
数据结构学习,图的遍历(DFS和BFS)
前言
前面我们学习了数据结构图的基础,关于图的定义,图的术语,以及对图结构使用邻接矩阵和邻接表的存储处理,今天我们学习图的遍历,我们主要学习DFS(深度优先遍历)和BFS(广度优先遍历)两种遍历。这两种遍历衍生的搜索在算法里面考的比较多,在一些算法比赛也运用的比较频繁,像蓝桥杯这样的比赛老喜欢考了,考BFS搜索和DFS搜索。好了别的咋不扯了,我们开始学习吧!!
每日一遍,防止恋爱

1.图的遍历
图的遍历指的是从图中的任一顶点出发,对图中的所有顶点访问一次且只访问一次。图的遍历操作和树的遍历操作功能相似。图的遍历是图的一种基本操作,图的许多其它操作都是建立在遍历操作的基础之上。由于图结构本身的复杂性,所以图的遍历操作也较复杂,我们一般是给定一个图G=(V,E)和其中的任一顶点v,从顶点v出发,访问图G中的所有顶点而且每个顶点仅被访问一次。为了避免同一顶点被访问多次,在遍历图的过程中,必须记下每个已访问过的顶点。
1.DFS
深度优先遍历(Depth First Search,简称DFS)
1.访问顶点v----》2.选择一个与顶点v相邻且没被访问过的顶点w,从w出发深度优先遍历----》直到图中与v相邻的所有顶点都被访问过为止。(讲人话:就是递归,一直往下面找自己没有遍历过的值,直到到了最后一层,而且这一层为空,就返回到上一层,在上一层找其他相邻的值遍历往下遍历)(就是二叉树的先根遍历😂😂😂,不扒拉有的没的)
注:在DFS搜索里面搜索的值,其实就是我们这里的输出,逻辑是一样的
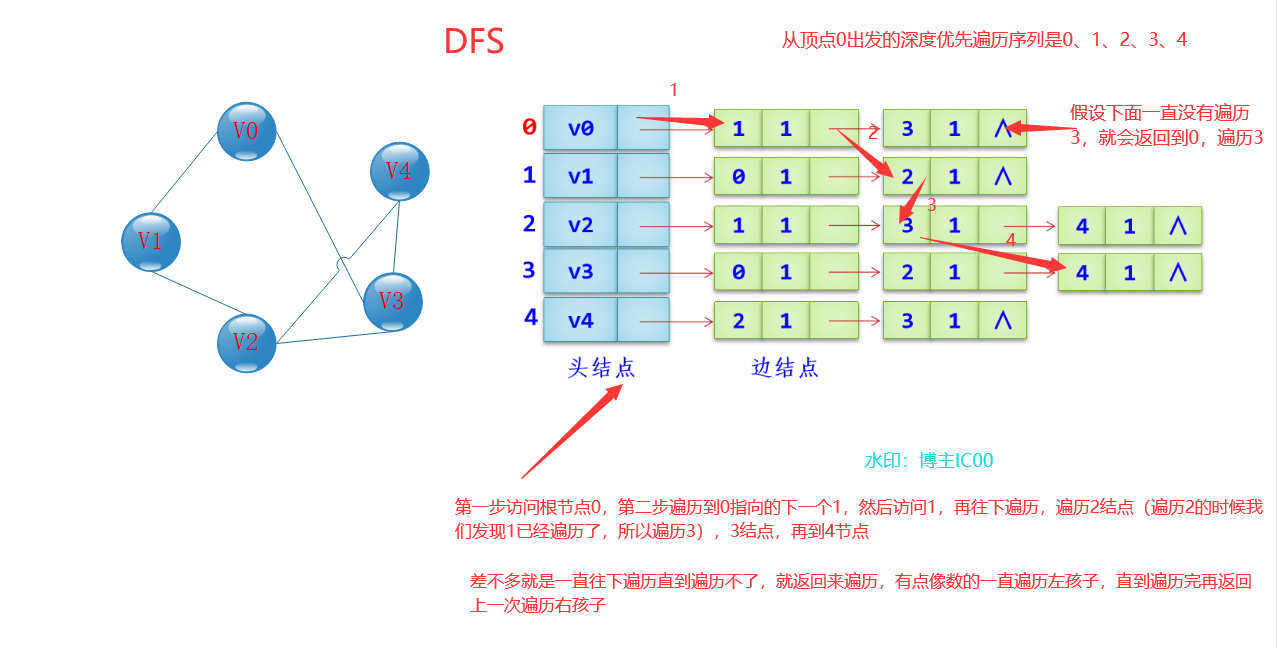
代码讲解:
visited[MAXVEX]={0}; //全局变量
void DFS(AdjGraph *G,int v)
{ int w; ArcNode *p;
printf("%d ",v); //访问v顶点
visited[v]=1; //改变这个顶点的状态,为1表示遍历过了,为0表示没有遍历
p=G->adjlist[v].firstarc; //找v的第一个相邻点
while (p!=NULL) //找v的所有相邻点
{ w= p->adjvex; //顶点v的相邻点w
if (visited[w]==0) //顶点w未访问过
DFS(G,w); //从w出发深度优先遍历,一直往下面遍历直到为空会返回上一层
p=p->nextarc; //找v的下一个相邻点
}
}
2.BFS
广度优先遍历(Breadth First Search,简称BFS)
1.访问顶点v-----》2.访问顶点v的所有未被访问过的相邻点-----》3.访问每个顶点的所有未被访问过的相邻点,直到图中所有和初始点v有路径相通的顶点都被访问过为止.(讲人话:用队列实现,先进先出,只要队列不空,就可以一直在里面找与这个顶点相连下一个顶点或者找我们指向的这个顶点的关系下一个,比如顶点0,它和1,3顶点有关联,(顶点1又和顶点2有关联,顶点3也和顶点0,2,4有关联),我们遍历就是根据关系层进队遍历,发散型的)
注:在BFS搜索里面搜索的值,其实就是我们这里的输出,逻辑是一样的
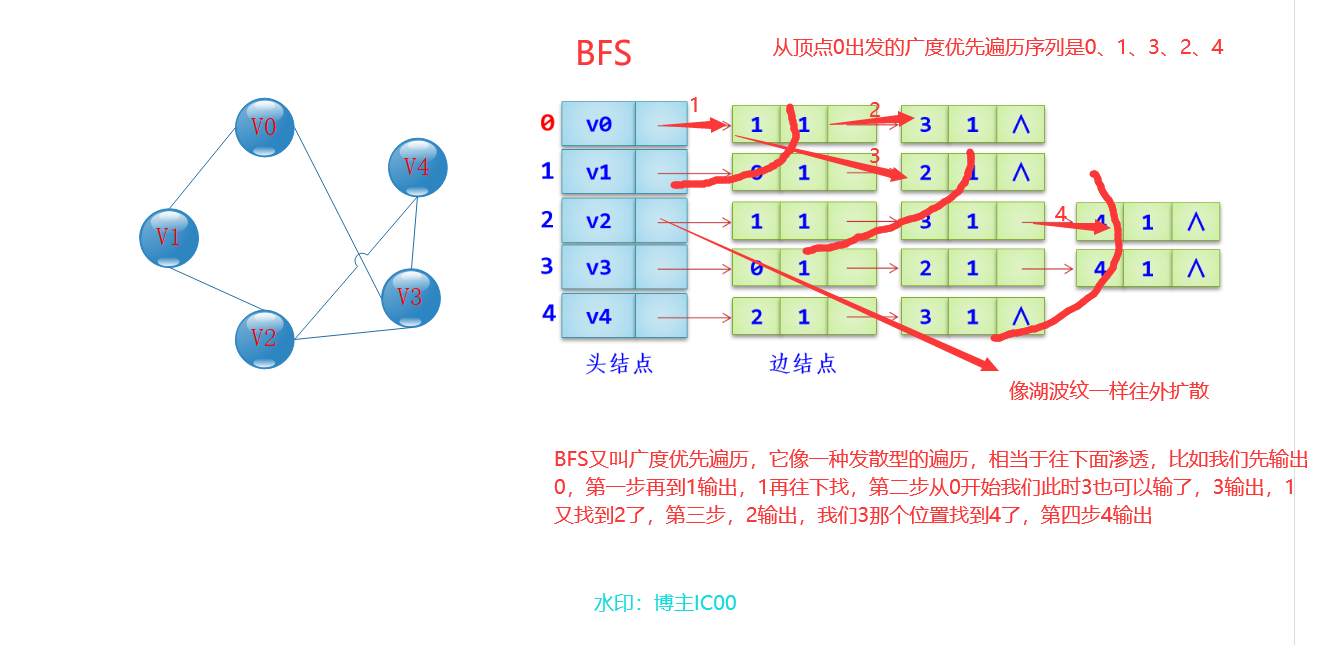
代码讲解:
void BFS(AdjGraph *G,int vi)
{ int i,v,visited[MAXVEX]; ArcNode *p;
int Qu[MAXVEX],front=0,rear=0; //定义一个循环队列Qu
for (i=0;i<G->n;i++) visited[i]=0; //visited数组置初值0
printf("%d ",vi); //访问初始顶点
visited[vi]=1; //改变这个顶点的状态,为1表示遍历过了,为0表示没有遍历
rear=(rear=1)%MAXVEX;Qu[rear]=vi; //初始顶点进队
while (front!=rear) //队不为空时循环
{ front=(front+1) % MAXVEX;
v=Qu[front]; //出队顶点v
p=G->adjlist[v].firstarc; //查找v的第一个相邻点
while (p!=NULL) //查找v的所有相邻点
{ if (visited[p->adjvex]==0) //未访问过则访问之
{ printf("%d ",p->adjvex); //访问该点并进队
visited[p->adjvex]=1;
rear=(rear+1) % MAXVEX;
Qu[rear]=p->adjvex;
}
p=p->nextarc; //查找v的下一个相邻点
}
}
}
总结
图的遍历我们就学完了,主要就是DFS和BFS,DFS就是相当于我们二叉树的先根遍历,使用的也是递归的操作方法,只是有在输出的时候有区别,需要我们标记谁输出了,因为它们之间的存储结构是有区别的,BFS广度优先遍历,就是用一个队列来帮助我们遍历,逻辑可以理解为扩散,我们依次扩大的感觉,成倍数在往外面扩展。我们在学习这两种遍历的时候不要把这两种遍历想的特别难,只要是人想出来的就可以理解,多看几遍量变引起质变。好了创作不易,点赞关注评论收藏,谢谢啦!!

版权归原作者 IC00 所有, 如有侵权,请联系我们删除。