
Selenium
- ❤️ 作者简介:大家好我是小鱼干儿♛是一个热爱编程、热爱算法的大三学生,蓝桥杯国赛二等奖获得者
- 🐟 个人主页 :https://blog.csdn.net/qq_52007481
- ⭐ 个人社区:【小鱼干爱编程】
- 🔥 算法专栏:算法竞赛进阶指南
- 💯 刷题网站:市面上的刷题网站有很多如何选择一个适合自己的网站呢,博主给这里推荐一款我常用的刷题网站 👉点击跳转
写在前面:文章有点长,大约一万四千多子,selenium基本的用法都有讲解,也有相应的实例,希望能够能够帮助到大家,有什么不对的地方也欢迎大家提出来
Selenium简介
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,可以按指定的命令自动操作,直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器,现在已经被弃用了,会报警告,但是仍然可以用)。
Selenium 可以根据我们的指令,模拟用户操作浏览器,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。
Selenium 的安装
使用pip安装
pip install Selenium
驱动的安装
- Chrome浏览器驱动:https://registry.npmmirror.com/binary.html?path=chromedriver/
- 火狐浏览器驱动:https://liushilive.github.io/github_selenium_drivers/md/Firefox.html
- PhantomJS 浏览器:https://phantomjs.org/download.html
注意:需要下载的驱动需要和自己电脑上的浏览器版本一样,不一致会导致报错程序无法运行
Selenium基础操作
实例化浏览器对象
from selenium import webdriver
from lxml import etree
# 驱动的位置
bro = webdriver.Chrome(executable_path='./chromedriver.exe')
发送请求
bro.get('http://www.baidu.com/')
page_text = bro.page_source # 获取页面源码
tree = etree.HTML(page_text)# 解析源码
title = tree.xpath('')# 使用xpath提取数据
使用百度进行自动搜索
实现功能有
- 自动填充关键字并搜索
- 截图并保存
- 清空内容重新搜索
- 获取当前网页的cookies值和url
import time
from selenium import webdriver
# 路径放自己驱动的路径
driver = webdriver.webdriver.Chrome(executable_path=r"./chromedriver.exe")
driver.get('http://www.baidu.com/')
data = driver.find_element_by_id("wrapper").text
print(data)# 输出文字print(driver.title)# 网页的标题# warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '# selenium已经放弃Phantomjs,建议使用谷歌或者火狐的无界面浏览器。# 搜索长城相关的内容
driver.find_element_by_id('kw').send_keys(u'长城')#在搜索康框中填写内容
driver.save_screenshot('百度.png')# 截屏
driver.find_element_by_id('su').click()# 点击搜索按钮
time.sleep(1)# 暂停1秒,给浏览器加载一定的时间
driver.save_screenshot("搜索.png")# 调用键盘按键操作,首先引入Keys包from selenium.webdriver.common.keys import Keys
# 通过模拟键盘按键操作# Ctrl + A 全选
driver.find_element_by_id('kw').send_keys(Keys.CONTROL,'a')# 剪切
driver.find_element_by_id('kw').send_keys(Keys.CONTROL,'x')# 在输入框输入 新的搜索锁关键字python
driver.find_element_by_id('kw').send_keys('python')# 模拟 Enter
driver.find_element_by_id('kw').send_keys(Keys.RETURN)
time.sleep(2)
driver.save_screenshot("新搜索.png")# 清除输入框内容
driver.find_element_by_id('kw').click()# 获取当前页面的Cookie# 使用get_cookies()方法获当前页面的Cookieprint("cookies:",driver.get_cookies())# 获取当前url# 使用current_urlprint('url:',driver.current_url)# 关闭当前页面,# close() 方法关闭当前页面,如果只有一个页面,就会关闭浏览器
driver.close()
定位UI元素
find_element_by_id()# 通过id
find_element_by_name()# 通过name标签值
find_element_by_class_name()# 通过class_name标签值
find_element_by_css_selector()# 通过css样式名称
find_element_by_link_text()# 通过链接文本定位
find_element_by_xpath()# 通过Xpath来定位页面元素
find_element_by_partial_link_text()# 通过部分链接文本定位
find_element_by_tag_name()# 通过标签名称定位
导包和实例浏览器对象
浏览器的需要可以根据需要进行选择,一般跟编写的代码都没有区别
在测试初期可以选择有界面的,这样方便观察,对项目的编写也是有很大帮助的
在项目测试或者上线的时候可以换成无头浏览器,这样可以提高效率
import time
from selenium import webdriver
# 这里的浏览器驱动推荐大家使用Chrome的
driver = webdriver.PhantomJS(executable_path="./phantomjs-2.1.1-windows/bin/phantomjs.exe")
driver.get('http://www.baidu.com/')
- find_element_by_id() # 通过id
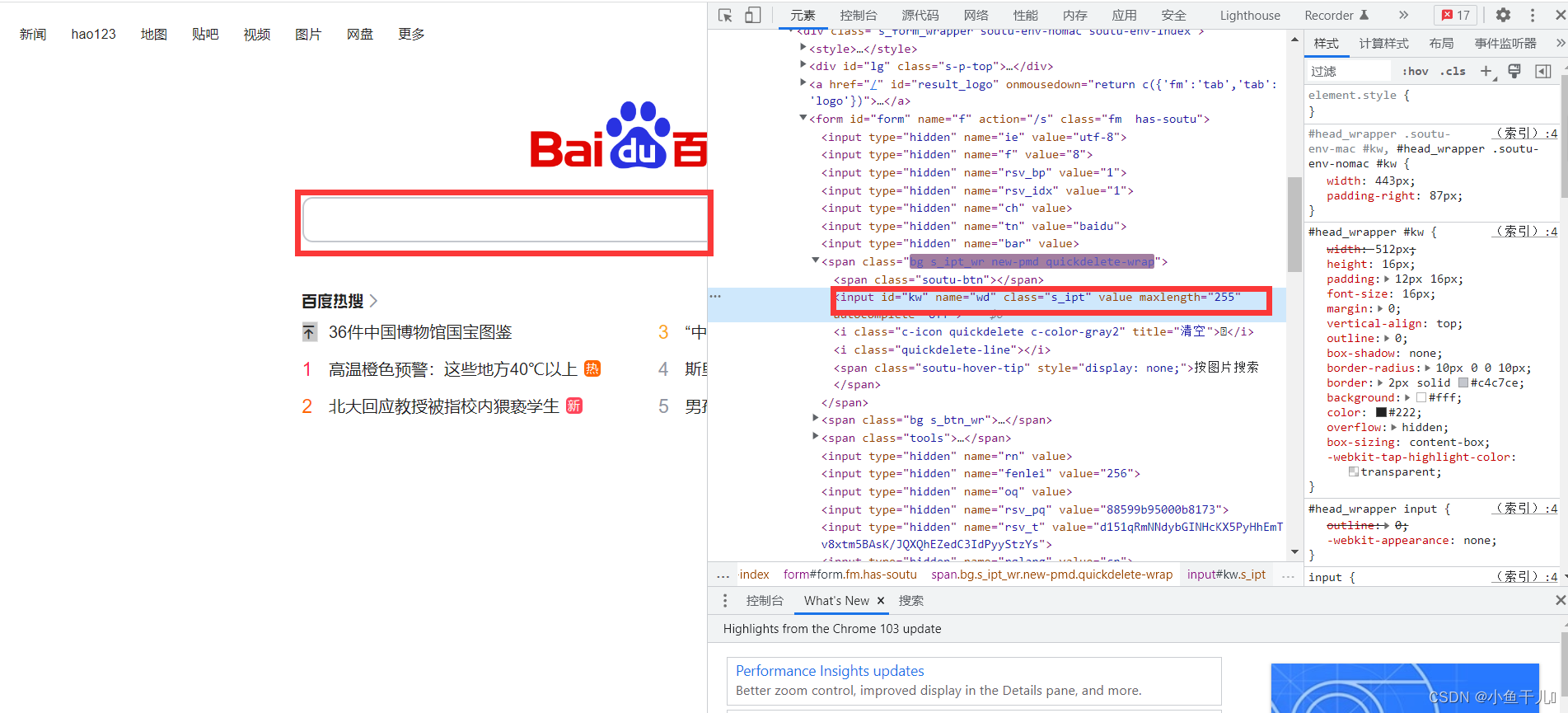
定位到搜索框并在搜索框中输入要搜索内容
element = driver.find_element_by_id("kw")
element.send_keys(u'你好')
time.sleep(2)
driver.save_screenshot('t1.png')
第二种方式
from selenium.webdriver.common.by import By
element = driver.find_element(by=By.ID,value='kw')
结果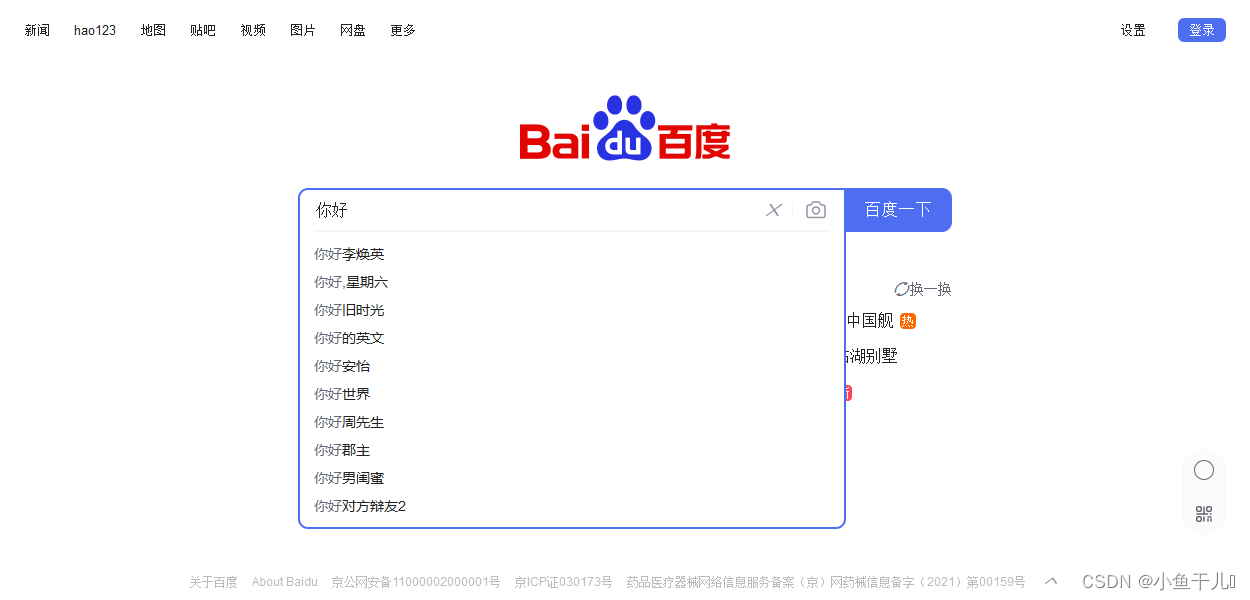
- find_element_by_class_name() # 通过class_name标签值
选中百度以下,然后点击
driver.find_element_by_class_name('s_btn').click()# 选中并点击
另一种方式
driver.find_element(by=By.CLASS_NAME,value='s_btn').click()
没有图片是加载时间不够,可以考延长
time.sleep()
的时间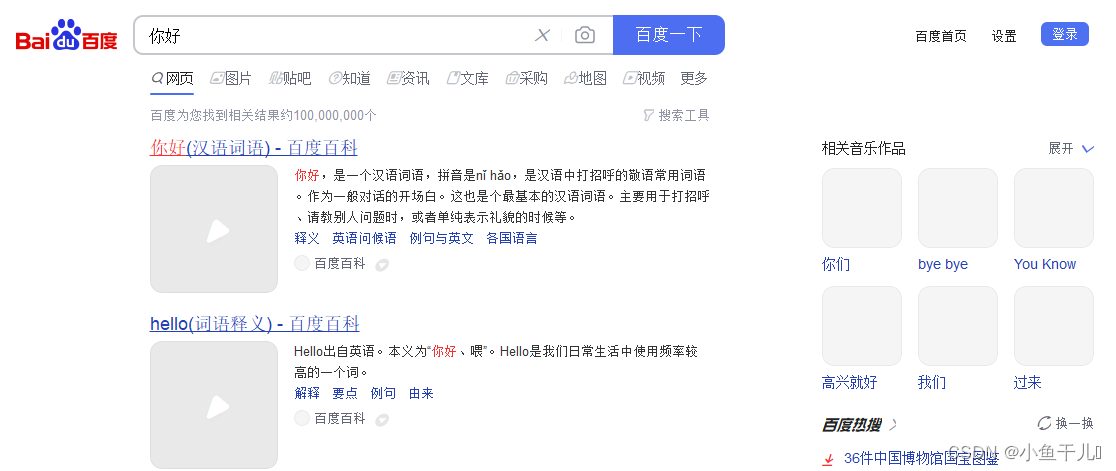
下面的都是类似的
- find_element_by_name() # 通过name标签值
方式一
driver.find_element_by_name('wd')
方式二
driver.find_element(by=By.NAME,value='title-content')
- find_element_by_link_text() # 通过链接文本定位
driver.find_element_by_link_text('图片')# 通过链接文本定位
driver.find_element(by=By.LINK_TEXT,value='图片')
- find_element_by_xpath() # 通过Xpath来定位页面元素 xpath也可以根据浏览器的工具进行复制,不过记住也不能完全相信浏览器,必要时需要看源码
driver.find_element_by_xpath('//*[@id="kw"]')# 通过Xpath来定位页面元素
driver.find_element(by=By.XPATH,value='//*[@id="kw"]')
- find_element_by_partial_link_text() # 通过部分链接文本定位
driver.find_element_by_partial_link_text('图')# 通过部分链接文本定位
driver.find_element(by=By.PARTIAL_LINK_TEXT,value='图')
- find_element_by_tag_name() # 通过标签名称定位
driver.find_element_by_tag_name('body')# 通过标签名称定位
driver.find_element(by=By.TAG_NAME,value='body')
- find_element_by_css_selector() # 通过css样式名称 这个css样式选择比较繁琐,这里可以根据浏览器自带的工具快捷选择
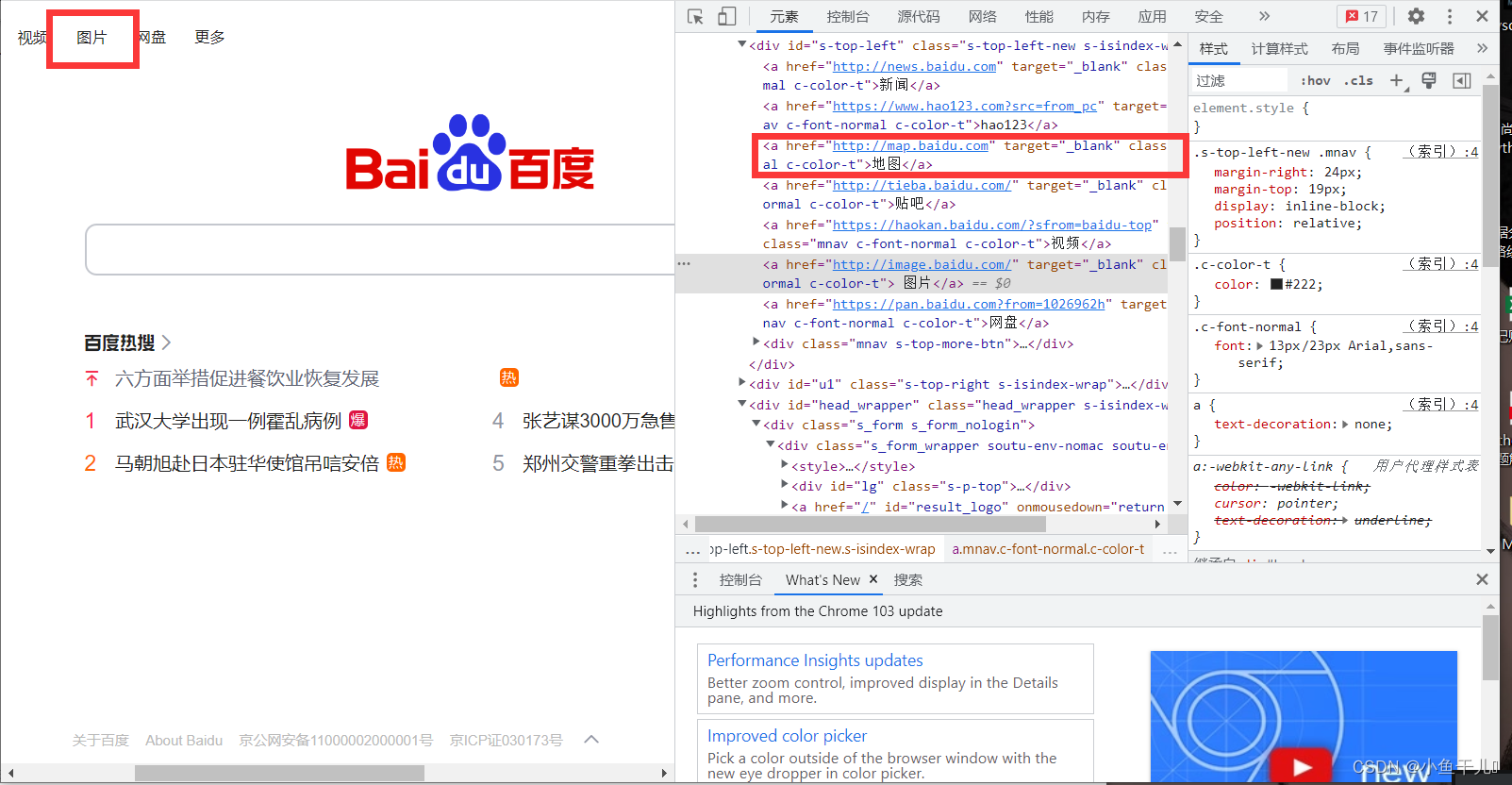
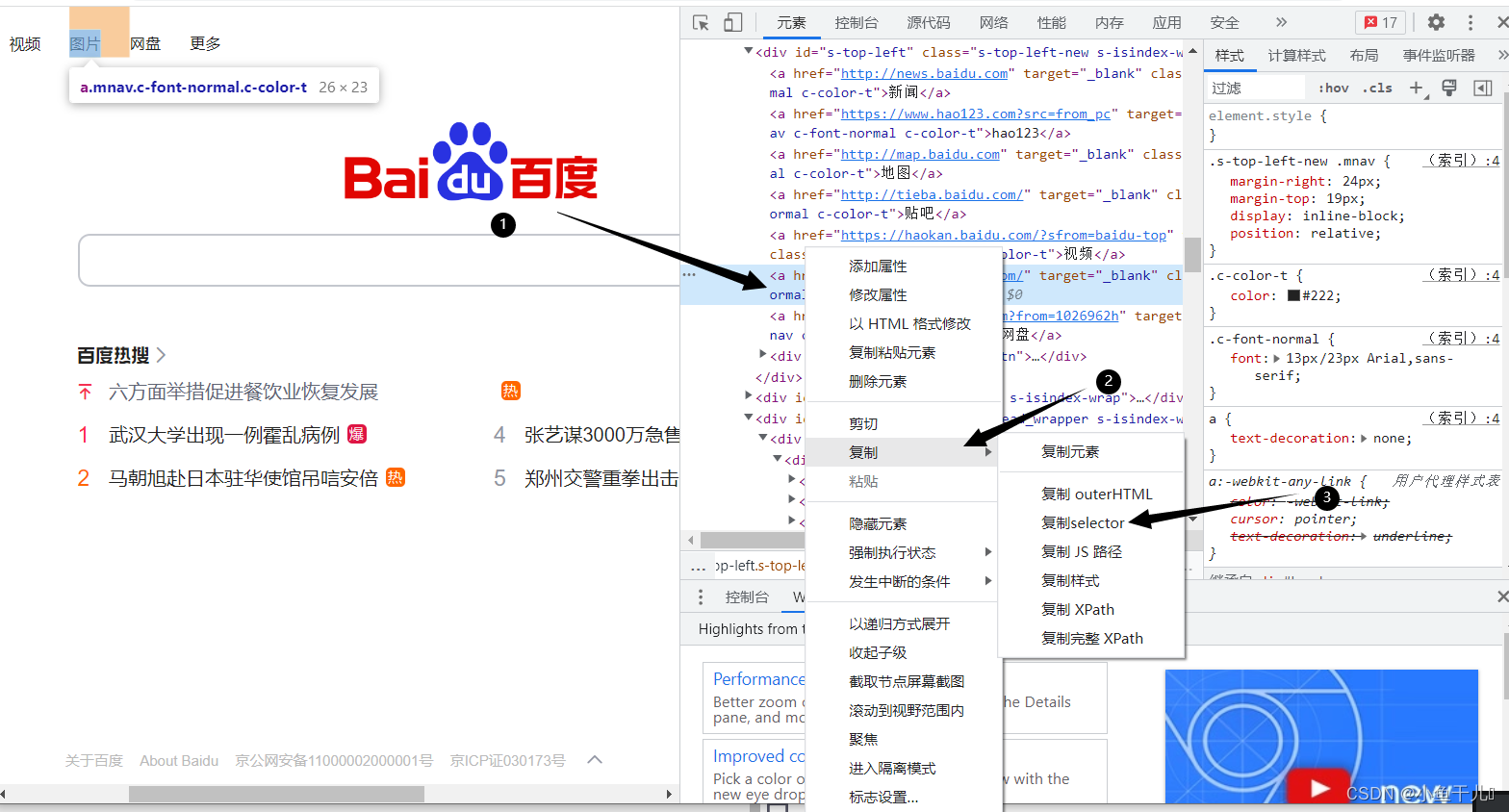
driver.find_element_by_css_selector('#s-top-left > a:nth-child(6)').click()# 通过css
会打开一个新的窗口,但是浏览器所在的页面仍是原来的页面,关于切换页面的切换下面有方法
鼠标动作链
有些时候,需要在页面上模拟一些鼠标的操作,比如双击,右击,拖动,甚至按住不懂,这些操作都可以使用ActionChains类来实现
将鼠标移动到 ’换一换‘ 的位置
ac = driver.find_element_by_xpath('//*[@id="hotsearch-refresh-btn"]/span')
ActionChains(driver).move_to_element(ac).perform()

移动后’换一换’变蓝说明鼠标已经移动到该位置
移动并点击(左)
ac = driver.find_element_by_xpath('//*[@id="hotsearch-refresh-btn"]/span')# perform() 执行前面的所有动作# 方式一
ActionChains(driver).move_to_element(ac).click().perform()# 方式二
ActionChains(driver).click(ac).perform()
双击(左)
方式一
ActionChains(driver).move_to_element(ac).double_click().perform()
方式二
ActionChains(driver).double_click(ac).perform()
右击
# 移动后右击
ActionChains(driver).move_to_element(ac).context_click().perform()# 直接在该位置右击
ActionChains(driver).context_click(ac).perform()
左键单击并保持
方式1
ActionChains.move_to_element(ac).click_and_hold().perform()
方式2
ActionChains(driver).click_and_hold(ac).perform()
拖动元素
这个百度没有相应的内容,就没有相应的实例
ActionChains.drag_and_drop(ac,ac2).perform()
键盘常用
- send_keys(Keys.BACK_SPACE) 删除键(BackSpace)
- send_keys(Keys.SPACE) 空格键(Space)
- send_keys(Keys.TAB) 制表键(Tab)
- send_keys(Keys.ESCAPE) 回退键(Esc)
- send_keys(Keys.ENTER) 回车键(Enter)
- send_keys(Keys.CONTROL,‘a’) 全选(Ctrl+A)
- send_keys(Keys.CONTROL,‘c’) 复制(Ctrl+C)
- send_keys(Keys.CONTROL,‘x’) 剪切(Ctrl+X)
- send_keys(Keys.CONTROL,‘v’) 粘贴(Ctrl+V)
- element.send_keys() # 输入框中输入数据
下拉列表,填充表单
非select元素,鼠标悬浮,以后展现
这里的项目实例是百度首页的设置按钮, 设置 > 搜索设置
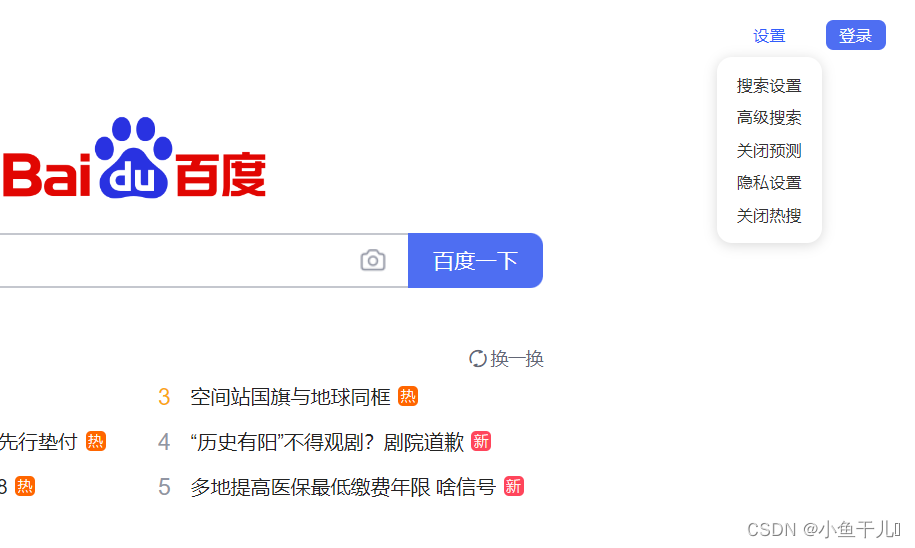
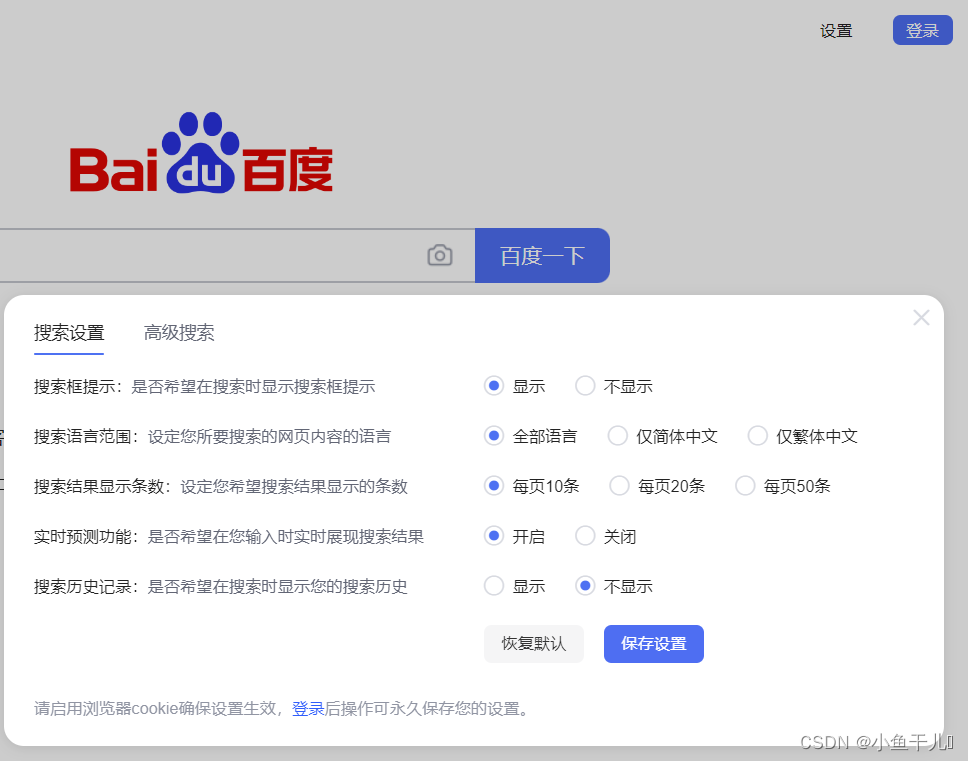
小技巧:关于这种悬浮的,无法选择xpath路径的问题,我们只需要在元素中 按 Ctrl+F 然后搜索需要定位的内容,最后复制Xpath路径
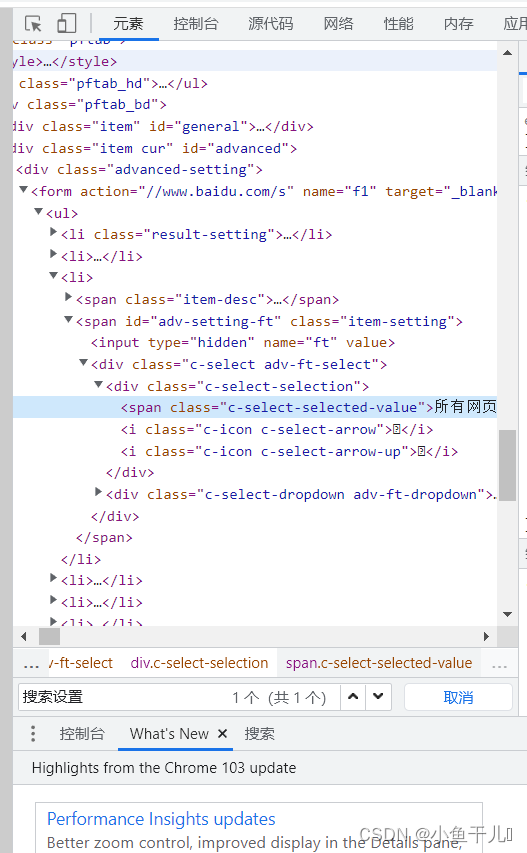
主要的思路还是控制自己的鼠标,让鼠标像人一样进行操作
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
driver = webdriver.Chrome(executable_path=r"D:\Python work space\ Reptile\抖音selenium\chromedriver.exe")
driver.get('http://www.baidu.com/')
time.sleep(2)
ac = driver.find_element_by_xpath('//*[@id="s-usersetting-top"]')
ActionChains(driver).move_to_element(ac).perform()# 移动到设置上面
ac2 = driver.find_element_by_xpath('//*[@id="s-user-setting-menu"]/div/a[1]')# 搜索设置的xpath
ActionChains(driver).move_to_element(ac2).click().perform()# 移动并点击
select元素
因为没有找到就自己写了一个
<!DOCTYPEhtml><html><body><selectid="status"><optionvalue="选项一">选项一</option><optionvalue="选项二">选项二</option><optionvalue="选项三">选项三</option><optionvalue="选项四">选项四</option></select></body></html>
这个在发送get请求时,填html文件的路径就可以
from selenium.webdriver.support.ui import Select
# 找到下拉框元素
select = Select(driver.find_element_by_id('status'))# 选择一个下拉框的元素
select.select_by_index(1)# 根据索引选择,索引从0开始
select.select_by_value('选项一')# 根据value进行选择
select.select_by_visible_text('选项三')# 根据文本内容选择
其他一些常用功能
弹窗处理
常见的弹窗
- alert:用来提示
- confirm:用来确认
- prompt:输入内容
处理弹框的方法
- driver.switch_to_alert() 这个方法已经被弃用了,会有警告,但是仍然可以使用
- driver.switch_to.alert 推荐用这个
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"D:\Python work space\ Reptile\抖音selenium\chromedriver.exe")
driver.get('https://cdn2.byhy.net/files/selenium/test4.html')#看其他博客找来的网址
driver.find_element_by_xpath('//*[@id="b1"]').click()
s = driver.switch_to.alert
print(s.text)# 输出弹出框中的文字
s.accept()# 点击接受
driver.find_element_by_xpath('//*[@id="b2"]').click()
confirm = driver.switch_to.alert
print(confirm.text)# 输出文本
confirm.accept()# 点击确认
confirm.dismiss()# 点击取消
driver.find_element_by_id('b3').click()
prompt = driver.switch_to.alert
print(prompt.text)# 原来输入框中默认的内容
prompt.send_keys("测试成功")# 向输入框中输入新内容
prompt.accept()# accept() 接受# dismiss() 取消# text() 显示文本# send_keys() 输入内容
页面切换
一个浏览器会有多个窗口,我们在做测试或者其他内容时也需要进行窗口的切换
打开新窗口以后,窗口
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
driver = webdriver.Chrome(executable_path=r"D:\Python work space\ Reptile\抖音selenium\chromedriver.exe")
driver.get('http://www.baidu.com/')
time.sleep(2)
driver.find_element_by_xpath('//*[@id="s-top-left"]/a[6]').click()print(driver.window_handles)# ['CDwindow-B2E0B1FD44171195E4F38465C3AE2168', 'CDwindow-84141EE6D8C06BE4B8A9EBABC999B427']for i in driver.window_handles:print(i)
driver.switch_to.window(driver.window_handles[1])
页面的前进和后退
driver.forward()# 前进
driver.back()# 后退
获取页面的Cookies
driver.get_cookies()
获取页面的url
driver.current_url
页面等待
现阶段越来越多的网站使用Ajax技术,异步加载,还有网络环境的问题,会导致网页的加载是不确定性的,如果页面响应时间过长,某个元素还没有被加载出来,就被代码引用这样就会引起异常
为了解决这个问题,selenium提供了两种等待方式,显式等待,隐式等待
固定等待
python自带的time.sleep(),在开发自动化框架的过程中,最忌讳使用time.sleep()方法,虽然可以自定义时间,但是无论网络是否良好,都会按照指定的等待时间进行等待,而在设置停止时间时,也需要要根据最大等待时间设置,这样大大延长了项目的运行效率
我们在开始测试的过程是可以用的,但是最后一定要替换掉
import time
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"D:\Python work space\ Reptile\抖音selenium\chromedriver.exe")
driver.get('http://www.baidu.com/')
time.sleep(1)
driver.find_element_by_id('kw').send_keys("python")
time.sleep(1)
driver.find_element_by_id('su').click()
time.sleep(1)
driver.quit()
显式等待
显式等待是指指定某一条件,直到这个条件成立以后才能继续执行,需要设置最长等待时间(秒),如果超过这个最长时间还没有找到指定元素就会报错
显示等待需要用WebDriverWait类来实现,是项目中使用较多的方式
两种调用方式
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.wait import WebDriverWait
参数参数说明driverWebDriver的驱动程序timeout最长超时时间poll_frequency休眠间隔的时间,默认为0.5秒ignored_exceptions超时后会抛出异常信息 ,是否忽略
一共有两个方法
WebDriverWait.until(method,message)
WebDriverWait.until_not(method,message)
- method在等待时间,每隔一段时间调用这个传入的方法
- message 如果超时抛出TimeoutException,将message传入异常
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome(executable_path=r"D:\Python work space\ Reptile\抖音selenium\chromedriver.exe")
driver.get('http://www.baidu.com/')
wait = WebDriverWait(driver,2)
wait.until(EC.title_is("百度一下,你就知道"))#根据标题是否加载出来判断是否登录# 这个等待条件还有很多,具体使用哪个可以灵活的换,另外还需要注意返回值
driver.find_element_by_id('kw').send_keys("python")
driver.find_element_by_id('su').click()
driver.quit()
隐式等待
隐式等待就是设置一个最大等待时间(秒),在定位元素时对所有元素设置超时时间,超出时间则抛出异常
隐式等待对整个driver周期都起作用,在最开始设置一次就可以了
缺点:不是很灵活,有些js代码加载很慢,对实际需求也没有帮助,会拖慢效率
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r"D:\Python work space\ Reptile\抖音selenium\chromedriver.exe")
driver.implicitly_wait(10)# 最长等待时间为10秒
driver.get('http://www.baidu.com/')
driver.find_element_by_id('kw').send_keys("python")
driver.find_element_by_id('su').click()
driver.quit()
网易登录项目实战
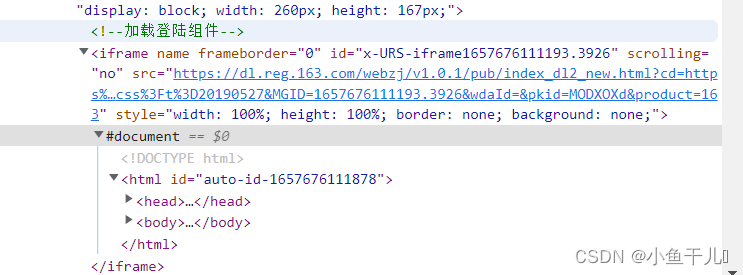
分析网易的登录采用了 iframe,又叫浮动帧标记,是内嵌的网页元素,可以将一个html文件嵌入到另一个html文件中显示。这种方法我们不能直接定位里面的元素,需要先切换到iframe里面,
代码如下
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 这一部分是用来伪装浏览器的,避免网站发现
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option('excludeSwitches',['enable-automation'])
chrome_options.add_experimental_option('useAutomationExtension',False)
chrome_options.add_argument('lang=zh-CN,zh,zh-TW,en-US,en')
chrome_options.add_argument("disable-blink-features=AutomationControlled")
driver = webdriver.Chrome(executable_path=r"D:\Python work space\ Reptile\抖音selenium\chromedriver.exe",options=chrome_options)
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument',{'source':'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'})
driver.get('https://www.163.com')
wait = WebDriverWait(driver,2)# 显示等待方式一,先声明对象,后判断条件
wait.until(EC.title_is('网易'))
ActionChains(driver).move_to_element(driver.find_element_by_xpath('//*[@id="js_N_nav_login_title"]')).perform()# 鼠标移动到登录并悬浮
iframe = driver.find_element_by_xpath('/html/body/div[1]/div[1]/div/div/div/div[2]/div[2]/div[1]/div[1]/div/iframe')# 显式等待方式二 ,直接一步完成,原理都一样
WebDriverWait(driver,3).until(EC.frame_to_be_available_and_switch_to_it(iframe))# frame_to_be_available_and_switch_to_it判断该frame是否可以switch进去,如果可以的话,返回True并且switch进去,否则返回False# switch进入iframe两种方式,推荐使用上面的# iframe = driver.find_element_by_xpath('/html/body/div[1]/div[1]/div/div/div/div[2]/div[2]/div[1]/div[1]/div/iframe')# wait.until(EC.frame_to_be_available_and_switch_to_it(iframe))# driver.switch_to.frame(iframe)
user = driver.find_element_by_name('email')
user.send_keys('账号,邮箱')# 输入自己的邮箱
password = driver.find_element_by_name('password')# time.sleep(3)
password.send_keys('密码')# 输入自己的密码
time.sleep(1)# 可以不要
login = driver.find_element_by_xpath('//*[@id="dologin"]').click()# 点击登录按键#退出iframe
driver.switch_to.default_content()# 退出iframe
要点
- 伪装浏览器,防止被发现
- 使用显示等待,避免元素没有加载出来就使用
- 因为登录页面是用的 iframe,需要先switch to 进入iframe中,然后再定位元素
- 登录完成以后需要退出iframe
版权归原作者 小鱼干儿♛ 所有, 如有侵权,请联系我们删除。