
****1. 集群安装配置完整过程 ****
a) 3 台客户机(关闭防火墙、设置好IP、主机名、时钟同步等信息在之前发布的博客有)
1
2
3
虚拟机
Hadoop100
Hadoop101
Hadoop100
主机名
Hadoop100
Hadoop101
Hadoop100
IP地址
192.168.9.10
192.168.9.11
192.168.9.10
Hdfs
NameNode
DataNode
DataNode
SecondaryNameNode
DataNode
yarn
NodeManager
ResourceManager
NodeManager
NodeManager
b) 分别安装 JDK 并配置环境变量
c) 安装 Hadoop 并配置环境变量
d) 配置 SSH 免密钥通信
e) 配置集群
f) 群起集群并测试
建议先配置xsync集群分发脚本!!这样只需要在一台虚拟机修改,之后通过脚本分发给另外两台虚拟机即可。
参考我写的另一篇博客:
【Hadoop集群搭建】xsync集群分发脚本-CSDN博客
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/m0_67830223/article/details/139803036
****2. 配置 SSH 免密钥通信 ****
ssh 基本用法,输入以下命令测试(注意使用自己配置的主机名和 IP 地址)
ssh 192.168.9.10
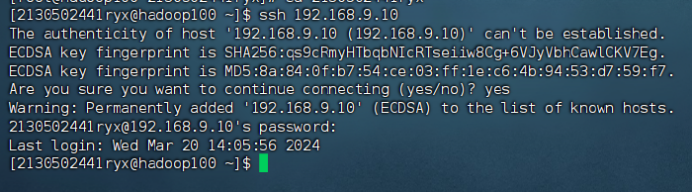
SSH 免密钥配置具体步骤
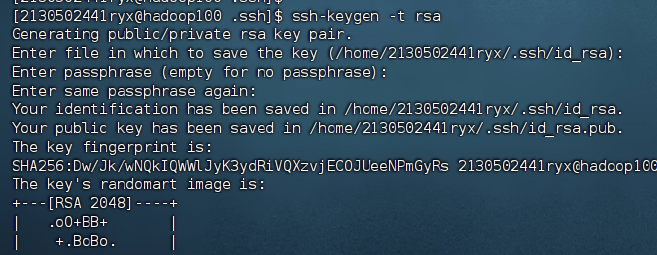
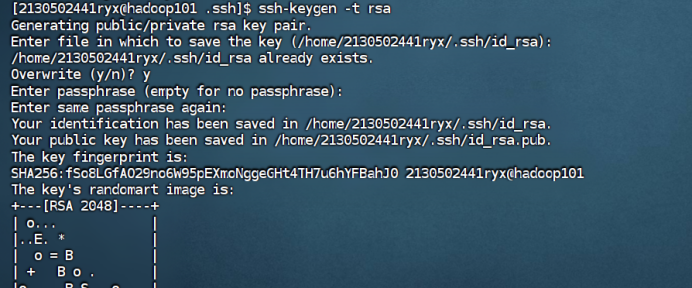
步骤 1:进入.ssh 目录(该目录是一个隐藏文件夹,在/home/账户名下,这****里的账户名每个人都不同,不是说文件夹的名字叫‘账户名’),在 hadoop100 生成密钥对(公钥+私钥),输入命令并敲击三次回车
ssh-keygen -t rsa
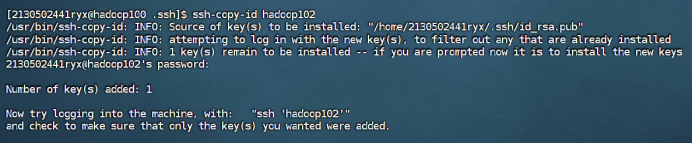
步骤 2:查看生成的密钥对,并拷贝密钥至hadoop100,hadoop101,Hadoop102。
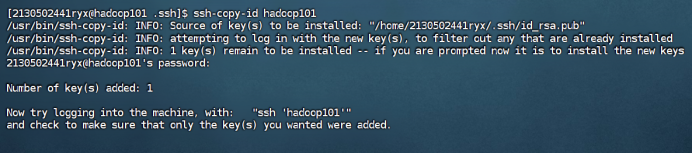
① 拷贝密钥至hadoop100
ssh-copy-id hadoop100

② 拷贝密钥至hadoop101
ssh-copy-id hadoop101

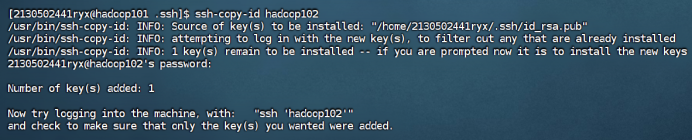
③ 拷贝密钥至hadoop102
ssh-copy-id hadoop102
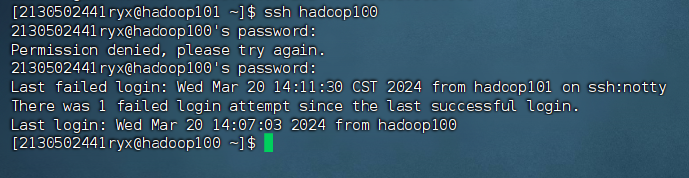
步骤 3:在hadoop100 测试免密钥到 hadoop101,反之需要密码。
ssh hadoop101

ssh hadoop100
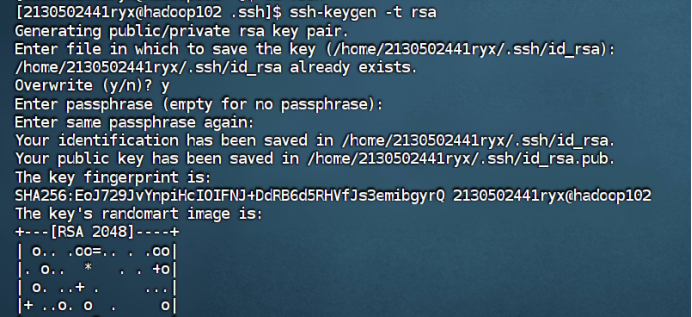
在hadoop101和hadoop102中重复步骤1-2如下:
**** **** **** hadoop101

hadoop102

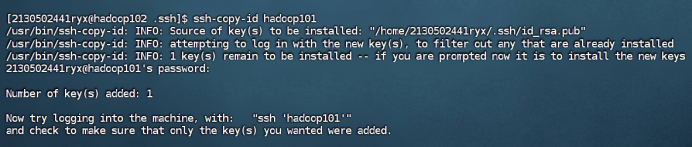
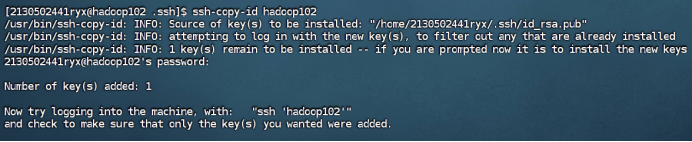
在hadoop100中用root身份,重复步骤1-2
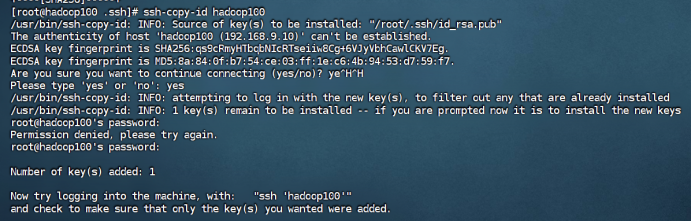
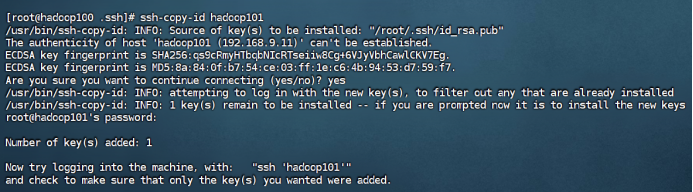
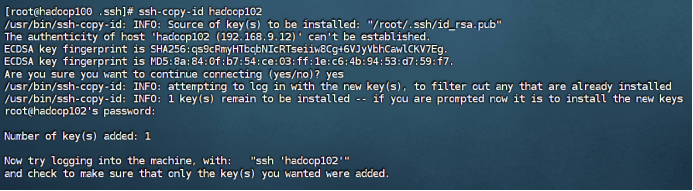
到这里可以ssh测试一下,如果还是不行,那么最重要的一步:把文件夹权限改了!
三台虚拟机都得修改!!!!
chmod 700 /home/2130502441ryx
chmod 700 /home/2130502441ryx/.ssh
chmod 600 /home/2130502441ryx/.ssh/authorized_keys



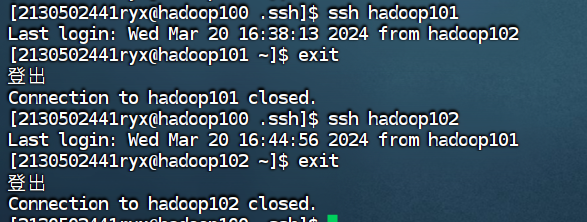
实现集群中相互免密钥的运行截图如下:
① 在hadoop100 测试免密钥到 hadoop101和hadoop102
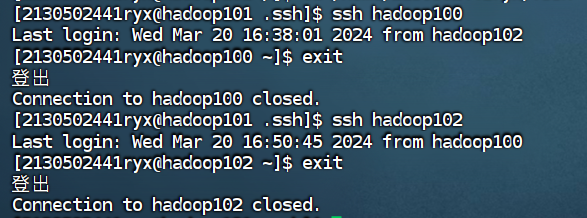
② 在hadoop101 测试免密钥到 hadoop100和hadoop102
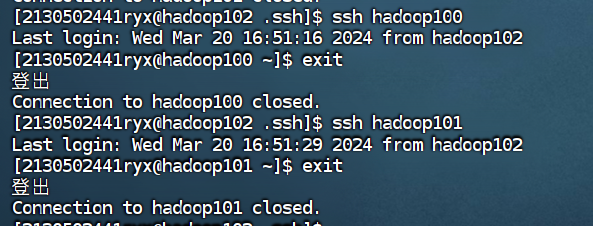
③ 在hadoop102 测试免密钥到 hadoop100和hadoop101
****3. Hadoop 集群配置 ****
*注意:Hadoop 只需要安装配置在一台机器上,配置结束后可以远程拷贝至*****集群中其他机器。 ****
具体步骤如下:
步骤 1:解压缩 hadoop 安装包(注意必须使用 hadoop 普通用户)

步骤 2:配置 hadoop 用户环境变量,将 hadoop 命令和可执行文件目录加入到环境变量 PATH 中,并使环境变量生效。

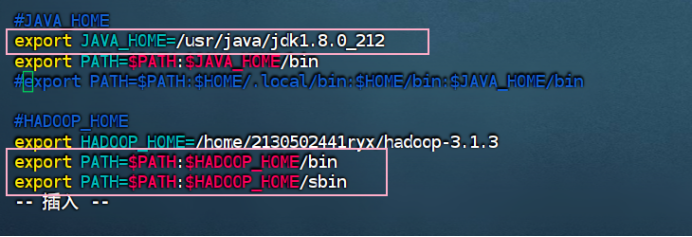
步骤 3:配置 hadoop 运行时需要的环境变量
在目录/home/2130502441ryx/hadoop-2.8.1/etc/hadoop 下找到文件 hadoop-env.sh,用 vi 编辑文件内容 JAVA_HOME,在文件内找到以下代码:将上述内容修改为 JDK 安装路径(注意自己机器的安装路径)


在目录/home/2130502441ryx/hadoop-2.8.1/etc/hadoop 下找到文件 yarn-env.sh,用vi 编辑文件内容 JAVA_HOME,在文件内找到以下代码: 将上述内容修改为 JDK 安装路径(注意自己机器的安装路径)

步骤 4:hadoop 集群配置文件,在 hadoop 安装目录下的/etc/hadoop 中。
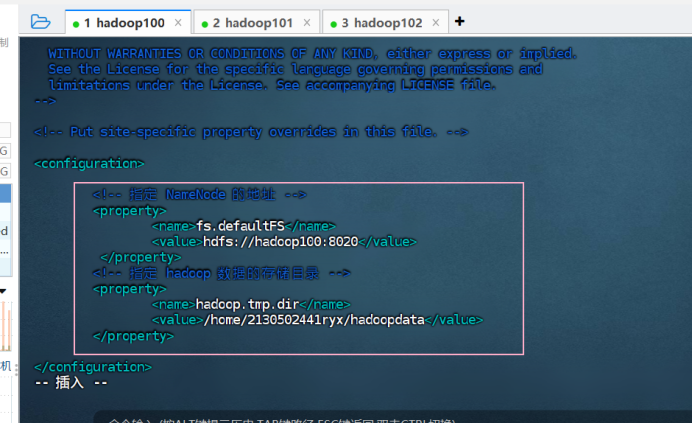
① 配置 core-site.xml 文件
vim core-site.xml

<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
② 配置 hdfs-site.xml
vim hdfs-site.xml

<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop100:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop102:9868</value>
</property>
</configuration>

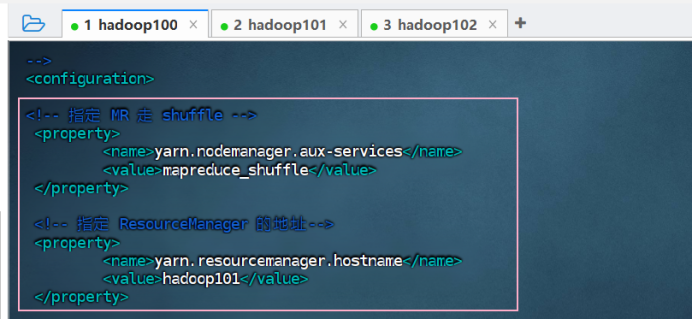
③ 配置 yarn-site.xml
vim yarn-site.xml

<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
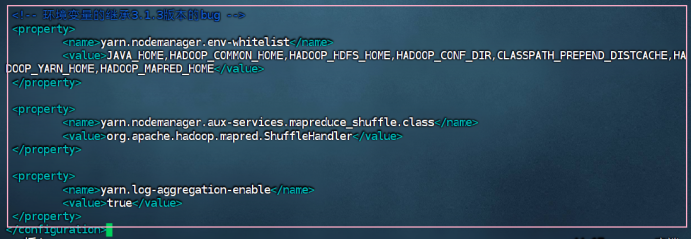
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
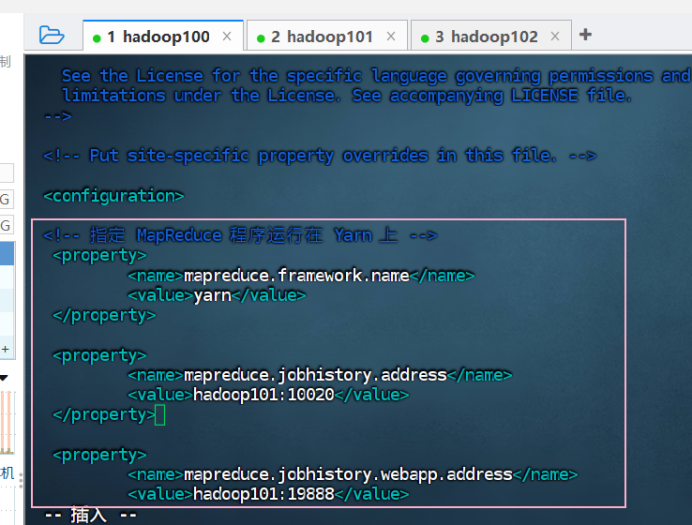
④ 配置 mapred-site.xml (历史服务器)
vim mapred-site.xml

<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
</configuration>
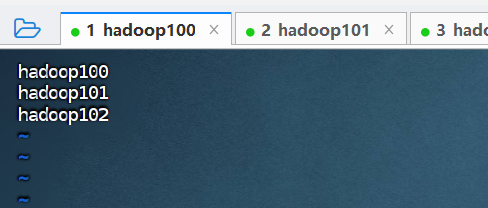
⑤ 配置 slaves 文件,将所有从节点主机名编辑到该文件中。
(根据本实验集群规划,所有主机都充当 DataNode 角色,所以该文件包含集群所有主机名称。根据自己的规划编辑该文件。)
vim workers

hadoop100
hadoop101
hadoop102
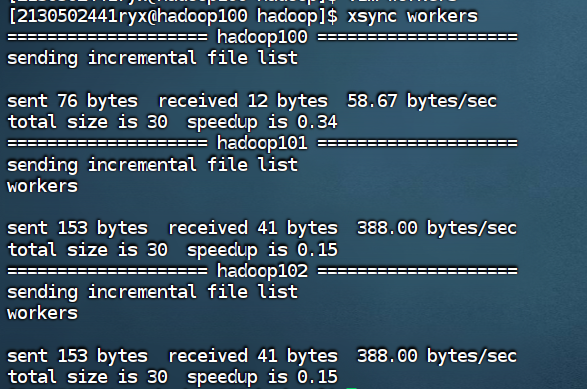
使用xsync进行分发。
xsync workers
****4. 分发配置、格式化并群起集群 ****
4.1将配置好的 hadoop 安装目录复制到集群中其他节点
xsync hadoop/
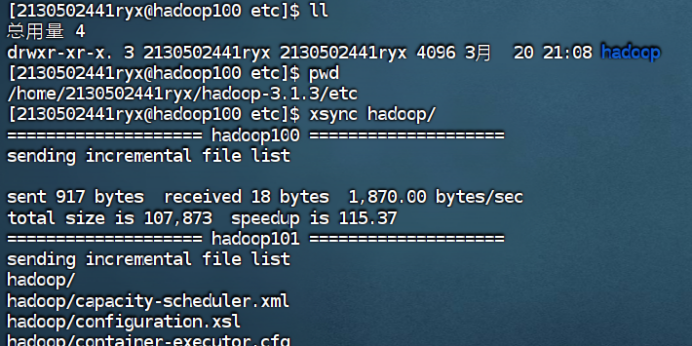
4.2在hadoop101和hadoop102查看分发情况
hadoop101(查看任意一个文件即可)
cat core-site.xml

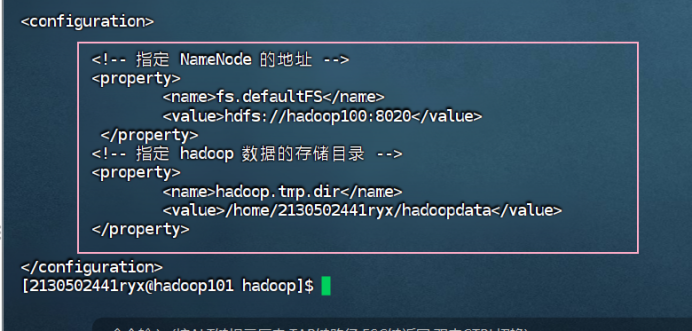
hadoop102

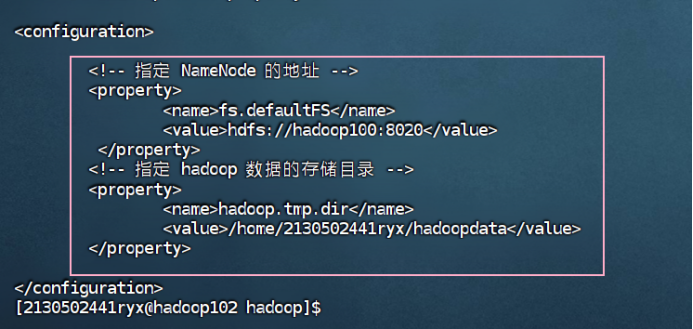
4.3 创建 hadoop 数据目录
**** 所有主机都要创建!!!****
mkdir /home/2130502441ryx/hadoopdata

分发文件夹
xsync /home/2130502441ryx/hadoopdata


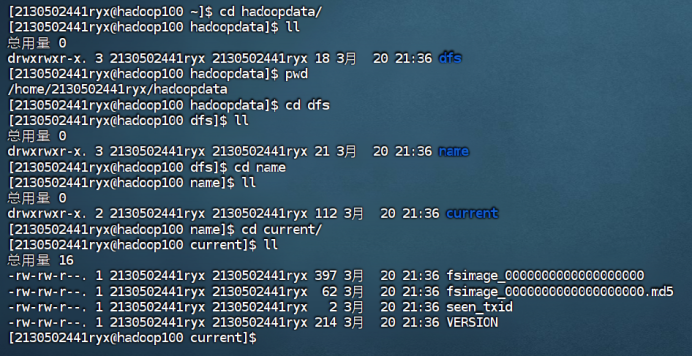
4.4 格式化 NameNode
hdfs namenode -format

Data存储的数据
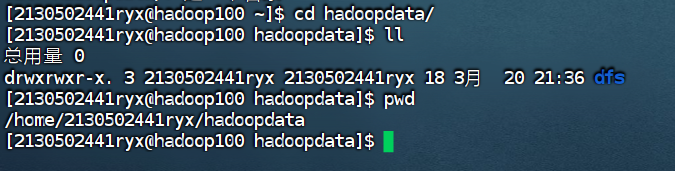
4.****5测试集群服务 ****
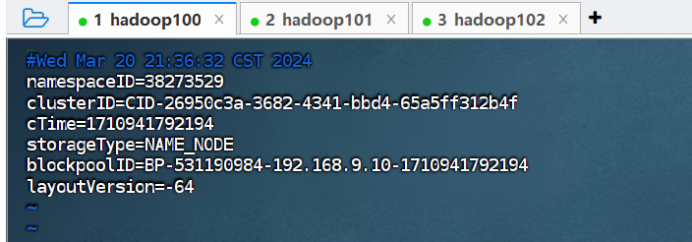
4.6 在 NameNode 节点启动分布式文件系统 HDFS。
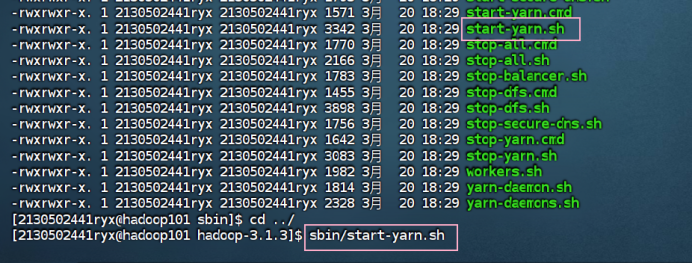
cd sbin/

sbin/start-dfs.sh

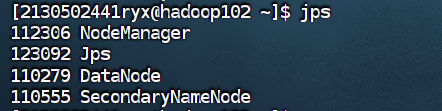
使用 jps 命令查看进程启动情况(集群中每台主机都要查看)
Hadoop100

Hadoop101
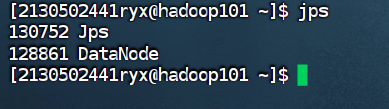
Hadoop102
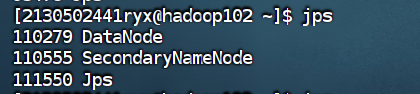
4.7 在 ResourceManager 节点启动分布式资源调度框架 yarn (hadoop101)
sbin/start-yarn.sh

使用 jps 命令查看集群中各主机进程启动状况,请截图在下面的方框中。
Hadoop100
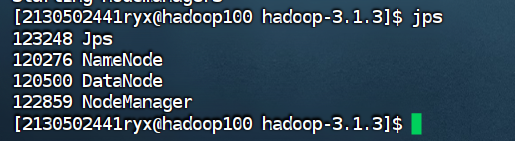
Hadoop101
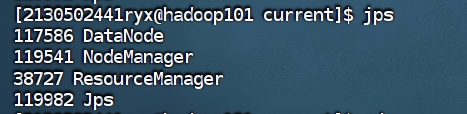
Hadoop102
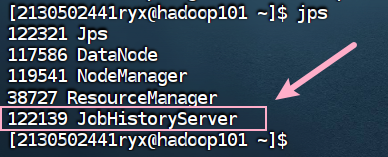
4.8 在配置了历史服务的节点启动历史服务器。 (hadoop101)
bin/mapred --daemon start historyserver

使用 jps 命令查看历史服务器所在主机进程启动状况,请截图在下面的方框。
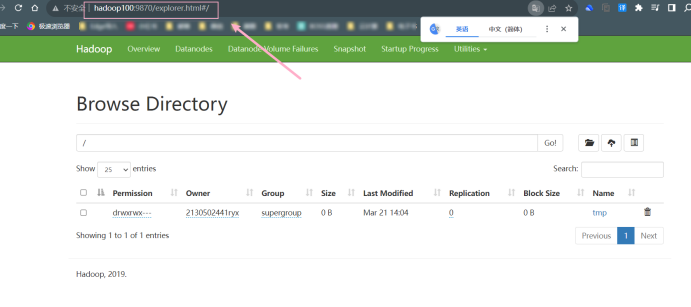
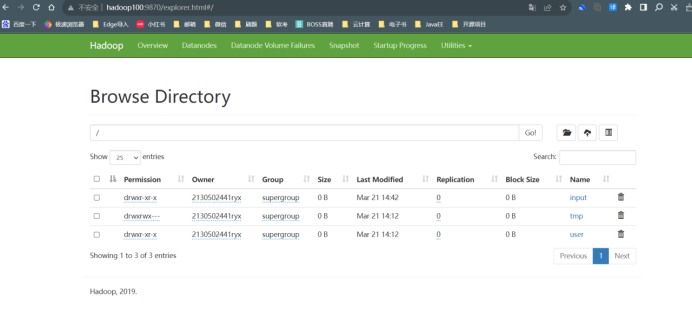
在浏览器 FireFox 中输入 URL http://hadoop100:9870,查看文件系统各项参数。将结果截图在下面。
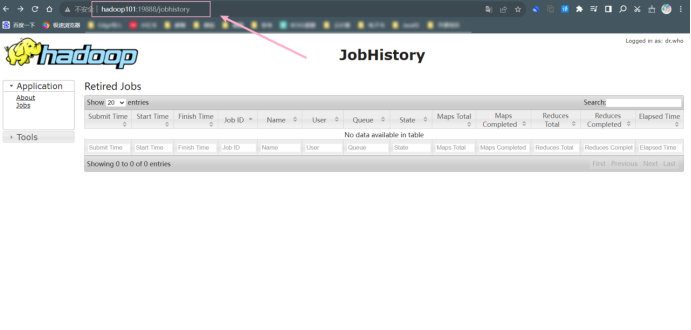
在浏览器 FireFox 中输入 URL http://hadoop101:19888,查看历史信息。将结果截图在下面。
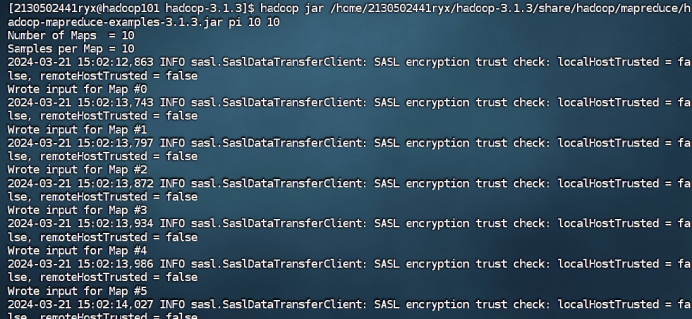
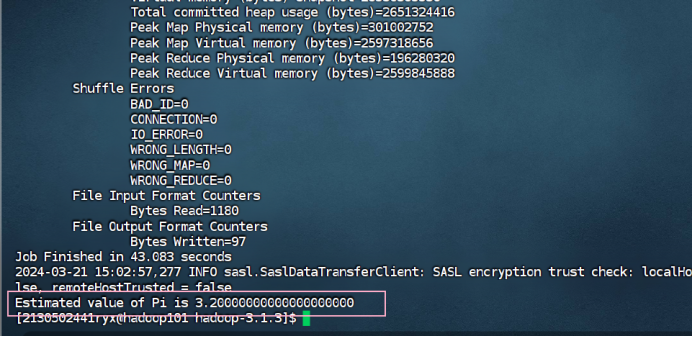
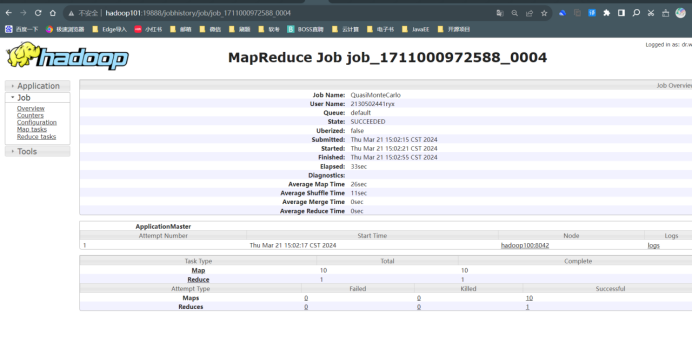
运行程序测试 MapReduce 计算框架:使用以下命令执行 MapReduce 程序 pi, 将执行结果截图在后面的方框中,注意截图中必须包含 Hadoop 账户名称。(学号 +姓名缩写)

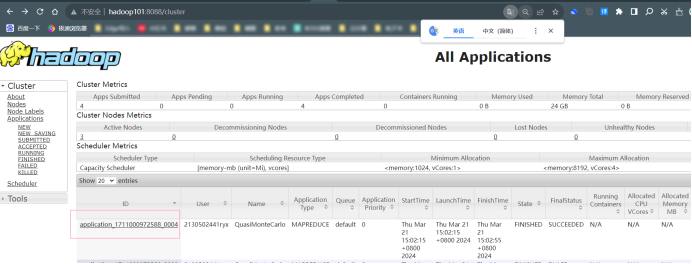
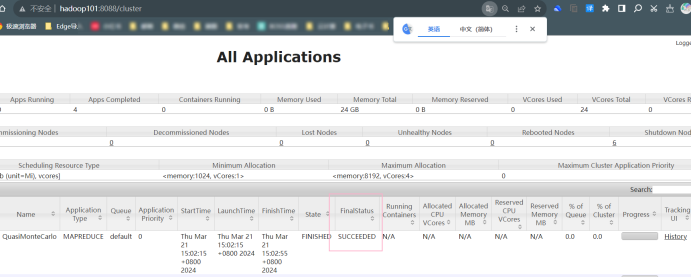
点击History
版权归原作者 布丁椰奶冻 所有, 如有侵权,请联系我们删除。