
一.安装准备
1.创建虚拟机
选择自定义(高级)选项
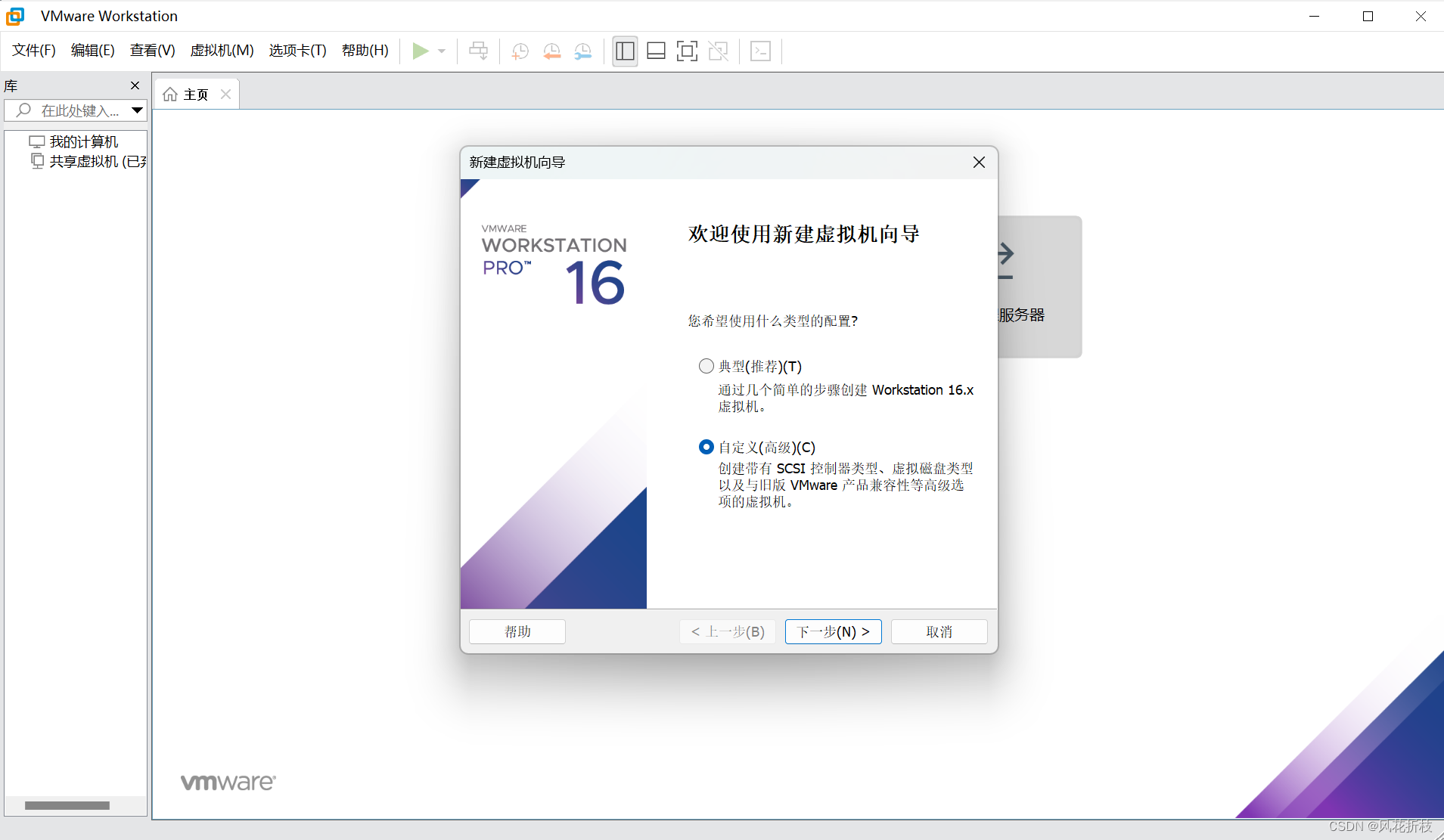
单击“下一步”选择硬件兼容性为Workstation 16.x
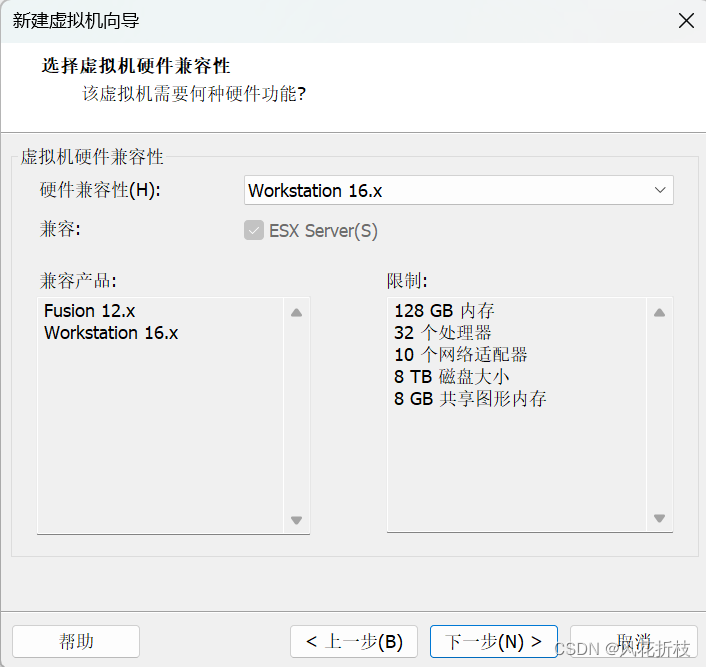
单击“下一步”选择安装来源为“稍后安装操作系统”
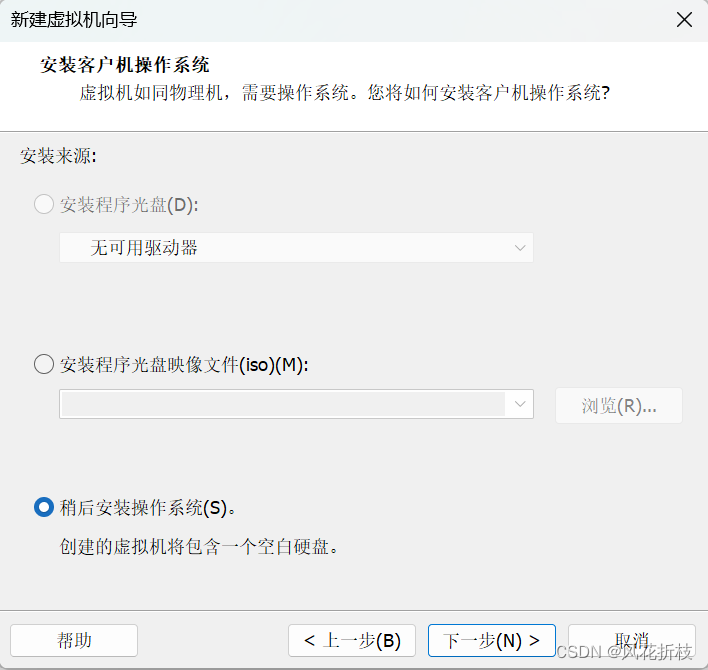
单击“下一步”,设置操作系统为Linux,版本为Linux 5.x内核64位
单击“下一步”,将虚拟机命名为Hadoop1,指定虚拟机在本地的存储位置为D:\Virtual Machine\Hadoop\Hadoop1
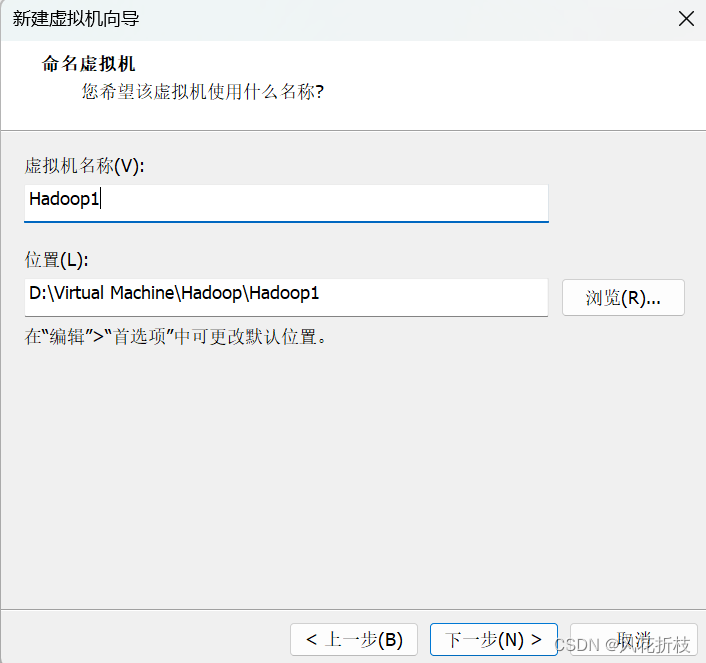
单击“下一步”,设置处理器的数量为1,每个处理器的内核数量为2
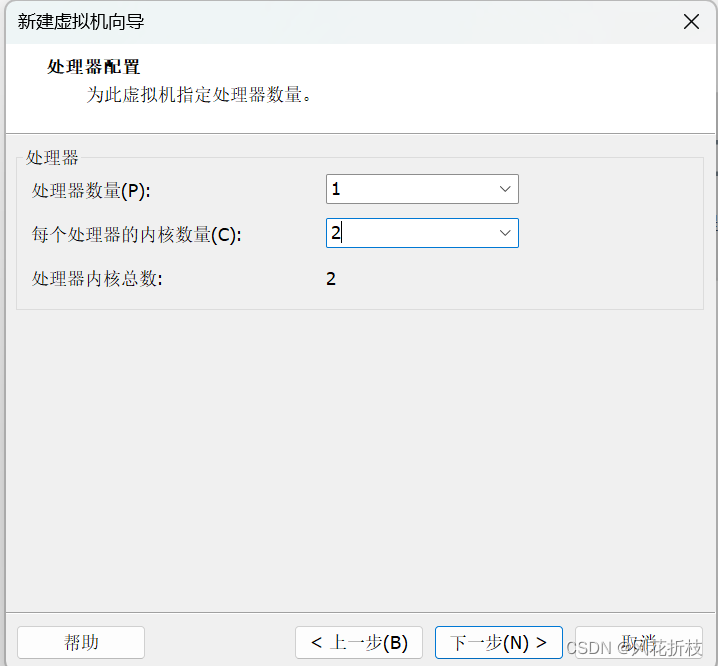
单击“下一步”,设置虚拟机的内存为4096MB。实际内存可以根据需要调整,但不建议低于4096MB。
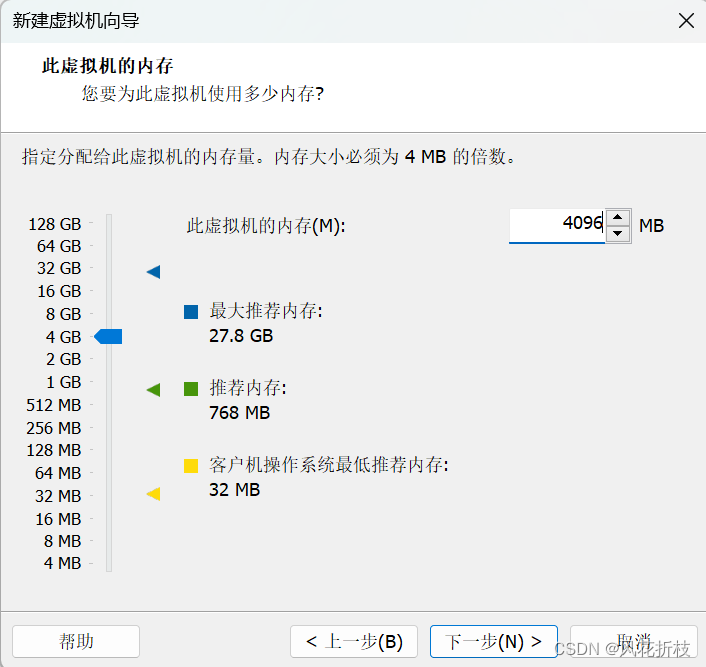
单击“下一步”,设置网络连接为“使用网络地址转换(NAT)”
单击“下一步”,设置控制器类型为LSI Logic
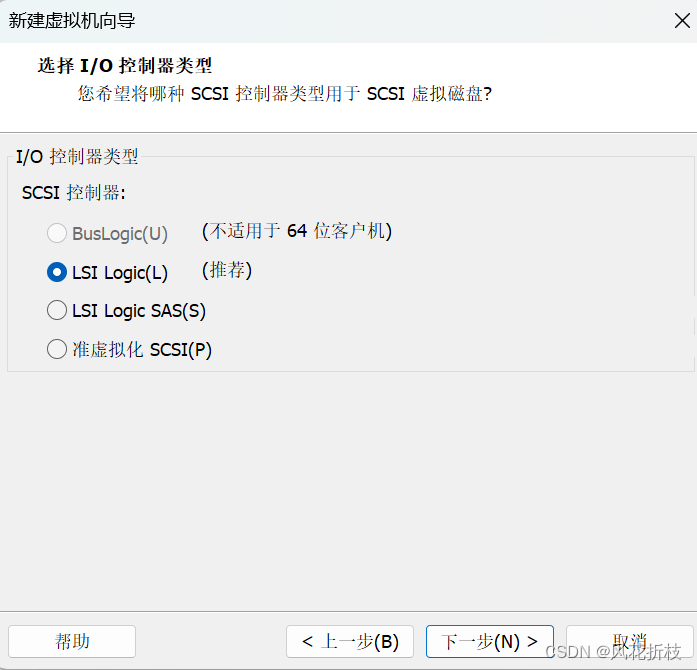
单击“下一步”,设置虚拟机磁盘类型为SCSI
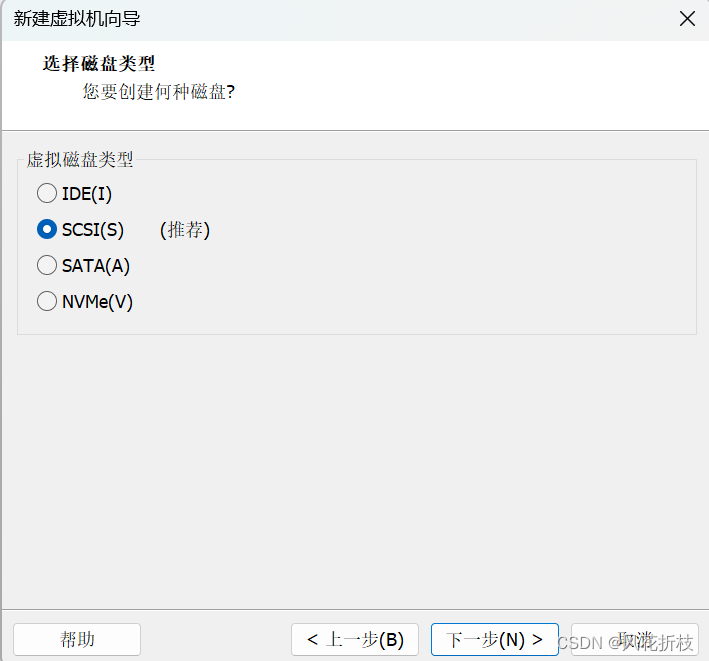
单击“下一步”,设置磁盘为“创建新虚拟磁盘”
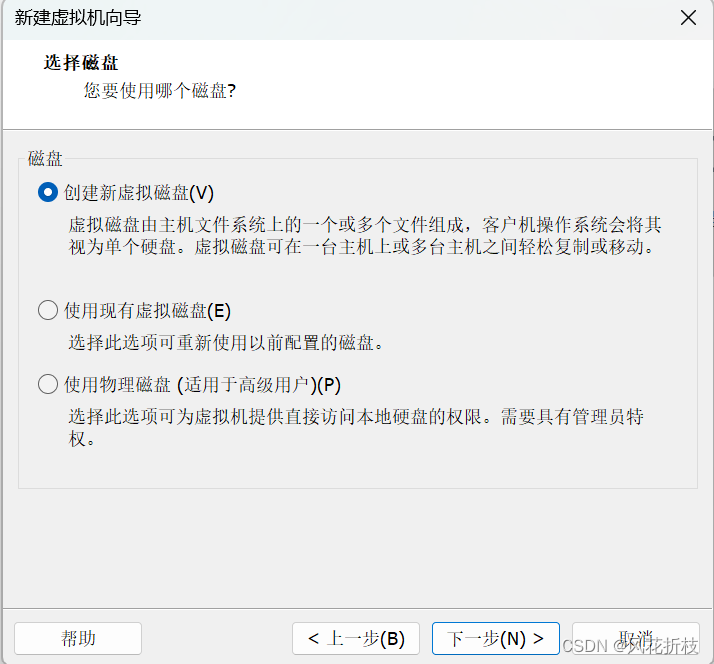
单击“下一步”,设置最大磁盘大小为30.0,并选择“将虚拟磁盘拆分为多个文件”
单击“下一步”,设置磁盘文件名如下
单击“下一步”,点击完成创建
创建完成的效果图如下
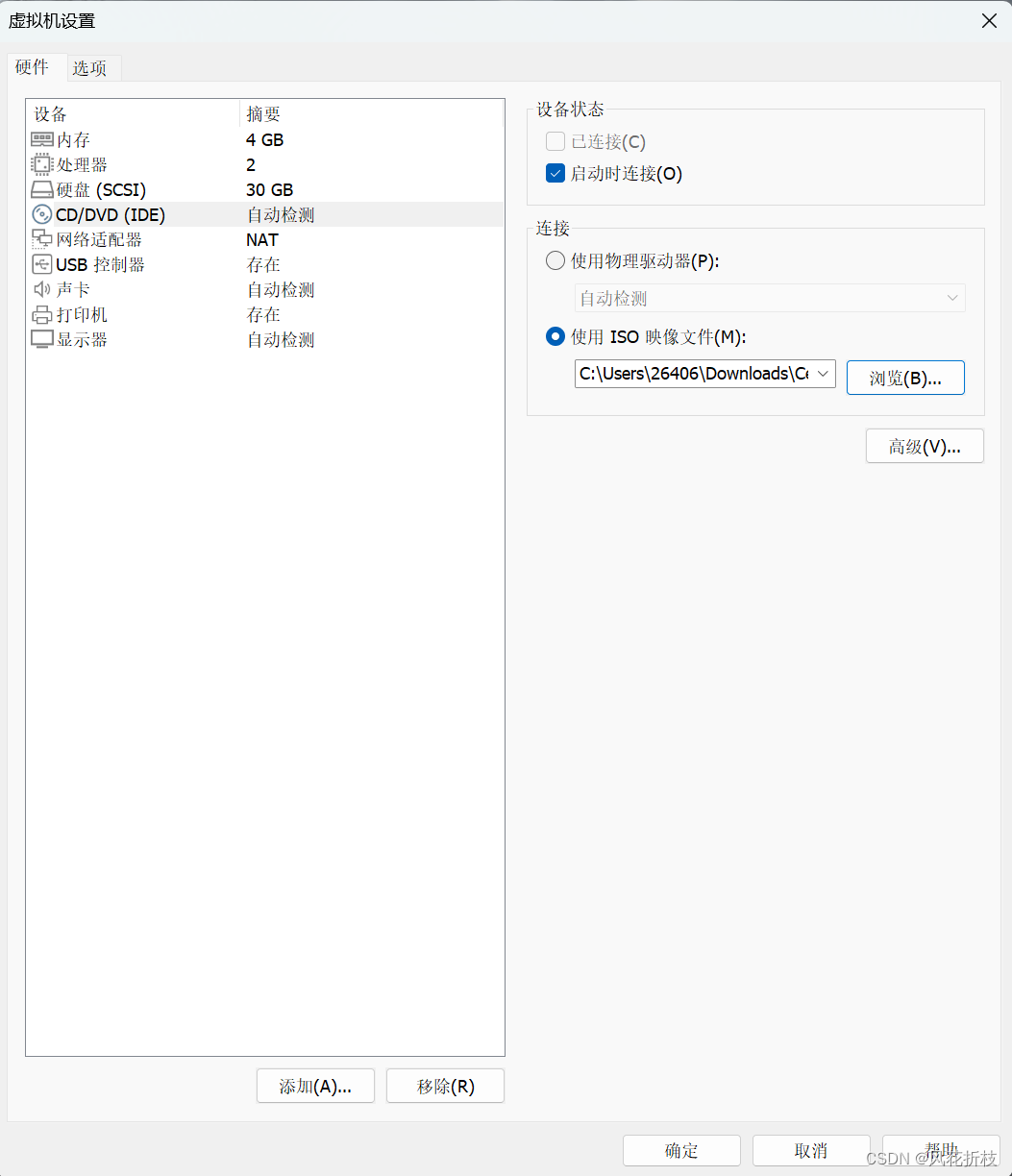
在上图中单击“编辑虚拟机设置”,进入如图所示界面,点击CD/DVD(IDE),设置如下,镜像文件可从官网下载,这里使用的是CentOS-Stream-9-latest-x86_64-dvd1.iso,点击确定。
开启虚拟机,选择语言为中文
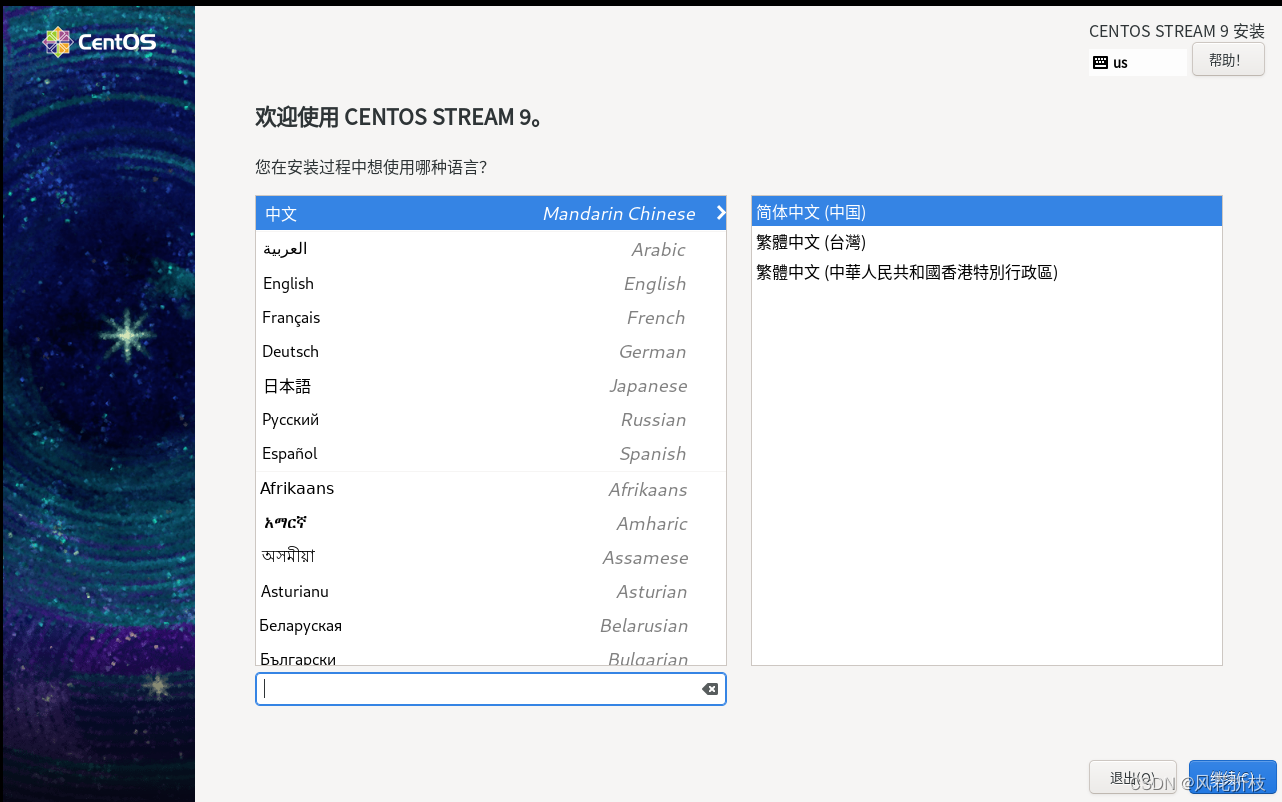
点击“继续”进入如图所示界面
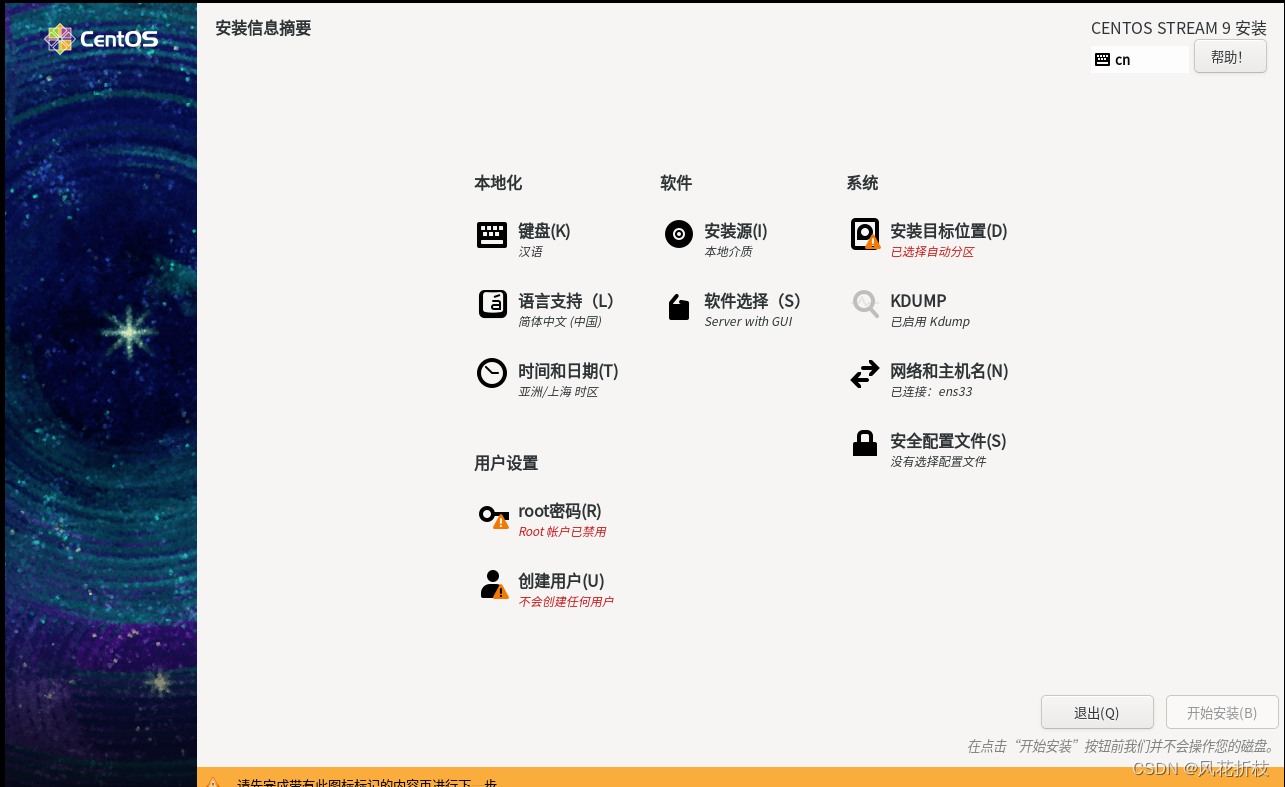
首先选择"网络和主机名",在该页面确认以太网(ens33)为打开状态,然后设置主机名为hadoop1,点击“应用”。点击左上角的“完成”返回
选择“时间和日期”,确定“地区”和“城市”为“亚洲”,“上海”,网络时间为打开状态。点击“完成”返回。
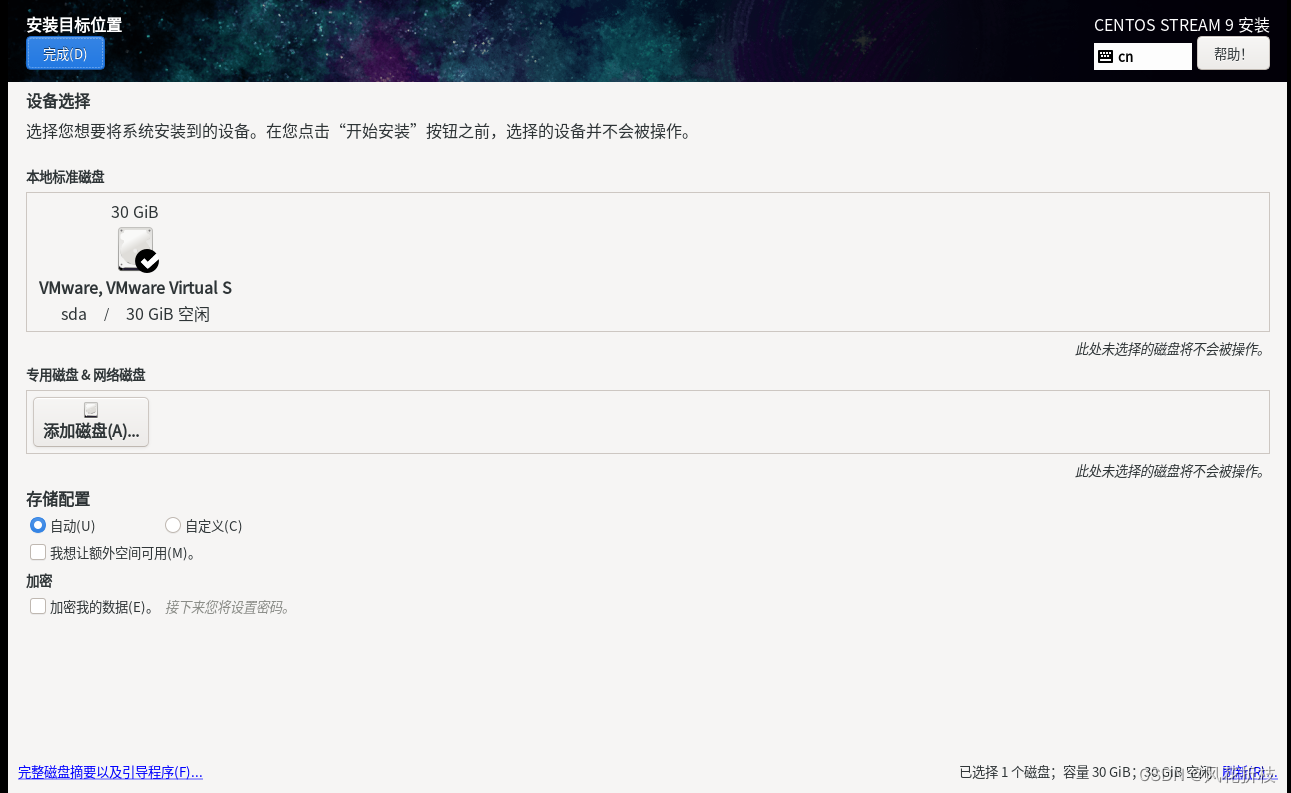
选择“安装目标位置”,配置如下,点击“完成”返回。
点击“软件选择”,设置如下,点击“完成”返回。
点击“root密码”,设置密码,如果你的密码太过简单的话,必须按两次“完成”才可设置成功

完成上述步骤后我们就可以点击“开始安装”了,这个时间可能会有点久,稍等一会。
安装完成后重启系统
进入系统后输入你的用户和密码,需要注意的是虚拟机进入后你的数字键会熄灭,输密码不要输错。
如果你完成了上面的登录,说明你成功了。
2.克隆虚拟机
首先关闭虚拟机hadoop1,关闭完成后右键虚拟机hadoop1,依次选择“管理”,“克隆”。
单击“下一步”。
选择“创建完整克隆”后,单击“下一步”。
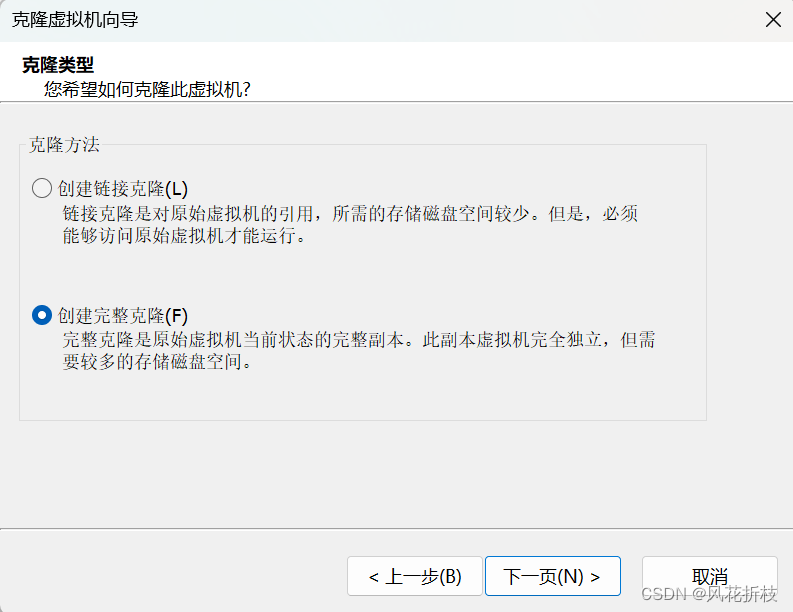
设置新的虚拟机名称为hadoop2,设置安装位置如图所示
单击“完成”,完成克隆,虚拟机hadoop3也这样克隆
3.配置虚拟机
3.1配置虚拟机的主机名和ip映射
因为虚拟机Hadoop2,Hadoop3是克隆虚拟机Hadoop1的,所以做出如下修改。首先分别在Hadoop2,Hadoop3执行如下命令
hostnamectl set-hostname hadoop2
hostnamectl set-hostname hadoop3
上述命令完成后分别在Hadoop2,Hadoop3执行如下命令重启虚拟机
reboot
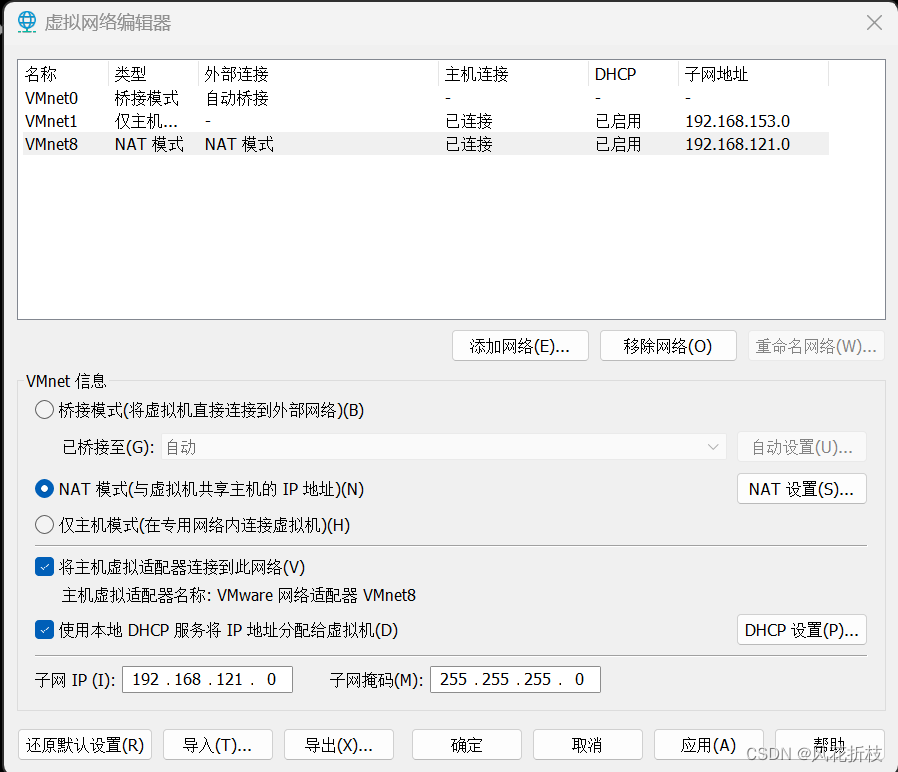
然后配置VMware Workstation网络,在主页依次选择“编辑”,"虚拟网络编辑器",选中类型为NAT模式的网卡,单击“更改设置”。
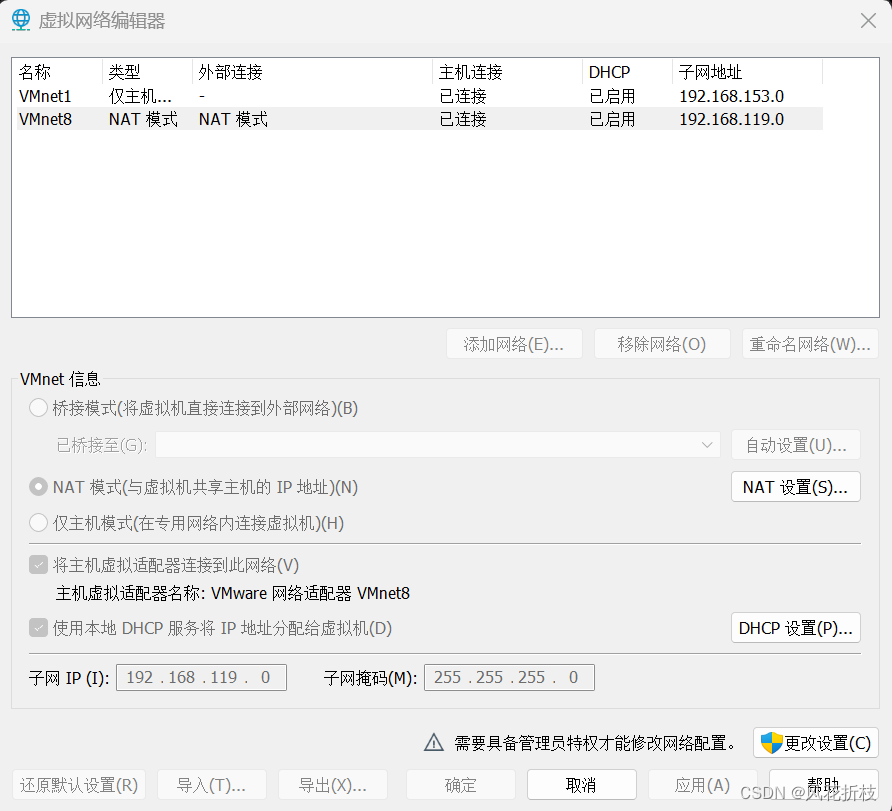
在新弹出来的页面作出如下配置,单击“完成”完成VMware Workstation的配置。
分别在三台虚拟机中执行vi /etc/profile命令,并在打开的文件添加如下内容。(先单击键盘的“i”进入修改模式,修改完成后单击“esc”退出编写模式,按住"shift"+":",输入“wq”保存退出。)
192.168.121.0 hadoop1
192.168.121.1 hadoop2
192.168.121.2 hadoop3
3.2.配置虚拟机的网络参数
将三台虚拟机的动态ip修改为静态ip,下面以Hadoop2为例进行修改。
首先编辑网络配置文件ens33.nmconnection
vi /etc/NetworkManager/system-connections/ens33.nmconnection
修改ipv4的参数,包括method的值改为manual,添加参数address1=192.168.121.161/24,192.168.121.2和dns=114.114.114.114,前者用于指定IP和网关,后者用于制定域名和解析器。
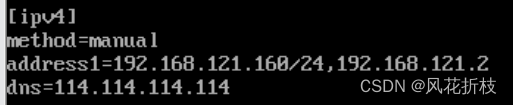
修改网卡配置文件中的uuid,它的作用是使分布式系统中的所有元素都有唯一的标识码(只有2和3需要修改)
sed -i ' /uuid=/c\uuid='`uuidgen`'' /etc/NetworkManager/system-connections/ens33.nmconnection
修改完成后需要执行“nmcli c reload”命令重新加载网络配置文件以及执行“nmcli c up ens33”命令重启ens33网卡,执行完毕后通过“ip addr”查看Hadoop2的网络信息验证配置文件是否更改成功。
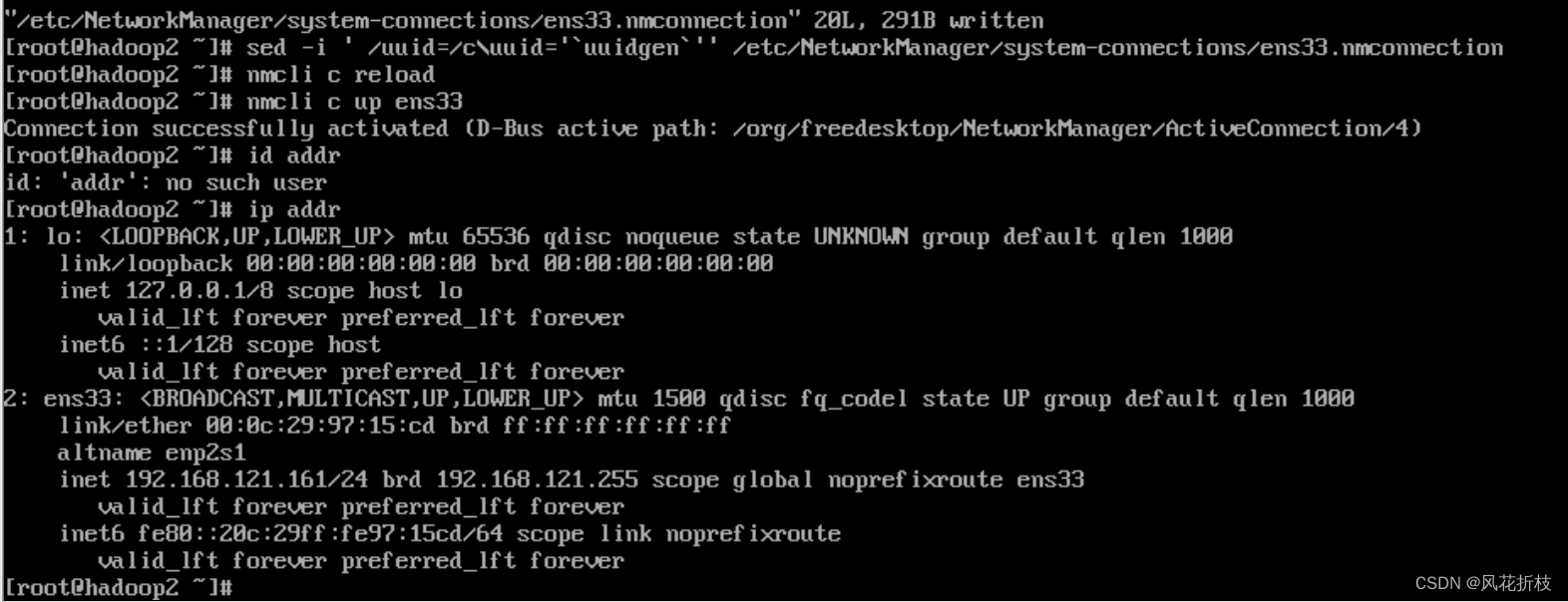
从上图可以看出IP地址成功修改为192.168.121.161。hadoop1和hadoop3的网络参数配置方式与hadoop2的方式相同,其中dns的值相同,hadoop1和hadoop3的address1值分别为192.168.121.160/24,192.168.121.2和192.168.121.162/24,192.168.121.2
3.3配置虚拟机远程登录
以Hadoop2为例,使用如下命令查看当前虚拟机是否安装和开启SSH服务
rmp -qa|grep ssh和ps -ef | grep sshd
如果没有安装可以使用“yum install open-server”命令安装SSH服务,执行“systemctl start sshd”命令开启SSH服务
使用"vi /etc/ssh/sshd_config"编辑sshd_config,在尾部添加"PermitRootLogin yes"
执行“systenctl restart sshd”命令重启SSH服务使配置文件生效。
下载设置SecureCRT,在主界面依次选择File-Quack Conect进入连接对话框,输入如下信息连接hadoop2
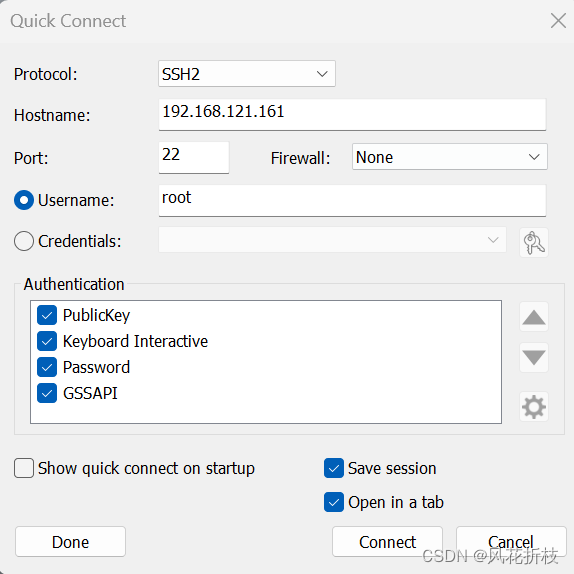
选Accept Once

输入你的用户名和密码
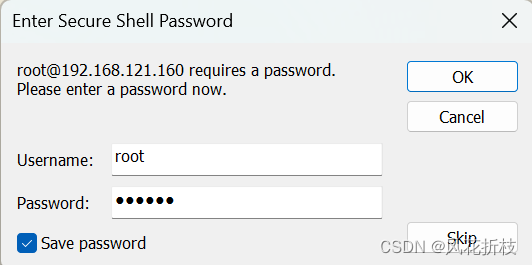
连接成功的页面如图所示
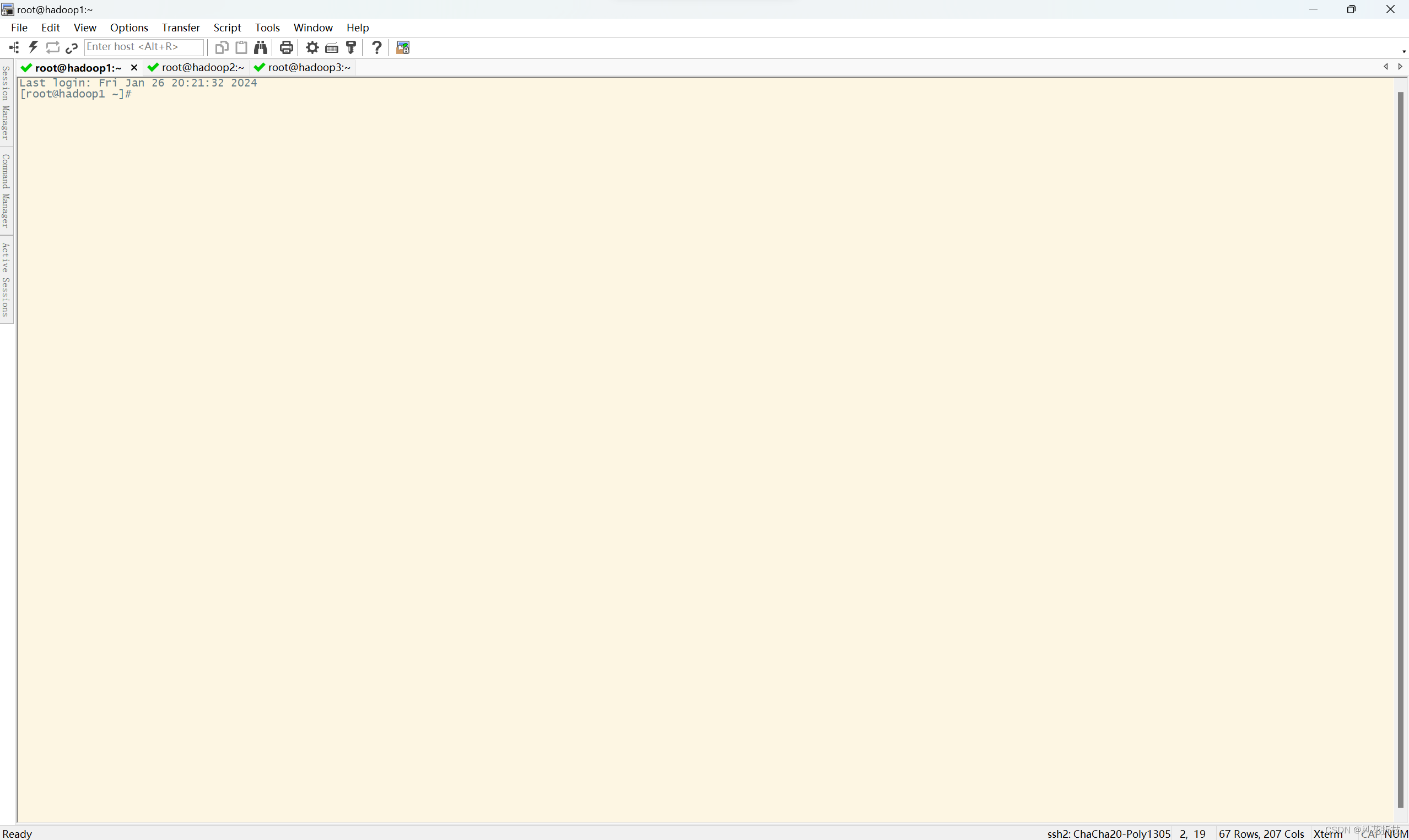
其他两台虚拟机按照上述步骤执行完成连接远程连接工具secureCRT
3.4配置虚拟机SSH免密登录
我们以Hadoop1为主节点
使用命令ssh-keygen -t rsa生成秘钥(连续按四次enter进行确认)
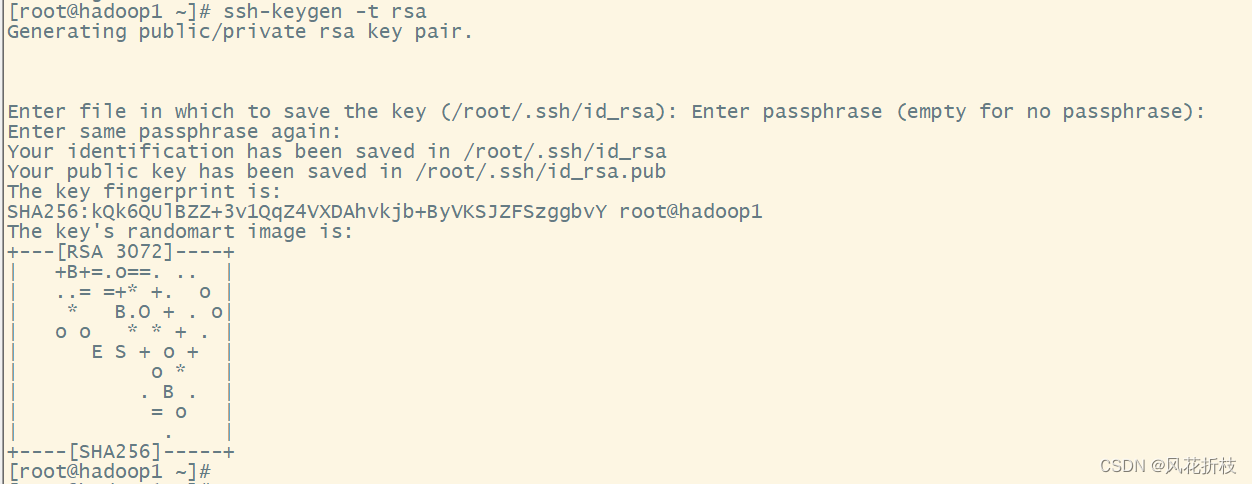
执行cd /root/.ssh/命令查看ssh下的文件,这两个文件分别为虚拟机的私有密钥和共有秘钥
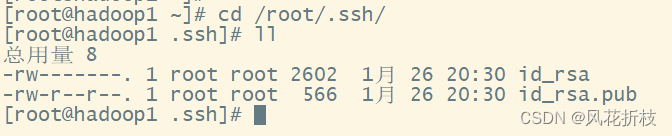
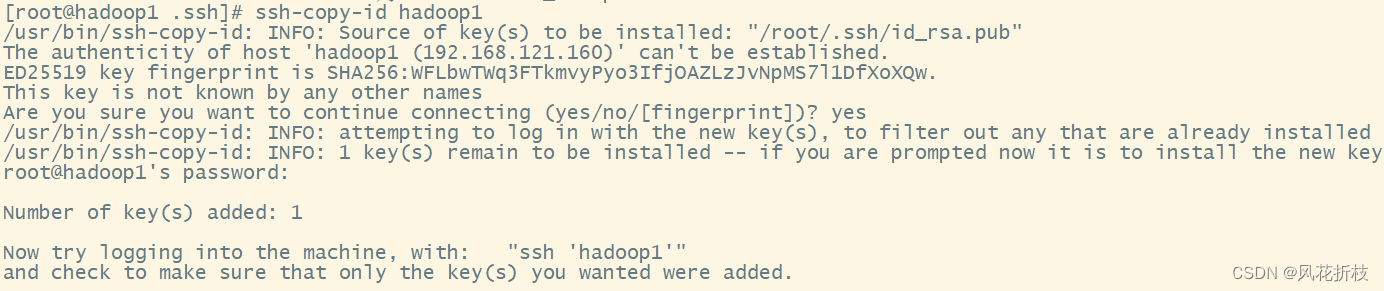
执行如下命令复制Hadoop1的共有秘钥到所有虚拟机,执行过程中需要注意输入“yes”后按“Enter”表示同意连接制定虚拟机,然后输入root用户的密码
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
在Hadoop1上执行ssh hadoop2访问虚拟机验证是否可以免密登录

4.安装JDK
4.1创建目录
分别在虚拟机hadoop1,Hadoop,hadoop3下创建三个目录
创建存放数据的目录
mkdir -p /export/data/
创建安装程序的目录
mkdir -p /export/servers/
创建存放安装包的目录
mkdir -p /export/software/
4.2上传JDK安装包
执行cd /export/software进入目录,执行”rz“”命令上传JDK安装包(如果rz执行后提示无法找到该命令,则可以执行“yum install lrzsz -y”命令安装文件传输工具lrzsz)
查看JDK安装包是否上传成功
在hadoop1的/export/software目录下执行“ls”命令查看是否包含JDK安装包

安装JDK
使用如下命令安装到/export/servers目录
tar -zxvf jdk-8u241-linux-x64.tar.gz -C /export/servers
4.3配置JDK系统环境变量
在hadoop1上执行vi /etc/profile编辑环境变量profile
export JAVA_HOME=/export/servers/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
执行sourse /etc/profile初始环境变量,使JDK生效
4.4验证JDK是否安装成功
在hadoop1上执行java -version查看JDK版本号,验证是否安装JDK

4.5分发JDK目录
scp -r /export/servers/jdk1.8.0_241 root@hadoop2:/export/servers/
scp -r /export/servers/jdk1.8.0_241 root@hadoop3:/export/servers/
4.6分发系统环境变量文件
scp /etc/profile root@hadoop2:/etc
scp /etc/profile root@hadoop3:/etc
分别执行sourse /etc/profile初始化系统环境变量
二.基于完全分布式模式部署Hadoop
1.安装hadoop
上传hadoop安装包到/export/software目录
上传后使用“ls”命令查看是否上传成功

使用如下命令安装Hadoop到/export/servers目录
tar -zxvf /export/software/hadoop-3.3.0.tar.gz -C /export/servers
2.配置Hadoop系统环境变量
在Hadoop1上执行vi /etc/profile配置profile,在文件底部添加内容,如下所示
export HADOOP_HOME=/export/servers/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行“source /etc/profile”命令初始化系统环境变量使配置生效
3.验证Hadoop系统环境变量是否成功

执行hadoop version查看当前版本号为3.3.0,配置成功
4.修改Hadoop配置文件
在Hadoop1的 /export/servers/hadoop-3.3.0/etc/hadoop/目录执行vi hadoop-env.sh命令,在改文件下方添加命令如下所示内容
export JAVA_HOME=/export/servers/jdk1.8.0_201
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
在Hadoop1的 /export/servers/hadoop-3.3.0/etc/hadoop/目录执行vi core-site.xml命令,在<configuration>标签中添加如下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
在Hadoop1的 /export/servers/hadoop-3.3.0/etc/hadoop/目录执行执行vi hdfs-site.xml命令,在<configuration>标签下添加如下所示内容
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9868</value>
</property>
在Hadoop1的 /export/servers/hadoop-3.3.0/etc/hadoop/目录执行vi mapred-site.xml命令,在<configuration>添加如下所示内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.Webapp.address</name>
<value>hadoop1:19888</value>
</property>
<property>
<name> yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
在Hadoop1 /export/servers/hadoop-3.3.0/etc/hadoop/目录执行vi yarn-site.xml命令,在<configuration>添加如下内容
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name> yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop1:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
配置Hadoop从节点运行的服务器,在Hadoop1的/export/servers/hadoop-3.3.0/etc/hadoop/目录执行vi works命令修改为
hadoop1
hadoop2
hadoop3
5.分发hadoop安装目录
使用scp命令将hadoop1的安装目录分发至hadoop2,hadoop3
scp -r /export/servers/hadoop-3.3.0 root@hadoop2:/export/servers/
scp -r /export/servers/hadoop-3.3.0 root@hadoop3:/export/servers/
6.分发系统环境变量文件
scp /etc/profile root@hadoop2:/etc
scp /etc/profile root@hadoop3:/etc
分发完成后分别在hadoop2,hadoop3上执行“source /etc/profile”命令格式化系统环境变量
7.格式化hdfs文件系统
在hadoop上执行格式化 HDFS文件系统操作“hdfs namenode -format”(切记只有这一次需要格式化,不要多次格式化)
8.启动hadoop
在hadoop1上执行“start-all.sh”命令启动集群,分别在三台虚拟机使用"jps"命令查看hadoop的运行状态,如与下面一样则配置成功
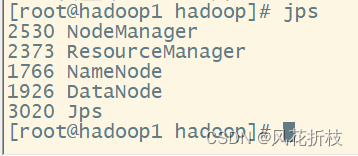
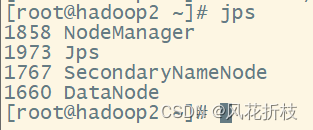
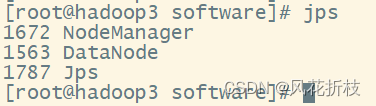
9.通过Web UI查看Hadoop运行状态
9.1关闭防火墙
#关闭防火墙
systemctl stop firewalld
#禁止防火墙开机启动
systemctl disable firewalld
9.2添加映射
在自己的电脑C:\Windows\System32\drivers\etc位置编辑hosts文件,添加如下
192.168.121.160 hadoop1
192.168.121.161 hadoop2
192.168.121.162 hadoop3
三.运用集群进行词频统计
1.创建文本
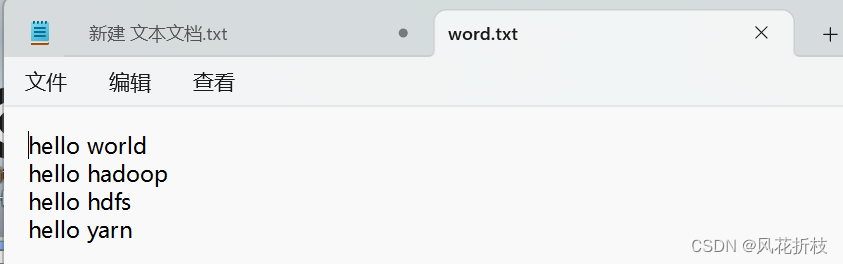
2.在hdfs上创建目录
首先开启集群,然后在hdfs创建目录
hdfs dfs -mkdir -p /wordcount/input
3.上传文件
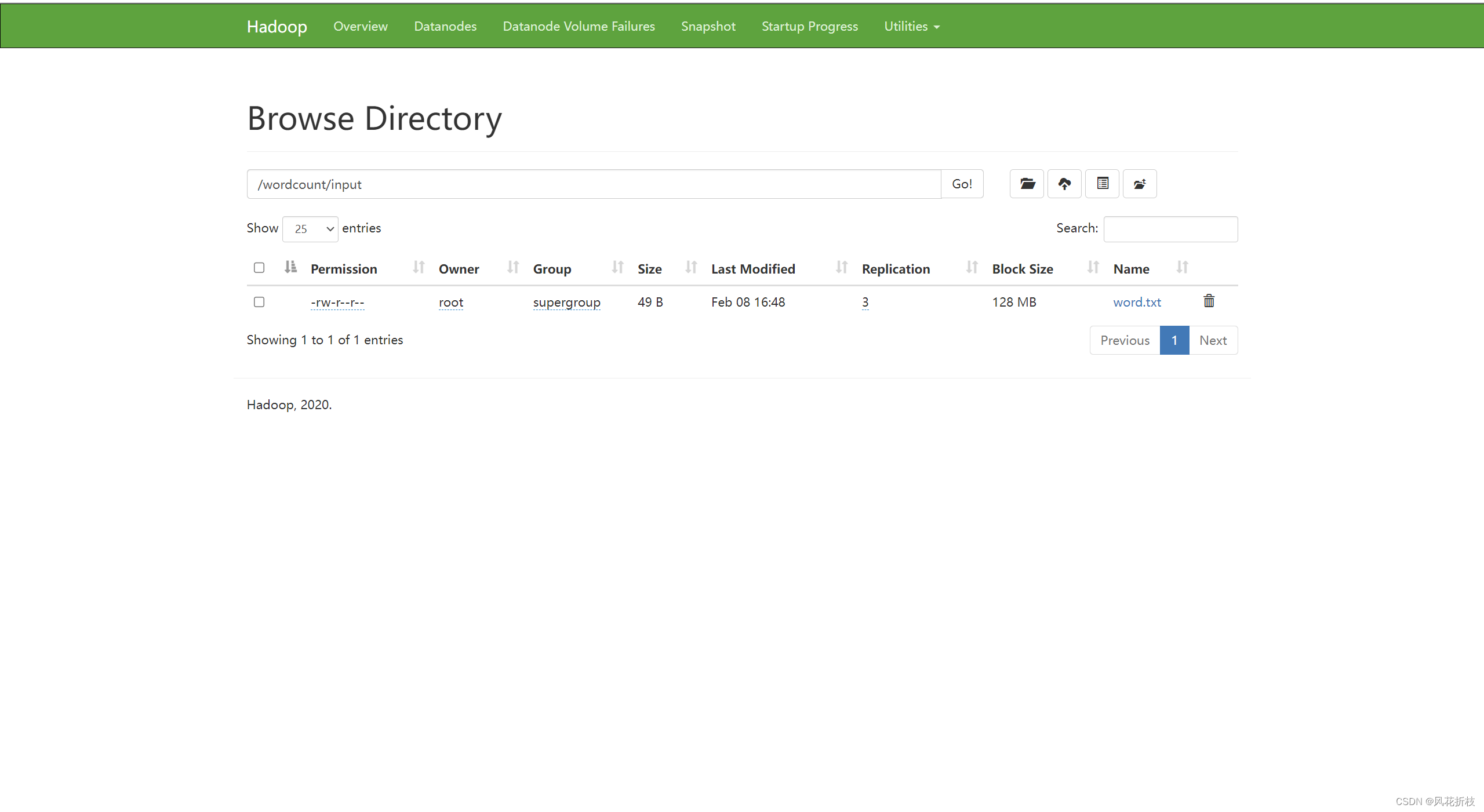
在hadoop1的/export/data目录执行“rz”上传文本word.txt,然后将该文本上传到hdfs的/wordcount/input目录
hdfs dfs -put /export/data/word.txt /wordcount/input
4.查看文件是否上传成功
依图所示打开
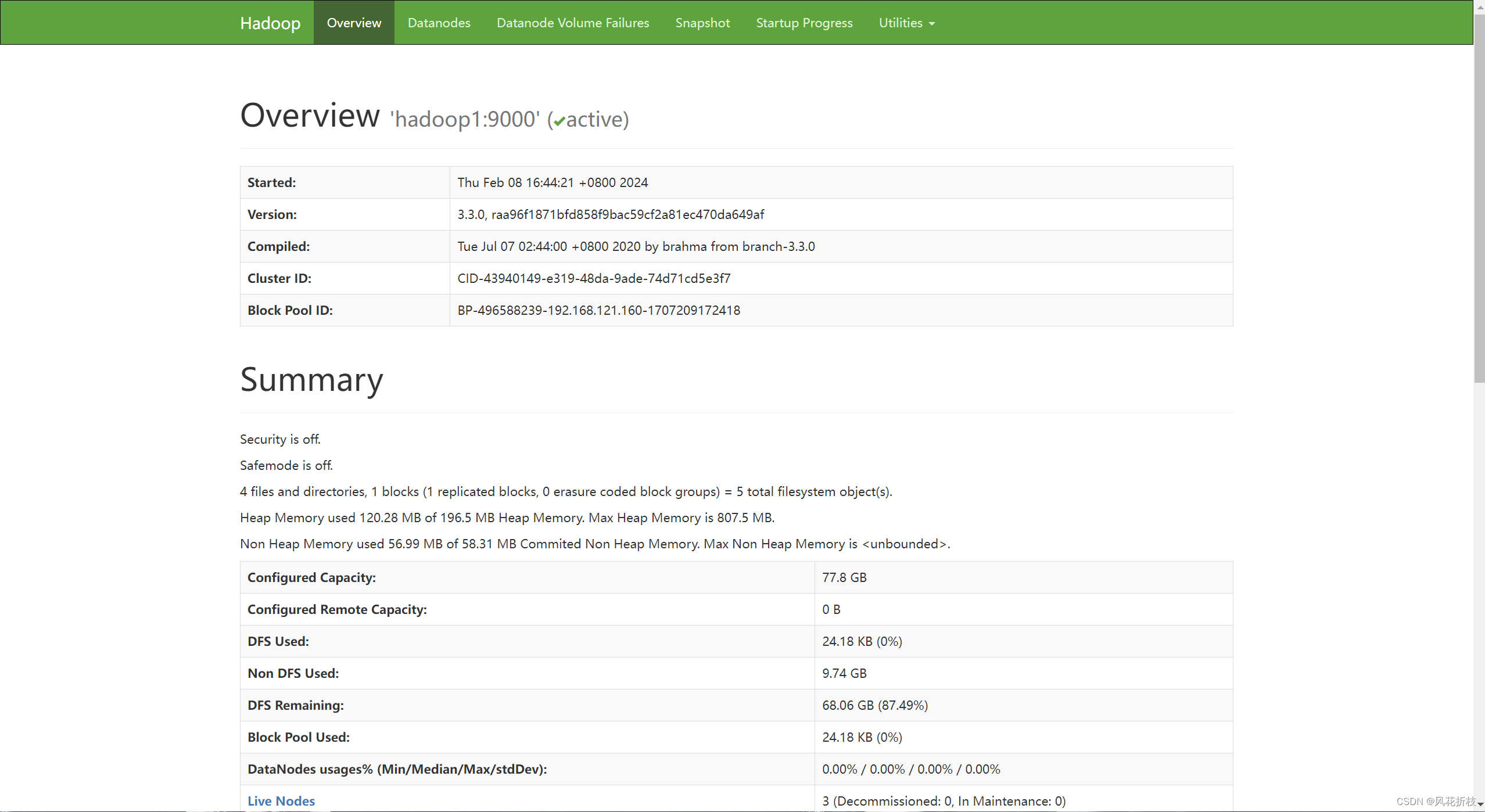
第一个
发现上传成功
5.运行mapreduce程序
在hadoop1的/export/servers/hadoop-3.3.0/share/hadoop/mapreduce目录执行“ll”命令,查看hadoop提供的MapReduce程序
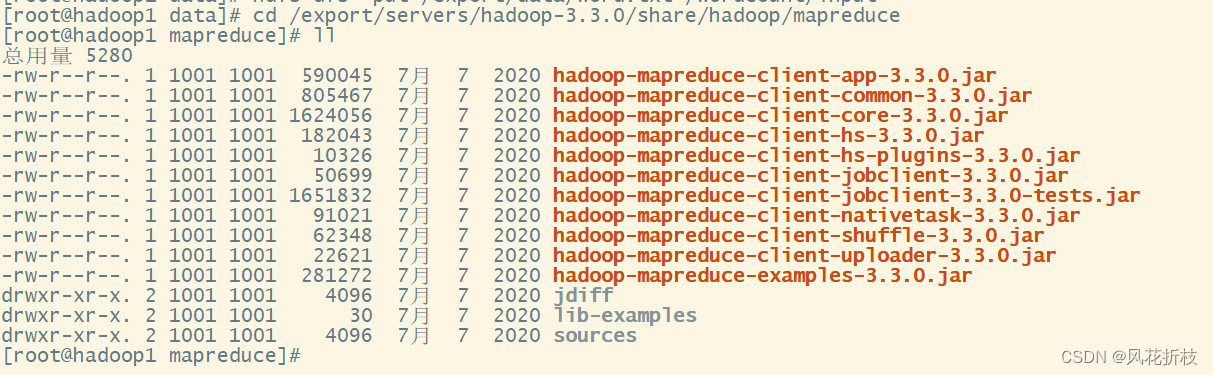
其中hadoop-mapreduce-examples-3.3.0.jar可以实现词频统计,在该程序所在目录执行命令,统计文本
hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /wordcount/input /wordcount/output
代码运行部分截图

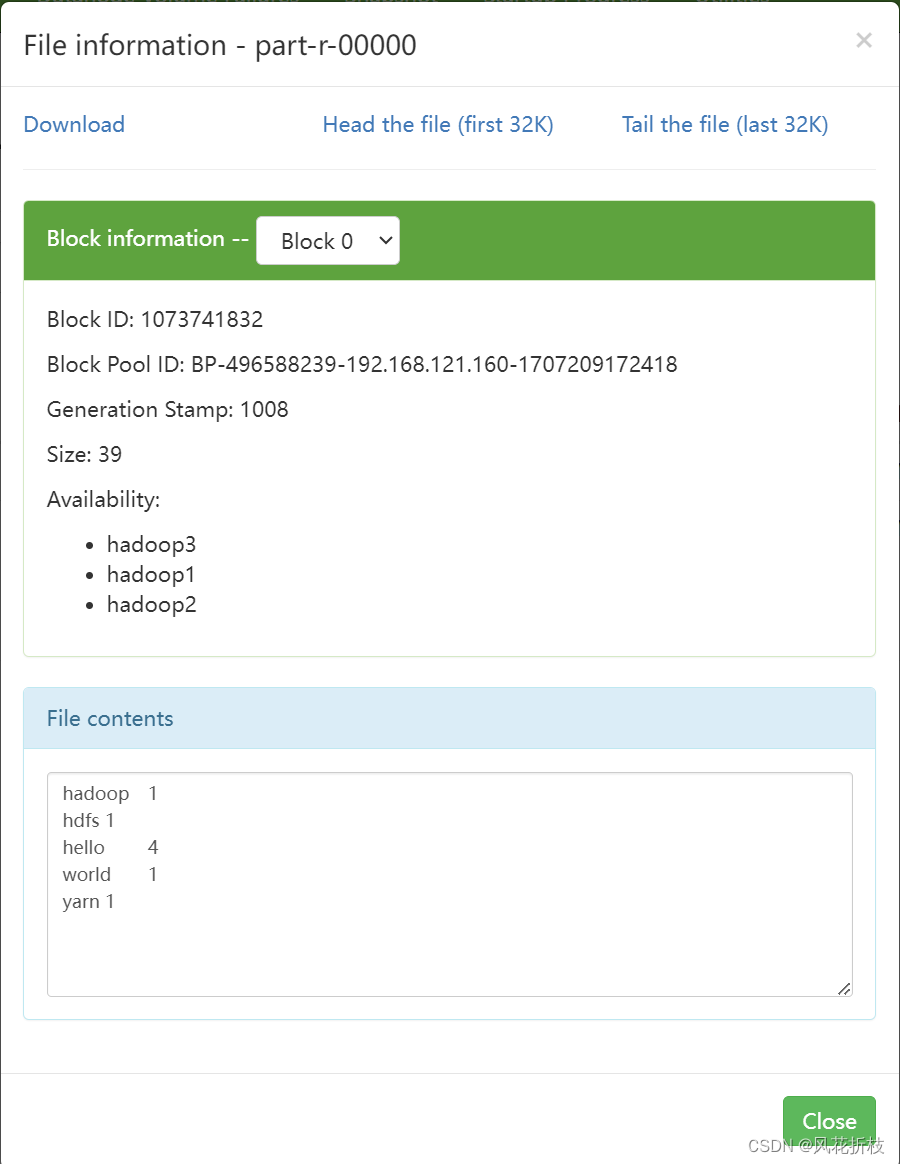
6.查看MapReduce程序运行状态
在output中的part-r- 00000中查看运行结果
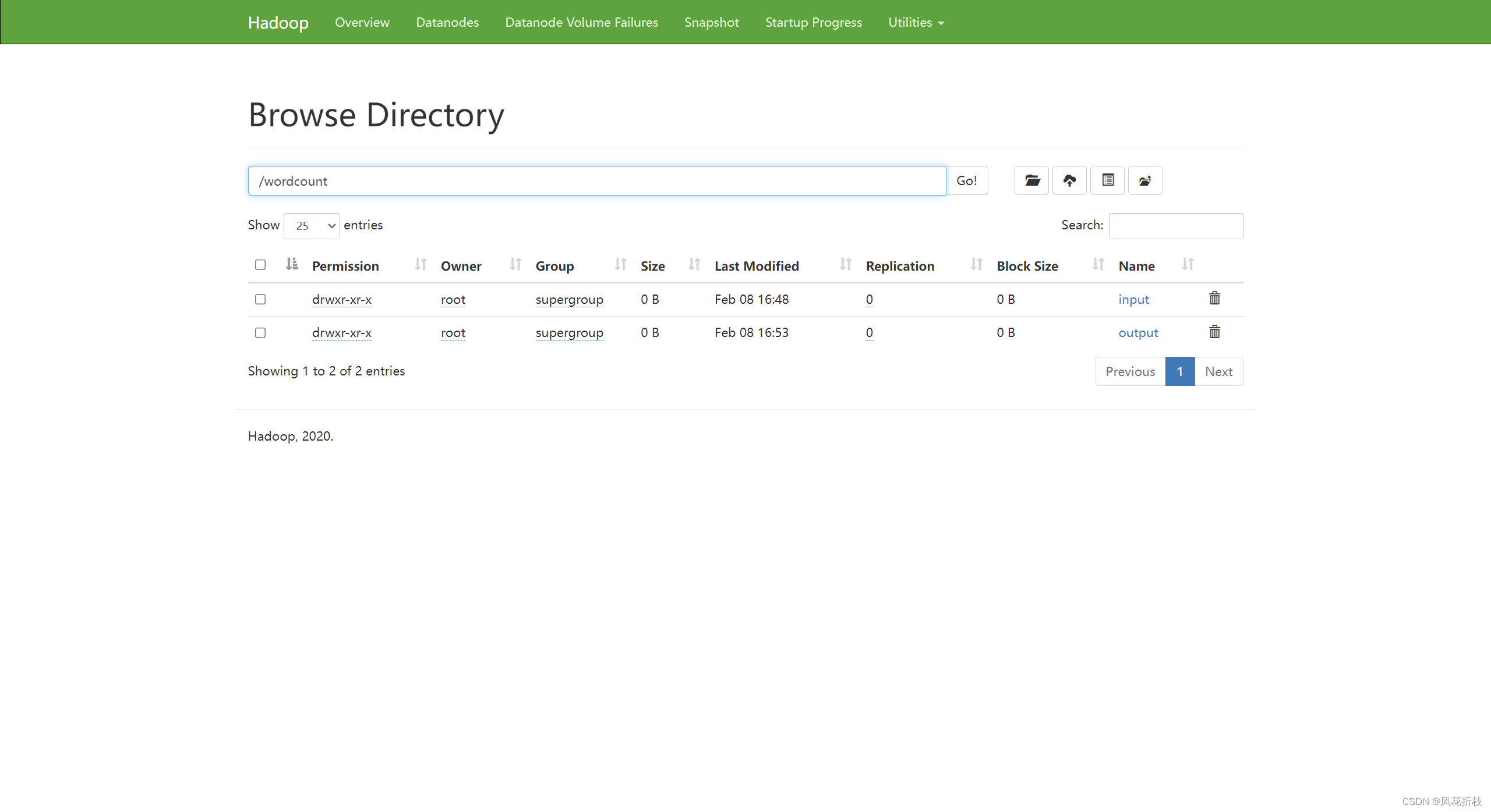
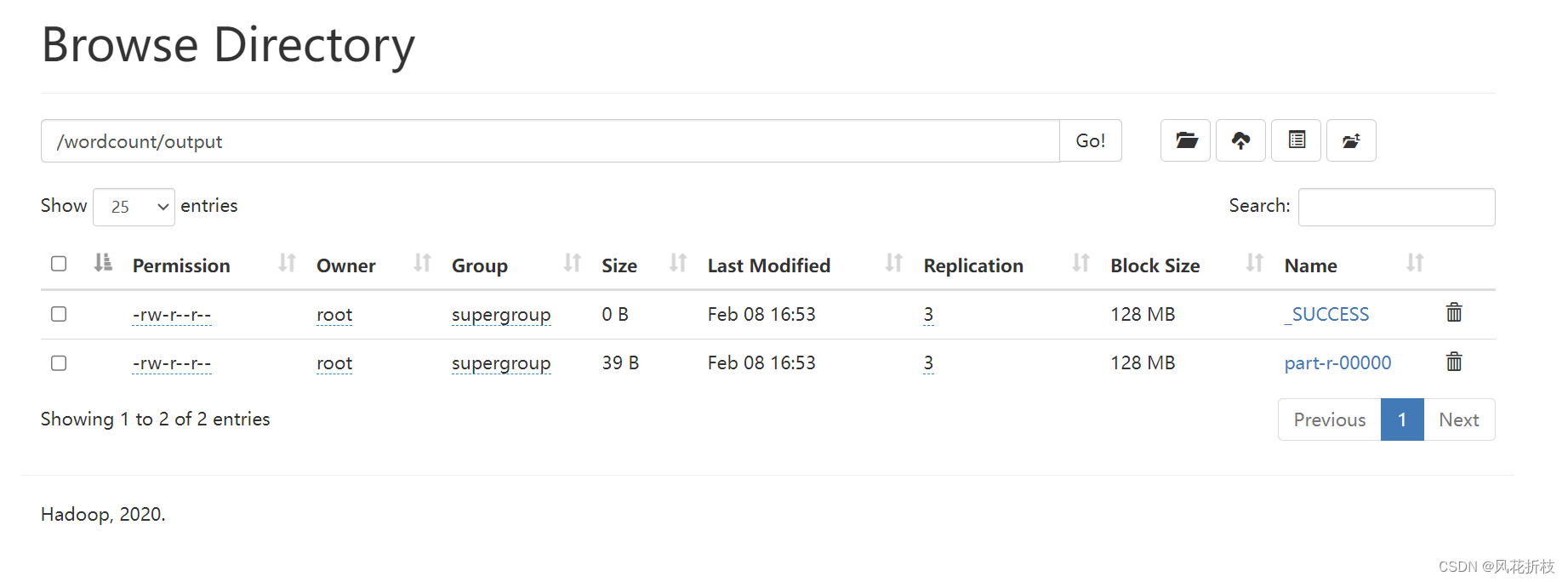
如图所示为运行结果
版权归原作者 风花折枝 所有, 如有侵权,请联系我们删除。