
前言
为解决从Selenium中获取Network接口数据,潜心研究了一小会儿,遂有此文
基本看这篇文章的,多多少少都跟
spider
沾亲带故。所以直接进入正题。
- 只想要代码,文章前边自取
- 想看长篇大论,先看这篇 【Selenium】控制当前已经打开的 chrome浏览器窗口(高级版)
应用场景
Chrome浏览器 -> 开发者工具 -> Network 中所有的数据包,我要全部拿下来。
举个例子🌰
- 网站通过XHR异步加载数据,然后再渲染到网页上。而通过Selenium去获取渲染后的数据,是同HTML打交道的
- 异步加载返回数据是json文件的,有时渲染在网页上,不一定是完整的json文件中的数据;最重要的是,json文件解析起来很方便
通过selenium去拿网页数据,往往是两个途径:
- selenium.page_source,通过解析HTML
- 通过中间人进行数据截获,数据源是啥就是啥
这两种方法各有利弊,但是这篇文章就可以将他们相结合起来了,实在是妙啊!
可能你会有疑惑👀?直接使用
requests
去请求不就完事了,
请你想一下,我这都使用上selenium了,你觉得我还会去使用
requests
再多请求一遍吗???
完整代码
Selenium获取Network
这里指定9527端口打开浏览器,也可以不指定,看上一篇文章
代码讲解在下面
# -*- coding: utf-8 -*-# @Time : 2022-08-27 11:59# @Name : selenium_cdp.pyimport json
from selenium import webdriver
from selenium.common.exceptions import WebDriverException
from selenium.webdriver.chrome.options import Options
caps ={"browserName":"chrome",'goog:loggingPrefs':{'performance':'ALL'}# 开启日志性能监听}
options = Options()
options.add_experimental_option("debuggerAddress","127.0.0.1:9527")# 指定端口为9527
browser = webdriver.Chrome(desired_capabilities=caps, options=options)# 启动浏览器
browser.get('https://blog.csdn.net/weixin_45081575')# 访问该urldeffilter_type(_type:str):
types =['application/javascript','application/x-javascript','text/css','webp','image/png','image/gif','image/jpeg','image/x-icon','application/octet-stream']if _type notin types:returnTruereturnFalse
performance_log = browser.get_log('performance')# 获取名称为 performance 的日志for packet in performance_log:
message = json.loads(packet.get('message')).get('message')# 获取message的数据if message.get('method')!='Network.responseReceived':# 如果method 不是 responseReceived 类型就不往下执行continue
packet_type = message.get('params').get('response').get('mimeType')# 获取该请求返回的typeifnot filter_type(_type=packet_type):# 过滤typecontinue
requestId = message.get('params').get('requestId')# 唯一的请求标识符。相当于该请求的身份证
url = message.get('params').get('response').get('url')# 获取 该请求 urltry:
resp = browser.execute_cdp_cmd('Network.getResponseBody',{'requestId': requestId})# selenium调用 cdpprint(f'type: {packet_type} url: {url}')print(f'response: {resp}')print()except WebDriverException:# 忽略异常pass
运行效果看下面动图,轻松拿到该网页请求中的所有数据包~

知识点📖
Chrome DevTools Protocol 允许使用工具来检测、检查、调试和分析 Chromium、Chrome 和其他基于 Blink 的浏览器。
Chrome DevTools Protocol
,简称CDP
看以下 Chrome DevTools Protocol官方文档 ,感兴趣的可以深入去学习了解。这个将另起一篇文章来讲。
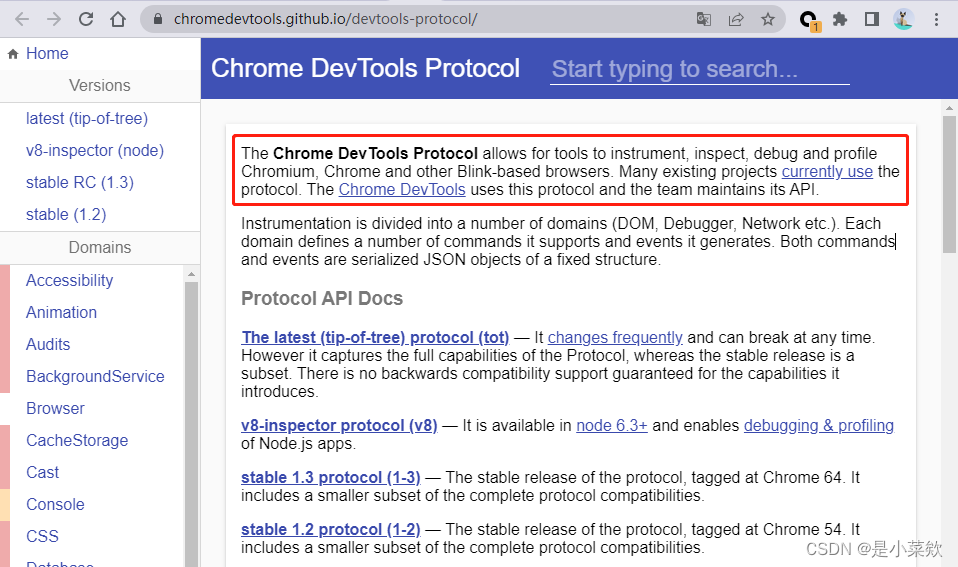
再看 Selenium官方文档,所以是可以通过CDP协议去操作Selenium打开的Chrome浏览器的。

代码解析
在上一篇文章 【Selenium】控制当前已经打开的 chrome浏览器窗口(高级版) 中,介绍了链接Chrome浏览器,这里进一步介绍。
以调试模式启动Selenium,打上断点,跟一下源码。来到下面这里,因为咱们指定了端口为
9527
,否则这个
port
将是随机的,至于为什么,看源码
site-packages\selenium\webdriver\common\utils.py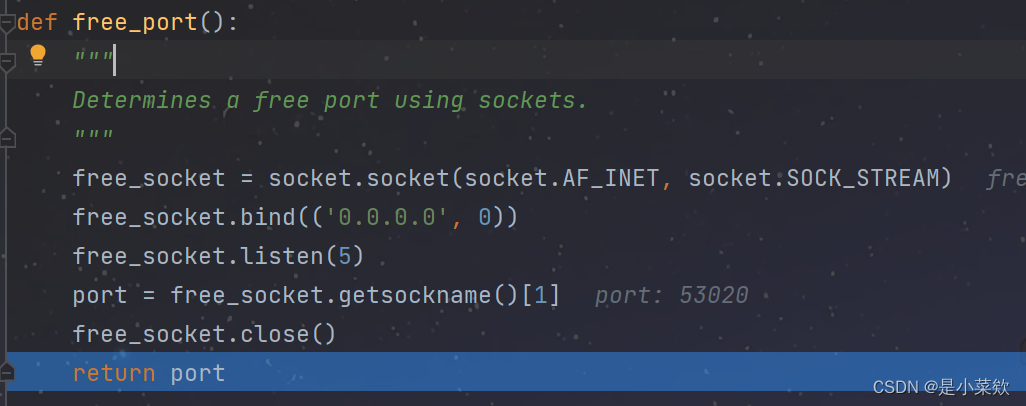
回到上面的代码中,
'goog:loggingPrefs': {'performance': 'ALL'},这段代码是开启浏览器的性能日志记录
caps ={"browserName":"chrome",
'goog:loggingPrefs':{'performance':'ALL'}# 开启性能日志记录}
简单理解为 开发者工具中的
performance
,看下图

以下代码返回的是一个列表,装着该网页请求中所有的数据包
performance_log = browser.get_log('performance')
看下图
- 因为我们要获取的是 Network中的返回值,所以只取
method =Network.responseReceived

知识补充
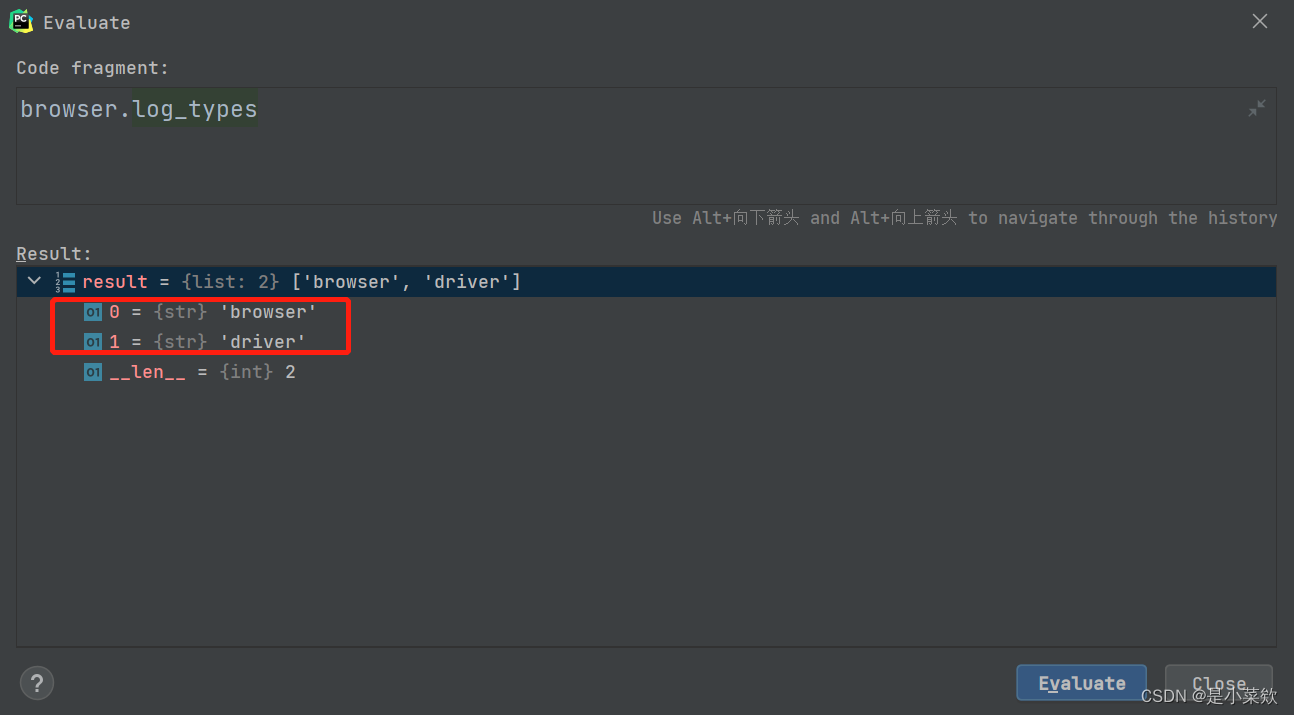
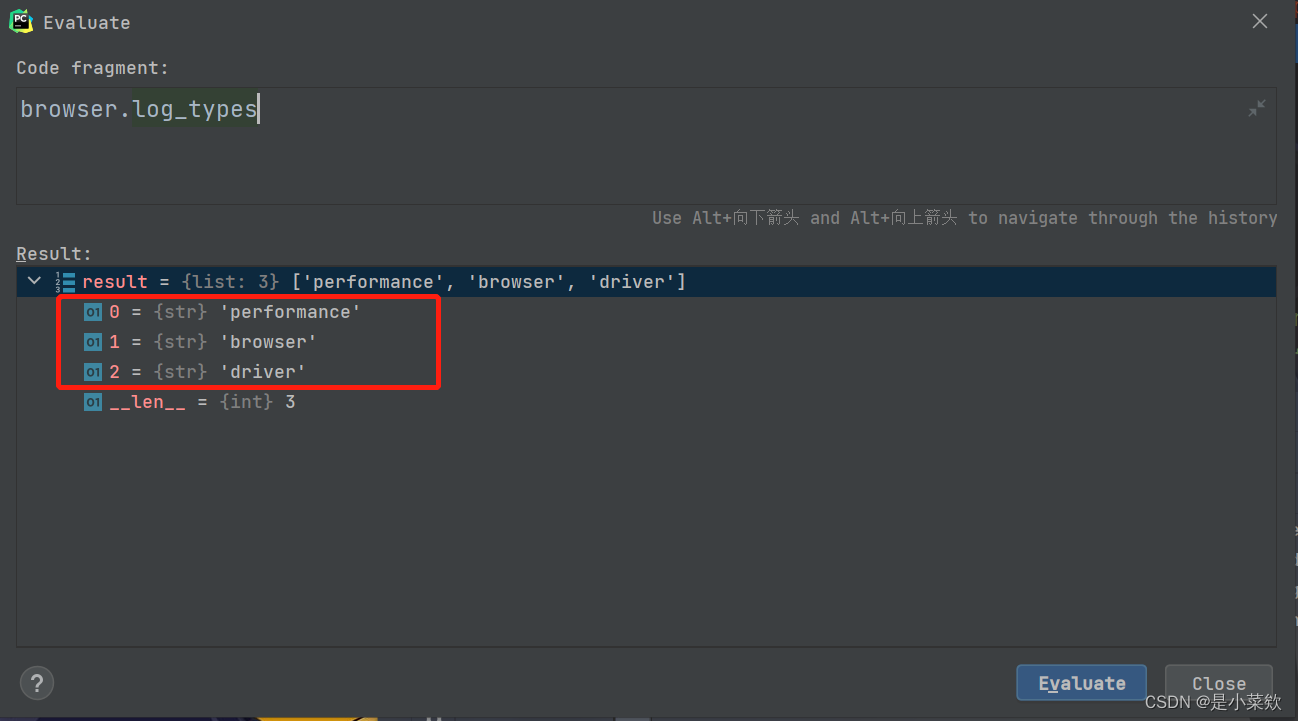
使用
browser.log_types
可以查看当前的可用日志类型的列表,
下面两幅图分别是开启性能日志记录 和 不开启性能日志记录 的可用日志类型返回值~
再接下来就是过滤请求包,一般来说,像图片、css&js文件等,往往是不需要的,所以可以对它们过滤~(这一步可以根据自己的需求来过滤)
deffilter_type(_type:str):
types =['application/javascript','application/x-javascript','text/css','webp','image/png','image/gif','image/jpeg','image/x-icon','application/octet-stream']if _type notin types:returnTruereturnFalse
最后是获取数据包的
requestId
,这个是调用 cdp 的关键,它就好比每个网络数据包的身份证。
在Selenium中调用cdp时候,需要传入
requestId
,浏览器会验证是否存在该
requestId
,
- 如果存在,则响应并返回数据;
- 如果不存在,则会抛出
WebDriverException异常。 在这里的代码中,我对这个异常进行了忽略的处理~
try:
resp = browser.execute_cdp_cmd('Network.getResponseBody',{'requestId':'123123123'})# selenium调用 cdpprint(f'type: {packet_type} url: {url}')print(f'response: {resp}')print()except WebDriverException:# 忽略异常pass
后话
简单来说,本文章所能实现的,还算是有用的😎😎
远的不说,起码本文章就帮助我解决了mitmproxy + Selenium 的组合拳(现在只用Selenium就可以完成了~
See you.
版权归原作者 是小菜欸 所有, 如有侵权,请联系我们删除。