出来我们想要查询的那一天的数据。
如果你已经采集了一年的数据,这样每次计算都需要把一年的数据取出来,再过滤出来某一天的数据,效率就太低了,会非常浪费资源,所以我们可以让hive在查询的时候,根据你要查询的日期,直接定位到对应的日期目录。这样就可以直接查询满足条件的数据了,效率提升可不止一点点啊,是质的提升。想要实现这个功能,就需要使用分区表了。
分区可以理解为分类,通过分区把不同类型的数据放到不同目录中。
分区的标准就是指定分区字段,分区字段可以有一个或多个,根据咱们刚才举的例子,分区字段就是日期分区表的意义在于优化查询,查询时尽量利用分区字段,如果不使用分区字段,就会全表扫描,最典型的一个场景就是把天作为分区字段,查询的时候指定天按照上面的分析,我们来创建一个分区表,使用partitioned by指定区分字段,分区字段的名称为dt,类型为string。
createtable partition_1 (
id int,
name string
) partitioned by(dt string)row format delimited
fieldsterminatedby'\t';
查看表的信息,可以看到分区信息
hive (default)>desc partition_1;
OK
col_name data_type comment
id int
name string
dt string
# Partition Information# col_name data_type comment
dt string
Time taken: 0.745 seconds, Fetched: 7row(s)
数据格式是这样的
[root@bigdata04 hivedata]# more partition_1.data1 zhangsan
2 lisi
向分区表中加载数据【注意,在这里添加数据的同时需要指定分区信息】
hive (default)>loaddatalocal inpath '/data/soft/hivedata/partition_1.data'
Loading datatotabledefault.partition_1 partition(dt=2020-01-01)
OK
Time taken: 1.337 seconds
来查看一下hdfs中的信息,刚才创建的分区信息在hdfs中的体现是一个目录。
由于这个分区表属于内部表, 所以目录还在warehouse这个目录中
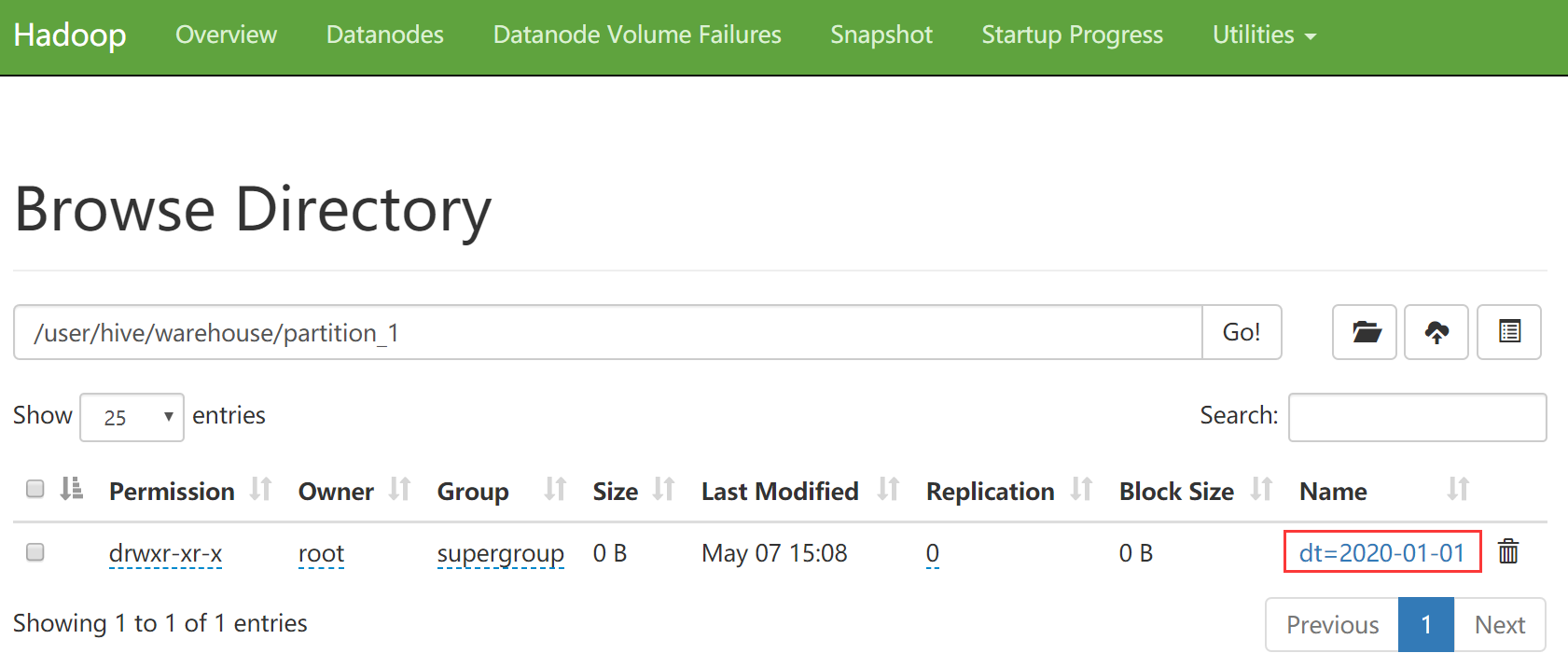
当然我也可以手动在表中只创建分区:
hive (default)>altertable partition_1 addpartition(dt='2020-01-02');
OK
Time taken: 0.295 seconds
如何查看我的表中目前有哪些分区呢,语法为: show partitions tblName
hive (default)>show partitions partition_1;
OK
partition
dt=2020-01-01
dt=2020-01-02Time taken: 0.246 seconds, Fetched: 2row(s)
那问题来了,刚才增加了一个分区,那我能删除一个分区吗?
必须是可以的!
hive (default)>altertable partition_1 droppartition(dt='2020-01-02');
Dropped the partition dt=2020-01-02
OK
Time taken: 0.771 seconds
hive (default)>show partitions partition_1;
OK
partition
dt=2020-01-01Time taken: 0.174 seconds, Fetched: 1row(s)
注意了,此时分区删除之后,分区中对应的数据也就没有了,因为是内部表,所以分区的数据是会被删掉的
前面我们讲了如何创建、增加和删除分区
还有一个比较重要的是我们该如何查询分区中的数据呢?其实非常简单,分区相当于我们的一个查询条件,直接跟在where后面就可以了。
select * from partition_2; 【全表扫描,没有用到分区的特性】
select * from partition_2 where year = 2019;【用到了一个分区字段进行过滤】
select * from partition_2 where year = 2019 and school = ‘xk’;【用到了两个分区字段进行过滤】
外部分区表
外部分区表示工作中最常用的表
我们先来创建一个外部分区表
create external table ex_par(
id int,
name string
)partitioned by(dt string)row format delimited
fieldsterminatedby'\t'
location '/data/ex_par';
其它的操作和前面操作普通分区表是一样的,我们主要演示一下添加分区数据和删除分区的操作
添加分区数据
hive (default)>loaddatalocal inpath '/data/soft/hivedata/ex_par.data'into ex_par
Loading datatotabledefault.ex_par partition(dt=2020-01-01)
OK
Time taken: 0.791 seconds
hive (default)>show partitions ex_par;
OK
partition
dt=2020-01-01Time taken: 0.415 seconds, Fetched: 1row(s)
删除分区
hive (default)>altertable ex_par droppartition(dt='2020-01-01');
Dropped the partition dt=2020-01-01
OK
Time taken: 0.608 seconds
hive (default)>show partitions ex_par;
OK
partitionTime taken: 0.229 seconds
分区删除之后,在这里就看不到分区信息了,那hdfs上的分区目录被删除了吗?
注意:此时分区目录的数据还是在的,因为这个是外部表,所以删除分区也只是删除分区的定义,分区中的数据还是在的,这个和内部分区表就不一样了。
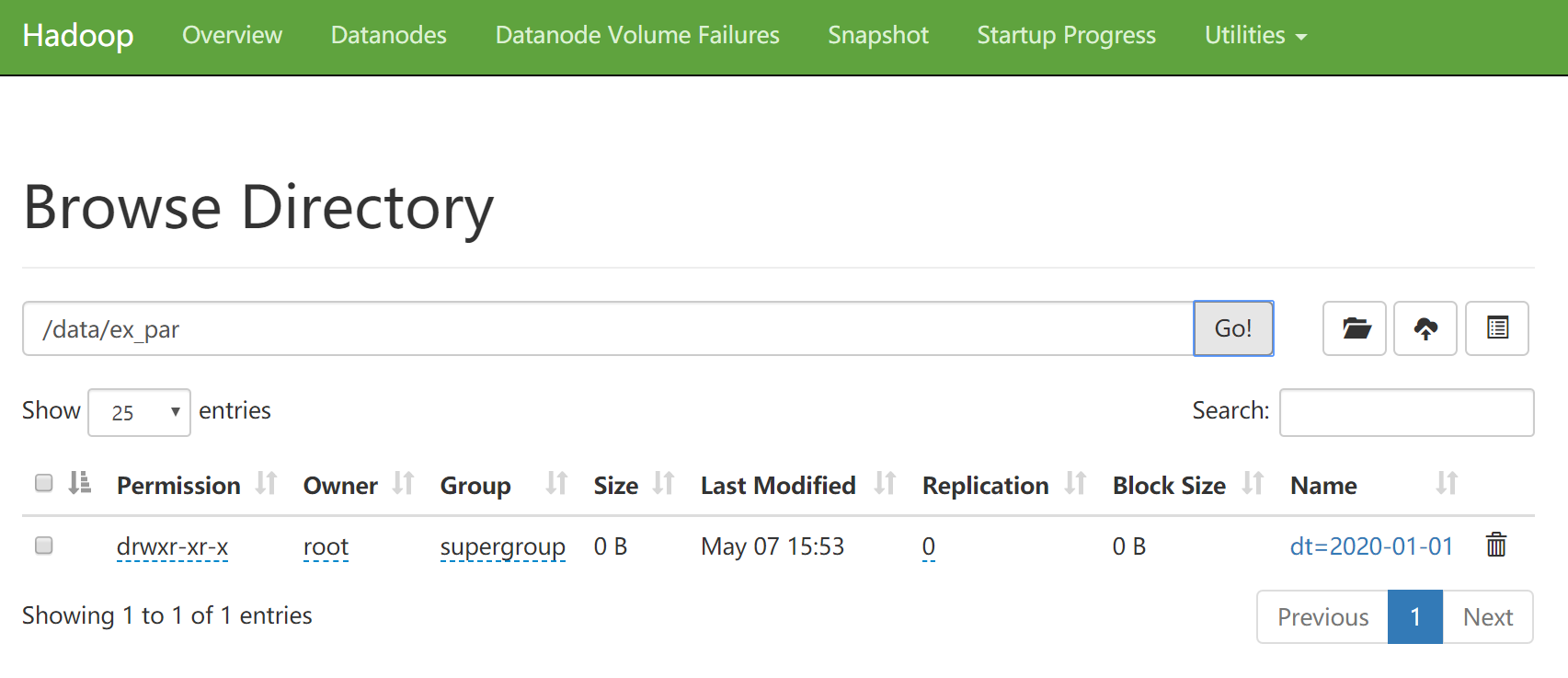
虽然这个分区目录还在,但是刚才我们通过,show partitions 已经查不到分区信息了,所以查询表数据是查不出来的,虽然这个目录确实在这个表对应的hdfs目录中,但是由于这个是一个分区表,这份数据没有和任何分区绑定,所以就查询不出来
这个一定要注意,在实际工作中新手最容易遇到的一个问题就是,针对分区表,通过hdfs的put命令把数据上传上去了,但是却查不到数据,就是因为没有在表中添加分区信息,也就是说你们现在虽然在一起了,但是还没有领结婚证,国家还不承认。
hive (default)>select*from ex_par;
OK
ex_par.id ex_par.name ex_par.dt
Time taken: 0.279 seconds
如果数据已经上传上去了,如何给他们绑定关系呢?就是使用前面咱们讲的alter add partition命令,注意在这里需要通过location指定分区目录
hive (default)>altertable ex_par addpartition(dt='2020-01-01') location '/
此时再查询分区数据和表数据,就正常了。
hive (default)>show partitions ex_par;
OK
partition
dt=2020-01-01Time taken: 0.19 seconds, Fetched: 1row(s)
hive (default)>select*from ex_par;
OK
ex_par.id ex_par.name ex_par.dt
1 zhangsan 2020-01-012 lisi 2020-01-013 wangwu 2020-01-01Time taken: 0.432 seconds, Fetched: 3row(s)
总结一下:
load data…partition这条命令做了两件事情,上传数据,添加分区(绑定数据和分区之间的关系)
hdfs dfs -mkdir /data/ex_par/dt=2020-01-01
hdfs dfs -put /data/soft/hivedata/ex_par.data/data/ex_par/dt=2020-01-01altertable ex_par addpartition(dt='2020-01-01') location '/data/ex_par/dt=2
上面这三条命令做了两个事情,上传数据,添加分区(绑定数据和分区之间的关系)
桶表
桶表是对数据进行哈希取值,然后放到不同文件中存储
物理上,每个桶就是表(或分区)里的一个文件
什么时候会用到桶表呢?
举个例子,针对中国的人口,主要集中河南、江苏、山东、广东、四川,其他省份就少的多了,你像西藏就三四百万,海南也挺少的,如果使用分区表,我们把省份作为分区字段,数据会集中在某几个分区,其他分区数据就不会很多,那这样对数据存储以及查询不太友好,在计算的时候会出现数据倾斜的问题,计算效率也不高,我们应该相对均匀的存放数据,从源头上解决,这个时候我们就可以采用分桶的概念,也就是使用桶表。
下面来建立一个桶表:
这个表的意思是按照id进行分桶,分成4个桶。
createtable bucket_tb(
id int)clusteredby(id)into4 buckets;
这个时候往桶中加载数据的时候,就不能使用load data的方式了,而是需要使用其它表中的数据,那么给桶表加载数据的写法就有新的变化了。
类似这样的写法
insert into table … select … from …;
注意,在插入数据之前需要先设置开启桶操作,不然数据无法分到不同的桶里面。其实这里的分桶就是设置reduce任务的数量,因为你分了多少个桶,最终结果就会产生多少个文件,最终结果中文件的数量就和reduce任务的数量是挂钩的
设置完 set hive.enforce.bucketing = true 可以自动控制reduce的数量从而适配bucket的个数
hive (default)>set hive.enforce.bucketing=true;
初始化一个表,用于向桶表中加载数据
原始数据文件是这样的
[root@bigdata04 hivedata]# more b_source.data123456789101112
hive (default)>createtable b_source(id int);
OK
Time taken: 0.262 seconds
hive (default)>loaddatalocal inpath '/data/soft/hivedata/b_source.data'int
Loading datatotabledefault.b_source
OK
Time taken: 0.388 seconds
hive (default)>select*from b_source;
OK
b_source.id
123456789101112Time taken: 0.187 seconds, Fetched: 12row(s)
视图
我们在Hive中如何来创建一个视图呢?
需要使用create view命令,
下面我们来创建一个视图
hive (default)>createview v1 asselect t3_new.id,t3_new.stu_name from t3_n
OK
id stu_name
Time taken: 0.3 seconds
此时通过 show tables 也可以查看到这个视图
hive (default)>showtables;
OK
tab_name
b_source
bucket_tb
ex_par
partition_1
partition_2
stu
stu2
stu3
student
t1
t2
t2_bak
t3
t3_new
v1
Time taken: 0.029 seconds, Fetched: 15row(s)
查看视图的结构,显示的内容和表显示的内容是没有区别的
hive (default)>desc v1;
OK
col_name data_type comment
id int
stu_name string
Time taken: 0.041 seconds, Fetched: 2row(s)
版权归原作者 小崔的技术博客 所有, 如有侵权,请联系我们删除。