
一、安装Eclipse
1.下载Eclipse(我使用Xftp传输的,大家可以直接在虚拟机中下载)
下载链接:https://www.eclipse.org/downloads/package

2.解压Eclipse
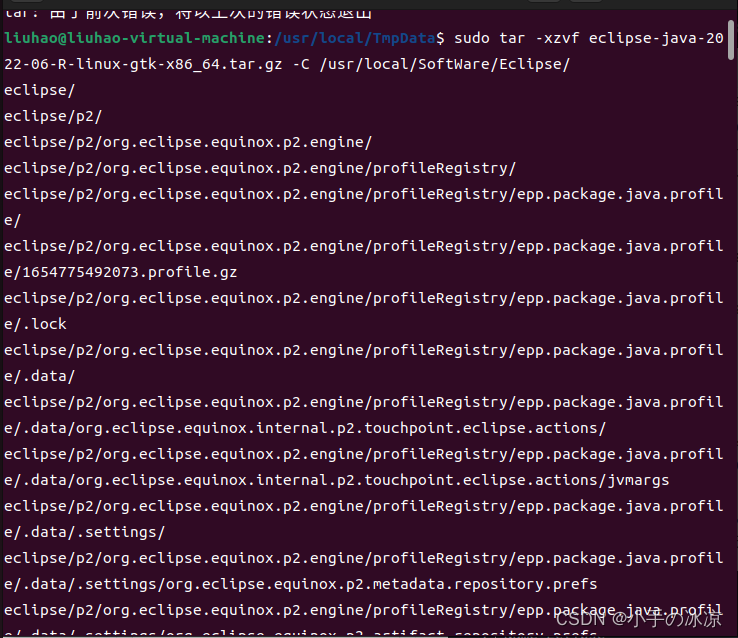
3.桌面显示Eclipse图标
在终端输入:cd /usr/share/applications/
在终端输入:ls
查看有无:eclipse.desktop文件,若没有,在终端输入:cp xxx.desktop eclipse.desktop,有就跳过这一步;命令行必须在进入cd /usr/share/applications/后输入,xxx是文件名,任意找一个存在的文件进行复制
在终端输入:sudo gedit eclipse.desktop,打开eclipse.desktop文件
在打开的eclipse.desktop文件中,进行修改,修改后的内容如下:
[Desktop Entry]
Encoding=UTF-8
Name=Eclipse
Comment=Eclipse
****Exec=/usr/local/SoftWare/Eclipse/eclipse/eclipse ****
Icon=/usr/local/SoftWare/Eclipse/eclipse/icon.xpm
Terminal=false
StartupNotify=true
Type=Application
Categories=Application;Development;
原文链接:https://blog.csdn.net/weixin_44941350/article/details/122380269
4.配置Eclipse(JDK)
新建JavaProject
二、生成文件
1.打开HDFS
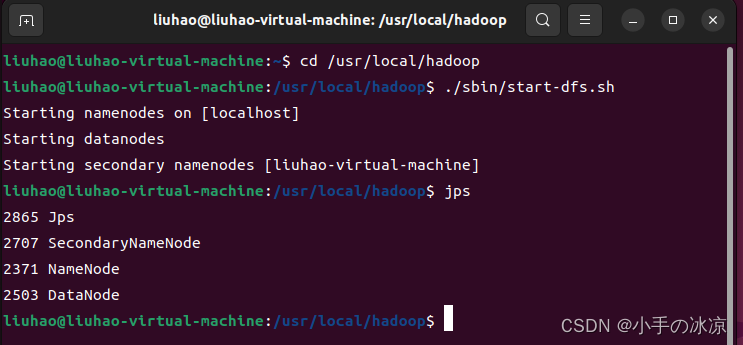
利用Shell命令与HDFS进行交互
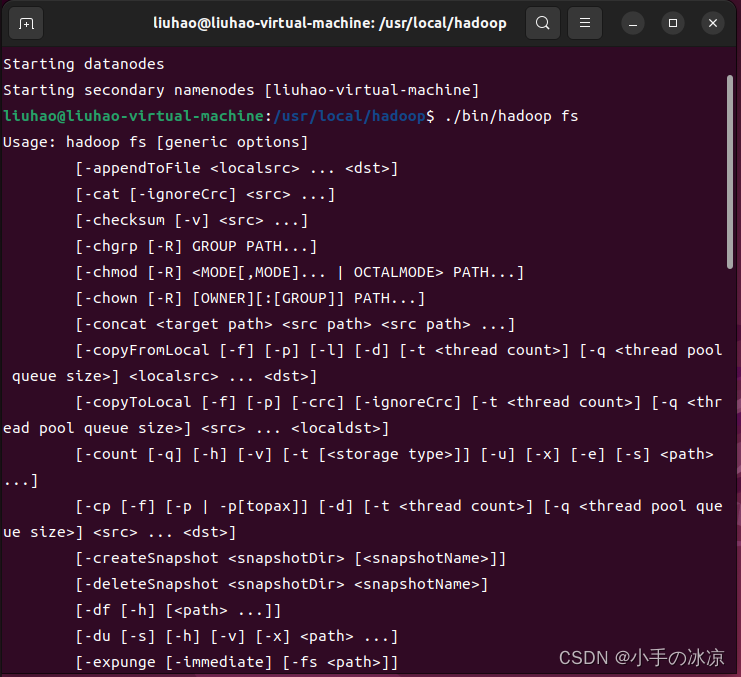
Hadoop支持很多Shell命令,其中fs是HDFS最常用的命令,利用fs可以查看HDFS文件系统的目录结构、上传和下载数据、创建文件等。实际上有三种shell命令方式。
1.**** hadoop fs**** : 适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
2. hadoop dfs : 只能适用于HDFS文件系统
3. hdfs dfs : 只能适用于HDFS文件系统
我们可以在终端输入如下命令,查看fs总共支持了哪些命令
2.创建目录

3.创建文件

记得在文件里写入内容(vim)
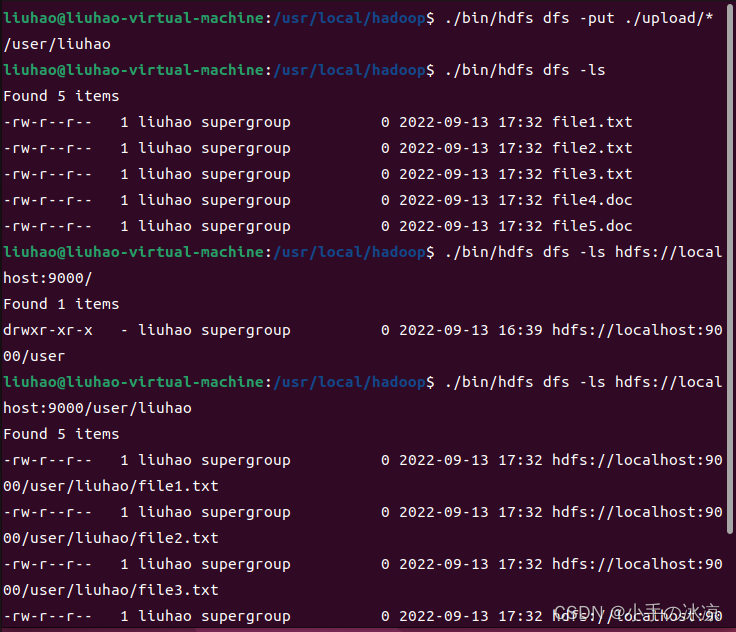
4.将文件上传到hdfs://localhost:9000/user/liuhao
三、编写Java代码
(此处使用IDEA编写,因为界面好看^_^)
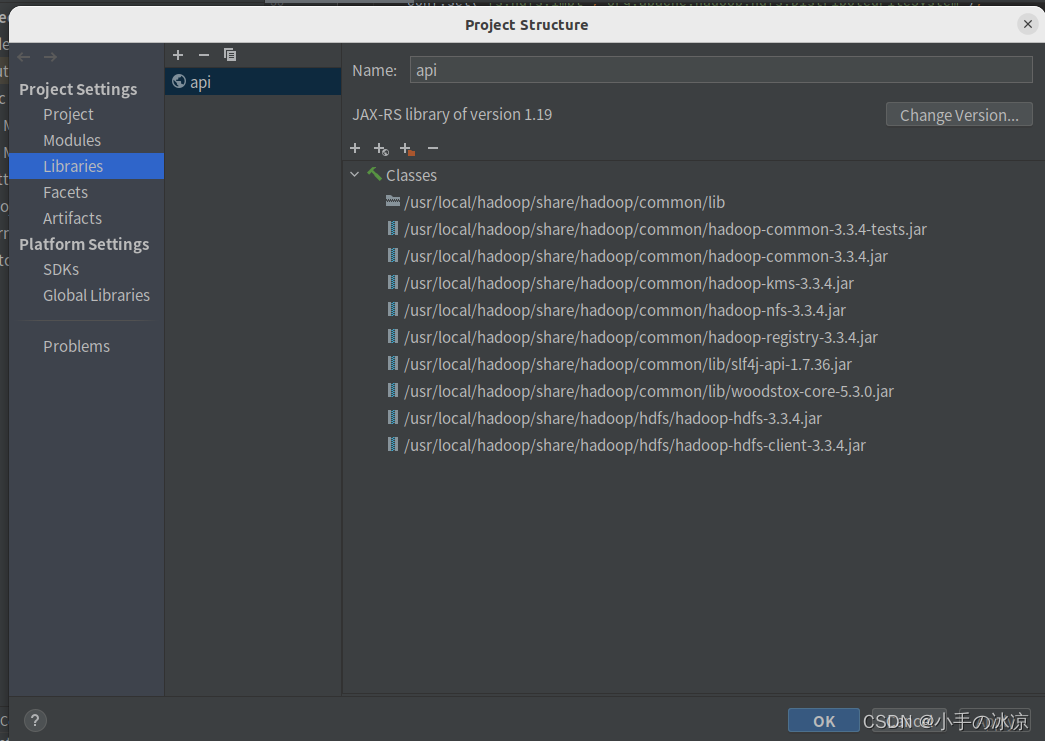
1.注意导入jar包!
2.编写Java代码
import java.io.IOException;
import java.io.PrintStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
****/过滤掉文件名满足特定条件的文件 /*
class MyPathFilter implements PathFilter {
String reg = null;
MyPathFilter(String reg) {
this.reg = reg;
}
public boolean accept(Path path) {
if (!(path.toString().matches(reg)))
return true;
return false;
}
}
/* 利用FSDataOutputStream和FSDataInputStream合并HDFS中的文件 */*
public class MergeFile {
Path inputPath = null; //待合并的文件所在的目录的路径
Path outputPath = null; //输出文件的路径
public MergeFile(String input, String output) {
this.inputPath = new Path(input);
this.outputPath = new Path(output);
}
public void doMerge() throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fsSource = FileSystem.get(URI.create(inputPath.toString()), conf);
FileSystem fsDst = FileSystem.get(URI.create(outputPath.toString()), conf);
//下面过滤掉输入目录中后缀为.doc的文件
FileStatus[] sourceStatus = fsSource.listStatus(inputPath,
new MyPathFilter(".*\.doc"));
FSDataOutputStream fsdos = fsDst.create(outputPath);
PrintStream ps = new PrintStream(System.out);
//下面分别读取过滤之后的每个文件的内容,并输出到同一个文件中
for (FileStatus sta : sourceStatus) {
//下面打印后缀不为.abc的文件的路径、文件大小
System.out.print("路径:" + sta.getPath() + " 文件大小:" + sta.getLen()
- " 权限:" + sta.getPermission() + " 内容:");
FSDataInputStream fsdis = fsSource.open(sta.getPath());
byte[] data = new byte[1024];
int read = -1;
while ((read = fsdis.read(data)) > 0) {
ps.write(data, 0, read);
fsdos.write(data, 0, read);
}
fsdis.close();
}
ps.close();
fsdos.close();
}
public static void main(String[] args) throws IOException {
MergeFile merge = new MergeFile(
"hdfs://localhost:9000/user/liuhao/",
"hdfs://localhost:9000/user/liuhao/file123.txt");
merge.doMerge();
}
}
【注意:把liuhao改成自己的名字!】
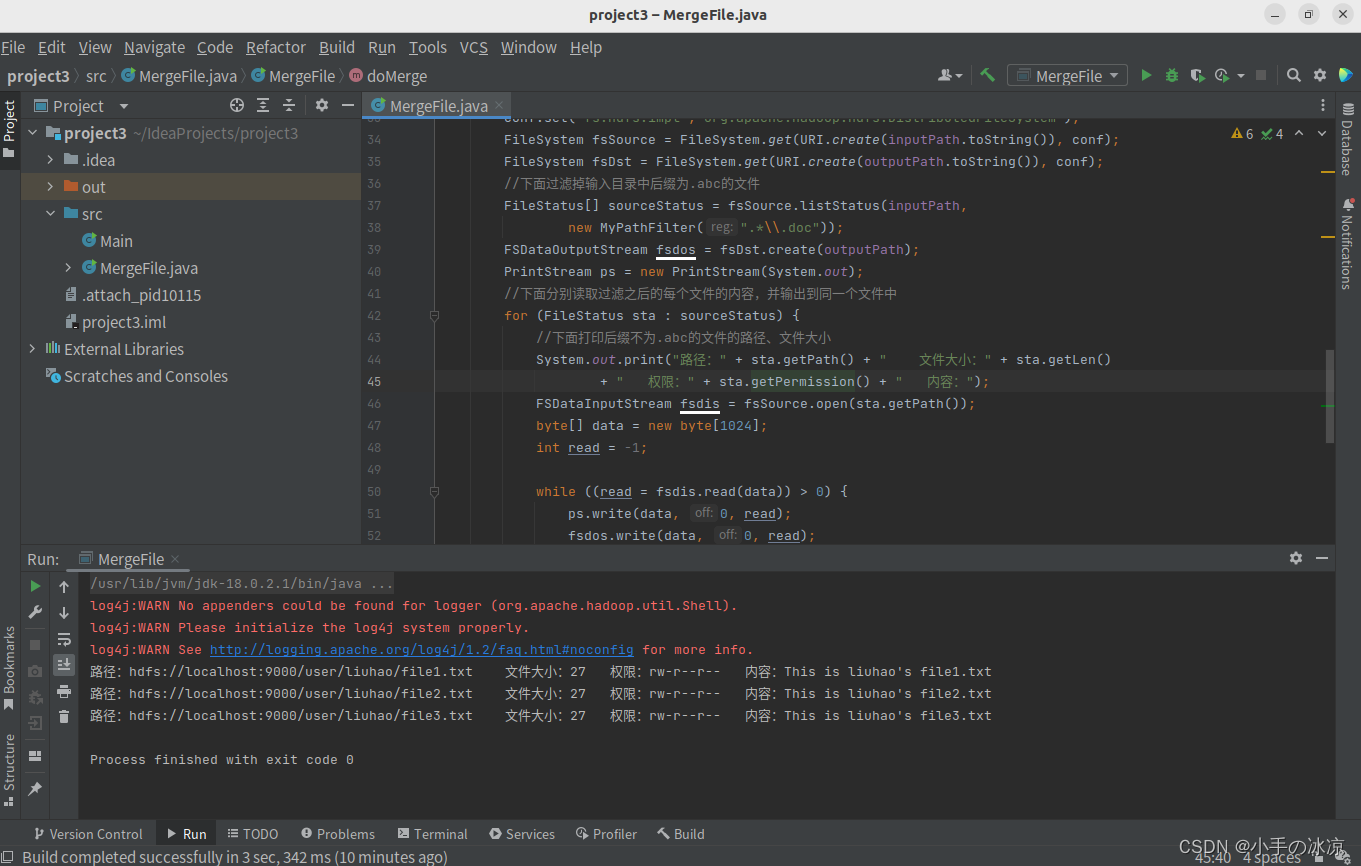
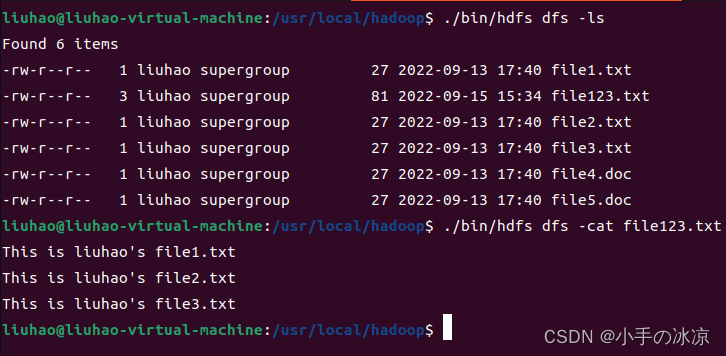
3.运行结果
版权归原作者 小手の冰凉 所有, 如有侵权,请联系我们删除。