
Spark读取Excel文件需要先添加对应的第三方库
<dependency><groupId>com.crealytics</groupId><artifactId>spark-excel_2.12</artifactId><version>3.3.1_0.18.5</version></dependency>
将上面的依赖添加上即可
测试数据如下图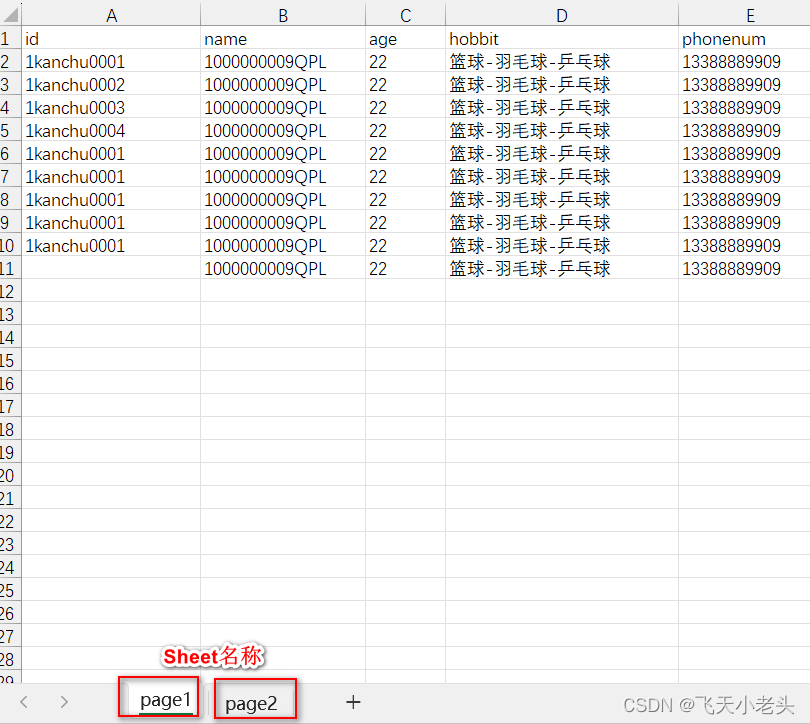
代码模板如下
importorg.apache.spark.sql.{DataFrame, SparkSession}/**
* @Author: J
* @Version: 1.0
* @CreateTime: 2023/4/25
* @Description: 读取Excel表
* */object ReadExcel {def main(args: Array[String]):Unit={val spark = SparkSession.builder().master("local[*]").appName("Read Excel file").getOrCreate()val excelDF: DataFrame = spark.read
.format("com.crealytics.spark.excel")// .option("sheetName", "Sheet1") // 读取的Sheet页.option("header","false")// 第一行不作为表头,如果为true则作为表头.option("dataAddress","'page1'!A3:E6")// 'page1'Sheet页名称(也可以选用'sheetName'的方式进行配置),A3代表从第几行读取(3则代表从第三行),E6代表行的范围.option("treatEmptyValuesAsNulls","true")// 空值是否为作为null.load("file:///E:\\TestData\\TEST.xlsx")// 如果是本地文件需要标注'file:///实际路径'因为spark会默认将HDFS作为文件系统val excelHeader = Seq("id2","name2","age2","hobbit2","phoneNum")// 自定义表头名称val frameDF = excelDF.toDF(excelHeader: _*)
frameDF.show()
spark.stop()}}
结果数据如下
+-----------+-------------+----+------------------+-----------+|1kanchu0002|1000000009QPL| 22|篮球-羽毛球-乒乓球|13388889909||1kanchu0003|1000000009QPL| 22|篮球-羽毛球-乒乓球|13388889909||1kanchu0004|1000000009QPL| 22|篮球-羽毛球-乒乓球|13388889909||1kanchu0001|1000000009QPL| 22|篮球-羽毛球-乒乓球|13388889909|+-----------+-------------+----+------------------+-----------+
具体的代码模板大概就这些内容了,要根据实际的开发需求进行逻辑变更或配置变更.
本文转载自: https://blog.csdn.net/AnameJL/article/details/130366678
版权归原作者 飞天小老头 所有, 如有侵权,请联系我们删除。
版权归原作者 飞天小老头 所有, 如有侵权,请联系我们删除。