
文章目录
操作系统IP地址主机名主机名主机名CentOS 7.2.1511192.168.42.131node01jdk1.8.0_91scala-2.12.13CentOS 7.2.1511192.168.42.132node02jdk1.8.0_91scala-2.12.13CentOS 7.2.1511192.168.42.139node03jdk1.8.0_91scala-2.12.13安装的组件版本hadoop3.2.2hbase2.0.6hive3.1.2kafka2.11-2.0.0solr8.9.0atlas2.1.0spark3.0.3sqoop1.4.6flume1.9.0elasticsearch7.14.1kibana7.14.1
注:本文所需所有安装包请于我的资源下载(附带本文的PDF版文档):大数据各组件安装(数据中台搭建)所需安装包
一、基础环境配置(三台机器都操作)
1.修改主机名:
hostnamectl set-hostname node01
hostnamectl set-hostname node02
hostnamectl set-hostname node03
vim /etc/hosts
# 增加对应的内容:
192.168.42.131 node01
192.168.42.132 node02
192.168.42.139 node03
2.关闭防火墙:
systemctl stop firewalld.service
# 设置开机不启动:
systemctl disable firewalld.service
3.关闭Selinux:
vim /etc/selinux/config
# 修改如下配置项:
SELINUX=disabled
4.文件描述符配置:
Linux操作系统会对每个进程能打开的文件数进行限制(某用户下某进程),Hadoop生态系统的很多组件一般都会打开大量的文件,因此要调大相关参数(生产环境必须调大,学习环境稍微大点就可以)。检查文件描述符限制数,可以用如下命令检查当前用户下一个进程能打开的文件数:
ulimit -Sn
1024
ulimit -Hn
4096
建议的最大打开文件描述符数为10000或更多:
vim /etc/security/limits.conf
# 直接添加内容:* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
三台机器重启生效:reboot
5.自定义JDK安装:
5.1 删除默认openJDK:
删除所有机器上默认openJDK,注意这里是只写了一个。一些开发版的centos会自带jdk,我们一般用自己的jdk,把自带的删除。先看看有没有安装:
[root@node01 ~]# java -version
openjdk version "1.8.0_65"
OpenJDK Runtime Environment (build 1.8.0_65-b17)
OpenJDK 64-Bit Server VM (build 25.65-b01, mixed mode)
查找安装位置:
[root@node01 ~]# rpm -qa | grep java
java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64
javapackages-tools-3.4.1-11.el7.noarch
java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64
tzdata-java-2015g-1.el7.noarch
java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64
java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64
python-javapackages-3.4.1-11.el7.noarch
删除全部,noarch文件可以不用删除:
[root@node01 ~]# rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.65-3.b17.el7.x86_64[root@node01 ~]# rpm -e --nodeps java-1.8.0-openjdk-1.8.0.65-3.b17.el7.x86_64[root@node01 ~]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.91-2.6.2.3.el7.x86_64[root@node01 ~]# rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.91-2.6.2.3.el7.x86_64# 检查有没有删除:[root@node01 ~]# java -version-bash: /usr/bin/java: No such file or directory
5.2 安装jdk1.8.0_91:
mkdir /opt/java
tar -zxvf jdk-8u91-linux-x64.tar.gz -C /opt/java/
vim /etc/profile
export JAVA_HOME=/opt/java/jdk1.8.0_91
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
source /etc/profile
[root@node01 ~]# java -version
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
6.创建Hadoop用户:
adduser hadoop(密码123456)
[root@node01 ~]# passwd hadoop
Changing password for user hadoop.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.
7.配置SSH免密登录:
# 三台都做[hadoop@node01 ~]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:omdYd47S9iPHrABsycOTFaJc3xowcTOYokKtf0bAKZg root@node03
The key's randomart image is:
+---[RSA 2048]----+|..o B+= ||E+.Bo* = ||..=..+.||o.+ = o ||..%+ S .|| o X ++|| = = +o.|| o +..= ||.+..|+----[SHA256]-----+# 之后你会发现,在/root/.ssh目录下生成了公钥文件:[hadoop@node01 ~]# ll /root/.ssh
total 8
-rw-------. 1 root root 1679 Mar 24 06:47 id_rsa
-rw-r--r--. 1 root root 393 Mar 24 06:47 id_rsa.pub
ssh-copy-id node01
ssh-copy-id node02
ssh-copy-id node03
# 检查免密登录是否设置成功:
ssh node01
ssh node02
ssh node03
二、大数据组件安装
1.安装Zookeeper:
[hadoop@node01 ~]$ tar -zxvf /mnt/zookeeper-3.4.6.tar.gz -C .
将zookeeper-3.4.6/conf目录下面的 zoo_sample.cfg修改为zoo.cfg:
[hadoop@node01 ~]$ cd zookeeper-3.4.6/conf
[hadoop@node01 conf]$ mv zoo_sample.cfg zoo.cfg
[hadoop@node01 conf]$ vim zoo.cfg
# 添加:
dataDir=/home/hadoop/zookeeper-3.4.6/data
dataLogDir=/home/hadoop/zookeeper-3.4.6/log
server.1=192.168.42.131:2888:3888
server.2=192.168.42.132:2888:3888
server.3=192.168.42.133:2888:3888
# 注:2888端口号是zookeeper服务之间通信的端口,而3888是zookeeper与其他应用程序通信的端口
注意:原配置文件中已经有:
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
创建目录:
[hadoop@node01 conf]$ cd ..[hadoop@node01 zookeeper-3.4.6]$ mkdir -pv data log
拷贝给所有节点:
scp -r /home/hadoop/zookeeper-3.4.6 node02:/home/hadoop
scp -r /home/hadoop/zookeeper-3.4.6 node03:/home/hadoop
在节点1上设置myid为1,节点2上设置myid为2,节点3上设置myid为3:
[hadoop@node01 zookeeper-3.4.6]$ vim /home/hadoop/zookeeper-3.4.6/data/myid
1
[hadoop@node02 ~]$ vim /home/hadoop/zookeeper-3.4.6/data/myid
2
[hadoop@node03 ~]$ vim /home/hadoop/zookeeper-3.4.6/data/myid
3
所有节点都切换到root用户,/var 目录有其他用户写权限:
[root@node01 ~]# chmod 777 /var[root@node02 ~]# chmod 777 /var[root@node03 ~]# chmod 777 /var
启动:
[hadoop@node01 ~]$ cd zookeeper-3.4.6/bin/
[hadoop@node01 bin]$ ./zkServer.sh start
JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@node02 bin]$ ./zkServer.sh start[hadoop@node03 bin]$ ./zkServer.sh start
分别在3个节点上查看状态:
[hadoop@node01 bin]$ ./zkServer.sh status
JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
[hadoop@node02 bin]$ ./zkServer.sh status
JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader
[hadoop@node03 bin]$ ./zkServer.sh status
JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
[hadoop@node01 bin]$ jps
19219 QuorumPeerMain
19913 Jps
[hadoop@node02 bin]$ jps
20016 Jps
19292 QuorumPeerMain
[hadoop@node03 bin]$ jps
19195 QuorumPeerMain
19900 Jpsnode01
注:你会发现node01和node03是follower,node02是leader,你会有所疑问node03的myid不是最大他为什么不是leader呢?
zookeeper是两个两个比较,当node01和node02比较时node02的myid大就将node02选举为leader了,就不和后面的node03做比较了。。。
注意:在Centos和RedHat中一定要将防火墙和selinux关闭,否则在查看状态的时候会报这个错:
JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.6/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
2.安装Hadoop:
[hadoop@node01 ~]$ tar -zxvf /mnt/hadoop-3.2.2.tar.gz -C .
配置核心组件文件(core-site.xml):
[hadoop@node01 ~]$ vim hadoop-3.2.2/etc/hadoop/core-site.xml
#修改 etc/hadoop/core-site.xml 文件,增加以下配置(一开始的配置文件没有内容的!!!)
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-3.2.2/tmp</value>
</property>
</configuration>
配置文件系统(hdfs-site.xml):
[hadoop@node01 ~]$ vim hadoop-3.2.2/etc/hadoop/hdfs-site.xml
#修改 etc/hadoop/hdfs-site.xml 文件,增加以下配置
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/hadoop-3.2.2/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/hadoop-3.2.2/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
配置MapReduce计算框架文件:
[hadoop@node01 ~]$ vim hadoop-3.2.2/etc/hadoop/mapred-site.xml
#增加以下配置
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--
可以设置AM【AppMaster】端的环境变量
如果上面缺少配置,可能会造成mapreduce失败
-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
配置yarn-site.xml文件:
[hadoop@node01 ~]$ vim hadoop-3.2.2/etc/hadoop/yarn-site.xml
#增加以下配置
<configuration>
<!--集群master,-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 关闭内存检测,虚拟机需要,不配会报错-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
配置Hadoop环境变量:
[hadoop@node01 ~]$ vim hadoop-3.2.2/etc/hadoop/hadoop-env.sh
# 添加如下内容:
export JAVA_HOME=/opt/java/jdk1.8.0_91
【选】配置workers文件(hadoop3.x修改workers):
vim etc/hadoop/workers
node01
node02
node03
【选】配置slaves文件(hadoop2.x修改slaves):
vim etc/hadoop/slaves
node02
node03
复制node01上的Hadoop到node02和node03节点上:
[hadoop@node01 ~]$ scp -r hadoop-3.2.2/ node02:/home/hadoop/
[hadoop@node01 ~]$ scp -r hadoop-3.2.2/ node03:/home/hadoop/
配置操作系统环境变量(需要在所有节点上进行,且使用一般用户权限):
[hadoop@node01 ~]$ vim ~/.bash_profile
#以下是新添加入代码
export JAVA_HOME=/opt/java/jdk1.8.0_91
export PATH=$JAVA_HOME/bin:$PATH#hadoop
export HADOOP_HOME=/home/hadoop/hadoop-3.2.2
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH[hadoop@node02 ~]$ vim ~/.bash_profile
[hadoop@node03 ~]$ vim ~/.bash_profile
# 使配置文件生效(三台都执行):
source ~/.bash_profile
格式化文件系统(主节点进行):
[hadoop@node01 ~]$ cd hadoop-3.2.2/
[hadoop@node01 hadoop-3.2.2]$ ./bin/hdfs namenode -format
启动Hadoop:
[hadoop@node01 hadoop-3.2.2]$ ./sbin/start-all.sh
WARNING: Attempting to start all Apache Hadoop daemons as hadoop in 10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [node01]
Starting datanodes
node03: WARNING: /home/hadoop/hadoop-3.2.2/logs does not exist. Creating.
node02: WARNING: /home/hadoop/hadoop-3.2.2/logs does not exist. Creating.
Starting secondary namenodes [node01]
Starting resourcemanager
Starting nodemanagers
启动成功结果:
[hadoop@node01 hadoop-3.2.2]$ jps
24625 NodeManager
19219 QuorumPeerMain
23766 DataNode
25095 Jps
23547 NameNode
24092 SecondaryNameNode
24476 ResourceManager
[hadoop@node02 ~]$ jps
22196 DataNode
22394 NodeManager
22555 Jps
19292 QuorumPeerMain
[hadoop@node03 ~]$ jps
22242 NodeManager
19195 QuorumPeerMain
21775 DataNode
22399 Jps
访问
hdfs:http://192.168.42.131:9870/
(老版本的端口为50070)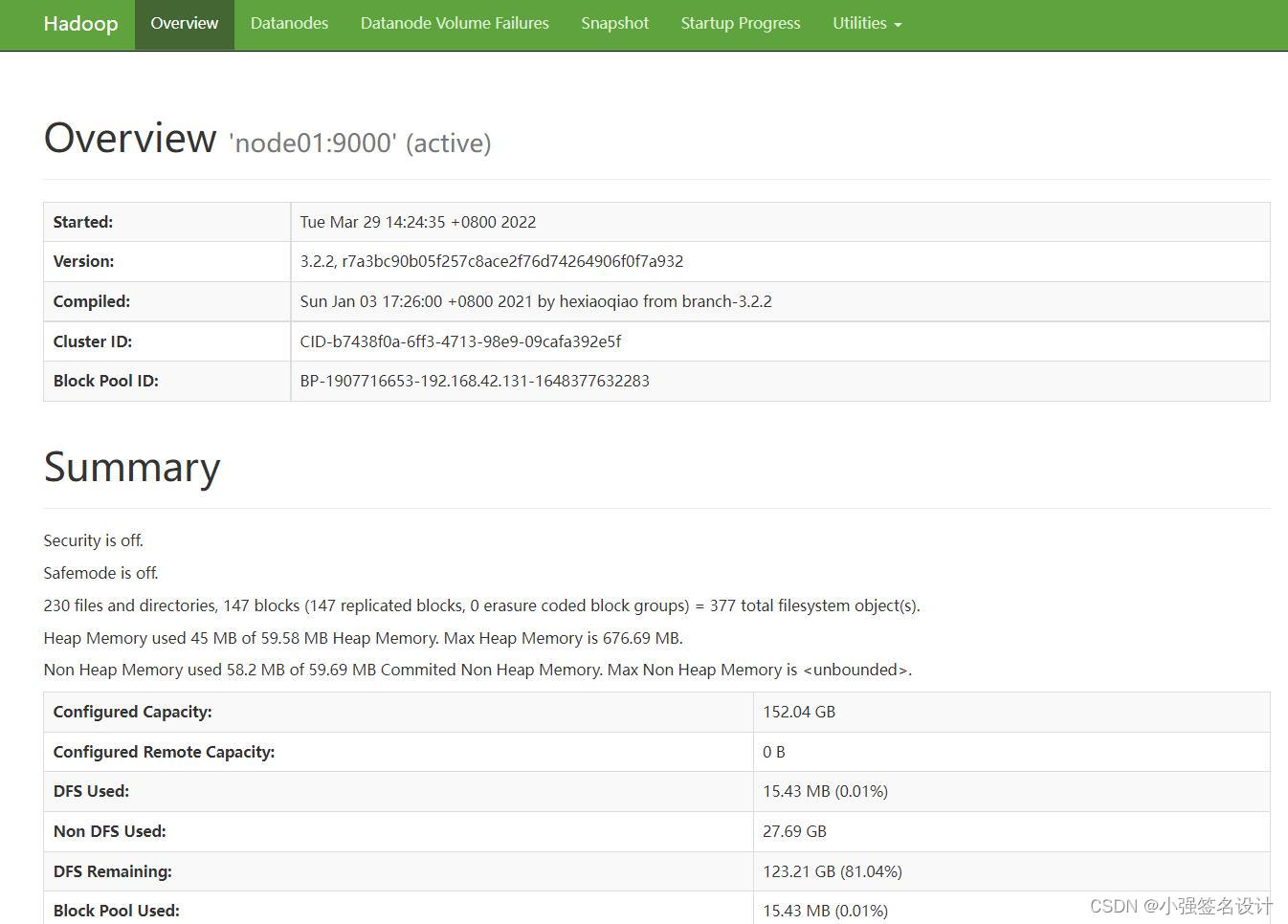
登录yarn界面:
http://192.168.42.131:8088/cluster
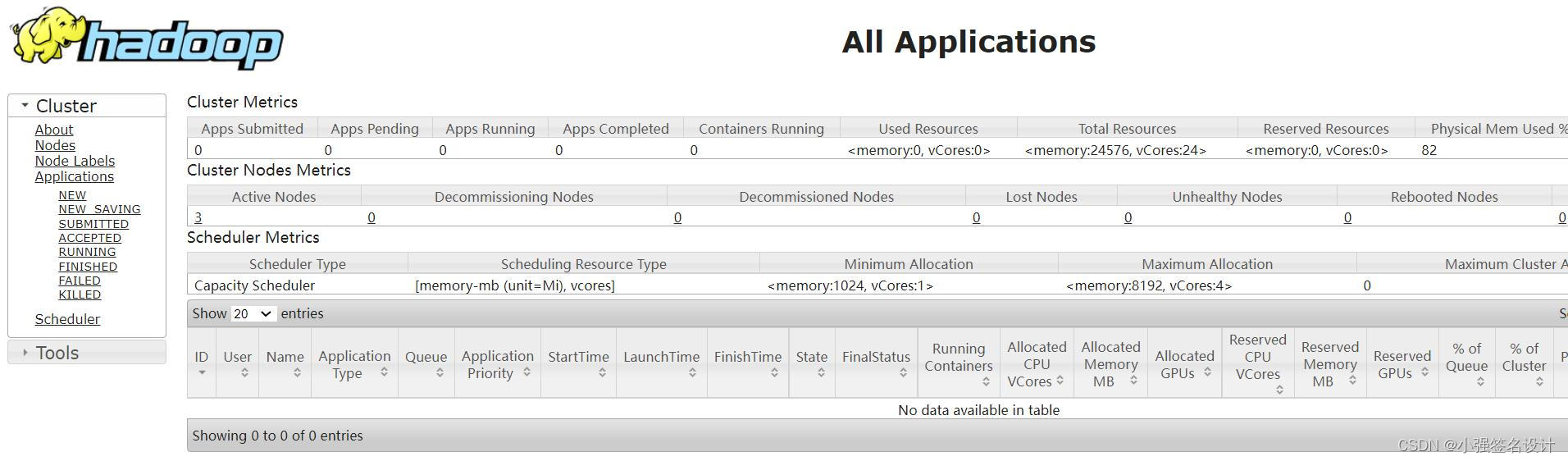
【最后测试】在Hadoop集群中运行程序,将计算圆周率pi的Java程序包投入运行:
[hadoop@node01 hadoop-3.2.2]$ cd share/hadoop/mapreduce/
[hadoop@node01 mapreduce]$ ll
total 5616
-rw-r--r-- 1 hadoop hadoop 624622 Jan 3 2021 hadoop-mapreduce-client-app-3.2.2.jar
-rw-r--r-- 1 hadoop hadoop 805829 Jan 3 2021 hadoop-mapreduce-client-common-3.2.2.jar
-rw-r--r-- 1 hadoop hadoop 1658800 Jan 3 2021 hadoop-mapreduce-client-core-3.2.2.jar
-rw-r--r-- 1 hadoop hadoop 217145 Jan 3 2021 hadoop-mapreduce-client-hs-3.2.2.jar
-rw-r--r-- 1 hadoop hadoop 45563 Jan 3 2021 hadoop-mapreduce-client-hs-plugins-3.2.2.jar
-rw-r--r-- 1 hadoop hadoop 85844 Jan 3 2021 hadoop-mapreduce-client-jobclient-3.2.2.jar
-rw-r--r-- 1 hadoop hadoop 1684779 Jan 3 2021 hadoop-mapreduce-client-jobclient-3.2.2-tests.jar
-rw-r--r-- 1 hadoop hadoop 126373 Jan 3 2021 hadoop-mapreduce-client-nativetask-3.2.2.jar
-rw-r--r-- 1 hadoop hadoop 97682 Jan 3 2021 hadoop-mapreduce-client-shuffle-3.2.2.jar
-rw-r--r-- 1 hadoop hadoop 57884 Jan 3 2021 hadoop-mapreduce-client-uploader-3.2.2.jar
-rw-r--r-- 1 hadoop hadoop 316483 Jan 3 2021 hadoop-mapreduce-examples-3.2.2.jar
drwxr-xr-x 2 hadoop hadoop 4096 Jan 3 2021 jdiff
drwxr-xr-x 2 hadoop hadoop 55 Jan 3 2021 lib
drwxr-xr-x 2 hadoop hadoop 29 Jan 3 2021 lib-examples
drwxr-xr-x 2 hadoop hadoop 4096 Jan 3 2021 sources
[hadoop@node01 mapreduce]$ hadoop jar hadoop-mapreduce-examples-3.2.2.jar pi 10 10
Number of Maps = 10
Samples per Map = 10
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
2022-03-27 04:21:32,464 INFO client.RMProxy: Connecting to ResourceManager at node01/192.168.42.131:8032
2022-03-27 04:21:33,368 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1648380068550_0001
2022-03-27 04:21:33,666 INFO input.FileInputFormat: Total input files to process : 10
2022-03-27 04:21:33,809 INFO mapreduce.JobSubmitter: number of splits:10
2022-03-27 04:21:34,146 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1648380068550_0001
2022-03-27 04:21:34,148 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-03-27 04:21:34,625 INFO conf.Configuration: resource-types.xml not found
2022-03-27 04:21:34,625 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-03-27 04:21:35,204 INFO impl.YarnClientImpl: Submitted application application_1648380068550_0001
2022-03-27 04:21:35,341 INFO mapreduce.Job: The url to track the job: http://node01:8088/proxy/application_1648380068550_0001/
2022-03-27 04:21:35,343 INFO mapreduce.Job: Running job: job_1648380068550_0001
2022-03-27 04:21:48,935 INFO mapreduce.Job: Job job_1648380068550_0001 running in uber mode : false
2022-03-27 04:21:48,936 INFO mapreduce.Job: map 0% reduce 0%
2022-03-27 04:22:18,394 INFO mapreduce.Job: map 30% reduce 0%
2022-03-27 04:22:19,423 INFO mapreduce.Job: map 40% reduce 0%
2022-03-27 04:22:29,728 INFO mapreduce.Job: map 60% reduce 0%
2022-03-27 04:22:30,747 INFO mapreduce.Job: map 80% reduce 0%
2022-03-27 04:22:31,754 INFO mapreduce.Job: map 100% reduce 0%
2022-03-27 04:22:33,777 INFO mapreduce.Job: map 100% reduce 100%
2022-03-27 04:22:33,791 INFO mapreduce.Job: Job job_1648380068550_0001 completed successfully
2022-03-27 04:22:33,915 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=226
FILE: Number of bytes written=2591281
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2620
HDFS: Number of bytes written=215
HDFS: Number of read operations=45
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=10
Launched reduce tasks=1
Data-local map tasks=10
Total time spent by all maps in occupied slots (ms)=337962
Total time spent by all reduces in occupied slots (ms)=11764
Total time spent by all map tasks (ms)=337962
Total time spent by all reduce tasks (ms)=11764
Total vcore-milliseconds taken by all map tasks=337962
Total vcore-milliseconds taken by all reduce tasks=11764
Total megabyte-milliseconds taken by all map tasks=346073088
Total megabyte-milliseconds taken by all reduce tasks=12046336
Map-Reduce Framework
Map input records=10
Map output records=20
Map output bytes=180
Map output materialized bytes=280
Input split bytes=1440
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=280
Reduce input records=20
Reduce output records=0
Spilled Records=40
Shuffled Maps =10
Failed Shuffles=0
Merged Map outputs=10
GC time elapsed (ms)=4553
CPU time spent (ms)=9450
Physical memory (bytes) snapshot=2082545664
Virtual memory (bytes) snapshot=30050701312
Total committed heap usage (bytes)=1440980992
Peak Map Physical memory (bytes)=212971520
Peak Map Virtual memory (bytes)=2733191168
Peak Reduce Physical memory (bytes)=106774528
Peak Reduce Virtual memory (bytes)=2741334016
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1180
File Output Format Counters
Bytes Written=97
Job Finished in 61.657 seconds
Estimated value of Pi is 3.20000000000000000000
注:可能会出现如下问题: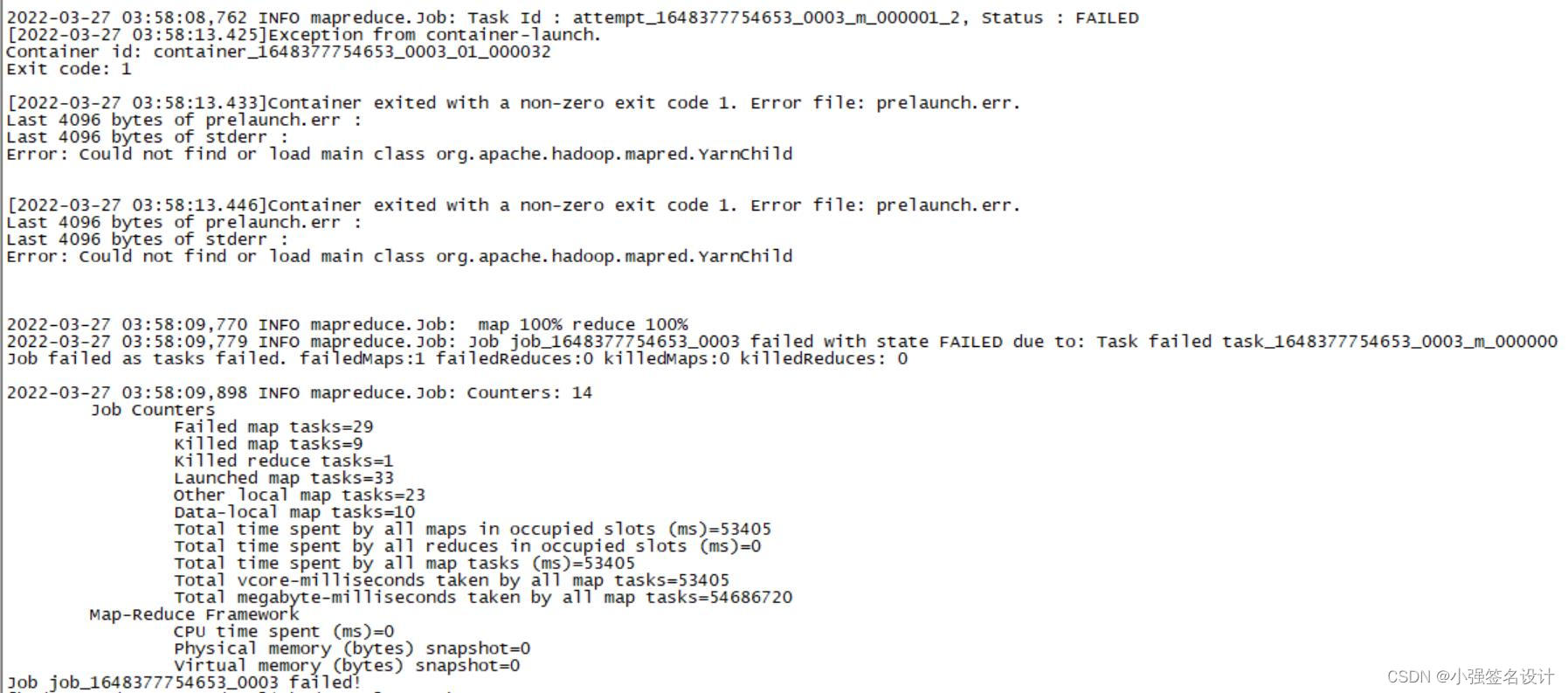
解决:在hadoop用户下执行hadoop classpath命令,我们可以得到运行 Hadoop 程序所需的全部 classpath 信息。再在yarn-site.xml中添加如下配置后(三台都添加)再重启Hadoop集群。
<property><name>yarn.application.classpath</name><value>/home/hadoop/hadoop-3.2.2/etc/hadoop:/home/hadoop/hadoop-3.2.2/share/hadoop/common/lib/*:/home/hadoop/hadoop-3.2.2/share/hadoop/common/*:/home/hadoop/hadoop-3.2.2/share/hadoop/hdfs:/home/hadoop/hadoop-3.2.2/share/hadoop/hdfs/lib/*:/home/hadoop/hadoop-3.2.2/share/hadoop/hdfs/*:/home/hadoop/hadoop-3.2.2/share/hadoop/mapreduce/lib/*:/home/hadoop/hadoop-3.2.2/share/hadoop/mapreduce/*:/home/hadoop/hadoop-3.2.2/share/hadoop/yarn:/home/hadoop/hadoop-3.2.2/share/hadoop/yarn/lib/*:/home/hadoop/hadoop-3.2.2/share/hadoop/yarn/*</value></property>
3.安装Hbase:
[hadoop@node01 ~]$ tar -zxvf /mnt/hbase-2.0.6-bin.tar.gz -C .[hadoop@node01 ~]$ cd hbase-2.0.6/
[hadoop@node01 hbase-2.0.6]$ vim conf/hbase-env.sh
# 添加
export JAVA_HOME=/opt/java/jdk1.8.0_91
export HBASE_HOME=/home/hadoop/hbase-2.0.6
export HBASE_CLASSPATH=/home/hadoop/hbase-2.0.6/lib/*#HBASE_MANAGES_ZK=false是不启用HBase自带的Zookeeper集群。
export HBASE_MANAGES_ZK=false
修改hbase-site.xml:
[hadoop@node01 hbase-2.0.6]$ vim conf/hbase-site.xml
# 添加
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://node01:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01,node02,node03</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/hbase-2.0.6/data</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/hadoop/hbase-2.0.6/tmp</value>
</property>
</configuration>
[hadoop@node01 hbase-2.0.6]$ vim conf/regionservers
node02
node03
# 拷贝给其他两个节点:[hadoop@node01 hbase-2.0.6]$ scp -r /home/hadoop/hbase-2.0.6/ node02:/home/hadoop/
[hadoop@node01 hbase-2.0.6]$ scp -r /home/hadoop/hbase-2.0.6/ node03:/home/hadoop/
[hadoop@node01 ~]$ vim ~/.bash_profile
# 三台添加如下配置
export HBASE_HOME=/home/hadoop/hbase-2.0.6
export PATH=$PATH:$HBASE_HOME/bin
# 三台生效
source ~/.bash_profile
启动:
[hadoop@node01 hbase-2.0.6]$ bin/start-hbase.sh
# 查看:[hadoop@node01 hbase-2.0.6]$ jps
44912 SecondaryNameNode
19219 QuorumPeerMain
47955 Jps
44596 DataNode
45428 NodeManager
45289 ResourceManager
47805 HMaster
44350 NameNode
[hadoop@node02 hbase-2.0.6]$ jps
30944 NodeManager
31875 HRegionServer
30728 DataNode
19292 QuorumPeerMain
32092 Jps
[hadoop@node03 hbase-2.0.6]$ jps
19195 QuorumPeerMain
31789 NodeManager
31534 DataNode
32975 Jps
访问hbase ui:
http://192.168.42.132:16030/rs-status
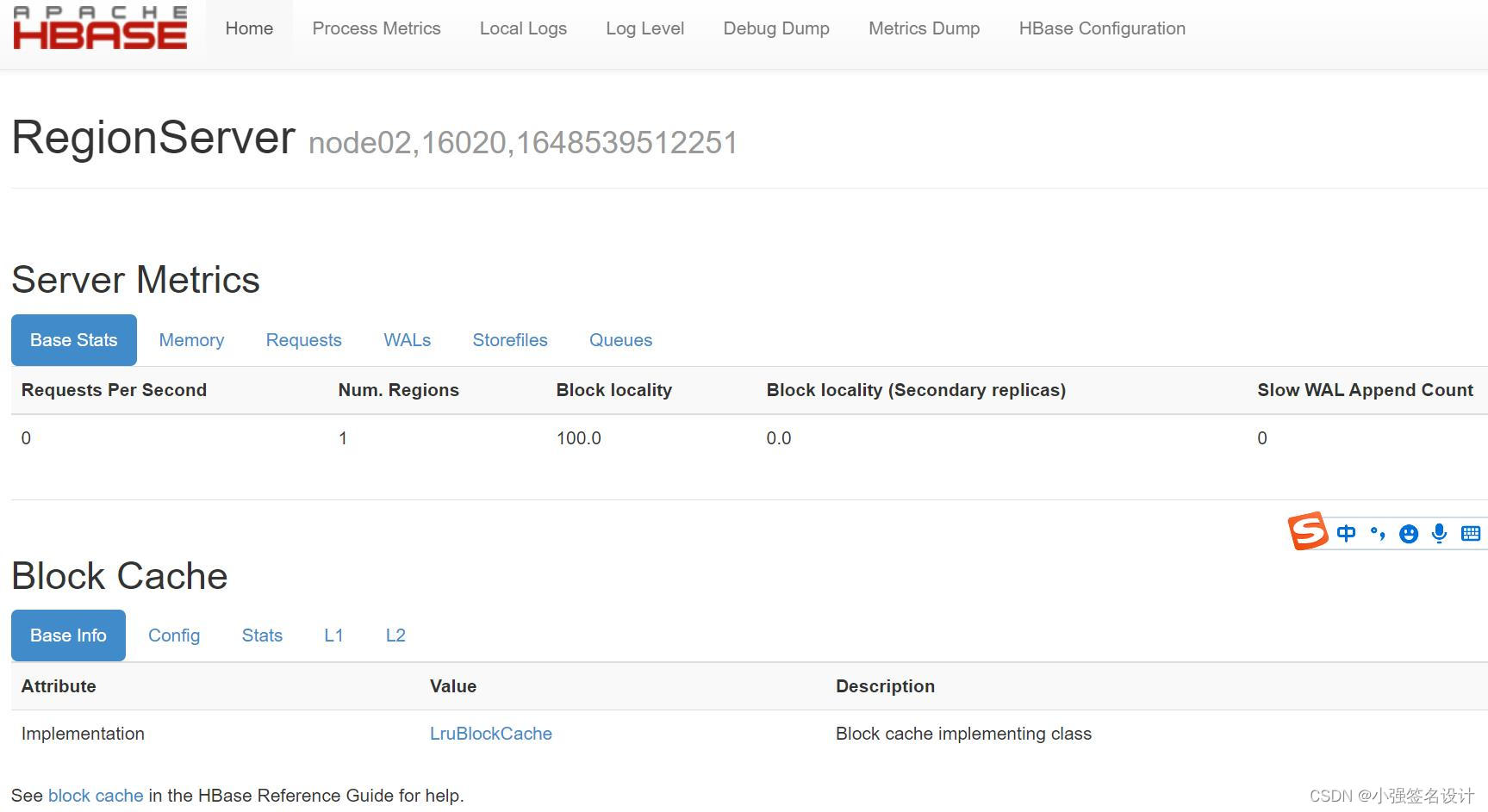
可能遇到的问题:HMaster进程一会就消失了。
[hadoop@node01 hbase-2.0.6]$ vim logs/hbase-hadoop-master-node01.log
2022-03-27 05:14:02,373 ERROR [Thread-14] master.HMaster: Failed to become active master
java.lang.IllegalStateException: The procedure WAL relies on the ability to hsync for proper operation during component failures, but the underlying filesystem does not support doing so. Please check the config value of 'hbase.procedure.store.wal.use.hsync' to set the desired level of robustness and ensure the config value of 'hbase.wal.dir' points to a FileSystem mount that can provide it.
at org.apache.hadoop.hbase.procedure2.store.wal.WALProcedureStore.rollWriter(WALProcedureStore.java:1083)
at org.apache.hadoop.hbase.procedure2.store.wal.WALProcedureStore.recoverLease(WALProcedureStore.java:421)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.init(ProcedureExecutor.java:611)
at org.apache.hadoop.hbase.master.HMaster.createProcedureExecutor(HMaster.java:1411)
at org.apache.hadoop.hbase.master.HMaster.finishActiveMasterInitialization(HMaster.java:855)
at org.apache.hadoop.hbase.master.HMaster.startActiveMasterManager(HMaster.java:2227)
at org.apache.hadoop.hbase.master.HMaster.lambda$run$0(HMaster.java:569)
at java.lang.Thread.run(Thread.java:745)
2022-03-27 05:14:02,377 ERROR [Thread-14] master.HMaster: ***** ABORTING master node01,16000,1648383233653: Unhandled exception. Starting shutdown.*****
java.lang.IllegalStateException: The procedure WAL relies on the ability to hsync for proper operation during component failures, but the underlying filesystem does not support doing so. Please check the config value of 'hbase.procedure.store.wal.use.hsync' to set the desired level of robustness and ensure the config value of 'hbase.wal.dir' points to a FileSystem mount that can provide it.
at org.apache.hadoop.hbase.procedure2.store.wal.WALProcedureStore.rollWriter(WALProcedureStore.java:1083)
at org.apache.hadoop.hbase.procedure2.store.wal.WALProcedureStore.recoverLease(WALProcedureStore.java:421)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.init(ProcedureExecutor.java:611)
at org.apache.hadoop.hbase.master.HMaster.createProcedureExecutor(HMaster.java:1411)
at org.apache.hadoop.hbase.master.HMaster.finishActiveMasterInitialization(HMaster.java:855)
at org.apache.hadoop.hbase.master.HMaster.startActiveMasterManager(HMaster.java:2227)
at org.apache.hadoop.hbase.master.HMaster.lambda$run$0(HMaster.java:569)
at java.lang.Thread.run(Thread.java:745)
解决:在hbase-site.xml中添加如下配置后重启hbase
# 这个属性主要作用是禁止检查流功能(stream capabilities)
<property><name>hbase.unsafe.stream.capability.enforce</name><value>false</value></property>
4.安装Hive:
4.1 安装MySQL:
卸载系统自带的 mariadb-lib:
[root@node01 ~]# rpm -qa|grep mariadb
mariadb-libs-5.5.44-2.el7.centos.x86_64
[root@node01 ~]# rpm -e --nodeps mariadb-libs-5.5.44-2.el7.centos.x86_64
将MySQL安装包上传并解压安装:
[root@node01 mnt]# tar xvf mysql-5.7.13-1.el7.x86_64.rpm-bundle.tar[root@node01 mnt]# rpm -ivh mysql-community-common-5.7.13-1.el7.x86_64.rpm[root@node01 mnt]# rpm -ivh mysql-community-libs-5.7.13-1.el7.x86_64.rpm[root@node01 mnt]# rpm -ivh mysql-community-client-5.7.13-1.el7.x86_64.rpm[root@node01 mnt]# rpm -ivh mysql-community-server-5.7.13-1.el7.x86_64.rpm
数据库初始化:
[root@node01 mnt]# mysqld --initialize --user=mysql# 查看临时root 临时密码:[root@node01 mnt]# grep 'temporary password' /var/log/mysqld.log
2022-03-24T14:00:51.393438Z 1 [Note] A temporary password is generated for root@localhost: O829rd-#M=)b
启动数据库:
[root@node01 mnt]# systemctl start mysqld[root@node01 mnt]# mysql -uroot -p
修改 root 密码:该密码被标记为过期了,如果想正常使用还需要修改密码
mysql> show databases;
ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement.# 以前的 password()函数将会被抛弃,官方建议使用下面的命令来修改密码:
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
Query OK, 0 rows affected (0.00 sec)
mysql> create user 'root'@'%' identified by '123456';
Query OK, 0 rows affected (0.00 sec)# 赋予权限,with grant option这个选项表示该用户可以将自己拥有的权限授权给别人
mysql> grant all privileges on *.* to 'root'@'%' with grant option;
Query OK, 0 rows affected (0.00 sec)# flush privileges 命令本质上的作用是将当前user和privilige表中的用户信息/权限设置从mysql库(MySQL数据库的内置库)中提取到内存里
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)# 创建hive用户
mysql> CREATE DATABASE hive;
Query OK, 1 row affected (0.00 sec)
mysql> use hive;
Database changed
mysql> CREATE USER 'hive'@'%' IDENTIFIED BY 'hive';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT ALL PRIVILEGES ON *.* TO 'hive'@'%';
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE USER 'hive'@'localhost' IDENTIFIED BY 'hive';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT ALL PRIVILEGES ON *.* TO 'hive'@'localhost';
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE USER 'hive'@'master' IDENTIFIED BY 'hive';
Query OK, 0 rows affected (0.00 sec)
mysql> GRANT ALL PRIVILEGES ON *.* TO 'hive'@'master';
Query OK, 0 rows affected (0.00 sec)
mysql> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
4.2 部署Hive:
修改Hive配置文件:
[hadoop@node01 apache-hive-3.1.2-bin]$ vim conf/hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration>
[hadoop@node01 apache-hive-3.1.2-bin]$ vim conf/hive-env.sh
export HADOOP_HOME=/home/hadoop/hadoop-3.2.2
export HIVE_CONF_DIR=/home/hadoop/apache-hive-3.1.2-bin/conf
[hadoop@node01 apache-hive-3.1.2-bin]$ cp/mnt/mysql-connector-java-5.1.31-bin.jar lib/
修改环境变量:三台机器都操作
vim ~/.bash_profile
# 添加如下内容
export HIVE_HOME=/home/hadoop/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin
source ~/.bash_profile
初始化数据库:
[hadoop@node01 apache-hive-3.1.2-bin]$ schematool -initSchema -dbType mysql
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/hadoop-3.2.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type[org.apache.logging.slf4j.Log4jLoggerFactory]
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357)
at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338)
at org.apache.hadoop.mapred.JobConf.setJar(JobConf.java:536)
at org.apache.hadoop.mapred.JobConf.setJarByClass(JobConf.java:554)
at org.apache.hadoop.mapred.JobConf.<init>(JobConf.java:448)
at org.apache.hadoop.hive.conf.HiveConf.initialize(HiveConf.java:5141)
at org.apache.hadoop.hive.conf.HiveConf.<init>(HiveConf.java:5104)
at org.apache.hive.beeline.HiveSchemaTool.<init>(HiveSchemaTool.java:96)
at org.apache.hive.beeline.HiveSchemaTool.main(HiveSchemaTool.java:1473)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:323)
at org.apache.hadoop.util.RunJar.main(RunJar.java:236)
错误原因:hive和hadoop的lib下面的guava.jar版本不一致造成的。
解决:保持都为高版本的。
[hadoop@node01 apache-hive-3.1.2-bin]$ cp../hadoop-3.2.2/share/hadoop/common/lib/guava-27.0-jre.jar lib/
rm lib/guava-19.0.jar
[hadoop@node01 apache-hive-3.1.2-bin]$ rm lib/guava-19.0.jar
[hadoop@node01 apache-hive-3.1.2-bin]$ schematool -initSchema -dbType mysql
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/hadoop-3.2.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type[org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 3.1.0
Initialization script hive-schema-3.1.0.mysql.sql
Initialization script completed
schemaTool completed
使用hive:
[hadoop@node01 apache-hive-3.1.2-bin]$ hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/hbase-2.0.6/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/hadoop-3.2.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type[org.slf4j.impl.Log4jLoggerFactory]
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apache-hive-3.1.2-bin/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/hadoop-3.2.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type[org.apache.logging.slf4j.Log4jLoggerFactory]
Hive Session ID = 7b7e0171-f19f-4a73-b824-e968c2bdd78b
Logging initialized using configuration in jar:file:/home/hadoop/apache-hive-3.1.2-bin/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Hive Session ID = 164c3935-2ff0-45fa-acfa-d4e3d6eb3ec5
hive> show databases;
OK
default
Time taken: 1.634 seconds, Fetched: 1 row(s)
5.安装kafka:
[hadoop@node01 ~]$ tar -zxvf /mnt/kafka_2.11-2.0.0.tgz -C .[hadoop@node01 ~]$ vim kafka_2.11-2.0.0/config/server.properties
# 修改如下配置为
zookeeper.connect=192.168.42.131:2181,192.168.42.132:2181,192.168.42.139:2181
拷贝给其他两个节点:
[hadoop@node01 ~]$ scp -r kafka_2.11-2.0.0/ node02:/home/hadoop/
[hadoop@node01 ~]$ scp -r kafka_2.11-2.0.0/ node03:/home/hadoop/
其他两个节点修改broker.id的值:
[hadoop@node02 ~]$ vim kafka_2.11-2.0.0/config/server.properties
broker.id=1
[hadoop@node03 ~]$ vim kafka_2.11-2.0.0/config/server.properties
broker.id=2
[hadoop@node01 ~]$ vim ~/.bash_profile
# 三台添加如下配置
export KAFKA_HOME=/home/hadoop/kafka_2.11-2.0.0
export PATH=$PATH:$KAFKA_HOME/bin
# 三台生效
source ~/.bash_profile
三台kafka都要后台启动服务:
[hadoop@node01 ~]$ nohup kafka_2.11-2.0.0/bin/kafka-server-start.sh kafka_2.11-2.0.0/config/server.properties &
[hadoop@node02 ~]$ nohup kafka_2.11-2.0.0/bin/kafka-server-start.sh kafka_2.11-2.0.0/config/server.properties &
[hadoop@node03 ~]$ nohup kafka_2.11-2.0.0/bin/kafka-server-start.sh kafka_2.11-2.0.0/config/server.properties &
查看kafka服务是否启动正常:
[hadoop@node01 ~]$ jps
19219 QuorumPeerMain
88418 SecondaryNameNode
92549 Kafka
88820 ResourceManager
91364 HMaster
87786 NameNode
92877 Jps
88031 DataNode
88974 NodeManager
[hadoop@node02 ~]$ jps
39504 NodeManager
40327 HRegionServer
40872 Kafka
19292 QuorumPeerMain
41228 Jps
39390 DataNode
[hadoop@node03 ~]$ jps
39937 DataNode
40051 NodeManager
41687 Jps
40889 HRegionServer
19195 QuorumPeerMain
41391 Kafka
测试:
[hadoop@node03 ~]$ cd kafka_2.11-2.0.0/bin/
[hadoop@node03 bin]$ kafka-topics.sh --list --zookeeper node01:2181,node02:2181,node03:2181
[hadoop@node03 bin]$ kafka-topics.sh --zookeeper node01:2181,node02:2181,node03:2181 --create --topic huiq --replication-factor 3 --partitions 3
artitions 3
Created topic "huiq".[hadoop@node03 bin]$ kafka-topics.sh --list --zookeeper node01:2181,node02:2181,node03:2181
huiq
6.安装Solr:
[hadoop@node01 ~]$ tar -zxvf /mnt/solr-8.9.0.tgz -C .[hadoop@node01 ~]$ vim solr-8.9.0/bin/solr.in.sh
#添加下列指令
ZK_HOST="node01:2181,node02:2181,node03:2181"
SOLR_HOST="node01"
SOLR_HOME=/home/hadoop/solr-8.9.0/server/solr
#可修改端口号
SOLR_PORT=8983
分发Solr,进行Cloud模式部署:
[hadoop@node01 ~]$ scp -r /home/hadoop/solr-8.9.0/ node02:/home/hadoop
[hadoop@node01 ~]$ scp -r /home/hadoop/solr-8.9.0/ node03:/home/hadoop
分发完成后,分别对node02、node02主机的solr.in.sh文件,修改为SOLR_HOST=对应主机名:
[hadoop@node02 ~]$ vim solr-8.9.0/bin/solr.in.sh
# 修改如下配置
SOLR_HOST="node02"[hadoop@node03 ~]$ vim solr-8.9.0/bin/solr.in.sh
SOLR_HOST="node03"
三台修改环境变量:
[hadoop@node01 ~]$ vim ~/.bash_profile
export SOLR_HOME=/home/hadoop/solr-8.9.0
export PATH=$PATH:$SOLR_HOME/bin
# 生效:
source ~/.bash_profile
在三台节点上分别启动Solr,这个就是Cloud模式:
[hadoop@node01 ~]$ solr-8.9.0/bin/solr start-force
[hadoop@node02 ~]$ solr-8.9.0/bin/solr start-force
[hadoop@node03 ~]$ solr-8.9.0/bin/solr start-force
注意:启动Solr前,需要提前启动Zookeeper服务。
Web访问8983端口,可指定三台节点中的任意一台IP
http://192.168.42.131:8983/
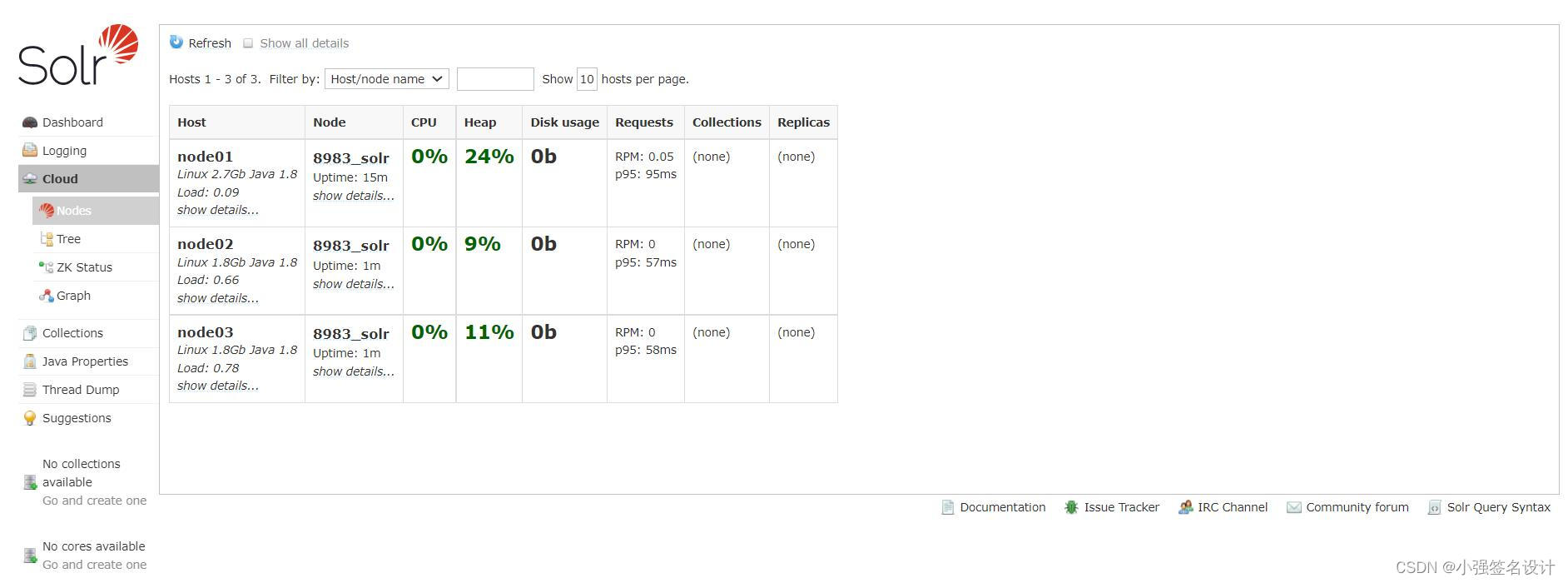
7.安装Atlas:
[hadoop@node01 ~]$ tar -zxvf /mnt/apache-atlas-2.1.0-bin.tar.gz -C .
7.1 集成 Hbase:
[hadoop@node01 ~]$ vim apache-atlas-2.1.0/conf/atlas-application.properties
# 修改atlas存储数据主机,zookeeper地址
atlas.graph.storage.hostname=node01:2181,node02:2181,node03:2181
添加Hbase集群的配置文件到atlas下:
[hadoop@node01 ~]$ ln -s /home/hadoop/hbase-2.0.6/conf/ apache-atlas-2.1.0/conf/hbase/
[hadoop@node01 ~]$ ll apache-atlas-2.1.0/conf/hbase/
total 4
lrwxrwxrwx 1 hadoop hadoop 30 Mar 29 00:42 conf -> /home/hadoop/hbase-2.0.6/conf/
-rw-r--r-- 1 hadoop hadoop 1507 Mar 28 20:28 hbase-site.xml.template
在atlas-env.sh中添加HBASE_CONF_DIR:
[hadoop@node01 ~]$ vim apache-atlas-2.1.0/conf/atlas-env.sh
# 添加HBase配置文件路径
export HBASE_CONF_DIR=/home/hadoop/hbase-2.0.6/conf
7.2 集成 Solr:
[hadoop@node01 ~]$ vim apache-atlas-2.1.0/conf/atlas-application.properties
# 修改如下配置,zookeeper地址
atlas.graph.index.search.solr.zookeeper-url=node01:2181,node02:2181,node03:2181
将Atlas自带的Solr文件夹拷贝到外部Solr集群的各个节点(solr三台机器都需要拷贝):
[hadoop@node01 ~]$ cp-r apache-atlas-2.1.0/conf/solr/ solr-8.9.0/
[hadoop@node01 ~]$ scp -r apache-atlas-2.1.0/conf/solr/ node02:/home/hadoop/solr-8.9.0/
[hadoop@node01 ~]$ scp -r apache-atlas-2.1.0/conf/solr/ node03:/home/hadoop/solr-8.9.0/
修改拷贝过来的文件夹solr修改为atlas_conf:
[hadoop@node01 ~]$ mv solr-8.9.0/solr solr-8.9.0/atlas_conf
[hadoop@node02 ~]$ mv solr-8.9.0/solr solr-8.9.0/atlas_conf
[hadoop@node03 ~]$ mv solr-8.9.0/solr solr-8.9.0/atlas_conf
在Cloud模式下,启动Solr(需要提前启动Zookeeper集群),并创建collection(只需要在其中一台机器上运行即可):
[hadoop@node01 ~]$ solr create -c vertex_index -d solr-8.9.0/atlas_conf -shards 3 -replicationFactor 2 -force
Created collection 'vertex_index' with 3 shard(s), 2 replica(s) with config-set'vertex_index'[hadoop@node01 ~]$ solr create -c edge_index -d solr-8.9.0/atlas_conf -shards 3 -replicationFactor 2 -force
Created collection 'edge_index' with 3 shard(s), 2 replica(s) with config-set'edge_index'[hadoop@node01 ~]$ solr create -c fulltext_index -d solr-8.9.0/atlas_conf -shards 3 -replicationFactor 2 -force
Created collection 'fulltext_index' with 3 shard(s), 2 replica(s) with config-set'fulltext_index'
- -shards 3:表示该集合分片数为3
- -replicationFactor 2:表示每个分片数都有2个备份
- vertex_index、edge_index、fulltext_index:表示集合名称
注意:如果需要删除vertex_index、edge_index、fulltext_index等collection可以执行如下命令
solr delete -c ${collection_name}
验证创建collection成功:
登录solr web控制台:
http://192.168.42.131:8983/solr/#/~cloud
看到如下图显示: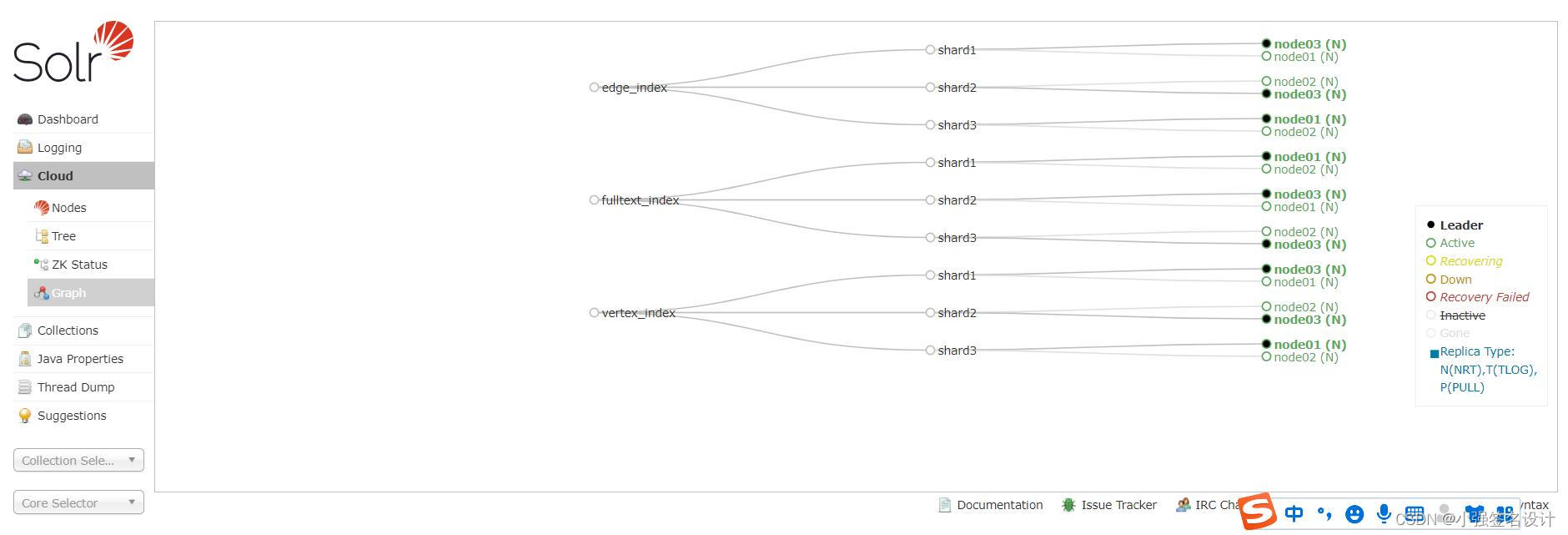
7.3 集成 Kafka:
[hadoop@node01 ~]$ vim apache-atlas-2.1.0/conf/atlas-application.properties
# 修改配置为# 如果要使用外部的kafka,则改为false
atlas.notification.embedded=false
atlas.kafka.data=/home/hadoop/apache-atlas-2.1.0/data/kafka
atlas.kafka.zookeeper.connect=node01:2181,node02:2181,node03:2181
atlas.kafka.bootstrap.servers=node01:9092,node02:9092,node03:9092
atlas.kafka.zookeeper.session.timeout.ms=4000
atlas.kafka.zookeeper.connection.timeout.ms=2000
atlas.kafka.enable.auto.commit=true
创建Topic:
[hadoop@node01 ~]$ kafka-topics.sh --zookeeper node01:2181,node02:2181,node03:2181 --create --topic _HOATLASOK --replication-factor 3 --partitions 3
[hadoop@node01 ~]$ kafka-topics.sh --zookeeper node01:2181,node02:2181,node03:2181 --create --topic ATLAS_ENTITIES --replication-factor 3 --partitions 3
7.4 集成 Hive:
[hadoop@node01 ~]$ vim apache-atlas-2.1.0/conf/atlas-application.properties
# 添加如下配置
atlas.hook.hive.synchronous=false
atlas.hook.hive.numRetries=3
atlas.hook.hive.queueSize=10000
atlas.cluster.name=primary
将atlas-application.properties配置文件加入到atlas-plugin-classloader-2.0.0.jar中(只需要在node01执行即可,会将node01的atlas安装包拷贝到hive所在每一台服务器):
[hadoop@node01 ~]$ zip -u apache-atlas-2.1.0/hook/hive/atlas-plugin-classloader-2.1.0.jar apache-atlas-2.1.0/conf/atlas-application.properties
adding: apache-atlas-2.1.0/conf/atlas-application.properties (deflated 66%)[hadoop@node01 ~]$ cp apache-atlas-2.1.0/conf/atlas-application.properties apache-hive-3.1.2-bin/conf/
原因:这个配置不能参照官网,将配置文件考到hive的conf中。参考官网的做法一直读取不到atlas-application.properties配置文件,看了源码发现是在classpath读取的这个配置文件,所以将它压到jar里面。
在hive-site.xml 文件中设置 Atlas hook:
[hadoop@node01 ~]$ vim apache-hive-3.1.2-bin/conf/hive-site.xml
# 添加如下配置
<property>
<name>hive.exec.post.hooks</name>
<value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
修改hive-env.sh:
[hadoop@node01 ~]$ vim apache-hive-3.1.2-bin/conf/hive-env.sh
# 添加如下配置
export HIVE_AUX_JARS_PATH=/home/hadoop/apache-atlas-2.1.0/hook/hive
7.5 Atlas HA:
[hadoop@node01 ~]$ vim apache-atlas-2.1.0/conf/atlas-application.properties
# 修改如下配置
atlas.rest.address=http://node01:21000
atlas.server.ha.enabled=true
atlas.server.ids=id1,id2
atlas.server.address.id1=node01:21000
atlas.server.address.id2=node02:21000
atlas.server.ha.zookeeper.connect=node01:2181,node02:2181,node03:2181
Atlas其他配置:
[hadoop@node01 ~]$ vim apache-atlas-2.1.0/conf/atlas-application.properties
atlas.server.run.setup.on.start=false
atlas.audit.hbase.zookeeper.quorum=node01:2181,node02:2181,node03:2181
记录性能指标,进入 conf 路径,修改当前目录下的 atlas-log4j.xml,去掉如下代码的注释:
[hadoop@node01 ~]$ vim apache-atlas-2.1.0/conf/atlas-log4j.xml
<appender name="perf_appender"class="org.apache.log4j.DailyRollingFileAppender">
<param name="file" value="${atlas.log.dir}/atlas_perf.log"/>
<param name="datePattern" value="'.'yyyy-MM-dd"/>
<param name="append" value="true"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d|%t|%m%n"/>
</layout>
</appender>
<logger name="org.apache.atlas.perf" additivity="false">
<level value="debug"/>
<appender-ref ref="perf_appender"/>
</logger>
修改完配置文件后,将node01的配置文件拷贝给node02,修改配置文件中的主机atlas.rest.address= http://node02:21000,分别启动atlas:
[hadoop@node01 ~]$ scp -r apache-atlas-2.1.0/ node02:/home/hadoop/
[hadoop@node02 ~]$ vim apache-atlas-2.1.0/conf/atlas-application.properties
# 修改配置为
atlas.rest.address=http://node02:21000
[hadoop@node01 ~]$ python2.7 apache-atlas-2.1.0/bin/atlas_start.py
starting atlas on host localhost
starting atlas on port 21000
............................................................................................................
Apache Atlas Server started!!![hadoop@node02 ~]$ python2.7 apache-atlas-2.1.0/bin/atlas_start.py
查看相应进程:
[hadoop@node01 ~]$ jps
24964 ResourceManager
24520 DataNode
26057 QuorumPeerMain
38345 Jps
30346 HMaster
24396 NameNode
24716 SecondaryNameNode
31102 Kafka
25087 NodeManager
37983 Atlas
[hadoop@node02 ~]$ jps
18547 Kafka
21287 Atlas
18184 HRegionServer
16489 QuorumPeerMain
15963 NodeManager
15837 DataNode
21517 Jps
查看atlas HA状态:
[hadoop@node01 ~]$ apache-atlas-2.1.0/bin/atlas_admin.py -status
Invalid credentials. Format: <user>:<password>
Enter username for atlas :- admin
Enter password for atlas :-
ACTIVE
[hadoop@node02 ~]$ apache-atlas-2.1.0/bin/atlas_admin.py -status
Invalid credentials. Format: <user>:<password>
Enter username for atlas :- admin
Enter password for atlas :-
PASSIVE
# 注:在正常操作情况下,这些实例中只有一个应该打印值ACTIVE作为对脚本的响应,而其他实例将打印PASSIVE。
- ACTIVE:此实例处于活动状态,可以响应用户请求。
- PASSIVE:这个实例是被动的。它会将收到的任何用户请求重定向到当前活动实例。
- BECOMING_ACTIVE:如果服务器正在转换为ACTIVE实例,则会打印出来。服务器无法在此状态下为任何元数据用户请求提供服务。
- BECOMING_PASSIVE:如果服务器正在转换为PASSIVE实例,则会打印出来。服务器无法在此状态下为任何元数据用户请求提供服务。
访问atlas:等待时间大概2分钟,
http://192.168.42.131:21000/
,账户:admin,密码:admin
8.安装Spark:
8.1 安装 Scala:
spark依赖scala,所以需要先安装scala。
scala安装(三台机器都装),这里以2.12.13为例:
[root@node01 ~]# tar -zxvf /mnt/scala-2.12.13.tgz -C /opt
设置环境变量:
[hadoop@node01 ~]$ vim ~/.bash_profile
export SCALA_HOME=/opt/scala-2.12.13
export PATH=.:$SCALA_HOME/bin:$PATH[hadoop@node01 ~]$ source ~/.bash_profile
检验配置是否成功:
[hadoop@node01 ~]$ scala -version
Scala code runner version 2.12.13 -- Copyright 2002-2020, LAMP/EPFL and Lightbend, Inc.
8.2 部署 Spark:
[hadoop@node01 ~]$ tar -zxvf /mnt/spark-3.0.3-bin-hadoop3.2.tgz -C .
修改spark-env.sh:
[hadoop@node01 ~]$ cd spark-3.0.3-bin-hadoop3.2/conf/
[hadoop@node01 conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@node01 conf]$ vim spark-env.sh
# 添加
export JAVA_HOME=/opt/java/jdk1.8.0_91/
export SPARK_MASTER_IP=node01
export SPARK_MASTER_PORT=7077
配置spark on yarn:
export HADOOP_CONF_DIR=/home/hadoop/hadoop-3.2.2/etc/hadoop
export YARN_CONF_DIR=/home/hadoop/hadoop-3.2.2/etc/hadoop
编辑slaves文件:
[hadoop@node01 conf]$ vim slaves
node02
node03
同步到其他两个节点:
[hadoop@node01 ~]$ scp -r spark-3.0.3-bin-hadoop3.2/ node02:/home/hadoop/
[hadoop@node01 ~]$ scp -r spark-3.0.3-bin-hadoop3.2/ node03:/home/hadoop/
修改环境变量(三台机器都操作):
[hadoop@node01 ~]$ vim ~/.bash_profile
export SPARK_HOME=/home/hadoop/spark-3.0.3-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin
[hadoop@node01 ~]$ source ~/.bash_profile
启动:
[hadoop@node01 ~]$ spark-3.0.3-bin-hadoop3.2/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/hadoop/spark-3.0.3-bin-hadoop3.2/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-node01.out
node03: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-3.0.3-bin-hadoop3.2/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node03.out
node02: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-3.0.3-bin-hadoop3.2/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-node02.out
[hadoop@node01 ~]$ jps
55617 Jps
24964 ResourceManager
55542 Master
24520 DataNode
26057 QuorumPeerMain
39291 HMaster
24396 NameNode
24716 SecondaryNameNode
31102 Kafka
43774 Atlas
25087 NodeManager
[hadoop@node02 ~]$ jps
18547 Kafka
28918 Worker
16489 QuorumPeerMain
22010 HRegionServer
15963 NodeManager
23404 Atlas
15837 DataNode
28974 Jps
[hadoop@node03 ~]$ jps
19252 NodeManager
19126 DataNode
24966 HRegionServer
31718 Worker
19768 QuorumPeerMain
21835 Kafka
31774 Jps
访问web页面,查看集群情况
http://192.168.42.131:8080/
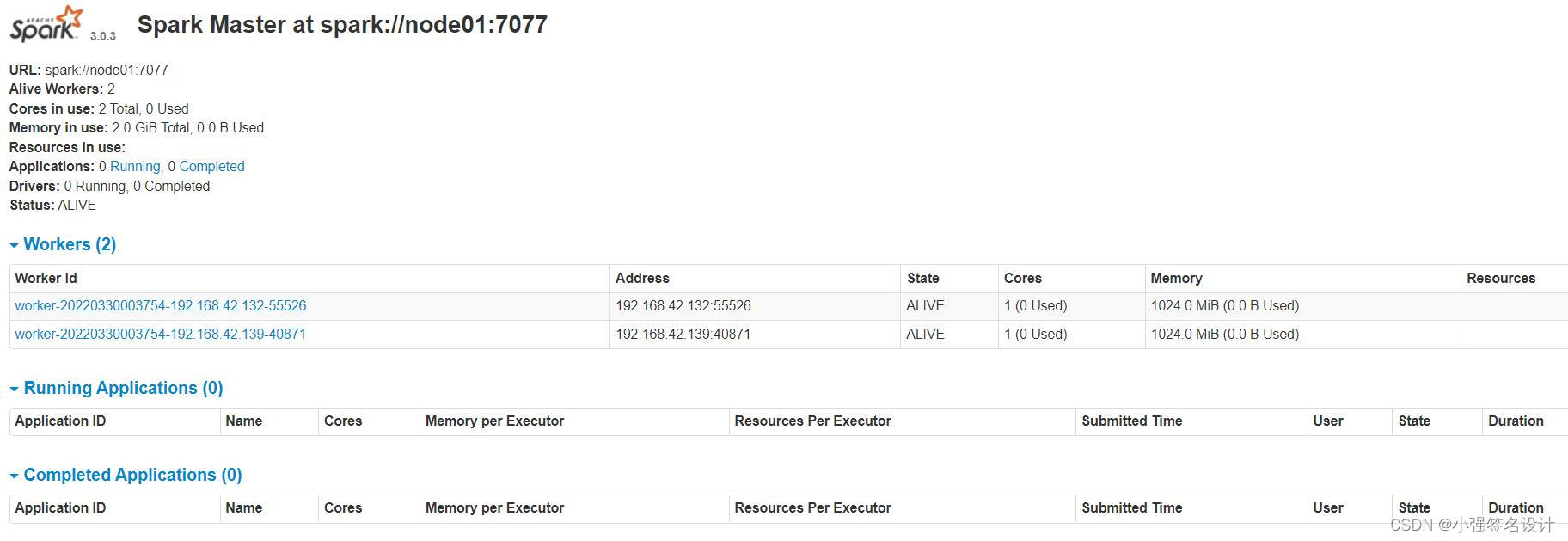
测试:提交到Yarn的cluster模式
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
/home/hadoop/spark-3.0.3-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.0.3.jar 3
执行完后可以去yarn的页面查看任务情况:
http://192.168.42.131:8088/cluster
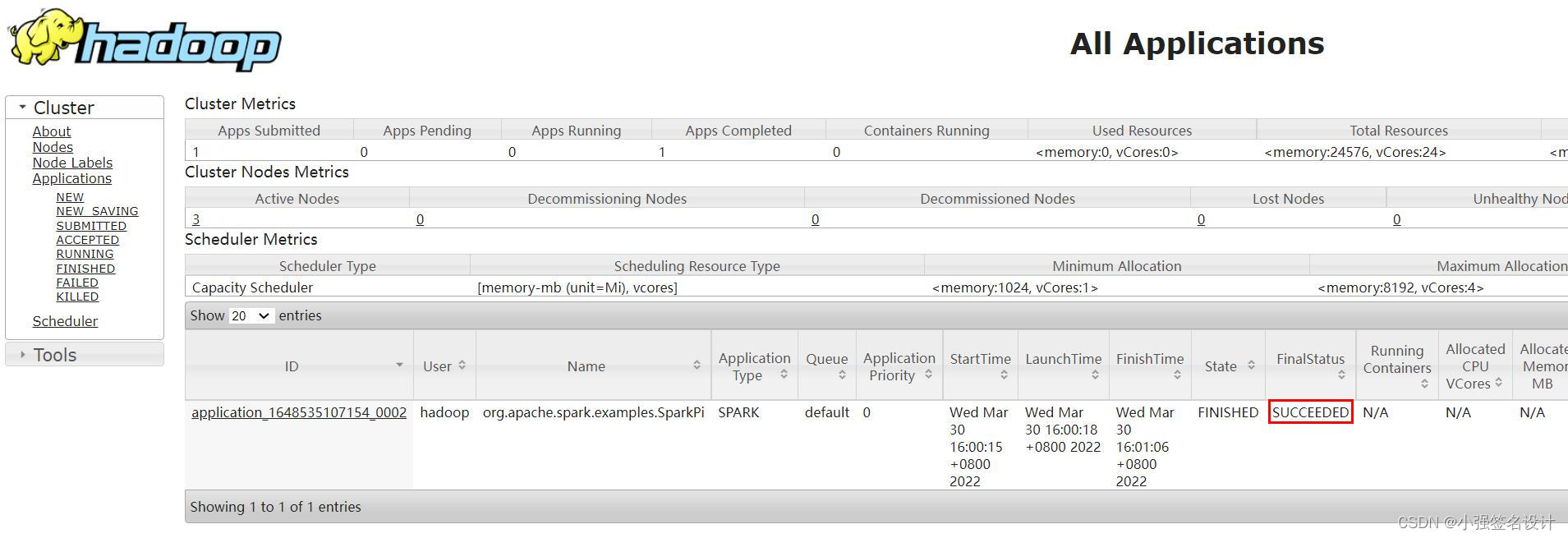
9.安装Sqoop:
[hadoop@node01 ~]$ tar -zxvf /mnt/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C .
修改环境变量:
[hadoop@node01 ~]$ vim ~/.bash_profile
export SQOOP_HOME=/home/hadoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
export PATH=$PATH:$SQOOP_HOME/bin
[hadoop@node01 ~]$ source ~/.bash_profile
修改configure-sqoop文件:
[hadoop@node01 ~]$ vim sqoop-1.4.6.bin__hadoop-2.0.4-alpha/bin/configure-sqoop
# 注释掉hbase和zookeeper检查## Moved to be a runtime check in sqoop.#if [ ! -d "${HBASE_HOME}" ]; then# echo "Warning: $HBASE_HOME does not exist! HBase imports will fail."# echo 'Please set $HBASE_HOME to the root of your HBase installation.'#fi
将mysql的连接驱动移到sqoop里面lib目录下:
[hadoop@node01 ~]$ cp/mnt/mysql-connector-java-5.1.31-bin.jar sqoop-1.4.6.bin__hadoop-2.0.4-alpha/lib/
在MySQL中创建测试数据:
mysql> create database test;
Query OK, 1 row affected (0.01 sec)
mysql> use test;
Database changed
mysql> create table students (id int not null primary key,name varchar(20),age int);
Query OK, 0 rows affected (0.03 sec)
mysql> insert into students values('1001','zhangsan',18);
Query OK, 1 row affected (0.06 sec)
mysql> insert into students values('1002','lisi',27);
Query OK, 1 row affected (0.00 sec)
mysql> insert into students values('1003','wangwu',36);
Query OK, 1 row affected (0.00 sec)
测试sqoop能否连接上mysql:
[hadoop@node01 ~]$ sqoop list-tables --connect jdbc:mysql://192.168.42.131:3306/test --username root --password 123456
Warning: /home/hadoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/../hcatalog does not exist! HCatalog jobs will fail.
Please set$HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/../accumulo does not exist! Accumulo imports will fail.
Please set$ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /home/hadoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha/../zookeeper does not exist! Accumulo imports will fail.
Please set$ZOOKEEPER_HOME to the root of your Zookeeper installation.
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/hadoop-3.2.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/hbase-2.0.6/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type[org.slf4j.impl.Log4jLoggerFactory]
2022-03-30 14:47:49,232 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
2022-03-30 14:47:49,349 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using-P instead.
2022-03-30 14:47:49,580 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
students
将mysql里面的表导入到hdfs里面:
[hadoop@node01 ~]$ sqoop import --connect jdbc:mysql://192.168.42.131:3306/test --username root --password 123456 --table students -m 1
[hadoop@node01 ~]$ hadoop fs -ls/user/hadoop/students
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2022-03-30 14:36 /user/hadoop/students/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 45 2022-03-30 14:36 /user/hadoop/students/part-m-00000
[hadoop@node01 ~]$ hadoop fs -cat/user/hadoop/students/part-m-00000
1001,zhangsan,18
1002,lisi,27
1003,wangwu,36
10.安装Flume:
[hadoop@node01 ~]$ tar -zxvf /mnt/apache-flume-1.9.0-bin.tar.gz -C .
修改环境变量:
[hadoop@node01 ~]$ vim ~/.bash_profile
export FLUME_HOME=/home/hadoop/apache-flume-1.9.0-bin
export PATH=$PATH:$FLUME_HOME/bin
[hadoop@node01 ~]$ source ~/.bash_profile
编辑flume-env.sh文件:
[hadoop@node01 ~]$ cp apache-flume-1.9.0-bin/conf/flume-env.sh.template apache-flume-1.9.0-bin/conf/flume-env.sh
[hadoop@node01 ~]$ vim apache-flume-1.9.0-bin/conf/flume-env.sh
# 添加如下配置
export JAVA_HOME=/opt/java/jdk1.8.0_91
验证是否成功:
[hadoop@node01 ~]$ apache-flume-1.9.0-bin/bin/flume-ng version
Error: Could not find or load main class org.apache.flume.tools.GetJavaProperty
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9
往hbase中导入数据:
将Hbase下lib目录中的jar包复制到flume的lib目录下:
[hadoop@node01 ~]$ cp hbase-2.0.6/lib/*.jar apache-flume-1.9.0-bin/lib/
确保test_idoall_org表在hbase中已经存在:
hbase(main):002:0> create 'test_idoall_org','uid','name'
0 row(s) in 0.6730 seconds
=> Hbase::Table - test_idoall_org
hbase(main):003:0> put 'test_idoall_org','10086','name:idoall','idoallvalue'
0 row(s) in 0.0960 seconds
编辑配置文件:
[hadoop@node01 ~]$ vim apache-flume-1.9.0-bin/conf/hbase_simple.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/data.txt
a1.sources.r1.port = 44444
a1.sources.r1.host = 192.168.42.131
a1.sources.r1.channels = c1
# Describe the sink
a1.sinks.k1.type = logger
a1.sinks.k1.type = hbase
a1.sinks.k1.table = test_idoall_org
a1.sinks.k1.columnFamily = name
a1.sinks.k1.serializer = org.apache.flume.sink.hbase.RegexHbaseEventSerializer
a1.sinks.k1.channel = memoryChannel
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动:
[hadoop@node01 ~]$ flume-ng agent -c .-f apache-flume-1.9.0-bin/conf/hbase_simple.conf -n a1 -Dflume.root.logger=INFO,console
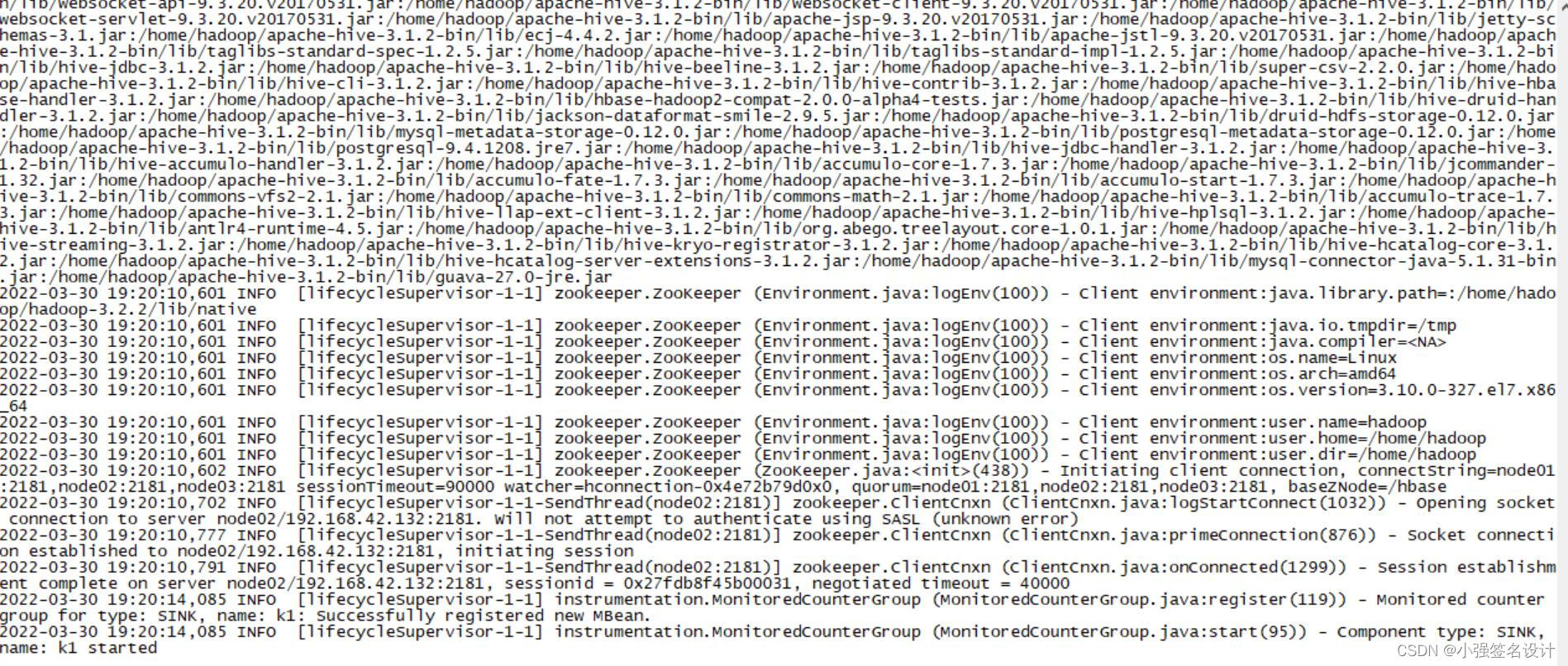
可能遇到的问题:
解决:下载hive-2.3.0版本,将lib目录下的hbase相关的包上传到flume的lib目录下
[hadoop@node01 ~]$ rm apache-flume-1.9.0-bin/lib/hbase-*.jar
[hadoop@node01 ~]$ cp/mnt/apache-hive-2.3.0-bin/lib/hbase-*.jar apache-flume-1.9.0-bin/lib/
产生数据:
[hadoop@node01 ~]$ touch data.txt
[hadoop@node01 ~]$ echo"hello idoall.org from flume" >> data.txt
这时登录到hbase中,可以发现新数据已经插入:
hbase(main):005:0> scan 'test_idoall_org'
ROW COLUMN+CELL
10086 column=name:idoall, timestamp=1355329032253, value=idoallvalue
1355329550628-0EZpfeEvxG-0 column=name:payload, timestamp=1355329383396, value=hello idoall.org from flume
2 row(s) in 0.0140 seconds
11.安装Es:
[hadoop@node01 ~]$ tar -zxvf /mnt/elasticsearch-7.14.1-linux-x86_64.tar.gz -C .
编辑elasticsearch.yml:
[hadoop@node01 ~]$ vim elasticsearch-7.14.1/config/elasticsearch.yml
# 添加如下配置
cluster.name: my-application
node.name: node-1
path.data: /home/hadoop/elasticsearch-7.14.1/data
path.logs: /home/hadoop/elasticsearch-7.14.1/logs
network.host: 192.168.42.131
http.port: 9200
discovery.seed_hosts: ["192.168.42.131","192.168.42.132","192.168.42.139"]
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
拷贝给其他两个节点:
[hadoop@node01 ~]$ scp -r elasticsearch-7.14.1/ node02:/home/hadoop/
[hadoop@node01 ~]$ scp -r elasticsearch-7.14.1/ node03:/home/hadoop/
修改其他两个节点的配置:
[hadoop@node02 ~]$ vim elasticsearch-7.14.1/config/elasticsearch.yml
cluster.name: my-application
node.name: node-2
path.data: /home/hadoop/elasticsearch-7.14.1/data
path.logs: /home/hadoop/elasticsearch-7.14.1/logs
network.host: 192.168.42.132
http.port: 9200
discovery.seed_hosts: ["192.168.42.131","192.168.42.132","192.168.42.139"]
cluster.initial_master_nodes: ["node-1","node-2","node-3"][hadoop@node03 ~]$ vim elasticsearch-7.14.1/config/elasticsearch.yml
cluster.name: my-application
node.name: node-3
path.data: /home/hadoop/elasticsearch-7.14.1/data
path.logs: /home/hadoop/elasticsearch-7.14.1/logs
network.host: 192.168.42.139
http.port: 9200
discovery.seed_hosts: ["192.168.42.131","192.168.42.132","192.168.42.139"]
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
配置环境变量:三台都操作
vim ~/.bash_profile
# 三台添加如下配置
export ES_HOME=/home/hadoop/elasticsearch-7.14.1
export PATH=$PATH:$ES_HOME/bin
# 三台生效
source ~/.bash_profile
三台机器切换到root用户:
[hadoop@node01 ~]$ su - root
[root@node01 ~]# vim /etc/sysctl.conf
vm.max_map_count=655360
fs.file-max=65536
[root@node01 ~]# sysctl -p
vm.max_map_count = 655360
fs.file-max = 65536
启动elasticsearch:
[hadoop@node01 ~]$ elasticsearch-7.14.1/bin/elasticsearch
[hadoop@node02 ~]$ elasticsearch-7.14.1/bin/elasticsearch
[hadoop@node03 ~]$ elasticsearch-7.14.1/bin/elasticsearch
访问每个ip的9200端口,出现下图所示内容即安装成功:
http://192.168.42.131:9200/
{"name":"node-1","cluster_name":"my-application","cluster_uuid":"qJ2RmibhSqayOfBciYE_-w","version":{"number":"7.14.1","build_flavor":"default","build_type":"tar","build_hash":"66b55ebfa59c92c15db3f69a335d500018b3331e","build_date":"2021-08-26T09:01:05.390870785Z","build_snapshot":false,"lucene_version":"8.9.0","minimum_wire_compatibility_version":"6.8.0","minimum_index_compatibility_version":"6.0.0-beta1"},"tagline":"You Know, for Search"}
集群健康状态:
http://192.168.42.131:9200/_cat/health?v

11.1 安装 Kibana:
[hadoop@node01 ~]$ tar -zxvf /mnt/kibana-7.14.1-linux-x86_64.tar.gz -C .
编辑kibana.yml:
[hadoop@node01 ~]$ vim kibana-7.14.1-linux-x86_64/config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://node01:9200","http://node02:9200","http://node03:9200"]
kibana.index: ".kibana"
kibana.defaultAppId: "home"
启动:
[hadoop@node01 ~]$ kibana-7.14.1-linux-x86_64/bin/kibana
浏览器输入
http://192.168.42.131:5601
或者直接访问
http://192.168.42.131:5601/app/dev_tools#/console
进入kibana的界面: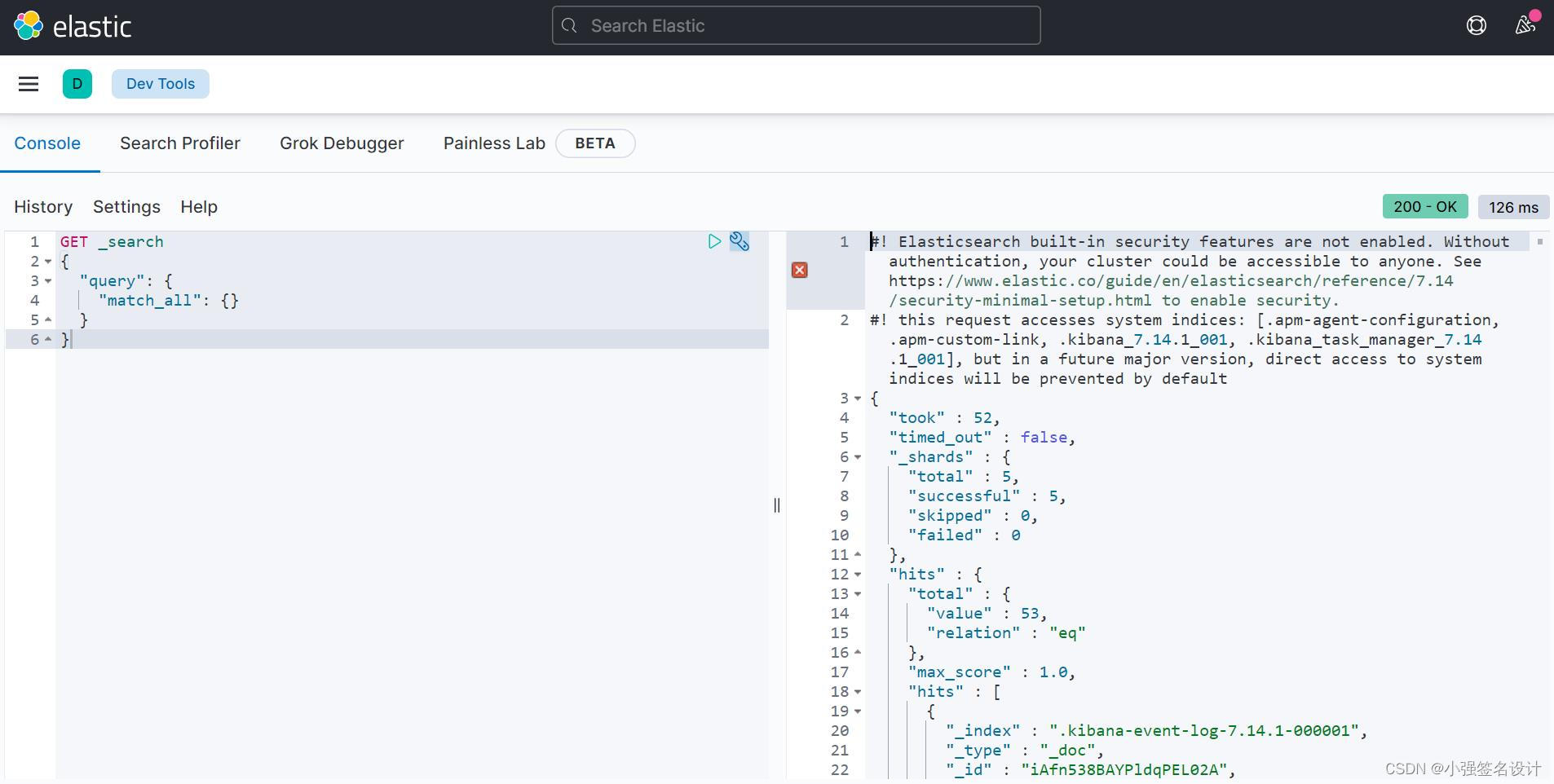
创建索引并插入数据:
PUT huiqtest
POST huiqtest/employee/1
{"first_name" : "John","last_name" : "Smith","age" : 25,"about" : "I love to go rock climbing","interests": ["sports","music"]}
查询:
GET huiqtest/employee/1
# 查询结果{"_index" : "huiqtest","_type" : "employee","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : {"first_name" : "John","last_name" : "Smith","age" : 25,"about" : "I love to go rock climbing","interests" : ["sports","music"]}}
版权归原作者 小强签名设计 所有, 如有侵权,请联系我们删除。