
配置jdk环境
sudo apt-get update
sudo apt-get install openjdk-8-jdk
出现以下内容代表安装成功,安装目录为/usr/bin/java: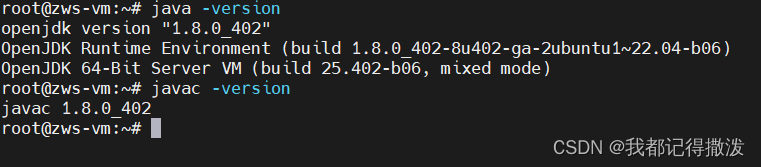
部署HDFS集群
下载hadoop,用清华镜像下载很快,新建个目录输入以下命令
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz
解压安装包

创建软连接hadoop后cd进去,进入hadoop/etc/hadoop下,修改文件配置
配置workers
vim workers后,里面默认只有一个localhost,可以按照需求填写节点主机的ip,这里不做修改。
配置hadoop-env.sh
首先找到JAVA_HOME
sudo update-alternatives --config java

vim打开hadoop-env.sh后添加以下内容,这里JAVA_HOME注意别填错了
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
配置core-site.xml
添加以下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
配置hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
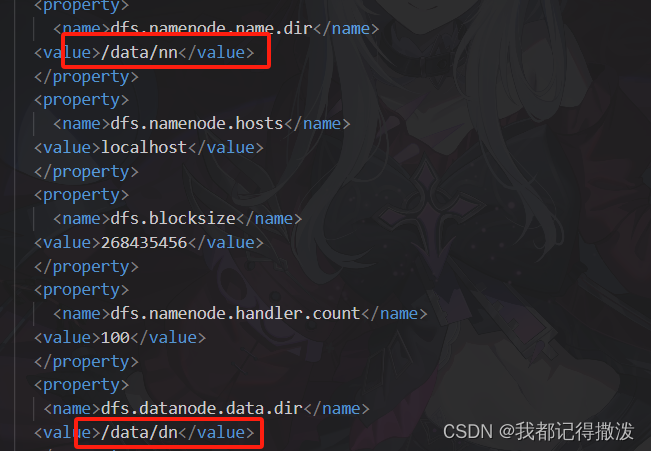
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>localhost</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>
记得创建这两个文件夹
此外可以根据需求把hadoop操作权限授权给非root用户。
现在配置完了,接着初始化文件系统
初始化文件系统
hadoop namenode -format
配置免密登录
ssh-keygen -t rsa -b 4096
输入后疯狂按回车,再输入
ssh-copy-id localhost
至此配置完成。
执行start-dfs.sh可以打开9870端口进入webui就代表成功了。
部署YARN集群
配置mapred-env.sh($HADOOP_HOME/etc/hadoop下
添加以下内容
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
export HADOOP_MAPRED_ROOT_LOGGER=info,RFA
配置mapred-site.xml
添加以下内容
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>localhost:10020</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>localhost:19888</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description></description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
配置yarn-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.log.server.url</name>
<value>http://localhost:19888/jobhistory/logs</value>
<description></description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>localhost:8089</value>
<description>proxy server hostname and port</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description></description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>Comma-separated list of paths on the local filesystem where intermediate data is written.</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>Comma-separated list of paths on the local filesystem where logs are written.</description>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
<description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service that needs to be set for Map Reduce applications.</description>
</property>
</configuration>
启动命令:
start-dfs.sh
start-yarn.sh
启动历史服务器:
mapred --daemon start historyserver
输入jps显示以下进程

至此配置完毕。
本文转载自: https://blog.csdn.net/m0_63500252/article/details/138465542
版权归原作者 我都记得撒泼 所有, 如有侵权,请联系我们删除。
版权归原作者 我都记得撒泼 所有, 如有侵权,请联系我们删除。