
参考博客:
Datax 二次开发插件详细过程_键盘上的艺术家w的博客-CSDN博客_datax kafkareader
简书-DataX kafkawriter
背景
基于阿里开源DataX3.0版本,开发kafka的读写驱动,可以实现从mysql、postgresql抽取数据到kafka,从kafka 消费消息写入hdfs等功能。
1、整体模块代码结构
1、kafkareader
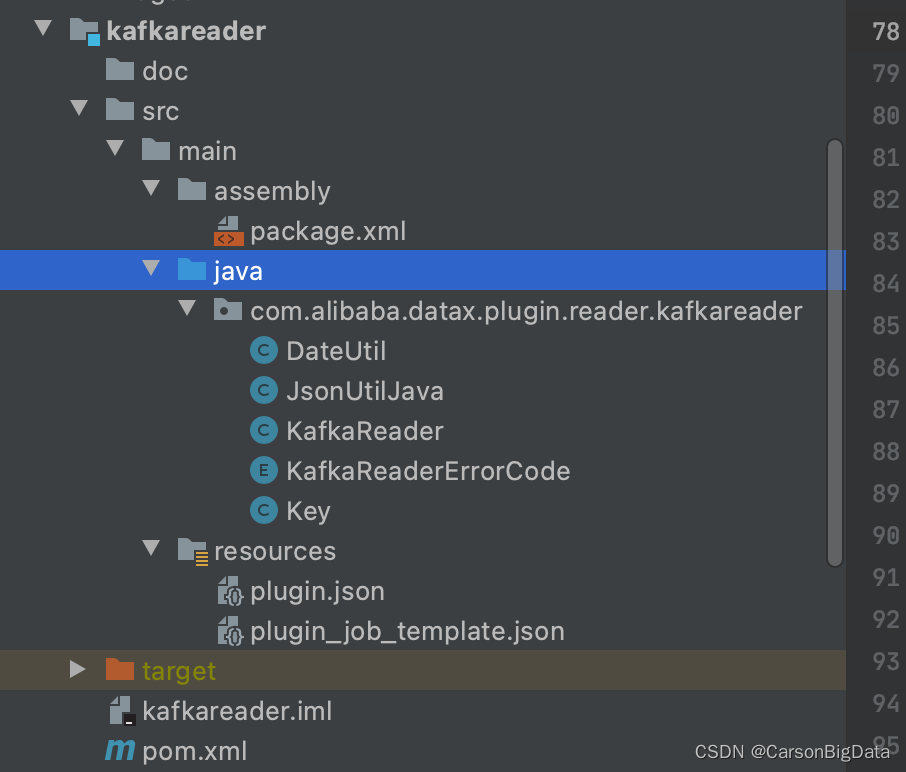
2、kafkawriter

3、package.xml
<fileSet>
<directory>kafkareader/target/datax/</directory>
<includes>
<include>**/*.*</include>
</includes>
<outputDirectory>datax</outputDirectory>
</fileSet>
<fileSet>
<directory>kafkawriter/target/datax/</directory>
<includes>
<include>**/*.*</include>
</includes>
<outputDirectory>datax</outputDirectory>
</fileSet>
4、pom.xml
<module>kafkareader</module>
<module>kafkawriter</module>
2、kafkareader模块代码
package.xml
<assembly
xmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0 http://maven.apache.org/xsd/assembly-1.1.0.xsd">
<id></id>
<formats>
<format>dir</format>
</formats>
<includeBaseDirectory>false</includeBaseDirectory>
<fileSets>
<fileSet>
<directory>src/main/resources</directory>
<includes>
<include>plugin.json</include>
</includes>
<outputDirectory>plugin/reader/kafkareader</outputDirectory>
</fileSet>
<fileSet>
<directory>target/</directory>
<includes>
<include>kafkareader-0.0.1-SNAPSHOT.jar</include>
</includes>
<outputDirectory>plugin/reader/kafkareader</outputDirectory>
</fileSet>
</fileSets>
<dependencySets>
<dependencySet>
<useProjectArtifact>false</useProjectArtifact>
<outputDirectory>plugin/reader/kafkareader/libs</outputDirectory>
<scope>runtime</scope>
</dependencySet>
</dependencySets>
</assembly>
DateUtil.java
package com.alibaba.datax.plugin.reader.kafkareader;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* @Description: TODO
* @Author: chenweifeng
* @Date: 2022年09月05日 下午1:43
**/
public class DateUtil {
/**
* 时间转 yyyy-MM-dd HH:mm:ss 字符串
*
* @param date
* @return
*/
public static String targetFormat(Date date) {
String dateString = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(date);
return dateString;
}
/**
* 时间转字符串
*
* @param date
* @param pattern
* @return
*/
public static String targetFormat(Date date, String pattern) {
String dateString = new SimpleDateFormat(pattern).format(date);
return dateString;
}
}
JsonUtilJava.java
package com.alibaba.datax.plugin.reader.kafkareader;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.TypeReference;
import java.util.HashMap;
/**
* @Description: TODO
* @Author: chenweifeng
* @Date: 2022年09月05日 下午1:47
**/
public class JsonUtilJava {
/**
* json转hashmap
*
* @param jsonData
* @return
*/
public static HashMap<String, Object> parseJsonStrToMap(String jsonData) {
HashMap<String, Object> hashMap = JSONObject.parseObject(jsonData, new TypeReference<HashMap<String, Object>>() {
});
return hashMap;
}
}
KafkaReader.java
package com.alibaba.datax.plugin.reader.kafkareader;
import com.alibaba.datax.common.element.Record;
import com.alibaba.datax.common.element.StringColumn;
import com.alibaba.datax.common.exception.DataXException;
import com.alibaba.datax.common.plugin.RecordSender;
import com.alibaba.datax.common.spi.Reader;
import com.alibaba.datax.common.util.Configuration;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.time.Duration;
import java.util.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class KafkaReader extends Reader {
public static class Job extends Reader.Job {
private static final Logger LOG = LoggerFactory.getLogger(Job.class);
private Configuration originalConfig = null;
@Override
public void init() {
this.originalConfig = super.getPluginJobConf();
// warn: 忽略大小写
String topic = this.originalConfig.getString(Key.TOPIC);
Integer partitions = this.originalConfig.getInt(Key.KAFKA_PARTITIONS);
String bootstrapServers = this.originalConfig.getString(Key.BOOTSTRAP_SERVERS);
String groupId = this.originalConfig.getString(Key.GROUP_ID);
Integer columnCount = this.originalConfig.getInt(Key.COLUMNCOUNT);
String split = this.originalConfig.getString(Key.SPLIT);
String filterContaintsStr = this.originalConfig.getString(Key.CONTAINTS_STR);
String filterContaintsFlag = this.originalConfig.getString(Key.CONTAINTS_STR_FLAG);
String conditionAllOrOne = this.originalConfig.getString(Key.CONDITION_ALL_OR_ONE);
String parsingRules = this.originalConfig.getString(Key.PARSING_RULES);
String writerOrder = this.originalConfig.getString(Key.WRITER_ORDER);
String kafkaReaderColumnKey = this.originalConfig.getString(Key.KAFKA_READER_COLUMN_KEY);
LOG.info("topic:{},partitions:{},bootstrapServers:{},groupId:{},columnCount:{},split:{},parsingRules:{}",
topic, partitions, bootstrapServers, groupId, columnCount, split, parsingRules);
if (null == topic) {
throw DataXException.asDataXException(KafkaReaderErrorCode.TOPIC_ERROR,
"没有设置参数[topic].");
}
if (partitions == null) {
throw DataXException.asDataXException(KafkaReaderErrorCode.PARTITION_ERROR,
"没有设置参数[kafka.partitions].");
} else if (partitions < 1) {
throw DataXException.asDataXException(KafkaReaderErrorCode.PARTITION_ERROR,
"[kafka.partitions]不能小于1.");
}
if (null == bootstrapServers) {
throw DataXException.asDataXException(KafkaReaderErrorCode.ADDRESS_ERROR,
"没有设置参数[bootstrap.servers].");
}
if (null == groupId) {
throw DataXException.asDataXException(KafkaReaderErrorCode.KAFKA_READER_ERROR,
"没有设置参数[groupid].");
}
if (columnCount == null) {
throw DataXException.asDataXException(KafkaReaderErrorCode.PARTITION_ERROR,
"没有设置参数[columnCount].");
} else if (columnCount < 1) {
throw DataXException.asDataXException(KafkaReaderErrorCode.KAFKA_READER_ERROR,
"[columnCount]不能小于1.");
}
if (null == split) {
throw DataXException.asDataXException(KafkaReaderErrorCode.KAFKA_READER_ERROR,
"[split]不能为空.");
}
if (filterContaintsStr != null) {
if (conditionAllOrOne == null || filterContaintsFlag == null) {
throw DataXException.asDataXException(KafkaReaderErrorCode.KAFKA_READER_ERROR,
"设置了[filterContaintsStr],但是没有设置[conditionAllOrOne]或者[filterContaintsFlag]");
}
}
if (parsingRules == null) {
throw DataXException.asDataXException(KafkaReaderErrorCode.KAFKA_READER_ERROR,
"没有设置[parsingRules]参数");
} else if (!parsingRules.equals("regex") && parsingRules.equals("json") && parsingRules.equals("split")) {
throw DataXException.asDataXException(KafkaReaderErrorCode.KAFKA_READER_ERROR,
"[parsingRules]参数设置错误,不是regex,json,split其中一个");
}
if (writerOrder == null) {
throw DataXException.asDataXException(KafkaReaderErrorCode.KAFKA_READER_ERROR,
"没有设置[writerOrder]参数");
}
if (kafkaReaderColumnKey == null) {
throw DataXException.asDataXException(KafkaReaderErrorCode.KAFKA_READER_ERROR,
"没有设置[kafkaReaderColumnKey]参数");
}
}
@Override
public void preCheck() {
init();
}
@Override
public List<Configuration> split(int adviceNumber) {
List<Configuration> configurations = new ArrayList<Configuration>();
Integer partitions = this.originalConfig.getInt(Key.KAFKA_PARTITIONS);
for (int i = 0; i < partitions; i++) {
configurations.add(this.originalConfig.clone());
}
return configurations;
}
@Override
public void post() {
}
@Override
public void destroy() {
}
}
public static class Task extends Reader.Task {
private static final Logger LOG = LoggerFactory.getLogger(Task.class);
//配置文件
private Configuration readerSliceConfig;
//kafka消息的分隔符
private String split;
//解析规则
private String parsingRules;
//是否停止拉去数据
private boolean flag;
//kafka address
private String bootstrapServers;
//kafka groupid
private String groupId;
//kafkatopic
private String kafkaTopic;
//kafka中的数据一共有多少个字段
private int count;
//是否需要data_from
//kafka ip 端口+ topic
//将包含/不包含该字符串的数据过滤掉
private String filterContaintsStr;
//是包含containtsStr 还是不包含
//1 表示包含 0 表示不包含
private int filterContaintsStrFlag;
//全部包含或不包含,包含其中一个或者不包含其中一个。
private int conditionAllOrOne;
//writer端要求的顺序。
private String writerOrder;
//kafkareader端的每个关键子的key
private String kafkaReaderColumnKey;
//异常文件路径
private String exceptionPath;
//
private Boolean enableAutoCommit;
//
private Integer maxPollRecords;
@Override
public void init() {
flag = true;
this.readerSliceConfig = super.getPluginJobConf();
split = this.readerSliceConfig.getString(Key.SPLIT);
bootstrapServers = this.readerSliceConfig.getString(Key.BOOTSTRAP_SERVERS);
groupId = this.readerSliceConfig.getString(Key.GROUP_ID);
kafkaTopic = this.readerSliceConfig.getString(Key.TOPIC);
count = this.readerSliceConfig.getInt(Key.COLUMNCOUNT);
filterContaintsStr = this.readerSliceConfig.getString(Key.CONTAINTS_STR);
filterContaintsStrFlag = this.readerSliceConfig.getInt(Key.CONTAINTS_STR_FLAG);
conditionAllOrOne = this.readerSliceConfig.getInt(Key.CONTAINTS_STR_FLAG);
parsingRules = this.readerSliceConfig.getString(Key.PARSING_RULES);
writerOrder = this.readerSliceConfig.getString(Key.WRITER_ORDER);
kafkaReaderColumnKey = this.readerSliceConfig.getString(Key.KAFKA_READER_COLUMN_KEY);
exceptionPath = this.readerSliceConfig.getString(Key.EXECPTION_PATH);
enableAutoCommit = Objects.isNull(this.readerSliceConfig.getBool(Key.ENABLE_AUTO_COMMIT)) ? true : this.readerSliceConfig.getBool(Key.EXECPTION_PATH);
maxPollRecords = Objects.isNull(this.readerSliceConfig.getInt(Key.MAX_POLL_RECORDS)) ? 200 : this.readerSliceConfig.getInt(Key.MAX_POLL_RECORDS);
LOG.info(filterContaintsStr);
}
@Override
public void startRead(RecordSender recordSender) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId != null ? groupId : UUID.randomUUID().toString());
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit);
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, maxPollRecords);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Collections.singletonList(kafkaTopic));
Record oneRecord = null;
int commitSyncMaxNum = maxPollRecords;
int commitSyncNum = 0;
while (flag) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(500));
for (ConsumerRecord<String, String> record : records) {
String value = record.value();
//定义过滤标志
int ifNotContinue = filterMessage(value);
//如果标志修改为1了那么就过滤掉这条数据。
if (ifNotContinue == 1) {
LOG.info("过滤数据: " + record.value());
continue;
}
oneRecord = buildOneRecord(recordSender, value);
//如果返回值不等于null表示不是异常消息。
if (oneRecord != null) {
LOG.info("oneRecord:{}", oneRecord.toString());
recordSender.sendToWriter(oneRecord);
}
}
recordSender.flush();
if (!enableAutoCommit) {
commitSyncNum++;
if (commitSyncNum >= commitSyncMaxNum) {
consumer.commitSync();
commitSyncNum = 0;
}
}
//判断当前事件是不是0点,0点的话进程他退出
Date date = new Date();
if (DateUtil.targetFormat(date).split(" ")[1].substring(0, 2).equals("00")) {
destroy();
}
}
}
private int filterMessage(String value) {
//如果要过滤的条件配置了
int ifNotContinue = 0;
if (filterContaintsStr != null) {
String[] filterStrs = filterContaintsStr.split(",");
//所有
if (conditionAllOrOne == 1) {
//过滤掉包含filterContaintsStr的所有项的值。
if (filterContaintsStrFlag == 1) {
int i = 0;
for (; i < filterStrs.length; i++) {
if (!value.contains(filterStrs[i])) break;
}
if (i >= filterStrs.length) ifNotContinue = 1;
} else {
//留下掉包含filterContaintsStr的所有项的值
int i = 0;
for (; i < filterStrs.length; i++) {
if (!value.contains(filterStrs[i])) break;
}
if (i < filterStrs.length) ifNotContinue = 1;
}
} else {
//过滤掉包含其中一项的值
if (filterContaintsStrFlag == 1) {
int i = 0;
for (; i < filterStrs.length; i++) {
if (value.contains(filterStrs[i])) break;
}
if (i < filterStrs.length) ifNotContinue = 1;
}
//留下包含其中一下的值
else {
int i = 0;
for (; i < filterStrs.length; i++) {
if (value.contains(filterStrs[i])) break;
}
if (i >= filterStrs.length) ifNotContinue = 1;
}
}
}
return ifNotContinue;
}
private Record buildOneRecord(RecordSender recordSender, String value) {
Record record = null;
if (parsingRules.equals("regex")) {
record = parseRegex(value, recordSender);
} else if (parsingRules.equals("json")) {
record = parseJson(value, recordSender);
} else if (parsingRules.equals("split")) {
record = parseSplit(value, recordSender);
}
LOG.info("record:{}", record.toString());
return record;
}
private Record parseSplit(String value, RecordSender recordSender) {
Record record = recordSender.createRecord();
String[] splits = value.split(this.split);
if (splits.length != count) {
writerErrorPath(value);
return null;
}
return parseOrders(Arrays.asList(splits), record);
}
private Record parseJson(String value, RecordSender recordSender) {
LOG.info("parseJson value :{}", value);
Record record = recordSender.createRecord();
HashMap<String, Object> map = JsonUtilJava.parseJsonStrToMap(value);
LOG.info("map :{}", map);
List<Map<String, Object>> mapData = (List<Map<String, Object>>) map.get("data");
LOG.info("mapData :{}", mapData);
LOG.info("parseJson kafkaReaderColumnKey :{}", kafkaReaderColumnKey);
String[] columns = kafkaReaderColumnKey.split(",");
if (mapData.size() != columns.length) {
throw new RuntimeException("kafka字段数和columns的字段数不一致,无法映射数据");
}
ArrayList<String> datas = new ArrayList<>();
for (int i = 0; i < columns.length; i++) {
datas.add(String.valueOf(mapData.get(i).get("rawData")));
}
// for (String column : columns) {
// datas.add(map.get(column).toString());
// }
if (datas.size() != count) {
writerErrorPath(value);
return null;
}
LOG.info("datas:{}", datas);
return parseOrders(datas, record);
}
private Record parseRegex(String value, RecordSender recordSender) {
Record record = recordSender.createRecord();
ArrayList<String> datas = new ArrayList<String>();
Pattern r = Pattern.compile(split);
Matcher m = r.matcher(value);
if (m.find()) {
if (m.groupCount() != count) {
writerErrorPath(value);
}
for (int i = 1; i <= count; i++) {
// record.addColumn(new StringColumn(m.group(i)));
datas.add(m.group(i));
return record;
}
} else {
writerErrorPath(value);
}
return parseOrders(datas, record);
}
private void writerErrorPath(String value) {
if (exceptionPath == null) return;
FileOutputStream fileOutputStream = null;
try {
fileOutputStream = getFileOutputStream();
fileOutputStream.write((value + "\n").getBytes());
fileOutputStream.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
private FileOutputStream getFileOutputStream() throws FileNotFoundException {
return new FileOutputStream(exceptionPath + "/" + kafkaTopic + "errordata" + DateUtil.targetFormat(new Date(), "yyyyMMdd"), true);
}
private Record parseOrders(List<String> datas, Record record) {
//writerOrder
String[] orders = writerOrder.split(",");
LOG.info("writerOrder:{}", writerOrder);
for (String order : orders) {
if (order.equals("data_from")) {
record.addColumn(new StringColumn(bootstrapServers + "|" + kafkaTopic));
} else if (order.equals("uuid")) {
record.addColumn(new StringColumn(UUID.randomUUID().toString()));
} else if (order.equals("null")) {
record.addColumn(new StringColumn("null"));
} else if (order.equals("datax_time")) {
record.addColumn(new StringColumn(DateUtil.targetFormat(new Date())));
} else if (isNumeric(order)) {
record.addColumn(new StringColumn(datas.get(new Integer(order) - 1)));
}
}
return record;
}
public static boolean isNumeric(String str) {
for (int i = 0; i < str.length(); i++) {
if (!Character.isDigit(str.charAt(i))) {
return false;
}
}
return true;
}
@Override
public void post() {
}
@Override
public void destroy() {
flag = false;
}
}
}
KafkaReaderErrorCode.java
package com.alibaba.datax.plugin.reader.kafkareader;
import com.alibaba.datax.common.spi.ErrorCode;
/**
* @Description: TODO
* @Author: chenweifeng
* @Date: 2022年09月05日 上午11:14
**/
public enum KafkaReaderErrorCode implements ErrorCode {
TOPIC_ERROR("KafkaReader-00", "您没有设置topic参数"),
PARTITION_ERROR("KafkaReader-01", "您没有设置kafkaPartitions参数"),
ADDRESS_ERROR("KafkaReader-02", "您没有设置bootstrapServers参数"),
KAFKA_READER_ERROR("KafkaReader-03", "参数错误"),
;
private final String code;
private final String description;
private KafkaReaderErrorCode(String code, String description) {
this.code = code;
this.description = description;
}
@Override
public String getCode() {
return this.code;
}
@Override
public String getDescription() {
return this.description;
}
@Override
public String toString() {
return String.format("Code:[%s], Description:[%s].", this.code,
this.description);
}
}
Key.java
package com.alibaba.datax.plugin.reader.kafkareader;
/**
* @Description: TODO
* @Author: chenweifeng
* @Date: 2022年09月05日 上午11:08
**/
public class Key {
public final static String TOPIC = "topic";// 主题
public final static String KAFKA_PARTITIONS = "kafkaPartitions";// 分区数
public final static String BOOTSTRAP_SERVERS = "bootstrapServers";//
public final static String GROUP_ID = "groupId";// 消费组
public final static String COLUMNCOUNT = "columnCount";// 字段数
public final static String SPLIT = "split";// 分割符
public final static String CONTAINTS_STR = "filterContaints";// 过滤的字符串 英文逗号隔开
public final static String CONTAINTS_STR_FLAG = "filterContaintsFlag";// 1 表示包含 0 表示不包含
public final static String CONDITION_ALL_OR_ONE = "conditionAllOrOne";// 1 全部包含或不包含,0 包含其中一个或者不包含其中一个
public final static String PARSING_RULES = "parsingRules";//
public final static String WRITER_ORDER = "writerOrder";//
public final static String KAFKA_READER_COLUMN_KEY = "kafkaReaderColumnKey";//
public final static String EXECPTION_PATH = "execptionPath";//
public final static String ENABLE_AUTO_COMMIT = "enableAutoCommit";// 是否自动提交
public final static String MAX_POLL_RECORDS = "maxPollRecords";// 最大Poll数
}
plugin.json
{
"name": "kafkareader",
"class": "com.alibaba.datax.plugin.reader.kafkareader.KafkaReader",
"description": "kafka reader 插件",
"developer": "chenweifeng"
}
plugin_job_template.json
{
"name": "kafkareader",
"parameter": {
"topic": "Event",
"bootstrapServers": "192.168.7.128:9092",
"kafkaPartitions": "1",
"columnCount": 11,
"groupId": "ast",
"filterContaints": "5^1,6^5",
"filterContaintsFlag": 1,
"conditionAllOrOne": 0,
"parsingRules": "regex",
"writerOrder": "uuid,1,3,6,4,8,9,10,11,5,7,2,null,datax_time,data_from",
"kafkaReaderColumnKey": "a",
"execptionPath": "/opt/module/datax/log/errorlog"
}
}
3、kafkawriter模块代码
package.xml
<assembly
xmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0 http://maven.apache.org/xsd/assembly-1.1.0.xsd">
<id></id>
<formats>
<format>dir</format>
</formats>
<includeBaseDirectory>false</includeBaseDirectory>
<fileSets>
<fileSet>
<directory>src/main/resources</directory>
<includes>
<include>plugin.json</include>
</includes>
<outputDirectory>plugin/writer/kafkawriter</outputDirectory>
</fileSet>
<fileSet>
<directory>target/</directory>
<includes>
<include>kafkawriter-0.0.1-SNAPSHOT.jar</include>
</includes>
<outputDirectory>plugin/writer/kafkawriter</outputDirectory>
</fileSet>
</fileSets>
<dependencySets>
<dependencySet>
<useProjectArtifact>false</useProjectArtifact>
<outputDirectory>plugin/writer/kafkawriter/libs</outputDirectory>
<scope>runtime</scope>
</dependencySet>
</dependencySets>
</assembly>
KafkaWriter.java
package com.alibaba.datax.plugin.writer.kafkawriter;
import com.alibaba.datax.common.element.Column;
import com.alibaba.datax.common.element.Record;
import com.alibaba.datax.common.exception.DataXException;
import com.alibaba.datax.common.plugin.RecordReceiver;
import com.alibaba.datax.common.spi.Writer;
import com.alibaba.datax.common.util.Configuration;
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.ListTopicsResult;
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
/**
* @ClassName: KafkaWriter
* @Author: majun
* @CreateDate: 2019/2/20 11:06
* @Version: 1.0
* @Description: datax kafkawriter
*/
public class KafkaWriter extends Writer {
public static class Job extends Writer.Job {
private static final Logger logger = LoggerFactory.getLogger(Job.class);
private Configuration conf = null;
@Override
public List<Configuration> split(int mandatoryNumber) {
List<Configuration> configurations = new ArrayList<Configuration>(mandatoryNumber);
for (int i = 0; i < mandatoryNumber; i++) {
configurations.add(conf);
}
return configurations;
}
private void validateParameter() {
this.conf.getNecessaryValue(Key.BOOTSTRAP_SERVERS, KafkaWriterErrorCode.REQUIRED_VALUE);
this.conf.getNecessaryValue(Key.TOPIC, KafkaWriterErrorCode.REQUIRED_VALUE);
}
@Override
public void init() {
this.conf = super.getPluginJobConf();
logger.info("kafka writer params:{}", conf.toJSON());
this.validateParameter();
}
@Override
public void destroy() {
}
}
public static class Task extends Writer.Task {
private static final Logger logger = LoggerFactory.getLogger(Task.class);
private static final String NEWLINE_FLAG = System.getProperty("line.separator", "\n");
private Producer<String, String> producer;
private String fieldDelimiter;
private Configuration conf;
private Properties props;
@Override
public void init() {
this.conf = super.getPluginJobConf();
fieldDelimiter = conf.getUnnecessaryValue(Key.FIELD_DELIMITER, "\t", null);
props = new Properties();
props.put("bootstrap.servers", conf.getString(Key.BOOTSTRAP_SERVERS));
props.put("acks", conf.getUnnecessaryValue(Key.ACK, "0", null));//这意味着leader需要等待所有备份都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的保证。
props.put("retries", conf.getUnnecessaryValue(Key.RETRIES, "0", null));
// Controls how much bytes sender would wait to batch up before publishing to Kafka.
//控制发送者在发布到kafka之前等待批处理的字节数。
//控制发送者在发布到kafka之前等待批处理的字节数。 满足batch.size和ling.ms之一,producer便开始发送消息
//默认16384 16kb
props.put("batch.size", conf.getUnnecessaryValue(Key.BATCH_SIZE, "16384", null));
props.put("linger.ms", 1);
props.put("key.serializer", conf.getUnnecessaryValue(Key.KEYSERIALIZER, "org.apache.kafka.common.serialization.StringSerializer", null));
props.put("value.serializer", conf.getUnnecessaryValue(Key.VALUESERIALIZER, "org.apache.kafka.common.serialization.StringSerializer", null));
producer = new KafkaProducer<String, String>(props);
}
@Override
public void prepare() {
if (Boolean.valueOf(conf.getUnnecessaryValue(Key.NO_TOPIC_CREATE, "false", null))) {
ListTopicsResult topicsResult = AdminClient.create(props).listTopics();
String topic = conf.getNecessaryValue(Key.TOPIC, KafkaWriterErrorCode.REQUIRED_VALUE);
try {
if (!topicsResult.names().get().contains(topic)) {
new NewTopic(
topic,
Integer.valueOf(conf.getUnnecessaryValue(Key.TOPIC_NUM_PARTITION, "1", null)),
Short.valueOf(conf.getUnnecessaryValue(Key.TOPIC_REPLICATION_FACTOR, "1", null))
);
List<NewTopic> newTopics = new ArrayList<NewTopic>();
AdminClient.create(props).createTopics(newTopics);
}
} catch (Exception e) {
throw new DataXException(KafkaWriterErrorCode.CREATE_TOPIC, KafkaWriterErrorCode.REQUIRED_VALUE.getDescription());
}
}
}
@Override
public void startWrite(RecordReceiver lineReceiver) {
logger.info("start to writer kafka");
Record record = null;
while ((record = lineReceiver.getFromReader()) != null) {//说明还在读取数据,或者读取的数据没处理完
//获取一行数据,按照指定分隔符 拼成字符串 发送出去
if (conf.getUnnecessaryValue(Key.WRITE_TYPE, WriteType.TEXT.name(), null).toLowerCase()
.equals(WriteType.TEXT.name().toLowerCase())) {
producer.send(new ProducerRecord<String, String>(this.conf.getString(Key.TOPIC),
recordToString(record),
recordToString(record))
);
} else if (conf.getUnnecessaryValue(Key.WRITE_TYPE, WriteType.TEXT.name(), null).toLowerCase()
.equals(WriteType.JSON.name().toLowerCase())) {
producer.send(new ProducerRecord<String, String>(this.conf.getString(Key.TOPIC),
recordToString(record),
record.toString())
);
}
logger.info("complete write " + record.toString());
producer.flush();
}
}
@Override
public void destroy() {
if (producer != null) {
producer.close();
}
}
/**
* 数据格式化
*
* @param record
* @return
*/
private String recordToString(Record record) {
int recordLength = record.getColumnNumber();
if (0 == recordLength) {
return NEWLINE_FLAG;
}
Column column;
StringBuilder sb = new StringBuilder();
for (int i = 0; i < recordLength; i++) {
column = record.getColumn(i);
sb.append(column.asString()).append(fieldDelimiter);
}
sb.setLength(sb.length() - 1);
sb.append(NEWLINE_FLAG);
logger.info("recordToString:{}",sb.toString());
return sb.toString();
}
}
}
KafkaWriterErrorCode.java
package com.alibaba.datax.plugin.writer.kafkawriter;
import com.alibaba.datax.common.spi.ErrorCode;
public enum KafkaWriterErrorCode implements ErrorCode {
REQUIRED_VALUE("KafkaWriter-00", "您缺失了必须填写的参数值."),
CREATE_TOPIC("KafkaWriter-01", "写入数据前检查topic或是创建topic失败.");
private final String code;
private final String description;
private KafkaWriterErrorCode(String code, String description) {
this.code = code;
this.description = description;
}
@Override
public String getCode() {
return this.code;
}
@Override
public String getDescription() {
return this.description;
}
@Override
public String toString() {
return String.format("Code:[%s], Description:[%s].", this.code,
this.description);
}
}
Key.java
package com.alibaba.datax.plugin.writer.kafkawriter;
/**
* @ClassName: Key
* @Author: majun
* @CreateDate: 2019/2/20 11:17
* @Version: 1.0
* @Description: TODO
*/
public class Key {
//
// bootstrapServers": "",
// "topic": "",
// "ack": "all",
// "batchSize": 1000,
// "retries": 0,
// "keySerializer":"org.apache.kafka.common.serialization.StringSerializer",
// "valueSerializer": "org.apache.kafka.common.serialization.StringSerializer",
// "fieldFelimiter": ","
public static final String BOOTSTRAP_SERVERS = "bootstrapServers";
// must have
public static final String TOPIC = "topic";
public static final String ACK = "ack";
public static final String BATCH_SIZE = "batchSize";
public static final String RETRIES = "retries";
public static final String KEYSERIALIZER = "keySerializer";
public static final String VALUESERIALIZER = "valueSerializer";
// not must , not default
public static final String FIELD_DELIMITER = "fieldDelimiter";
public static final String NO_TOPIC_CREATE = "noTopicCreate";
public static final String TOPIC_NUM_PARTITION = "topicNumPartition";
public static final String TOPIC_REPLICATION_FACTOR = "topicReplicationFactor";
public static final String WRITE_TYPE = "writeType";
}
WriterType.java
package com.alibaba.datax.plugin.writer.kafkawriter;
public enum WriteType {
JSON("json"),
TEXT("text");
private String name;
WriteType(String name) {
this.name = name;
}
}
plugin.json
{
"name": "kafkawriter",
"class": "com.alibaba.datax.plugin.writer.kafkawriter.KafkaWriter",
"description": "kafka writer 插件",
"developer": "chenweifeng"
}
plugin_job_template.json
{
"name": "kafkawriter",
"parameter": {
"bootstrapServers": "10.1.20.150:9092",
"topic": "test-topic",
"ack": "all",
"batchSize": 1000,
"retries": 0,
"keySerializer": "org.apache.kafka.common.serialization.StringSerializer",
"valueSerializer": "org.apache.kafka.common.serialization.StringSerializer",
"fieldFelimiter": ",",
"writeType": "json",
"topicNumPartition": 1,
"topicReplicationFactor": 1
}
}
4、由kafka写到kafka的例子
{
"job": {
"setting": {
"speed": {
"channel": 12
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "kafkareader",
"parameter": {
"topic": "test_datax_kafka_read",
"bootstrapServers": "10.254.21.6:59292,10.254.21.1:59292,10.254.21.2:59292",
"kafkaPartitions": 12,
"columnCount": 34,
"groupId": "datax_kafka_kafka",
"filterContaints": "5^1,6^5",
"filterContaintsFlag": 1,
"conditionAllOrOne": 0,
"parsingRules": "json",
"writerOrder": "1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34",
"kafkaReaderColumnKey": "id,c1,c2,c3,c4,c5,c6,c7,c8,c9,c10,c11,c12,c13,c14,c15,c16,c17,c18,c19,c20,c21,c22,c23,c24,c25,c26,c27,c28,c29,c30,c31,c32,crt_time",
"execptionPath": "/Users/chenweifeng/datax/log/errorlog",
"split":"\t"
}
},
"writer": {
"name": "kafkawriter",
"parameter": {
"print": true,
"topic": "test_datax_kafka_write",
"bootstrapServers": "10.254.21.6:59292,10.254.21.1:59292,10.254.21.2:59292",
"fieldDelimiter": "\t",
"batchSize": 20,
"writeType": "json",
"notTopicCreate": false,
"topicNumPartition": 12,
"topicReplicationFactor": 3
}
}
}
]
}
}
注:目前kafkareader和kafkawriter处于可行状态,但是我本人做了性能测试,目前存在性能问题,做了一些参数的调整,仍然存在,以后会尝试进行优化,如有朋友已经对其进行优化的,可以在评论留下你建议,谢谢。
本文转载自: https://blog.csdn.net/Carson073/article/details/126728411
版权归原作者 CarsonBigData 所有, 如有侵权,请联系我们删除。
版权归原作者 CarsonBigData 所有, 如有侵权,请联系我们删除。